
PostgreSQL 18 の async I/O 性能を RDS で確認してみた(benckmark for io_method: sync vs worker )
TL;DR
- RDS PostgreSQL v18(db.m6g.large、2 vCPU、8GB RAM、scale 1000)で
io_method: syncとio_method: workerを比較したが、今回の環境では性能差はほぼ見られなかった(pgbench で約 1% の差) io_method: io_uringが最も効果的らしいが、RDS では利用不可(パラメータグループでAllowed values: sync, workerのみ)io_workersを増やしすぎると逆効果になる場合がある(今回の環境では 32 に増やしたら性能が 45% 悪化)- 今回のテストでは、EBS の IOPS を上げる(gp2 → gp3 で約 2 倍)や、キャッシュヒット率を高める方が性能改善に効果的だった
参考: pganalyze による詳細な性能差が出たテスト記事 Waiting for Postgres 18: Accelerating Disk Reads with Asynchronous I/O
はじめに
PostgreSQL 18 で asynchronous I/O が導入されて、読み取り性能が大幅に改善されるという話を聞いた。実際どうなのか、RDS で試してみることにした。
検証環境
RDS 設定
| 項目 | 設定値 |
|---|---|
| Engine version | PostgreSQL 18.1-R1 |
| Instance class | db.m6g.large(2 vCPU、8GB RAM) |
| EBS(初期) | gp2 40GB(ベースライン 120 IOPS) |
| EBS(後半) | gp3 400GB(12,000 IOPS、500 MB/s) |
| Region | ap-northeast-1(東京) |
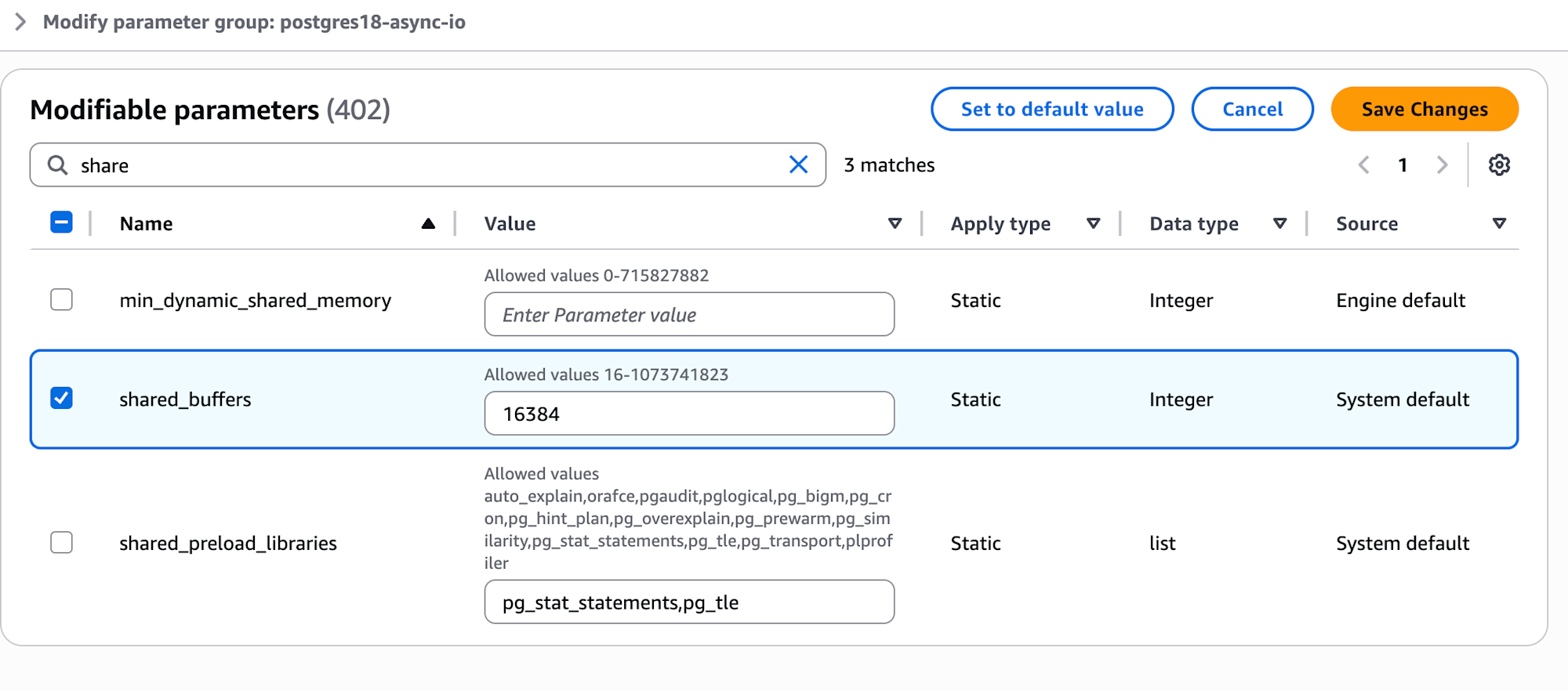
パラメータグループ
比較用に 2 つ作成:
- postgres18-sync:
io_method = sync、shared_buffers = 16384(128MB) - postgres18-worker:
io_method = worker、shared_buffers = 16384(128MB)
クライアント環境
ローカルコンテナ(Debian):
# PostgreSQL クライアントのインストール
sudo apt-get install postgresql-client-18
sudo apt-get install -y postgresql-contrib-18
# 確認
psql --version # psql (PostgreSQL) 18.1 (Debian 18.1-1.pgdg12+2)
pgbench --version # pgbench (PostgreSQL) 18.1 (Debian 18.1-1.pgdg12+2)
AWS CloudShell:
# PostgreSQL 17 のインストール(Amazon Linux 2023 では 18 がまだなかった)
sudo dnf remove -y postgresql15 postgresql15-private-libs
sudo dnf install -y postgresql17 postgresql17-contrib
# 確認
psql --version # PostgreSQL 17.7
pgbench --version # PostgreSQL 17.7
ベンチマークコマンド
各テストの前に RDS インスタンスを再起動してキャッシュをクリアした。
pgbench 初期化
# scale 1000 = 1億アカウント、約15GB
PGPASSWORD='<password>' pgbench -i -s 1000 \
-h <rds-endpoint>.rds.amazonaws.com \
-U <user> -d postgres
フルスキャンテスト用 SQL
cat > /tmp/full-scan-test.sql << 'EOF'
SELECT COUNT(*) FROM pgbench_accounts;
SELECT SUM(abalance) FROM pgbench_accounts;
SELECT aid % 1000 as bucket, COUNT(*), AVG(abalance) FROM pgbench_accounts GROUP BY bucket;
SELECT COUNT(*) FROM pgbench_accounts a CROSS JOIN pgbench_branches b WHERE a.bid = b.bid;
SELECT COUNT(*) FROM pgbench_accounts WHERE abalance > 0;
EOF
テスト実行
# フルスキャンテスト
PGPASSWORD='<password>' psql \
-h <rds-endpoint>.rds.amazonaws.com \
-U <user> -d postgres \
-c "\timing on" \
-f /tmp/full-scan-test.sql
# pgbench TPC-B(5分間、20クライアント)
PGPASSWORD='<password>' pgbench \
-h <rds-endpoint>.rds.amazonaws.com \
-U <user> -d postgres \
-c 20 -j 4 -T 300 -P 60
# キャッシュヒット率確認
PGPASSWORD='<password>' psql \
-h <rds-endpoint>.rds.amazonaws.com \
-U <user> -d postgres \
-c "SELECT relname, heap_blks_read as disk, heap_blks_hit as cache,
round(100.0 * heap_blks_hit / NULLIF(heap_blks_hit + heap_blks_read, 0), 2) as hit_ratio
FROM pg_statio_user_tables
WHERE relname LIKE 'pgbench%';"
テスト結果
ローカルコンテナからのテスト(概要)
まずはローカル環境から RDS(東京)に接続して pgbench を実行してみた。
| テスト | Scale | io_method | TPS | 備考 |
|---|---|---|---|---|
| Free tier (t4g.micro) | 50 | sync | 46.7 | ベースライン |
| Free tier (t4g.micro) | 50 | worker | 42.7 | -8.5%(CPU スロットリング) |
| m6g.large | 250 | sync | 130 | ベースライン |
| m6g.large | 250 | worker | 133 | +2.3% |
ネットワークレイテンシ(約 140ms)が大きすぎて、async I/O の効果が見えない。これでは比較にならないので、CloudShell に移動することにした。
CloudShell からのテスト(gp2、120 IOPS)
同一リージョンの CloudShell からテストを実施。ネットワークレイテンシは約 17ms まで改善。
| テスト | Scale | io_method | TPS | レイテンシ |
|---|---|---|---|---|
| CloudShell | 250 | sync | 1,206 | 16.58ms |
| CloudShell | 250 | worker | 1,190 | 16.80ms |
| CloudShell | 1000 | sync | 837 | 23.88ms |
| CloudShell | 1000 | worker | 838 | 23.87ms |
TPS は大幅に改善したが、sync と worker の差はほぼゼロ。gp2 のベースライン IOPS(120)がボトルネックになっているのでは?と考え、EBS を変更してみることにした。
CloudShell からのテスト(gp3、12,000 IOPS)
EBS を gp3(400GB、12,000 IOPS、500 MB/s)に変更して再テスト。これが今回の本番テスト。
フルスキャン結果
| クエリ | sync | worker | 差分 |
|---|---|---|---|
| COUNT(*) | 98.0s | 82.6s | -16% |
| SUM() | 26.9s | 25.9s | -4% |
| GROUP BY | 33.4s | 40.4s | +21% |
| CROSS JOIN | 24.6s | 24.7s | ~0% |
| WHERE | 24.7s | 25.0s | +1% |
※ COUNT(*) は再起動直後のコールドキャッシュ状態での比較
結果はまちまち。COUNT(*) では 16% 改善したが、GROUP BY では逆に 21% 悪化した。
pgbench TPC-B 結果(5 分間、20 クライアント)
| メトリクス | sync | worker | 差分 |
|---|---|---|---|
| TPS | 1,660 | 1,679 | +1% |
| レイテンシ | 12.04ms | 11.91ms | -1% |
| 標準偏差 | 7.06ms | 7.67ms | +9% |
pgbench では約 1% の改善。誤差の範囲と言っていいレベル。
キャッシュヒット率
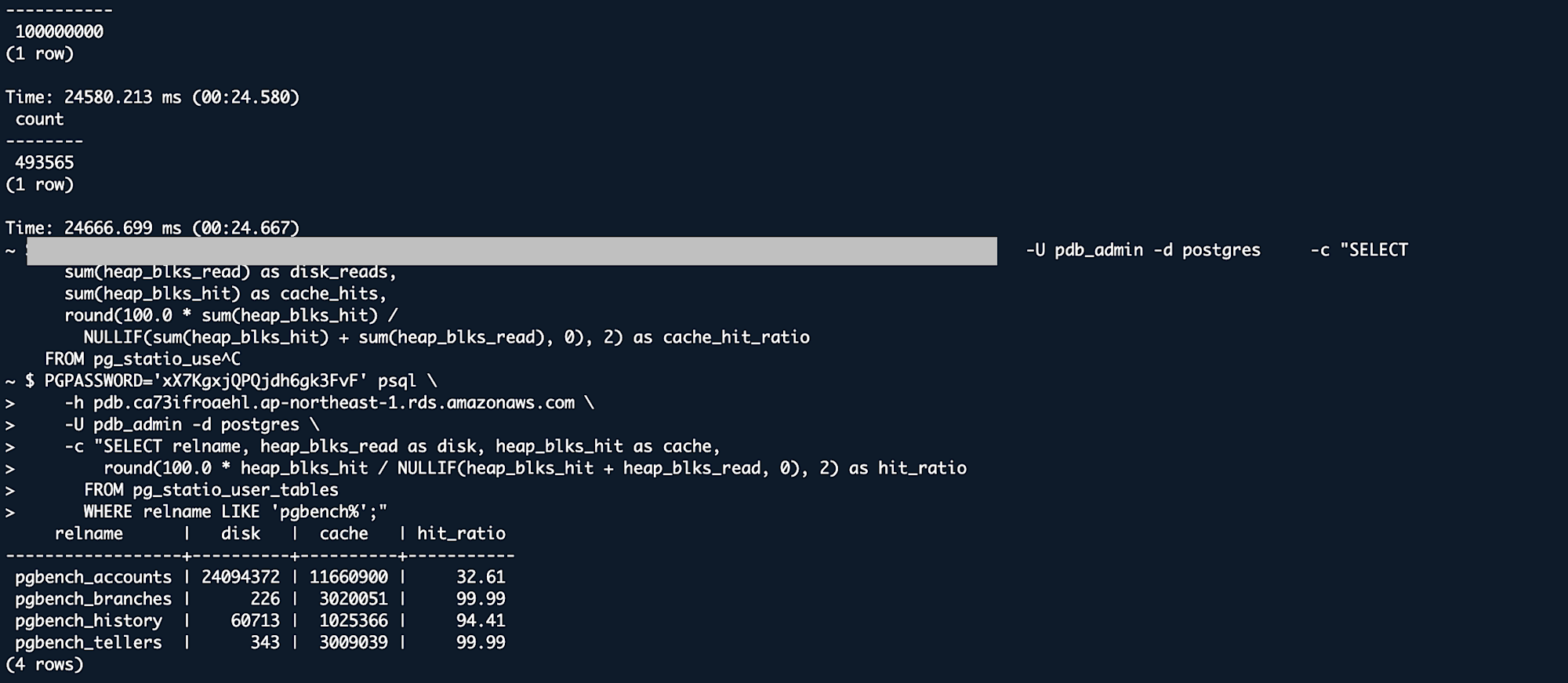
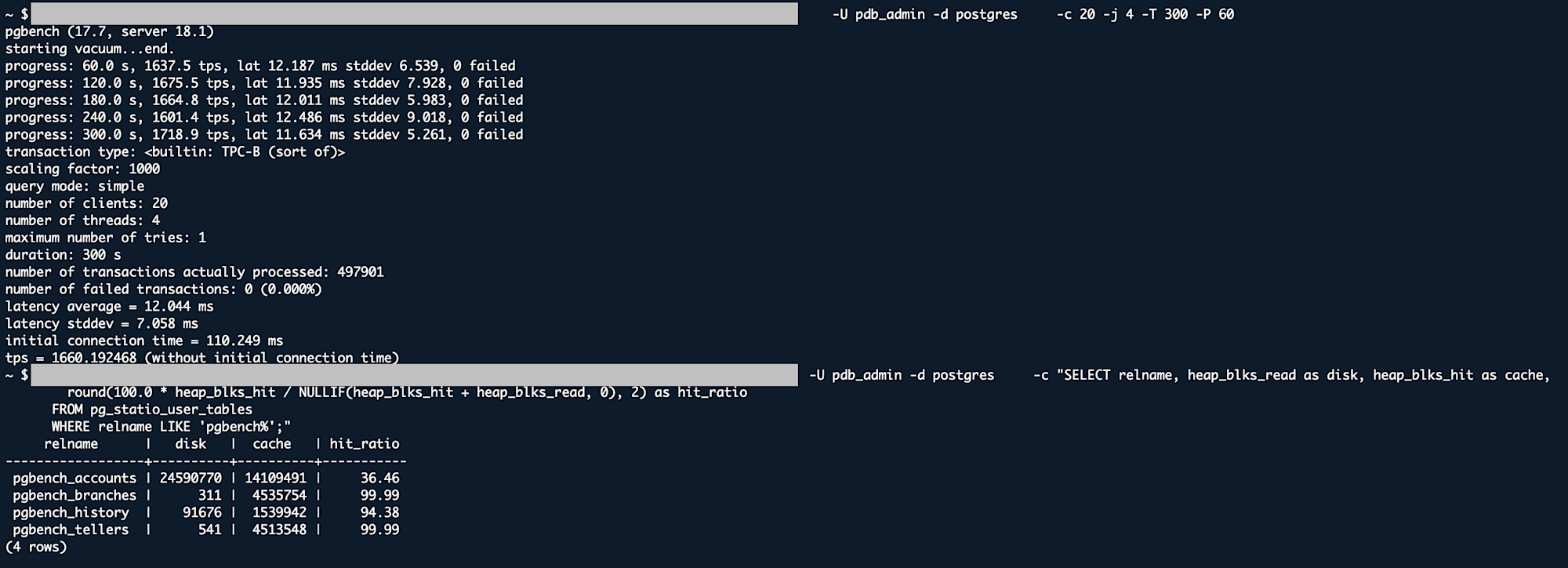
| テーブル | sync | worker |
|---|---|---|
| pgbench_accounts | 32.61% | 34.64% |
| pgbench_branches | 99.99% | 99.99% |
| pgbench_history | 94.41% | 94.38% |
| pgbench_tellers | 99.99% | 99.99% |
12,000 IOPS に上げても、sync と worker の差は pgbench で約 1%、フルスキャンでは結果がバラバラだった。
io_workers=32 の実験(やらなきゃよかった)
「io_workers を増やせば効果が出るのでは?」と思い、デフォルトの 3 から 32 に増やしてみた。
結果
| メトリクス | io_workers=3 | io_workers=32 | 差分 |
|---|---|---|---|
| TPS | 838 | 460 | -45% |
| レイテンシ | 23.87ms | 43.37ms | +82% |
逆効果。しかも途中で性能が崩壊した。
時間経過での変化(gp2 環境)
経過時間:
├─ 1-2分目: 843-866 TPS ← 正常
├─ 3分目: 574 TPS ← 低下開始
├─ 4分目: 13 TPS ← 崩壊(1509ms レイテンシ)
└─ 5分目: 13 TPS ← 継続(1546ms レイテンシ)
gp2 のバーストクレジットが約 3 分で枯渇して、ベースライン(120 IOPS)に落ちたのが原因だと思われる。32 ワーカーが一斉にストレージにアクセスして大渋滞。
教訓: 今回の環境(2 vCPU、gp2 120 IOPS)では io_workers を増やしても効果がなく、むしろ悪化した。インスタンスのリソースやストレージ性能に見合った設定が必要そう。
EBS ストレージの影響
今回のテストで一番性能差が出たのは、io_method の変更ではなく、EBS タイプの変更だった。
| 項目 | gp2 (40GB) | gp3 (400GB) | 差分 |
|---|---|---|---|
| ベースライン IOPS | 120 | 12,000 | 100 倍 |
| pgbench TPS | 837 | 1,679 | +100%(2 倍) |
| フルスキャン | ~99s | ~25s | -75%(4 倍速) |
io_method の変更で 1% 改善を頑張るより、gp3 に変えた方が圧倒的に効果的だった。
また、キャッシュヒット率を見ると、pgbench_branches や pgbench_tellers は 99.99% のキャッシュヒット率を示しており、頻繁にアクセスされるデータはキャッシュから読まれている。適切な shared_buffers 設定でキャッシュを活用することも性能に大きく影響する。
なぜ RDS で async I/O の効果が出ないのか
正直なところ、完全には分からない。ただ、いくつか思い当たる点はある。
io_uring が使えない
RDS のパラメータグループを見ると、io_method の選択肢は sync と worker のみ。io_uring は選べない。pganalyze の記事を読むと、大きな改善効果が出ているのは io_uring モードのようで、worker モードの改善は限定的っぽい。
すでに十分最適化されている?
PostgreSQL 自体のシーケンシャルスキャンや、AWS EBS のパフォーマンスが、すでにある程度最適化されているのかもしれない。改善の余地が少ない状態では、async I/O を入れても効果が出にくい。
まとめ
今回実際にテストして確認できたこと(db.m6g.large、scale 1000 環境):
| 変更内容 | 実測での性能変化 |
|---|---|
| gp2 → gp3(IOPS 100 倍) | +100%(2 倍) |
| io_method: sync → worker | +1% |
| io_workers: 3 → 32 | -45%(悪化) |
感想
- 今回の環境では、io_method の変更よりも、ストレージの IOPS やキャッシュヒット率の方が性能に影響していた
- io_workers を増やす場合は、インスタンスのリソース(CPU、メモリ)やストレージ性能とのバランスを考慮する必要がある。今回の環境では増やしても逆効果だった
- async I/O の「3 倍速」みたいな話は、io_uring が使える環境の話のようで、RDS の
workerモードではそこまでの効果は見られなかった
他の環境(より大きなインスタンス、io_uring 対応環境など)では異なる結果になる可能性はある。
以上











