
Databricks Knowledge Assistantは日本語PDFをどこまで扱えるのか試してみた
さがらです。
DatabricksのKnowledge Assistantは、2026年1月13日に一般提供(GA)となった機能です。
Knowledge Assistantは、PDFやPowerPointなどのドキュメントを読み込み、引用付きで回答してくれるフルマネージドなナレッジQAエージェントを構築できる機能です。
これまでRAGを自分で実装しようとすると、ドキュメントのチャンク化・埋め込みモデルの選定・Vector Search Indexの構築・品質評価…と多くの工程が必要でした。Knowledge Assistantを使うと、これらの多くをDatabricks側に任せつつ、UI中心でエージェントを作成できます。
ただし、後述の通り公式ドキュメントの制限事項には 「Only English is supported.」 と明記されており、現時点では日本語ドキュメントは正式にはサポートされていません。
とはいえ「実際に日本語PDFを読ませると、どこまで動くのか/どんな挙動になるのか」が気になったため、本記事では弊社クラスメソッドの決算報告書(3期分)と会社紹介資料のPDFを題材に、あえて日本語PDFでKnowledge Assistantを試してみた検証記録 をまとめます。
以前、同じPDFを題材にSnowflakeのCortex Agentsで検証した記事も書いています。
機能概要
Knowledge Assistantは、Databricks上でドキュメントQA向けのエージェントを構築するためのフルマネージド機能です。知識ソースとして以下を指定できます。
- Unity Catalog Volume / Volume配下ディレクトリのファイル
- Mosaic AI Vector Searchインデックス
Knowledge AssistantはInstructed Retrieverアプローチを採用しており、従来型RAGの制約に対処しながら、与えたドキュメントに基づく高品質な回答を返すことが公式ドキュメントで説明されています。
また、作成したエージェントはアプリケーションから利用可能なagent endpointとしてデプロイされ、AI PlaygroundやAPI経由で利用できます。
制限事項
2026年4月17日時点で、公式ドキュメント上の主な制限事項は以下です。
- 対応言語は英語のみ(Only English is supported.)
- サポートされるファイル形式は
txt、pdf、md、ppt/pptx、doc/docx - 50MBを超えるファイルは自動的にスキップ
- ファイル名が
_または.で始まるファイルは自動的にスキップ - Unity Catalogテーブルは知識ソースとして非対応
- Vector Search Indexは、
databricks-gte-large-enを埋め込みモデルとして使っているもののみ対応
今回検証する日本語PDFは公式には非対応ですが、本記事では 「制限事項に書かれている通り日本語ではどの程度厳しいのか」 を確認する目的で進めていきます。
前提条件
- Databricks: Express SetupでサインアップしたAWS環境のトライアルアカウント
- 参考ブログ
- Free Editionでは本機能は使用できないため、ご注意ください
事前準備
分析対象PDFの取得
今回はクラスメソッド公式サイトで公開されている以下のPDFをダウンロードして使用します。
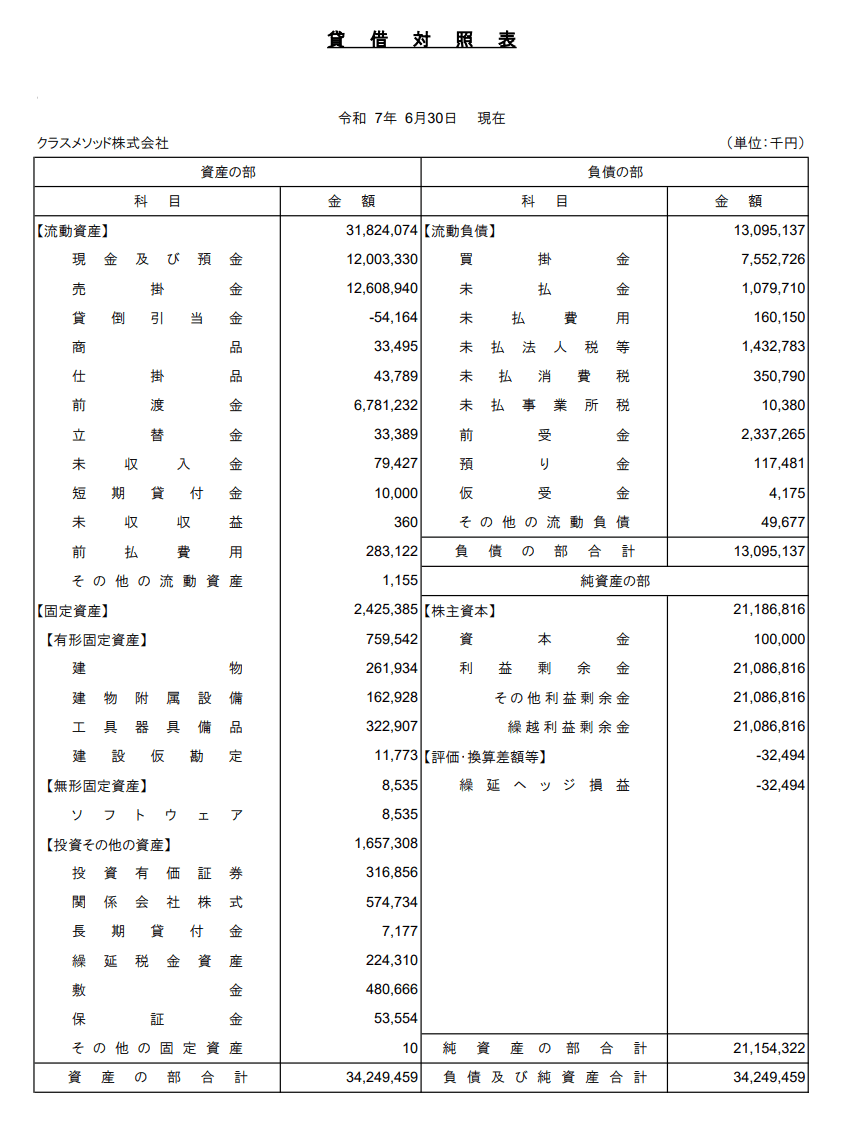
決算報告書
以下のリンク先から取得した、3期分のPDFを使用します。
下図のようなファイルです。

会社紹介資料
以下のリンク先から取得したPDFを使用します。
下図のようなファイルです。
Unity Catalog Volumeの作成とPDFアップロード
Knowledge Assistantの知識ソースとして使うため、Unity Catalog配下にVolumeを作成します。
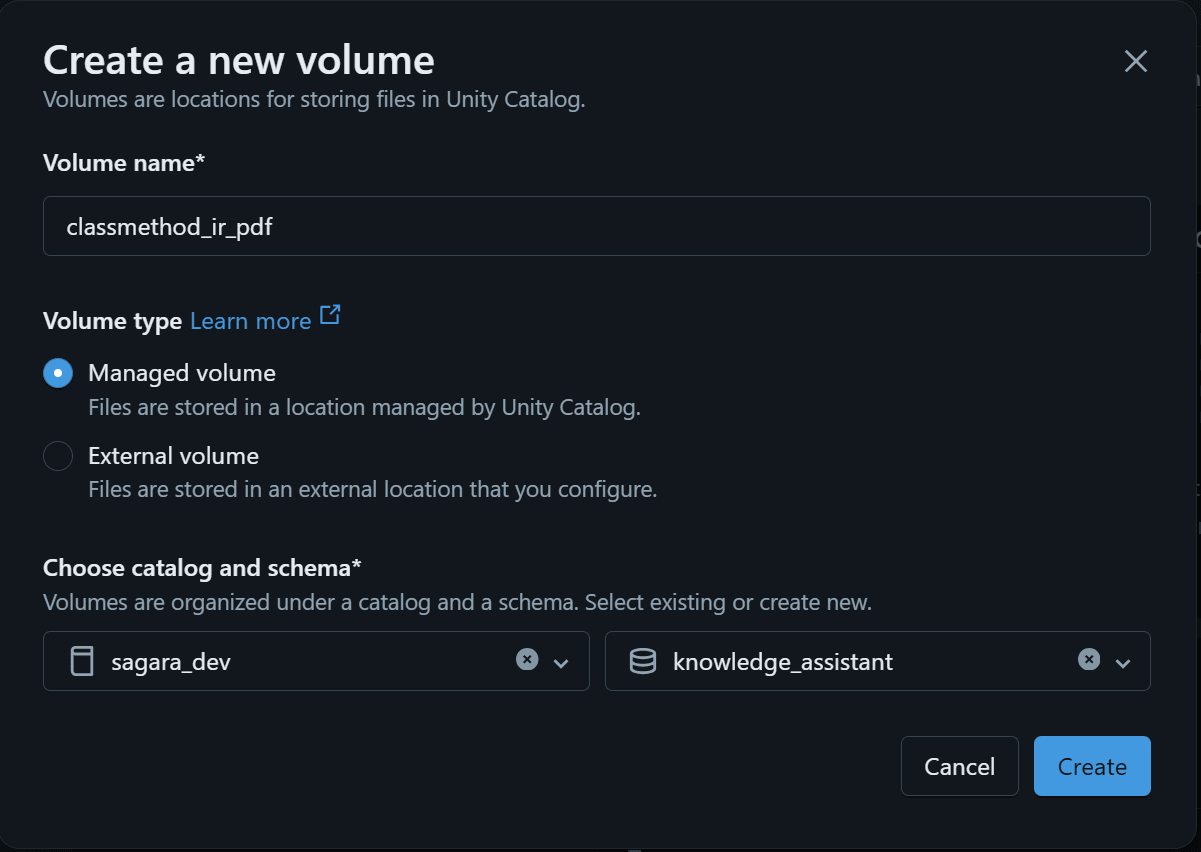
DatabricksワークスペースでCatalogを開き、対象のCatalog・Schema配下でCreate → Volumeを選択します。
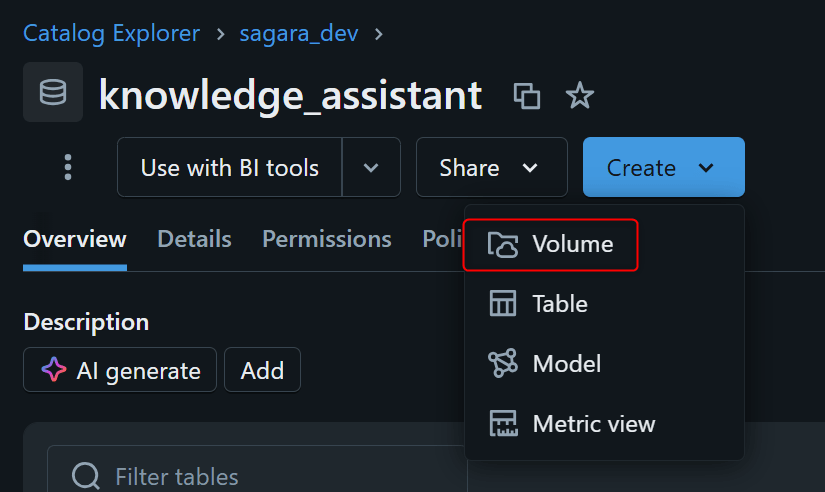
今回は例として以下の名前で作成しました。
- Catalog:
sagara_dev - Schema:
knowledge_assistant - Volume:
classmethod_ir_pdf
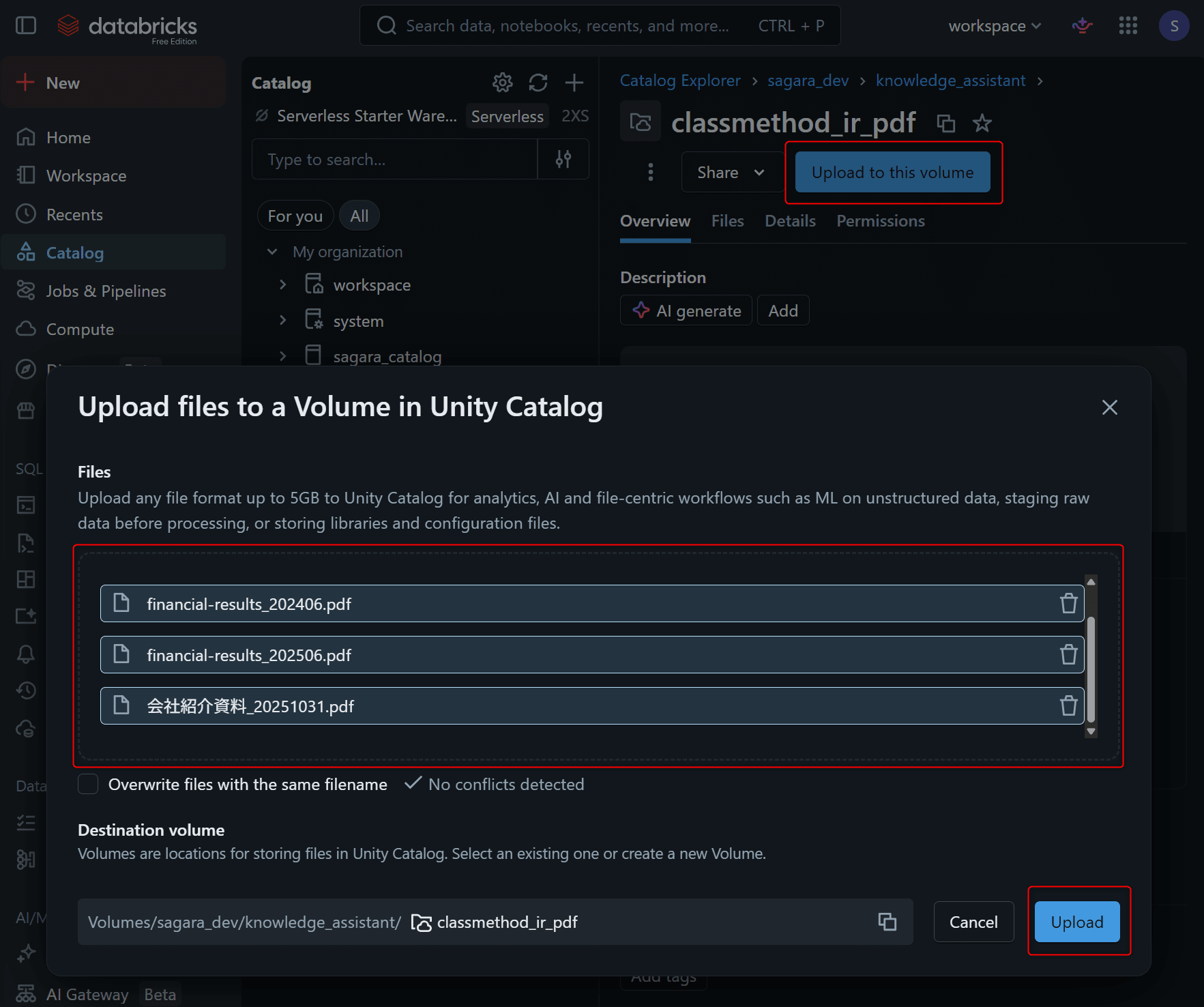
作成したVolumeを開き、Upload to this volumeからダウンロードしておいた4つのPDFをアップロードします。
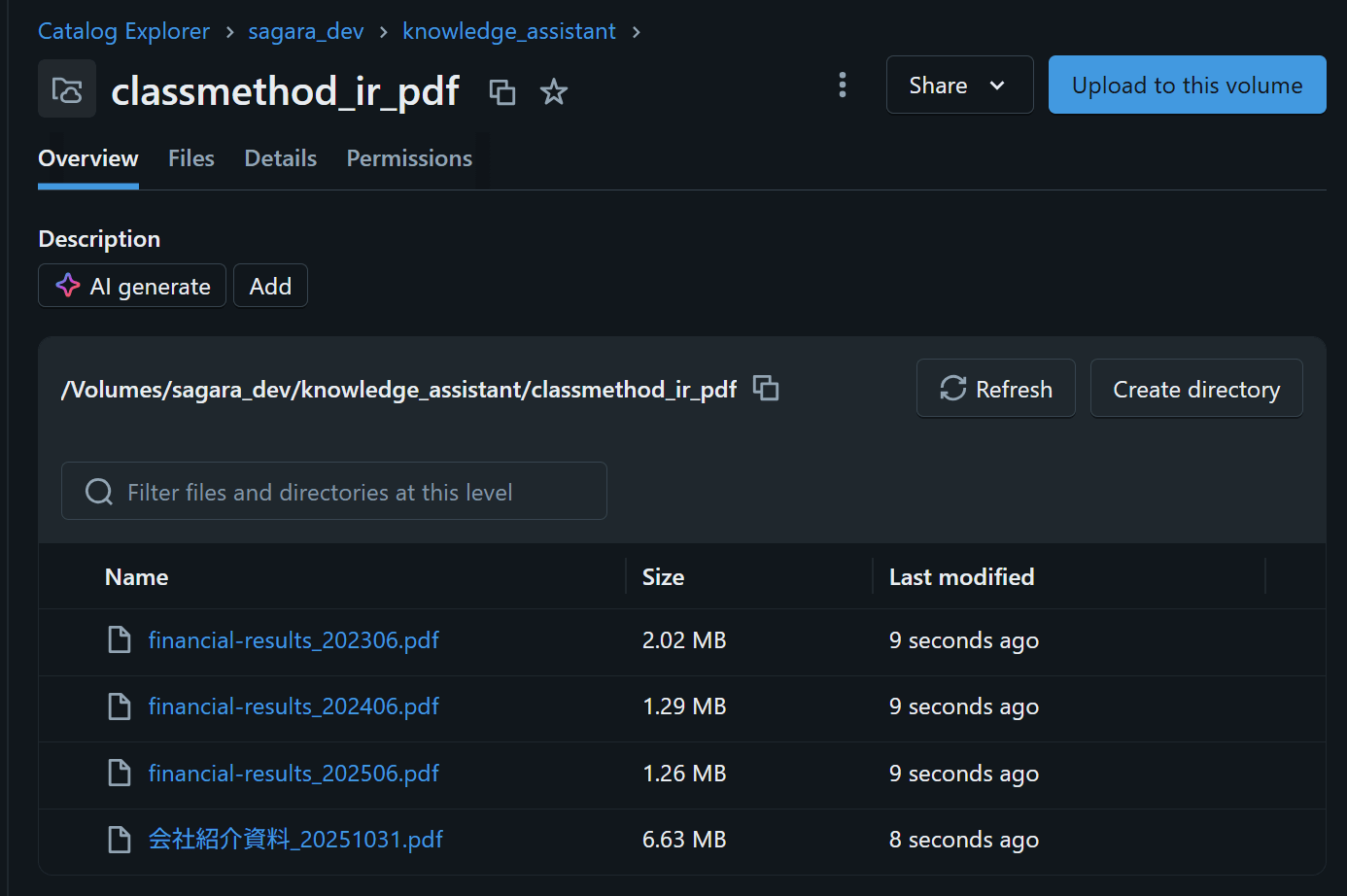
アップロード完了後、4つのPDFがVolume内にリストされていればOKです。
試してみた
1. Knowledge Assistantエージェントの作成
左ナビゲーションのAgentsを開き、Create Agent → Knowledge Assistantを選択します。
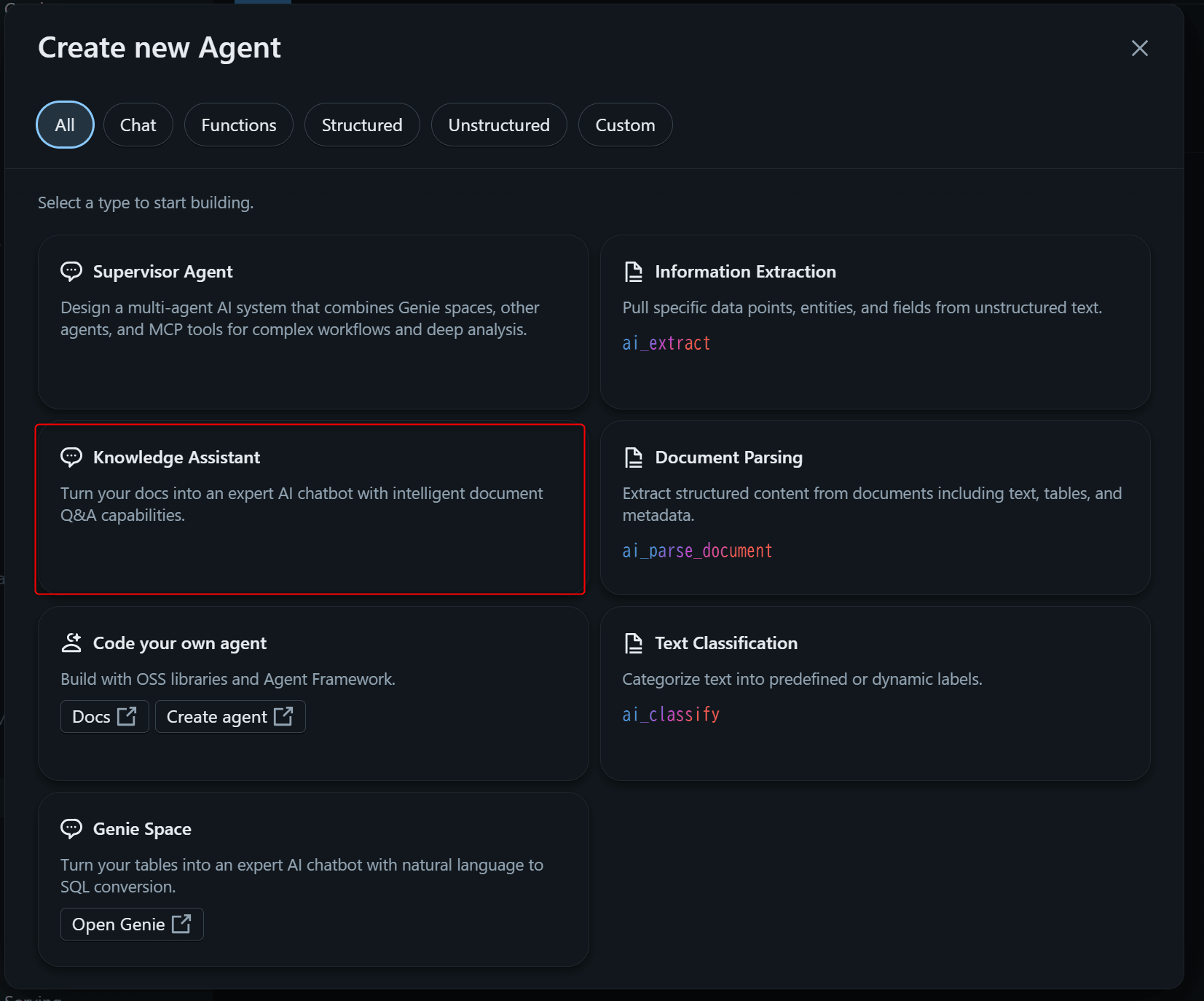
まずは以下を入力します。
- Name:
classmethod-ir-assistant - Description:
クラスメソッド公式の決算報告書と会社説明会資料について質問ができるエージェントです
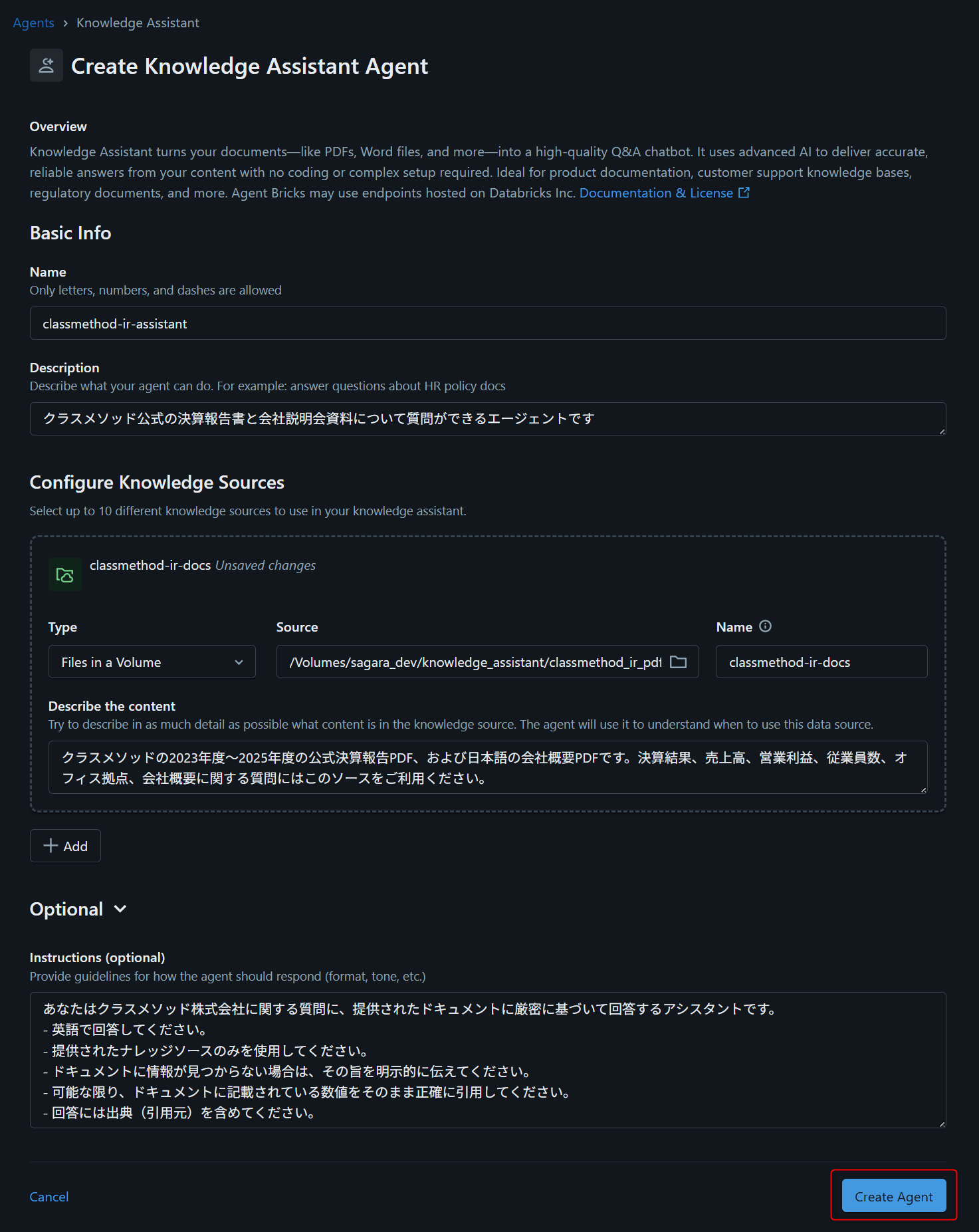
続いてConfigure Knowledge Sourcesパネルでknowledge sourceを追加します。今回はVolume上のPDFを使うので、UC Filesを選択します。
設定例:
- Type:
UC Files - Source:
sagara_dev.knowledge_assistant.classmethod_ir_pdf - Name:
classmethod-ir-docs - Describe the content:
クラスメソッドの2023年度〜2025年度の公式決算報告PDF、および日本語の会社概要PDFです。決算結果、売上高、営業利益、従業員数、オフィス拠点、会社概要に関する質問にはこのソースをご利用ください。
最後にInstructionsフィールドに応答ガイドラインを記入します。今回は以下のように設定してみました。
あなたはクラスメソッド株式会社に関する質問に、提供されたドキュメントに厳密に基づいて回答するアシスタントです。
- 英語で回答してください。
- 提供されたナレッジソースのみを使用してください。
- ドキュメントに情報が見つからない場合は、その旨を明示的に伝えてください。
- 可能な限り、ドキュメントに記載されている数値をそのまま正確に引用してください。
- 回答には出典(引用元)を含めてください。
- 回答は日本語でお願いします。
必要に応じてAdd knowledge sourceから追加ソースも設定できます。Knowledge Assistantでは最大10個まで knowledge sourceを追加可能です。
全て入力を終えると下図のような状態になると思います。入力内容を確認したらCreate Agentをクリックします。
2. エージェント作成完了まで待機
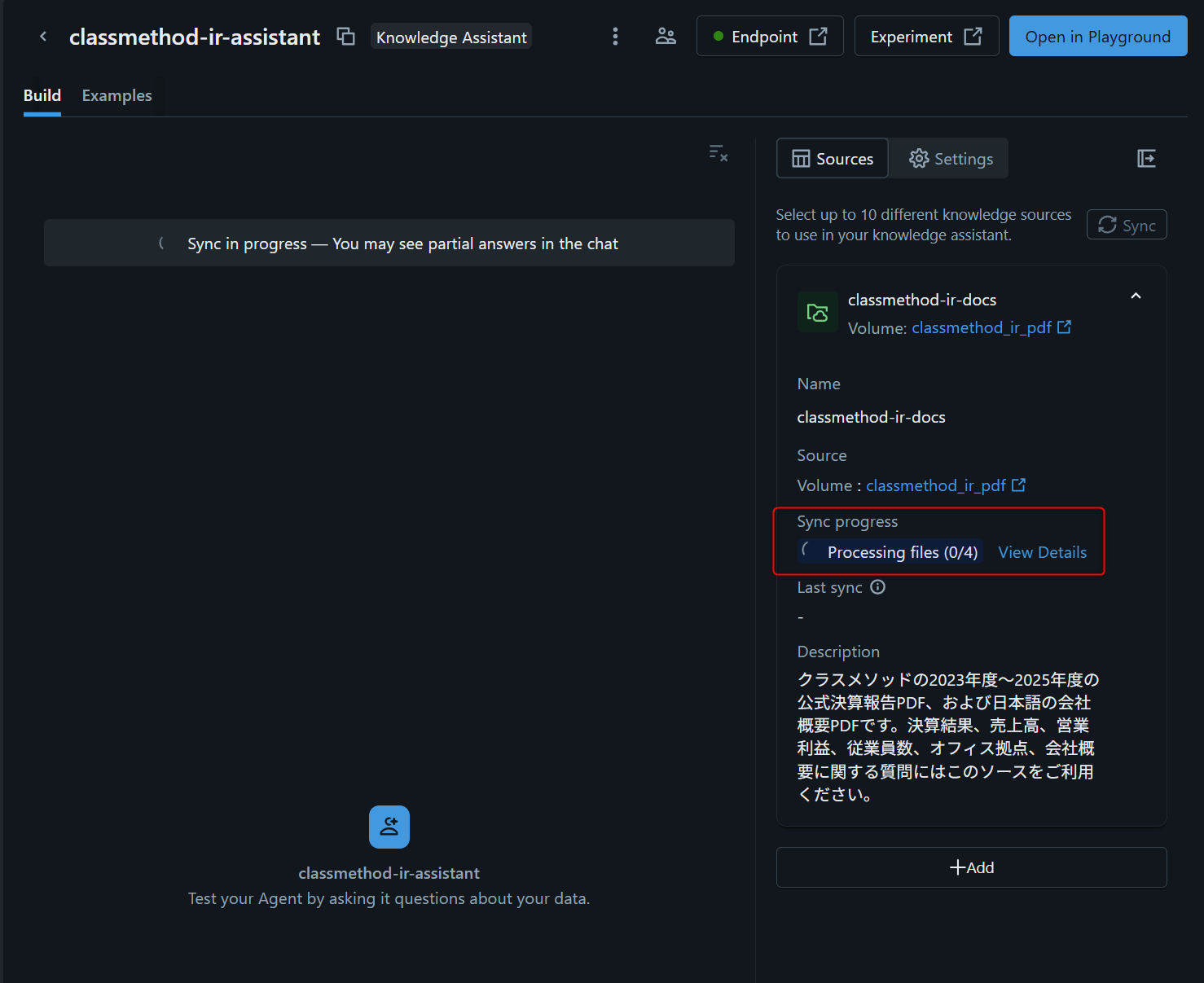
下図のようにエージェントの画面が表示されますが、赤枠の通りドキュメントの処理に時間がかかります。この処理が終わるまで待機します。
※公式ドキュメントでは、エージェント作成とknowledge source同期に数時間かかる場合があると記載されています。
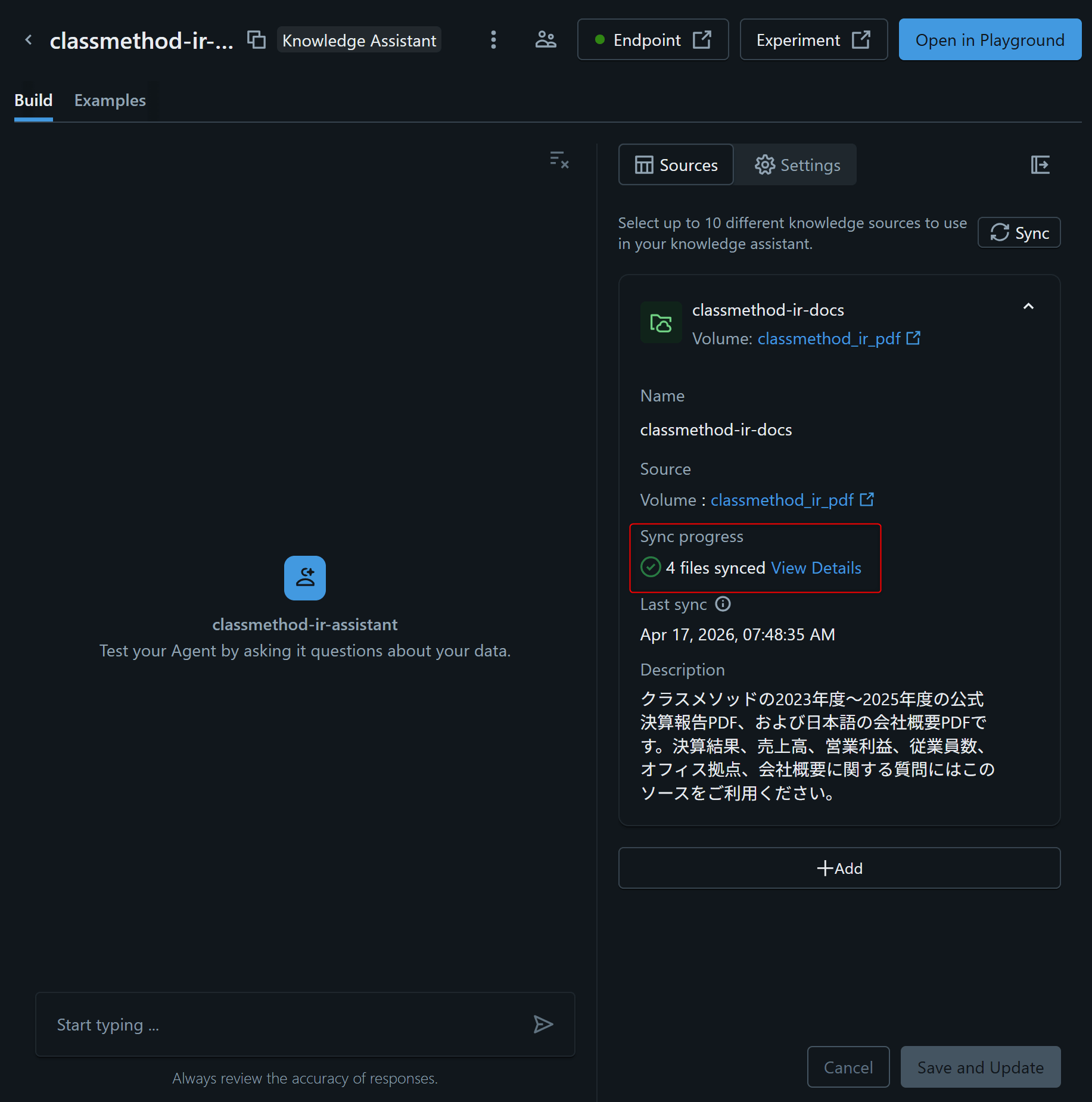
処理が完了すると、下図のように表示されます。(今回の場合は、1時間ほどで完了しました。)
これで準備完了です!
3. Buildタブ / AI Playgroundで質問してみる
Knowledge Assistantは、作成後にBuildタブ上でそのままチャットできます。必要に応じてOpen in Playgroundをクリックし、AI Playgroundで試すこともできます。
ここから、日本語PDFに対してどこまで回答できるかを確認していきます。
質問1: 売上高と営業利益
各会計年度の売上高と営業利益を教えてください。
下図のように結果が返ってきました。3年分のPDFを取り込ませていたのですが、何度聞いても19期分のデータしか取り出すことができませんでした。日本語PDFのテキスト抽出・チャンク化がうまくいっておらず、ドキュメント全体を横断的に拾えていない可能性が高そうです。

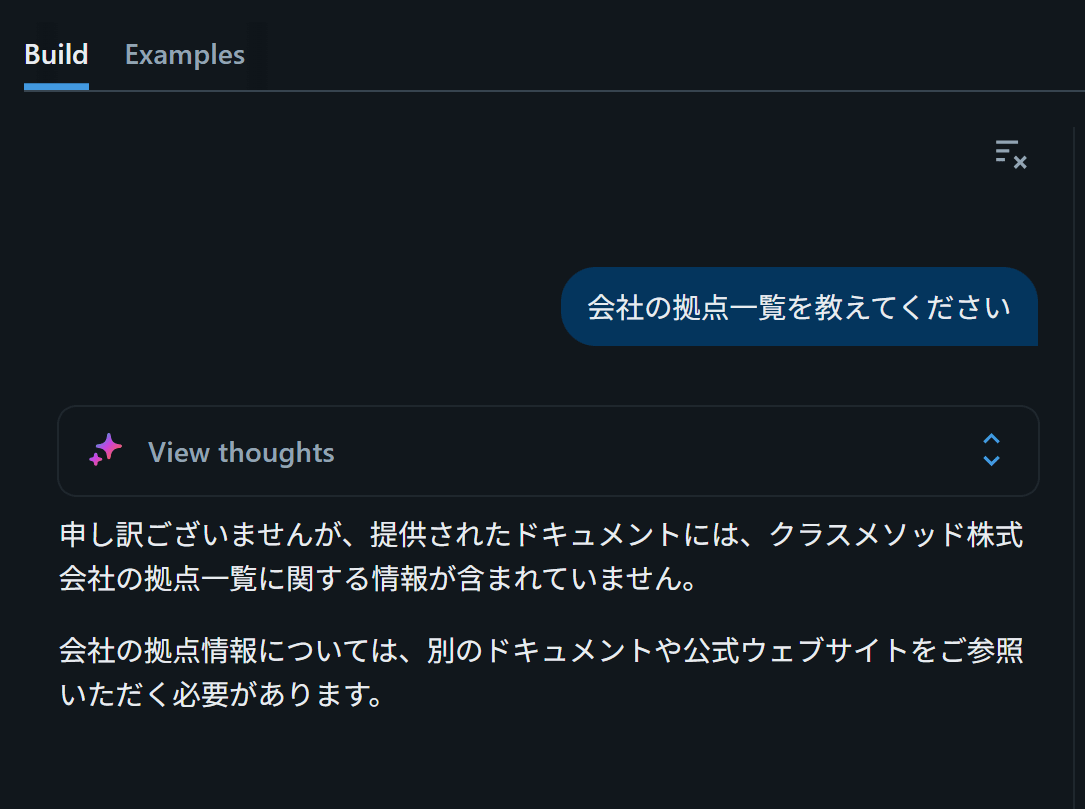
質問2: 拠点一覧
会社の拠点一覧を教えてください
下図のように結果が返ってきました。会社紹介資料には拠点一覧のページが含まれているのですが、こちらも回答を得ることはできませんでした。日本語PDF特有のレイアウト(縦書き・複数カラム・図中テキスト等)が読み取れていないと推測されます。
公式ドキュメントの 「Only English is supported.」 という制限事項通り、日本語PDFに対しては期待した精度での回答を得ることはできませんでした。
最後に
DatabricksのKnowledge Assistantを使って、クラスメソッドの決算資料・会社紹介資料(いずれも日本語PDF)を題材に、公式には非対応の日本語ドキュメントでどこまで動くか を試してみました。
Unity Catalog VolumeにPDFをアップロードし、Knowledge Assistantでknowledge sourceとして指定するだけで、比較的短い手順で引用付きのドキュメントQAチャットボットを構築できる体験自体は非常に強力だと感じました。
一方で、公式ドキュメントの制限事項に明記されている通り、現時点(2026年4月17日時点)では日本語PDFはうまく読み取れず、十分な回答精度は得られない という結果になりました。今回の検証でも以下のような挙動が確認できました。
- 3期分の決算PDFを入れても、特定の年度(19期)の数値しか拾えない
- 会社紹介資料の拠点一覧ページに記載がある内容も回答できない
そのため、日本語ドキュメントを対象としたナレッジQAエージェントを構築したい場合は、
- Knowledge Assistantが日本語に対応するまで待つ
- もしくは、日本語対応している他の手段(Mosaic AI Vector Searchなど用いたカスタムRAG実装等)を検討する
といった選択肢が現実的かと思います。
英語ドキュメントを対象とするユースケースであれば、Knowledge Assistantは非常に有力な選択肢になりそうです。日本語対応のアップデートにも期待したいです!








