![[レポート]Coalesce on the road Tokyo KEYNOTE #dbtCoalesceTokyo](https://images.ctfassets.net/ct0aopd36mqt/wp-refcat-img-a0f70de29a00d596aa50512303131e72/2fcbfee571e6db80cd904c3c64f7cecc/dbt-1200x630-1.jpg?w=3840&fm=webp)
[レポート]Coalesce on the road Tokyo KEYNOTE #dbtCoalesceTokyo
かわばたです。
2025年12月11日に、「Coalesce on the road Tokyo」が開催されました。
本記事はセッション「KEYNOTE」のレポートブログとなります。
登壇者
- Clarke Patterson氏
- dbt Labs VP of Marketing
- Elias DeFaria氏
- dbt Labs Product Manager

Clarke Patterson氏よりOpening Keynote:Rewrite

Clarke Patterson氏がデータとAIを取り巻く現状の常識を「書き換える(Rewrite)」というテーマで、dbtのビジョンと技術革新について講演しました。
- テーマ:Rewrite

『抽象化レイヤー』の存在
**「データエコシステムには、さらに別の『抽象化レイヤー』が存在しうる」**というdbtの思想に興味を惹かれた。
ビジネスを支える様々な技術で使われているロジックを抽出し、標準化できる可能性を意味している。

オープンスタンダードの再構築
Fivetran社との合併
- 昨年10月13日、長年の素晴らしいパートナーであり、データ移動のリーダーであるFivetran社との合併を発表
- **「オープンデータインフラ(Open Data Infrastructure)」**という概念
- データアーキテクチャ全体に抽象化レイヤーを設け、組織のビジネスロジックやセマンティクスをすべて標準化するという考え方
- AIのためのコンテキストを効率的に収集・整理・提供できる


「オープンコンピュート」の重要性
- 「オープンコンピュート」という考え方が示すように、意図的にエコシステム全体と連携することを目指している
- コンピュートエンジンだけでなく、LLM、データカタログ、BIツールなど、皆さんが現在の投資や将来の投資を最大限に活用し、これらを簡単に組み合わせられるようにすること




オープンスタンダード
- SQL、MCP(MetricFlow)、ODBC、そして業界標準になりつつあるIcebergといったオープンスタンダードへの強いこだわりによって支えられている。この基盤があることで、変化への柔軟な対応が簡単になる。

ルールの再定義
dbt Fusionエンジンに関する内容

-
生産性の飛躍的向上:Fusionエンジンを標準体験として活用することで、開発者の生産性は大幅に向上。
-
コスト最適化:dbtはデータのモデリングや変換を深く理解しているため、不要なコストが発生しているパターンを見つけ出し、より効率的な方法を提案できる。
-
AI対応データのためのコンテキスト提供:組織がデータ定義を標準化し、そのコンテキストをすべてのAIアプリケーションに届けることで、より有意義な成果を生み出す役割を担う。

AIによる再定義
-
AIのためのコンテキストと自動化:すべてのAIアプリケーションにコンテキストを提供し、修正作業を自動化するツールを提供することで、皆さんの生産性を高め、組織に価値ある成果をもたらすことを目指す。

-
dbt Agentsと分析開発ライフサイクル:
私たちは「計画→分析→発見→変換→キュレーション→学習」という一連の「分析開発ライフサイクル」を可能な限り自動化したいと考えており、このワークフローを支援するために発表したのが「dbt Agents」です。

-
中心を担うFusion Engine:dbtは、データの出所、変換方法、そしてAIアプリケーションにとっての意味をすべて把握できるのです。その中心ですべてを支えているのがFusion エンジンで、生データを有意義なインサイトへと変換するためのコンテキストを提供します。

まとめ
今のデータの捉え方や扱い方にチャレンジしてほしい、データ分野は信じられないスピードで進化しており、働き方を見直す絶好の機会です。
注目したい観点は以下の3つ。
-
オープンスタンダードという考え方:Fivetranとの統合がもたらすアプローチにより、物事をより簡単かつ効率的に組み合わせ、変化に迅速に対応できるようになる。
-
開発ルールの見直し:生産性向上とコスト最適化を実現。
-
AIのためのコンテキスト:dbtを活用して日々の業務でデータをどう扱うかを考え、様々な業務の自動化を進める。

Elias DeFaria氏よりdbt Fusion エンジンによる次世代のデータ開発

Elias DeFaria氏がdbt Fusionエンジンについて、講演しました。

dbt Coreの現在地
- dbt Coreは、ソフトウェアエンジニアリングのベストプラクティスをデータの世界に持ち込み、データ変換の標準を確立した。
- その設計は約10年前のもので、AIがワークフローの一部となり、オープンテーブル形式が標準となるなど、データの世界は劇的に変化している。
- dbt Coreが提供したモジュラー性、バージョン管理、ドキュメント化といった機能は、今や業界の「当たり前」となり、より迅速で信頼性の高いデータ基盤が求められている。

dbt Fusion
-
dbtのエンジンを再構築したものが「dbt Fusion」
-
Fusionは、dbt Labsが買収したSDFのマルチダイアレクトSQLコンパイラ技術を基盤としている。

-
外側のレイヤー:SQL、YAML、設定ファイルなど、使い慣れたdbt言語はそのままで、ワークフローを学び直す必要はない。
-
内側のレイヤー:依存関係の構築、コードの処理、データベースでの実行を担う中心部分は、スケーラビリティに課題があったdbt Coreのものから完全に置き換えた。

Fusionは、高速かつ低遅延なコンパイル型言語である「Rust」で作り直されています。
3つの新しい概念
-
コンパイラ:実行時にエラーを検出するインタプリタ型言語(例: Python)から、実行前にコードの最適化やエラー検出が可能なコンパイル型言語(例: Rust)へ移行するような大きな変化。
-
高速性:Rustの採用により、PythonのGIL(グローバルインタプリタロック)に起因するパフォーマンスの制約から解放され、圧倒的な処理速度を実現。
-
ステートフル実行:Fusionは、過去の実行状態を記憶し、データやコードの変更点を把握し、不要なモデルの実行を自動的にスキップするなど、処理を最適化。

3つの価値
-
開発者体験の向上:プロジェクトのパースは最大30倍高速化。リアルタイムのコード検証、CTEプレビュー、カラムレベルのリネージといったインテリジェントな機能により、dbtでの開発がより速くなります。これらの体験は、VS Code拡張機能や新しいStudio IDEなど、あらゆる開発環境で利用可能。
-
コスト最適化:ステートフルな実行により、依存先に変更がないモデルやテストの実行をスキップ。カラムレベルで変更を認識するCI/CDにより、必要な処理だけを正確に実行し、コンピューティングリソースを節約。
-
AIとの連携強化:Fusionのメタデータは、モデルの依存関係、影響範囲、アクセス権限といった情報をAIシステムに提供し、信頼できるデータ活用の基盤となる。



Fusionを使ってライブで開発
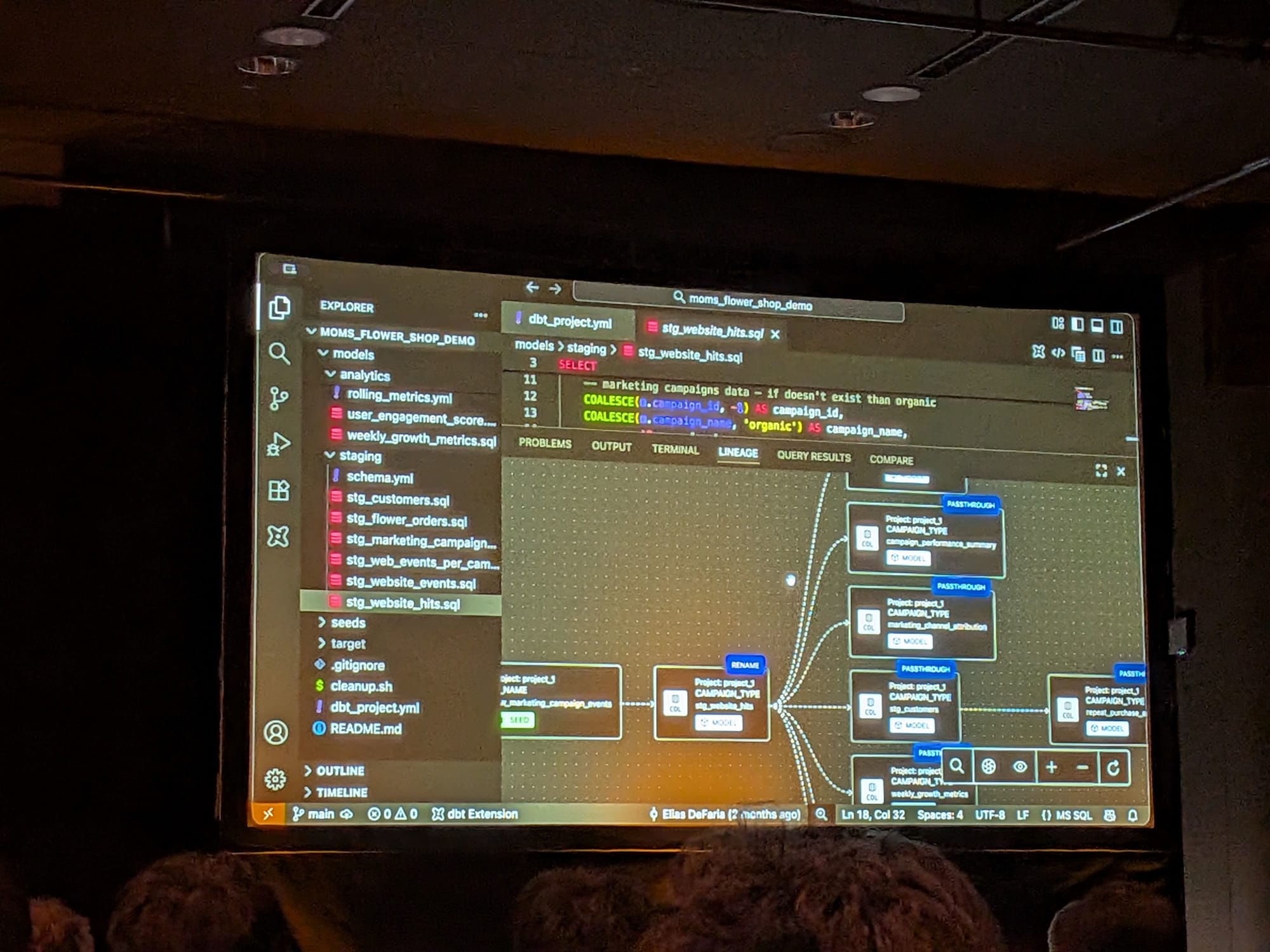
開発効率の向上
-
リネージの可視化:テーブルレベルやカラムレベルのリネージ(データの流れ)をVS Code上で直接、視覚的に確認可能。
-
モデルのプレビュー:ボタン一つでモデルが生成する結果をプレビューでき、タブを切り替える手間なく作業を継続できる。
-
SQLの深い理解:FusionはSQLを深く理解しているため、カラムが単なる「リネーム」なのか、データをそのまま流す「パススルー」なのか、あるいは新しい値を生成する「トランスフォーメーション」なのかを自動で判別し、ラベル付けしてくれる。
開発支援機能
-
リアルタイムのエラー検出:ウィンドウ関数を使って7日間のローリング注文数を計算する際、WHERE句でウィンドウ関数の結果をフィルタリングしようとすると、ウィンドウ関数の評価順序が誤っていることをFusionクエリを実際に実行する前に「エラー」として検知します。
-
SQLデバッガーのようなCTEプレビュー:特定のCTE(共通テーブル式)がどのようなデータを出力するか確認したい場合、FusionにはCTEを直接プレビューする機能があり、そのCTEの計算に必要な部分だけを実行して結果を表示できる。
-
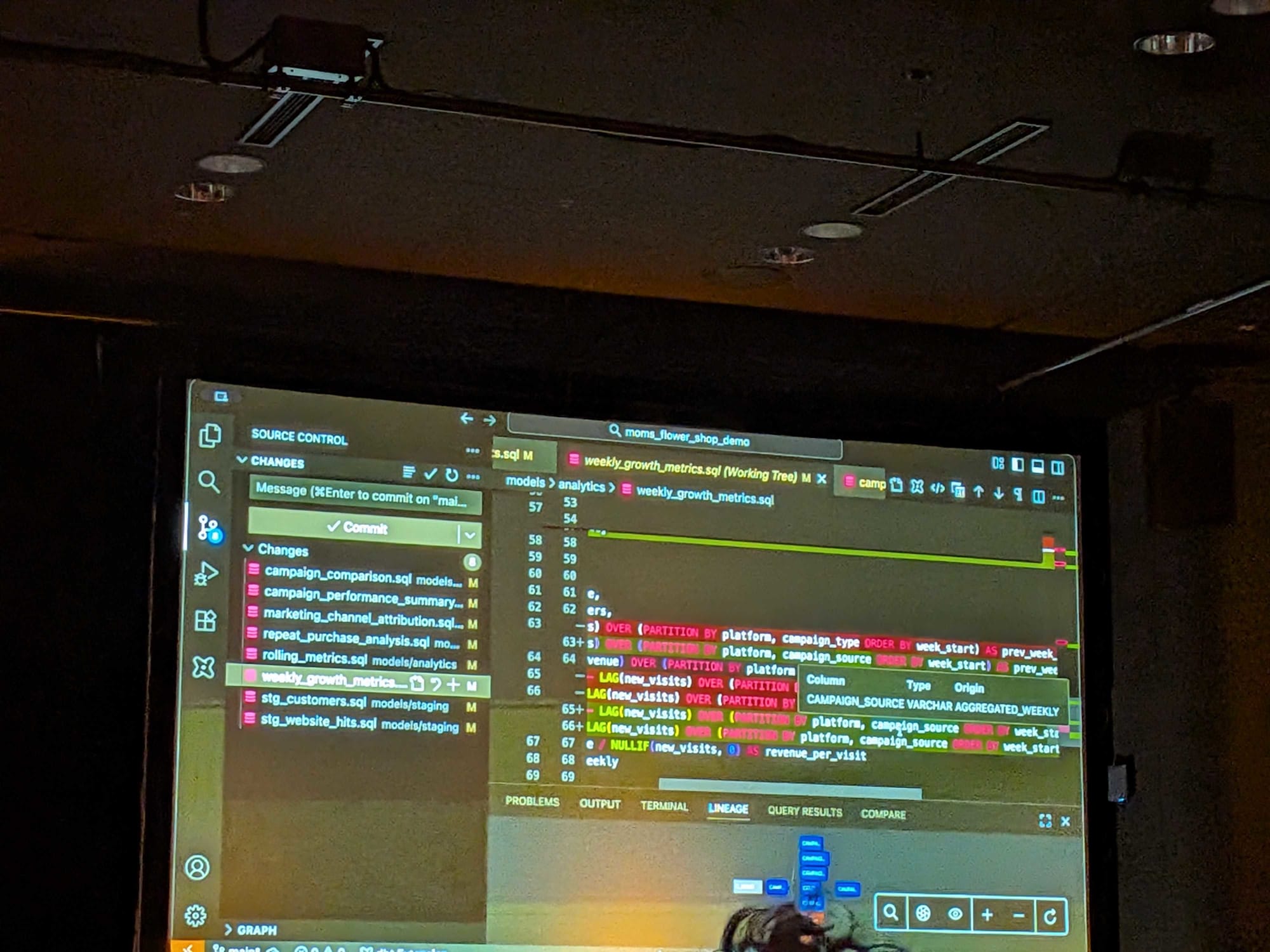
データ差分による影響確認:Fusionの「変更を比較」機能を使うと、そのコード変更がデータに与えた影響(例:2,184行、99.7%の行に影響)を具体的に示してくれます。どのレコードが削除され、どの値がどう変わったかを詳細に確認できる。

-
インパクト分析とリネーム伝播:あるカラムの名前を変更すると、Fusionはその変更によって影響を受ける下流のモデルを即座に検出し、ファイル一覧を赤くハイライトして「壊れる」ことを警告する。さらに、「リネーム伝播」機能を使えば、カラム名を変更するだけで、依存するすべての下流モデルのコードを自動で新しいカラム名に書き換えてくれる。
最後に
AIとdbtの関わりと、dbt Fusionエンジンの話がメインでした。
特にFivetran社との合併でどのようなシナジーが生まれるかは期待したい部分です。
dbt Fusionエンジンは期待できる機能がたくさんあるので提供が待ち遠しいですね。
この記事が何かの参考になれば幸いです!









