[新機能]Cortex AI Function Studioがパブリックプレビューとなったので試してみた
かわばたです。
2026年5月20日に、Snowflakeの新機能としてCortex AI Function StudioがPublic Previewとなりました。自然言語によるタスク定義を起点に、Cortex AI Functionの作成・評価・最適化をガイド付きで進められる機能です。
今回はCortex Code(Snowsight)インターフェースを使い、注文金額に基づく優先度分類タスクでCreate → Evaluate → Optimizeの全ワークフローを実データで検証しました。
対象読者
- Cortex AI Function Studioについて確認したい方
- Cortex CodeでAI関数の作成・評価・最適化を試したい方
- Snowflake上の構造化データに対して、自然言語ベースの分類・構造化生成を試したい方
機能概要
Cortex AI Function Studioは、非構造化データおよびマルチモーダルデータワークフロー向けのCortex AI Functionを作成・評価・最適化するためのツールです。プロンプトエンジニアリング、モデル選択、評価、最適化を自動化した構造化された開発ライフサイクルを提供します。
Cortex AI Function Studioは、Custom AI Functionの作成・評価・最適化を支援するツールです。従来はプロンプトの調整やモデル選択を手動で試行錯誤する必要がありましたが、この機能では3フェーズ(後述)を通じて自動的に最適な構成を見つけてくれます。なお、EvaluateとOptimizeは任意のステップであり、作成後に必要に応じて実行・再実行できます。
インターフェース
Cortex AI Function Studioには2つのインターフェースがあります。
| インターフェース | 対象ユーザー | 特徴 |
|---|---|---|
| Cortex Code CLI | AIエンジニア・データエンジニア | コマンドラインベース、スクリプト可能 |
| Snowsight AI Studio | アナリスト・データサイエンティスト | コード不要のGUI体験 |
今回は Cortex Code(Snowsightワークスペース上)を使って検証していきます。
3つのフェーズ
| フェーズ | 概要 |
|---|---|
| Create(作成) | タスク定義・モデル選択・スモークテスト |
| Evaluate(評価) | データセットを使った精度・品質の評価 |
| Optimize(最適化) | アルゴリズムによるプロンプトとモデルの自動最適化 |
対応するユースケース
ドキュメント抽出、要約、センチメント分析、分類、構造化生成、コンプライアンスワークフロー、推論パイプラインなど幅広いタスクに対応しています。また、テキストだけでなくドキュメント・画像・音声・動画のマルチモーダル入力もサポートしています。
制限事項
- 2026年5月23日時点ではPublic Previewかつ**リージョン限定(Regional)**の機能です。利用可否はリージョン・アカウント設定に依存し、GAまでに仕様が変わる可能性があります
- 対応モデルはリージョンによって異なります。利用前に公式ドキュメントで対応モデルを確認してください
コスト
開発フェーズでは、評価・最適化などの実験プロセスでモデルが処理したトークンに加え、Cortex Codeの利用分が課金対象になります。本番環境では、登録されたCustom AI Functionが利用する基盤モデルに応じて課金され、関数抽象化自体への追加料金はありません。
コスト監視にはSNOWFLAKE.ACCOUNT_USAGE.CORTEX_AI_FUNCTIONS_USAGE_HISTORYビューを使用できます。利用クレジットはCREDITSカラム、トークンやページ数などの詳細メトリクスはMETRICS配列から確認できます。
-- 過去30日間のCortex AI Function利用クレジットを確認
SELECT
DATE_TRUNC('day', START_TIME) AS usage_date,
FUNCTION_NAME,
MODEL_NAME,
SUM(CREDITS) AS total_credits,
COUNT(DISTINCT QUERY_ID) AS query_count
FROM SNOWFLAKE.ACCOUNT_USAGE.CORTEX_AI_FUNCTIONS_USAGE_HISTORY
WHERE START_TIME >= DATEADD('day', -30, CURRENT_TIMESTAMP())
GROUP BY 1, 2, 3
ORDER BY usage_date DESC, total_credits DESC;
前提条件
- Snowflake Enterprise版 AWS_AP_NORTHEAST_1リージョン
- Cortex AI Functionsの利用には、
USE AI FUNCTIONSアカウント権限(またはper-functionのUSE AI FUNCTION <name>権限)に加えて、SNOWFLAKE.CORTEX_USERまたはSNOWFLAKE.AI_FUNCTIONS_USERデータベースロールが必要です。ただし、USE AI FUNCTIONSはデフォルトでPUBLICロールに付与されているため、追加作業が不要な環境もあります - Cortex Code CLIを使用する場合、Snowflakeワークシートまたは対応するSQLクライアントからストアドプロシージャを実行できる環境が必要です
事前準備
検証シナリオ
今回はjaffle-shopのサンプルデータでraw_ordersを使用し、注文金額に基づく優先度分類というカスタムユースケースで検証しました。
入力データ:
| カラム | 説明 |
|---|---|
| ORDER_TOTAL | 注文合計金額 |
| SUBTOTAL | 小計 |
| TAX_PAID | 税額 |
| ORDERED_AT | 注文日時 |
分類カテゴリ:
| カテゴリ | 条件 |
|---|---|
| vip_express | ORDER_TOTAL >= 3000 |
| high_priority | ORDER_TOTAL >= 1500 AND < 3000 |
| standard | ORDER_TOTAL >= 500 AND < 1500 |
| low_priority | ORDER_TOTAL > 0 AND < 500 |
| review_needed | ORDER_TOTAL = 0 or 異常パターン |
データ準備: Teacher-Studentによるラベリング
Cortex AI Function StudioのEvaluate/Optimizeフェーズでは、正解ラベル付きのデータセットが必要です。しかし、実務では最初からラベル付きデータが用意されていないケースが多いです。
そこで今回は、広義のTeacher-Studentアプローチ(疑似ラベリング + 最適化)を採用しました。強力な「教師モデル」に疑似ラベルを生成させ、そのラベルに対してCustom AI Functionのプロンプトと候補モデルを最適化するという手法です。厳密なモデル蒸留(モデルの重みを学習・転写する手法)とは異なりますが、教師モデルの知識をラベルを介して活用する点で類似のアプローチです。
このアプローチのメリット:
- ラベル付きデータがない現場でもすぐに評価・最適化ワークフローを開始できる
- 教師モデル(高精度・高コスト)で全推論するのではなく、生徒モデル側のプロンプトを最適化することで精度とコストのバランスを調整できる
- Cortex AI Function StudioのOptimizeフェーズと組み合わせることで、プロンプトとモデルの最適な組み合わせを自動探索できる
まず、40行のサブセットを作成し、教師モデル(mistral-large2)で疑似ラベルを生成します。教師モデルには推論能力が高く、分類タスクで安定した出力が期待できるmistral-large2を選定しました。
-- 40行のサブセットを作成
CREATE TABLE KAWABATA_MART_DB.AI_FUNCTIONS.DEMO_ORDERS_UNLABELED AS
SELECT ID, CUSTOMER, ORDERED_AT, STORE_ID, SUBTOTAL, TAX_PAID, ORDER_TOTAL
FROM KAWABATA_MART_DB.AI_FUNCTIONS.RAW_ORDERS
ORDER BY RANDOM()
LIMIT 40;
-- 教師モデル(mistral-large2)で疑似ラベル生成
CREATE TABLE KAWABATA_MART_DB.AI_FUNCTIONS.DEMO_ORDERS_LABELED AS
SELECT *,
TRIM(AI_COMPLETE(
'mistral-large2',
'You are an order priority classifier...' || ORDER_TOTAL::STRING || ...
)) AS EXPECTED_OUTPUT
FROM KAWABATA_MART_DB.AI_FUNCTIONS.DEMO_ORDERS_UNLABELED;
生成されたラベル分布:
| カテゴリ | 件数 |
|---|---|
| standard | 25 |
| high_priority | 8 |
| low_priority | 3 |
| review_needed | 2 |
| vip_express | 2 |
ラベル分布を見ると、standardが最多で実データの金額分布を反映しています。各カテゴリに最低2件以上のサンプルがあるため、評価・最適化に最低限必要なデータは確保できています。
試してみた
Create(AI関数作成)
生徒モデルとして推論コストが低く高速な llama3.1-8b を使用し、Custom AI Functionを作成します。
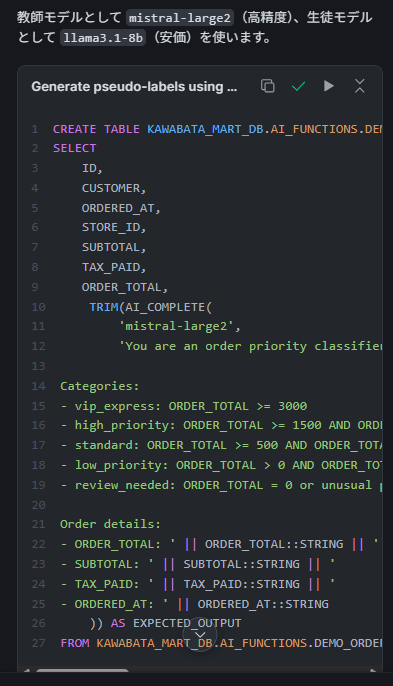
Cortex Codeでは CALL SNOWFLAKE.CORTEX.CREATE_AI_FUNCTION() ストアドプロシージャで関数を作成します。
CALL SNOWFLAKE.CORTEX.CREATE_AI_FUNCTION(
'KAWABATA_MART_DB.AI_FUNCTIONS.DEMO_CLASSIFY_ORDER_PRIORITY',
'llama3.1-8b', -- 安価な生徒モデル
$$You are an order priority classifier...$$,
$$Classify this order:
- ORDER_TOTAL: {ORDER_TOTAL}
- SUBTOTAL: {SUBTOTAL}
- TAX_PAID: {TAX_PAID}
- ORDERED_AT: {ORDERED_AT}$$,
PARSE_JSON('[{"name":"ORDER_TOTAL","sql_type":"VARCHAR"},...]'),
PARSE_JSON('[{"name":"priority","json_type":"string","description":"..."}]'),
'Classify order priority based on order amount and details',
NULL, NULL
);
本番環境で大量の注文を処理する想定のため、コスト効率を優先しています。
今回、Cortex Code が生成した CREATE_AI_FUNCTION の呼び出し例では、
9つの位置引数が使用されていました。
| # | パラメータ | 型 | 説明 |
|---|---|---|---|
| 1 | ai_function_name | STRING | 完全修飾関数名(DB.SCHEMA.FUNC_NAME) |
| 2 | base_model | STRING | 推論に使用するベースモデル名 |
| 3 | system_prompt | STRING | システムプロンプト(モデルの役割定義) |
| 4 | user_prompt_template | STRING | ユーザープロンプトテンプレート({COLUMN}プレースホルダー使用) |
| 5 | input_schema | ARRAY | 入力カラムのスキーマ定義(name, sql_type) |
| 6 | output_schema | ARRAY | 出力フィールドのスキーマ定義(name, json_type, description) |
| 7 | task_description | STRING | タスクの自然言語での説明 |
| 8 | example_input | VARIANT | スモークテスト用のサンプル入力(NULL可) |
| 9 | example_output | VARIANT | スモークテスト用の期待出力(NULL可) |
関数が作成されると、DEMO_CLASSIFY_ORDER_PRIORITYという名前のCustom AI FunctionがSnowflake上に登録されます。SQLから直接呼び出せる状態になっていればOKです。
Evaluate(評価)

作成した関数の精度を、ラベル付きデータセットで評価します。
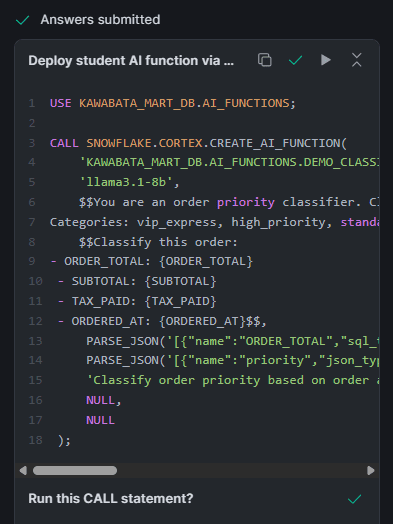
CALL SNOWFLAKE.CORTEX.EVALUATE_AI_FUNCTION(
'KAWABATA_MART_DB.AI_FUNCTIONS.DEMO_CLASSIFY_ORDER_PRIORITY',
'KAWABATA_MART_DB.AI_FUNCTIONS.DEMO_ORDERS_LABELED',
ARRAY_CONSTRUCT('ORDER_TOTAL', 'SUBTOTAL', 'TAX_PAID', 'ORDERED_AT'),
'EXPECTED_OUTPUT',
'exact_match',
'llama3.1-8b',
NULL, NULL, NULL, 500, NULL, NULL
);
今回、Cortex Code が生成した EVALUATE_AI_FUNCTION の呼び出し例では、
以下のような位置引数が使用されていました。
| # | パラメータ | 説明 |
|---|---|---|
| 1 | ai_function_name | 評価対象のAI関数名(完全修飾名) |
| 2 | evaluation_dataset | 評価データセットのテーブル名 |
| 3 | input_columns | 入力カラム名の配列(ARRAY_CONSTRUCTで指定) |
| 4 | expected_output_column | 正解ラベルのカラム名 |
| 5 | metric | 評価メトリクス |
| 6 | model | 評価時に使用するモデル |
| 7-12 | その他 | NULL指定可能なオプション群(judge_model、max_tokens等) |
評価メトリクスの選択肢:
| メトリクス | 説明 | 適用場面 |
|---|---|---|
| exact_match | 大文字小文字を区別しない完全一致 | カテゴリ分類など離散値 |
| llm_judge | 参照LLMによる意味的評価(UI上は「LLM-as-a-Judge」と表示) | 要約・翻訳・自由記述などのオープンエンドな生成 |
| contains_match | 出力に期待値の部分文字列が含まれるか | キーワード抽出や部分一致で十分な場合 |
| fuzzy_match | トークンレベルの類似度にもとづくあいまい一致 | 表記ゆれや軽微な差分を許容する場合 |
| custom | タスク固有のカスタム評価メトリクス | 標準メトリクスでは評価しきれない場合 |
今回はカテゴリ分類タスクのため、exact_matchを選択しました。なお、Custom AI Functionの出力スキーマはJSON形式(priorityフィールド)で定義していますが、評価時は出力のpriorityフィールド値とEXPECTED_OUTPUTカラムのスカラー文字列を比較する形で評価しています。
評価結果:
| メトリクス | スコア |
|---|---|
| exact_match | 0.65 (65%) |
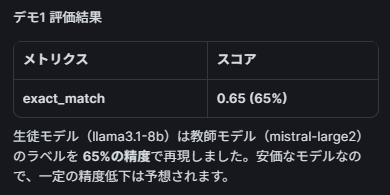
安価なモデル(llama3.1-8b)は教師のラベルを65%しか再現できませんでした。プロンプトに具体的な分類ルール(金額の閾値等)を明示していないため、モデルが独自に解釈してしまっていることが原因と考えられます。
Optimize(最適化)
評価結果を踏まえて、プロンプトとモデルの最適化を実行します。
CALL SNOWFLAKE.CORTEX.OPTIMIZE_AI_FUNCTION(
'KAWABATA_MART_DB.AI_FUNCTIONS.DEMO_CLASSIFY_ORDER_PRIORITY',
'KAWABATA_MART_DB.AI_FUNCTIONS.DEMO_ORDERS_LABELED',
'EXPECTED_OUTPUT',
ARRAY_CONSTRUCT('ORDER_TOTAL', 'SUBTOTAL', 'TAX_PAID', 'ORDERED_AT'),
'exact_match',
ARRAY_CONSTRUCT('llama3.1-70b'), -- より大きいモデルを候補に
'mistral-large2', -- リフレクションモデル
NULL,
'demo', -- 予算: demo(クイック検証向け)
0.5, 0.0, 8192,
NULL, NULL, NULL, NULL,
'body', -- 最適化タイプ: body(プロンプト+SQL全体)
'DEMO_CLASSIFY_ORDER_PRIORITY_OPT_EXP'
);
今回、Cortex Code が生成したOPTIMIZE_AI_FUNCTIONの呼び出し例では、
以下のような引数が使用されていました。
| # | パラメータ | 説明 |
|---|---|---|
| 1 | ai_function_name | 最適化対象のAI関数名 |
| 2 | evaluation_dataset | 評価データセットテーブル |
| 3 | expected_output_column | 正解ラベルカラム |
| 4 | input_columns | 入力カラム配列 |
| 5 | metric | 評価メトリクス |
| 6 | candidate_models | 最適化時の候補モデル配列 |
| 7 | reflection_model | プロンプト改善の推論に使うモデル |
| 8 | judge_model | LLM-as-a-Judge使用時のジャッジモデル(NULL可) |
| 9 | budget | 最適化予算 |
| 10-12 | temperature, top_p, max_tokens | 推論パラメータ |
| 13-16 | その他 | NULL指定可能なオプション群 |
| 17 | optimize_type | 最適化タイプ |
| 18 | experiment_name | 実験名(結果を後から参照するための識別子) |
最適化予算の選択肢:
| 予算 | 反復数 | 適用用途 |
|---|---|---|
| demo | 2 | クイック検証・プロトタイプ |
| light | 6 | シンプルなタスク |
| medium | 12 | 複雑なタスク |
| heavy | 18 | 本番環境 |
今回は検証目的のためdemo(2反復)を選択しました。
最適化の推移:
| イテレーション | スコア |
|---|---|
| SEED(初期プロンプト) | 0.65 |
| ITER_1 | 0.70 |
| ITER_2 | 0.65 |
| ITER_3 | 0.90 |
| ITER_4 (BEST) | 0.95 |
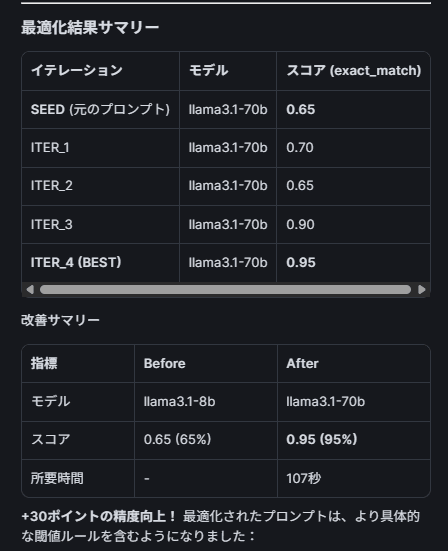
最適化で何が変わったか
最適化により、システムプロンプトに具体的な閾値ルールが自動追加されました。
Before(初期プロンプト):
You are an order priority classifier. Classify the order into exactly one category...
Categories: vip_express, high_priority, standard, low_priority, review_needed
After(最適化後):
You are an order priority classifier...
Consider the following rules:
- If ORDER_TOTAL is greater than 2000, classify as high_priority.
- If ORDER_TOTAL is less than 500, classify as low_priority.
- If ORDER_TOTAL is between 1500 and 2000, classify as high_priority.
- If ORDER_TOTAL is 0, classify as review_needed.
- Otherwise, classify as standard.
変化のポイント:
- 曖昧な指示から具体的なルールへ: 初期プロンプトではカテゴリ名を列挙するだけでしたが、最適化後はデータの実態に基づいた具体的な金額閾値ルールが追加されています。これにより、モデルが独自解釈する余地が大幅に減りました
- モデルの変更:
llama3.1-8bからllama3.1-70bに変更されました。より大きなモデルを使うことで、ルールベースの指示をより正確に遂行できるようになっています。ただし、初期構成のllama3.1-8bと比べて推論コスト・レイテンシは増える可能性があります。本番ではllama3.1-8bでの最適化結果とllama3.1-70bでの最適化結果を比較し、品質とコストのトレードオフを確認する必要があります - 閾値の差異に注意: 最適化後のルールでは、元の定義にあった
vip_express(>= 3000)のカテゴリが明示的なルールとして含まれていません。これはdemo予算(少ない反復数)での最適化結果のため、データの分布(vip_expressが40件中2件のみ)を十分に学習しきれていない可能性があります。light以上の予算で再最適化することで改善が期待できます
実験結果の確認
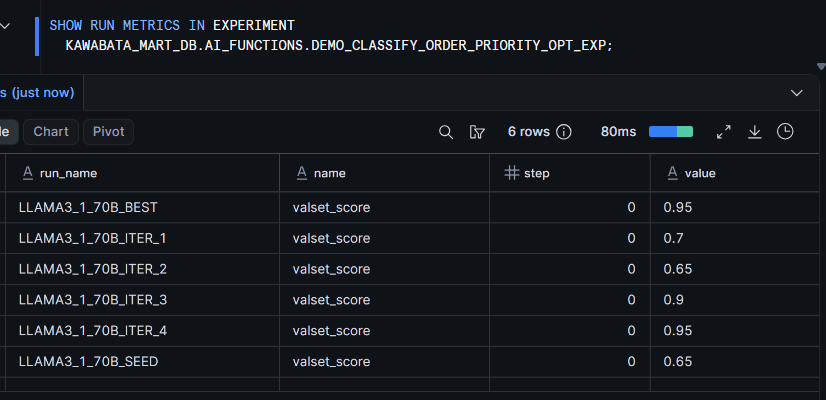
最適化の実験結果は SHOW RUN METRICS / SHOW RUN PARAMETERS で確認できます。
SHOW RUN METRICS IN EXPERIMENT
KAWABATA_MART_DB.AI_FUNCTIONS.DEMO_CLASSIFY_ORDER_PRIORITY_OPT_EXP;
本番利用時の考慮点
今回はトライアル環境でのクイック検証でしたが、本番利用を検討する場合は以下の点を確認しておくとよさそうです。
- 実データを使ったラベル付き評価データセットでも精度を確認する
- PIIや機密情報を含むデータを入力する場合は、マスキングやアクセス制御を検討する
USE AI FUNCTIONSアカウント権限とSNOWFLAKE.CORTEX_USER/SNOWFLAKE.AI_FUNCTIONS_USERデータベースロールの付与範囲を確認する
最後に
Cortex AI Function Studioを使い、Cortex CodeでCreate → Evaluate → Optimizeの全ワークフローを検証しました。手動でのプロンプトエンジニアリングからかなり効率化できる機能だと感じました。
今回は検証のため構造化データに対して行いましたが、Cortex AI Functionの強みである非構造化データへのアプローチがより力を発揮する機能と思います。
なお、本機能は2026年5月時点では Public Preview かつリージョン限定の機能のため、利用前に対象リージョンや最新の制約を確認することをおすすめします。今後のGA(一般提供)に期待したいです。
この記事が何かの参考になれば幸いです!








