
Cross-cloud Lakehouse for AWS Glue を使って BigQuery から Iceberg テーブルを直接参照してみた
はじめに
Google Cloud Lakehouse(旧 BigLake)のカタログフェデレーション機能による AWS Glue データカタログに存在する Iceberg テーブルの BigQuery からのクエリを試してみましたので、その際の手順を本記事でまとめます。
Google Cloud Lakehouse のクロスクラウド連携
Google Cloud Lakehouse(ドキュメントでは Lakehouse for Apache Iceberg との記載もあります)は、Google Cloud 上で Apache Iceberg 形式のテーブルを管理・参照するための機能です。
Cross-cloud Lakehouse という機能が現在プレビューとなっており、他クラウドプロバイダーに存在する Iceberg テーブルを、データの移行や ETL 処理を行うことなく Google Cloud から直接クエリできるようになっています。
機能登場当初の2026年4月時点では、AWS の 外部ロケーションまたは Google Cloud の外部ロケーションを使用する Databricks Unity Catalog カタログのみがサポートされていました。
2026年6月5日のリリースノートで、フェデレーションカタログのリモートカタログプロバイダーとして AWS Glue のサポートがプレビューとなりました。
前提条件
検証環境
以下の環境を使用しています。
- AWS:リージョン
ap-northeast-1(東京)- Glue データカタログ(Iceberg テーブル)
- S3(テーブルデータの保存先)
- Google Cloud:リージョン
asia-northeast1(東京)
なお、本記事の検証環境では Cross-Cloud Interconnect(CCI)は設定していません。
事前準備
Glue データカタログに Iceberg テーブルが作成済みで、クエリできる状態としています。本記事では Amazon Athena を使用して Iceberg テーブルの作成とサンプルデータの投入を行いました。
-- Iceberg テーブルを作成
CREATE TABLE glue_iceberg_db.sales_data (
sale_id BIGINT,
sale_ts TIMESTAMP,
amount DECIMAL(10,2),
region STRING
)
LOCATION 's3://<バケット名>/iceberg_external/sales_data/'
TBLPROPERTIES (
'table_type'='ICEBERG',
'format'='parquet'
);
-- サンプルデータを投入
INSERT INTO glue_iceberg_db.sales_data VALUES
(1001, CAST('2025-12-01 10:30:00' AS TIMESTAMP), CAST(15000.50 AS DECIMAL(10,2)), 'Tokyo'),
(1002, CAST('2025-12-01 11:45:00' AS TIMESTAMP), CAST(8500.00 AS DECIMAL(10,2)), 'Osaka'),
(1003, CAST('2025-12-01 14:20:00' AS TIMESTAMP), CAST(12300.75 AS DECIMAL(10,2)), 'Tokyo');
SELECT * FROM glue_iceberg_db.sales_data ORDER BY sale_id;
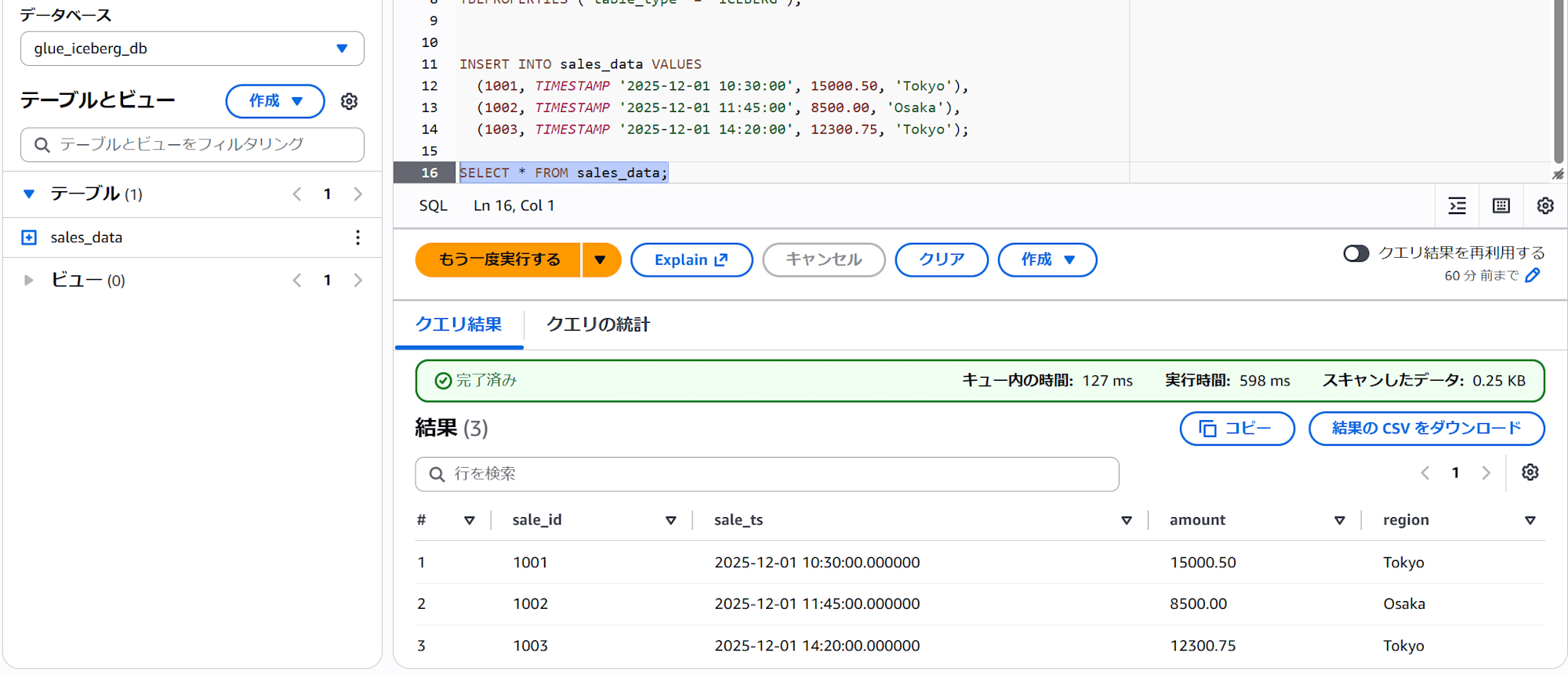
AWS 側の設定
AWS 側も含めて各種設定手順は以下に記載があります。
IAM ロールの作成
Google Cloud 側から Glue データカタログにアクセスするための IAM ロールを AWS 上で作成します。はじめにカスタム信頼ポリシーで IAM ロールを作成します。BigLake service account IDは後の手順で Google Cloud 側のフェデレーションカタログ作成後に払い出される BigLake サービスアカウント ID で更新します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "accounts.google.com"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"accounts.google.com:aud": [
"<BigLake service account ID>"
],
"accounts.google.com:sub": [
"<BigLake service account ID>"
]
}
}
}
]
}
権限ポリシーの追加
作成した IAM ロールに対し、Glue リソースへのアクセス権限と S3 バケットへの読み取り権限を付与します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "GlueRead",
"Effect": "Allow",
"Action": [
"glue:GetCatalog",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:GetTable",
"glue:GetTables"
],
"Resource": "arn:aws:glue:<リージョン>:<AWSアカウントID>:*"
},
{
"Sid": "S3Read",
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::<バケット名>",
"arn:aws:s3:::<バケット名>/*"
]
}
]
}
Google Cloud 側の設定
API の有効化
BigLake の API を有効化します。
gcloud services enable biglake.googleapis.com
フェデレーションカタログを作成
gcloud alpha biglake iceberg catalogs createでフェデレーションカタログを作成します。--federated-catalog-typeにglueを指定し、AWS アカウント ID・AWS リージョン・IAM ロール ARN を指定します。
# 変数の設定
PROJECT_ID="<プロジェクトID>"
REGION="asia-northeast1"
CATALOG_NAME="federated-catalog-glue"
AWS_ACCOUNT_ID="<AWSアカウントID>"
AWS_REGION="ap-northeast-1"
ROLE_ARN="arn:aws:iam::<AWSアカウントID>:role/<IAMロール名>"
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="glue" \
--glue-warehouse="${AWS_ACCOUNT_ID}" \
--glue-aws-region="${AWS_REGION}" \
--glue-aws-role-arn="${ROLE_ARN}"
実行結果は以下のようになり、作成後のBigLake service accountとBigLake service account IDが表示されます。次の手順でBigLake service account IDを AWS 側の信頼ポリシーに設定します。
Created catalog [projects/<プロジェクトID>/catalogs/federated-catalog-glue].
BigLake service account: blirc-xxxxxxxxxxxxx-xxxx@gcp-sa-biglakerestcatalog.iam.gserviceaccount.com
BigLake service account ID: xxxxxxxxxxxxxxxxxxxx
AWS 側の信頼ポリシーを更新
フェデレーションカタログ作成時に払い出されたBigLake service account IDを使って、先ほど作成した IAM ロールの信頼ポリシーを更新します。以下のコマンドでカタログの詳細情報からBigLake service account IDを確認できます。
gcloud alpha biglake iceberg catalogs describe ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--format="value(biglake-service-account-id)"
取得した値をaccounts.google.com:audとaccounts.google.com:subに設定して信頼ポリシーを更新します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "accounts.google.com"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"accounts.google.com:aud": "<BigLake service account ID>",
"accounts.google.com:sub": "<BigLake service account ID>"
}
}
}
]
}
なお、AWS IAM の変更は反映まで数分かかる場合があります。
メタデータ更新の有効化
カタログ作成後、Glue 側のメタデータ更新間隔を設定します。
gcloud alpha biglake iceberg catalogs update ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--refresh-interval="300s"
--refresh-intervalは、フェデレーションカタログが Glue 側のメタデータを取得し直す(同期する)頻度を指定するオプションです。
接続確認
カタログの状態を確認します。
gcloud alpha biglake iceberg catalogs describe ${CATALOG_NAME} \
--project="${PROJECT_ID}"
biglake-service-account: blirc-xxxxxxxxxxxxx-xxxx@gcp-sa-biglakerestcatalog.iam.gserviceaccount.com
biglake-service-account-id: 'xxxxxxxxxxxxxxxxxxxx'
catalog-type: CATALOG_TYPE_FEDERATED
...
federated-catalog-options:
glue-catalog-info:
aws-region: ap-northeast-1
aws-role-arn: arn:aws:iam::<AWSアカウントID>:role/<IAMロール名>
warehouse: '<AWSアカウントID>'
refresh-options:
refresh-schedule:
refresh-interval: 300s
...
続けて、データベース(名前空間)の一覧を確認します。
gcloud alpha biglake iceberg namespaces list \
--catalog="${CATALOG_NAME}" \
--project="${PROJECT_ID}"
NAME: projects/<プロジェクトID>/catalogs/federated-catalog-glue/namespaces/glue_iceberg_db
NAMESPACE-ID: glue_iceberg_db
その後、BigQuery のコンソール上からフェデレーションカタログ経由でテーブルが認識されていることを確認できました。
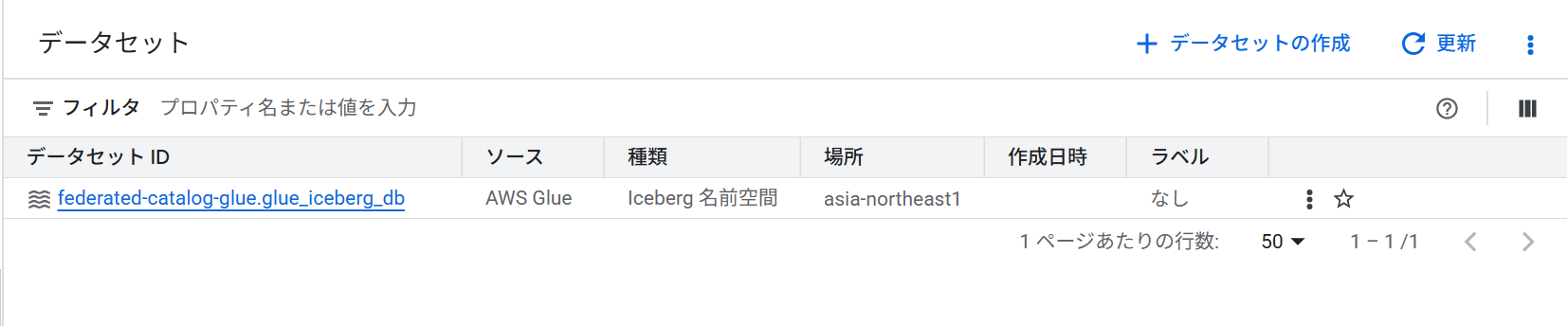
BigQuery からフェデレーションカタログのテーブルをクエリする際は、プロジェクトID.カタログ名.データベース名.テーブル名の 4 階層で指定します。
SELECT * FROM `<プロジェクトID>.federated-catalog-glue.glue_iceberg_db.sales_data` LIMIT 10
実際に SELECT 文を実行すると、Glue データカタログ上のテーブルのレコードが BigQuery から取得できました。
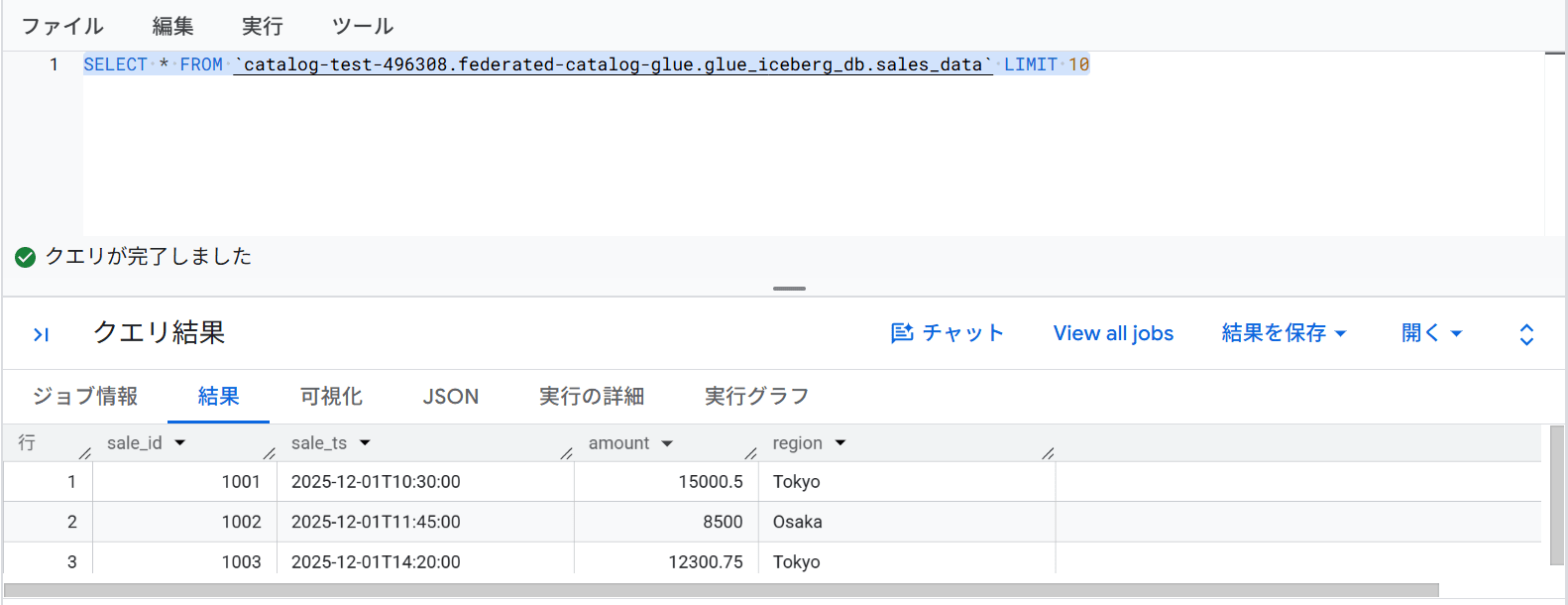
BigQuery からの書き込みを試してみる
参考までに、BigQuery 側から INSERT 文を実行してみました。この場合はエラーとなります。
INSERT INTO `<プロジェクトID>.federated-catalog-glue.glue_iceberg_db.sales_data`
(sale_id, sale_ts, amount, region)
VALUES (1006, TIMESTAMP('2025-12-03 10:00:00'), 5000.00, 'Sapporo');
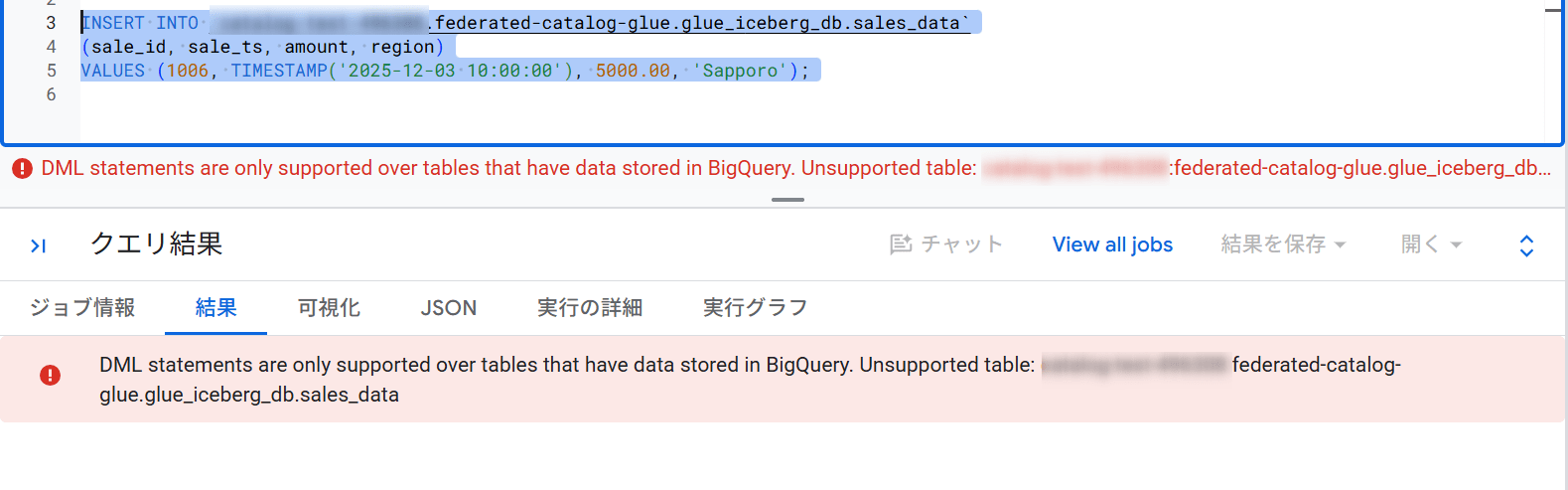
Glue 側でのデータ更新の反映確認
Glue 側でデータを更新した際に、リフレッシュ後に BigQuery へ反映されることも確認しました。
既存テーブルへのレコード追加
Athena から既存テーブルへレコードを追加します。
INSERT INTO glue_iceberg_db.sales_data VALUES
(1004, CAST('2025-12-02 09:15:00' AS TIMESTAMP), CAST(22000.00 AS DECIMAL(10,2)), 'Nagoya'),
(1005, CAST('2025-12-02 13:50:00' AS TIMESTAMP), CAST(9800.25 AS DECIMAL(10,2)), 'Fukuoka');
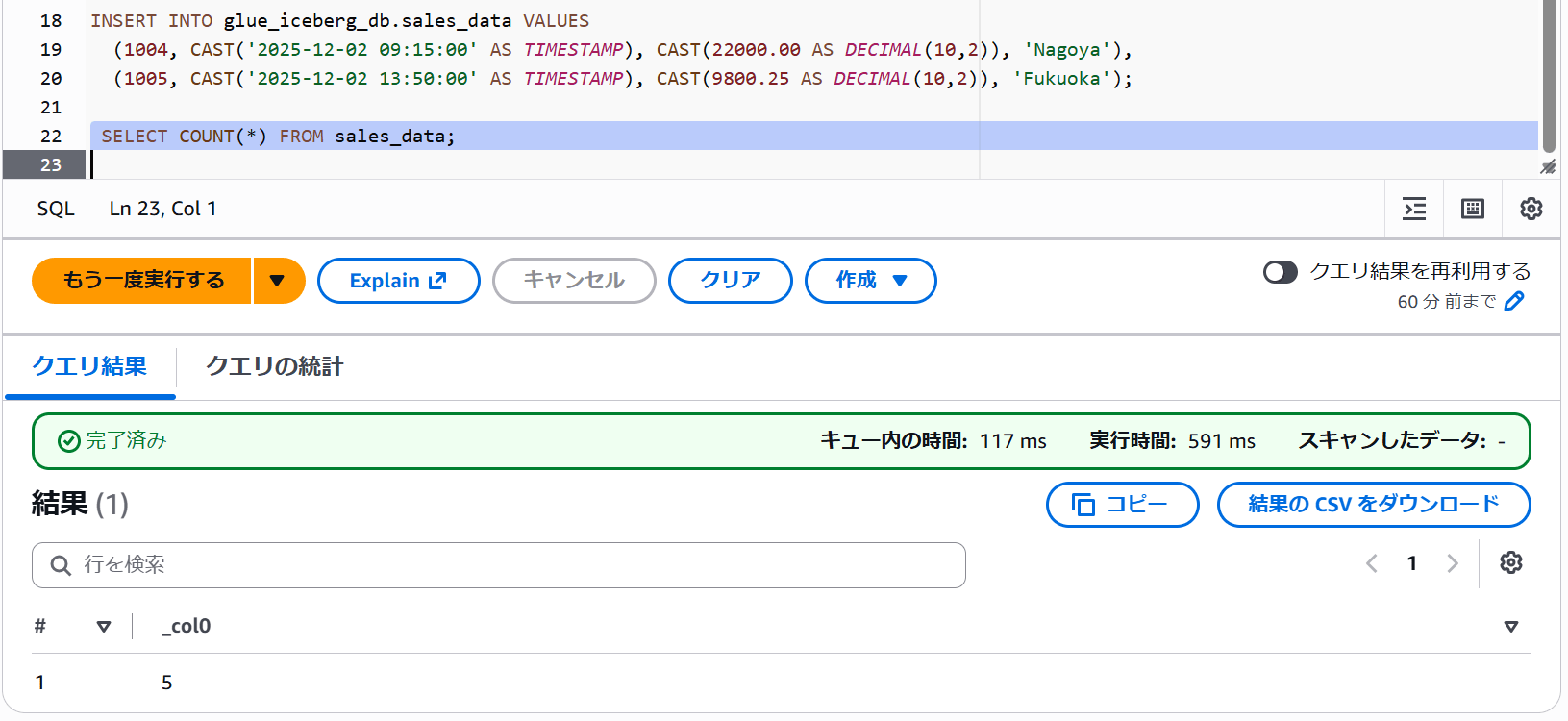
その後、BigQuery からクエリすると追加したレコードが反映されていることを確認できました。
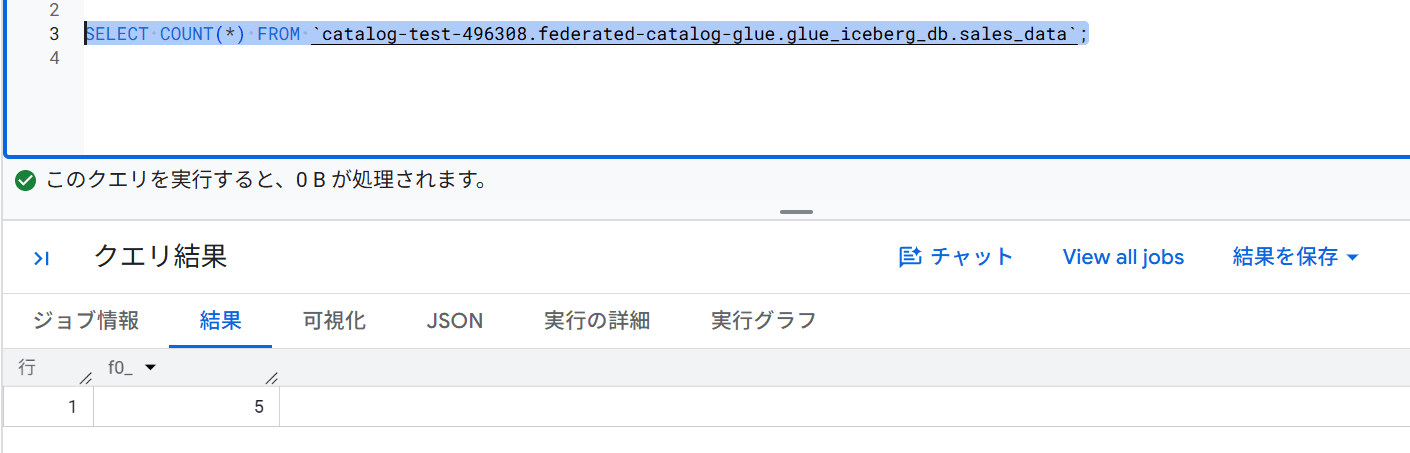
新規テーブルの作成
続けて、Athena から新規テーブルを作成します。
CREATE TABLE glue_iceberg_db.products_data (
product_id INT,
product_name STRING,
category STRING,
price DECIMAL(10,2),
created_at TIMESTAMP
)
LOCATION 's3://<バケット名>/iceberg_external/products_data/'
TBLPROPERTIES (
'table_type'='ICEBERG',
'format'='parquet'
);
INSERT INTO glue_iceberg_db.products_data VALUES
(101, 'Laptop Pro', 'Electronics', CAST(129800.00 AS DECIMAL(10,2)), CAST('2025-12-01 09:00:00' AS TIMESTAMP)),
(102, 'Wireless Mouse', 'Electronics', CAST(2980.00 AS DECIMAL(10,2)), CAST('2025-12-01 10:00:00' AS TIMESTAMP)),
(103, 'Desk Chair', 'Furniture', CAST(45000.00 AS DECIMAL(10,2)), CAST('2025-12-02 11:00:00' AS TIMESTAMP));
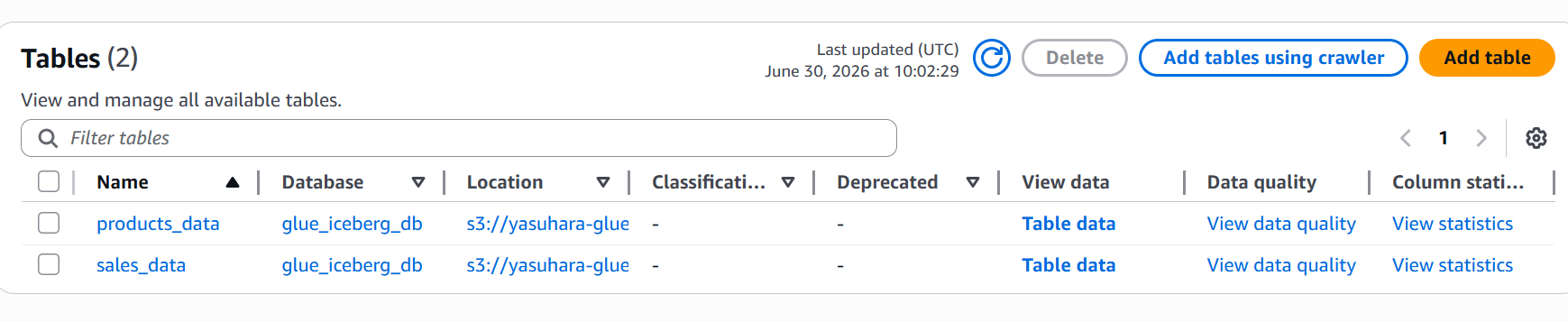
リフレッシュ間隔経過後、BigQuery 側で新規テーブルが反映されていることも確認できました。
さいごに
Lakehouse for Apache Iceberg のカタログフェデレーション機能を使用して、AWS 上の Glue データカタログにある Iceberg テーブルを Google Cloud の BigQuery から直接参照する手順を確認してみました。
こちらの内容がどなたかの参考になれば幸いです。









