
Claude の tool use でテキスト以外(画像・PDF)を返してみる
リテールアプリ共創部の末永です。
Claude API の tool use で、tool の実行結果 (tool_result) には画像やファイルも返せます。自分でも結構使ってきたのですが、「tool_result は文字列だけ」という印象を持っている方もいそうだなと思い、どんな形で返せるのか・Claude がちゃんと中身を読めるのかを改めて整理してみました。
tool_result が返せるもの
tool use の流れは、Claude が tool_use ブロックを返す → 自分のコードでツールを実行する → 結果を tool_result ブロックで返す、というものです。
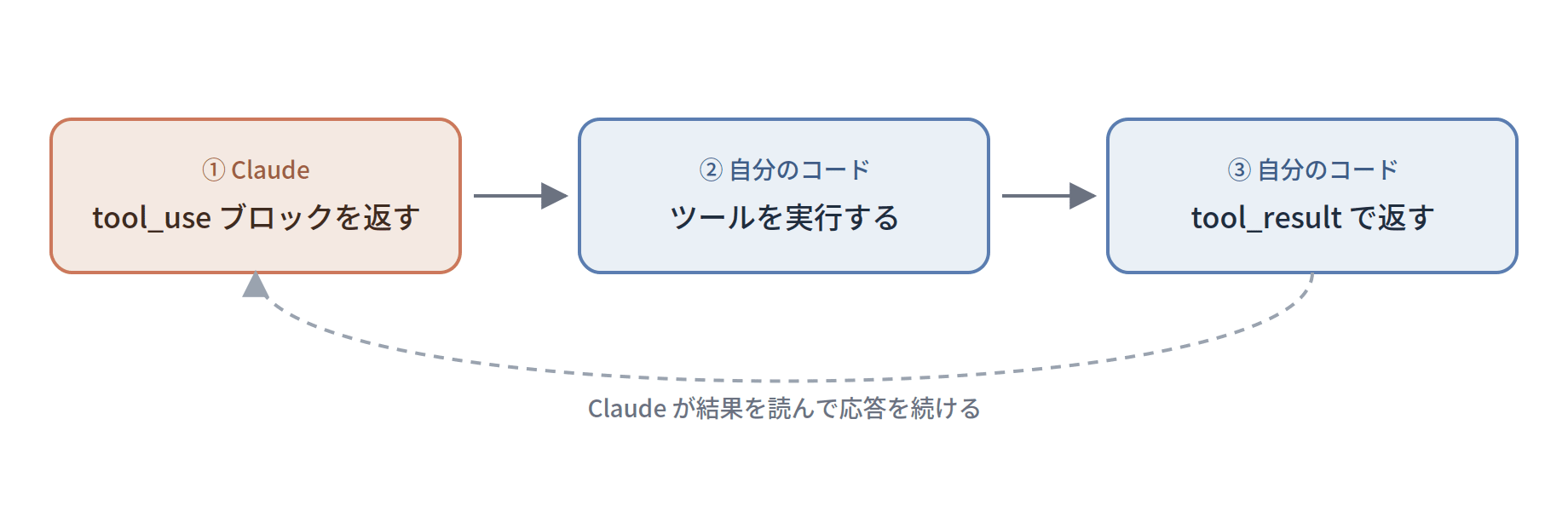
content は文字列のほかに、ブロックの配列も取れて、そのブロックには text / image / document の3種類が使えます。
image / document ブロックがそれぞれ何を受け付けるかをまとめると次のとおりです。
| ブロック | 渡せるもの | 渡し方 |
|---|---|---|
| image | PNG / JPEG / GIF / WebP の画像 | base64 / URL |
| document | base64 / URL | |
| document | プレーンテキスト | text |
| document | text・image ブロック | 入れ子 (content) |
画像の扱いは ビジョン、PDF は PDF サポート、プレーンテキストや独自コンテンツの document は Citations の Document Types のページにそれぞれ解説があります。
実際に動かしてみる
題材は 別記事 で使った「国を連想させるイラスト」(日本・アメリカ・フランスの3枚)を流用しました。tool が画像を返したときに Claude が国名を当てられれば、画像が伝わっていると確認できます。
実際に使った画像はこちらの3枚です。

検証は、ツールを必ず呼ぶようにしておき、その戻り値だけを差し替えて Claude の最終応答を見る形にしています。
画像を1枚返す
画像は base64 にして image ブロックで返します。
const toolResult = {
type: "tool_result",
tool_use_id: toolUse.id,
content: [
{
type: "image",
source: { type: "base64", media_type: "image/png", data: pngBase64 },
},
],
};
フランスのイラストを返したところ、Claude の応答はこうなりました。
- **フランス国旗**:左側に青・白・赤の3色の旗が描かれている ✓
- **エッフェル塔**:中央に高くそびえ立つパリの象徴的な建造物 ✓
- **パリの風景**:灰色の建物が並ぶ街並み ✓
画像とフランスの関連要素が完全に一致しており、文句なくフランスと判定できます。
画像の中身を読んで「フランス」と答えています。
画像を2枚 + テキストを混ぜる
content は配列なので、テキストと画像を混在させたり、画像を複数並べたりもできます。日本とアメリカの画像に、それぞれ説明用のテキストを挟んで返してみます。
content: [
{ type: "text", text: "1枚目:" },
{ type: "image", source: { type: "base64", media_type: "image/png", data: japanPng } },
{ type: "text", text: "2枚目:" },
{ type: "image", source: { type: "base64", media_type: "image/png", data: usaPng } },
];
応答です。
**1枚目:日本**
- 富士山、赤い塔、桜の枝、そしてスカイツリーなど、日本を代表するランドマークが描かれています。
**2枚目:アメリカ**
- アメリカの国旗、自由の女神、ワシントンモニュメント、ホワイトハウスなど、アメリカを代表する建造物や象徴が描かれています。
順序も保ったまま、それぞれの画像を読み分けています。
PDF を返す
PDF も base64 にすれば document ブロックで返せます。合言葉 (ALPACA-7788) を埋め込んだ PDF を生成して返し、本文を読めるか確認しました。
content: [
{
type: "document",
source: { type: "base64", media_type: "application/pdf", data: pdfBase64 },
},
];
レポートPDFを生成しました。PDFの本文に書かれている Passphrase は「ALPACA-7788」です。
PDF の中身もちゃんと読めています。
画像・テキスト・document をすべて1つの tool_result に混ぜても、Claude は画像の国名・添付メモの合言葉をそれぞれ拾って報告してくれました。
file_id 参照を tool_result に入れる
Claude には Files API があり、ファイルを事前にアップロードして得た file_id をメッセージから参照できます。(Files APIに関しての解説記事はこちら)
ただ、公式ドキュメントで file_id を参照している例はいずれも通常のユーザーメッセージの中で、tool_result の content に file_id を入れる例は見当たりませんでした。
型定義上は受け付けられそうだったので、実際に試してみます。file_id を使うときはベータヘッダ files-api-2025-04-14 が必要です。
const uploaded = await client.beta.files.upload({
file: await toFile(imageBytes, "usa.png", { type: "image/png" }),
betas: ["files-api-2025-04-14"],
});
content: [
{ type: "image", source: { type: "file", file_id: uploaded.id } },
];
アメリカのイラストをアップロードして file_id で返したところ、問題なく中身が読めました。
この画像は、アメリカ国旗、自由の女神像、ホワイトハウス、そしてワシントン記念塔など、アメリカを代表するシンボルが描かれています。
**米国**
同じように PDF を file_id で document ブロックに入れても、合言葉を読み取れました。tool_result 経由でも file_id 参照はそのまま使えるようです。
base64 で直接埋め込む場合はベータヘッダ不要で、file_id を参照する場合だけ files-api-2025-04-14 が要る、という違いがあります。同じファイルを何度も渡すなら Files API にアップロードして file_id で参照する、その場限りなら base64 で埋める、と使い分けできます。
最後に
画像も PDF も tool_result でそのまま返せて、Claude も中身を読んでくれます。使いどころとしては、検索した文書や画像をそのまま渡す簡易的な RAG(広義の意味で)や、画像の一部を拡大したものを返して認識し直させる、といったケースで便利かなと思います。tool_result は文字列だけ、という印象を持っていた方は、選択肢として覚えておくと良いことがあるかもしれませんね🙄。
では👋









