
Athena パーティション射影を設定してみた
Athena のパーティション射影がどんなものなのかわからなかったため、触ってみようと思います。
なお、Athena パーティションってそもそも何?という方は、下記ブログをご参照ください。
パーティション射影(Partition Projection)とは
パーティション射影とは、Athena のパーティションを動的に認識してくれる機能です。
例えば以下のように月毎にフォルダ分けされている S3 があるとします。
s3://<バケット名>/2025/06/sample_data_1.csv
s3://<バケット名>/2025/06/sample_data_2.csv
s3://<バケット名>/2025/07/sample_data_3.csv
s3://<バケット名>/2025/08/sample_data_4.csv
上記のような S3 に対し、Athena パーティションを追加するには、ALTER TABLE ADD PARTITION クエリを発行し、以下のように 「S3 の 〜 のパスは Athena の 〜 のパーティションに対応します」 と、手動で追加していく必要があります。
ALTER TABLE <テーブル名> ADD PARTITION (year='2025',month='06') location 's3://<バケット名>/2025/06/';
上記のように S3 のフォルダが 3 つに分けられている(06, 07, 08)場合は、3回 ALTER TABLE ADD PARTITION をしないといけません。
ALTER TABLE <テーブル名> ADD PARTITION (year='2025',month='06') location 's3://<バケット名>/2025/06/';
ALTER TABLE <テーブル名> ADD PARTITION (year='2025',month='07') location 's3://<バケット名>/2025/07/';
ALTER TABLE <テーブル名> ADD PARTITION (year='2025',month='08') location 's3://<バケット名>/2025/08/';
一方で、この方法では S3 のフォルダ分けが 1000, 2000 と増えていくと現実的ではありません。
このような手動追加では厳しい状況に対し、パーティション射影の機能を用いる事で、正規表現(のような指定方法)を使ってパーティションを自動認識させる事ができます。
今回は以下検証で実際に設定し、それを確かめようと思います。
S3 の設定
デフォルト設定で S3 バケットを作成します。
以下 3 つのサンプルデータを準備します。
TeamID,prefecture,point
TEAM_A,okinawa,100
TEAM_B,tokyo,200
TeamID,prefecture,point
TEAM_C,okinawa,300
TEAM_D,tokyo,400
TeamID,prefecture,point
TEAM_E,okinawa,500
TEAM_F,tokyo,600
S3 バケットを年と月でフォルダ分けし、上記サンプルデータを以下のパスでアップロードしておきます。
s3://<バケット名>/2025/06/sample_data_1.csv
s3://<バケット名>/2025/06/sample_data_2.csv
s3://<バケット名>/2025/07/sample_data_3.csv
Athena テーブル作成
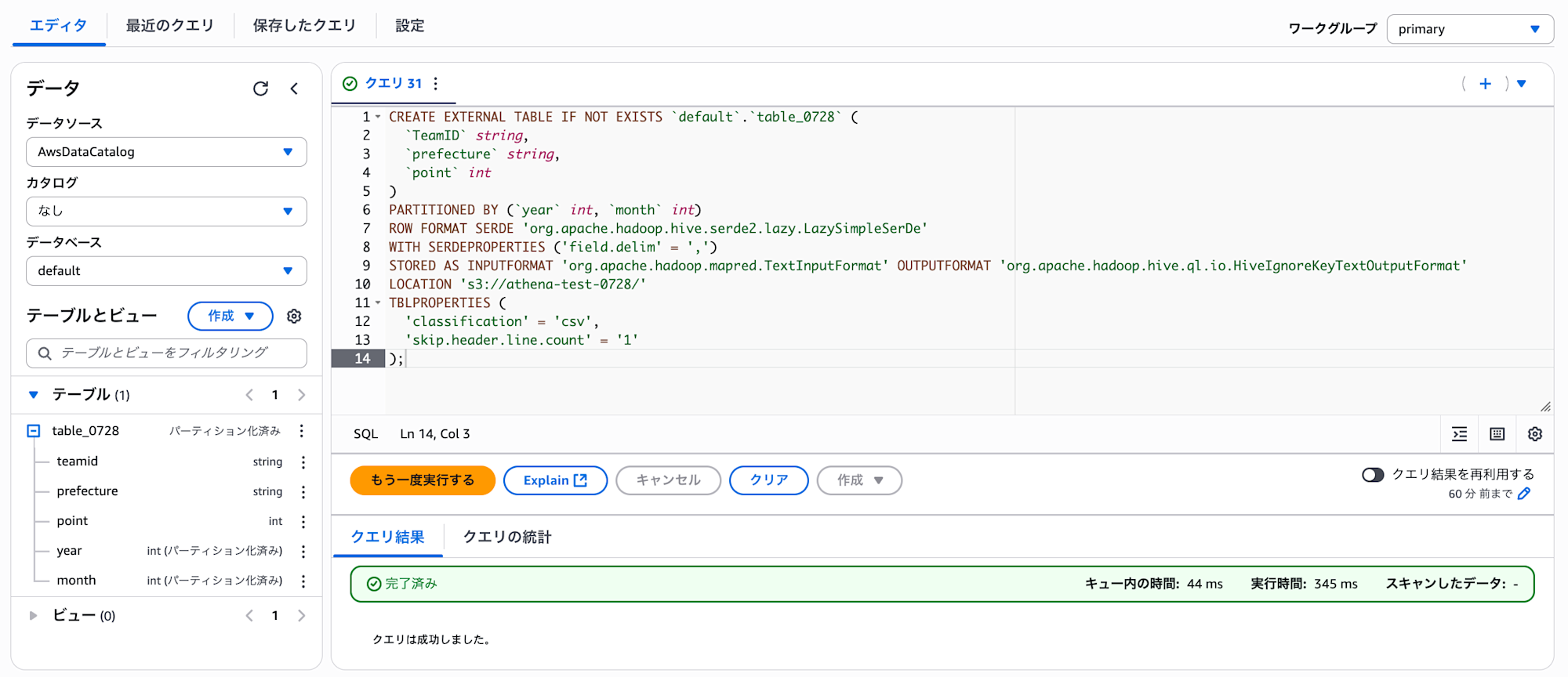
Athena にて CREATE TABLE を実行します。
本クエリは、Athena の default データベースにテーブル table_0728 を作成するスクリプトになります。
LOCATION 句 には前項で作成済みの S3 バケット(athena-test-0728) を指定しています。
また、year と month の 2 つのカラムをパーティションカラムとして設定しています。
CREATE EXTERNAL TABLE IF NOT EXISTS `default`.`table_0728` (
`TeamID` string,
`prefecture` string,
`point` int
)
PARTITIONED BY (`year` int, `month` int)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ('field.delim' = ',')
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://athena-test-0728/'
TBLPROPERTIES (
'classification' = 'csv',
'skip.header.line.count' = '1'
);
上記クエリを実行後、default データベースに table_0728 が作成されていることが確認できました。
現在の状態では、まだ S3 フォルダ毎の絞り込み検索は行えません。以下画像のようにクエリ結果が 0 件となります。
select * from table_0728 where year=2025 AND month=07;
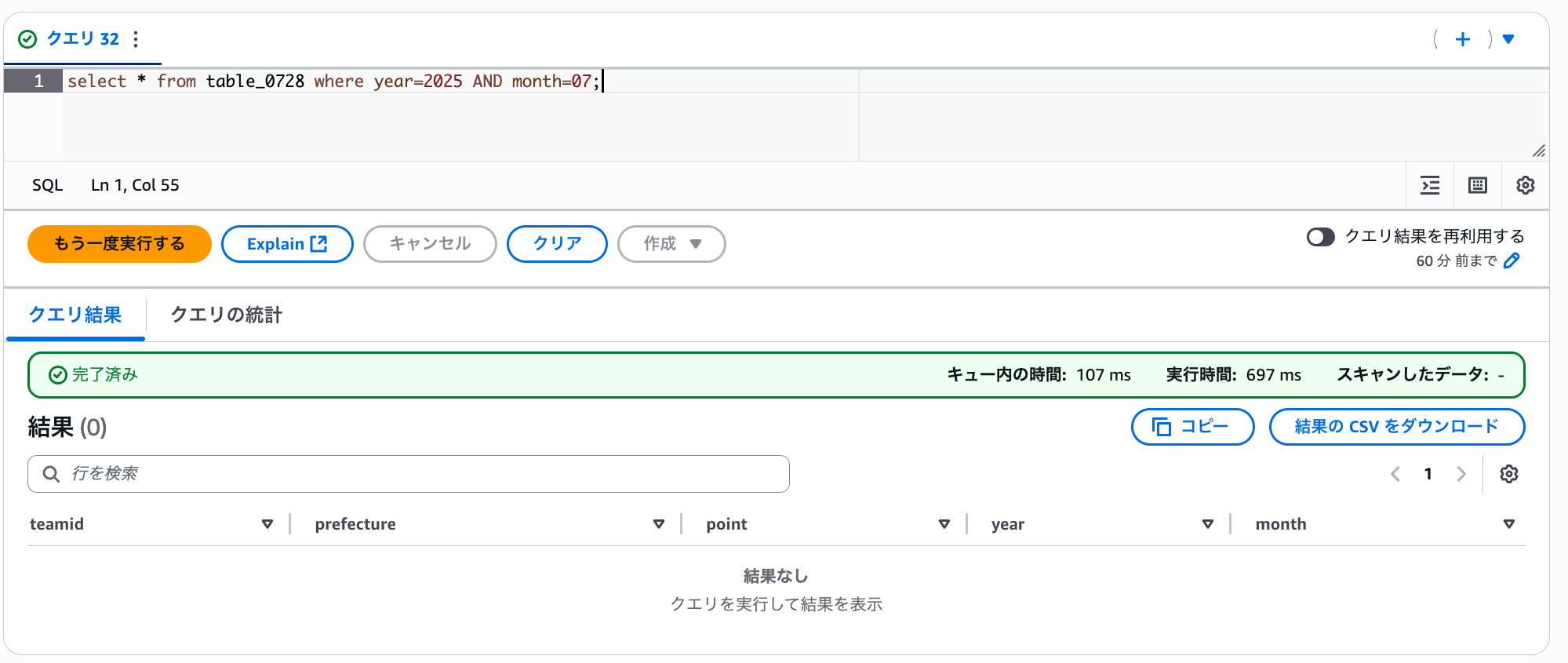
クエリ成功しても結果が 0 件となり検索できていないことがわかる
パーティション射影を追加
作成した Athena テーブル table_0728 にパーティション射影を設定していきます。
設定手順は以下ドキュメントを参考にやっていきます。
テーブル右横にある 3 点リーダーから「Glue で表示」を選択。
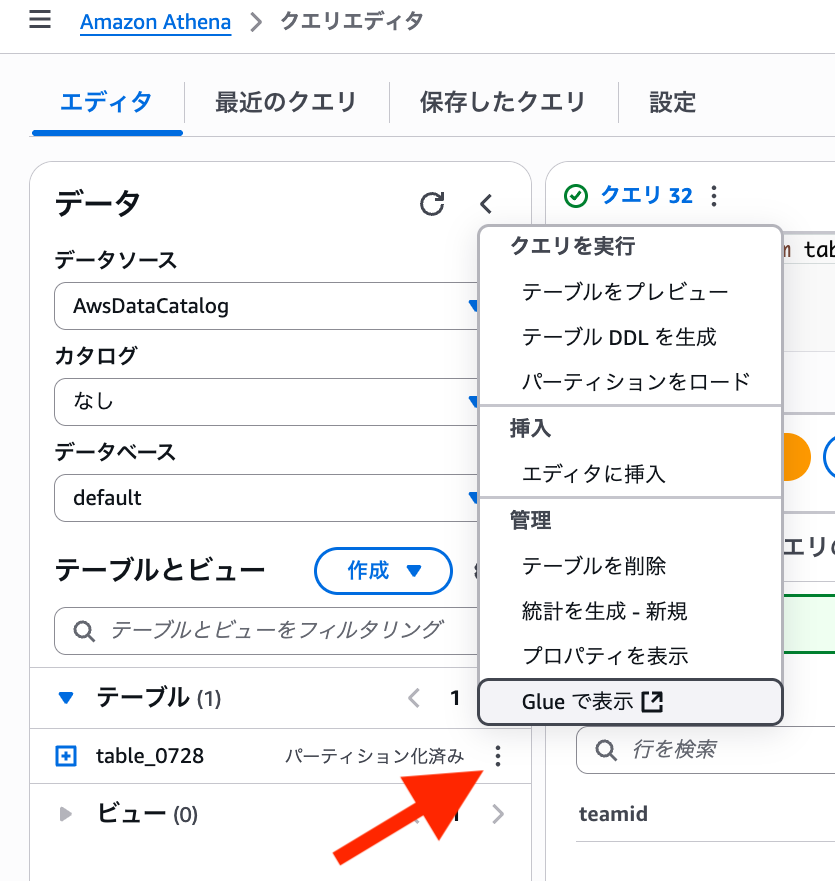
右上の Action から Edit table を選択。
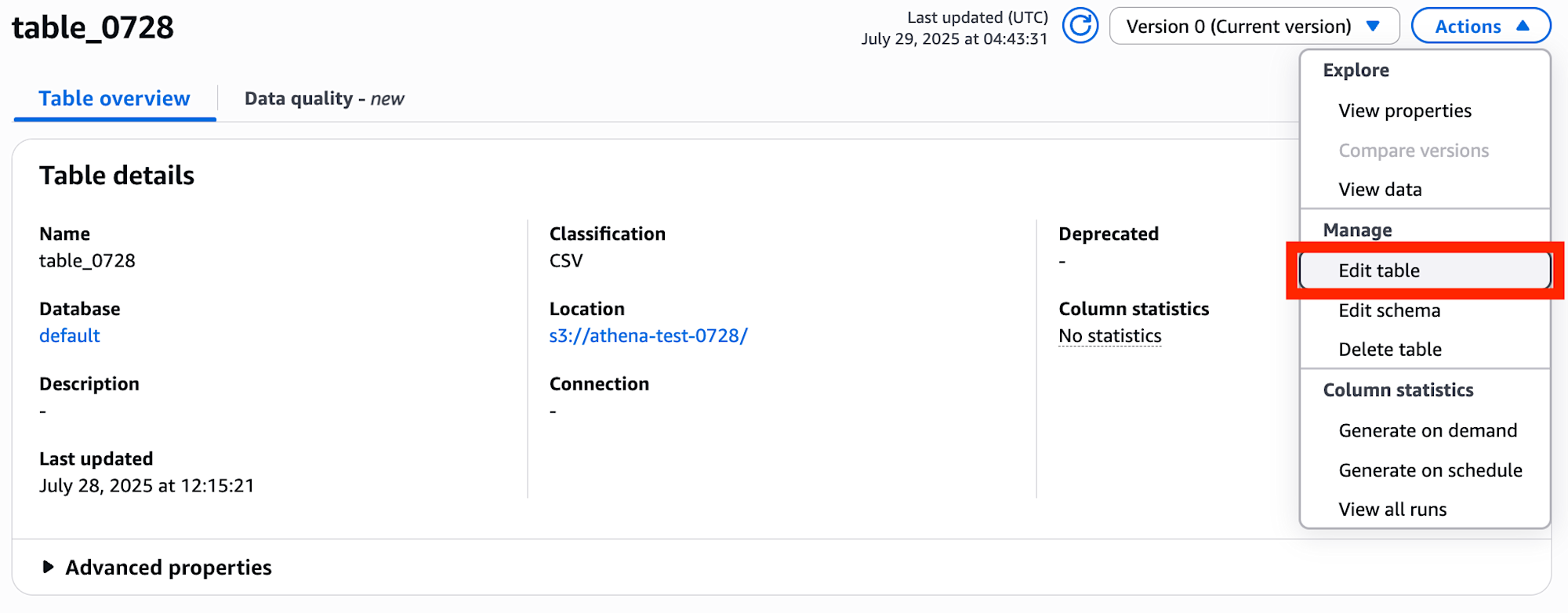
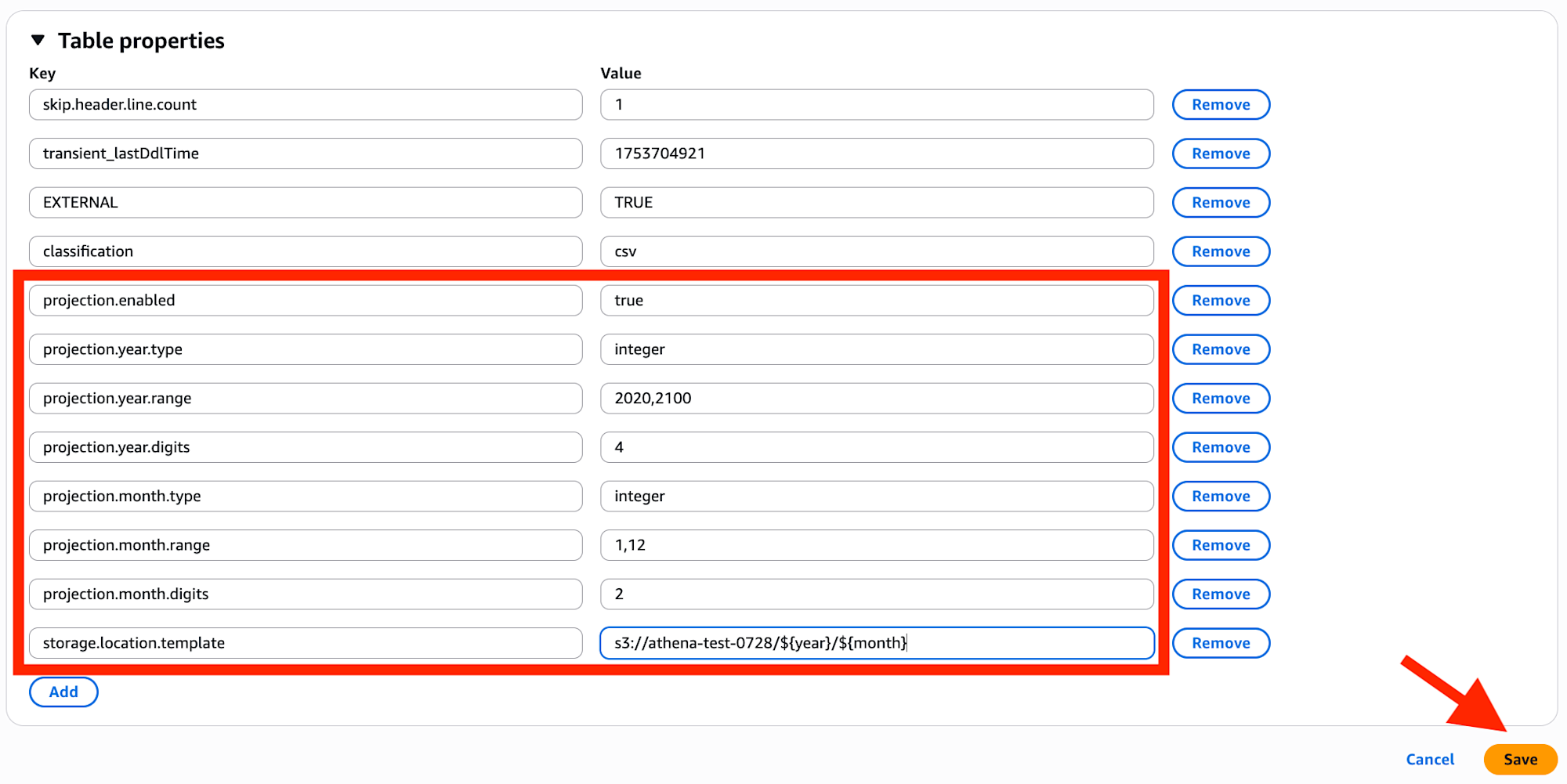
Table properties 項目にて、テーブル table_0728 のパーティションカラム(year と month) に対して射影を設定します。
以下の項目をコンソールにて設定後、Save します。
projection.enabled=true
projection.year.type=integer
projection.year.range=2020,2100
projection.year.digits=4
projection.month.type=integer
projection.month.range=1,12
projection.month.digits=2
storage.location.template=s3://<バケット名>/${year}/${month}
各項目の説明
- projection.enabled - パーティション射影の有効/無効を切り替える
- projection.<columnName>.type - カラムの型指定。今回は整数型にしたが、他にも日付型などがある。詳細はドキュメントを参照
- projection.<columnName>.range - パーティションカラムの範囲。今回は2020年から2100年までを指定している。そのため、S3 のフォルダに 2101 のようなものを作るとそこはパーティションとして認識されない(後述の動作確認を参照)
- projection.<columnName>.digits - カラムの桁数。例えば今回は月のフォルダを 06,07 と2桁で分けているので、month カラムの桁数には 2 を設定した。
- storage.location.template - Atena パーティションに対応する S3 パス。今回は S3 フォルダを "バケット名/<year>/<month>" のように分けているので、その形式で指定した。
なお、上記の各項目のより詳細な内容については、以下公式ドキュメントをご確認ください。
動作確認
それではパーティション射影が設定できたので、先ほどできなかった絞り込み検索によるデータ取得を試してみます。
以下のクエリを実行します。
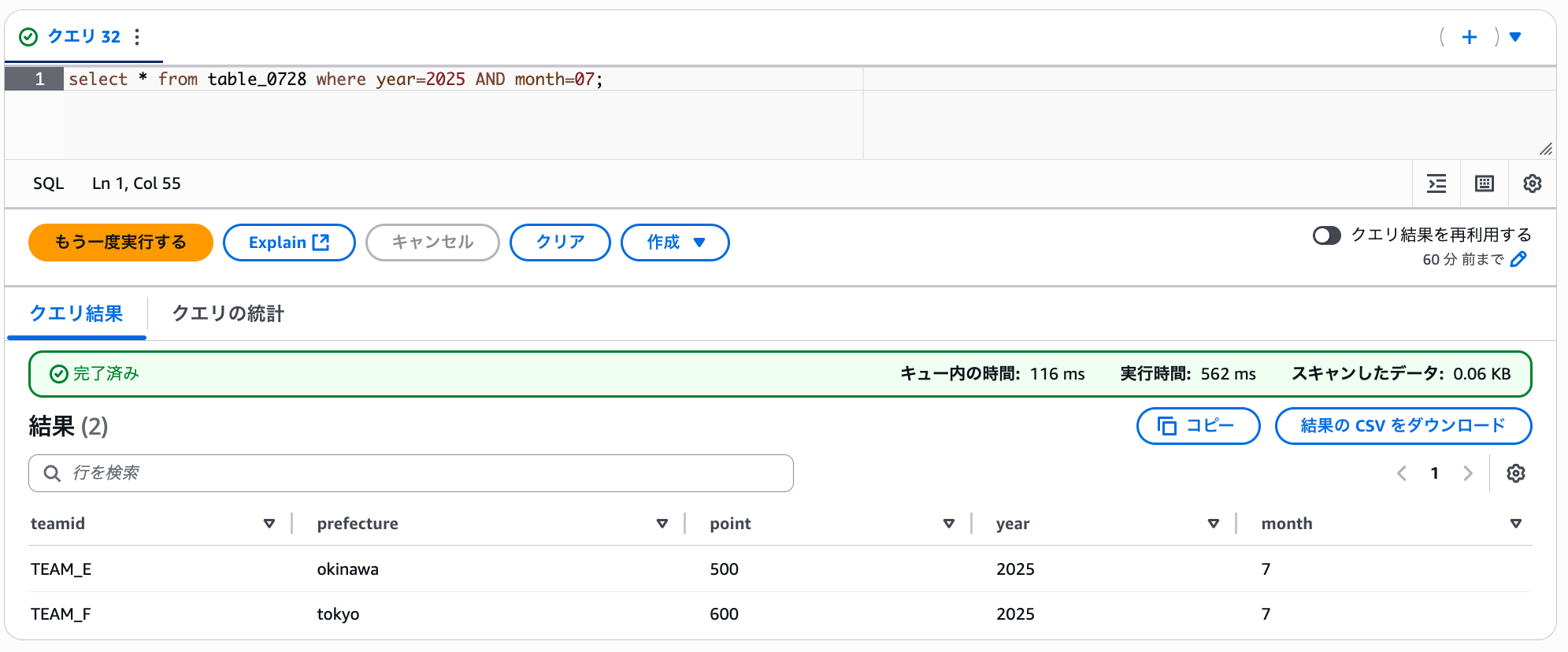
select * from table_0728 where year=2025 AND month=07;
無事結果が取得できました。sample_data_3.csv のレコードが 2 件返ってきていることがわかります。
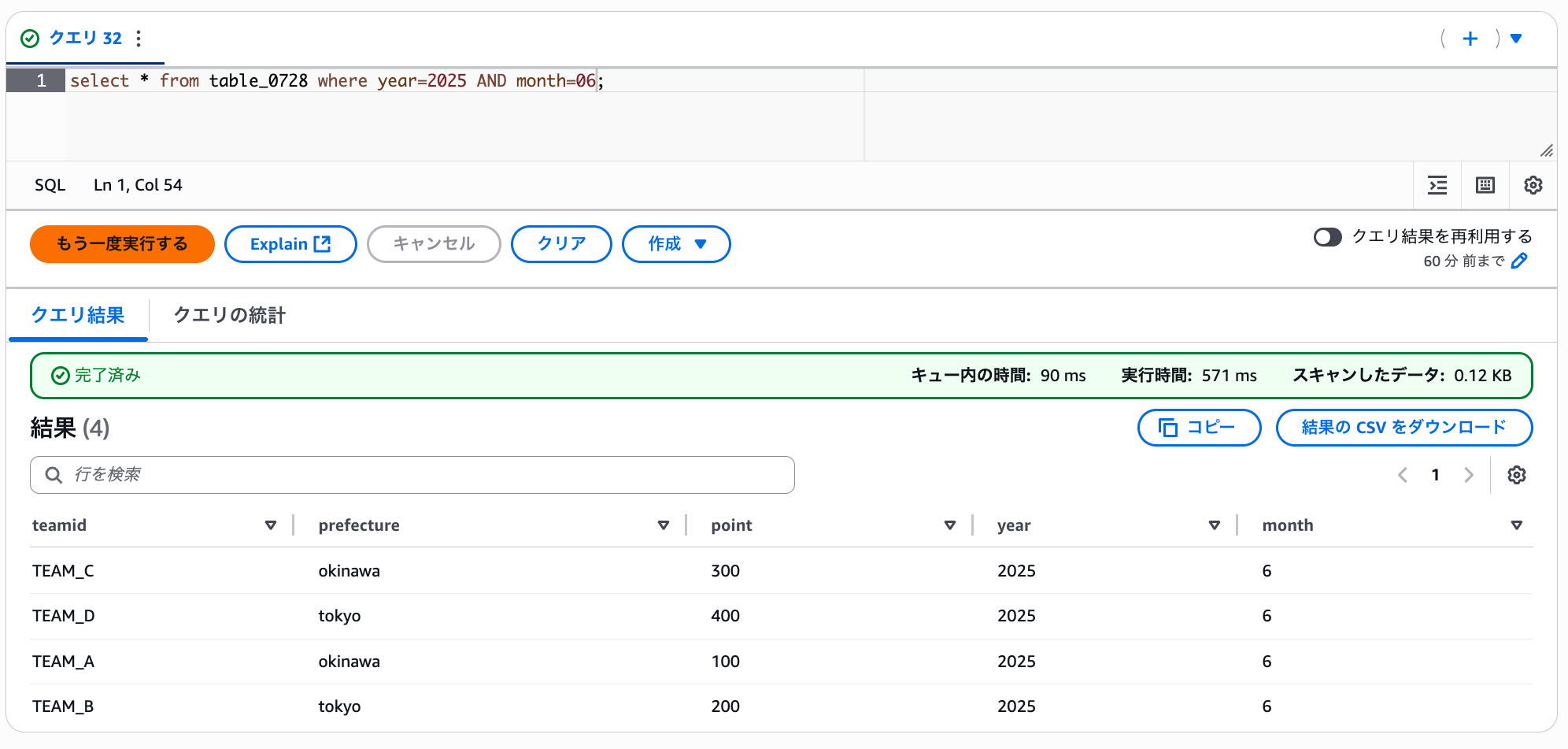
6 月のフォルダもクエリしてみます。こちらもきちんと sample_data1 と 2 の合計 4 レコードを取得できました。
select * from table_0728 where year=2025 AND month=06;
S3 に新たに "08" のフォルダを追加し、サンプルデータ sample_data_4.csv をアップロードし、そちらを絞り込み検索できるか試してみます。これで検索できれば、パーティションが自動で認識されていることになります。
s3://<バケット名>/2025/08/sample_data_4.csv
TeamID,prefecture,point
TEAM_G,okinawa,700
TEAM_H,tokyo,800
Athena から以下クエリを実行します。
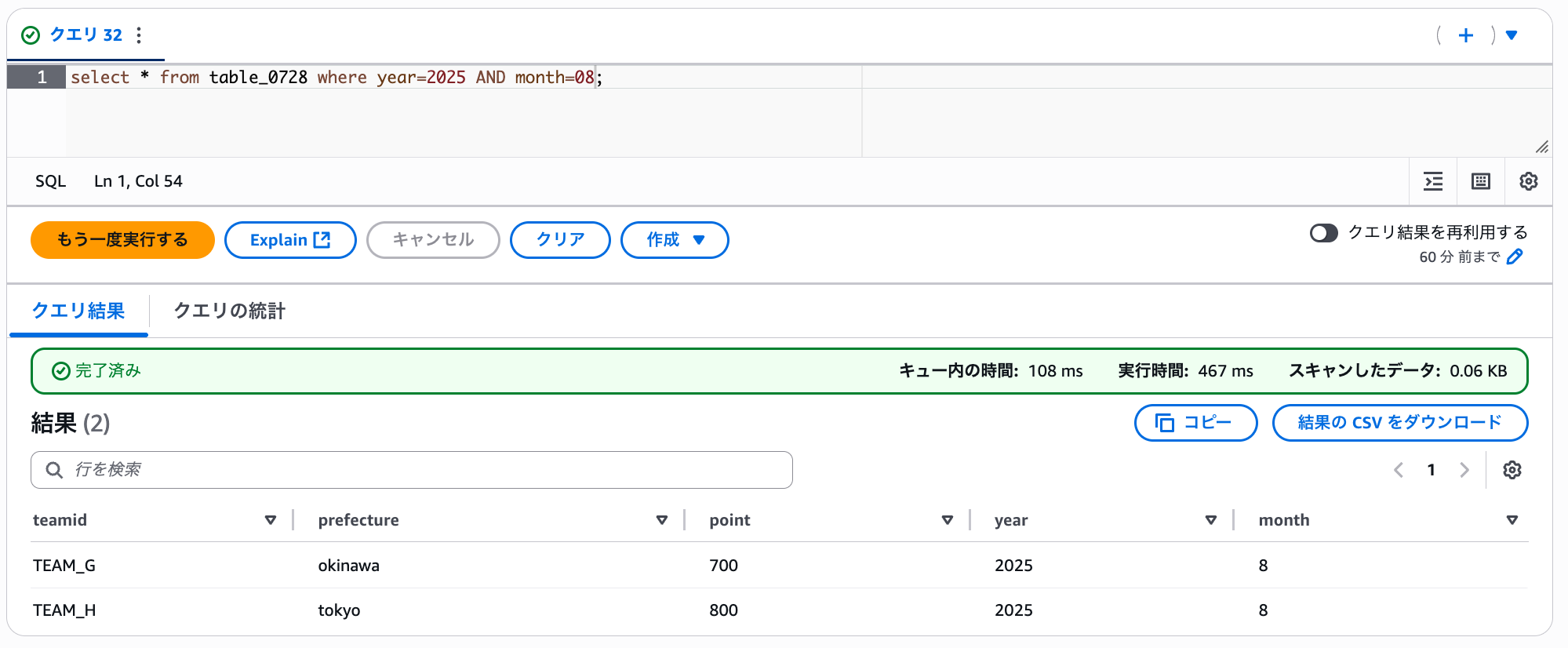
select * from table_0728 where year=2025 AND month=08;
その結果、以下の通り 8 月のデータがきちんと取得できました。
以上のことより、新たに追加したフォルダにも ALTER TABLE ADD PARTITION をしなくても、しっかりとパーティション設定が反映されていることがわかります。
最後に、year が 2101 のフォルダを追加してこちらもクエリできるかやってみます。
S3パスに以下のように追加しました。
s3://<バケット名>/2101/01/sample_data_1.csv
以下クエリを実行。
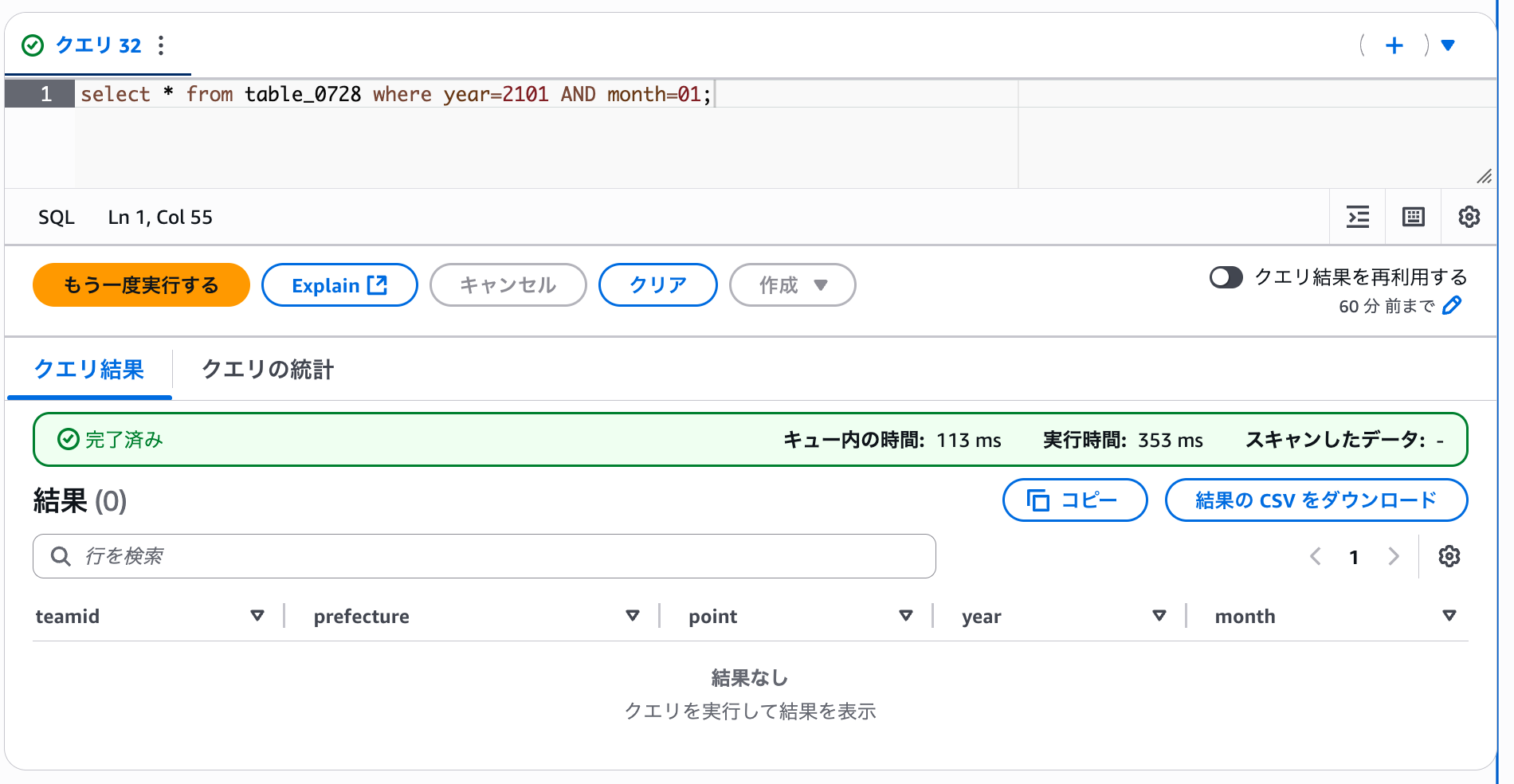
select * from table_0728 where year=2101 AND month=01;
こちらは結果が取得できませんでした。前項で projection.year.range を 2020〜2100 までとしているため、こちらの結果は想定通りです。ちゃんとパーティション射影が反映されていますね。以上で検証は終わりです。
終わりに
今回は Athena のパーティション射影を実際に設定してみました。過去にもたくさんの弊社ブログで紹介されている機能ではありますが、手を動かしてやってみることで、より理解が深まりました。
パーティション射影を使うことで、ALTER TABLE ADD PARTITION を手動で設定しなくてもパーティションによる絞り込み検索が行えるとのことで、とても便利な機能だと思いました。
本記事がどなたかのお役に立てば幸いです。
参考情報








