
CloudFormationでマルチリージョン構成を実装するテクニック
はじめに
皆様こんにちは、あかいけです。
今までTerraformで細々と命を繋いできた私ですが、
クラスメソッドに入社してからCloudFormationと触れ合うことが多くなりました。
そして直近でCloudFormationでマルチリージョン構成を実装する機会があったのですが、
CloudFormation初学者ということもあり色々苦戦することがありました…。
というわけで、これからCloudFormationでマルチリージョン構成を作る方に向けて、
考えるべきことと使えそうな技をまとめておきます。
なおAWS CloudFormationを初めて触る方は、
まずは以下のベストプラクティスに目を通しておくことをおすすめします。
コードのメンテナンスについて
まず最初に考えることは、コードをメンテナンスするか、ということです。
「こいつは一体何を言っているんだ?」、と思うかもしれませんが、
正直なところCloudFormationの設計上、リリース後もコードをメンテナンスして保守し続けるのはかなり大変です。
なので個人的には初期構築やDR環境構築など、作り切りの環境はCloudFormation、
インフラレベルでのアップデートが多く、なおかつコードをメンテナンスし続けるのであればTerraformがおすすめです。
※ 作り切りの環境であっても、中規模以上ならTerraformがおすすめ
この辺りの話は以下の記事が大変参考になるので、よければご参照ください。
設計編
さて、CloudFormationを利用することになって一番最初に考えることは、おそらくスタックの設計でしょう。
ここを間違えると後戻りが大変なので、めんどくさいですが少しだけ真面目に考えましょう。
マルチリージョンの使い方
マルチリージョンの使い方によって設計が大きく変わります。
使い方は大きく分けると「複製環境」と「DR環境」の2つのパターンがあります。
複製環境
複製環境は複数のリージョンで同一の環境を構築し、同時に稼働させるパターンです。
主な用途は以下のとおりです。
- グローバル展開: 世界各地のユーザーに低レイテンシーでサービスを提供
- 負荷分散: リージョン間でトラフィックを分散させる
- 高可用性: 一部のリージョンで障害が発生しても、他のリージョンでサービスを継続
複製環境では、基本的に各リージョンのリソースが同一構成となるため、
コード作成においてはDR環境と比較すると考えることは少ないでしょう。
DR環境
DR(Disaster Recovery)環境は、
主要リージョンで障害が発生した際のバックアップとして別リージョンを準備するパターンです。
AWSに限った話ではないですが、DR環境は以下の4種類に大別されます。
マルチサイトアクティブ/アクティブ (ホットスタンバイ)
- 特徴
- 常に完全に同期された環境を別リージョンで稼働させておく
- CloudFormationでは同一テンプレートを両リージョンに展開し、データ同期の仕組みを実装
- 復旧時間
- フェイルオーバー時間が最小(数秒から数分程度)
- コスト
- コストは最も高い(約2倍)
ウォームスタンバイ
- 特徴
- 縮小版の環境を別リージョンで稼働させておき、障害時にスケールアップ
- CloudFormationではパラメータを変えて同一テンプレートを展開
- 復旧時間
- フェイルオーバー時間は中程度(数分から数十分程度)
- コスト
- コストは中程度(メインの50-70%程度)
パイロットライト (コールドスタンバイ)
- 特徴
- 最小限のリソース(データベースなど)のみ別リージョンで稼働
- CloudFormationでは必要最小限のリソースのみを別リージョンに展開
- 復旧時間
- フェイルオーバー時間は長い(数十分程度)
- コスト
- コストは低い(メインの10-30%程度)
バックアップ&リストア
- 特徴
- データのバックアップのみを別リージョンに保存
- CloudFormationでは障害時に新規スタックを展開
- 復旧時間
- 復旧時間は最も長い(数十分から数時間程度)
- コスト
- コストは最も低い
スタック構成
次にスタックの構成です。
それぞれメリットデメリットがあり、
一概にどれがベストとは言えないので要件をもとにメリデメを考慮して決めましょう。
ただ一つだけ言えるのは、
大規模な環境ほどスタックを分割する必要に迫られるということです。
個人的には20リソース以上、
またはコードが1000行を超えるようであれば分割したほうがいいと考えています。
(誰だって1ファイル数千行のコードは見たくないですよね…?)
単一スタック
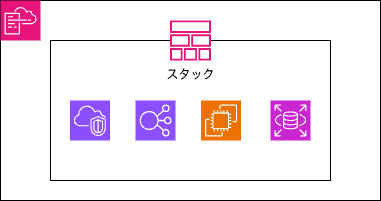
- メリット
- シンプルで管理が容易
- デプロイが一度で完了する
- リソース間の依存関係が明確
- デメリット
- スタックが大きくなりすぎると更新時間が長くなる
- 一部のリソース更新で全体に影響が出る可能性がある
クロススタック
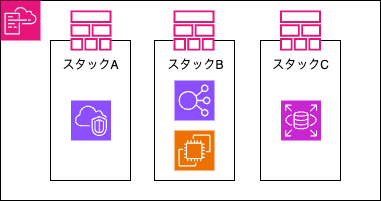
- メリット
- リソースをカテゴリ別にスタック分割できる
- 部分的な更新が容易
- 作業分担がしやすい
- デメリット
- スタック間の依存関係の管理が必要
- デプロイ順序を考慮する必要がある
ネストスタック
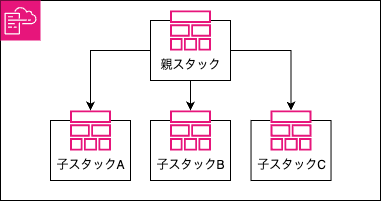
- メリット
- 親スタックから一括デプロイが可能
- モジュール化による再利用性の向上
- 複雑なアーキテクチャの管理が可能
- デメリット
- テンプレートの管理が複雑になる
スタック間の値の受け渡しについて
次に決める必要があるのは、スタック間の値の受け渡し方法でしょう。
単一スタックでない限りは、必ず議論する必要が出てきます。
Export / Import
クロススタックの場合は、基本的にこの方法を使います。
ただしExportした値は同じリージョンのすべてのスタックから参照できてしまうため、命名規則に気をつける必要があったり、
スタック間の参照関係によって更新順を考える必要があったりします。
そのため複数システムのスタックが乱立するような大規模な環境では、
デメリットの方が目立ちがちな気がします。
- メリット
- CloudFormation標準の機能で簡単に実装できる
- スタック間の依存関係が明示的になる
- コンソールからも参照関係が確認しやすい
- デメリット
- エクスポート名はリージョン内でユニークである必要がある
- エクスポート値を参照しているスタックがある場合、元のスタックを更新/削除できない
Resources:
VPC:
Type: AWS::EC2::VPC
Properties:
CidrBlock: 10.0.0.0/16
Subnet:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref VPC
CidrBlock: 10.0.0.0/24
Outputs:
VpcId:
Value: !Ref VPC
Export:
Name: !Sub VpcId
SubnetId:
Export:
Name: !Ref Subnet
Resources:
Subnet:
Type: AWS::EC2::Subnet
Properties:
VpcId: !ImportValue VpcId
CidrBlock: 10.0.0.0/24
GetAtt
ネストスタックの場合は、基本的にこの方法を使います。
親スタックを経由して値を受け渡すため記述量が少々増えてしまいますが、
Export / Importで問題となるExportした値のスコープや、スタック更新時のスタック間の依存関係などの問題点が多少解消されます。
あくまで個人的な意見ですが、
ネストスタック + GetAtt が一番汎用的に利用できる気がします。
- メリット
- 親スタックから一元管理できる
- 出力された値がスタック内で完結する
- デプロイ順序が自動的に解決される
- デメリット
- ネストスタックでのみ利用可能
- 親スタックの記述量が増える
- 深い階層になると管理が複雑になる
Resources:
NetworkStack:
Type: AWS::CloudFormation::Stack
Properties:
TemplateURL: https://s3.amazonaws.com/bucket/network.yaml
ComputeStack:
Type: AWS::CloudFormation::Stack
Properties:
TemplateURL: https://s3.amazonaws.com/bucket/compute.yaml
Parameters:
SubnetId: !GetAtt NetworkStack.Outputs.SubnetId
Resources:
VPC:
Type: AWS::EC2::VPC
Properties:
CidrBlock: 10.0.0.0/16
Subnet:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref VPC
CidrBlock: 10.0.0.0/24
Outputs:
VpcId:
Value: !Ref VPC
SubnetId:
Value: !Ref Subnet
Parameters:
VpcId:
Type: String
SubnetId:
Type: String
Resources:
EC2Instance:
Type: AWS::EC2::Instance
Properties:
SubnetId: !Ref SubnetId
パラメータストア (動的参照)
クロススタック、ネストスタックのどちらでも利用できます。
パラメータストアに格納する分コードの記述量は増えてしまいますが、
スタック間の依存関係を分離できます。
そのため特定のリソースを複数システムで共通して利用するなど、
大規模や複雑な構成になる場合におすすめです。
- メリット
- リージョン間での値の共有が可能(各リージョンのパラメータストアに保存)
- スタック以外のシステム(CI/CDパイプラインなど)からも参照可能
- 暗号化された値の保存が可能(SecureString型)
- デメリット
- 記述量が増える
- 依存関係が暗黙的になりがち
Resources:
VPC:
Type: AWS::EC2::VPC
Properties:
CidrBlock: 10.0.0.0/16
Subnet:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref VPC
CidrBlock: 10.0.0.0/24
VpcParameter:
Type: AWS::SSM::Parameter
Properties:
Name: vpcid
Type: String
Value: !Ref VPC
SubnetParameter:
Type: AWS::SSM::Parameter
Properties:
Name: subnetid
Type: String
Value: !Ref Subnet
Resources:
EC2Instance:
Type: AWS::EC2::Instance
Properties:
SubnetId: '{{resolve:ssm:subnetid}}'
スタックセットの利用について
マルチリージョンのデプロイをする場合、スタックセットの利用が考えられます。
確かに便利な機能ではありますが、以下の性質を考慮して採用を考える必要があるでしょう。
- 管理者アカウントでの一元的な管理が必要である
- 複数のアカウント、複数のリージョンでのデプロイ可能
- 同一のテンプレートを複数のリージョンやアカウントに展開する
個人的にはアカウントの初期セットアップでマルチアカウント + マルチリージョンに共通のリソースを作成する場合などは有用だと思います。
なので単一システムのマルチリージョン構成などであれば、使う意味合いは薄いかと思います。
文法編
以降は役立つ文法と具体例を挙げていきます。
まさに小技といった内容ですが、具体的に実装する際に役立つと思うのでご参考になれば幸いです。
Mappings + 擬似パラメータ
リージョンごとにリソースの設定値を変更したい場合、大抵はこの記法で何とかなります。
例:VPC / Subnet の IP CIDR と AZ
これはIP CIDRとAZをリージョンごとに異なる値に設定する例です。
なおAZについては GetAZs であれば直接値を埋め込まなくて済むので、こちらの利用も検討してみてください。
Mappings:
RegionToCIDRs:
ap-northeast-1:
VpcCidr: 192.168.0.0/24
PublicSubnet1Cidr: 192.168.0.0/26
PublicSubnet1Cidr: 192.168.0.64/26
ap-northeast-3:
VpcCidr: 192.168.1.0/24
PublicSubnet1Cidr: 192.168.1.0/26
PublicSubnet1Cidr: 192.168.1.64/26
RegionToAvailabilityZones:
ap-northeast-1:
AZ1: "ap-northeast-1a"
AZ2: "ap-northeast-1c"
ap-northeast-3:
AZ1: "ap-northeast-3a"
AZ2: "ap-northeast-3b"
Resources:
VPC:
Type: AWS::EC2::VPC
Properties:
CidrBlock: !FindInMap [RegionToCIDRs, !Ref "AWS::Region", VpcCidr]
Subnet1:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref VPC
CidrBlock:
!FindInMap [RegionToCIDRs, !Ref "AWS::Region", PublicSubnet1Cidr]
AvailabilityZone:
!FindInMap [RegionToAvailabilityZones, !Ref "AWS::Region", AZ1]
Subnet2:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref VPC
CidrBlock:
!FindInMap [RegionToCIDRs, !Ref "AWS::Region", PublicSubnet2Cidr]
AvailabilityZone:
!FindInMap [RegionToAvailabilityZones, !Ref "AWS::Region", AZ2]
例:リージョンごとに異なるNameタグをつける
以下はリージョンごとに異なるNameタグをつける例です、
AZなどリージョンごとに異なる値をNameタグに含めたい場合に役立ちます。
Mappings:
AvailabilityZoneToShortname:
ap-northeast-1:
AZ1: "1a"
AZ2: "1c"
ap-northeast-3:
AZ1: "3a"
AZ2: "3b"
NatGateway1:
Type: AWS::EC2::NatGateway
Properties:
Tags:
- Key: Name
Value: !Join
- "-"
- - "natgw"
- !FindInMap [
AvailabilityZoneToShortname,
!Ref "AWS::Region",
AZ1,
]
NatGateway2:
Type: AWS::EC2::NatGateway
Properties:
Tags:
- Key: Name
Value: !Join
- "-"
- - "natgw"
- !FindInMap [
AvailabilityZoneToShortname,
!Ref "AWS::Region",
AZ2,
]
例:ElastiCache レプリカ用AZ
ElastiCache::ReplicationGroup ではそのリージョンに対応したAZを指定する必要があります。
なおAZについては GetAZs であれば直接値を埋め込まなくて済むので、こちらの利用も検討してみてください。
Mappings:
RegionToAZs:
ap-northeast-1:
AZ1: "ap-northeast-1a"
AZ2: "ap-northeast-1c"
ap-northeast-3:
AZ1: "ap-northeast-3a"
AZ2: "ap-northeast-3b"
ElastiCacheReplicationGroup:
Type: AWS::ElastiCache::ReplicationGroup
Properties:
ReplicationGroupId: "elasticache"
PreferredCacheClusterAZs:
- !FindInMap [RegionToAZs, !Ref "AWS::Region", AZ1]
- !FindInMap [RegionToAZs, !Ref "AWS::Region", AZ2]
例:TemplateURL
リージョン障害を想定すると、S3に格納するテンプレートファイルも複製しておく必要があります。
そんな時はS3のバケット名にリージョン識別子を埋め込んで、親スタックのTemplateURLで参照するといい感じになります。
Mappings:
RegionToShortname:
ap-northeast-1:
Shortname: "apne1"
ap-northeast-3:
Shortname: "apne3"
Resources:
CloudWatch:
Type: AWS::CloudFormation::Stack
Properties:
TemplateURL: !Sub
- "https://s3.amazonaws.com/${RegionShortname}-cfn-s3/cfn.yaml"
- RegionShortname:
!FindInMap [RegionToShortname, !Ref "AWS::Region", Shortname]
例:ELB アクセスログ用S3バケットポリシー
ELBのアクセスログ配信元のアカウントは、リージョンごとに異なります。
そのためMappingsで定義した値を埋め込んであげると、いい感じにバケットポリシーを作れます。
Mappings:
ElbRegionToAccountId:
ap-northeast-1:
AccountId: "582318560864"
ap-northeast-3:
AccountId: "383597477331"
AlbLogS3Bucket:
Type: AWS::CloudFormation::Stack
Properties:
TemplateURL: "https://s3.amazonaws.com/bucket/s3.yaml"
Parameters:
ElbRegionToAccountId:
!FindInMap [ElbRegionToAccountId, !Ref "AWS::Region", AccountId]
Parameters:
ElbRegionToAccountId:
Type: String
Resources:
AlbLogS3Bucket:
Type: AWS::S3::Bucket
Properties:
BucketName: "alb-s3"
AlbLogS3BucketPolicy:
Type: AWS::S3::BucketPolicy
Properties:
Bucket: !Ref AlbLogS3Bucket
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
AWS: !Sub "arn:aws:iam::${ElbRegionToAccountId}:root"
Action: "s3:PutObject"
Resource: !Sub "${AlbLogS3Bucket.Arn}/*"
例:DNS Firewall マネージドドメインリスト
DNS Firewall の マネージドドメインリスト はリージョンごとにIDが決まっています。
そのためMappingsで定義した値を埋め込んであげると、いい感じに指定できます。
Mappings:
AWSManagedDomainsAggregateThreatListId:
ap-northeast-1:
Id: "rslvr-fdl-103b4302c274455e"
ap-northeast-3:
Id: "rslvr-fdl-2e57899062984ed1"
Resources:
DnsFirewallRuleGroup:
Type: AWS::Route53Resolver::FirewallRuleGroup
Properties:
FirewallRules:
- Action: BLOCK
BlockResponse: NODATA
Priority: 100
FirewallDomainListId: !FindInMap [AWSManagedDomainsAggregateThreatListId, !Ref "AWS::Region", Id]
Condition + 擬似パラメータ
作成するリソースを制御したい場合は、大抵この方法で何とかなります。
例:リージョンごとに作成するリソースを制御する
DR環境など普段は一部リソースのみ作成して、EC2などは作成しない環境の場合、
親スタック側でConditionを利用することで、作成するリソースを制御できます。
以下であれば東京リージョンの場合だけ、子スタックを作成します。
Conditions:
IsTokyoRegion: !Equals [!Ref "AWS::Region", "ap-northeast-1"]
Resources:
SecretsManager:
Type: AWS::CloudFormation::Stack
Condition: IsTokyoRegion
Properties:
TemplateURL: "https://s3.amazonaws.com/${RegionShortname}-cfn-s3/cfn.yaml"
Resources:
Secret:
Type: AWS::SecretsManager::Secret
Properties:
Name: "secret"
If 関数 + AWS::NoValue
条件に応じてリソースのパラメータを制御したい場合、
この方法が使えます。
例:RDS スナップショットの制御
以下はAuroraクラスター作成時にスナップショットを利用するかを制御しています。
例えば東京リージョンで初回構築の場合、スナップショットなしで作成します。
逆にDR環境の場合は東京リージョンで作成されたスナップショットから、クラスターを作成する必要があります。
Parameters:
PostgressqlAuroraSnapShot:
Type: String
Default: ""
Conditions:
HasPostgressqlAuroraSnapShot:
!Not [!Equals [!Ref PostgressqlAuroraSnapShot, ""]]
CreatePostgresqlInstances:
!Equals [!Ref PostgressqlAuroraSnapShot, ""]
Resources:
PostgresqlCluster:
Type: AWS::RDS::DBCluster
Properties:
DBClusterIdentifier: "aurora-postgresql"
Engine: aurora-postgresql
SnapshotIdentifier:
!If [
HasPostgressqlAuroraSnapShot,
!Ref PostgressqlAuroraSnapShot,
!Ref "AWS::NoValue",
]
さいごに
以上、CloudFormationでマルチリージョン構成を実装するテクニックでした。
CloudFormationはPoCや単一リージョンでの構築、また小規模な環境であればパパッとできてとても便利なのですが、
マルチリージョンなど複雑な構成になってくると途端に考えることが増えてきます。
マルチリージョン構成を検討する際は、環境の目的(複製かDRか)、スタック構成、値の受け渡し方法などをしっかり設計することで、後々の運用がスムーズになります。
ぜひ本記事のテクニックを参考に、最適なマルチリージョン環境を構築してみてください。








