![[AWS Glue]ViewテーブルをAWS CLIで作成してみた](https://devio2023-media.developers.io/wp-content/uploads/2019/04/aws-glue.png)
[AWS Glue]ViewテーブルをAWS CLIで作成してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部の若槻です。
Amazon Athenaでは、Glueのテーブルタイプの一つであるViewを使用することにより、実行するクエリを単純化したり、動的に変わるクエリを固定のクエリで実行するようにすることができます。
このViewテーブルはAthenaでCREATE VIEWクエリを使用することにより作成できますが、AWS CLIのglue create-tableコマンドを使用して作成することも可能です。
今回は、AWS GlueのViewテーブルをAWS CLIのglue create-tableコマンドで作成してみました。
やってみた
まず最初に以降のコマンド実行で使用する変数を定義しておきます。
% AWS_REGION=ap-northeast-1
% ACCOUNT_ID=$(aws sts get-caller-identity | jq -r ".Account")
% RAW_DATA_BUCKET=s3://devices-raw-data-${ACCOUNT_ID}-${AWS_REGION}
% GLUE_DATABASE_NAME=devices_data_analystics
% RAW_DATA_GLUE_TABLE_NAME=devices_raw_data
% ATHENA_WORK_GROUP_NAME=devices-data-analytics
環境作成
CloudFormationスタック
CloudFormationスタックのテンプレートです。
AWSTemplateFormatVersion: '2010-09-09'
Resources:
DevicesRawDataBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub devices-raw-data-${AWS::AccountId}-${AWS::Region}
DevicesDataAnalyticsAthenaWorkGroup:
Type: AWS::Athena::WorkGroup
Properties:
Name: devices-data-analytics
WorkGroupConfiguration:
ResultConfiguration:
OutputLocation: !Sub s3://${DevicesRawDataBucket}/query-result
EnforceWorkGroupConfiguration: true
PublishCloudWatchMetricsEnabled: true
DevicesDataAnalyticsGlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: devices_data_analystics
DevicesRawDataGlueTable:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName: !Ref DevicesDataAnalyticsGlueDatabase
TableInput:
Name: devices_raw_data
TableType: EXTERNAL_TABLE
Parameters:
has_encrypted_data: false
serialization.encoding: utf-8
EXTERNAL: true
StorageDescriptor:
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Columns:
- Name: device_id
Type: string
- Name: timestamp
Type: bigint
- Name: state
Type: boolean
InputFormat: org.apache.hadoop.mapred.TextInputFormat
Location: !Sub s3://${DevicesRawDataBucket}/raw-data
SerdeInfo:
Parameters:
paths: "device_id, timestamp, state"
SerializationLibrary: org.apache.hive.hcatalog.data.JsonSerDe
Viewが参照するテーブルをリソースDevicesRawDataGlueTableで定義しています。
スタックをデプロイします。
% aws cloudformation deploy \
--template-file template.yaml \
--stack-name devices-data-analytics-stack \
--capabilities CAPABILITY_NAMED_IAM \
--no-fail-on-empty-changeset
データ作成
DevicesRawDataGlueTableのLocationとなるS3バケットのパスにデータとしてオブジェクトraw-data.jsonを作成します。
@
```shell
% aws s3 cp raw-data.json \
${RAW_DATA_BUCKET}/raw-data/raw-data.json
Viewの作成
AWS CLIのglue create-tableコマンドを使用してdevices_raw_data_viewという名前のViewテーブルを作成します。
まずcreate-tableのTableInputパラメータで指定する値を作成します。
Viewが実行するSQLクエリをファイルで定義します。
@
`eval "echo \"$(cat originalsql.sql)\""`によりSQLクエリを変数に格納します。(`eval`によりファイルの記述内の変数を展開しています)
```shell
% original_sql=$(eval "echo \"$(cat originalsql.sql)\"")
% echo $original_sql
SELECT * FROM devices_raw_data
TableInputのViewOriginalTextパラメータで指定する値をファイルで定義します。(先程作成したSQLクエリをoriginalSqlパラメータに指定しています)
{
\"originalSql\":\"${original_sql}\",
\"catalog\":\"awsdatacatalog\",
\"schema\":\"${GLUE_DATABASE_NAME}\",
\"columns\":[
{
\"name\":\"device_id\",
\"type\":\"varchar\"
},
{
\"name\":\"timestamp\",
\"type\":\"bigint\"
},
{
\"name\":\"state\",
\"type\":\"boolean\"
}
]
}
※ここでViewOriginalTextの値の作成時の注意点として、columnsでのtypeで文字列型を指定したい場合は、参照元のテーブルでの型の指定のされ方に関わらず、上記のハイライト部分のようにvarcharを指定する必要があります。stringを指定した場合はViewの作成自体はできますが、作成されたViewに対してクエリを実行すると下記のようなエラーが出て失敗します。
INVALID_VIEW: Invalid view JSON: { "originalSql":"SELECT * FROM devices_raw_data", "catalog":"awsdatacatalog", "schema":"devices_data_analystics", "columns":[ { "name":"device_id", "type":"string" }, { "name":"timestamp", "type":"bigint" }, { "name":"state", "type":"boolean" } ] }
eval "echo \"$(cat vieworiginaltext.json)\""によりViewOriginalTextの値を変数に格納します。(evalによりファイルの記述内の変数を展開しています)
% view_original_text=$(eval "echo \"$(cat vieworiginaltext.json)\"")
$ echo $view_original_text
{
"originalSql":"SELECT * FROM devices_raw_data",
"catalog":"awsdatacatalog",
"schema":"devices_data_analystics",
"columns":[
{
"name":"device_id",
"type":"varchar"
},
{
"name":"timestamp",
"type":"bigint"
},
{
"name":"state",
"type":"boolean"
}
]
}
ViewOriginalTextの値をBase64エンコードして変数に格納します。
% view_original_text_b64encoded=$(echo -n $view_original_text | base64)
TableInputパラメータで指定する値をファイルで定義します。ここまでで作成したViewOriginalTextの値のBase64エンコードをViewOriginalTextパラメータで使用します。
{
\"Name\": \"devices_raw_data_view\",
\"TableType\": \"VIRTUAL_VIEW\",
\"Parameters\": {
\"presto_view\": \"true\"
},
\"ViewOriginalText\": \"/* Presto View: ${view_original_text_b64encoded} */\",
\"ViewExpandedText\": \"/* Presto View */\",
\"StorageDescriptor\": {
\"SerdeInfo\": {},
\"Columns\": [
{
\"Name\":\"device_id\",
\"Type\":\"string\"
},
{
\"Name\":\"timestamp\",
\"Type\":\"bigint\"
},
{
\"Name\":\"state\",
\"Type\":\"boolean\"
}
]
}
}
eval "echo \"$(cat tableinput.json)\""により変数を展開したTableInputの値を--table-inputに指定し、glue create-tableによりViewを作成します。
% tableinput=$(eval "echo \"$(cat tableinput.json)\"")
% aws glue create-table \
--database-name ${GLUE_DATABASE_NAME} \
--table-input ${tableinput}
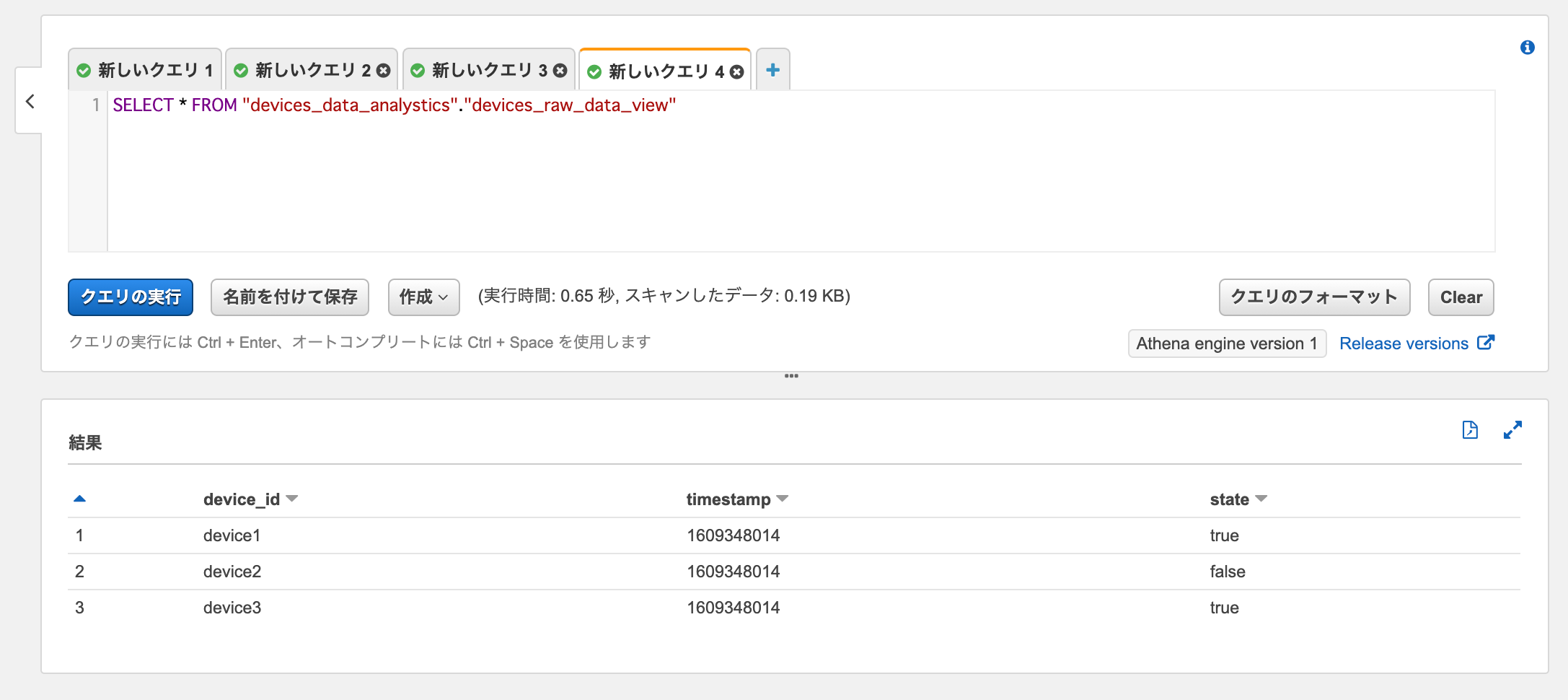
作成したViewテーブルdevices_raw_data_viewに対してSELECTクエリを実行すると、オリジナルのSQLによりGlueテーブルのデータが取得できました。
SELECT * FROM "devices_data_analystics"."devices_raw_data_view"
おわりに
AWS GlueのViewテーブルをAWS CLIのglue create-tableコマンドで作成してみました。
TableInputのViewOriginalTextパラメータでBase64エンコードしての指定が必要となるなど少々面倒な部分はありましたが、Athenaでのクエリ実行でない方法を今回確立出来て良かったです。
参考
- [AWS Glue]データカタログのパーティションをAWS CLIで更新してみた | Developers.IO
- Shellでもbase64 - Qiita
- AWS Glueデータカタログへのテーブルの作成とAthenaでのクエリ実行をAWS CLIでやってみた | Developers.IO
- amazon web services - External View query works in athena console but fails to work when using it in aws quicksight - Stack Overflow
- Create Virtual Views with AWS Glue and Query them Using Athena — Ujjwal Bhardwaj
- 整形済みJSON文字列を1行JSONに変換(圧縮)する - Qiita
以上









