
BigQuery Lakehouse カタログ Iceberg テーブルへの SQL 書き込みとクエリパフォーマンスを検証してみた。
こんにちは、みかみです。
ここのところ雨で犬の散歩に行けません。
犬の散歩と言いつつ私の運動不足解消の目的が強いので残念です。
散歩があまり好きではないらしい犬はへっちゃらなようです。
はじめに
BigQuery 管理の Iceberg テーブルを Snowflake から参照することは可能ですが、最新データを参照するためには、メタデータファイルパスを更新する必要があります。
このメタデータファイルパスの更新処理なしに最新データを参照可能な Google Cloud BigLake メタストアカタログ統合が、Snowflake で先日 GA になりました。
なお、Google Cloud の BigLake は Lakehouse に名称変更されたので、Lakehouse と BigLake は同義です。
この BigLake メタストアカタログ統合では、Snowflake からのデータ書き込みが可能なので、Snowflake → BigQuery 方向のデータ連携でもメタデータファイルパスの更新なしで最新データを参照することが可能になります。
ですが、BigLake メタストアの Iceberg テーブルは、BigQuery の SQL から直接データを書き込みすることができません
また、BigQuery の Lakehouse カタログ Iceberg テーブルの公式ドキュメントには、
クエリ速度は Cloud Storage からデータを読み取る処理と同等になります
との制限事項の記載があります。
BigQuery の Lakehouse カタログ Iceberg テーブルに、SQL レイヤからデータ書き込みするにはどうすればよいか、また、他の種類のテーブルと比べてクエリ速度はどのくらいなのか、確認してみます。
やりたいこと
- BigQuery から Snowflake に、メタデータファイルパスの更新なしに Iceberg テーブル経由でデータ連携したい
- BigQuery からの連携データは SQL レイヤから書き込みしたい
- BigQuery Lakehouse カタログ Iceberg テーブルのクエリ処理速度を確認したい
前提
Google Cloud SDK(gcloud コマンド)の実行環境は準備済みであるものとします。 本エントリでは、Cloud Shell を使用しました。
また、BigQuery や GCS など各サービス操作に必要な API の有効化と権限は付与済みです。
Snowflake 環境側でも、必要なユーザーの作成や権限付与は実施済みです。
なお、文中、Google Cloud プロジェクト ID など一部の文字は伏字に変更しています。
準備:BigQuery の Lakehouse カタログ Iceberg テーブルと、Snowflake の BigLake メタストアカタログ統合を作成
検証に使用する BigQuery の Lakehouse カタログ Iceberg テーブルと、Snowflake の BigLake メタストアカタログ統合の作成手順は、以下のブログをご参照ください。
作成した BigQuery の Lakehouse カタログ Iceberg テーブルデータを、Snowflake と BigQuery 双方から参照できることが確認できました。

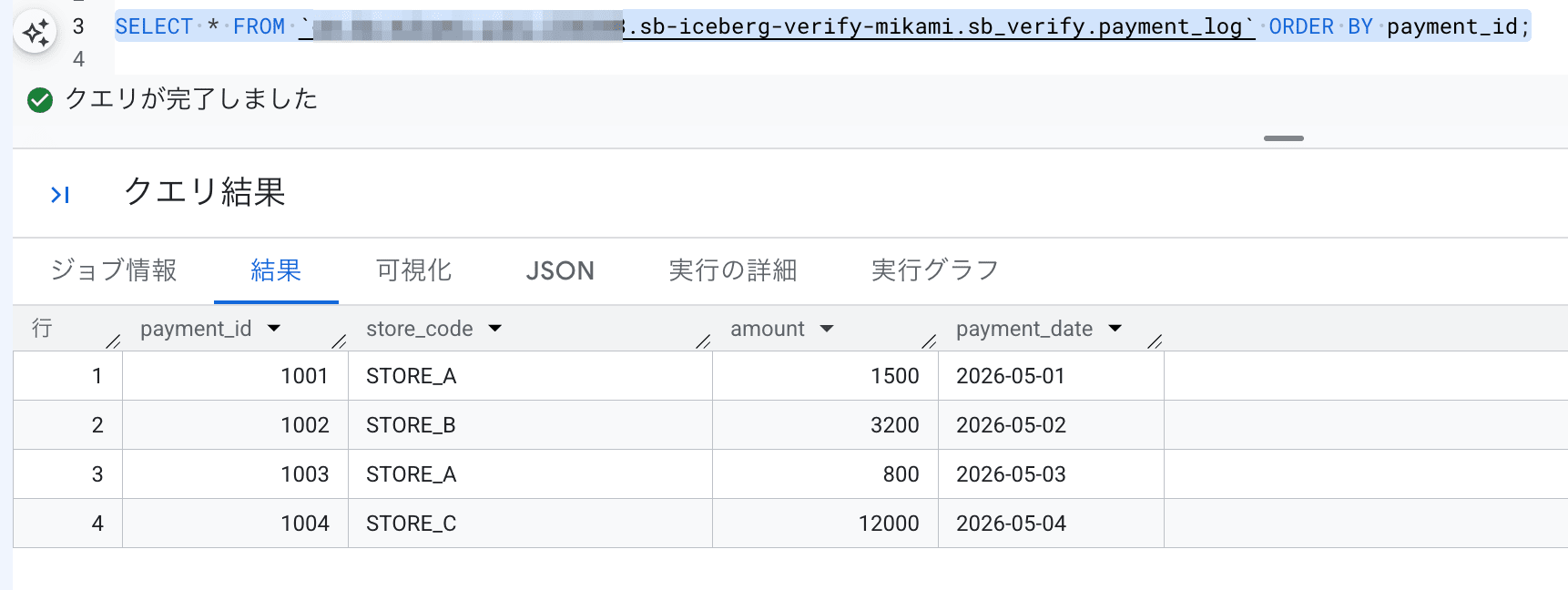
なお、BigQuery から Lakehouse カタログ Iceberg テーブルにクエリを実行する際には、FROM 句の テーブル名はプロジェクト ID 含めた完全修飾名で指定しないとエラーになります。
通常のテーブルは プロジェクト.データセット.テーブル の 3層構造なのに対して、Lakehouse カタログの Iceberg テーブルは プロジェクト.カタログ.グループ.テーブル の 4層で構成されているためです。
準備:BigQuery SQL からのデータ書き込みプロシージャを作成
BigQuery で Lakehouse カタログの Iceberg テーブルにデータを書き込むためのプロシージャを作成します。
Cloud Shell から以下のコマンドを実行して、BigQuery から Spark ジョブを実行するための connection を作成して、Spark が Lakehouse カタログと GCS にアクセスするための権限を付与します。
export PROJECT_ID="[PROJECT_ID]"
export LOCATION="asia-northeast1"
export GCS_BUCKET="sb-iceberg-verify-mikami"
bq mk --connection \
--location="$LOCATION" \
--connection_type=SPARK \
--project_id="$PROJECT_ID" \
"spark-iceberg-verify"
# サービスアカウントを変数に設定
export SPARK_SA=$(bq show --connection --project_id="$PROJECT_ID" \
--location="$LOCATION" --format=json spark-iceberg-verify \
| jq -r '.cloudResource.serviceAccountId')
# Spark サービスアカウントへの権限付与
gcloud storage buckets add-iam-policy-binding "gs://$GCS_BUCKET" \
--member="serviceAccount:$SPARK_SA" --role="roles/storage.objectAdmin"
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="serviceAccount:$SPARK_SA" --role="roles/biglake.admin"
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="serviceAccount:$SPARK_SA" --role="roles/serviceusage.serviceUsageConsumer"
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="serviceAccount:$SPARK_SA" --role="roles/bigquery.dataViewer"
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="serviceAccount:$SPARK_SA" --role="roles/bigquery.jobUser"
続いて BigQuery で以下の SQL を実行して、プロシージャで書き込むデータを格納したテーブルを作成します。
追加用データテーブルには、はじめに Lakehouse カタログに投入した payment_id 1001〜1004 の続き(1005〜1010)の6件のデータを格納します。
CREATE OR REPLACE TABLE
iceberg_dataset_tokyo.new_payments
AS
SELECT
payment_id,
CASE MOD(payment_id, 3)
WHEN 0 THEN 'STORE_A' WHEN 1 THEN 'STORE_B' ELSE 'STORE_C'
END AS store_code,
(MOD(payment_id, 5) + 1) * 2000 AS amount,
DATE_ADD(DATE '2026-05-05', INTERVAL (payment_id - 1005) DAY) AS payment_date
FROM UNNEST(GENERATE_ARRAY(1005, 1010)) AS payment_id;
SELECT * FROM iceberg_dataset_tokyo.new_payments
ORDER BY payment_id;
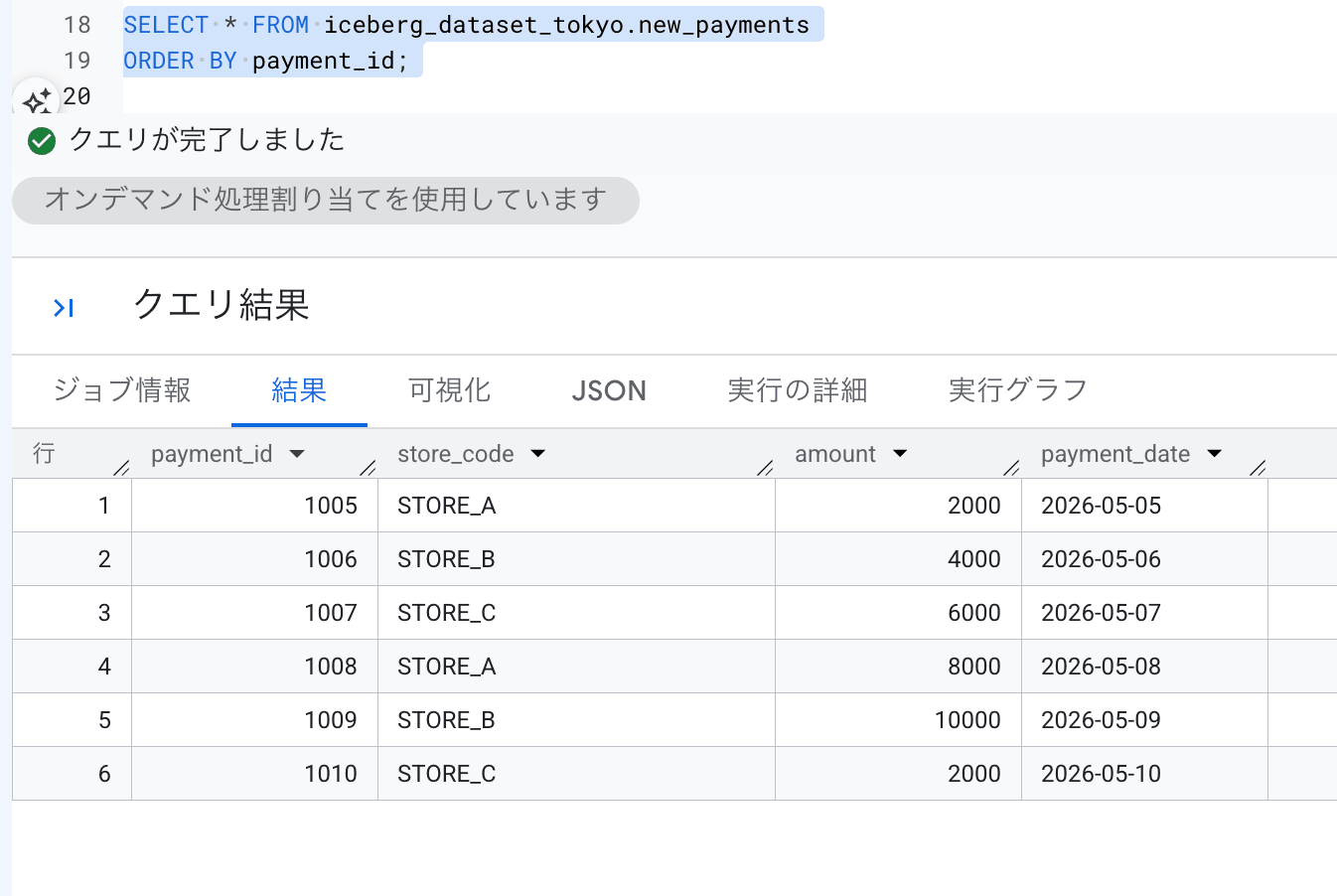
追加データが準備できました。
以下の SQL で、追加データテーブルを読み込み、Lakehouse カタログの payment_log テーブルに書き込む Spark プロシージャを作成して実行します。
CREATE OR REPLACE PROCEDURE
iceberg_dataset_tokyo.append_to_iceberg()
WITH CONNECTION `[PROJECT_ID].asia-northeast1.spark-iceberg-verify`
OPTIONS (
engine = 'SPARK',
runtime_version = '2.2'
)
LANGUAGE python AS R"""
import subprocess, sys
subprocess.run(
[sys.executable, "-m", "pip", "install", "pyiceberg[gcsfs,pyarrow]", "--quiet"],
check=True
)
from pyspark.sql import SparkSession
import google.auth
import google.auth.transport.requests
from pyiceberg.catalog.rest import RestCatalog
from google.cloud import bigquery as bq_lib
creds, _ = google.auth.default(
scopes=["https://www.googleapis.com/auth/cloud-platform"]
)
creds.refresh(google.auth.transport.requests.Request())
spark = SparkSession.builder \
.appName("append_to_iceberg") \
.getOrCreate()
# BigQuery Python クライアントで読み込み(Storage Read API 不使用)
bq_client = bq_lib.Client(
project="[PROJECT_ID]",
credentials=creds
)
arrow_table = (
bq_client
.query(
'SELECT '
'CAST(payment_id AS INT64) AS payment_id, '
'CAST(store_code AS STRING) AS store_code, '
'CAST(amount AS INT64) AS amount, '
'CAST(payment_date AS DATE) AS payment_date '
'FROM `[PROJECT_ID].iceberg_dataset_tokyo.new_payments`'
)
.result()
.to_arrow(create_bqstorage_client=False)
)
print(f"Source rows: {len(arrow_table)}")
catalog = RestCatalog(
name="lakehouse",
**{
"uri": "https://biglake.googleapis.com/iceberg/v1/restcatalog",
"warehouse": "gs://sb-iceberg-verify-mikami",
"token": creds.token,
"header.x-goog-user-project": "[PROJECT_ID]",
"header.X-Iceberg-Access-Delegation": "vended-credentials",
}
)
tbl = catalog.load_table("sb_verify.payment_log")
tbl.append(arrow_table)
result = tbl.scan().to_arrow()
print(result)
print(f"Total rows: {len(result)}")
""";
CALL iceberg_dataset_tokyo.append_to_iceberg();
Spark を起動する必要があるため、完了まで3分ほどがかかりました。
正常に完了したようなので、結果を確認してみます。
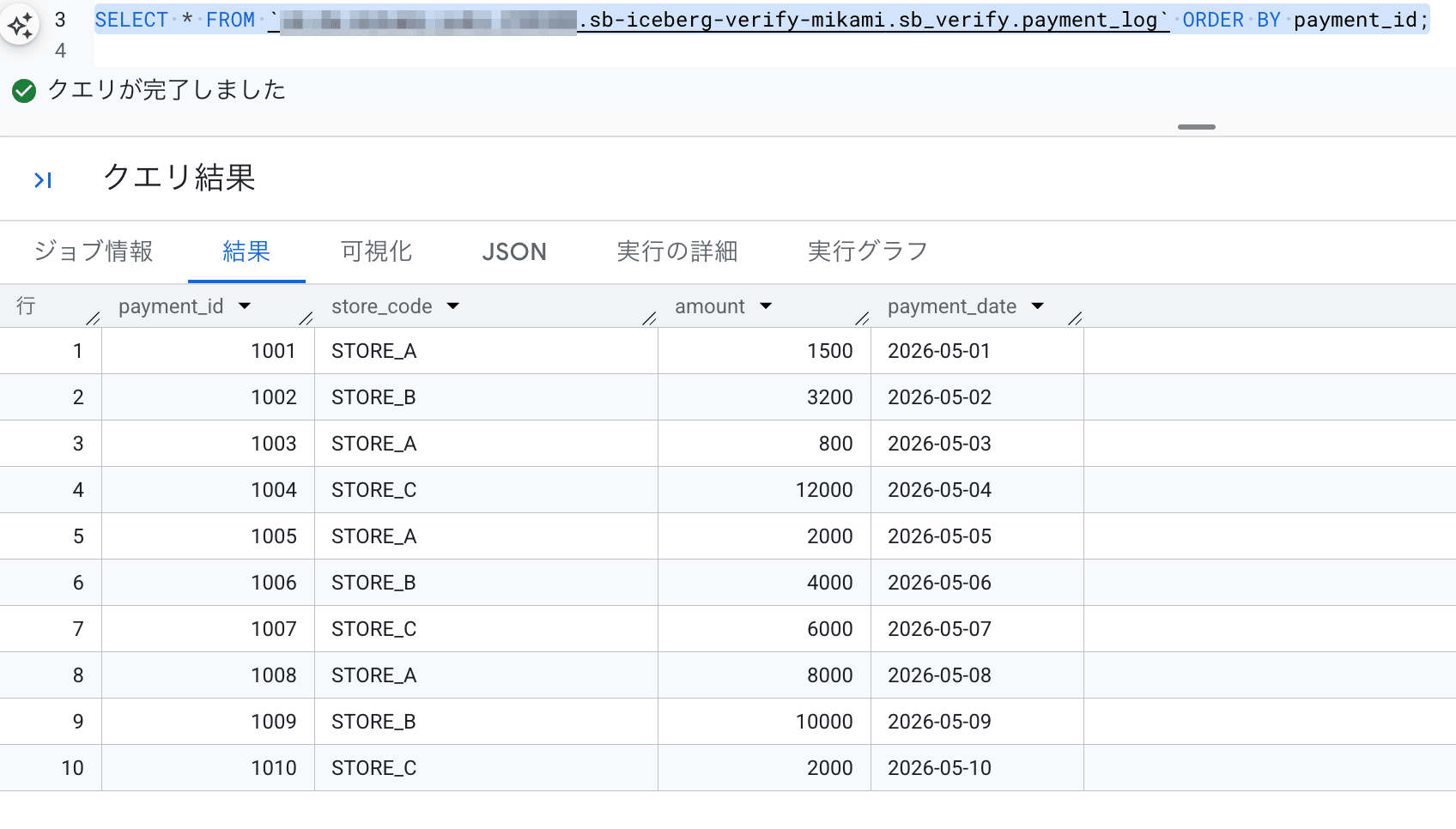
BigQuery の SQL レイヤから、payment_id 1005〜1010のデータが、Lakehouse カタログの Iceberg テーブルに追加されたことが確認できました。
Snowflake からも追加データが参照できるか確認してみます。
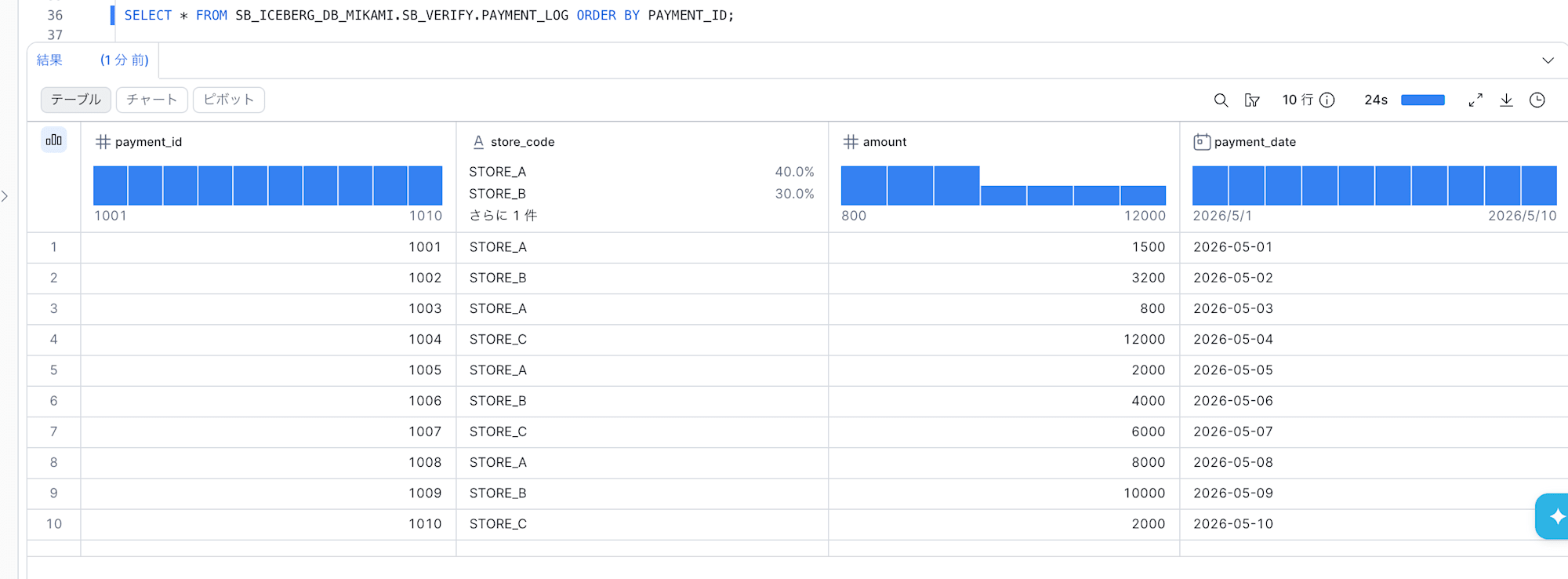
メタデータファイルパスの更新なしで、BigQuery の SQL レイヤで追加した最新データが Snowflake から参照できることが確認できました。
Lakehouse カタログ Iceberg テーブル のクエリパフォーマンスを確認
公式ドキュメントの以下の記載を検証してみます。
BigQuery エンジンの Lakehouse ランタイム カタログのテーブルに対するクエリのパフォーマンスは、標準的な BigQuery テーブルのデータに対するクエリよりも低速になる可能性があります。一般的に、クエリ速度は Cloud Storage からデータを読み取る処理と同等になります。
以下4種類の BigQuery テーブルに対してクエリを実行して、平均処理時間を確認します。
- Native テーブル
- 外部テーブル(Parquet ファイル参照)
- Lakehouse カタログの Iceberg テーブル
- BigQuery 管理の Iceberg テーブル
準備:Nativeテーブルを作成
BigQuery で以下の SQL を実行して、payment_id = 1〜1000000 の 100万件のデータを格納した Native テーブルを作成します。
CREATE OR REPLACE TABLE
iceberg_dataset_tokyo.payment_log_std
AS
SELECT
payment_id,
CONCAT('STORE_', LPAD(CAST(MOD(payment_id, 50) + 1 AS STRING), 3, '0')) AS store_code,
CASE MOD(payment_id, 3) WHEN 0 THEN 'CREDIT' WHEN 1 THEN 'DEBIT' ELSE 'QR' END
AS payment_method,
CAST(100 + RAND() * 49900 AS INT64) AS amount,
DATE_ADD(DATE '2022-01-01', INTERVAL MOD(payment_id, 2000) DAY) AS payment_date
FROM UNNEST(GENERATE_ARRAY(1, 1000000)) AS payment_id;
テーブルデータを確認します。
SELECT COUNT(*) as count, MIN(payment_id) as min_id, MAX(payment_id) as max_id FROM iceberg_dataset_tokyo.payment_log_std;
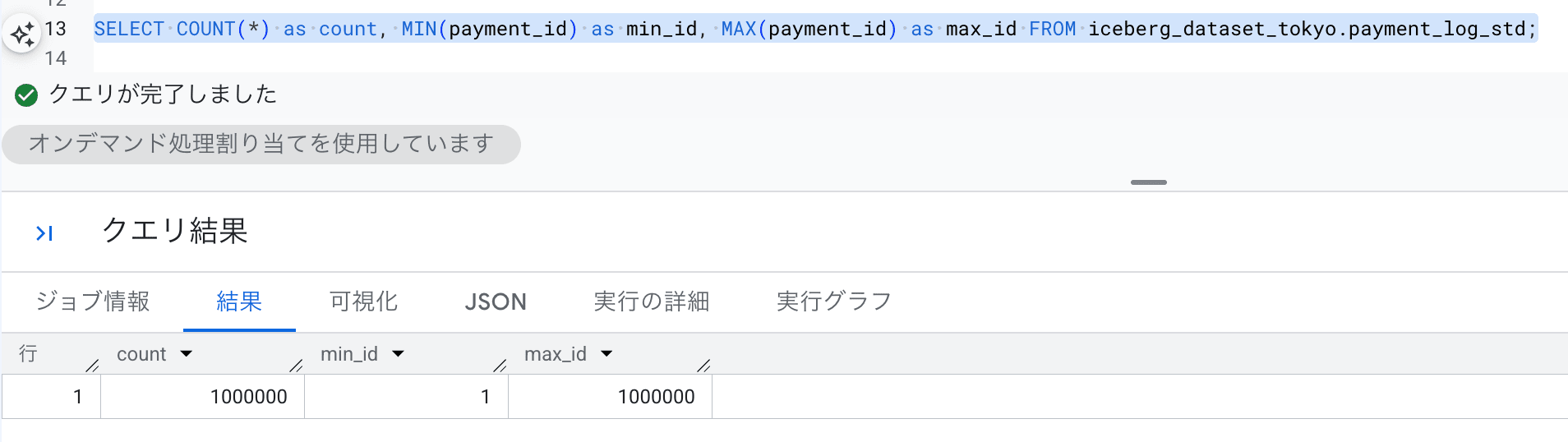
検証用データを格納した、Native テーブルが作成できました。
準備:外部テーブルを作成
以下の SQL で、先ほど作成した Native テーブルデータを Parquet ファイルで GCS にエクスポートして、ファイルを参照する外部テーブルを作成しました。
-- データエクスポート
EXPORT DATA OPTIONS (
uri = 'gs://sb-iceberg-verify-mikami/perf_test/parquet/*.parquet',
format = 'PARQUET', overwrite = true
)
AS SELECT * FROM `[PROJECT_ID].iceberg_dataset_tokyo.payment_log_std`;
-- 外部テーブルを作成
CREATE OR REPLACE EXTERNAL TABLE
`[PROJECT_ID].iceberg_dataset_tokyo.payment_log_ext`
OPTIONS (
format = 'PARQUET',
uris = ['gs://sb-iceberg-verify-mikami/perf_test/parquet/*.parquet']
);
準備:Lakehouse カタログ Iceberg テーブルを作成
続いて、今回の検証対象となる、Lakehouse カタログ Iceberg テーブルです。
Cloud Shell で以下を実行して、Lakehouse カタログ の Iceberg テーブルを作成し、外部テーブル用に出力した Parquet ファイルを取り込みました。
cat > create_perf_table.py << 'EOF'
import os, time
import google.auth, google.auth.transport.requests
import pyarrow as pa, pyarrow.parquet as pq
from google.cloud import storage
from pyiceberg.catalog.rest import RestCatalog
creds, _ = google.auth.default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
creds.refresh(google.auth.transport.requests.Request())
catalog = RestCatalog(
name="lakehouse",
**{
"uri": "https://biglake.googleapis.com/iceberg/v1/restcatalog",
"warehouse": f"gs://{os.environ['GCS_BUCKET']}",
"token": creds.token,
"header.x-goog-user-project": os.environ["PROJECT_ID"],
"header.X-Iceberg-Access-Delegation": "vended-credentials",
},
)
# GCS の Parquet ファイルを読み込んで Iceberg テーブルに書き込む
client = storage.Client(project=os.environ["PROJECT_ID"])
blobs = list(client.bucket(os.environ["GCS_BUCKET"]).list_blobs(prefix="perf_test/parquet/"))
print(f"Parquet files: {len(blobs)}")
combined = pa.concat_tables([
pq.read_table(f"gs://{os.environ['GCS_BUCKET']}/{b.name}") for b in blobs
])
print(f"Total rows: {len(combined)}")
t = catalog.create_table_if_not_exists("sb_verify.payment_log_perf", schema=combined.schema)
t0 = time.perf_counter()
t.append(combined)
print(f"Write elapsed: {time.perf_counter()-t0:.1f}s")
EOF
python3 create_perf_table.py
準備:BigQuery 管理 Iceberg テーブルを作成
最後に、BigQuery 管理の Iceberg テーブルです。
Cloud Shell で以下を実行して、BigQuery コネクションを作成して GCS バケットへのアクセス権限を付与します。
export PROJECT_ID="[PROJECT_ID]"
export LOCATION="asia-northeast1"
export GCS_BUCKET="sb-iceberg-verify-mikami"
bq mk --connection \
--location="$LOCATION" \
--connection_type=CLOUD_RESOURCE \
--project_id="$PROJECT_ID" \
bq-iceberg-resource
export RESOURCE_SA=$(bq show --connection --project_id="$PROJECT_ID" \
--location="$LOCATION" --format=json bq-iceberg-resource \
| jq -r '.cloudResource.serviceAccountId')
gcloud storage buckets add-iam-policy-binding "gs://$GCS_BUCKET" \
--member="serviceAccount:$RESOURCE_SA" \
--role="roles/storage.objectAdmin"
続いて以下の SQL で、検証用データ格納した BigQuery 管理の Iceberg テーブルを作成しました。
CREATE OR REPLACE TABLE
iceberg_dataset_tokyo.payment_log_bq_iceberg
WITH CONNECTION `[PROJECT_ID].asia-northeast1.bq-iceberg-resource`
OPTIONS (
table_format = 'ICEBERG',
storage_uri = 'gs://sb-iceberg-verify-mikami/bq_iceberg/'
)
AS SELECT * FROM
iceberg_dataset_tokyo.payment_log_std;
各テーブルのクエリ実行速度を確認
キャッシュ無効の指定をして、各テーブルに SELECT クエリを実行します。
Cloud Shell から以下のコマンドで、各クエリ5〜6回ずつ実行しました。
# 1. Native テーブル
bq query --use_legacy_sql=false --nouse_cache \
"SELECT store_code, payment_method, SUM(amount) AS total, COUNT(*) AS cnt
FROM \`[PROJECT_ID].iceberg_dataset_tokyo.payment_log_std\`
GROUP BY store_code, payment_method ORDER BY total DESC"
# 2. 外部テーブル(Parquet)
bq query --use_legacy_sql=false --nouse_cache \
"SELECT store_code, payment_method, SUM(amount) AS total, COUNT(*) AS cnt
FROM \`[PROJECT_ID].iceberg_dataset_tokyo.payment_log_ext\`
GROUP BY store_code, payment_method ORDER BY total DESC"
# 3. Lakehouse カタログ Iceberg テーブル
bq query --use_legacy_sql=false --nouse_cache \
"SELECT store_code, payment_method, SUM(amount) AS total, COUNT(*) AS cnt
FROM \`[PROJECT_ID].sb-iceberg-verify-mikami.sb_verify.payment_log_perf\`
GROUP BY store_code, payment_method ORDER BY total DESC"
# 4. BigQuery 管理 Iceberg テーブル
bq query --use_legacy_sql=false --nouse_cache \
"SELECT store_code, payment_method, SUM(amount) AS total, COUNT(*) AS cnt
FROM \`[PROJECT_ID].iceberg_dataset_tokyo.payment_log_bq_iceberg\`
GROUP BY store_code, payment_method ORDER BY total DESC"
以下の SQL で、それぞれのテーブルに対するクエリ実行時間の平均値・最小値・最大値・スキャンデータ量を確認します。
SELECT
CASE
WHEN REGEXP_CONTAINS(query, r'payment_log_std') THEN '1.Native テーブル'
WHEN REGEXP_CONTAINS(query, r'payment_log_ext') THEN '2.外部テーブル(Parquet)'
WHEN REGEXP_CONTAINS(query, r'payment_log_perf') THEN '3.Lakehouse Iceberg テーブル'
WHEN REGEXP_CONTAINS(query, r'payment_log_bq_iceberg') THEN '4.BigQuery 管理 Iceberg テーブル'
ELSE 'その他'
END AS target_table,
ROUND(AVG(TIMESTAMP_DIFF(end_time, start_time, MILLISECOND)) / 1000.0, 2)
AS avg_elapsed_sec,
ROUND(MIN(TIMESTAMP_DIFF(end_time, start_time, MILLISECOND)) / 1000.0, 2)
AS min_elapsed_sec,
ROUND(MAX(TIMESTAMP_DIFF(end_time, start_time, MILLISECOND)) / 1000.0, 2)
AS max_elapsed_sec,
ROUND(AVG(total_bytes_processed) / POW(1024, 3), 3) AS avg_processed_gb
FROM `[PROJECT_ID]`.`region-asia-northeast1`.INFORMATION_SCHEMA.JOBS
WHERE
statement_type = 'SELECT'
AND cache_hit = false
AND creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 24 HOUR)
AND REGEXP_CONTAINS(query, r'payment_log_(std|perf|ext|bq_iceberg)')
GROUP BY target_table
ORDER BY target_table;
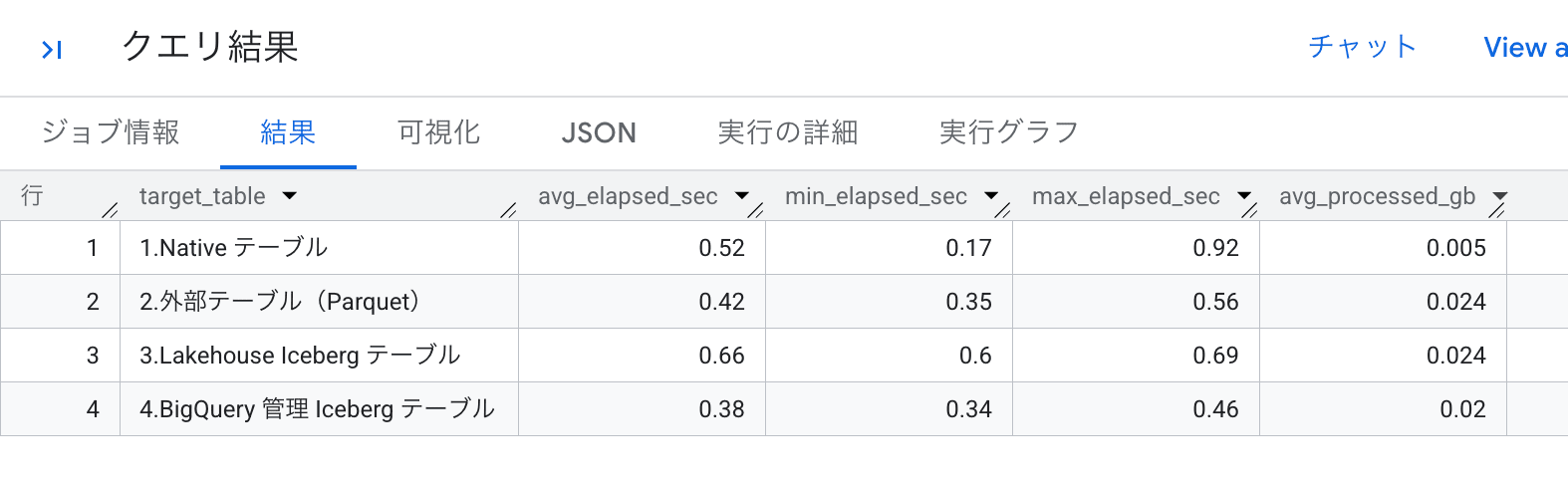
外部テーブル(Parquet)と比較しても、Lakehouse カタログの Iceberg テーブルは処理時間が長くなる傾向が見られました。
BigQuery では 列指向フォーマットの Parquet ファイルの処理速度は速い傾向が見られるため、Parquet ファイルを参照する外部テーブルではそれほど目立った速度遅延は見られないようです。
一方、Lakehouse カタログ Iceberg テーブルもデータは Parquet 形式ですが、メタデータの管理が外部カタログ(Lakehouse)側にあるため、メタデータ解決処理が必要なために処理時間が長いのではないかと思われます。
また、BigQuery 管理の Iceberg テーブルは、Lakehouse カタログの Iceberg テーブルと比べてだいぶ速い結果となりました。
BigQuery 管理の Iceberg テーブルはメタデータを BigQuery が直接管理するため、外部カタログへのアクセスが不要となり、処理時間が大幅に短縮されたと考えられます。
まとめ(所感)
BigQuery Lakehouse カタログの Iceberg テーブルを経由して、BigQuery - Snowflake 間のデータ連携できることが確認できました。
しかし、処理速度や BigQuery SQL レイヤからのデータ書き込みなどにまだ課題が残る印象です。
マルチプラットフォーム間のデータ連携をシームレスに実現できるのは大きなメリットですが、データ書き込み方法やクエリ速度の制約事項を考慮すると、現時点では本番運用は難しい印象を受けました。
とはいえ、処理速度が許容できる場合や連携データ量が少ない場合など、ユースケースによっては十分に実用的な選択肢ではないかと思います。
マルチクラウド・マルチプラットフォーム間のデータ連携方法を実現できるアップデートに、今後も期待したいと思います。
参考
- Lakehouse ランタイム カタログについて | BigQuery ドキュメント
- June 2, 2026: Google Cloud BigLake Metastore catalog integration (General availability) | Snowflake リリースノート
- Configure a catalog integration for Google Cloud BigLake Metastore | Snowflake ドキュメント
- [新機能]Snowflake から Google Cloud の Lakehouse ランタイム カタログに Apache Iceberg REST カタログ統合を使用して接続できるようになりました | DevelopersIO
- BigQuery tables for Apache Icebergで定義されたテーブルをSnowflakeのIceberg Tableとしてクエリできるようにしてみた | DevelopersIO
- BigLake 改め Google Cloud Lakehouse で AWS 側の Iceberg を BigQuery から直接アクセス可能になりました #GoogleCloudNext | DevelopersIO









