ブラウザのマイク音声をバックエンド経由でAmazon Transcribeにリアルタイム文字起こしするWebアプリを作ってみた
Amazon Transcribeのストリーミング文字起こしAPIの学習を目的として、ブラウザのマイクから音声を取得してリアルタイムで文字起こしするWebアプリを作ってみました。
この記事では実装の詳細よりも、ブラウザ音声をTranscribe SDKに渡すまでの設計ポイント に絞って整理します。作る中で「WebSocketで届く push なデータと、SDKが期待する pull なインターフェースをどう繋ぐか」という問題にぶつかり、その解決策が思ったより面白かったので、それを中心に書いていきます。
コード全体はGitHubで公開しています。
弊社ブログでもAmazon Transcribeのリアルタイム文字起こしについて解説しているのでこちらもご覧ください。
作ったもの
ブラウザのマイクで話すと、リアルタイムで文字が起こされるWebアプリです。
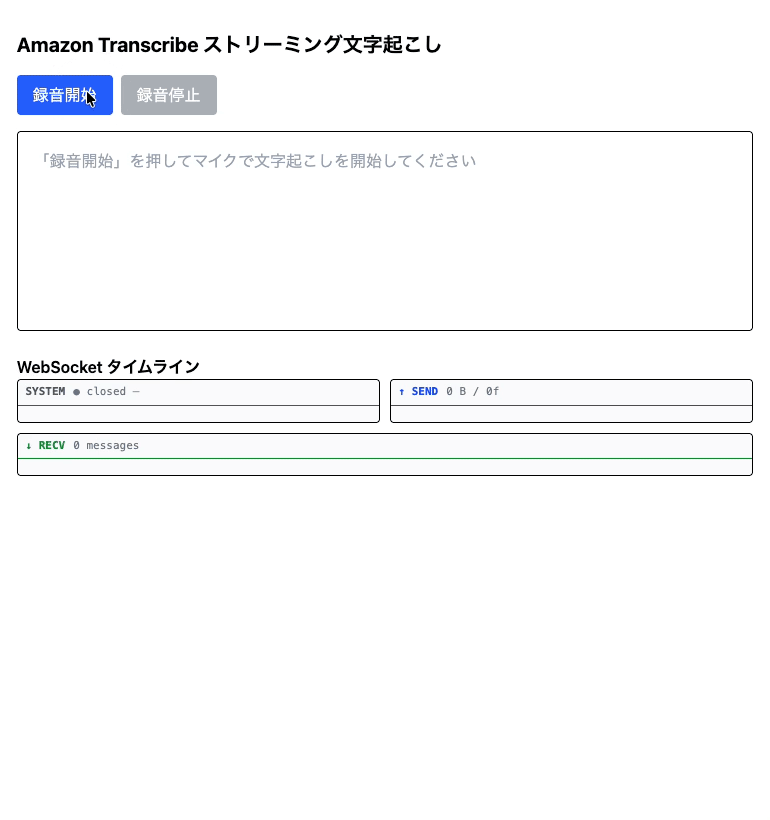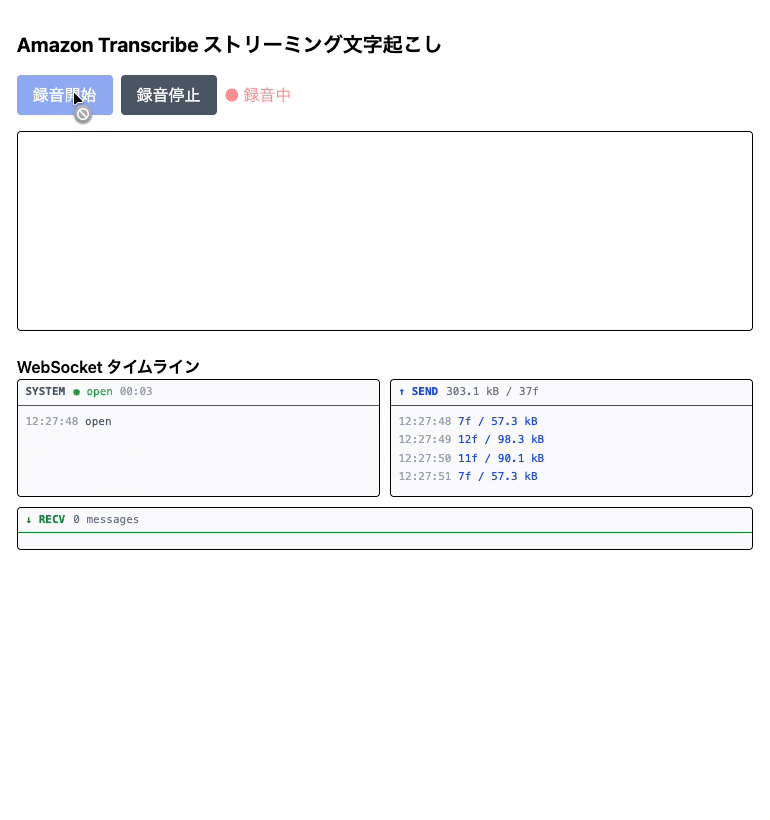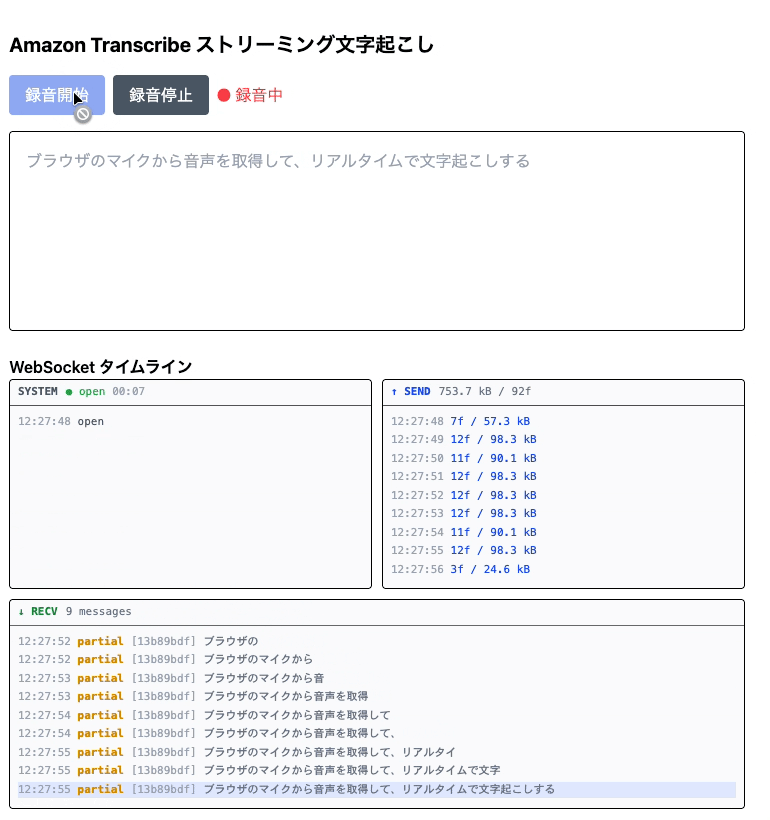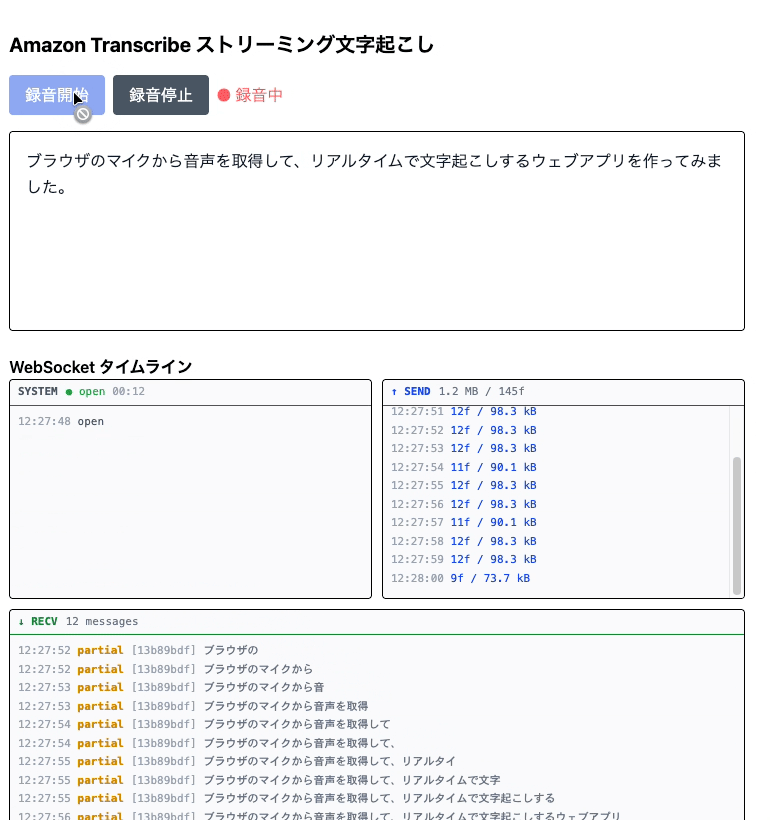
「録音開始」を押してマイクを許可すると文字起こしが始まります。話している途中はグレーで 部分結果 が表示され、発話が区切られると黒の 確定結果 として固定されます。
技術スタックはフロントエンドが React + Vite 、バックエンドが Hono + Node.js 、AWS SDKは @aws-sdk/client-transcribe-streaming を使っています。
なぜ普通のAPIとは違う設計が必要か
fetch を使ったAPIコールを思い浮かべてください。「リクエストを送る → レスポンスを1回受け取って終わり」です。データは自分のタイミングで取りに行け、受け取ったら処理は完了します。
音声のリアルタイム処理はこれと根本的に違います。マイクからは音声データが止まらずに流れ続け、細切れのかたまり(チャンク)になって生産者側のタイミングで次々と届きます。生産者がペースを握るこのモデルを便宜上 push 型と呼びます。一方、Transcribe SDKは for await...of でデータを1つずつ要求します。SDK(消費者)が next() を呼んだときだけデータが流れる、消費者がペースを握るこのモデルを便宜上 pull 型と呼びます。
このpushとpullという2つのモデルが混在することで問題が起きます。pushは「届いたら呼ばれる」コールバック型、pullは「要求したら返ってくる」イテレータ型で、タイミングが一致しません。
両者をそのまま繋ごうとすると、データが届いてもSDKがまだ「次ください」と言っていなかったり、逆にSDKが待っているのにデータがまだ届いていなかったりします。
そのため、キューのような仕組みが必要です。
このアプリにはpushとpullの境界が3箇所あります。以下の図のシリンダー形状(PcmQueue / TranscribeAudioQueue / TranscribeEventQueue)がその境界です。シリンダーに流れ込む矢印がpush、出ていく矢印がpullを表しています。
システム構成とデータの流れ
アプリ全体の構成とデータの流れを先に把握しておきます。
図中のシリンダー形状(PcmQueue / TranscribeAudioQueue / TranscribeEventQueue)が、この記事の主役です。3つとも同じパターンでpushをpullに変換するブリッジとして機能します。以降では、各ブリッジの設計を順番に見ていきます。
AudioWorkletとPcmQueue
AudioWorkletとは
ブラウザでマイクから音声データを受け取って加工するには、Web Audio APIの AudioWorklet を使います。
AudioWorkletが重要な理由は、メインスレッドとは独立した専用スレッドで動作する点です。音声処理はリアルタイム性が求められるため、DOM操作やJavaScriptの実行で忙しいメインスレッドでは処理できません。AudioWorkletスレッドはブラウザの音声エンジンから直接呼び出されるため、メインスレッドの状態に左右されません。
このアプリでは AudioWorkletProcessor を継承した PCMProcessor クラスを public/worklets/pcm-processor.js に定義し、それを AudioWorkletNode として音声グラフに繋いでいます。
// フロントエンド側
await audioCtx.audioWorklet.addModule("/worklets/pcm-processor.js");
const workletNode = new AudioWorkletNode(audioCtx, "pcm-processor", {
processorOptions: { bufferSize: 4096 },
});
const source = audioCtx.createMediaStreamSource(stream);
source.connect(workletNode);
process()が呼ばれる仕組み
AudioWorkletProcessorの中核はprocess()メソッドです。
process(inputs) {
const input = inputs[0]?.[0] // モノラルch0、Float32Arrayで128サンプル
// ...
return true // falseを返すとprocessorが停止
}
ブラウザの音声エンジンが128サンプルごとに自動で呼び出します。 48kHzなら約2.7ミリ秒に1回です。
Float32 → Int16 PCM変換
マイクから届く音声サンプルは Float32(-1.0〜1.0の小数)です。
一方、Amazon Transcribeに送るフォーマットは signed 16-bit PCM(Little Endian) です。
Float32よりサイズが小さくなるので、ブラウザ側のjavascript(_flush())でこの変換を行っています。
_flush() {
const pcm = new ArrayBuffer(this._offset * 2)
const view = new DataView(pcm)
for (let i = 0; i < this._offset; i++) {
const s = Math.max(-1, Math.min(1, this._buffer[i]))
// Float32(-1.0〜1.0)をInt16(-32768〜32767)にスケーリング
view.setInt16(i * 2, s < 0 ? s * 0x8000 : s * 0x7fff, true)
}
this.port.postMessage({ type: "pcm", audioData: new Uint8Array(pcm) })
this._offset = 0
}
毎回128サンプルをそのまま送るとpostMessageの呼び出し頻度が高すぎるため、内部バッファに蓄積して4096サンプル(約85ミリ秒分)たまったらまとめて送ります。
public/worklets/pcm-processor.js の全体
class PCMProcessor extends AudioWorkletProcessor {
constructor(options) {
super()
this._bufferSize = options.processorOptions?.bufferSize || 4096
this._buffer = new Float32Array(this._bufferSize)
this._offset = 0
this._ended = false
this.port.onmessage = (e) => {
if (e.data.type === "end") this._ended = true
}
}
process(inputs) {
const input = inputs[0]?.[0]
if (input) {
let i = 0
while (i < input.length) {
const remaining = this._bufferSize - this._offset
const toCopy = Math.min(remaining, input.length - i)
this._buffer.set(input.subarray(i, i + toCopy), this._offset)
this._offset += toCopy
i += toCopy
if (this._offset >= this._bufferSize) this._flush()
}
}
if (this._ended) {
if (this._offset > 0) this._flush()
this.port.postMessage({ type: "ended" })
return false
}
return true
}
_flush() {
const pcm = new ArrayBuffer(this._offset * 2)
const view = new DataView(pcm)
for (let i = 0; i < this._offset; i++) {
const s = Math.max(-1, Math.min(1, this._buffer[i]))
view.setInt16(i * 2, s < 0 ? s * 0x8000 : s * 0x7fff, true)
}
this.port.postMessage({ type: "pcm", audioData: new Uint8Array(pcm) })
this._offset = 0
}
}
registerProcessor("pcm-processor", PCMProcessor)
MessagePortでメインスレッドへ
AudioWorkletスレッドからメインスレッドへのデータ転送にはMessagePortを使います。postMessage()で送り、メインスレッド側のonmessageハンドラで受け取ります。
// メインスレッド側
workletNode.port.onmessage = (e) => {
if (e.data.type === "pcm")
audioQueue.push(e.data.audioData); // push!
else if (e.data.type === "ended") audioQueue.end();
};
「データが届いたときにコールバックが呼ばれる」 push 型です。
フロントのPcmQueueからWebSocket送信まで
PcmQueueに蓄積されたPCMデータは、for await...of(pull)で順番に取り出してWebSocketで送信されます。
// transcribeClient.ts
for await (const chunk of audioStream) {
ws.send(chunk); // chunk は Uint8Array
}
for await...of は「自分が要求するたびに1個ずつデータを受け取る」 pull 型です。ここで最初のpush→pull変換が起きています。PcmQueueが緩衝材になってくれるため、AudioWorkletが送ってくる音声データの push とWebSocket送信の pull ペースが合わなくても詰まらずに動きます。
TranscribeAudioQueue:pushをpullに変換する
フロントとまったく同じpush/pull変換が、バックエンドにも存在します。フロントのPcmQueueがAudioWorkletとWebSocket送信を繋いだように、バックエンドのTranscribeAudioQueueはWebSocket受信とTranscribe SDKを繋ぎます。
TranscribeSDKはpullで音声を取りに来る
StartStreamTranscriptionCommand の AudioStream パラメーターは AsyncIterable<AudioEvent> を受け付けます。
new StartStreamTranscriptionCommand({
LanguageCode: "ja-JP",
MediaEncoding: "pcm",
MediaSampleRateHertz: opts.sampleRate,
AudioStream: opts.audioStream, // AsyncIterableを渡す
});
SDKの内部では for await...of でこれを消費しています。 for await...of は 自分が「次をください」と要求するたびに1個ずつ受け取る pull 型です。
- 参考:Transcribe Streaming::StartStreamTranscriptionCommand - AWS SDK for JavaScript v3
- 参考:イテレーションプロトコル - JavaScript | MDN
pushとpullの不一致
まとめると、こういう不一致があります。
WebSocket.onmessage → データが来たときに呼ばれる(push)
↕ 不一致
Transcribe SDK → for await...ofで次のデータを要求する(pull)
この2つをそのまま繋ごうとすると、タイミングがかみ合いません。
- WebSocketからデータが届いても、SDKがまだ「次ください」と言っていない
- SDKが「次ください」と言っても、WebSocketからデータがまだ届いていない
TranscribeAudioQueueで解決する
TranscribeAudioQueueはキューを緩衝材にして、このタイミングのズレを吸収します。
async *[Symbol.asyncIterator](): AsyncGenerator<AudioEvent> {
while (true) {
// キューにデータがあれば順番にyield(pull側に渡す)
while (this.queue.length > 0) {
yield { AudioEvent: { AudioChunk: this.queue.shift()! } }
}
if (this.ended) break
// キューが空なら次のpushが来るまでPromiseで待機
await new Promise<void>((r) => (this.notify = r))
}
}
動作の流れはこうなります。
[WebSocket] chunk1 が届く → audioQueue.push(chunk1)
[SDK]「次ください」→ キューに chunk1 がある → yield chunk1
[SDK]「次ください」→ キューが空 → Promiseで待機
[WebSocket] chunk2 が届く → push() → notify() → 待機解除 → yield chunk2
[WebSocket] chunk3, chunk4 が連続して届く → キューに貯まる
[SDK]「次ください」→ chunk3 を yield
[SDK]「次ください」→ chunk4 を yield
pushのペースとpullのペースが合わなくても、キューが吸収してどちらも詰まらずに動き続けます。
backend/src/lib/transcribeAudioQueue.ts の全体
export class TranscribeAudioQueue {
private queue: Uint8Array[] = []
private notify: (() => void) | null = null
private ended = false
push(chunk: Uint8Array) {
this.queue.push(chunk)
this.notify?.()
this.notify = null
}
end() {
this.ended = true
this.notify?.()
this.notify = null
}
async *[Symbol.asyncIterator](): AsyncGenerator<AudioEvent> {
while (true) {
while (this.queue.length > 0) {
yield { AudioEvent: { AudioChunk: this.queue.shift()! } }
}
if (this.ended) break
await new Promise<void>((r) => (this.notify = r))
}
}
}
結果受信方向でも同じ変換が現れた
ここまではTranscribeAudioQueue(音声データをTranscribe SDKに送る方向)の話でしたが、結果受信の方向にも全く同じpush/pull変換が必要でした。
文字起こし結果はWebSocket経由でブラウザに返ってきますが、このデータも ws.onmessage(push)で届きます。これをfor await...of(pull)で受け取れるようにするには、同じブリッジが必要です。
TranscribeAudioQueueと同じ構造を TranscribeEventQueue として実装しました。
export class TranscribeEventQueue {
private queue: TranscribeEvent[] = [];
private resolve: (() => void) | null = null;
private closed = false;
send(event: TranscribeEvent) {
this.queue.push(event);
this.resolve?.();
this.resolve = null;
}
close() {
this.closed = true;
this.resolve?.();
this.resolve = null;
}
async *[Symbol.asyncIterator](): AsyncGenerator<TranscribeEvent> {
while (true) {
while (this.queue.length > 0) {
yield this.queue.shift()!;
}
if (this.closed) break;
await new Promise<void>((r) => (this.resolve = r));
}
}
}
パターン本体はTranscribeAudioQueueと同一です。transcribeClient.ts では TranscribeEventQueue をインスタンス化し、呼び出し元へ yield* で委譲します。
// ※ 概念を示す簡略コードです
export async function* startTranscription(...): AsyncGenerator<TranscribeEvent> {
const channel = new TranscribeEventQueue();
ws.onmessage = (event) => {
channel.send({ type: "result", data: ... }); // push
};
ws.onclose = () => {
channel.close(); // 終了シグナル
};
yield* channel; // TranscribeEventQueue の yield をそのまま委譲
}
channel.close() が呼ばれると TranscribeEventQueue が終了し、startTranscription 自体も終了します。yield* の詳細はMDNを参照してください。
resultIdによる部分結果の管理
ここまではデータを 送る 側の話でしたが、Transcribeから 受け取る 側にも特徴があります。
ストリーミング文字起こしの結果には2種類あります。
| 種別 | isPartial |
説明 |
|---|---|---|
| 部分結果 | true |
認識中の仮テキスト。後から変化する可能性がある |
| 確定結果 | false |
確定したテキスト。これ以上変化しない |
同じ発話区間の部分結果と確定結果は同じ resultId を持ちます。フロントエンドでは「同じ resultId なら上書き、なければ追加」という管理をすることで、部分結果がリアルタイムに更新されながら最終的に確定結果に置き換わる表示を実現しています。
for await (const event of startTranscription(
handle.audioStream,
handle.sampleRate,
)) {
if (event.type === "result") {
setSegments((prev) => {
const idx = prev.findIndex((s) => s.resultId === event.data.resultId);
return idx >= 0 ? prev.with(idx, event.data) : [...prev, event.data];
});
}
}
おわりに
AudioWorkletは今回初めて触りましたが、別スレッドで動きながらMessagePortで通信する仕組みは、リアルタイム音声処理ってこうやるんだなとわかって面白かったです。Float32からInt16 PCMへの変換という低レベルな処理も、実際に手を動かしてみることで理解が深まりました。
このブログがどなたかのお役に立てれば幸いです。