
CloudFrontのアクセスログをS3とCloudWatchLogsに出力、AthenaとLogsInsightで集計してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
2024年11月、Amazon CloudFront のアクセスログ(v2)が利用可能となり、JSON形式での保存や、S3、CloudWatchLogsなどログ出力先をカスタマイズできるようになりました。
今回は、JSON形式のアクセスログを S3とCloudWatchLogsに出力し、それぞれのログを対象に集計クエリを試す機会があったので、紹介します。
CloudFront
CloudFrontダッシュボードの Destination 設定より、「Logging」の設定を行いました。

ログ設定
-
Destination
- ログ出力先は、CloudWatch log group と S3をそれぞれ追加しました。
-
Selected fields
- S3は、2025年1月時点で指定可能な全項目を選択(41項目)しました。
- CloudWatch log group は、LogsInsightのスキャン量を抑制するため、対象カラムを限定しました。
-
Partitioning
- S3の出力先は「/{DistributionId}/{yyyy}/{MM}/{dd}/{HH}/」とし、年月日をパーティション投影で利用できる指定としました。
-
Output format
- S3、CloudWatchLogsともJSON形式を選択しました。
- コストや性能の最適化よりも、保守の容易さやログ項目の増減への追従性を優先しました。
CloudWatchLogs
CloudWatchLogsでは、CloudFrontから送信されたアクセスログをニアリアルタイムで確認することができます。
ログストリーム確認
- ログ出力先のロググループ以下に作成されるログストリームを確認しました。
- 参照操作を試みた数十秒前のタイムスタンプのアクセスログを確認する事ができました。

LogsInsight
Logs Insight の対象ロググループとして、CloudWatch Logs のログ出力先のロググループを指定。
JSON 形式で保存されたアクセスログを、Logs Insight で集計できることを確認しました。
クエリ例
IP別集計
IP アドレス別にリクエスト回数と所要時間を求め、大量リクエスト元の特定を試みました。
fields @timestamp, @message
| parse @message /\"c-ip\":\"(?<clientip>[^\"]+)\"/
| parse @message /\"time-taken\":\"(?<timetaken>[^\"]+)\"/
| parse @message /\"asn\":\"(?<asn>[^\"]+)\"/
| parse @message /\"x-edge-location\":\"(?<location>[^\"]+)\"/
| parse @message /\"cs\(User-Agent\)\":\"(?<useragent>[^\"]+)\"/
| parse @message /\"sc-status\":\"(?<status>[^\"]+)\"/
| stats count() as request_count,
sum(timetaken) as total_time,
avg(timetaken) as avg_time
by clientip, asn, location, useragent, status
| sort total_time desc
| limit 100
指定した時間帯の総リクエスト数と IP 別の所要時間などが確認できました。
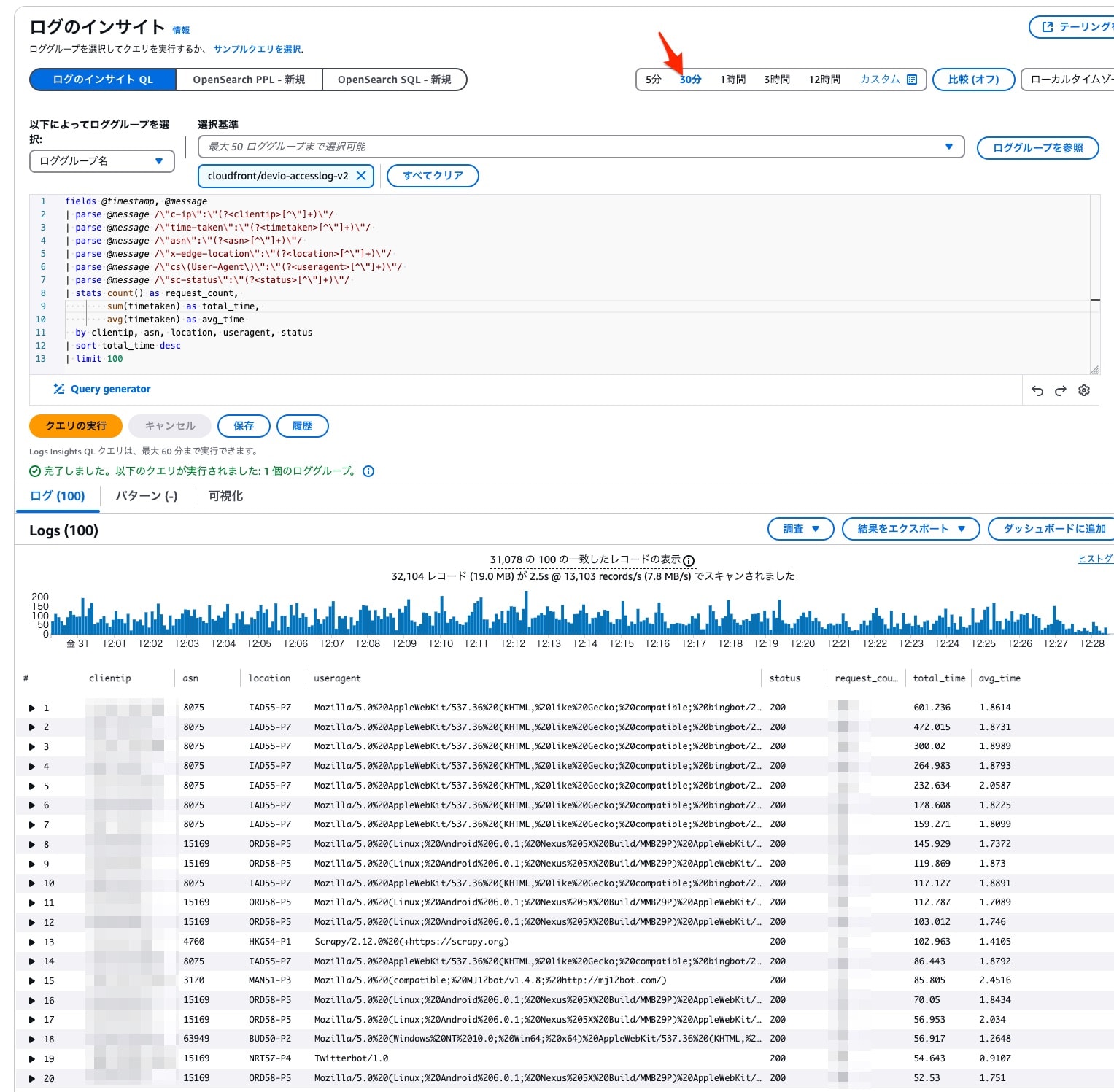
特定IPアドレス集計
Google のクローラーが利用されていたIPアドレスを求め、IPアドレスが該当するリクエストを集計しました。
$ dig -x 66.249.69.1 +short
crawl-66-249-69-1.googlebot.com.
fields @timestamp, @message
| parse @message /\"time-taken\":\"(?<timetaken>[^\"]+)\"/
| parse @message /\"c-ip\":\"(?<clientip>[^\"]+)\"/
| parse @message /\"cs-uri-stem\":\"(?<uri>[^\"]+)\"/
| parse @message /\"sc-status\":\"(?<status>[^\"]+)\"/
| parse @message /\"x-edge-response-result-type\":\"(?<edge_response_result_type>[^\"]+)\"/
| filter clientip like /66.249.69./
| stats count() as request_count,
sum(timetaken) as total_time,
avg(timetaken) as avg_time
by uri, status, edge_response_result_type
| sort request_count desc
| limit 100
RSSフィードを中心にリクエストされていた事がわかりました。
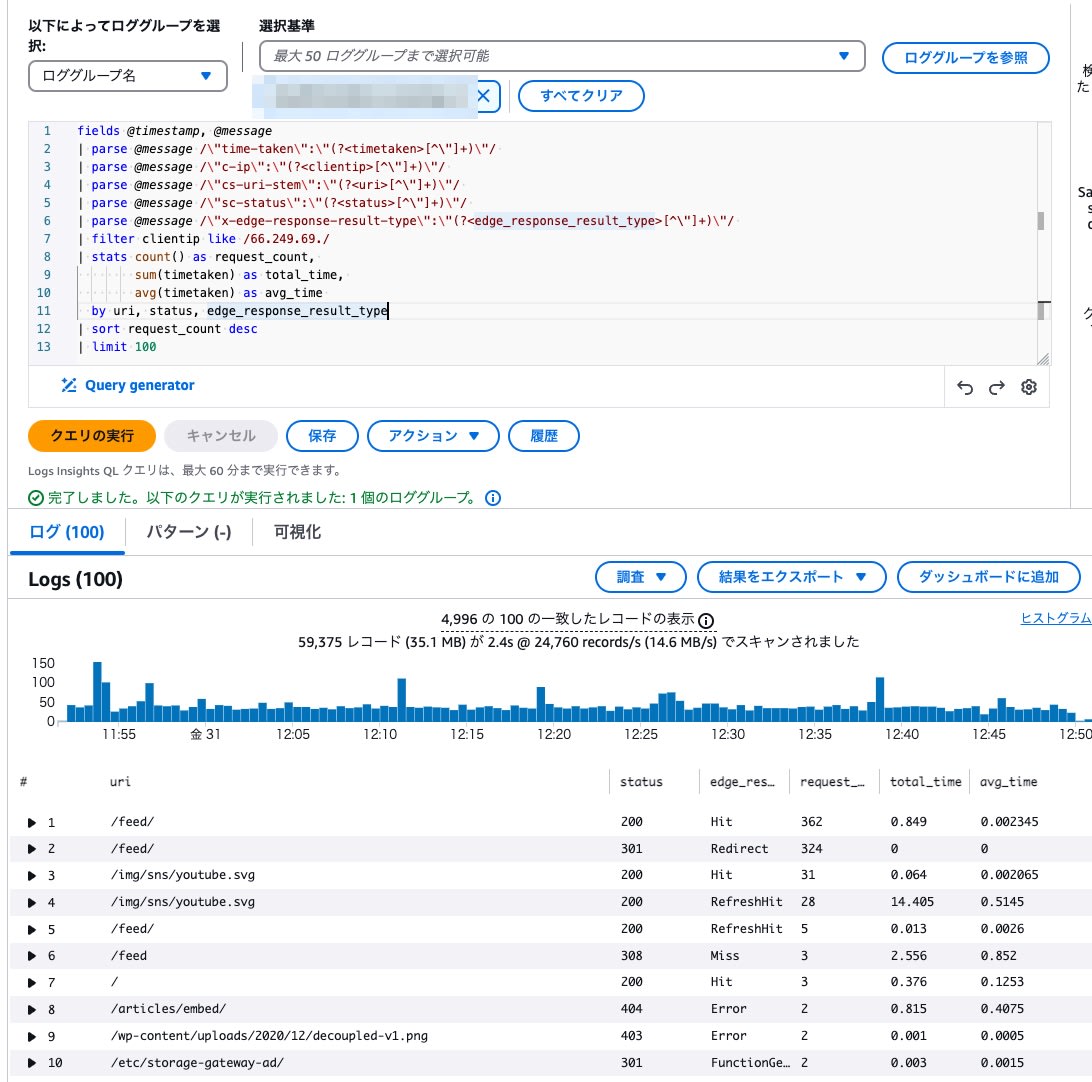
UserAgent別
User Agent に「SlackBot」を含むリクエストの集計を試みました
fields @timestamp, @message
| parse @message /\"time-taken\":\"(?<timetaken>[^\"]+)\"/
| parse @message /\"cs\(User-Agent\)\":\"(?<useragent>[^\"]+)\"/
| parse @message /\"cs-uri-stem\":\"(?<uri>[^\"]+)\"/
| parse @message /\"sc-status\":\"(?<status>[^\"]+)\"/
| parse @message /\"x-edge-response-result-type\":\"(?<edge_response_result_type>[^\"]+)\"/
| filter tolower(useragent) like /slackbot/
| stats count() as request_count,
sum(timetaken) as total_time,
avg(timetaken) as avg_time
by uri, status, edge_response_result_type
| sort request_count desc
| limit 100
トップページ (/) と RSS が多くリクエストされていました。
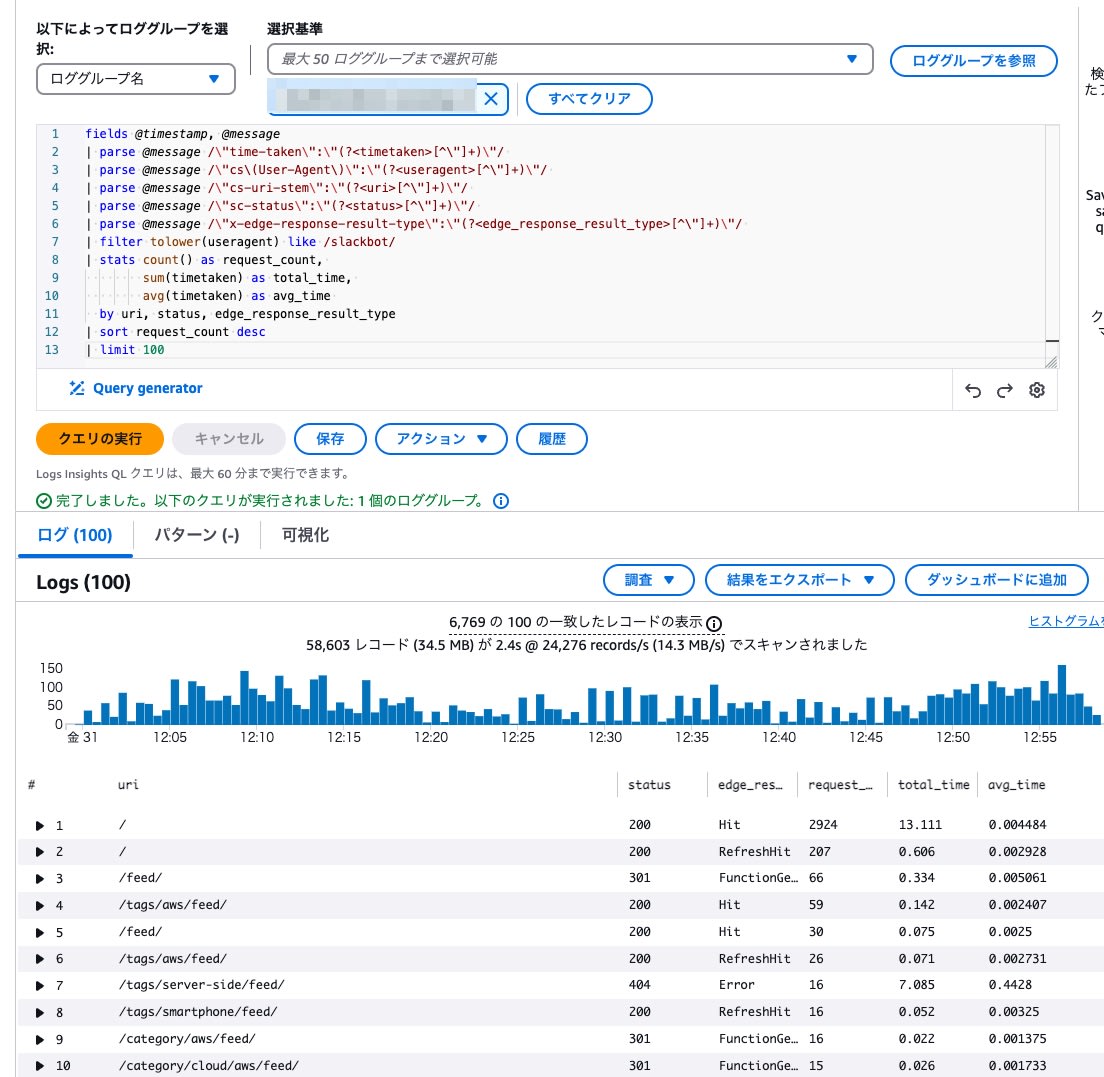
Athena
S3 に出力したアクセスログを対象とした、テーブルとビューを作成しました。
Table
パーティション分割でログ出力時間を指定、JSON のキーをそのまま取り込み、文字列型 (string) で扱うテーブルを用意しました。
CREATE EXTERNAL TABLE `cloudfront_logs_v2_json`(
`timestamp` string COMMENT 'from deserializer',
`DistributionId` string COMMENT 'from deserializer',
`date` string COMMENT 'from deserializer',
`time` string COMMENT 'from deserializer',
`x-edge-location` string COMMENT 'from deserializer',
`sc-bytes` string COMMENT 'from deserializer',
`c-ip` string COMMENT 'from deserializer',
`cs-method` string COMMENT 'from deserializer',
`cs(Host)` string COMMENT 'from deserializer',
`cs-uri-stem` string COMMENT 'from deserializer',
`sc-status` string COMMENT 'from deserializer',
`cs(Referer)` string COMMENT 'from deserializer',
`cs(User-Agent)` string COMMENT 'from deserializer',
`cs-uri-query` string COMMENT 'from deserializer',
`cs(Cookie)` string COMMENT 'from deserializer',
`x-edge-result-type` string COMMENT 'from deserializer',
`x-edge-request-id` string COMMENT 'from deserializer',
`x-host-header` string COMMENT 'from deserializer',
`cs-protocol` string COMMENT 'from deserializer',
`cs-bytes` string COMMENT 'from deserializer',
`time-taken` string COMMENT 'from deserializer',
`x-forwarded-for` string COMMENT 'from deserializer',
`ssl-protocol` string COMMENT 'from deserializer',
`ssl-cipher` string COMMENT 'from deserializer',
`x-edge-response-result-type` string COMMENT 'from deserializer',
`cs-protocol-version` string COMMENT 'from deserializer',
`fle-status` string COMMENT 'from deserializer',
`fle-encrypted-fields` string COMMENT 'from deserializer',
`c-port` string COMMENT 'from deserializer',
`time-to-first-byte` string COMMENT 'from deserializer',
`x-edge-detailed-result-type` string COMMENT 'from deserializer',
`sc-content-type` string COMMENT 'from deserializer',
`sc-content-len` string COMMENT 'from deserializer',
`sc-range-start` string COMMENT 'from deserializer',
`sc-range-end` string COMMENT 'from deserializer',
`timestamp(ms)` string COMMENT 'from deserializer',
`origin-fbl` string COMMENT 'from deserializer',
`origin-lbl` string COMMENT 'from deserializer',
`asn` string COMMENT 'from deserializer',
`c-country` string COMMENT 'from deserializer',
`cache-behavior-path-pattern` string COMMENT 'from deserializer'
)
PARTITIONED BY (
year STRING,
month STRING,
day STRING,
hour STRING
)
ROW FORMAT SERDE
'org.openx.data.jsonserde.JsonSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://<S3バケット>/<ディストリビューションID>/'
TBLPROPERTIES (
'compressionType'='gzip',
'has_encrypted_data'='false',
'ignore.malformed.json'='true',
'projection.enabled'='true',
'projection.year.type'='integer',
'projection.year.range'='2024,2025',
'projection.month.type'='integer',
'projection.month.range'='1,12',
'projection.month.digits'='2',
'projection.day.type'='integer',
'projection.day.range'='1,31',
'projection.day.digits'='2',
'projection.hour.type'='integer',
'projection.hour.range'='0,23',
'projection.hour.digits'='2',
'storage.location.template'='s3://<S3バケット>/<ディストリビューションID>/${year}/${month}/${day}/${hour}'
);
View
従来のCSV形式のログ集計に利用していたSQLを流用可能とするため、以下のViewを用意しました。
- 従来のCSV形式の標準ログで利用していたカラム名(スネークケース)に変更
- 数値の集計を可能にするため、転送容量や所要時間などは文字列型から数値型に変更
- 欠落値や未記録値は NULL として、型エラーを回避
Create a table for CloudFront standard logs
CREATE OR REPLACE VIEW cloudfront_logs_v2_view AS
SELECT
CASE
WHEN date IS NULL THEN NULL
WHEN TRIM(CAST(date AS VARCHAR)) = '' THEN NULL
ELSE TRY_CAST(date AS DATE)
END as date,
time,
"x-edge-location" as x_edge_location,
CASE
WHEN "sc-bytes" IS NULL THEN NULL
WHEN "sc-bytes" = '-' THEN NULL
WHEN TRIM("sc-bytes") = '' THEN NULL
ELSE TRY_CAST("sc-bytes" AS bigint)
END as sc_bytes,
"c-ip" as c_ip,
"cs-method" as cs_method,
"cs(Host)" as cs_host,
"cs-uri-stem" as cs_uri_stem,
CASE
WHEN "sc-status" IS NULL THEN NULL
WHEN "sc-status" = '-' THEN NULL
WHEN TRIM("sc-status") = '' THEN NULL
ELSE TRY_CAST("sc-status" AS int)
END as sc_status,
"cs(Referer)" as cs_referrer,
"cs(User-Agent)" as cs_user_agent,
"cs-uri-query" as cs_uri_query,
"cs(Cookie)" as cs_cookie,
"x-edge-result-type" as x_edge_result_type,
"x-edge-request-id" as x_edge_request_id,
"x-host-header" as x_host_header,
"cs-protocol" as cs_protocol,
CASE
WHEN "cs-bytes" IS NULL THEN NULL
WHEN "cs-bytes" = '-' THEN NULL
WHEN TRIM("cs-bytes") = '' THEN NULL
ELSE TRY_CAST("cs-bytes" AS bigint)
END as cs_bytes,
CASE
WHEN "time-taken" IS NULL THEN NULL
WHEN "time-taken" = '-' THEN NULL
WHEN TRIM("time-taken") = '' THEN NULL
ELSE TRY_CAST("time-taken" AS double)
END as time_taken,
"x-forwarded-for" as x_forwarded_for,
"ssl-protocol" as ssl_protocol,
"ssl-cipher" as ssl_cipher,
"x-edge-response-result-type" as x_edge_response_result_type,
"cs-protocol-version" as cs_protocol_version,
"fle-status" as fle_status,
CASE
WHEN "fle-encrypted-fields" IS NULL THEN NULL
WHEN "fle-encrypted-fields" = '-' THEN NULL
WHEN TRIM("fle-encrypted-fields") = '' THEN NULL
ELSE TRY_CAST("fle-encrypted-fields" AS int)
END as fle_encrypted_fields,
CASE
WHEN "c-port" IS NULL THEN NULL
WHEN "c-port" = '-' THEN NULL
WHEN TRIM("c-port") = '' THEN NULL
ELSE TRY_CAST("c-port" AS int)
END as c_port,
CASE
WHEN "time-to-first-byte" IS NULL THEN NULL
WHEN "time-to-first-byte" = '-' THEN NULL
WHEN TRIM("time-to-first-byte") = '' THEN NULL
ELSE TRY_CAST("time-to-first-byte" AS double)
END as time_to_first_byte,
"x-edge-detailed-result-type" as x_edge_detailed_result_type,
"sc-content-type" as sc_content_type,
CASE
WHEN "sc-content-len" IS NULL THEN NULL
WHEN "sc-content-len" = '-' THEN NULL
WHEN TRIM("sc-content-len") = '' THEN NULL
ELSE TRY_CAST("sc-content-len" AS bigint)
END as sc_content_len,
CASE
WHEN "sc-range-start" IS NULL THEN NULL
WHEN "sc-range-start" = '-' THEN NULL
WHEN TRIM("sc-range-start") = '' THEN NULL
ELSE TRY_CAST("sc-range-start" AS bigint)
END as sc_range_start,
CASE
WHEN "sc-range-end" IS NULL THEN NULL
WHEN "sc-range-end" = '-' THEN NULL
WHEN TRIM("sc-range-end") = '' THEN NULL
ELSE TRY_CAST("sc-range-end" AS bigint)
END as sc_range_end,
year,
month,
day,
hour
FROM cloudfront_logs_v2_json
WHERE year = '2025'
AND month = '01'
AND day = '30'
AND hour = '03'
今回、パーティションによるスキャン期間の絞り込みは、ビューの WHERE 句に含めました。
- プレビュー実施
SELECT * FROM "default"."cloudfront_logs_v2_view" limit 10;
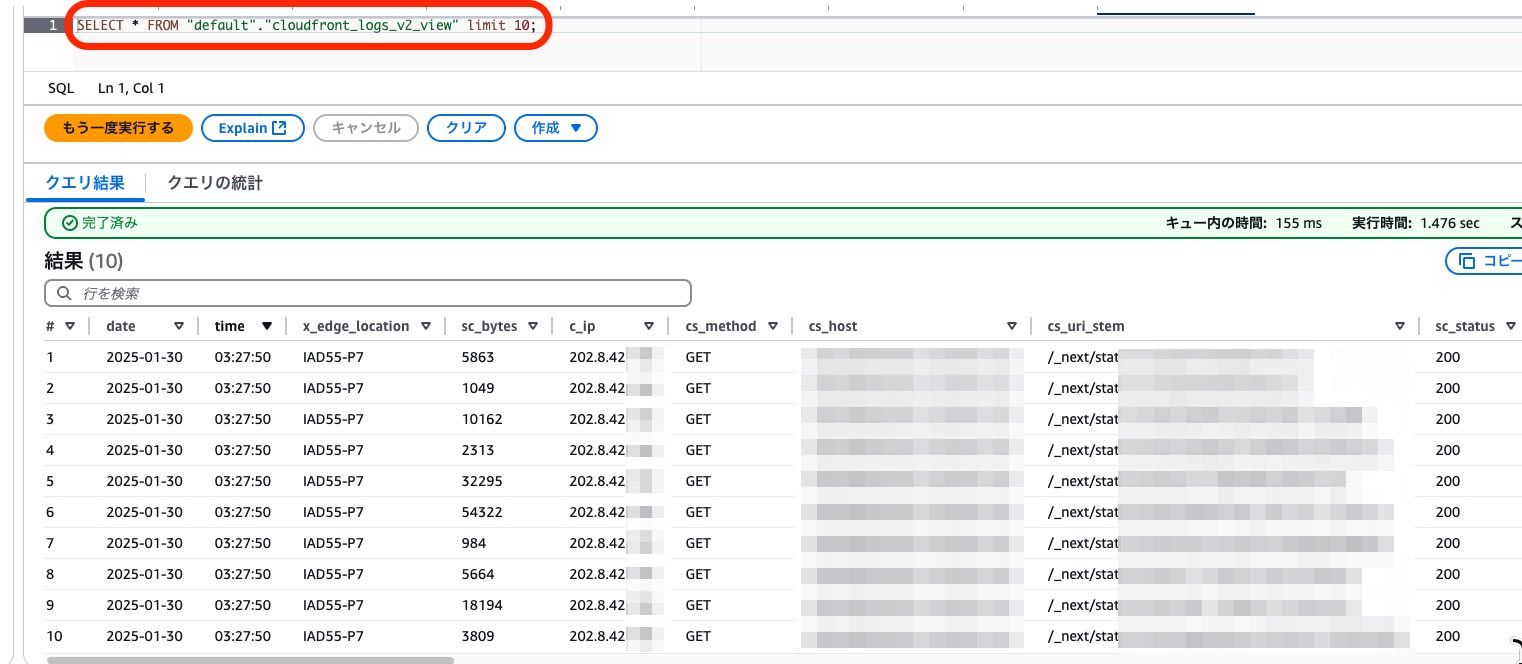
集計クエリ例
作成したビューを利用して、CloudFront アクセスログの集計を試みました。
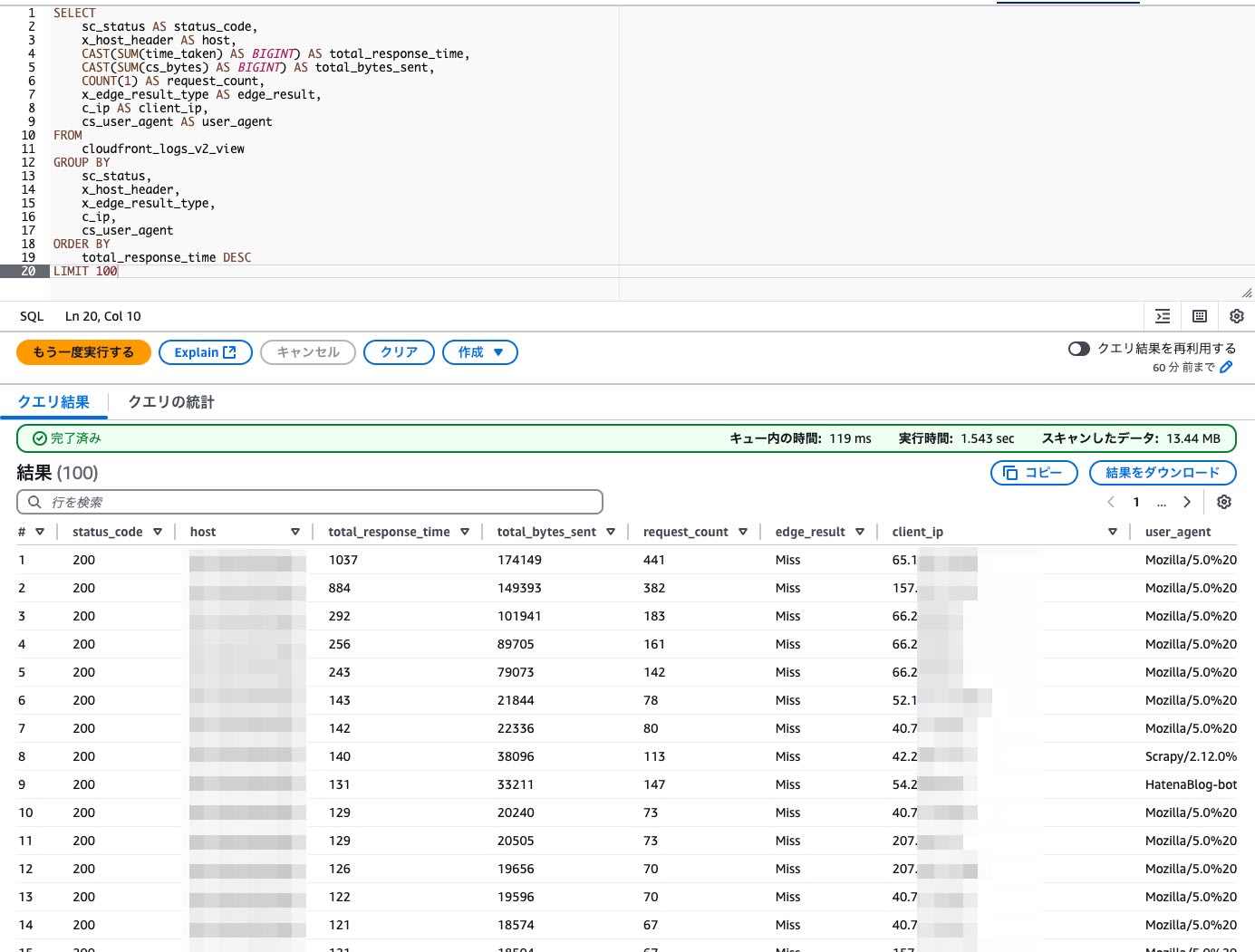
応答所要時間が多いアクセス元の抽出例
SELECT
sc_status AS status_code,
x_host_header AS host,
CAST(SUM(time_taken) AS BIGINT) AS total_response_time,
CAST(SUM(cs_bytes) AS BIGINT) AS total_bytes_sent,
COUNT(1) AS request_count,
x_edge_result_type AS edge_result,
c_ip AS client_ip,
cs_user_agent AS user_agent
FROM
cloudfront_logs_v2_view
GROUP BY
sc_status,
x_host_header,
x_edge_result_type,
c_ip,
cs_user_agent
ORDER BY
total_response_time DESC
LIMIT 100
まとめ
Athena、CloudWatch Logs Insight を利用して、JSON 形式で保存された CloudFront のアクセスログを確認できることを確認できました。
特に CloudWatch Logs Insight は ニアリアルタイムに使えるログ確認手段として、
発生直後の配信エラー、DoS、DDoS 影響などをアクセスログから調査する際などに、活用できると思われます。
CloudFront の標準ログ (v2) を利用される場合、ログ設定後、Vended Logs で発生するログ保存費用が意図した範囲である事。
また、ログ参照に Logs Insights 、Athenaを 利用する場合、それぞれ適切な期間指定などでスキャン費用に留意してご利用ください。
- Vended Logs料金 (USD 0.50/GB)
- Logs Insights クエリ料金 (USD 0.005/スキャンされたデータの GB)
- Atena SQL クエリ料金 (USD 5.00 per TB of data scanned)










