
【初心者向け】 Claude Code × Obsidian × Vertex AI を使って個人ナレッジ管理を始めてみた
はじめに
データ事業本部のkasamaです。
以下の記事を拝見し、アイデアがとても良いなと思い、自分なりにカスタマイズ設定してみて、1週間運用したのでその記録を残したいと思います。
(ObsidianもClaude Codeも初心者なのでもっと良い簡単な方法あれば教えてください..)
前提
個人で受けている英語レッスンのmp3/mp4動画をテキストに起こして、フィードバックをもらったり、普段のMTG動画をテキストに起こして、議事録に起こしたりしたいなーと思っていたので、その辺りを、Vertex AIを使って文字起こしや要約を行う仕組みにしました図にすると以下になります。
実装
今回の実装コードは、Github上に格納してあるのでご確認いただければと思います。
@obsidian-claude-feedback-sample % tree
.
├── .claude
│ ├── format-md.sh
│ ├── prompt
│ │ ├── english_lesson.md
│ │ └── meeting.md
│ └── settings.json
├── 00_Configs
│ ├── Extra
│ └── Templates
│ └── Daily.md
├── 01_Daily
├── 02_Inbox
│ └── 雑メモ.md
├── 03_eng_study
├── 04_Meetings
├── audio_video_to_text
│ ├── audio_video_to_text.py
│ ├── input
│ ├── output
│ └── requirements.txt
├── .prettierrc
├── CLAUDE.md
├── package-lock.json
├── package.json
└── README.md
.claude/format-md.shはClaude Codeのhooks機能で実行します。拡張子がmdだった場合にprettierでフォーマットを整えるようにしています。
#!/bin/bash
FILE_PATH=$(jq -r '.tool_input.file_path')
if [[ "$FILE_PATH" == *.md ]]; then
echo "📝 Formatting markdown file: $FILE_PATH"
if [ -f node_modules/.bin/prettier ]; then
npx prettier --write "$FILE_PATH" && echo "✅ Prettier formatting completed for $FILE_PATH" || echo "❌ Prettier formatting failed for $FILE_PATH"
elif command -v prettier >/dev/null 2>&1; then
prettier --write "$FILE_PATH" && echo "✅ Prettier formatting completed for $FILE_PATH" || echo "❌ Prettier formatting failed for $FILE_PATH"
else
echo "⚠️ Warning: prettier not found, skipping formatting for $FILE_PATH"
fi
fi
.claude/settings.jsonでは、基本的な許可、拒否コマンド、hooks設定でスクリプトを呼び出したり、通知を鳴らすように設定しています。
{
"env": {
"TF_LOG": "WARN",
"CLAUDE_CODE_ENABLE_TELEMETRY": "0",
"BASH_DEFAULT_TIMEOUT_MS": "600000"
},
"permissions": {
"allow": [
"Bash(ls ./)",
"Bash(ls ./*)",
"Bash(cat ./*)",
"Bash(grep:*)",
"Bash(rg:*)",
"Bash(find ./)",
"Bash(tree ./)",
"Bash(head ./*)",
"Bash(tail ./*)",
"Bash(echo:*)",
"Bash(pwd)",
"Bash(cd ./)",
"Bash(mkdir ./)",
"Bash(cp ./* ./)",
"Bash(mv ./* ./)",
"Bash(touch ./)",
"Bash(which:*)",
"Bash(env)",
"Bash(whoami)",
"Bash(date)",
"Bash(uv run:*)",
"Read(./**)",
"Edit(./**)",
"Grep(./**)",
"Glob(./**)",
"LS(./**)",
"LS(..)",
"Write(./**)",
"MultiEdit(./**)",
"TodoRead(**)",
"TodoWrite(**)",
"Task(**)",
"Bash(uv run:*)"
],
"deny": [
"Bash(rm -rf:*)",
"Bash(rm /*)",
"Bash(cp /* *)",
"Bash(cp:*)",
"Bash(mv /* *)",
"Bash(mv:*)",
"Bash(mkdir /*)",
"Bash(sudo:*)",
"Write(.git/**)"
]
},
"enabledMcpjsonServers": [
],
"disabledMcpjsonServers": [],
"hooks": {
"PostToolUse": [
{
"matcher": "Write|Edit|MultiEdit",
"hooks": [
{
"type": "command",
"command": ".claude/format-md.sh"
}
]
}
],
"Notification": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "afplay /System/Library/Sounds/Funk.aiff"
}
]
}
],
"Stop": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "afplay /System/Library/Sounds/Funk.aiff"
}
]
}
]
}
}
Obsidianのフォルダ構成は以下の記事を参考に作成しました。
フォルダ構成はかなり大まかに設定しているので、この辺りは使いながら変えていく可能性が高いです。
├── 00_Configs
│ ├── Extra → 画像ファイル格納先
│ └── Templates → テンプレファイル格納先
│ └── Daily.md
├── 01_Daily → Daily Note格納先
├── 02_Inbox → メモ格納先
│ └── 雑メモ.md
├── 03_eng_study → 英語学習メモ格納先
├── 04_Meetings → MTG議事録格納先
以下のPythonスクリプトでmp4/mp3ファイルを文字起こししています。
audio_video_to_text/audio_video_to_text.py
import os
import logging
import vertexai
from vertexai.generative_models import GenerativeModel, Part
from dotenv import load_dotenv
import ffmpeg
# .envファイルの読み込み
load_dotenv()
# ---------- 環境変数 ----------
PROJECT_ID = os.getenv("PROJECT_ID")
REGION = os.getenv("REGION")
FILE_NAME = os.getenv("FILE_NAME") # 例: "meeting_audio.mp4" または "meeting_audio.mp3"
OUTPUT_DIR = "output" # 出力先
MODEL_NAME = "gemini-2.5-pro"
GOOGLE_APPLICATION_CREDENTIALS = os.getenv("GOOGLE_APPLICATION_CREDENTIALS")
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = GOOGLE_APPLICATION_CREDENTIALS
# ---------- ロギング ----------
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(message)s")
logger = logging.getLogger(__name__)
# Vertex AI の初期化
vertexai.init(project=PROJECT_ID, location=REGION)
def convert_mp4_to_mp3(mp4_path: str, mp3_path: str) -> None:
"""MP4 ファイルをMP3に変換"""
logger.info("MP4からMP3への変換開始: %s -> %s", mp4_path, mp3_path)
try:
(
ffmpeg.input(mp4_path)
.output(mp3_path)
.global_args("-loglevel", "quiet")
.run(overwrite_output=True)
)
logger.info("MP4からMP3への変換完了")
except Exception as e:
logger.error("MP4変換中にエラーが発生しました: %s", e)
raise
def transcribe_audio(audio_path: str) -> str:
"""音声ファイルをテキストに書き起こす"""
logger.info("文字起こし開始: %s", audio_path)
model = GenerativeModel(MODEL_NAME)
# ファイル拡張子に基づいてMIMEタイプを決定
if audio_path.lower().endswith('.mp4'):
mime_type = "video/mp4"
elif audio_path.lower().endswith('.mp3'):
mime_type = "audio/mp3"
else:
raise ValueError(f"サポートされていないファイル形式: {audio_path}")
with open(audio_path, "rb") as f:
audio_part = Part.from_data(f.read(), mime_type=mime_type)
prompt = (
"以下の音声を書き起こしてください。\n"
"1. 発言者が変わるたびに改行してください。\n"
"2. 可能であれば句読点を補ってください。\n"
)
response = model.generate_content([audio_part, prompt])
logger.info("文字起こし完了")
return response.text
if __name__ == "__main__":
try:
# ファイル名と拡張子を分離
input_file_path = os.path.join("input", FILE_NAME)
file_name_without_ext, file_extension = os.path.splitext(FILE_NAME)
# 入力ファイルの存在確認
if not os.path.exists(input_file_path):
raise FileNotFoundError(f"入力ファイルが見つかりません: {input_file_path}")
audio_file = None
temp_mp3_file = None
if file_extension.lower() == ".mp4":
# MP4ファイルの場合、MP3に変換
temp_mp3_file = os.path.join("input", f"{file_name_without_ext}_converted.mp3")
convert_mp4_to_mp3(input_file_path, temp_mp3_file)
audio_file = temp_mp3_file
elif file_extension.lower() == ".mp3":
# MP3ファイルの場合、そのまま使用
audio_file = input_file_path
else:
raise ValueError(f"サポートされていないファイル形式: {file_extension}")
# 文字起こし実行
transcript = transcribe_audio(audio_file)
# 出力保存(拡張子なしのファイル名を使用)
os.makedirs(OUTPUT_DIR, exist_ok=True)
out_path = os.path.join(OUTPUT_DIR, f"{file_name_without_ext}_transcript.txt")
with open(out_path, "w", encoding="utf-8") as f:
f.write(transcript)
logger.info("書き起こしテキストを保存しました: %s", out_path)
# 一時ファイルの削除
if temp_mp3_file and os.path.exists(temp_mp3_file):
os.remove(temp_mp3_file)
logger.info("一時ファイルを削除しました: %s", temp_mp3_file)
except Exception as e:
logger.exception("処理中にエラーが発生しました: %s", e)
raise
.prettierrcでは、マークダウンファイルの自動フォーマット設定を行っています。
{
"tabWidth": 4,
"useTabs": false,
"proseWrap": "preserve",
"printWidth": 120,
"endOfLine": "lf"
}
セットアップ
Obsidian
それではセットアップをしていきます。
まずは先ほど共有したリポジトリをgit cloneでローカルにダウンロードします。
次にObsidianのセットアップがまだの方はインストールしてみてください。Obsidianのインストール方法はWeb上に色々あるのでここでは省略します。
インストールできたらObsidianを立ち上げ、以下の画面で保管庫としてフォルダを開くから先ほどcloneしたフォルダを開きます。
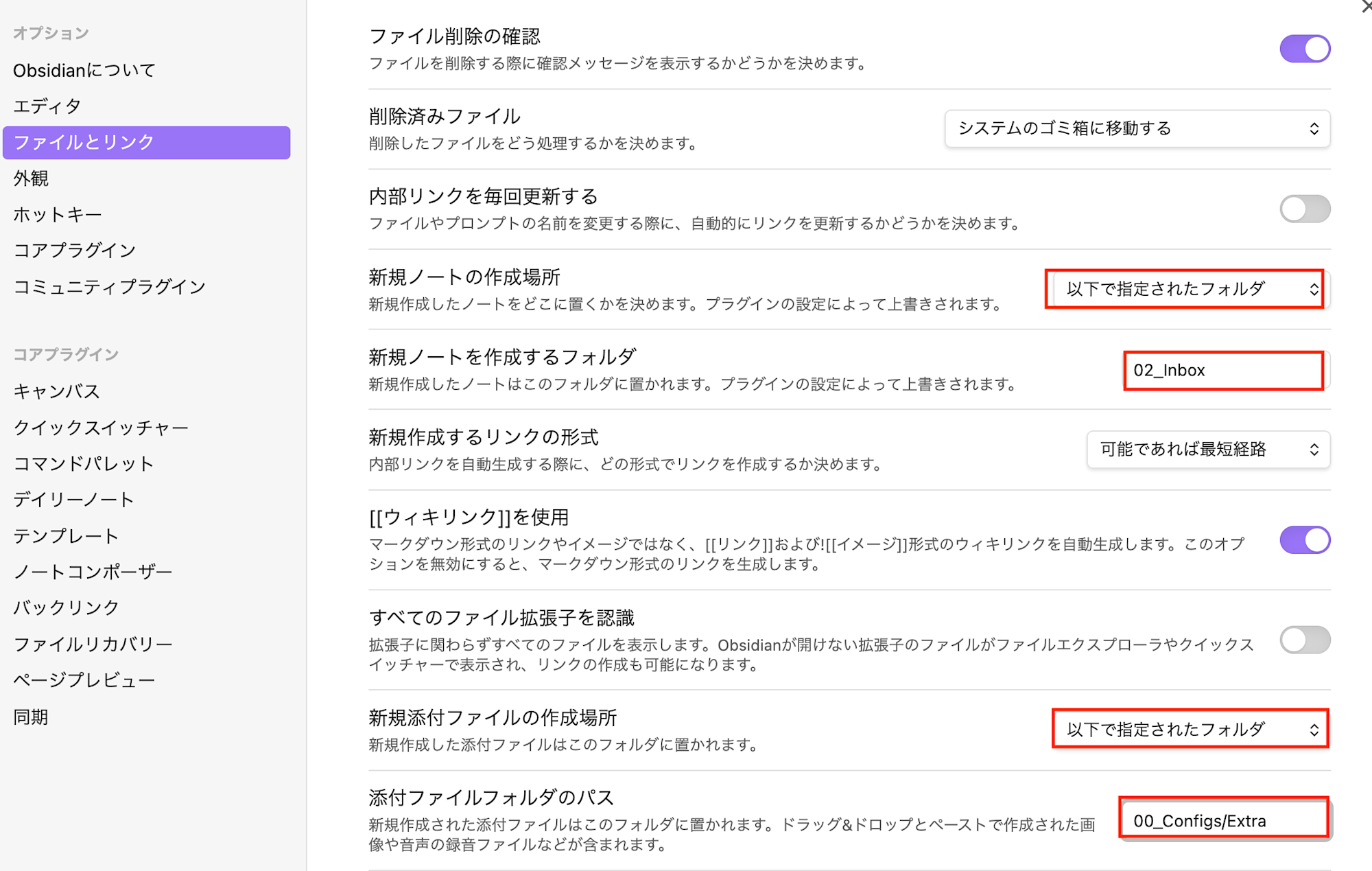
開いた後は設定画面で、赤枠で囲っているテンプレートやノート作成場所を指定します。
ファイルとリンク
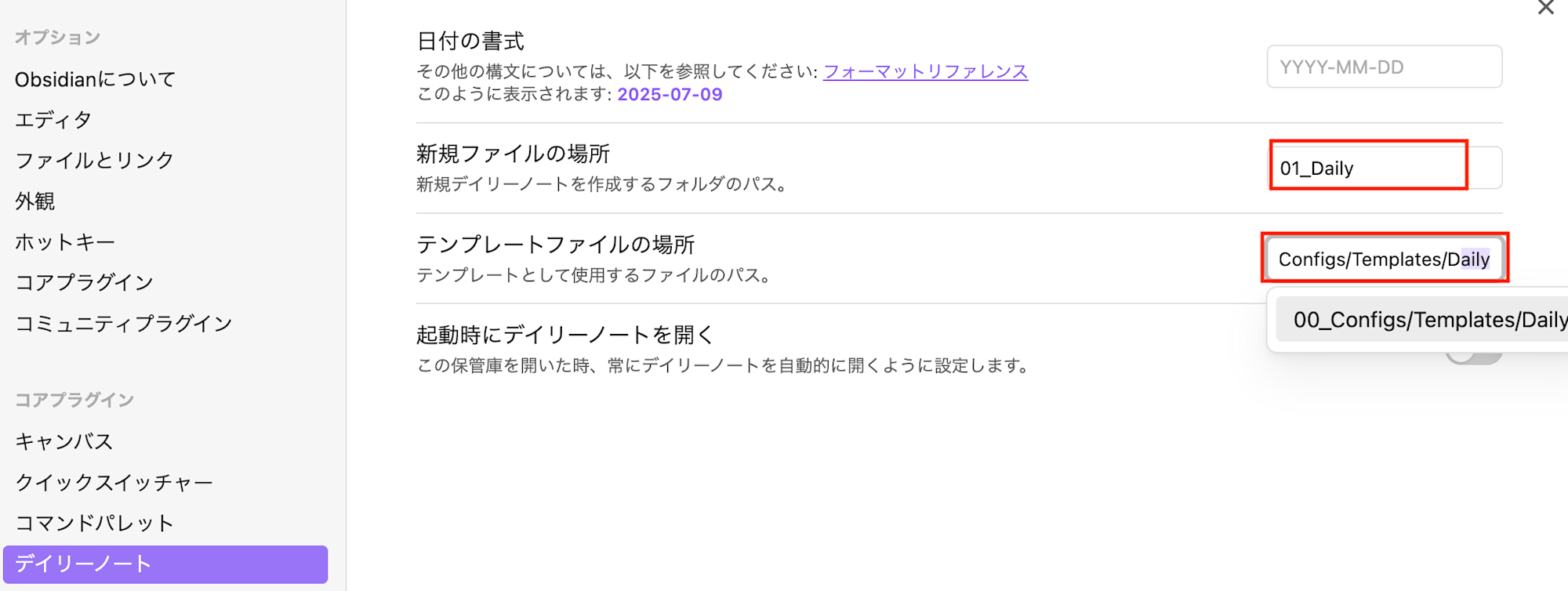
デイリーノート
テンプレート
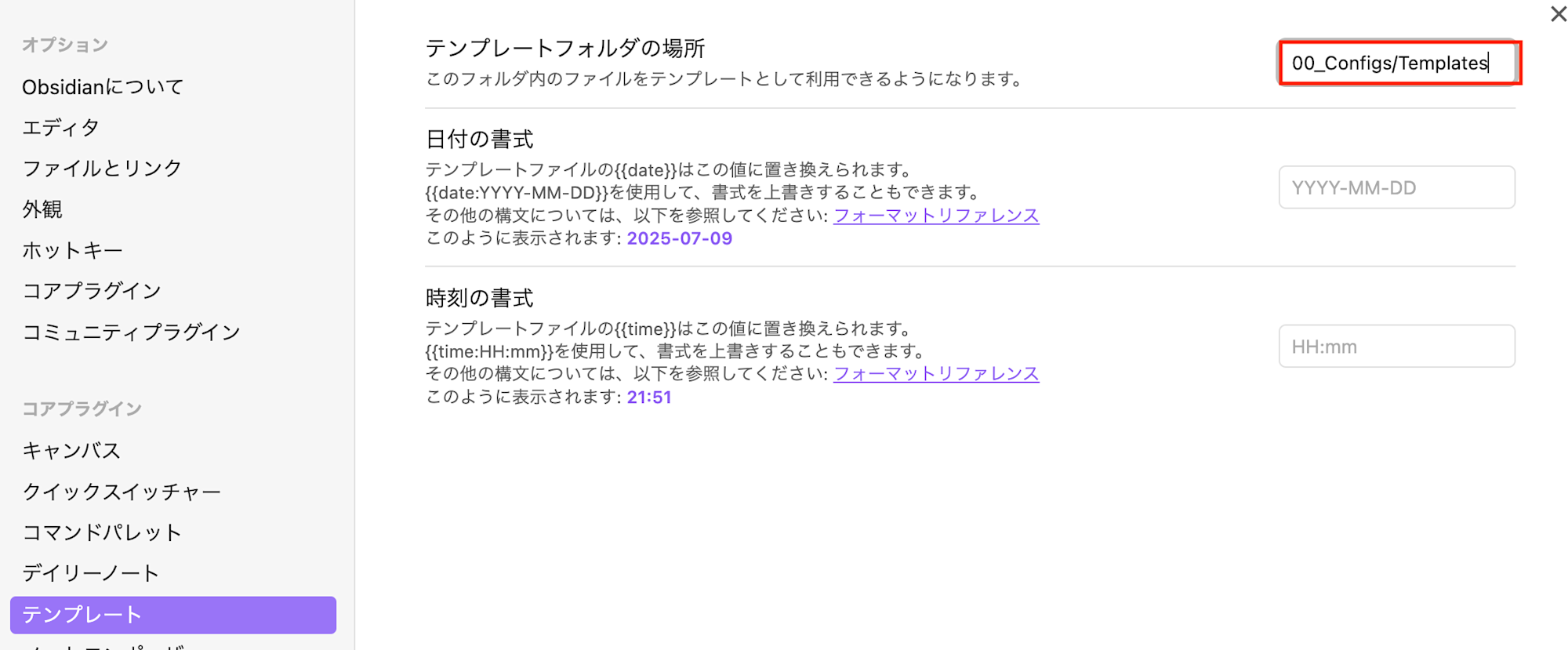
現状の私はこんなところでとりあえず最小設定で進めています。もう少し調べて色々やりたい気持ちはあります。
Vertex AI
次にVertex AIを使用してスクリプトを実行できるようにセットアップします。
Vertex AIの有効化については以下ブログのGoogle Cloudセットアップと同様ですので参照いただければと思います。
Python環境
次にPython バージョン管理、仮想環境、パッケージ管理をするためにuvをインストールします。
# macOS/Linux
curl -LsSf https://astral.sh/uv/install.sh | sh
# Windows
powershell -c "irm https://astral.sh/uv/install.ps1 | iex"
インストール後にプロジェクトディレクトリに移動し、uvの仮想環境を作成し依存関係をインストールします。
# プロジェクトディレクトリに移動
cd audio_video_to_text
# 仮想環境作成(Python 3.13を自動インストール)
uv venv --python 3.13
# 仮想環境の有効化
# macOS/Linux
source .venv/bin/activate
# Windows
.venv\Scripts\activate
# 依存関係のインストール
uv pip install -r requirements.txt
audio_video_to_text/ディレクトリに.envファイルを作成します。FILE_NAMEはinputのファイル名を拡張子ありで指定します。その他はGoogle Cloudの設定値を記載します。
PROJECT_ID=your-gcp-project-id
REGION=your-region
GOOGLE_APPLICATION_CREDENTIALS=path/to/your/service-account-key.json
FILE_NAME=eng_record.mp3
Claude Code
Claude Codeについても公式でセットアップ方法があるのでそちらを参考にしていただければと思います。
セットアップができたら、hooksでPrettierを使用するので、npm installでpackage.jsonからPrettierをインストールします。
@obsidian-claude-feedback-sample % npm install
added 1 package, and audited 2 packages in 706ms
1 package is looking for funding
run `npm fund` for details
found 0 vulnerabilities
npm listでinstallできたことを確認できます。
@obsidian-claude-feedback-sample % npm list
obsidian-claude-feedback-sample@1.0.0 /git/obsidian-claude-feedback-sample
└── prettier@3.6.2
hooksについては、Claudeコマンドの/hooksで実際に設定が適用されているか確認できます。
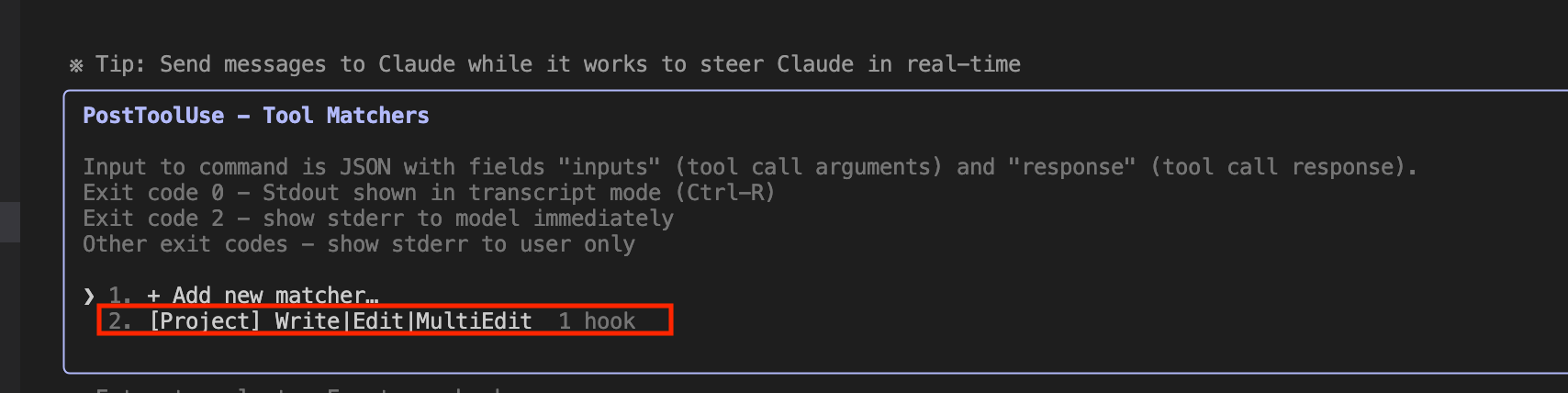
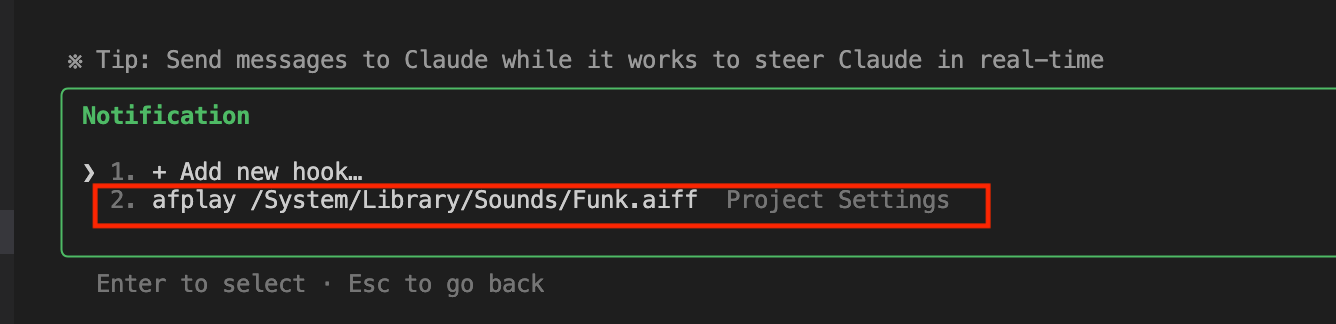
使ってみた
それでは実際に使ってみたいと思います。
audio_video_to_text/input/ フォルダに変換したい MP3 または MP4 ファイルを配置し、.env ファイルの FILE_NAME をファイル名(拡張子あり)に設定します。
先ほど作成した仮想環境が有効化されていることを確認してスクリプトを実行します。
cd audio_video_to_text
python audio_video_to_text.py
30分程度のファイルでしたが1分ちょっとで終了しました。
@audio_video_to_text % python audio_video_to_text.py
2025-07-09 22:41:02,151 - 文字起こし開始: input/eng_record.mp3
2025-07-09 22:42:15,686 - 文字起こし完了
2025-07-09 22:42:15,688 - 書き起こしテキストを保存しました: output/eng_record_transcript.txt
生成されたtxtファイルを元にClaudeにフィードバックを作成してもらいます。
Prettierが実行されることを確認するためにclaude --debugでデバックモードで実行します。
.claude/prompt/english_lesson.mdの録音テキスト箇所に文字起こしされたファイルパスを貼り、Claude Codeに渡し実行します。

DEBUGログでhooksが走りPrettierが起動したことを確認できました。

完了しました。
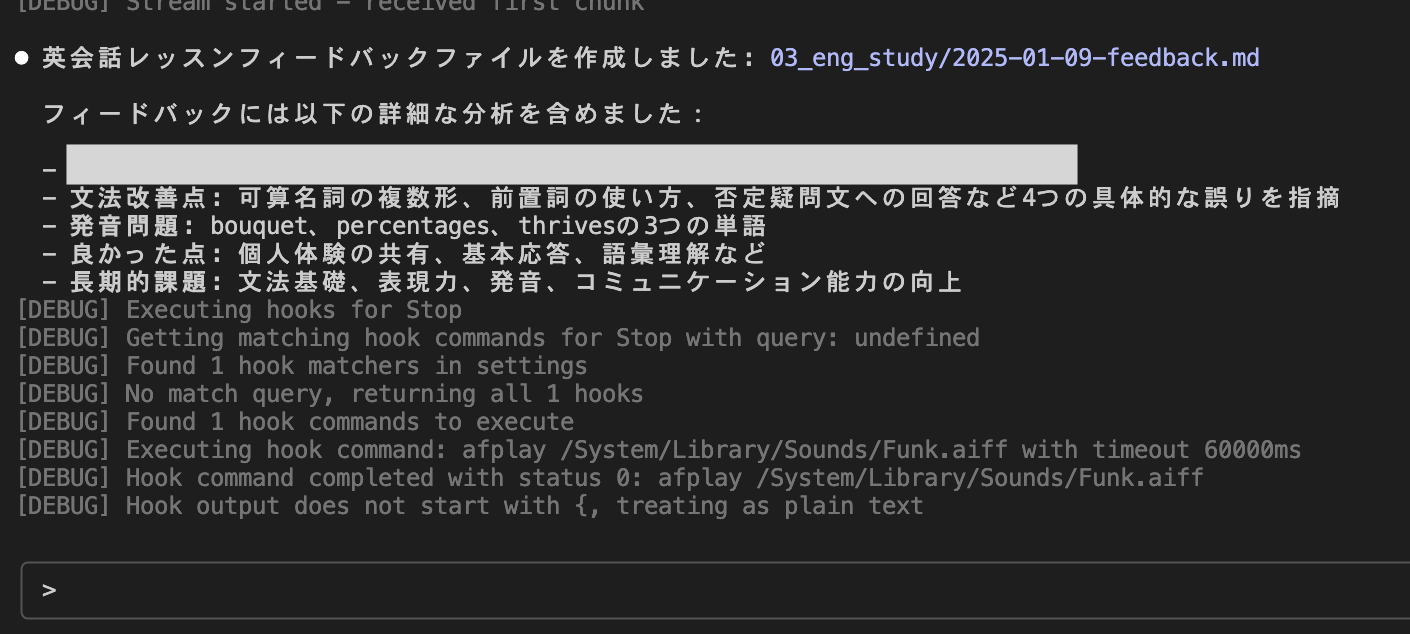
フィードバックファイルの日付はなぜか1月ですが、適切なフィードバックをいただけました。

議事録についてもpromptが異なるだけでほぼ同じ内容ですので、試していただければと思います。
mp4ファイルであればGemini Webからでもテキストに起こすことは可能だったと思うので、そちらを使用しても良いと思います。(mp3は対応していなかったのでスクリプトを実装しています..)
最後に
まだ個人ナレッジ管理を始めて一週間であり、構成については日々改善していく予定ですので、参考程度にしていただければと思います。









