![[AWS Glue]SparkとPython Shellのジョブを組み合わせたETLフローを作ってみた](https://devio2023-media.developers.io/wp-content/uploads/2019/04/aws-glue.png)
[AWS Glue]SparkとPython Shellのジョブを組み合わせたETLフローを作ってみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部の若槻です。
AWS Glueは、データ変換処理(ETL)をサーバーレスで実装できるAWSサービスです。
今回は、AWS GlueでSparkとPython Shellのジョブを組み合わせたETLフローを作ってみました。
2つのジョブタイプの違い
AWS GlueのジョブにはSparkとPython Shellの2つのジョブタイプがあります。
Sparkタイプは、Apache Sparkを使用したデータの分散処理が可能なため、大規模データのETL処理に向いています。
Python Shellタイプは、Python3.6(または2.7)環境を使用したスクリプトの実行が可能なため、Sparkタイプを使う程ではないがGlueジョブとして実行させたい処理に向いています。
なぜ2つのジョブタイプを組み合わせたか
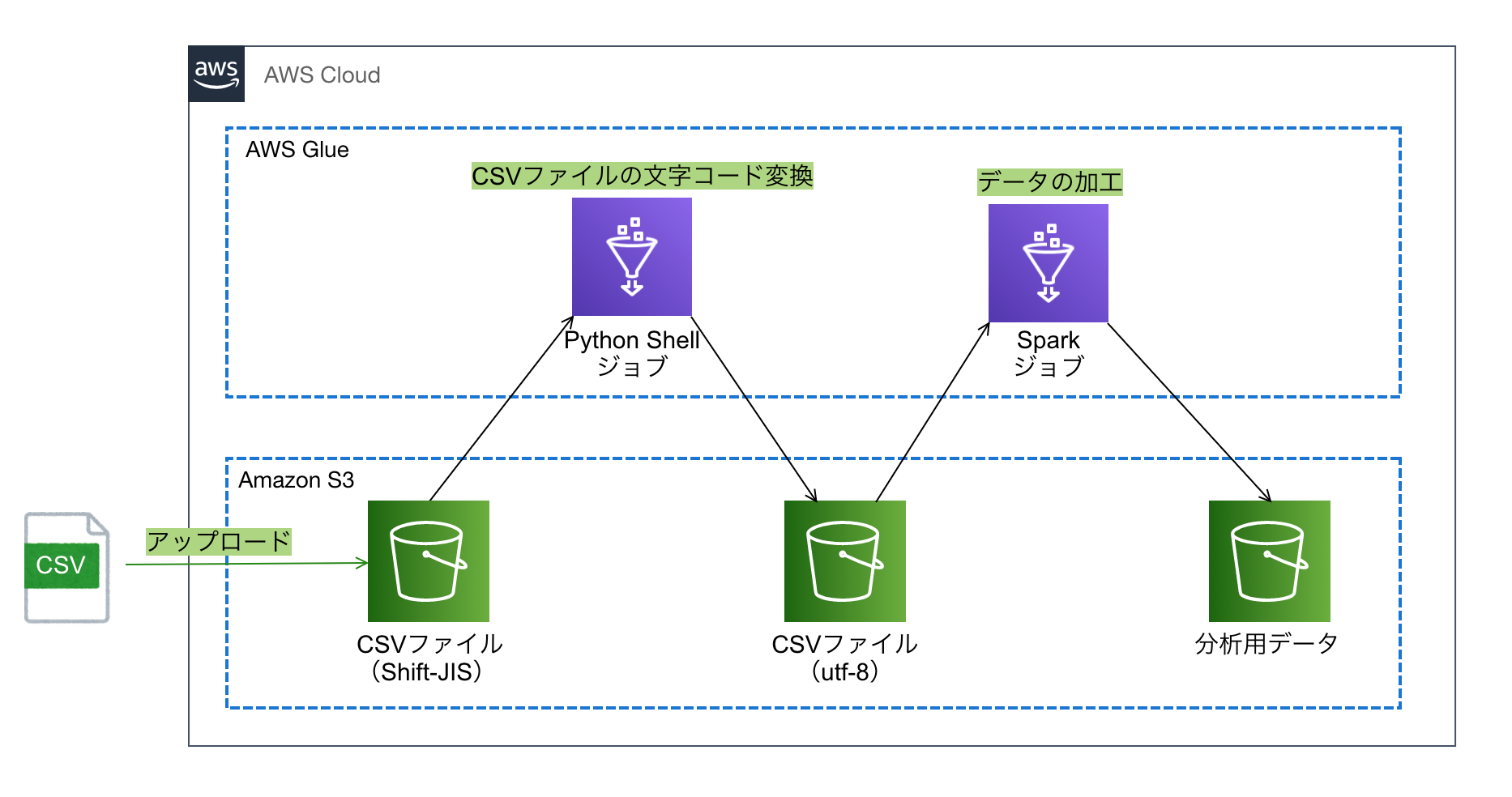
今回、データソースとして、データが記載されたShift-JIS形式のCSVファイルがS3バケットに1日1回アップロードされます。このデータを加工してS3バケットに保管する日次実行のETL処理をAWS Glueで作成しようとしました。
当初はSparkタイプのジョブ1つで対応できると考えていましたが、確認したところSparkジョブではutf-8形式のデータのみにしか対応していないことが分かりました。
そこで次の通りPython ShellとSparkのジョブを組み合わせることにより、行いたいETL処理の実現を図りました。
- CSVファイルの文字コード変換 -> Python Shellジョブ
- データの加工 -> Sparkジョブ
作ってみた
次のような構成のETLフローを作成してみました。
CloudFormationテンプレート
AWSTemplateFormatVersion: '2010-09-09'
Resources:
DevicesRawDataBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub devices-raw-data-${AWS::AccountId}-${AWS::Region}
DevicesDataAnalyticsBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub devices-data-analytics-${AWS::AccountId}-${AWS::Region}
DevicesGlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: devices_data_analystics
DevicesRawDataGlueTable:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName: !Ref DevicesGlueDatabase
TableInput:
Name: devices-raw-data-glue-table
TableType: EXTERNAL_TABLE
Parameters:
skip.header.line.count: 1
has_encrypted_data: false
serialization.encoding: utf-8
EXTERNAL: true
StorageDescriptor:
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Columns:
- Name: 端末ID
Type: string
- Name: イベント日時
Type: bigint
- Name: 状態
Type: string
InputFormat: org.apache.hadoop.mapred.TextInputFormat
Location: !Sub s3://${DevicesRawDataBucket}/utf8-data
SerdeInfo:
Parameters:
field.delim: ","
serialization.format: ","
SerializationLibrary: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
DevicesIntegratedDataGlueTable:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName: !Ref DevicesGlueDatabase
TableInput:
Name: devices-integrated-data-glue-table
TableType: EXTERNAL_TABLE
Parameters:
skip.header.line.count: 1
has_encrypted_data: false
serialization.encoding: utf-8
EXTERNAL: true
StorageDescriptor:
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Columns:
- Name: device_id
Type: string
- Name: timestamp
Type: bigint
- Name: status
Type: string
InputFormat: org.apache.hadoop.mapred.TextInputFormat
Location: !Sub s3://${DevicesDataAnalyticsBucket}/integrated-data
SerdeInfo:
Parameters:
field.delim: ","
serialization.format: ","
SerializationLibrary: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
ExecuteDevicesGlueJobRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
-
Effect: Allow
Principal:
Service:
- glue.amazonaws.com
Action:
- sts:AssumeRole
Policies:
- PolicyName: execute-devices-glue-job-policy
PolicyDocument:
Version: 2012-10-17
Statement:
-
Effect: Allow
Action:
- glue:StartJobRun
Resource:
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:job/devices-sjis-to-utf8
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:job/devices-etl
-
Effect: Allow
Action:
- glue:GetPartition
- glue:GetPartitions
- glue:GetTable
Resource:
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:catalog
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:database/${DevicesGlueDatabase}
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:table/${DevicesGlueDatabase}/${DevicesRawDataGlueTable}
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:table/${DevicesGlueDatabase}/${DevicesIntegratedDataGlueTable}
-
Effect: Allow
Action:
- glue:GetJobBookmark
Resource:
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:table/${DevicesGlueDatabase}/${DevicesRawDataGlueTable}
-
Effect: Allow
Action:
- s3:ListBucket
- s3:GetBucketLocation
Resource:
- arn:aws:s3:::*
-
Effect: Allow
Action:
- logs:CreateLogStream
- logs:CreateLogGroup
- logs:PutLogEvents
Resource:
- !Sub arn:aws:logs:${AWS::Region}:${AWS::AccountId}:log-group:/aws-glue/jobs/*
- !Sub arn:aws:logs:${AWS::Region}:${AWS::AccountId}:log-group:/aws-glue/python-jobs/*
-
Effect: Allow
Action:
- s3:GetObject
Resource:
- !Sub arn:aws:s3:::${DevicesRawDataBucket}/sjis-data/*
- !Sub arn:aws:s3:::${DevicesDataAnalyticsBucket}/glue-job-script/devices-sjis-to-utf8.py
- !Sub arn:aws:s3:::${DevicesDataAnalyticsBucket}/glue-job-script/devices-etl.py
-
Effect: Allow
Action:
- s3:GetObject
- s3:PutObject
Resource:
- !Sub arn:aws:s3:::${DevicesDataAnalyticsBucket}/glue-job-temp-dir/*
- !Sub arn:aws:s3:::${DevicesRawDataBucket}/utf8-data/*
-
Effect: Allow
Action:
- s3:PutObject
Resource:
- !Sub arn:aws:s3:::${DevicesDataAnalyticsBucket}/integrated-data/*
-
Effect: Allow
Action:
- s3:DeleteObject
Resource:
- !Sub arn:aws:s3:::${DevicesRawDataBucket}/sjis-data/*
DevicesETLGlueJob:
Type: AWS::Glue::Job
Properties:
Name: devices-etl
Command:
Name: glueetl
PythonVersion: 3
ScriptLocation: !Sub s3://${DevicesDataAnalyticsBucket}/glue-job-script/devices-etl.py
DefaultArguments:
--job-language: python
--job-bookmark-option: job-bookmark-enable
--TempDir: !Sub s3://${DevicesDataAnalyticsBucket}/glue-job-temp-dir
--GLUE_DATABASE_NAME: !Sub ${DevicesGlueDatabase}
--SRC_GLUE_TABLE_NAME: !Sub ${DevicesRawDataGlueTable}
--DEST_GLUE_TABLE_NAME: !Sub ${DevicesIntegratedDataGlueTable}
GlueVersion: 2.0
ExecutionProperty:
MaxConcurrentRuns: 1
MaxRetries: 0
Role: !Ref ExecuteDevicesGlueJobRole
DevicesSJIStoUTF8GlueJob:
Type: AWS::Glue::Job
Properties:
Name: devices-sjis-to-utf8
Command:
Name: pythonshell
PythonVersion: 3
ScriptLocation: !Sub s3://${DevicesDataAnalyticsBucket}/glue-job-script/devices-sjis-to-utf8.py
DefaultArguments:
--TempDir: !Sub s3://${DevicesDataAnalyticsBucket}/glue-job-temp-dir
--RAW_DATA_BUCKET_NAME: !Sub ${DevicesRawDataBucket}
--SRC_OBJECT_KEY: sjis-data/raw-sjis-data.csv
--SRC_FILE_ENCODING: shift_jis
--DEST_OBJECT_PREFIX: utf8-data
ExecutionProperty:
MaxConcurrentRuns: 1
MaxRetries: 0
Role: !Ref ExecuteDevicesGlueJobRole
DevicesAnalyticsGlueWorkflow:
Type: AWS::Glue::Workflow
Properties:
Name: devices-analytics-workflow
DevicesSJIStoUTF8JobGlueTrigger:
Type: AWS::Glue::Trigger
Properties:
WorkflowName: !Ref DevicesAnalyticsGlueWorkflow
Name: devices-sjis-to-utf8-job-glue-trigger
Type: ON_DEMAND
Actions:
- JobName: !Ref DevicesSJIStoUTF8GlueJob
DevicesETLJobGlueTrigger:
Type: AWS::Glue::Trigger
Properties:
WorkflowName: !Ref DevicesAnalyticsGlueWorkflow
Name: devices-etl-job-glue-trigger
Type: CONDITIONAL
Actions:
- JobName: !Ref DevicesETLGlueJob
Predicate:
Conditions:
- LogicalOperator: EQUALS
JobName: !Ref DevicesSJIStoUTF8GlueJob
State: SUCCEEDED
StartOnCreation: true
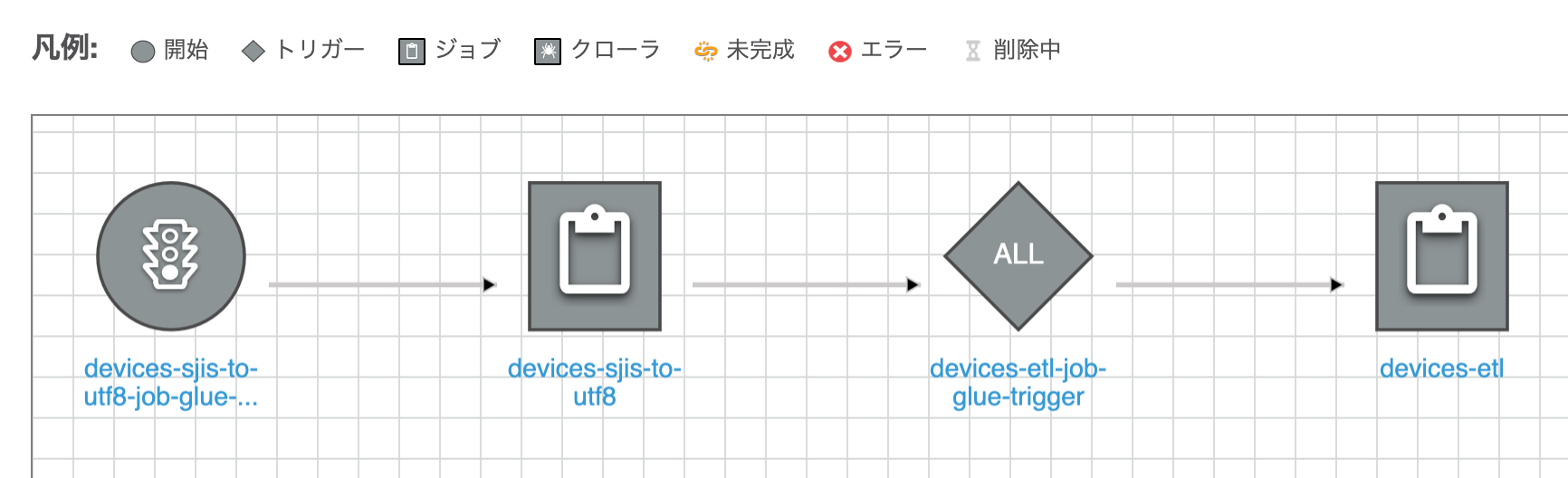
Glueワークフローは次のようになります。CSVファイルの文字コード変換を行うジョブ(devices-sjis-to-utf8)の実行が成功したら、データを加工するジョブ(devices-etl)が実行されます。
スクリプト
Python Shellジョブ
S3バケットからShift-JIS形式のファイルを取得し、UTF-8形式に変換して同じS3バケットの別のプレフィクスにPutします。
import boto3
import sys
import uuid
from awsglue.utils import getResolvedOptions
# ジョブパラメータの読み込み
args = getResolvedOptions(sys.argv, ['BUCKET_NAME', 'SRC_OBJECT_KEY', 'SRC_FILE_ENCODING', 'DEST_OBJECT_PREFIX'])
# S3 Service Resource 準備
s3 = boto3.resource('s3')
# ファイルを文字コード変換してロード
src_obj = s3.Object(args['BUCKET_NAME'], args['SRC_OBJECT_KEY'])
body = src_obj.get()['Body'].read().decode(args['SRC_FILE_ENCODING'])
# ファイルを保存
dest_obj_file_name = str(uuid.uuid4())
dest_obj = s3.Object(args['BUCKET_NAME'], args['DEST_OBJECT_PREFIX'] + '/' + dest_obj_file_name)
dest_obj.put(Body = body)
# ファイルを削除
src_obj.delete()
Sparkジョブ
データソースからデータを取得して、列名を変更する加工を行い、データターゲットにInsertしています。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'GLUE_DATABASE_NAME', 'SRC_GLUE_TABLE_NAME', 'DEST_GLUE_TABLE_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = args['GLUE_DATABASE_NAME'], table_name = args['SRC_GLUE_TABLE_NAME'], transformation_ctx = "datasource0")
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("端末id", "string", "device_id", "string"), ("イベント日時", "bigint", "timestamp", "bigint"), ("状態", "string", "status", "string")], transformation_ctx = "applymapping1")
selectfields2 = SelectFields.apply(frame = applymapping1, paths = ["device_id", "timestamp", "status"], transformation_ctx = "selectfields2")
resolvechoice3 = ResolveChoice.apply(frame = selectfields2, choice = "MATCH_CATALOG", database = args['GLUE_DATABASE_NAME'], table_name = args['DEST_GLUE_TABLE_NAME'], transformation_ctx = "resolvechoice3")
datasink4 = glueContext.write_dynamic_frame.from_catalog(frame = resolvechoice3, database = args['GLUE_DATABASE_NAME'], table_name = args['DEST_GLUE_TABLE_NAME'], transformation_ctx = "datasink4")
job.commit()
デプロイ
CloudFormationスタックをデプロイします。
% aws cloudformation deploy \
--template-file template.yaml \
--stack-name devices-data-analytics-stack \
--capabilities CAPABILITY_NAMED_IAM \
--no-fail-on-empty-changeset
GlueジョブのスクリプトをS3バケットにアップロードします。
% ACCOUNT_ID=<Account ID>
% AWS_REGION=<AWS Region>
% aws s3 cp devices-etl.py s3://devices-data-analytics-${ACCOUNT_ID}-${AWS_REGION}/glue-job-script/devices-etl.py
% aws s3 cp devices-sjis-to-utf8.py s3://devices-data-analytics-${ACCOUNT_ID}-${AWS_REGION}/glue-job-script/devices-sjis-to-utf8.py
使ってみる
CSVファイルを作成して加工対象のデータを記載します。
端末ID,イベント日時,状態
7d4215d0,1608976046746,開始
e36b7dfa,1608976059078,開始
7d4215d0,1608976150001,停止
CSVファイルをShift-JIS形式に変換して、S3バケットにアップロードします。
% iconv -f utf8 -t sjis raw-utf8-data.csv > raw-sjis-data.csv
% aws s3 cp raw-sjis-data.csv s3://devices-raw-data-${ACCOUNT_ID}-${AWS_REGION}/sjis-data/raw-sjis-data.csv
Glueワークフローを実行します。
% aws glue start-workflow-run --name devices-analytics-workflow
ワークフローが正常に実行されました。
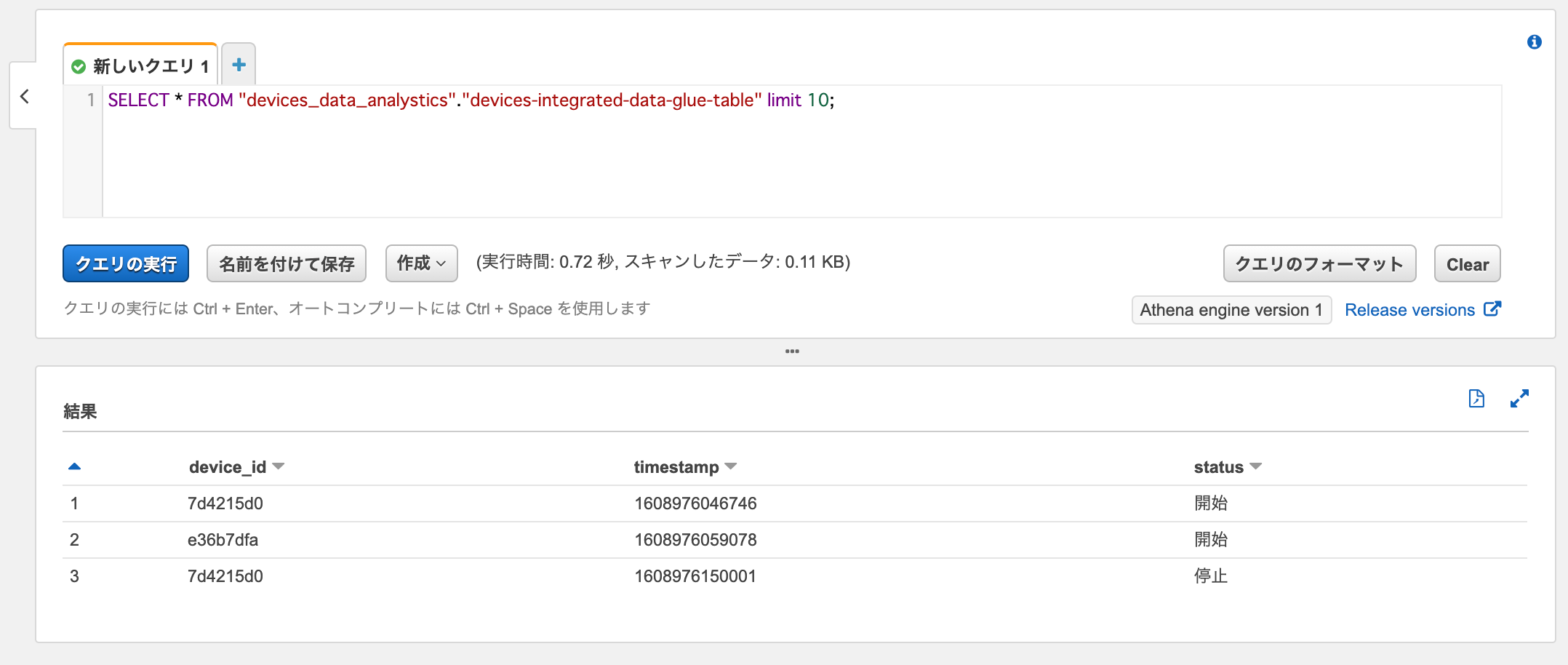
Athenaで分析用データに対してSelectクエリを実行すると、データが取得できました。
SELECT * FROM "devices_data_analystics"."devices-integrated-data-glue-table" limit 10;
おわりに
AWS GlueでSparkとPython Shellのジョブを組み合わせたETLフローを作ってみました。
やりようによっては、「CSVファイルの文字コード変換」と「データの加工」を同種類のジョブで実行したり、単一のジョブにまとめたりできるかもしれませんが、役割の分離やデータ数が大きくなった時を考慮すると今回のような構成が良いかと思います。
参考
- Building Serverless Analytics Pipelines with AWS Glue (ANT308) - AWS …
- GlueのPython Shellジョブでファイルの文字コードを変更してみた | Developers.IO
- AWS::Glue::Trigger - AWS CloudFormation
- 【 iconv 】コマンド――文字コードを変換する:Linux基本コマンドTips(46) - @IT
以上









