
Amazon AthenaからFederated QueryでDynamoDBに接続してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部の若槻です。
Amazon AthenaではFederated Queryを用いることにより、Amazon S3以外のデータソースに接続してデータを抽出することが可能となります。
Federated Queryには既定で下記のようなデータソースへの接続の作成が用意されています。また独自のコネクタをLambda関数を作成して使用することも可能です。
- Amazon CloudWatch Logs
- Amazon CloudWatch Metrics
- Amazon DocumentDB
- Amazon DynamoDB
- Amazon Redshift
- Apache HBase
- MySQL
- PostgreSQL
- Redis
そこで今回は、Amazon AthenaからFederated QueryでDynamoDBに接続してデータを取得してみました。
前提
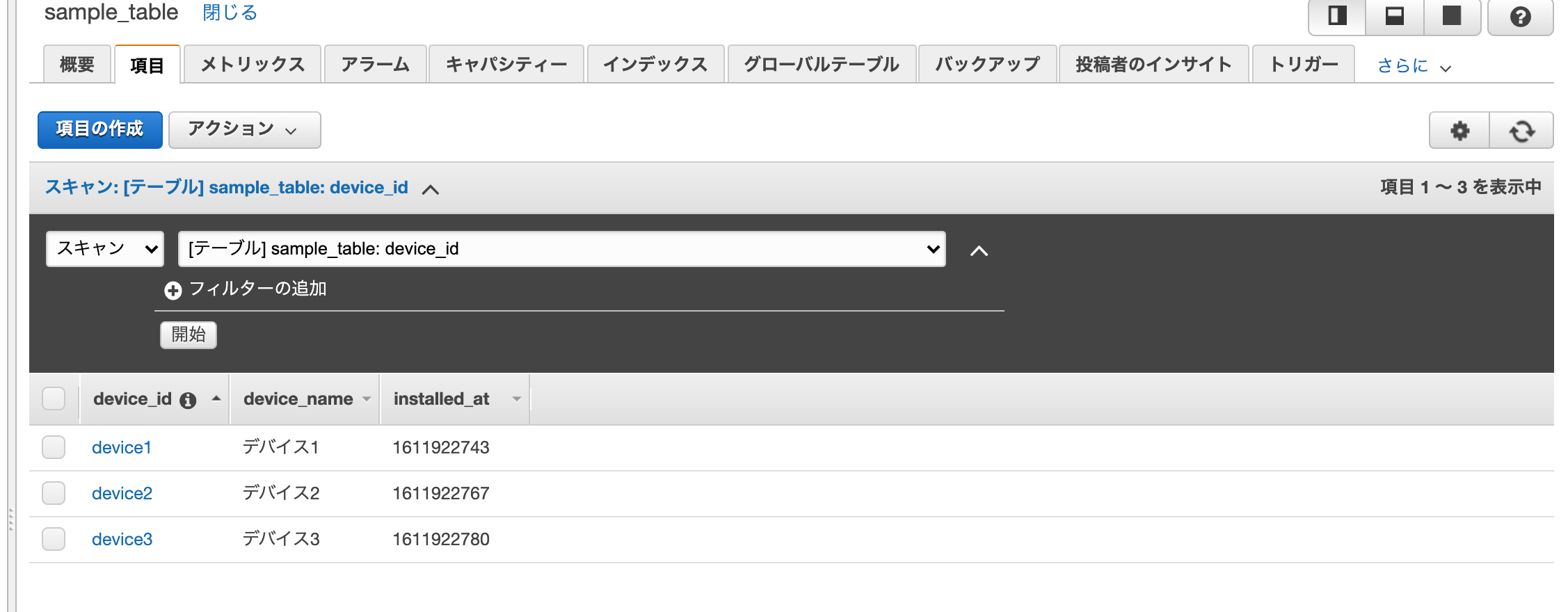
データソースとして下記のようなデータを持つDynamoDBテーブルsample_table(パーティションキー:device_id)を使用します。
前述のドキュメントに記載のある通り、Federated QueryによるAthenaでのクエリ実行にはAthenaエンジンVersion2を使用する必要があります。
Athena Federated Query is supported only on Athena engine version 2.
エンジンVersionはAthena Work Groupごとに1または2を指定できるため、Version2のWork Groupを作成しておきます。作成方法は下記が参考になります。
やってみる
Federated Queryによるデータソースへの接続にはコネクタとしてLambda関数を使用します。このLambda関数はコンソールからのデータソース接続作成時によろしく作ってくれるので、今回はコンソールから操作をしていきます。
データソースへの接続の作成
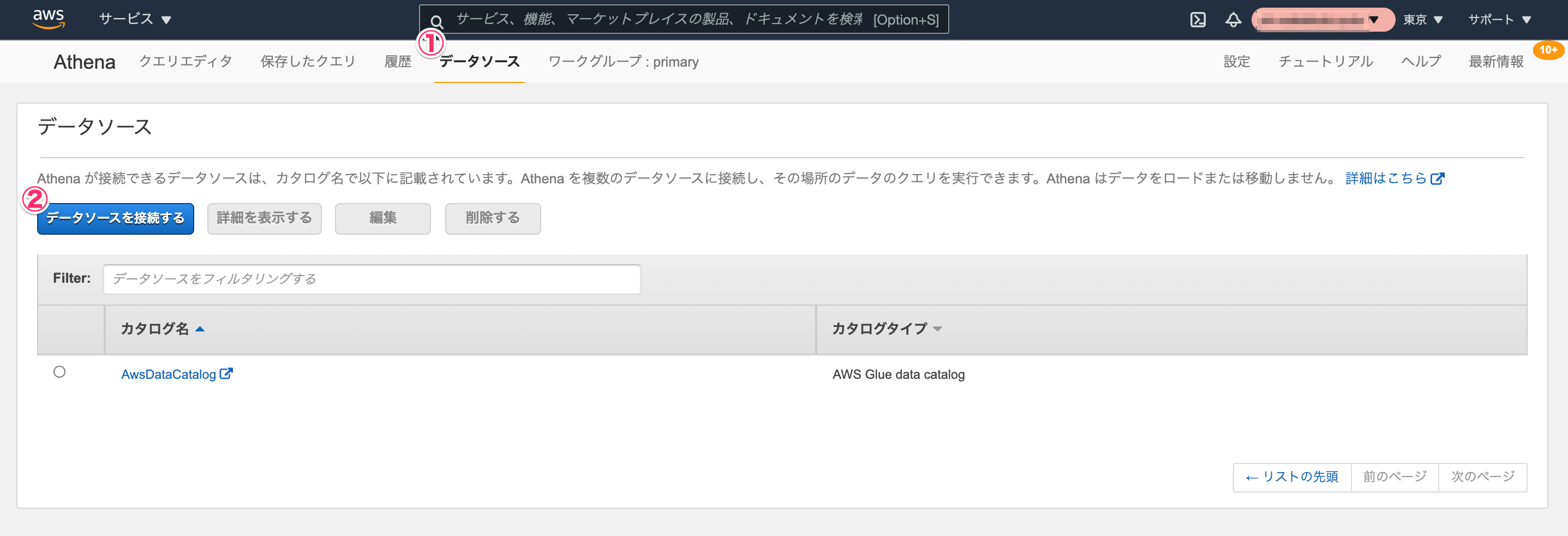
Athenaのコンソールで[データソース]タブで[データソースを接続する]クリックしてウィザードを開始します。
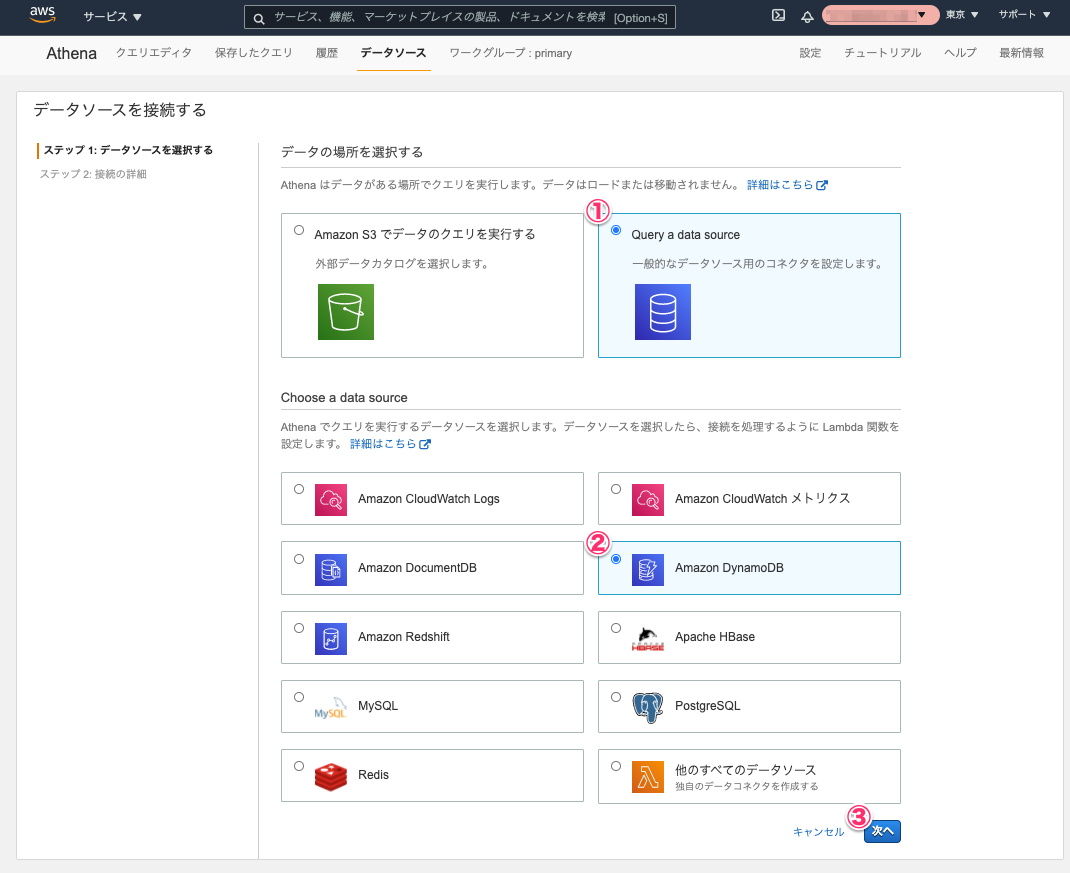
ステップ1で、データソースとして[Query a data source] - [Amazon DynamoDB]を選択し、[次へ]をクリックします。
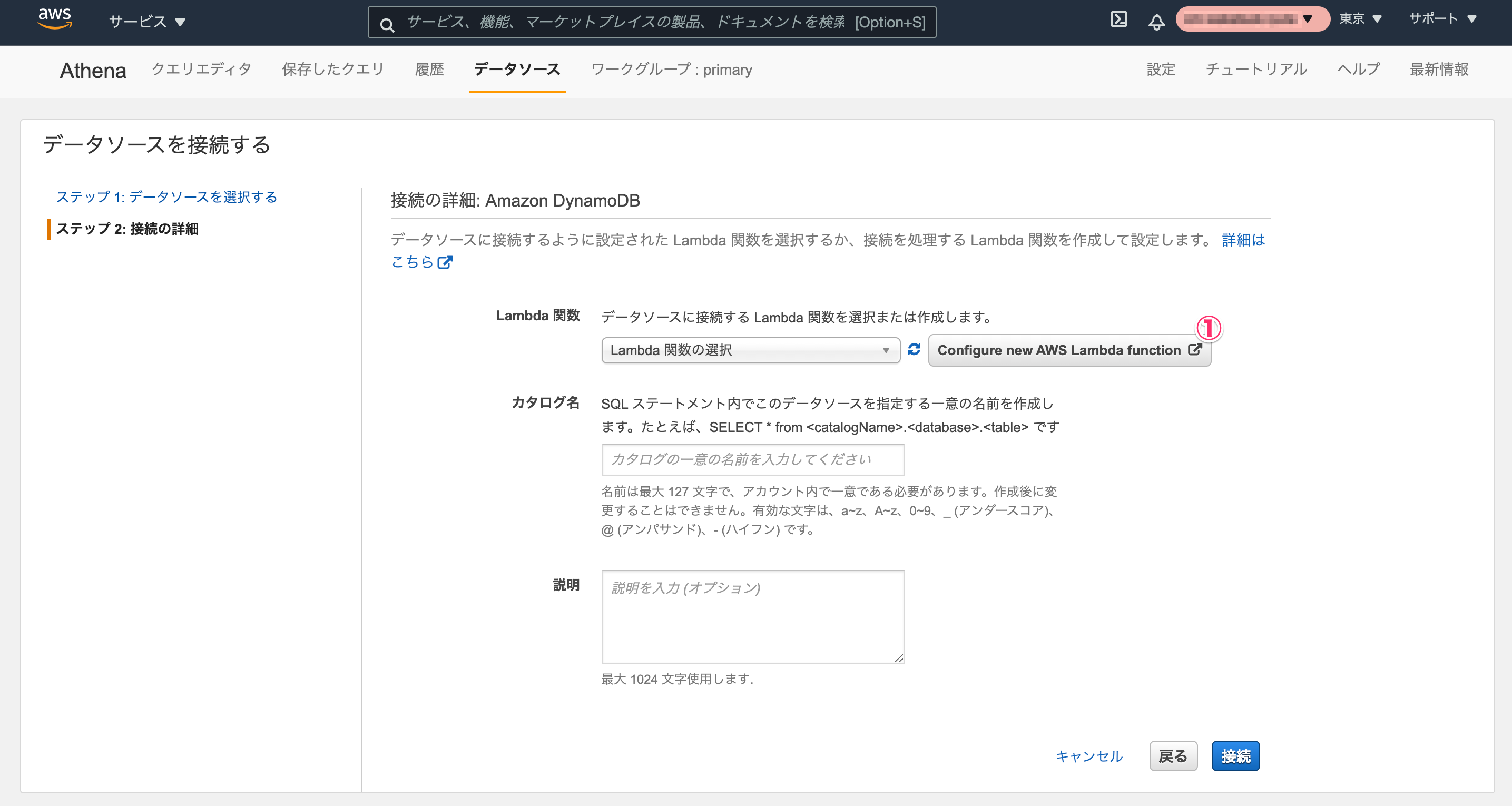
ステップ2で、[Configure new AWS Lambda function]をクリックします。
コネクタとなるLambda関数のアプリケーションの作成ページが開きます。このアプリケーションのソースコードはGitHubで公開、管理されています。
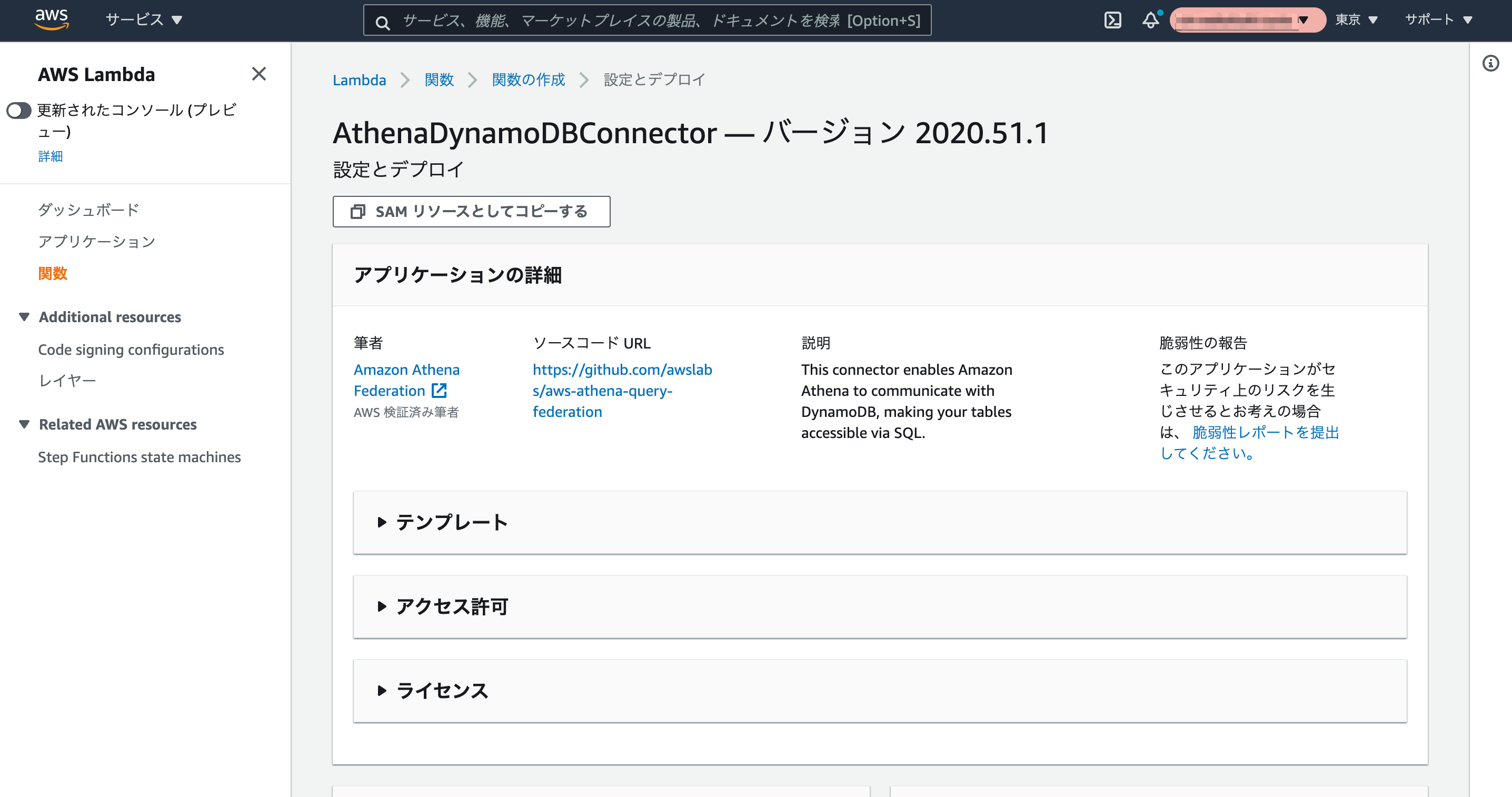
同ページを下へスクロールして、[アプリケーションの設定]で[SpillBucket]に作成済みのS3バケット名(※1)、[AthenaCatalogName]に作成するLambda関数名(※2)を指定し、[このアプリがカスタム IAM ロールを作成することを承認します。]にチェックを入れて、[デプロイ]をクリックしアプリケーションのデプロイを開始します。
- ※1:Spill Bucketとは、Lambda関数が返すデータがLambdaの制限を超過した場合に、超過分のデータをAthenaが読み取れるようにデータを一時的に保存するS3バケットです。
- ※2:「AthenaCatalogName」とありますがここでの指定はLambda関数名に使われます。なので名前は
^[a-z0-9-_]{1,64}$のパターンにマッチしている必要があります。
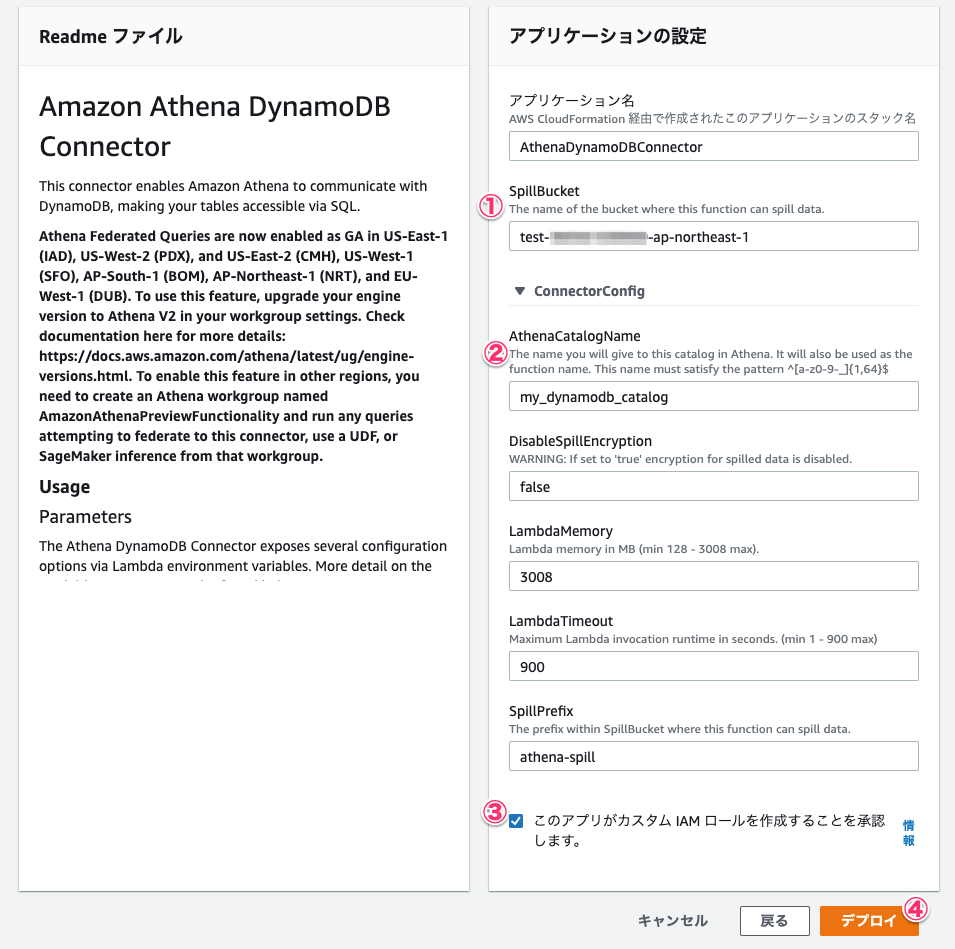
するとLambda関数のアプリケーションのページが開きます。[デプロイ]タブでLambda関数のデプロイメントの状態がCreate completeとなれば、コネクタとなるLambda関数の作成は完了です。
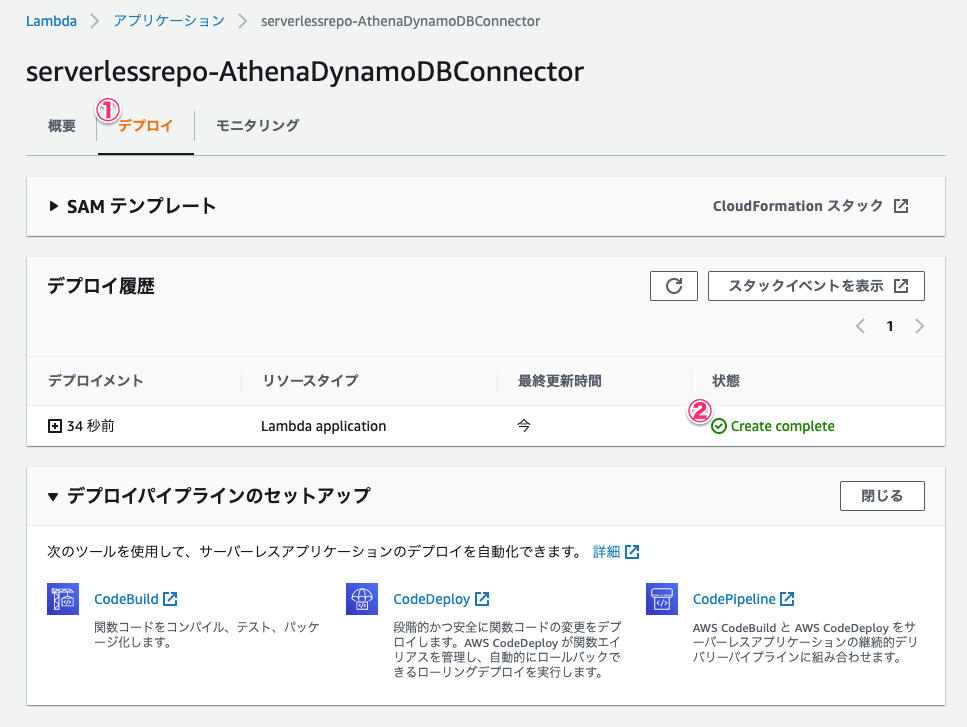
Athenaのデータソース接続作成ページに戻り、更新ボタンをクリックした上で先程作成したLambda関数を選択し、作成されるデータソースのカタログ名(今回はMyDynamoDBCatalog。カタログ名はクエリ実行時に使用します。)を指定して、[接続]をクリックします。
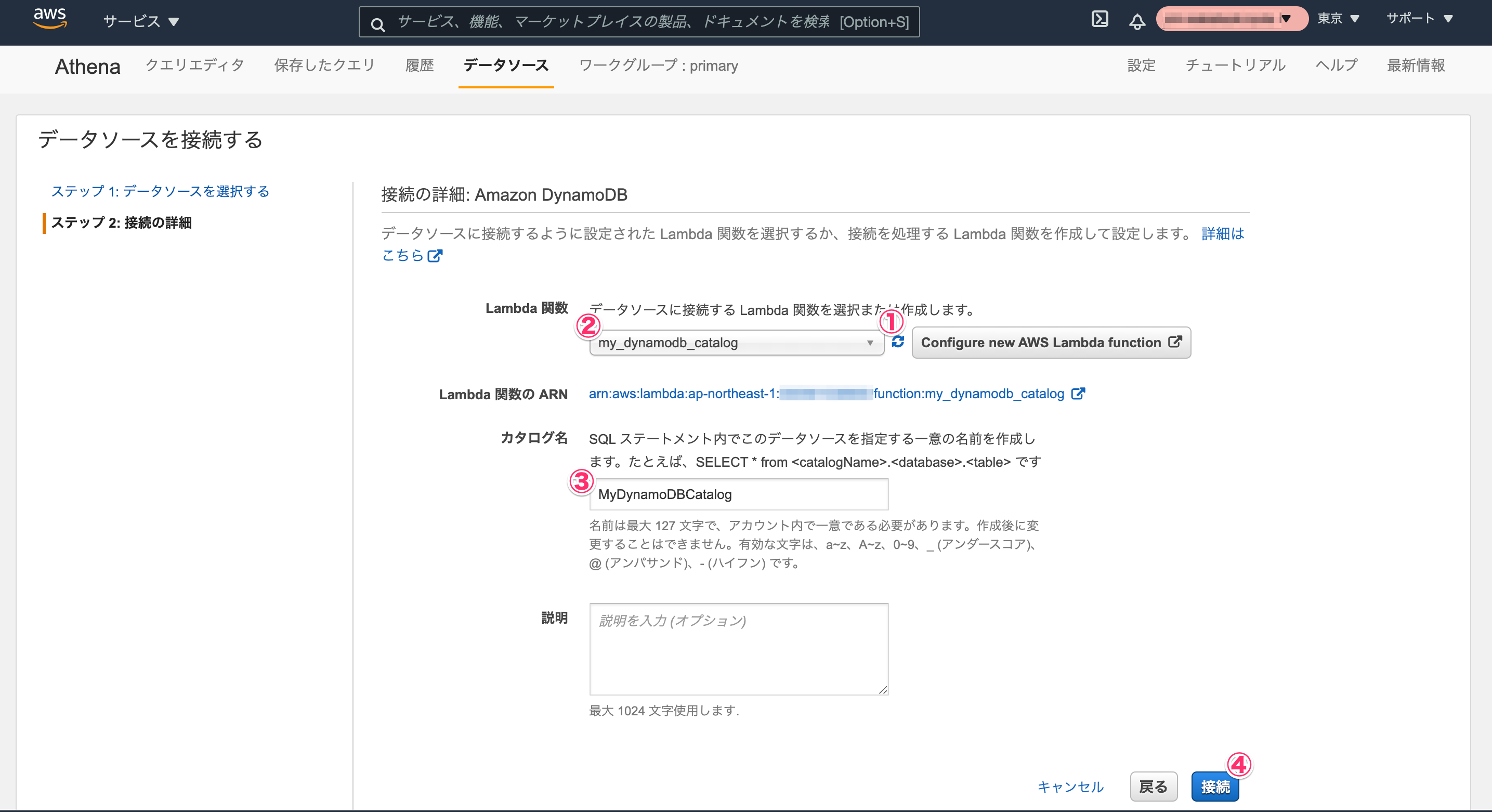
データソース一覧に戻ります。作成したデータソースがカタログ一覧に追加されています。
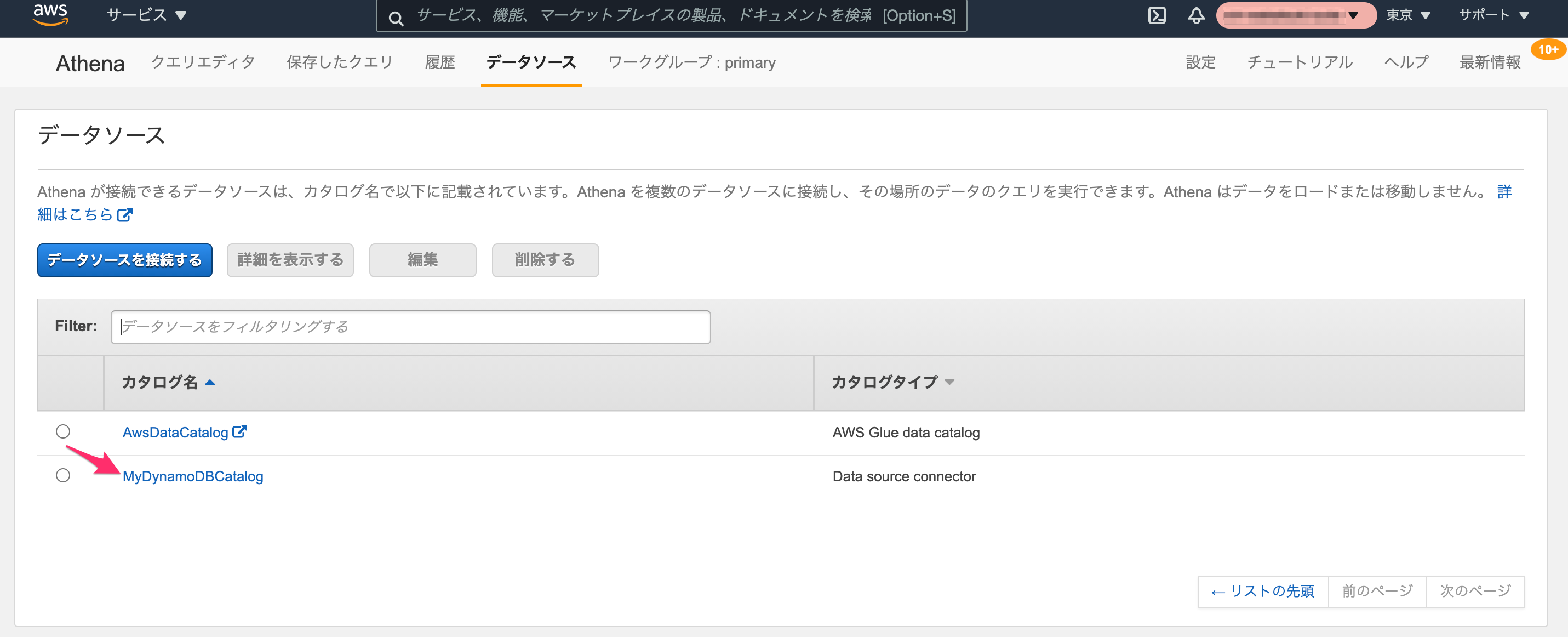
これでデータソースとなるDynamoDBへの接続が作成できました。
Federated Queryによるデータ取得
作成したデータソース接続を使用してDynamoDB上のデータをAthenaのFederated Queryにより取得してみます。実行するクエリは下記のようになります。
SELECT * FROM "<カタログ名>"."lambda:dynamodb"."<テーブル名>"
上記のFROM句の指定の仕方の確認に苦労しましたが、下記の公式のデモのYouTube動画で確認できました。
ワークグループをVersion 2のエンジンのものに切り替えた上で、クエリエディタで下記のクエリを指定し、[クエリの実行]を行うと、DynamoDB上のデータが取得できました。
SELECT * FROM "MyDynamoDBCatalog"."lambda:dynamodb"."sample_table"
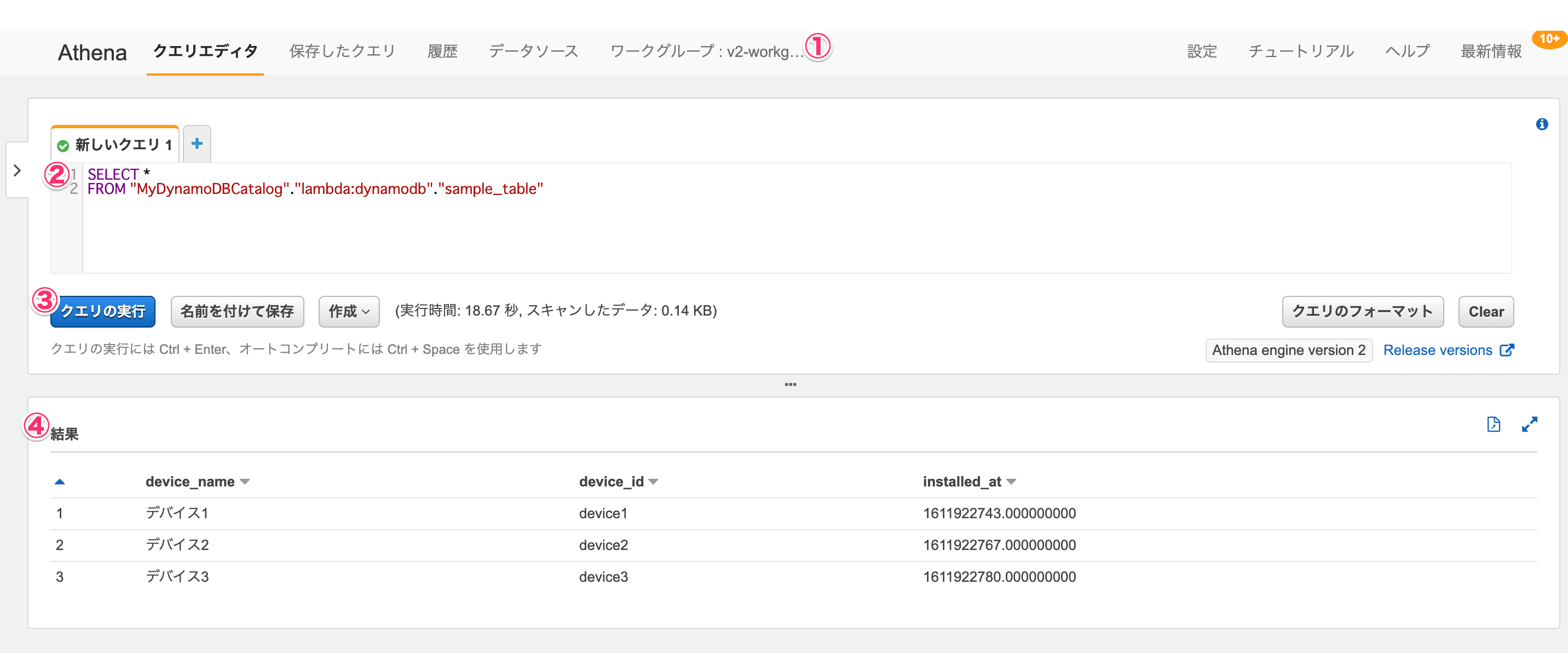
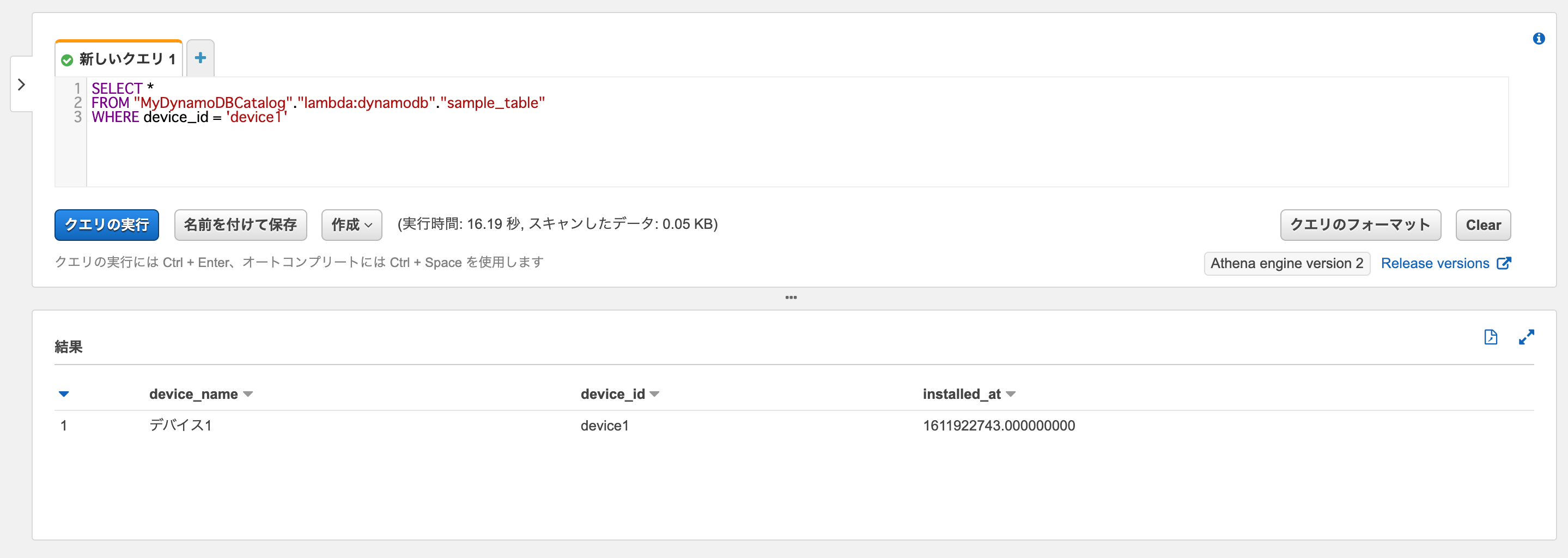
テーブルのパーティションキーdevice_idに対してWHERE句が使えますね。
SELECT * FROM "MyDynamoDBCatalog"."lambda:dynamodb"."sample_table" WHERE device_id = 'device1'
またキー以外のカラムでもWHERE句が使えました。
SELECT * FROM "MyDynamoDBCatalog"."lambda:dynamodb"."sample_table" WHERE device_name = 'デバイス2'
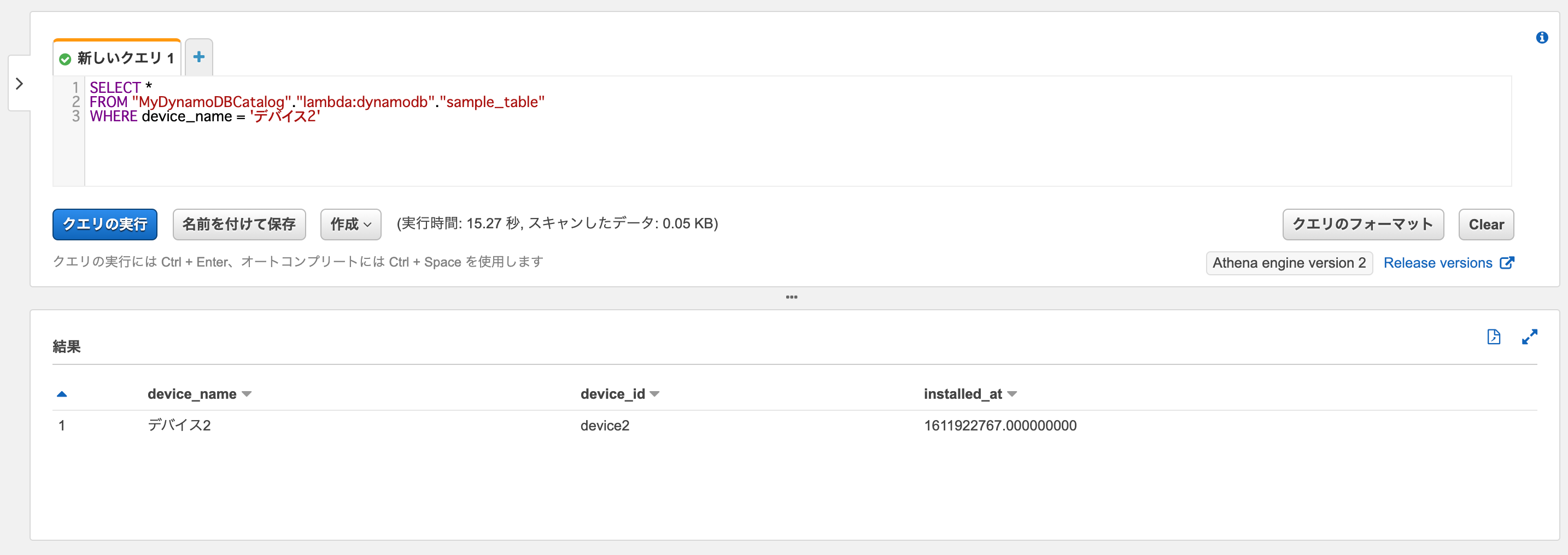
どうやらコネクタのLambda関数では(少なくともキー以外のカラムをWHERE句に使う場合は)DynamoDBから一度すべてのデータをスキャンしたものに対してWHERE句の処理を適用しているようですね。
※実際のLambda関数のコードは以下で公開されているので興味があれば見てみてください。
おわりに
Amazon AthenaからFederated QueryでDynamoDBに接続してデータを取得してみました。
DynamoDB上のデータにAthenaでアクセスしたい際に、GlueジョブなどでS3に吐き出してからアクセスするのか、今回のようにFederated Queryを使うのかは正直ユースケースによると思いますが、選択肢の一つとして念頭に置いておきたいですね!
参考
以上










