
BigQuery Data Transfer Service で、Snowflake のテーブルデータを増分転送してみた。
こんにちは、みかみです。
お祭りなど人の多いところで飼い犬を連れて歩いていると、すれ違う人が「アリクイ?」と会話しているのをしばしば耳にします。
私も似てると思ってるので、ちょっと嬉しい気持ちで聞いてます。
はじめに
BigQuery Data Transfer Serviceは(DTS)は、Teradata や Amazon Redshift などの様々な外部サービスのデータを BigQuery に取り込むことができる、Google Cloud のデータ連携サービスです。
スケジュール実行を設定することも可能で、自分でバッチ実装する必要なく GUI から転送ジョブを作成するだけでデータ連携パイプラインが構築できます。
データ連携元として Snowflake も選択できるようになりましたが、Snowflake サポート開始直後はテーブルデータの全件転送しかサポートされていませんでした。
現在も日本語の公式ドキュメントでは増分転送は非サポートの記載がありますが、英語版のドキュメントには、増分転送の記載があります。
DTS による Snowflake データの増分転送のジョブ作成手順と挙動を確認してみました。
なお、DTS を使って AWS 環境からデータ転送を行う場合、AWS 認証情報には IAM ユーザーのアクセスキーとシークレットアクセスキーを使う必要があります。
キーの発行には、漏洩時の不正アクセスや情報流出のリスクが伴うため、取り扱いには十分ご注意ください。
やりたいこと
- DTS の Snowflake データ増分転送のジョブ作成手順・挙動を確認したい
- DTS によるデータ転送時に、Snowflake 固有のデータ型が BigQuery ではどうなるのか確認したい。
前提
Google Cloud SDK(gcloud コマンド)の実行環境は準備済みであるものとします。 本エントリでは、Cloud Shell を使用しました。
また、BigQuery や Data Transfer Service など各サービス操作に必要な API の有効化と権限は付与済みです。
Snowflke や AWS 環境側でも、必要なユーザーの作成や権限付与は実施済みです。
なお、文中、Google Cloud プロジェクト ID や Snowflake 認証情報など一部の文字は伏字に変更しています。
本ブログの検証に使用した Snowflake の AWS と BigQuery のデータセットは、ともに東京リージョンです。
準備:Snowflake テーブル作成
まずは、連携元となる Snowflake のテーブルを作成して、データを挿入します。
Snowflake で以下の SQL を実行して、テーブルを作成後に連携データを3件 INSERT しました。
-- テーブル作成
CREATE OR REPLACE TABLE DTS_TYPE_TEST (
id NUMBER(38, 0) NOT NULL,
col_number NUMBER(18, 2),
col_int INT,
col_bigint BIGINT,
col_smallint SMALLINT,
col_tinyint TINYINT,
col_byteint BYTEINT,
col_float FLOAT,
col_double DOUBLE,
col_varchar VARCHAR(256),
col_char CHAR(10),
col_string STRING,
col_binary BINARY(16),
col_varbinary VARBINARY(16),
col_boolean BOOLEAN,
col_date DATE,
col_time TIME,
col_timestamp TIMESTAMP,
col_ts_ltz TIMESTAMP_LTZ,
col_ts_ntz TIMESTAMP_NTZ,
col_datetime DATETIME,
col_ts_tz TIMESTAMP_TZ,
col_object OBJECT,
col_variant VARIANT,
col_array ARRAY,
updated_at TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP()
);
-- 初期データ投入(id=1〜3)
INSERT INTO DTS_TYPE_TEST
SELECT
1, 12345.67, 42, 9999999999, 32767, 127, 255, 3.14159, 2.71828,
'hello world', 'CHAR ', 'string value',
TO_BINARY('DEADBEEF', 'HEX'), TO_BINARY('CAFEBABE', 'HEX'),
TRUE, '2026-05-15'::DATE, '12:34:56'::TIME,
'2026-05-15 12:34:56'::TIMESTAMP,
'2026-05-15 12:34:56 +09:00'::TIMESTAMP_LTZ,
'2026-05-15 12:34:56'::TIMESTAMP_NTZ,
'2026-05-15 12:34:56'::DATETIME,
'2026-05-15 12:34:56 +09:00'::TIMESTAMP_TZ,
OBJECT_CONSTRUCT('a', 1, 'b', 'two'),
PARSE_JSON('{"key": "value", "num": 42}'),
ARRAY_CONSTRUCT(1, 'two', TRUE, NULL),
'2026-05-15 00:00:00'::TIMESTAMP_NTZ
UNION ALL SELECT
2, 99.99, 10, 100, 10, 5, 20, 1.41421, 1.73205,
'foo', 'BAR ', 'text value',
TO_BINARY('11223344', 'HEX'), TO_BINARY('55667788', 'HEX'),
FALSE, '2026-05-15'::DATE, '09:00:00'::TIME,
'2026-05-15 09:00:00'::TIMESTAMP,
'2026-05-15 09:00:00 +09:00'::TIMESTAMP_LTZ,
'2026-05-15 09:00:00'::TIMESTAMP_NTZ,
'2026-05-15 09:00:00'::DATETIME,
'2026-05-15 09:00:00 +09:00'::TIMESTAMP_TZ,
OBJECT_CONSTRUCT('x', 10),
PARSE_JSON('{"status": "active"}'),
ARRAY_CONSTRUCT('a', 'b'),
'2026-05-15 00:00:00'::TIMESTAMP_NTZ
UNION ALL SELECT
3, 1.00, 1, 1, 1, 1, 1, 1.0, 1.0,
NULL, NULL, NULL, NULL, NULL,
NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL,
NULL, NULL, NULL,
'2026-05-15 00:00:00'::TIMESTAMP_NTZ;
また、以下の SQL を実行して、変更履歴を有効化しておきます。
ALTER TABLE MIKAMI_DB.PUBLIC.DTS_TYPE_TEST SET CHANGE_TRACKING = TRUE;
以下のテーブルが作成できました。
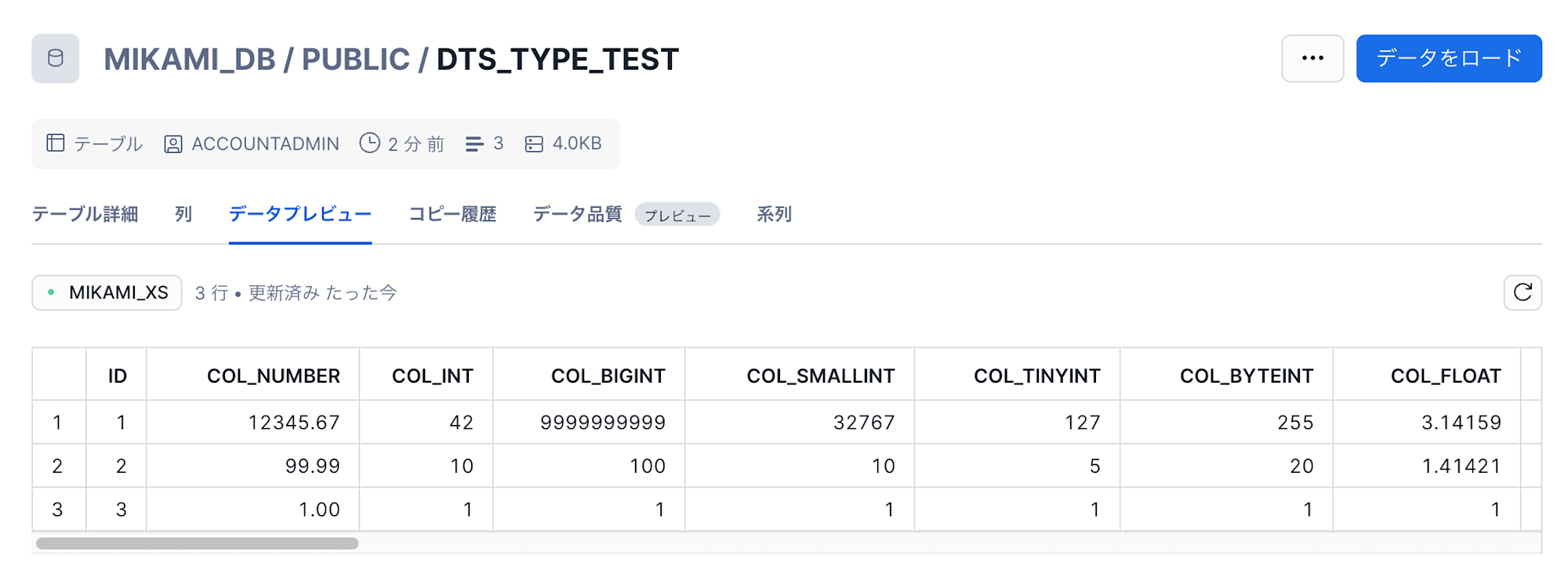
準備:AWS S3 バケットと Snowflake S3 統合を作成
DTS ジョブがデータ転送を行う際には、Snowflake データを一度 S3 にエクスポートし、S3 から GCS バケットに転送後、GCS から BigQuery にロードする流れとなります。
Google Cloud 側の GCS バケットはユーザーのプロジェクトとは別の Google Cloud 管理のテナントプロジェクトに作成されるので準備は不要ですが、AWS 側の S3 バケットは明示的に作成して Snowflake からのデータをエクスポートできよう準備しておく必要があります。
マネージドサービスのため、中間処理のデータエクスポートやファイル転送を意識する必要はありませんが、DTS 実行ログを見るとこのデータの流れが確認できます。
本検証では、AWS S3 バケットと Snowflake の Storage Integration(S3 統合)は作成済みのものを使います。
作成・設定手順は以下をご参照ください。
準備:Snowflake ユーザー作成
DTS 用の Snowflake サービスユーザーを作成して、データ転送時に使用するロールやウェアハウスを指定します。
以下の SQL でユーザーに付与するロールを作成し、連携元テーブルがあるデータベース・スキーマ・テーブル、ウェアハウスと S3 統合の使用権限を付与しました。
-- DTSユーザー専用ロール作成
CREATE ROLE MIKAMI_DTS_ROLE;
GRANT ROLE MIKAMI_DTS_ROLE TO ROLE SYSADMIN;
-- 必要な権限を付与
GRANT USAGE ON DATABASE MIKAMI_DB TO ROLE MIKAMI_DTS_ROLE;
GRANT USAGE ON SCHEMA MIKAMI_DB.PUBLIC TO ROLE MIKAMI_DTS_ROLE;
GRANT SELECT ON TABLE MIKAMI_DB.PUBLIC.DTS_TYPE_TEST TO ROLE MIKAMI_DTS_ROLE;
GRANT USAGE ON WAREHOUSE MIKAMI_XS TO ROLE MIKAMI_DTS_ROLE;
GRANT USAGE ON INTEGRATION MIKAMI_S3_INTEGRATION_VERSIONING TO ROLE MIKAMI_DTS_ROLE;
続いて、DTS 用の Snowflake ユーザーを作成して、認証に使用するキーペアを設定します。
以下でサービスユーザーを作成後、
-- ユーザー作成
CREATE USER MIKAMI_DTS_SERVICE
TYPE = SERVICE
DEFAULT_ROLE = MIKAMI_DTS_ROLE
DEFAULT_WAREHOUSE = MIKAMI_XS;
ローカル PC のコマンドラインで以下を実行して、キーペアを作成します。
# 秘密鍵の生成
openssl genrsa 2048 | openssl pkcs8 -topk8 -nocrypt -out rsa_key.p8
# 公開鍵の生成
openssl rsa -in rsa_key.p8 -pubout -out rsa_key.pub
# 公開鍵の内容確認
cat rsa_key.pub
公開鍵ファイルの内容からヘッダー・フッターを除いた値を、先ほど作成した Snowflake ユーザーに登録します。
ALTER USER MIKAMI_DTS_SERVICE SET RSA_PUBLIC_KEY='MIIBI(省略)DAQAB';
準備:Google Cloud サービスアカウント作成
次に、Google Cloud 側で、DTS 用のサービスアカウントを作成して、必要な権限を付与します。
以下の gcloud コマンドを実行しました。
# サービスアカウント作成
gcloud iam service-accounts create snowflake-dts-sa \
--display-name="Snowflake DTS SA" \
--project=[PROJECT_ID]
# BigQuery権限付与
gcloud projects add-iam-policy-binding [PROJECT_ID] \
--member="serviceAccount:snowflake-dts-sa@[PROJECT_ID].iam.gserviceaccount.com" \
--role="roles/bigquery.dataEditor"
gcloud projects add-iam-policy-binding [PROJECT_ID] \
--member="serviceAccount:snowflake-dts-sa@[PROJECT_ID].iam.gserviceaccount.com" \
--role="roles/bigquery.jobUser"
# GCS読み取り権限付与
gcloud projects add-iam-policy-binding [PROJECT_ID] \
--member="serviceAccount:snowflake-dts-sa@[PROJECT_ID].iam.gserviceaccount.com" \
--role="roles/storage.objectViewer"
DTSジョブ作成
準備ができたので、DTS の増分データ転送転送ジョブを作成します。
DTS ジョブのパラメータ定義ファイルと DTS ジョブを作成します。
DTS ジョブは Google Cloud コンソールから GUI で作成することもできますが、今回は gcloud コマンドで作成しました。
cat > sf_params_inc.json << 'EOF'
{
"account_identifier": "[SNOWFLAKE_ACCOUNT_ID]",
"username": "MIKAMI_DTS_SERVICE",
"auth_mechanism": "KEY_PAIR",
"private_key": "-----BEGIN PRIVATE KEY-----\nMI(省略)WCW\n-----END PRIVATE KEY-----",
"warehouse": "MIKAMI_XS",
"database": "MIKAMI_DB",
"schema": "PUBLIC",
"cloud_provider": "AWS",
"storage_integration_object_name": "MIKAMI_S3_INTEGRATION_VERSIONING",
"staging_s3_uri": "s3://cm-mikami-versioning/snowflake-dts-staging/",
"aws_access_key_id": "[AWS_ACCESS_KEY_ID]",
"aws_secret_access_key": "[AWS_SECRET_ACCESS_KEY]",
"service_account": "snowflake-dts-sa@[PROJECT_ID].iam.gserviceaccount.com",
"table_name_patterns": "DTS_TYPE_TEST",
"ingestion_type": "Incremental"
}
EOF
bq mk \
--transfer_config \
--project_id=[PROJECT_ID] \
--location=asia-northeast1 \
--data_source=snowflake_migration \
--display_name='SF Incremental Test' \
--target_dataset=dataset_1 \
--schedule='every 1 hours' \
--service_account_name=snowflake-dts-sa@[PROJECT_ID].iam.gserviceaccount.com \
--params="$(cat sf_params_inc.json)"
rm sf_params_inc.json
パラメータファイルには認証情報が記載されているため、念のためジョブ作成後には削除しておきます。
冒頭でも記載の通り、DTS では AWS アクセスに IAM ユーザーのアクセスキーとシークレットアクセスキーを使う必要があります。
[AWS_ACCESS_KEY_ID] と [YOUR_AWS_SECRET_ACCESS_KEY] には、DTS 用の最小権限のみを持つ IAM ユーザーの Credential を指定することを強く推奨いたします。
DTS ジョブ実行結果を確認
作成した DTS ジョブが正常に終了したので、BigQuery のデータを確認してみます。
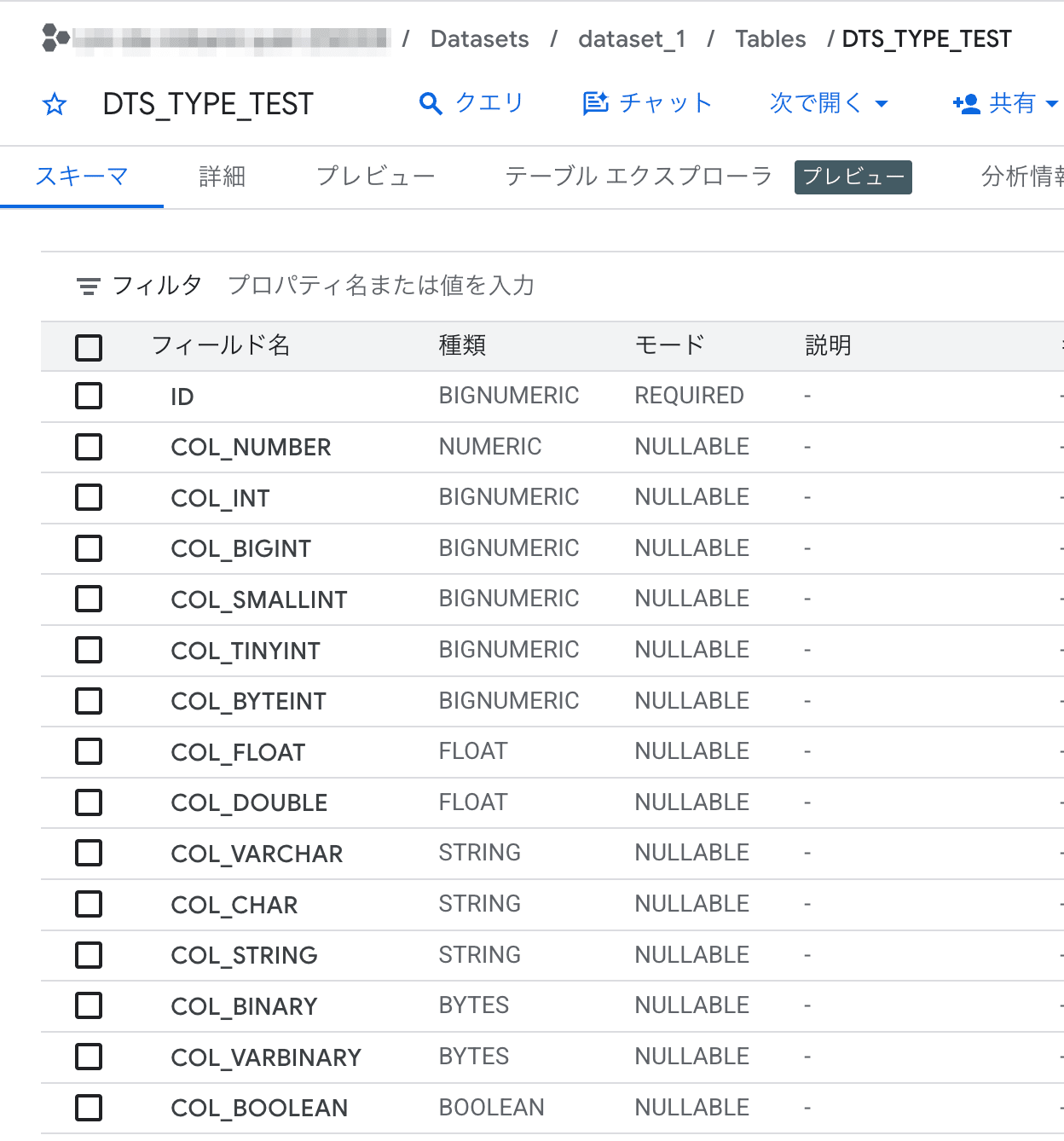
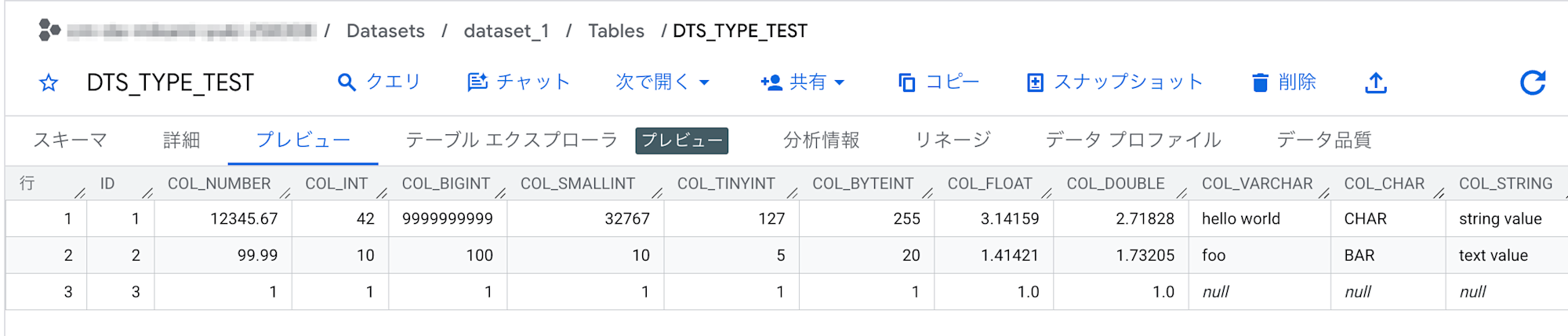
Snowflake と同名のテーブルが自動作成され、データが連携されていることが確認できました。
増分転送結果を確認
Snowflake 側のテーブルデータを追加・更新・削除して、BigQuery への連携結果を確認します。
Snowflake で以下の SQL を実行して、id = 4 のデータを追加、id = 1 のデータを更新、id = 2 のデータを削除しました。
-- 追加
INSERT INTO MIKAMI_DB.PUBLIC.DTS_TYPE_TEST
SELECT
4, 777.77, 100, 8888888888, 1000, 50, 100, 1.61803, 2.23607,
'inserted row', 'NEW ', 'incremental insert',
TO_BINARY('AABBCCDD', 'HEX'), TO_BINARY('EEFF0011', 'HEX'),
TRUE, '2026-05-16'::DATE, '15:00:00'::TIME,
'2026-05-16 15:00:00'::TIMESTAMP,
'2026-05-16 15:00:00 +09:00'::TIMESTAMP_LTZ,
'2026-05-16 15:00:00'::TIMESTAMP_NTZ,
'2026-05-16 15:00:00'::DATETIME,
'2026-05-16 15:00:00 +09:00'::TIMESTAMP_TZ,
OBJECT_CONSTRUCT('new', true),
PARSE_JSON('{"type": "insert"}'),
ARRAY_CONSTRUCT(10, 20, 30),
CONVERT_TIMEZONE('Asia/Tokyo', CURRENT_TIMESTAMP())::TIMESTAMP_NTZ;
-- 更新
UPDATE MIKAMI_DB.PUBLIC.DTS_TYPE_TEST
SET
col_varchar = 'updated row',
col_number = 111.11,
updated_at = CONVERT_TIMEZONE('Asia/Tokyo', CURRENT_TIMESTAMP())::TIMESTAMP_NTZ
WHERE id = 1;
-- 削除
DELETE FROM MIKAMI_DB.PUBLIC.DTS_TYPE_TEST WHERE id = 2;
Snowflake のテーブルデータを確認しておきます。
SELECT id, col_varchar, col_number, updated_at FROM DTS_TYPE_TEST ORDER BY ID;

新規追加した id = 4 のレコードと、COL_VARCHAR, COL_NUMBER, UPDATED_AT の値が更新された id = 1 のレコード、何も変更のない id = 3 のレコードが格納されている状態です。
DTS ジョブをもう一度実行して、BigQuery のテーブルデータがどうなるか確認してみます。
DTS ジョブ正常終後に、BigQuery のテーブルデータを確認します。
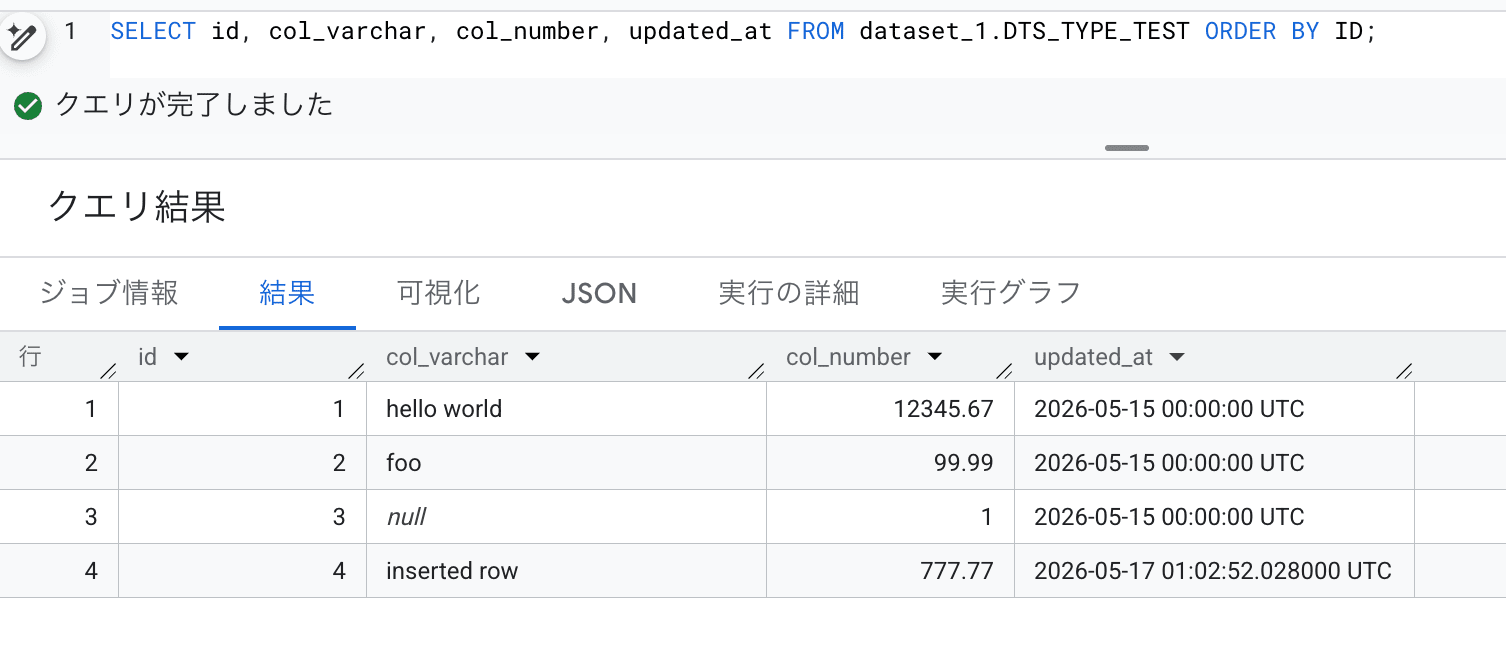
新規追加したデータが、BigQuery に追加連携されていることが確認できました。
「増分データ転送」なので、想定通り、更新や削除されたデータは反映されません。
更新・削除ケースのあるテーブルデータを連携する場合には、全件転送や論理削除カラム(削除フラグ)の追加などをご検討ください。
データ型マッピング
DTS ジョブで新規作成された BigQuery テーブルのカラムのデータ型を確認してみます。
$ bq query \
--project_id=[PROJECT_ID] \
--location=asia-northeast1 \
--use_legacy_sql=false \
'SELECT column_name, data_type, is_nullable
FROM `[PROJECT_ID]`.dataset_1.INFORMATION_SCHEMA.COLUMNS
WHERE table_name = "DTS_TYPE_TEST"
ORDER BY ordinal_position'
+---------------+------------+-------------+
| column_name | data_type | is_nullable |
+---------------+------------+-------------+
| ID | BIGNUMERIC | NO |
| COL_NUMBER | NUMERIC | YES |
| COL_INT | BIGNUMERIC | YES |
| COL_BIGINT | BIGNUMERIC | YES |
| COL_SMALLINT | BIGNUMERIC | YES |
| COL_TINYINT | BIGNUMERIC | YES |
| COL_BYTEINT | BIGNUMERIC | YES |
| COL_FLOAT | FLOAT64 | YES |
| COL_DOUBLE | FLOAT64 | YES |
| COL_VARCHAR | STRING | YES |
| COL_CHAR | STRING | YES |
| COL_STRING | STRING | YES |
| COL_BINARY | BYTES | YES |
| COL_VARBINARY | BYTES | YES |
| COL_BOOLEAN | BOOL | YES |
| COL_DATE | DATE | YES |
| COL_TIME | TIME | YES |
| COL_TIMESTAMP | TIMESTAMP | YES |
| COL_TS_LTZ | STRING | YES |
| COL_TS_NTZ | TIMESTAMP | YES |
| COL_DATETIME | TIMESTAMP | YES |
| COL_TS_TZ | STRING | YES |
| COL_OBJECT | STRING | YES |
| COL_VARIANT | STRING | YES |
| COL_ARRAY | STRING | YES |
| UPDATED_AT | TIMESTAMP | YES |
+---------------+------------+-------------+
なお、転送元の Snowflake テーブルのデータ型は以下のとおりです。
MIKAMI_DTS_SERVICE#MIKAMI_XS@MIKAMI_DB.PUBLIC>SELECT column_name, data_type, is_nullable FROM INFORMATION_SCHEMA.COLUMNS WHERE table_c
atalog='MIKAMI_DB' AND table_schema='PUBLIC' AND table_name='DTS_TYPE_TEST' ORDER BY ord
inal_position;
+---------------+---------------+-------------+
| COLUMN_NAME | DATA_TYPE | IS_NULLABLE |
|---------------+---------------+-------------|
| ID | NUMBER | NO |
| COL_NUMBER | NUMBER | YES |
| COL_INT | NUMBER | YES |
| COL_BIGINT | NUMBER | YES |
| COL_SMALLINT | NUMBER | YES |
| COL_TINYINT | NUMBER | YES |
| COL_BYTEINT | NUMBER | YES |
| COL_FLOAT | FLOAT | YES |
| COL_DOUBLE | FLOAT | YES |
| COL_VARCHAR | TEXT | YES |
| COL_CHAR | TEXT | YES |
| COL_STRING | TEXT | YES |
| COL_BINARY | BINARY | YES |
| COL_VARBINARY | BINARY | YES |
| COL_BOOLEAN | BOOLEAN | YES |
| COL_DATE | DATE | YES |
| COL_TIME | TIME | YES |
| COL_TIMESTAMP | TIMESTAMP_NTZ | YES |
| COL_TS_LTZ | TIMESTAMP_LTZ | YES |
| COL_TS_NTZ | TIMESTAMP_NTZ | YES |
| COL_DATETIME | TIMESTAMP_NTZ | YES |
| COL_TS_TZ | TIMESTAMP_TZ | YES |
| COL_OBJECT | OBJECT | YES |
| COL_VARIANT | VARIANT | YES |
| COL_ARRAY | ARRAY | YES |
| UPDATED_AT | TIMESTAMP_NTZ | YES |
+---------------+---------------+-------------+
26 Row(s) produced. Time Elapsed: 0.941s
Snowflake と BigQuery のデータ型のマッピング表は以下です。
| カラム名 | Snowflake型 | BigQuery型 | 備考 |
|---|---|---|---|
| ID | NUMBER | BIGNUMERIC | NOT NULL が維持される |
| COL_NUMBER | NUMBER(18,2) | NUMERIC | 精度付き NUMBER は NUMERIC にマッピング |
| COL_INT | NUMBER | BIGNUMERIC | |
| COL_BIGINT | NUMBER | BIGNUMERIC | |
| COL_SMALLINT | NUMBER | BIGNUMERIC | |
| COL_TINYINT | NUMBER | BIGNUMERIC | |
| COL_BYTEINT | NUMBER | BIGNUMERIC | |
| COL_FLOAT | FLOAT | FLOAT64 | |
| COL_DOUBLE | FLOAT | FLOAT64 | |
| COL_VARCHAR | TEXT | STRING | |
| COL_CHAR | TEXT | STRING | |
| COL_STRING | TEXT | STRING | |
| COL_BINARY | BINARY | BYTES | |
| COL_VARBINARY | BINARY | BYTES | |
| COL_BOOLEAN | BOOLEAN | BOOL | |
| COL_DATE | DATE | DATE | |
| COL_TIME | TIME | TIME | |
| COL_TIMESTAMP | TIMESTAMP_NTZ | TIMESTAMP | |
| COL_TS_LTZ | TIMESTAMP_LTZ | STRING | タイムゾーン情報が失われる |
| COL_TS_NTZ | TIMESTAMP_NTZ | TIMESTAMP | |
| COL_DATETIME | TIMESTAMP_NTZ | TIMESTAMP | |
| COL_TS_TZ | TIMESTAMP_TZ | STRING | タイムゾーン情報が失われる |
| COL_OBJECT | OBJECT | STRING | JSON文字列として格納 |
| COL_VARIANT | VARIANT | STRING | JSON文字列として格納 |
| COL_ARRAY | ARRAY | STRING | JSON文字列として格納 |
| UPDATED_AT | TIMESTAMP_NTZ | TIMESTAMP |
Snowflake の OBJECT / VARIANT や ARRAY 型は STRING 型に変換されていますが、中身が JSON データであれば BigQuery でも JSON_VALUE 関数を使用して視認性を確保したクエリが可能です。
$ bq query \
--project_id=[PROJECT_ID] \
--location=asia-northeast1 \
--use_legacy_sql=false \
'SELECT
id,
col_object,
col_variant,
col_array,
JSON_VALUE(col_object, "$.a") AS object_a,
JSON_VALUE(col_variant, "$.key") AS variant_key,
JSON_VALUE(col_array, "$[0]") AS array_first
FROM `[PROJECT_ID]`.dataset_1.DTS_TYPE_TEST
ORDER BY id'
+----+-------------------+--------------------------+--------------------------+----------+-------------+-------------+
| id | col_object | col_variant | col_array | object_a | variant_key | array_first |
+----+-------------------+--------------------------+--------------------------+----------+-------------+-------------+
| 1 | {"a":1,"b":"two"} | {"key":"value","num":42} | [1,"two",true,undefined] | 1 | value | 1 |
| 2 | {"x":10} | {"status":"active"} | ["a","b"] | NULL | NULL | a |
| 3 | NULL | NULL | NULL | NULL | NULL | NULL |
| 4 | {"new":true} | {"type":"insert"} | [10,20,30] | NULL | NULL | 10 |
+----+-------------------+--------------------------+--------------------------+----------+-------------+-------------+
また、一部の日時データが TIMESTAMP や DATETIME 型ではなく STRING 型に変換されてしまっていますが、こちらも PARSE や DATETIME で、日時型として参照することが可能です。
$ bq query \
--project_id=[PROJECT_ID] \
--location=asia-northeast1 \
--use_legacy_sql=false \
'SELECT
id,
COL_TS_LTZ,
COL_TS_TZ,
DATETIME(PARSE_TIMESTAMP("%Y-%m-%d %H:%M:%E*S %Ez", REPLACE(COL_TS_LTZ, " Z", "+00:00")), "UTC") AS COL_TS_LTZ_DATETIME_UTC,
DATETIME(PARSE_TIMESTAMP("%Y-%m-%d %H:%M:%E*S %Ez", COL_TS_TZ), "UTC") AS COL_TS_TZ_DATETIME_UTC,
DATETIME(PARSE_TIMESTAMP("%Y-%m-%d %H:%M:%E*S %Ez", REPLACE(COL_TS_LTZ, " Z", "+00:00")), "Asia/Tokyo") AS COL_TS_LTZ_DATETIME_JST,
DATETIME(PARSE_TIMESTAMP("%Y-%m-%d %H:%M:%E*S %Ez", COL_TS_TZ), "Asia/Tokyo") AS COL_TS_TZ_DATETIME_JST
FROM `[PROJECT_ID]`.dataset_1.DTS_TYPE_TEST
ORDER BY id'
+----+---------------------------------+--------------------------------------+-------------------------+------------------------+-------------------------+------------------------+
| id | COL_TS_LTZ | COL_TS_TZ | COL_TS_LTZ_DATETIME_UTC | COL_TS_TZ_DATETIME_UTC | COL_TS_LTZ_DATETIME_JST | COL_TS_TZ_DATETIME_JST |
+----+---------------------------------+--------------------------------------+-------------------------+------------------------+-------------------------+------------------------+
| 1 | 2026-05-15 03:34:56.000000000 Z | 2026-05-15 12:34:56.000000000 +09:00 | 2026-05-15T03:34:56 | 2026-05-15T03:34:56 | 2026-05-15T12:34:56 | 2026-05-15T12:34:56 |
| 2 | 2026-05-15 00:00:00.000000000 Z | 2026-05-15 09:00:00.000000000 +09:00 | 2026-05-15T00:00:00 | 2026-05-15T00:00:00 | 2026-05-15T09:00:00 | 2026-05-15T09:00:00 |
| 3 | NULL | NULL | NULL | NULL | NULL | NULL |
| 4 | 2026-05-16 06:00:00.000000000 Z | 2026-05-16 15:00:00.000000000 +09:00 | 2026-05-16T06:00:00 | 2026-05-16T06:00:00 | 2026-05-16T15:00:00 | 2026-05-16T15:00:00 |
+----+---------------------------------+--------------------------------------+-------------------------+------------------------+-------------------------+------------------------+
つまづいたところ
Snowflake テーブルの変更履歴を有効にしないと、DTS ジョブパラメータで "ingestion_type": "Incremental"を指定していても、全件転送のデータ連携となってしまいました。
はじめ、更新・削除レコードも BigQuery テーブルに反映されてしまったので、ログ確認したところ、WRITE_TRUNCATE の INSERT ジョブが走っていました。
公式ドキュメントにも、ちゃんと記載されていました。。
まとめ(所感)
BigQuery Data Transfer Service(DTS) で、Snowflake テーブルの増分データ転送が実行できることが確認できました。
昔は DTS といえば Migration 用途のサービスの印象で、定期的なデータ連携用途には適していないと思っていましたが、この増分転送機能を使えば、定期的なデータ連携にも十分対応できるのではないかと思いました。
また、BigQuery データエンジニアリング エージェントで使用されることもあってか、ここのところ DTS では連携元サービスがだいぶ充実してきた印象です。
AWS からのデータ転送の場合にまだ ロールベースの認証方法(Workload Identity 連携)に対応していないため、アクセスキーとシークレットアクセスキーの発行が必要になる点が残念ですが、今後のアップデートに期待したいと思います!







