
Amazon AthenaのPartition Projectionを設定したGlueテーブルをCloudFormationで作成してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部の若槻です。
Amazon AthenaではPartition Projectionを使用することにより、パーティション化されたデータソースへのクエリ処理を高速化したり、パーティション管理を自動化したりすることができます。
今回は、Amazon AthenaのPartition Projectionを設定したGlueテーブルをCloudFormationで作成してみました。
やってみた
具体的には、AWSの下記のドキュメントで紹介されている、Amazon Kinesis Data Firehoseが作成する/yyyy/MM/dd/HHというパスのパーティションに対するPartition ProjectionをCloudFormationで作成してみました。
環境作成
CloudFormationスタック
CloudFormationスタックのテンプレートです。
AWSTemplateFormatVersion: '2010-09-09'
Resources:
DevicesRawDataBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub devices-raw-data-${AWS::AccountId}-${AWS::Region}
DevicesDataAnalyticsGlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: devices_data_analystics
DevicesRawDataGlueTable:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName: !Ref DevicesDataAnalyticsGlueDatabase
TableInput:
Name: devices_raw_data
TableType: EXTERNAL_TABLE
Parameters:
has_encrypted_data: false
serialization.encoding: utf-8
EXTERNAL: true
projection.enabled: true
projection.datehour.type: date
projection.datehour.range: "2021/02/02/09,NOW"
projection.datehour.format: yyyy/MM/dd/HH
projection.datehour.interval: 1
projection.datehour.interval.unit: HOURS
storage.location.template:
!Join
- ''
- - !Sub s3://${DevicesRawDataBucket}/raw-data/
- '${datehour}'
StorageDescriptor:
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Columns:
- Name: device_id
Type: string
- Name: timestamp
Type: bigint
- Name: state
Type: boolean
InputFormat: org.apache.hadoop.mapred.TextInputFormat
Location: !Sub s3://${DevicesRawDataBucket}/raw-data
SerdeInfo:
Parameters:
paths: "device_id, timestamp, state"
SerializationLibrary: org.apache.hive.hcatalog.data.JsonSerDe
PartitionKeys:
- Name: datehour
Type: string
Glueテーブルのリソース定義DevicesRawDataGlueTableのProperties.TableInput.Parameters部分(ハイライト箇所1つ目)にてPartition Projectionの設定を行っています。Properties.TableInput.PartitionKeys部分(ハイライト箇所2つ目)がPartition Projectionの対象となるパーティションキーとなります。
スタックをデプロイします。
% aws cloudformation deploy \
--template-file template.yaml \
--stack-name devices-data-analytics-stack \
--capabilities CAPABILITY_NAMED_IAM \
--no-fail-on-empty-changeset
データ作成
データ作成時に使用する変数を定義しておきます。
% AWS_REGION=ap-northeast-1
% ACCOUNT_ID=$(aws sts get-caller-identity | jq -r ".Account")
% RAW_DATA_BUCKET=s3://devices-raw-data-${ACCOUNT_ID}-${AWS_REGION}
DevicesRawDataGlueTableのLocationとなるS3バケットのパスに、下記のそれぞれのパーティションパスを持つオブジェクトをデータとして作成します。
/2021/02/02/10/2021/02/02/11/2021/02/02/12
{"device_id": "device1", "timestamp": 1609348014, "state": true}
% aws s3 cp raw-data-1.json \
${RAW_DATA_BUCKET}/raw-data/2021/02/02/10/raw-data-1.json
{"device_id": "device2", "timestamp": 1609348014, "state": false}
% aws s3 cp raw-data-2.json \
${RAW_DATA_BUCKET}/raw-data/2021/02/02/11/raw-data-2.json
{"device_id": "device3", "timestamp": 1609348014, "state": false}
% aws s3 cp raw-data-3.json \
${RAW_DATA_BUCKET}/raw-data/2021/02/02/12/raw-data-3.json
動作確認
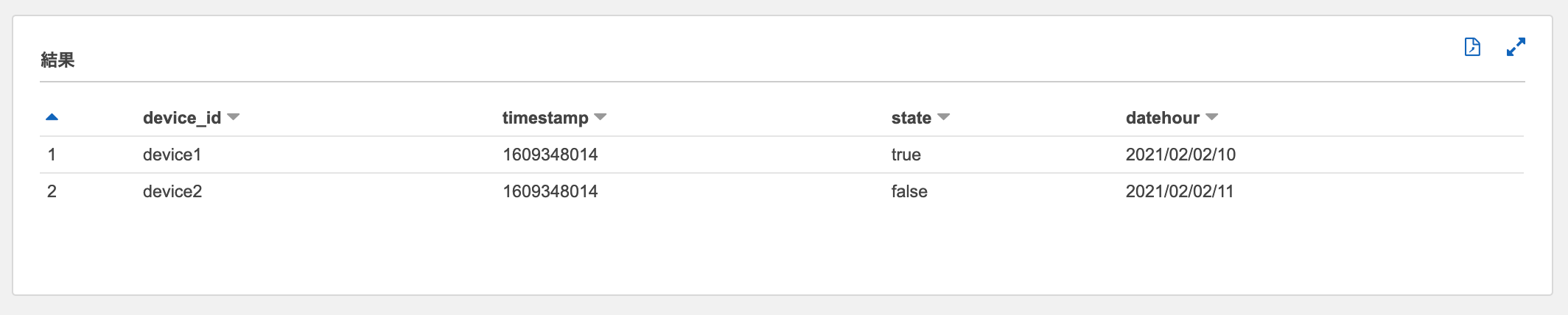
Athenaのマネジメントコンソールでクエリ実行時にPartition Projectionが動作することを確認してみます。
2021/02/02 20:10(JST)頃にテーブルに対して下記のSELECTクエリを実行したところ、projection.datehour.range: "2021/02/02/09,NOW"が作用して、ちゃんと20:10以前に該当するパーティション 2021/02/02/10および2021/02/02/11のデータのみを取得することができました。
SELECT * FROM "devices_data_analystics"."devices_raw_data"
Partition Projectionの仕様とSHOW PARTITIONSについて
AthenaでSHOW PARTITIONSクエリを使用すると、Glueテーブルに作成されているパーティションを取得することができます。
しかし、Partition Projectionが行っているのはテーブルへのパーティション作成や読み取りではなく、Athenaでのクエリ実行時に設定値からパーティションパターンを計算してパーティションプルーニングする(データを全スキャンせず計算結果に基づいたパーティションのデータのみスキャンする)ことです。
よってPartition Projectionが有効であるテーブルであっても、下記のようにSHOW PARTITIONSを使用したとしても、別の方法で明示的にテーブルにパーティションが作成されていない限りはパーティションは取得されない動作となります。
SHOW PARTITIONS devices_data_analystics.devices_raw_data
ドキュメントにもよく見たら考慮事項としてこのことが書かれていますね。
The following considerations apply:
- Because partition projection is a DML-only feature, SHOW PARTITIONS does not list partitions that are projected by Athena but not registered in the AWS Glue catalog or external Hive metastore.
おわりに
Amazon AthenaのPartition Projectionを設定したGlueテーブルをCloudFormationで作成してみました。
Glueクローラーや定期実行Lambdaを使わずともパーティションを自動作成してくれるのはやはりすごく便利ですね。使えるところではPartition Projectionをガンガン使っていきたいと思います。
参考
- [新機能]Amazon Athena ルールベースでパーティションプルーニングを自動化する Partition Projection の徹底解説 | Developers.IO
- Amazon Kinesis Data Firehose Example - Amazon Athena
- Fn::Join - AWS CloudFormation
以上










