
Aurora PostgreSQL Serverlessエクスプレス設定にLambdaからDrizzle ORMで接続してみた
先日、Aurora PostgreSQL Serverless エクスプレス設定(以下、Aurora Expressと呼びます)に Drizzle ORM で接続する記事を書きました。
記事の最後に「次はAWS Lambdaから使えるかも試してみたいです」と書いていたので、実際に試してみました。
結論から言うと、Lambda からも問題なく接続できました。ただし、Lambda の実行モデルに合わせた調整がいくつか必要でしたので、前回との差分を中心に解説します。
最初に結論
- Lambda からも Aurora Express に IAM 認証で接続できる
hono/aws-lambdaアダプターで Hono を Lambda ハンドラーとして動かせる- Lambda の実行モデルに合わせて 接続数を 1 に制限し、接続タイムアウトを設定する
- IAM 認証トークンのキャッシュはウォームスタート時に有効なため、無駄な API 呼び出しを抑制できる
今回作るもの
前回作った Hono + Drizzle ORM のサンプルを Lambda で動かします。API Gateway HTTP API(v2)経由でリクエストを受け付けます。
AWS構成はこんな感じです。
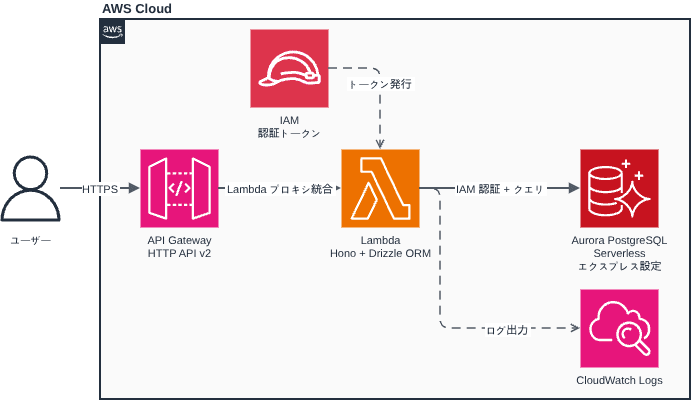
インフラのプロビジョニングには Terraform を使用します。
サンプルコード全体は前回と同じリポジトリの lambda ブランチで公開しています。
ディレクトリ構成は以下の通りです。前回から追加・変更したファイルに (変更) / (追加) と記載しています。
.
├── src/
│ ├── db/
│ │ ├── index.ts # DB接続設定(変更)
│ │ └── schema.ts # スキーマ定義(変更なし)
│ ├── app.ts # Honoルート定義
│ ├── index.ts # Lambda ハンドラーエントリーポイント(変更)
│ ├── local.ts # ローカル開発用エントリーポイント(追加)
│ └── logger.ts # ロガー設定(変更なし)
├── scripts/
│ ├── migrate.sh # マイグレーション用スクリプト(変更なし)
│ ├── package.sh # Lambda デプロイパッケージ作成スクリプト(追加)
│ └── psql.sh # psql 接続用スクリプト(追加)
├── terraform/
│ ├── main.tf
│ ├── lambda.tf # Lambda関数定義(追加)
│ ├── api_gateway.tf # API Gateway HTTP API(追加)
│ ├── iam.tf # IAMロール・ポリシー(追加)
│ ├── variables.tf
│ └── outputs.tf
├── drizzle.config.ts
├── .env.example
└── package.json
実装のポイント
前回との差分を中心に解説します。
エントリーポイントの分割(src/index.ts / src/local.ts)
前回は src/index.ts がローカル開発用のサーバー起動処理を兼ねていました。Lambda では起動方法が異なるため、エントリーポイントを 2 つに分けました。
Lambda 用(src/index.ts)
// Lambda ハンドラーエントリーポイント。
// API Gateway(v1 REST API / v2 HTTP API)からのイベントを Hono アプリに渡す。
// Lambda は環境変数をネイティブに提供するため dotenv は不要。
import { handle } from 'hono/aws-lambda';
import app from './app.js';
export const handler = handle(app);
hono/aws-lambda の handle() 関数が、API Gateway のイベント形式を Hono が処理できる形に変換してくれます。v1(REST API)、v2(HTTP API)どちらにも対応しています。
ローカル開発用(src/local.ts)
// ローカル開発用エントリーポイント。
// Lambda 環境では src/index.ts を使用する。
// dotenv/config は必ず最初に import する。
// 他のモジュール(db/index.ts など)が process.env を参照する前に .env を読み込む必要があるため。
import 'dotenv/config';
import { serve } from '@hono/node-server';
import app from './app.js';
import { logger } from './logger.js';
serve({ fetch: app.fetch, port: 3000 }, () =>
logger.info('http://localhost:3000'),
);
dotenv/config の import を最初に置くことで、db/index.ts が process.env を参照するより前に .env が読み込まれます。Lambda では環境変数はランタイムがネイティブに提供するため、dotenv は不要です。
DB接続の調整(src/db/index.ts)
前回から 2 点調整しました。
① 接続数を 1 に制限
const pool = new Pool({
// ...
max: 1, // 接続数を1に制限(このサンプルでは1接続で十分)
});
Lambda は 1 インスタンスにつき 1 リクエストを順次処理するため、接続プールのサイズは 1 で十分です。
② 接続タイムアウトの設定
const pool = new Pool({
// ...
connectionTimeoutMillis: 30 * 1000,
});
Aurora Express のコールドスタート(スリープ状態からの復帰)には 20 秒強かかることがあります。タイムアウトを設定しないと、Lambda が無限に待ち続けてしまいます。Lambda のタイムアウト(後述の 40 秒)より短い 30 秒を設定することで、Lambda タイムアウトより先に接続タイムアウトエラーを返せます。
Terraform でのデプロイ
インフラは Terraform で管理します。
Lambda 関数(terraform/lambda.tf)
terraform/lambda.tf
resource "aws_lambda_function" "this" {
function_name = var.function_name
role = aws_iam_role.this.arn
filename = "${path.module}/../lambda.zip"
source_code_hash = try(filebase64sha256("${path.module}/../lambda.zip"), null)
# ZIP ルートに index.js が配置されるため handler は index.handler
handler = "index.handler"
runtime = "nodejs22.x"
timeout = 40 # Aurora Express コールドスタート対策
memory_size = 128 # このサンプル程度なら 128MB で十分
architectures = ["arm64"] # Graviton2。x86_64 より低コスト
environment {
variables = {
DB_HOST = var.db_host
DB_USER = var.db_user
DB_NAME = var.db_name
LOG_LEVEL = var.log_level
TZ = var.tz
}
}
}
# CloudWatch ロググループ(保持期間を管理するため明示的に定義)
resource "aws_cloudwatch_log_group" "lambda" {
name = "/aws/lambda/${var.function_name}"
retention_in_days = 14
}
Lambda のタイムアウトを 40 秒に設定しているのは、Aurora Express のコールドスタートに 20 秒強かかるためです。接続タイムアウト(30 秒)が先に発火してエラーを返せるよう、Lambda タイムアウトはそれより長い値にしています。
source_code_hash に try() を使っているのは、lambda.zip が存在しない状態でも terraform validate を通すためです。デプロイ前に npm run package で ZIP を作成しておく必要があります。
API Gateway HTTP API(terraform/api_gateway.tf)
Hono 側でルーティングを処理するため、API Gateway には $default ルートで全リクエストを Lambda に転送する構成にしています。
terraform/api_gateway.tf
# HTTP API (v2)
resource "aws_apigatewayv2_api" "this" {
name = var.function_name
protocol_type = "HTTP"
}
# Lambda プロキシ統合(payload format version 2.0)
resource "aws_apigatewayv2_integration" "lambda" {
api_id = aws_apigatewayv2_api.this.id
integration_type = "AWS_PROXY"
integration_uri = aws_lambda_function.this.invoke_arn
payload_format_version = "2.0"
}
# $default ルート:全パス・全メソッドを Lambda へ転送
resource "aws_apigatewayv2_route" "this" {
api_id = aws_apigatewayv2_api.this.id
route_key = "$default"
target = "integrations/${aws_apigatewayv2_integration.lambda.id}"
}
# $default ステージ(auto_deploy = true でデプロイ手順が不要)
resource "aws_apigatewayv2_stage" "default" {
api_id = aws_apigatewayv2_api.this.id
name = "$default"
auto_deploy = true
}
# API Gateway から Lambda を呼び出す権限
resource "aws_lambda_permission" "apigw" {
statement_id = "AllowAPIGatewayInvoke"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.this.function_name
principal = "apigateway.amazonaws.com"
source_arn = "${aws_apigatewayv2_api.this.execution_arn}/*/*"
}
$default ステージを使うと、エンドポイントは https://<id>.execute-api.<region>.amazonaws.com/users のようにパスプレフィックスなしの形式になります。
IAM ロール・ポリシー(terraform/iam.tf)
Lambda が Aurora Express に IAM 認証で接続するために rds-db:connect 権限が必要です。
terraform/iam.tf
# Lambda 実行ロール
resource "aws_iam_role" "this" {
name = "${var.function_name}-lambda-exec"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [{
Effect = "Allow"
Principal = { Service = "lambda.amazonaws.com" }
Action = "sts:AssumeRole"
}]
})
}
# CloudWatch Logs への書き込み権限
resource "aws_iam_role_policy_attachment" "basic_execution" {
role = aws_iam_role.this.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
}
# Aurora IAM 認証権限(rds-db:connect)
resource "aws_iam_role_policy" "rds_iam_connect" {
name = "${var.function_name}-rds-iam-connect"
role = aws_iam_role.this.id
policy = jsonencode({
Version = "2012-10-17"
Statement = [{
Effect = "Allow"
Action = "rds-db:connect"
# dbuser:* でクラスター ID を固定しない。db_user のみで制限する
Resource = "arn:aws:rds-db:${var.aws_region}:${data.aws_caller_identity.current.account_id}:dbuser:*/${var.db_user}"
}]
})
}
- 参考:Lambda 実行ロール - AWS Lambda
- 参考:IAM データベースアクセス用の IAM ポリシーの作成と使用 - Amazon Relational Database Service
デプロイ手順
1. Lambda デプロイパッケージの作成
npm run package を実行すると、TypeScript をビルドして lambda.zip を作成します。
$ npm run package
==> TypeScript をビルドします...
==> 一時ディレクトリを作成します...
==> コンパイル済みファイルをコピーします(dist/src/ → ZIP ルート)...
==> 本番依存関係をインストールします(devDependencies を除外)...
==> ZIP を作成します...
✓ lambda.zip を作成しました: /path/to/lambda.zip
サイズ: 12M
ZIP の中身は dist/src/ の内容をルートに配置した構成になっています。Lambda ハンドラーは index.handler を指定します。
scripts/package.sh の全体
#!/bin/bash
set -euo pipefail
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
PROJECT_ROOT="$(cd "${SCRIPT_DIR}/.." && pwd)"
ZIP_OUTPUT="${PROJECT_ROOT}/lambda.zip"
echo "==> TypeScript をビルドします..."
cd "${PROJECT_ROOT}"
npm run build
echo "==> 一時ディレクトリを作成します..."
TEMP_DIR=$(mktemp -d)
trap 'rm -rf "${TEMP_DIR}"' EXIT
# dist/src/ の中身をルートにコピー(Lambda ハンドラー = index.handler)
echo "==> コンパイル済みファイルをコピーします(dist/src/ → ZIP ルート)..."
cp -r "${PROJECT_ROOT}/dist/src/." "${TEMP_DIR}/"
# package.json をコピー("type": "module" による ESM 検出に必要)
echo "==> 本番依存関係をインストールします(devDependencies を除外)..."
cp "${PROJECT_ROOT}/package.json" "${TEMP_DIR}/package.json"
cp "${PROJECT_ROOT}/package-lock.json" "${TEMP_DIR}/package-lock.json"
cd "${TEMP_DIR}"
npm ci --omit=dev
echo "==> ZIP を作成します..."
rm -f "${ZIP_OUTPUT}"
zip -r "${ZIP_OUTPUT}" . --exclude "package-lock.json"
2. Terraform でリソースを作成
terraform.tfvars を作成して Aurora Express のエンドポイントを設定します。
$ cp terraform/terraform.tfvars.example terraform/terraform.tfvars
db_host = "my-express-cluster.cluster-xxxxxxxxxxxx.ap-northeast-1.rds.amazonaws.com"
terraform apply でリソースを作成します。
$ cd terraform
$ terraform apply
Apply complete! Resources: 10 added, 0 changed, 0 destroyed.
Outputs:
api_url = "https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com"
lambda_function_arn = "arn:aws:lambda:ap-northeast-1:123456789012:function:aurora-express-drizzle-sample"
lambda_function_name = "aurora-express-drizzle-sample"
lambda_iam_role_arn = "arn:aws:iam::123456789012:role/aurora-express-drizzle-sample-lambda-exec"
lambda_log_group_name = "/aws/lambda/aurora-express-drizzle-sample"
動作確認
curl コマンドで作成したAPIの動作を確認します。
API_URL には Terraform の api_url 出力値を設定してください。
$ API_URL="https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com"
# POST - ユーザー作成
$ curl -s -X POST ${API_URL}/users \
-H 'Content-Type: application/json' \
-d '{"name":"クラスメソ太","email":"mesota@example.com"}'
{
"id": 1,
"name": "クラスメソ太",
"email": "mesota@example.com",
"createdAt": "2026-03-28T10:00:00.000Z"
}
# GET - 一覧取得
$ curl -s ${API_URL}/users
[
{ "id": 1, "name": "クラスメソ太", "email": "mesota@example.com", "createdAt": "2026-03-28T10:00:00.000Z" }
]
# PUT - 更新
$ curl -s -X PUT ${API_URL}/users/1 \
-H 'Content-Type: application/json' \
-d '{"name":"クラスメソ次郎"}'
{
"id": 1,
"name": "クラスメソ次郎",
"email": "mesota@example.com",
"createdAt": "2026-03-28T10:00:00.000Z"
}
# DELETE - 削除
$ curl -s -X DELETE ${API_URL}/users/1
{
"id": 1,
"name": "クラスメソ次郎",
"email": "mesota@example.com",
"createdAt": "2026-03-28T10:00:00.000Z"
}
問題なく動作しました!
実行時間をCloudWatch Logsのログで見てみる
Lambda の実行ログは CloudWatch Logs に出力されます。コールドスタート時のログを確認してみます。
前回(Express サーバー起動時)と同様、Aurora Express がスリープ状態からコールドスタートする場合は接続に時間がかかります。
今回は接続が確立するまで 20秒弱 かかっています。
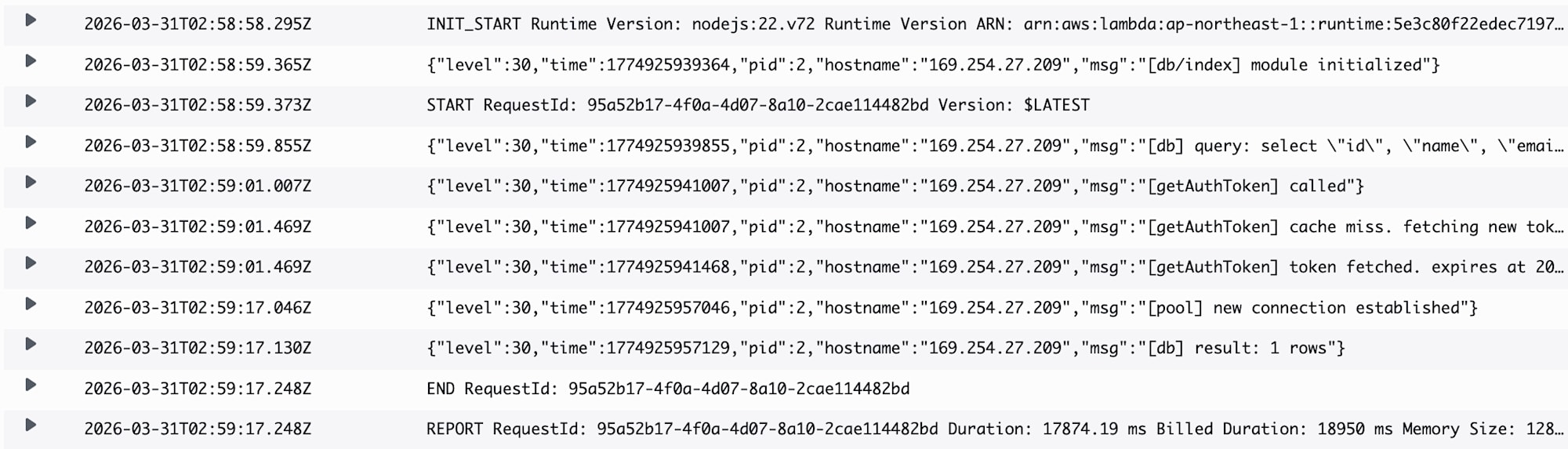
ウォームスタートで同じ Lambda インスタンスが再利用された場合、IAM 認証トークンのキャッシュが有効なため、トークン再取得の AWS API 呼び出しが省略されて、コネクションも使い回されます。
この場合は ミリ秒 レベルでレスポンスが返ってきています。ウォームスタートの恩恵をうまく受けられています。

Lambdaのコールドスタートで実行された場合は、再接続処理が入るため多少時間がかかります。
今回はレスポンスに 4〜5秒 時間がかかりました。
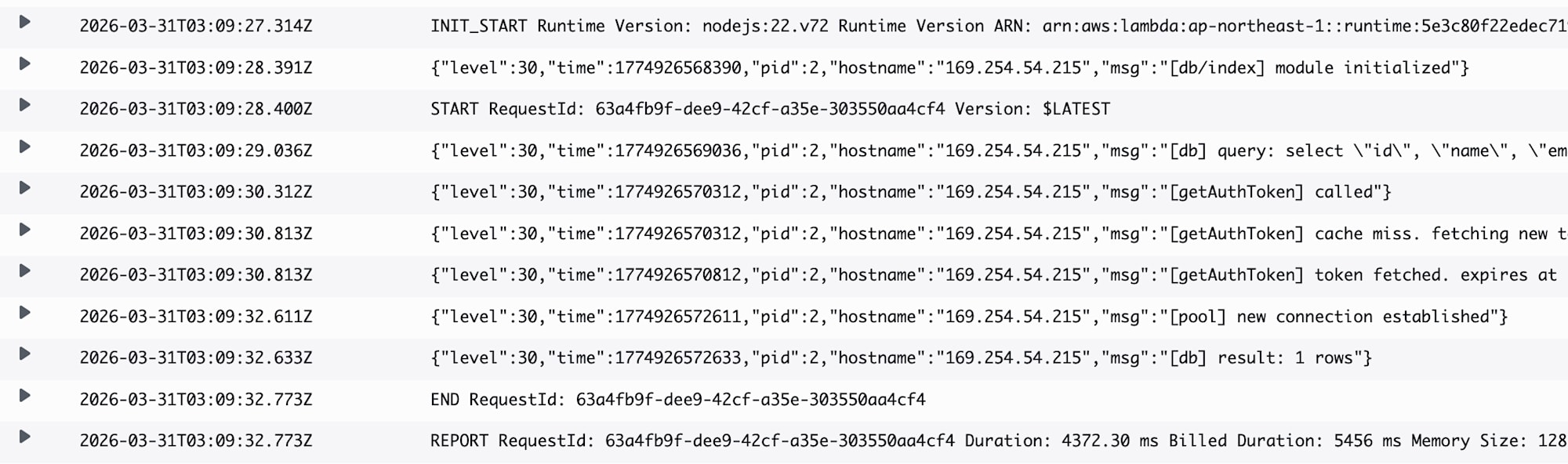
注意点
Lambda のコンカレンシーと max_connections の上限
Lambda は同時リクエスト数だけインスタンスが起動します(デフォルト上限 1,000)。各インスタンスが 1 接続を保持するため、同時リクエスト数 ≒ Aurora への同時接続数になります。
Aurora Serverless v2 の max_connections は、最大 ACU 設定のメモリから静的に決まります。現在の ACU ではなく最大 ACU 基準なのは、スケールダウン時に接続が切れないようにするためです。
以下は Aurora Serverless v2 の公式ドキュメントに記載されている最大 ACU 別の値です。Aurora Express で同様の値となるかはドキュメントでは確認できませんでしたが、オーダー感の参考にしてください。
| 最大 ACU | max_connections(参考値) |
|---|---|
| 1 | 189 |
| 4 | 823 |
| 8 | 1,669 |
| 16 | 3,360 |
| 32 | 5,000(上限) |
Lambda の同時実行数がこの値を超えると接続枯渇が発生します。
また、最小 ACU が 0(オートポーズあり)の場合、最大 ACU 設定にかかわらず max_connections の上限は 2,000 に制限されます。
この構成は、同時接続数が限られる 社内ツールや個人開発・プロトタイプ には非常に向いていますが、大規模な B2C システムへの適用は慎重に検討する必要があります。
おわりに
前回 Express サーバーで確認した Aurora Express への Drizzle ORM 接続を、Lambda でも実現できました。
エントリーポイントの分割、接続プールの設定調整などLambda 固有のポイントがいくつかありましたが、hono/aws-lambda アダプターのおかげで Hono のアプリコード自体はほとんど変更不要でした。
Aurora Expressのコールドスタートにそこそこ時間がかかる点は注意が必要ですが、VPC なしで手軽に使えて、Lambda + API Gateway の組み合わせは、個人開発やプロトタイプ作成で手軽に使えそうです。
このブログがどなたかのお役に立てれば幸いです。








