
Databricks Lakeflow Spark Declarative PipelinesのCDCチュートリアルを試してみた
さがらです。
Databricksでは、バッチ/ストリーミングのデータパイプラインを宣言的に構築できるフレームワークとして Lakeflow Spark Declarative Pipelines が提供されています。Flow、Streaming Table、Materialized View、Sink をパイプラインとしてまとめて定義でき、依存関係の解決や実行順序のオーケストレーションを Databricks 側に任せられます。AUTO CDC は Lakeflow Spark Declarative Pipelines 固有のストリーミングフローで、SCD Type 1 / Type 2 の両方をサポートします。
CDC(Change Data Capture)データを取り込みながら Bronze / Silver / Gold レイヤーを構築するチュートリアルが公開されていたので、今回はこちらを SQL で試してみた内容をまとめます。
機能概要
Lakeflow Spark Declarative Pipelines は、SQL または Python でデータパイプラインを宣言的に定義し、Databricks が依存関係・更新順序・増分処理を管理してくれる仕組みです。特に今回のような CDC パイプラインでは、Auto Loader による取り込み、expectations によるデータ品質チェック、AUTO CDC による最新スナップショット/履歴テーブルの構築までを一貫して記述できます。
主な構成要素は以下です。
- Flows: データを読み込み、処理し、ターゲットに書き込む基本単位
- 代表的なものは Append flow と AUTO CDC flow
- Streaming Tables: Unity Catalog managed table として公開されるストリーミングターゲット
- Materialized Views: バッチターゲットとして公開される Unity Catalog managed table
- Sinks: Delta tables、Apache Kafka topics、Azure EventHubs topics、custom Python data sources への出力先
- Pipelines: 上記要素をまとめて開発・実行する単位
前提条件
- Databricks:Free Edition
事前準備
Catalog と Schema の確認
Lakeflow Spark Declarative Pipelines では、出力先の Default Catalog / Schema をパイプライン作成時に指定します。今回は以下を使います。
- Catalog:
sagara_dev - Schema:
lakeflow_tutorial
Catalog Explorer で対象の Catalog / Schema が存在することを確認しておきます。まだ Schema がなければ先に作成しておきます。
試してみた
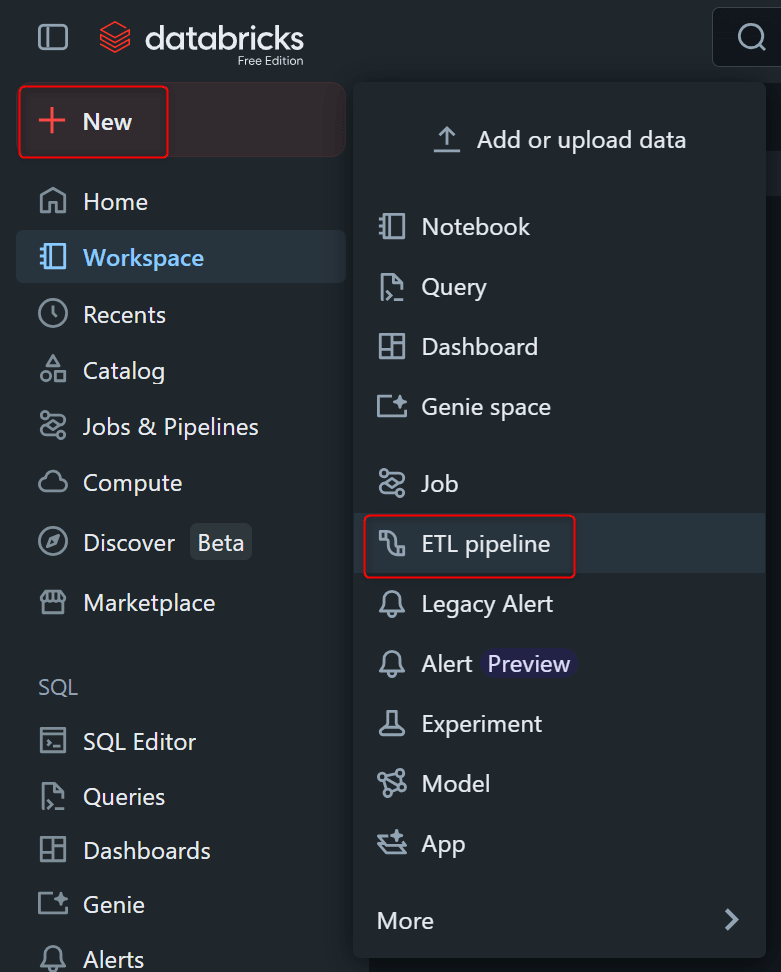
1. ETL Pipeline を作成する
Databricks workspace で、左上の New → ETL Pipeline を選択します。(ログインしているユーザーのHomeフォルダにフォルダが作られます。)
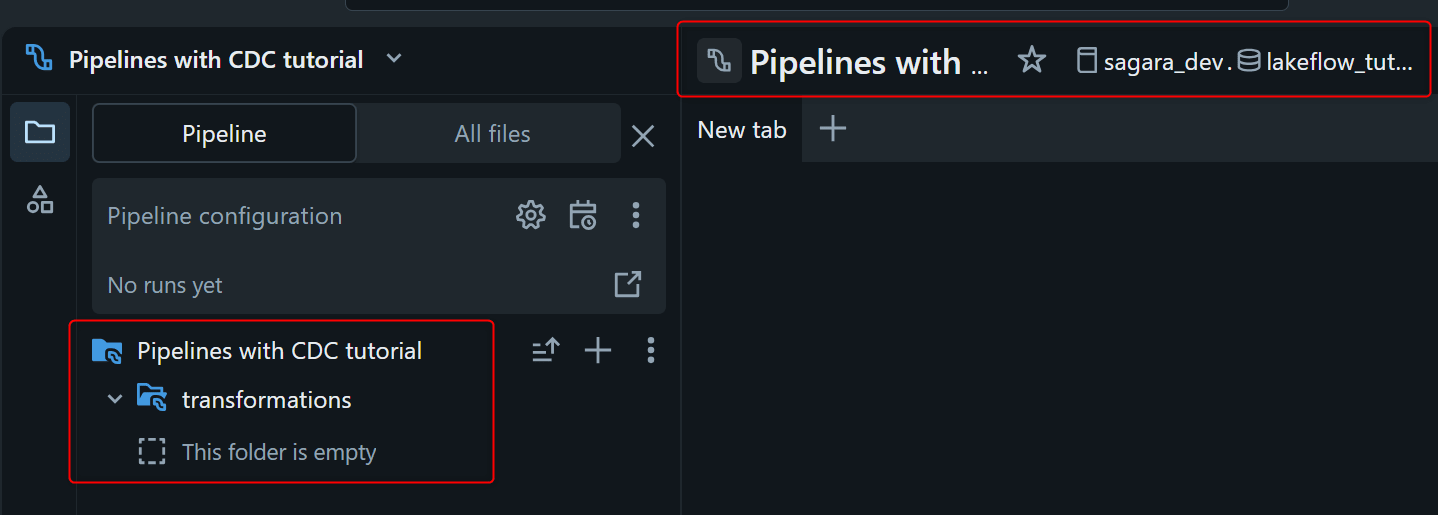
Lakeflow Pipelines Editor が開きますので、以下のように設定します。
- Title及びフォルダ名:
Pipelines with CDC tutorial- デフォルトで存在する
transformationsフォルダはそのまま使うので残しておく(中にあるmy_transformation.pyのみ削除する)
- デフォルトで存在する
- Default catalog:
sagara_dev - Default schema:
lakeflow_tutorial
設定後、下図のようになっていればOKです。
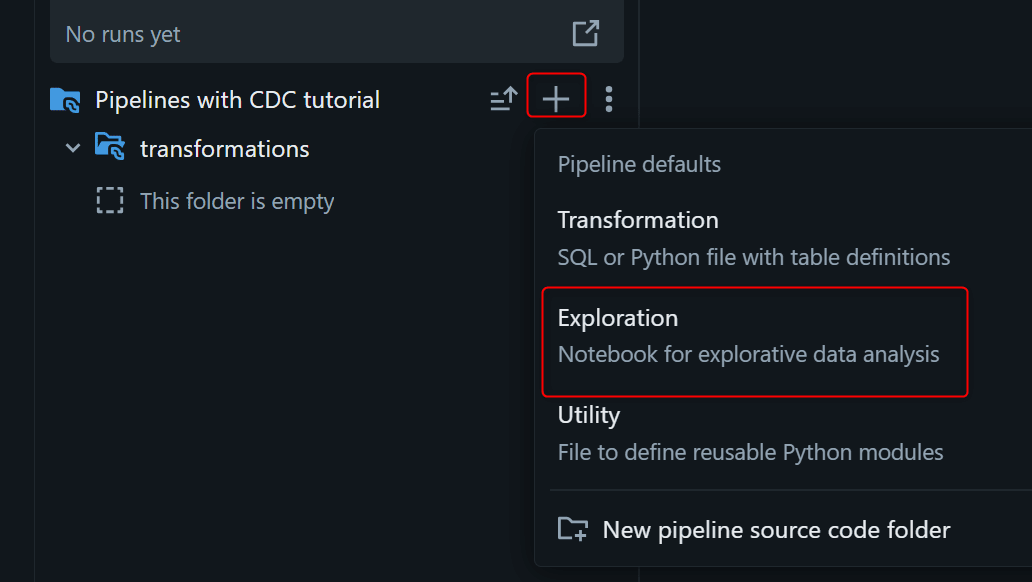
2. Exploration でサンプルデータを作成する
外部の CDC システムの代わりに、JSON ファイルを自前で生成します。これは pipeline update の対象外である explorations folder 配下の notebook で実行します。
Lakeflow Pipelines Editor 左側の asset browser から + → Exploration を選び、Python notebook を作成します。
以下のコードを、3 つのセルに分けて貼り付けて実行します。なお 2 つ目のセル(dbutils.library.restartPython())は元のチュートリアルにはありませんが、1 つ目で %pip install faker を実行した直後にそのまま 3 つ目のセルを動かすとカーネルに反映されずエラーになったため、faker を確実に読み込ませる目的で間に挟んでいます。
%pip install faker
# %pip install の結果をカーネルに反映させるために追加
dbutils.library.restartPython()
catalog = "sagara_dev"
schema = "lakeflow_tutorial"
spark.sql(f'USE CATALOG `{catalog}`')
spark.sql(f'USE SCHEMA `{schema}`')
spark.sql(f'CREATE VOLUME IF NOT EXISTS `{catalog}`.`{schema}`.`raw_data`')
volume_folder = f"/Volumes/{catalog}/{schema}/raw_data"
try:
dbutils.fs.ls(volume_folder + "/customers")
print("customers folder already exists, skip generating data")
except:
print(f"folder doesn't exist, generating data under {volume_folder}...")
from pyspark.sql import functions as F
from faker import Faker
from collections import OrderedDict
import uuid, random
fake = Faker()
fake_firstname = F.udf(fake.first_name)
fake_lastname = F.udf(fake.last_name)
fake_email = F.udf(fake.ascii_company_email)
fake_date = F.udf(lambda: fake.date_time_this_month().strftime("%m-%d-%Y %H:%M:%S"))
fake_address = F.udf(fake.address)
operations = OrderedDict([("APPEND", 0.5), ("DELETE", 0.1), ("UPDATE", 0.3), (None, 0.01)])
fake_operation = F.udf(lambda: fake.random_elements(elements=operations, length=1)[0])
fake_id = F.udf(lambda: str(uuid.uuid4()) if random.uniform(0, 1) < 0.98 else None)
df = spark.range(0, 100000).repartition(100)
df = df.withColumn("id", fake_id())
df = df.withColumn("firstname", fake_firstname())
df = df.withColumn("lastname", fake_lastname())
df = df.withColumn("email", fake_email())
df = df.withColumn("address", fake_address())
df = df.withColumn("operation", fake_operation())
df_customers = df.withColumn("operation_date", fake_date())
df_customers.repartition(100).write.format("json").mode("overwrite").save(volume_folder + "/customers")
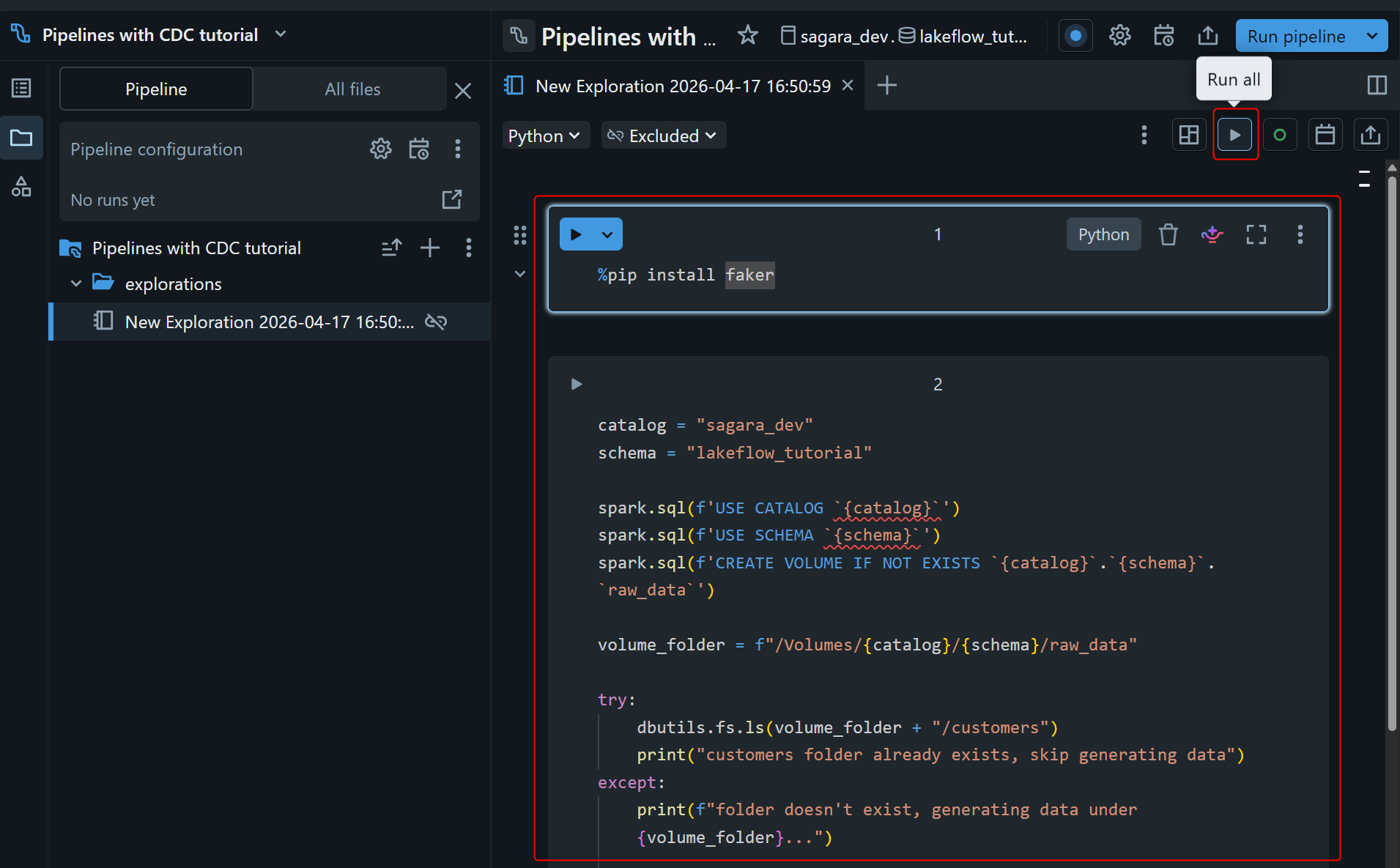
1 つ目・2 つ目のセルを実行してカーネルを再起動したあと、3 つ目のセルを実行します。実行完了までに、1 分~2 分ほどかかります。完了すると folder doesn't exist, generating data under /Volumes/sagara_dev/lakeflow_tutorial/raw_data... と出力され、100 partitions 分の JSON ファイル(合計 20 MB 前後)が raw_data volume 配下に書き込まれます。
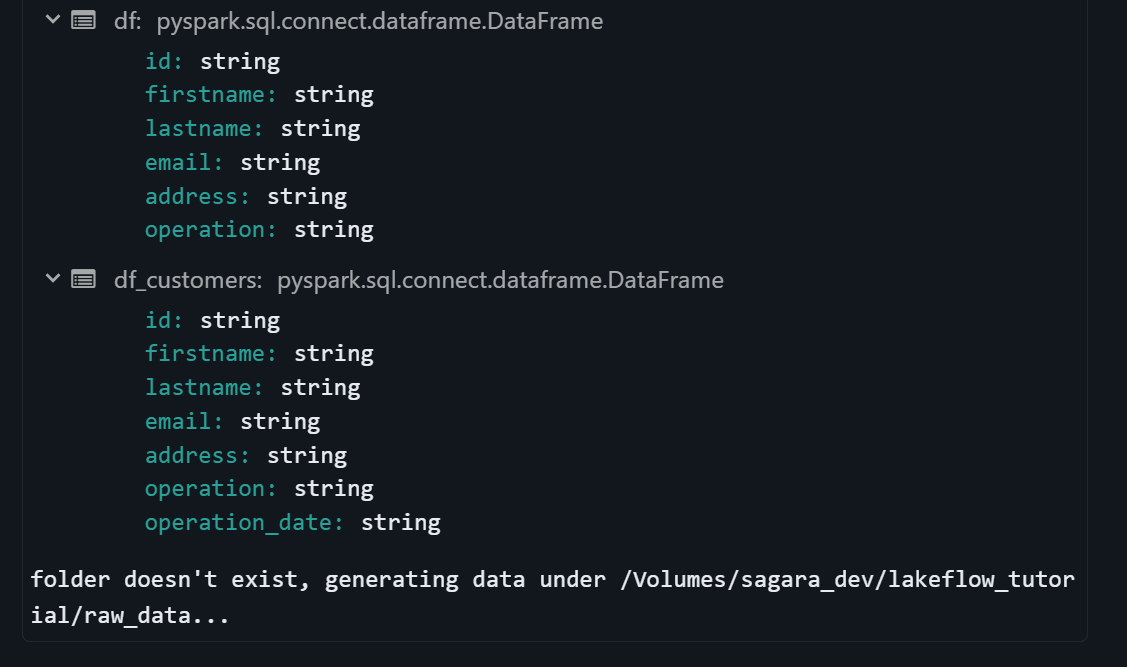
実行後、Catalog Explorer で sagara_dev.lakeflow_tutorial.raw_data volume 配下に JSON ファイルが作成されていれば OK です。
なお、この notebook は explorations folder 配下にあるため、Run pipeline では再実行されません。
3. Auto Loader で Bronze レイヤーに取り込む
ここから、作成したJSONをロードして処理するパイプラインを構築していきます。
Lakeflow Pipelines Editor 左側の asset browser から、デフォルトで用意されている transformations フォルダを右クリックして Create file を押し、ファイルを作成します。
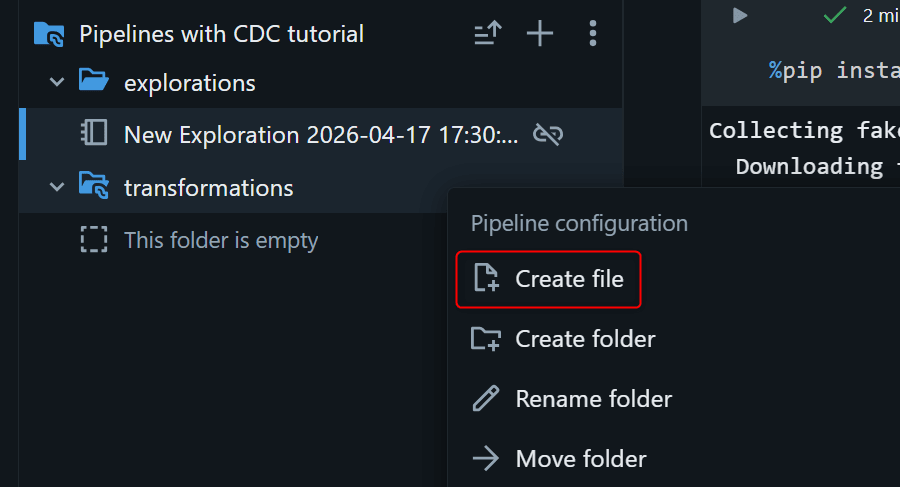
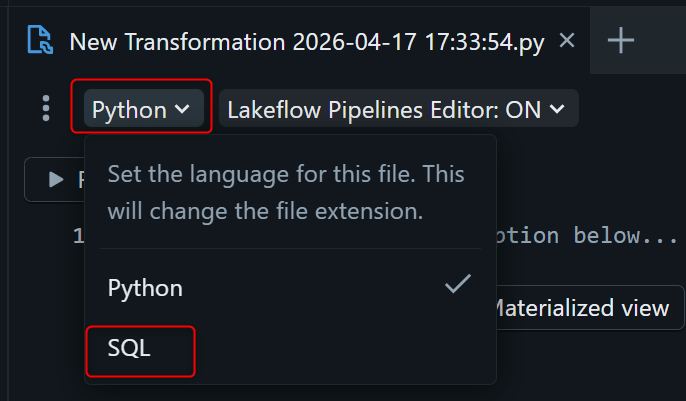
作成されたファイルがPythonだった場合、下図の赤枠を押してSQLに変更します。
ファイル名は01_bronze_customers_cdc.sqlとします。
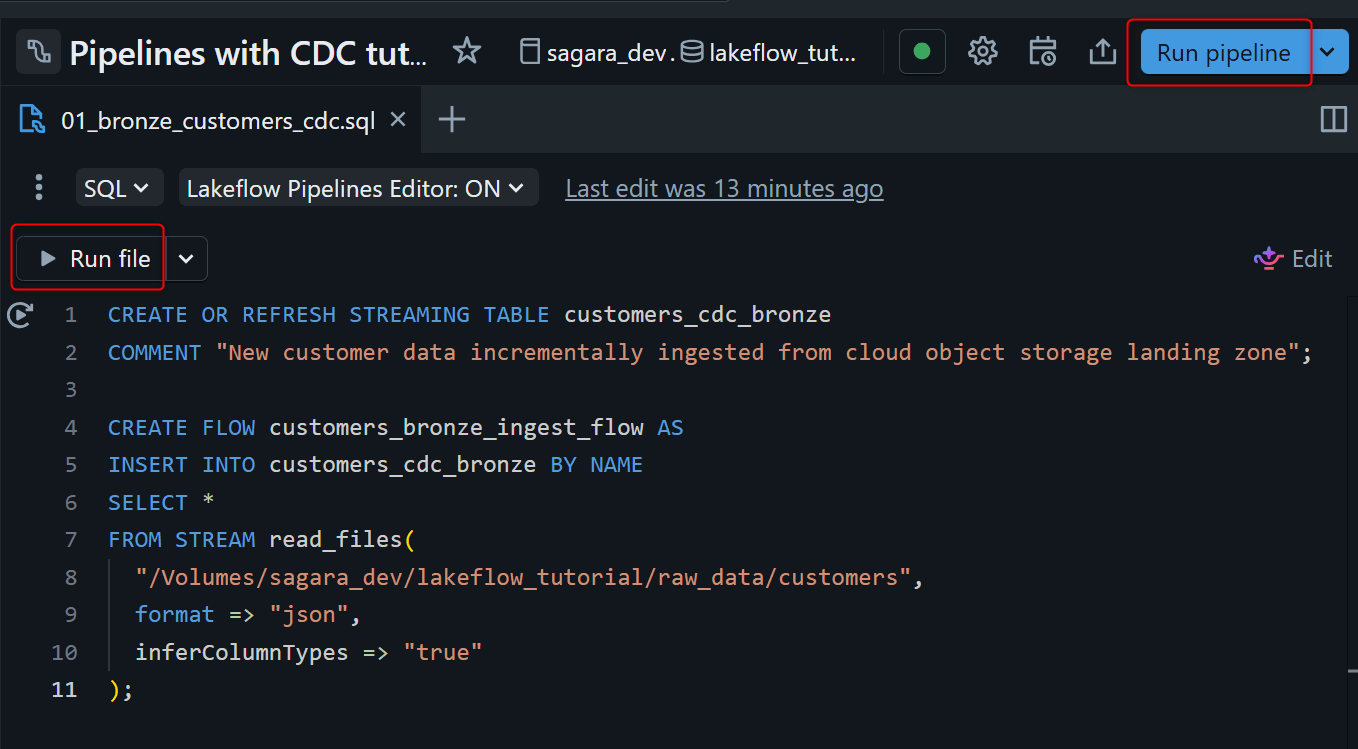
Bronze レイヤーの定義を書きます。Auto Loader は SQL では STREAM read_files(...) で使います。
CREATE OR REFRESH STREAMING TABLE customers_cdc_bronze
COMMENT "New customer data incrementally ingested from cloud object storage landing zone";
CREATE FLOW customers_bronze_ingest_flow AS
INSERT INTO customers_cdc_bronze BY NAME
SELECT *
FROM STREAM read_files(
"/Volumes/sagara_dev/lakeflow_tutorial/raw_data/customers",
format => "json",
inferColumnTypes => "true"
);
上の SQL は 2 つの文で構成されています。それぞれの役割は以下のとおりです。
- 1 つ目の
CREATE OR REFRESH STREAMING TABLE customers_cdc_bronze ...文:Bronze レイヤー用の streaming tablecustomers_cdc_bronzeを、中身が空の状態で作成します。実際のデータ取り込みは次の flow が担当します。 - 2 つ目の
CREATE FLOW customers_bronze_ingest_flow AS ...文:Auto Loader(STREAM read_files)を使って、Volume/Volumes/sagara_dev/lakeflow_tutorial/raw_data/customers配下の JSON ファイルを増分的に読み取り、customers_cdc_bronzeテーブルに追記で取り込む flow を定義しています。すでに取り込み済みのファイルはスキップされ、新しく追加されたファイルだけが処理されます。
実行は、エディター上部の Run file または Run pipeline を使います。この時点では source file が 1 つだけなので、どちらを選んでも実質同じです。
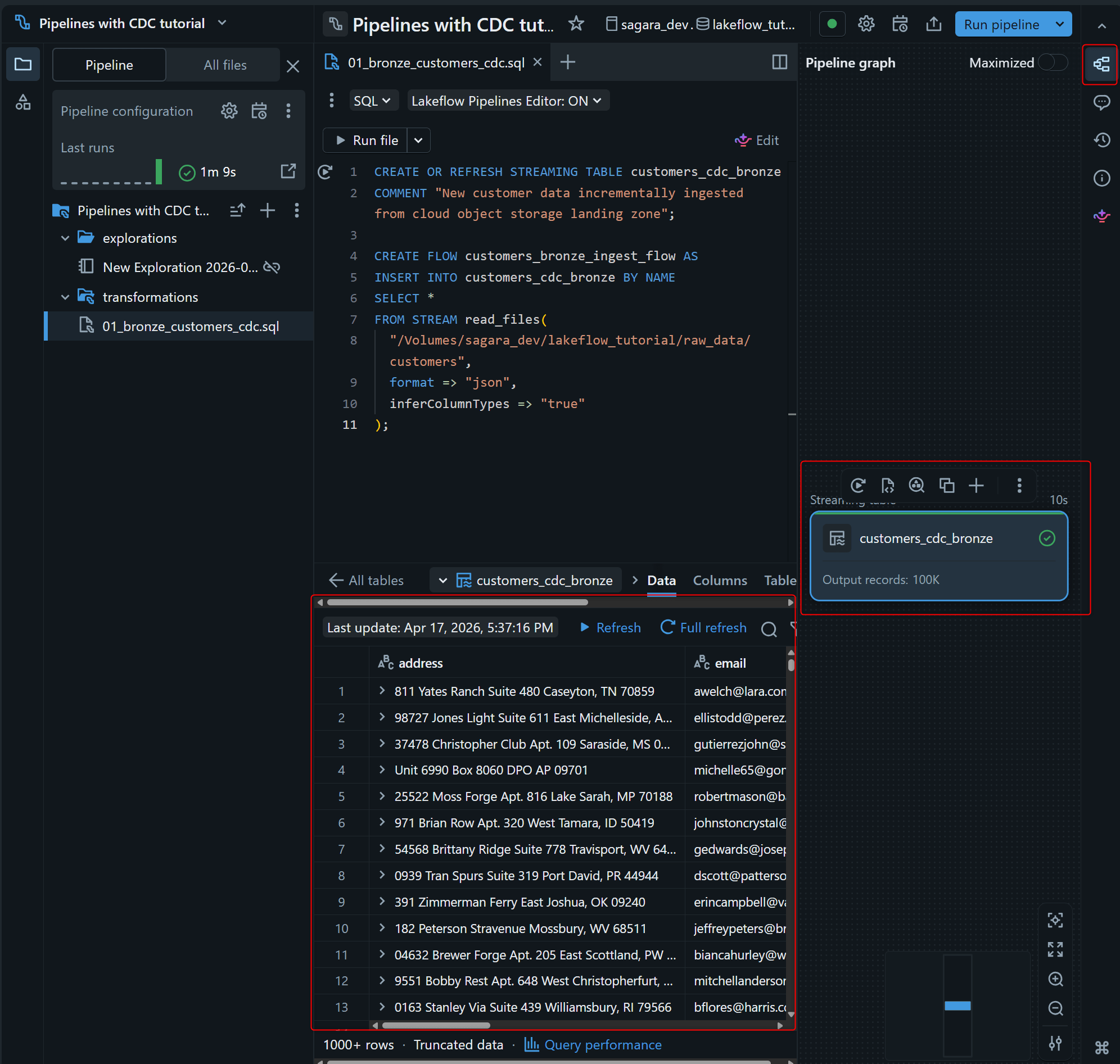
1分ほどで処理が完了するため、、右側の pipeline graph に customers_cdc_bronze が表示され、下部ペインからプレビューできれば OK です。
4. Transformation を追加して Silver レイヤーを作る
次に、transformations フォルダの中に Silver レイヤー用の SQL file を追加します。ファイル名は02_silver_customers_cdc_clean.sqlとします。ここでは expectations を使って、id IS NOT NULL、operation の妥当性、_rescued_data IS NULL の 3 つのデータ品質チェックを入れます。
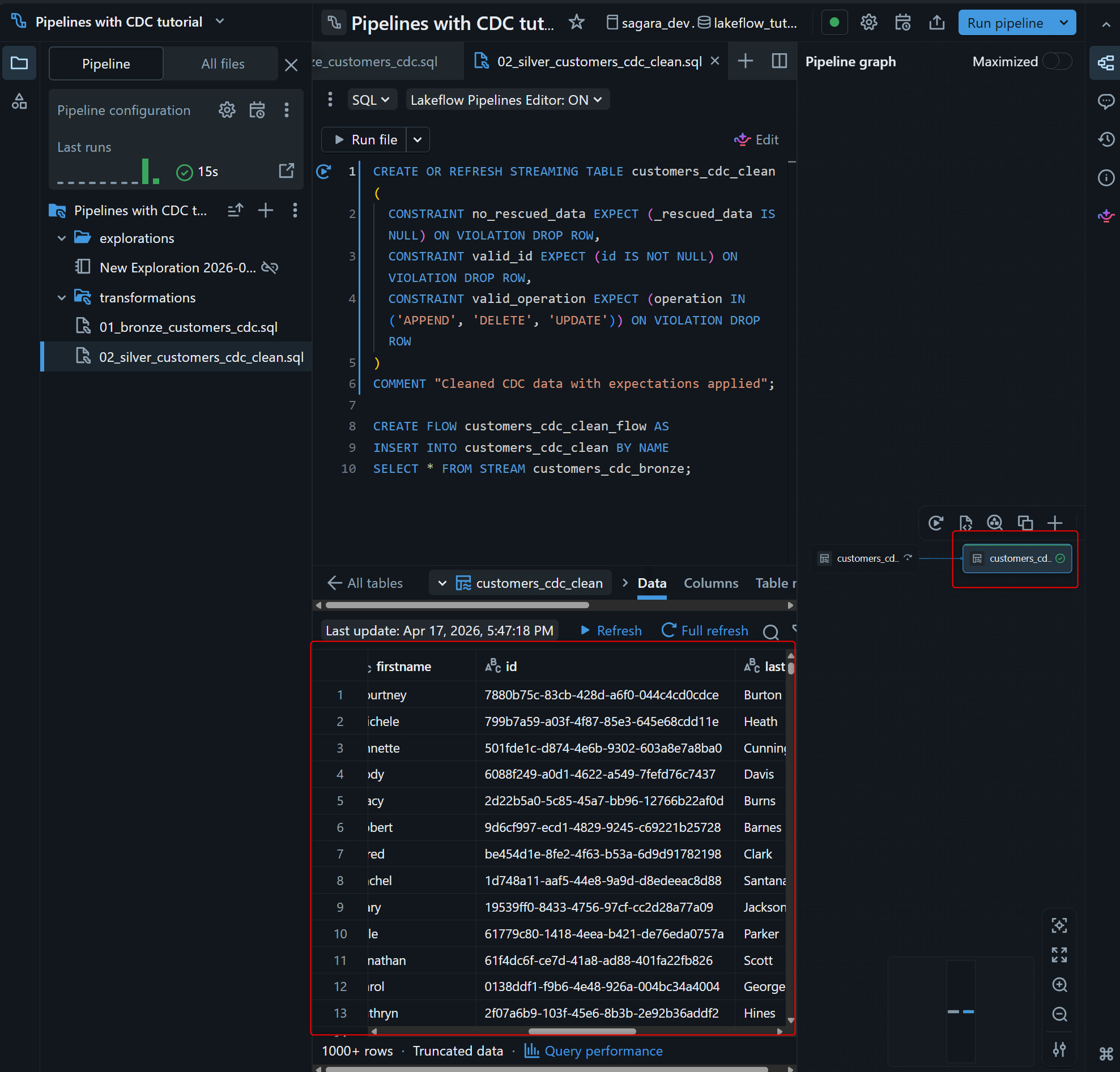
CREATE OR REFRESH STREAMING TABLE customers_cdc_clean (
CONSTRAINT no_rescued_data EXPECT (_rescued_data IS NULL) ON VIOLATION DROP ROW,
CONSTRAINT valid_id EXPECT (id IS NOT NULL) ON VIOLATION DROP ROW,
CONSTRAINT valid_operation EXPECT (operation IN ('APPEND', 'DELETE', 'UPDATE')) ON VIOLATION DROP ROW
)
COMMENT "Cleaned CDC data with expectations applied";
CREATE FLOW customers_cdc_clean_flow AS
INSERT INTO customers_cdc_clean BY NAME
SELECT * FROM STREAM customers_cdc_bronze;
上の SQL は 2 つの文で構成されています。それぞれの役割は以下のとおりです。
- 1 つ目の
CREATE OR REFRESH STREAMING TABLE customers_cdc_clean (...)文:Silver レイヤー用の streaming tablecustomers_cdc_cleanを、3 つの expectations 付きで作成します。_rescued_dataが NULL でないレコード(スキーマに合わない値が退避された行)、idが NULL のレコード、operationがAPPEND/DELETE/UPDATE以外のレコードは、ON VIOLATION DROP ROWにより取り込み時に破棄されます。サンプルデータには意図的にidが NULL のものやoperationが NULL のものが混ざっているため、これらが実際にフィルタされます。 - 2 つ目の
CREATE FLOW customers_cdc_clean_flow AS ...文:Bronze テーブルcustomers_cdc_bronzeを streaming 読み取りして、customers_cdc_cleanに追記する flow を定義しています。expectations は 1 つ目の文で定義したテーブル側に紐づいているため、この flow 自体は純粋に増分ロードを行うだけです。
この状態で Run file を実行すると、現在開いている source file だけを更新対象にできます。複数 file 構成になってからは、Run file と Run pipeline で挙動が変わる点に注意です。
更新後、customers_cdc_clean が graph に追加され、下部ペインの Data からnullなど品質チェックを満たしていないデータが除外されたデータが確認できます。
5. AUTO CDC で Gold レイヤーの最新スナップショットを作る
続いて、transformations フォルダにもう 1 つ SQL file を追加して、AUTO CDC で最新スナップショット用の customers table を作成します。ファイル名は03_gold_customers.sqlとします。AUTO CDC は out-of-order な CDC event も考慮して処理してくれるのがポイントです。
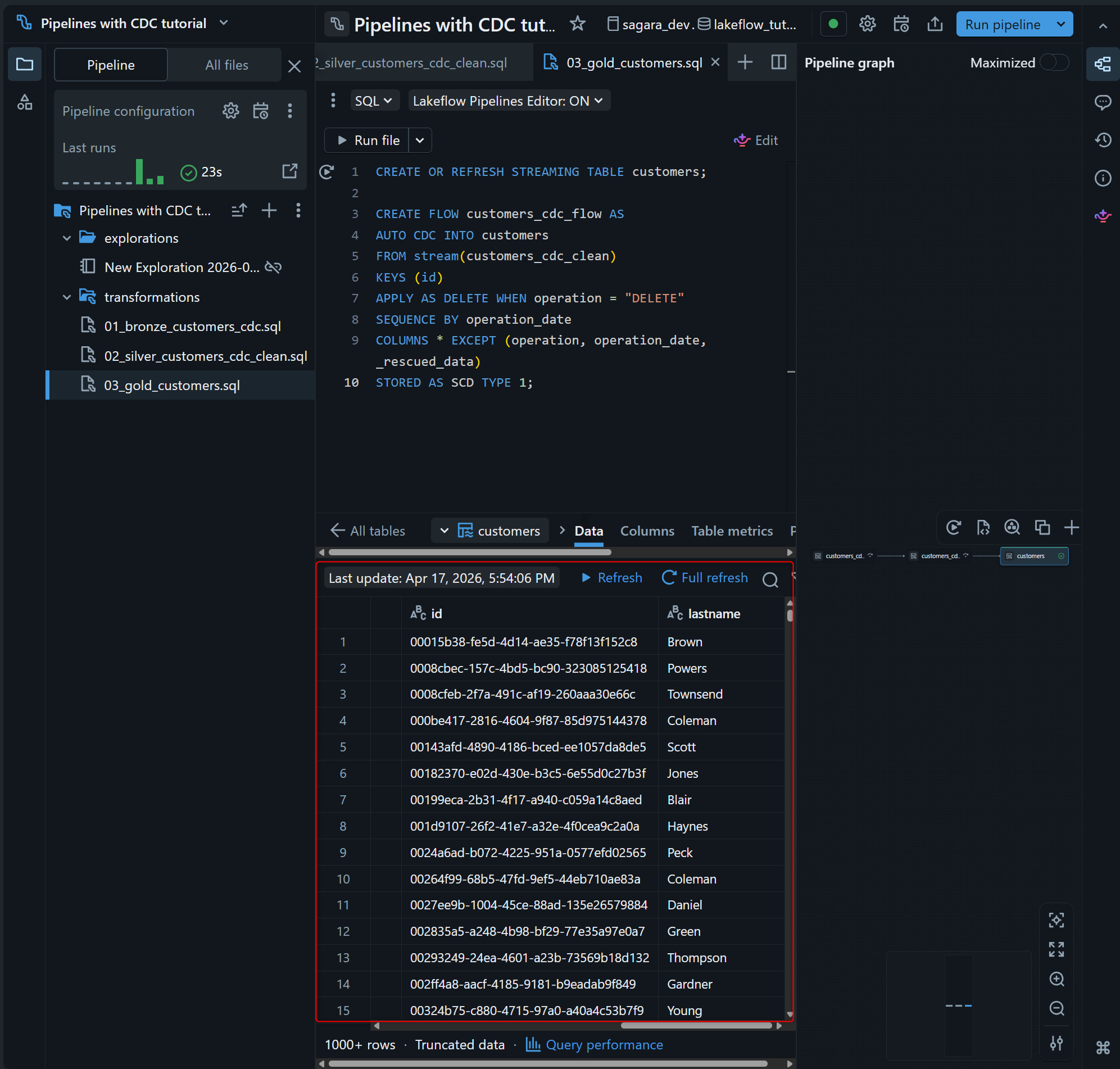
CREATE OR REFRESH STREAMING TABLE customers;
CREATE FLOW customers_cdc_flow AS
AUTO CDC INTO customers
FROM stream(customers_cdc_clean)
KEYS (id)
APPLY AS DELETE WHEN operation = "DELETE"
SEQUENCE BY operation_date
COLUMNS * EXCEPT (operation, operation_date, _rescued_data)
STORED AS SCD TYPE 1;
上の SQL は 2 つの文で構成されています。それぞれの役割は以下のとおりです。
- 1 つ目の
CREATE OR REFRESH STREAMING TABLE customers文:Gold レイヤーの最新スナップショット用テーブルcustomersを、中身が空の状態で作成しています。実際の書き込みは次の flow が担当します。 - 2 つ目の
CREATE FLOW customers_cdc_flow AS AUTO CDC INTO customers ...文:Silver テーブルcustomers_cdc_cleanを入力にして、AUTO CDCでcustomersに変更を反映する flow を定義しています。KEYS (id)でビジネスキーを指定し、APPLY AS DELETE WHEN operation = "DELETE"で削除扱いの条件を与え、SEQUENCE BY operation_dateで out-of-order イベントも正しい順序で適用されるようにしています。COLUMNS * EXCEPT (operation, operation_date, _rescued_data)により CDC 制御用の列は出力テーブルから除外され、STORED AS SCD TYPE 1によって各idにつき最新状態のみが保持される形(履歴は残らない)で保存されます。
Run file 実行後、customers table が graph に追加されます。プレビュー上で operation、operation_date、_rescued_data が除外され、id ごとの最新状態だけが残っていれば OK です。
6. SCD Type 2 で履歴テーブルを作る
さらに、履歴保持用の customers_history table も作ります。こちらも transformations フォルダに別の SQL file を追加し、ファイル名は04_gold_customers_history.sqlとします。STORED AS SCD TYPE 2 を使うと、変更履歴を保持するテーブルを自動構築できます。
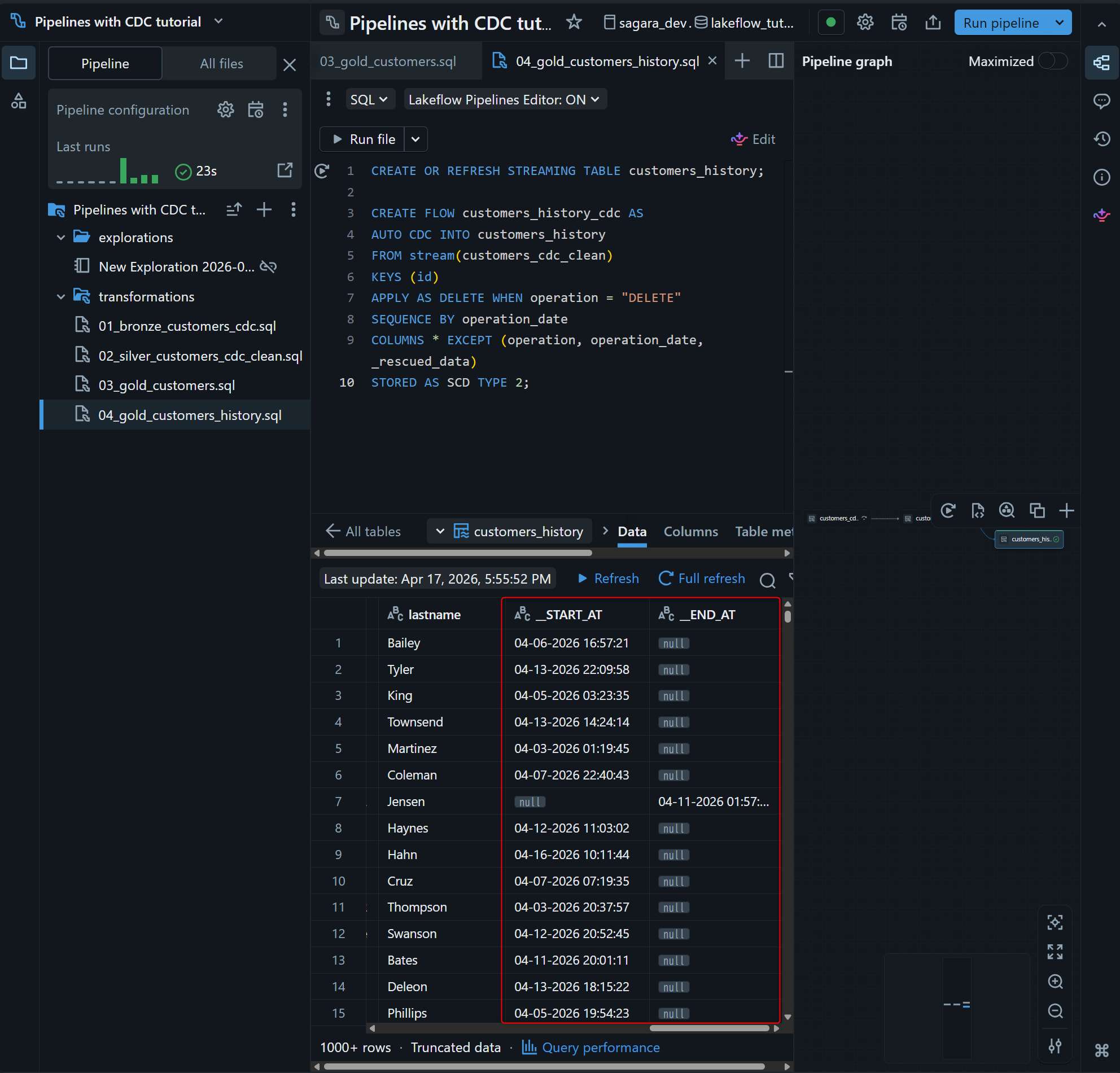
CREATE OR REFRESH STREAMING TABLE customers_history;
CREATE FLOW customers_history_cdc AS
AUTO CDC INTO customers_history
FROM stream(customers_cdc_clean)
KEYS (id)
APPLY AS DELETE WHEN operation = "DELETE"
SEQUENCE BY operation_date
COLUMNS * EXCEPT (operation, operation_date, _rescued_data)
STORED AS SCD TYPE 2;
上の SQL は 2 つの文で構成されています。それぞれの役割は以下のとおりです。
- 1 つ目の
CREATE OR REFRESH STREAMING TABLE customers_history文:履歴保持用の streaming tablecustomers_historyを、中身が空の状態で作成しています。 - 2 つ目の
CREATE FLOW customers_history_cdc AS AUTO CDC INTO customers_history ...文:Step 5 と同じ Silver テーブルcustomers_cdc_cleanを入力にして、AUTO CDCでcustomers_historyに変更を反映する flow を定義しています。キー・削除条件・並び順・カラム選択は Step 5 と同じですが、最後がSTORED AS SCD TYPE 2になっているため、idごとの変更履歴がすべて保持され、各レコードには有効期間を示す__START_AT/__END_AT列が自動で付与されます。
更新後、customers_history が graph に追加され、履歴管理用の列 __START_AT / __END_AT を含むレコードが確認できれば OK です。なお、必要に応じて TRACK HISTORY ON ... で追跡対象列を絞ることもできます。
7. Materialized View で集計テーブルを作る
最後に、customers_history を集計する Materialized View を作成します。これも transformations フォルダに SQL file を追加し、ファイル名は05_gold_customers_history_agg.sqlとします。
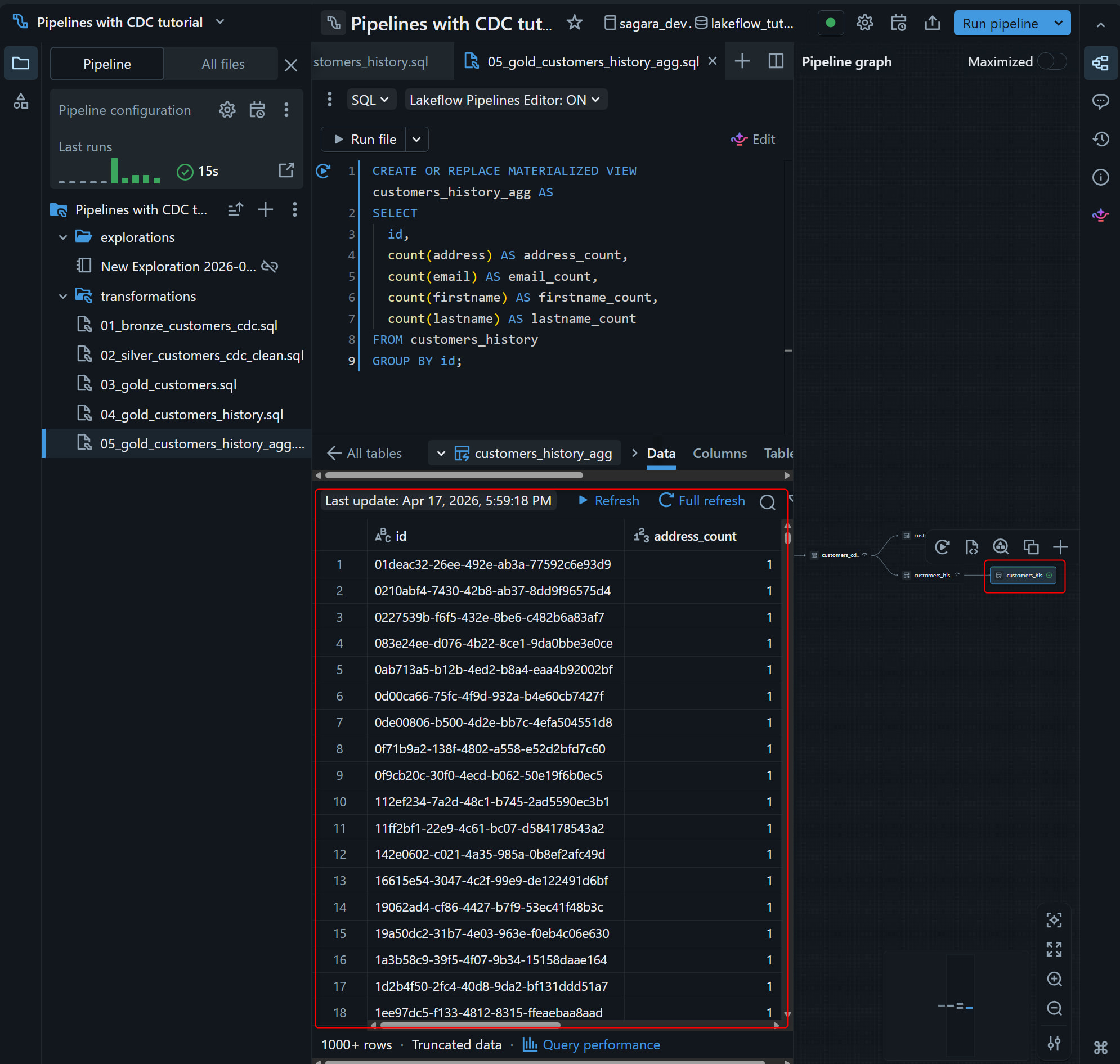
CREATE OR REPLACE MATERIALIZED VIEW customers_history_agg AS
SELECT
id,
count(address) AS address_count,
count(email) AS email_count,
count(firstname) AS firstname_count,
count(lastname) AS lastname_count
FROM customers_history
GROUP BY id;
上の SQL は 1 つの文で構成されています。
CREATE OR REPLACE MATERIALIZED VIEW customers_history_agg AS SELECT ... FROM customers_history GROUP BY id文:Step 6 で作成した SCD Type 2 の履歴テーブルcustomers_historyを入力に、idごとにaddress/email/firstname/lastnameの件数を集計する Materialized Viewcustomers_history_aggを定義しています。履歴テーブルは 1 レコード=1 変更なので、列ごとの件数がそのまま「その顧客が各属性を何回変更したか」を表します。Materialized View なので、パイプラインが更新されるたびに Databricks 側で自動的に増分更新されます。
Run file 実行後、customers_history_agg が graph に追加され、顧客ごとの変更回数が確認できれば完了です。
ここまでで pipeline の定義は一通り完了なので、最後にエディター上部の Run pipeline で pipeline 全体を更新して動作確認します。
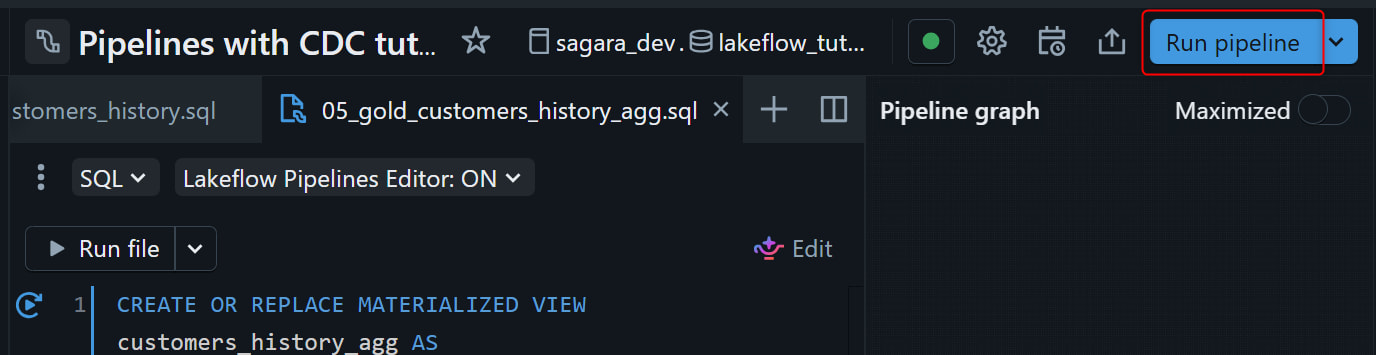
Lakeflow Spark Declarative Pipelines は定義された依存関係を解析して、Bronze → Silver → Gold の順に自動で実行してくれます。更新後、右側の pipeline graph で依存関係が一通りエラーなく表示されていれば、OKです。
8. Schedule から定期実行ジョブを作る
ここまでで pipeline の定義自体は完了していますが、Flow を定義しただけでは、新しいファイルが到着したタイミングで自動的に pipeline 全体が起動するわけではありません。Flow はあくまで「pipeline update 時に実行される処理定義」であり、実際に取り込み・変換を走らせるには、手動で Run pipeline を実行するか、Schedule を設定して update を定期実行する必要があります。
そのため、今回のように Auto Loader で Volume 配下の新規ファイルを継続的に取り込みたい場合は、Schedule を作成して pipeline update を定期実行するのが分かりやすい運用方法になります。Schedule 実行時には、Databricks が定義済みの依存関係を解決し、Bronze → Silver → Gold の順に必要な flow や view を更新してくれます。つまり、新しいファイルが Volume 配下に追加されていれば、Bronze への取り込みだけでなく、その後段の customers_cdc_clean、customers、customers_history、customers_history_agg まで順次反映されます。
定期実行を設定するには、エディター上部の Schedule をクリックします。
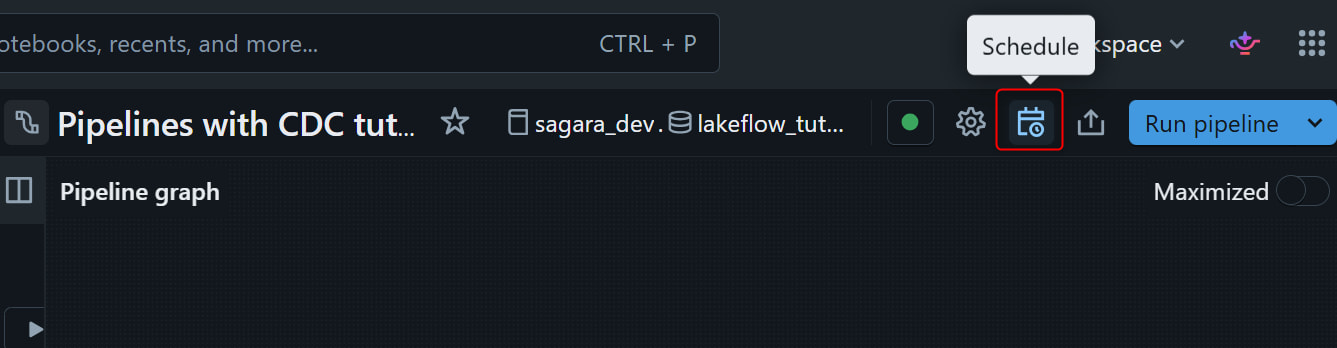
Schedule では、一定間隔ごとに実行するインターバル方式と、特定の日時・時刻で実行する方式の両方を設定できます。Advanced settings の Notifications では通知先を指定でき、job が失敗した際にアラートを受け取ることも可能です。定期的な CDC 取り込みを運用する場合は、ここで実行頻度や通知設定を決めておくと便利です。
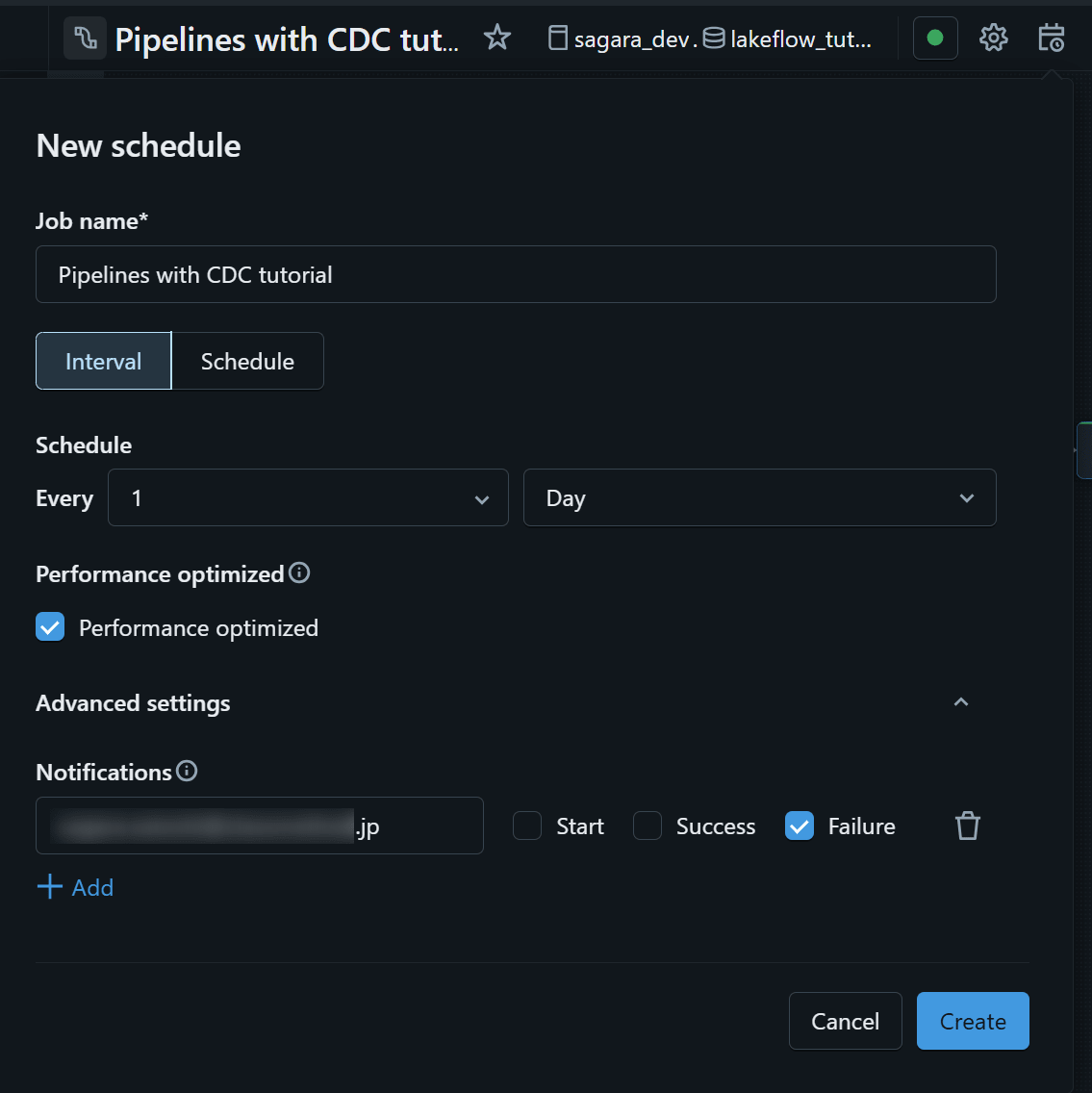
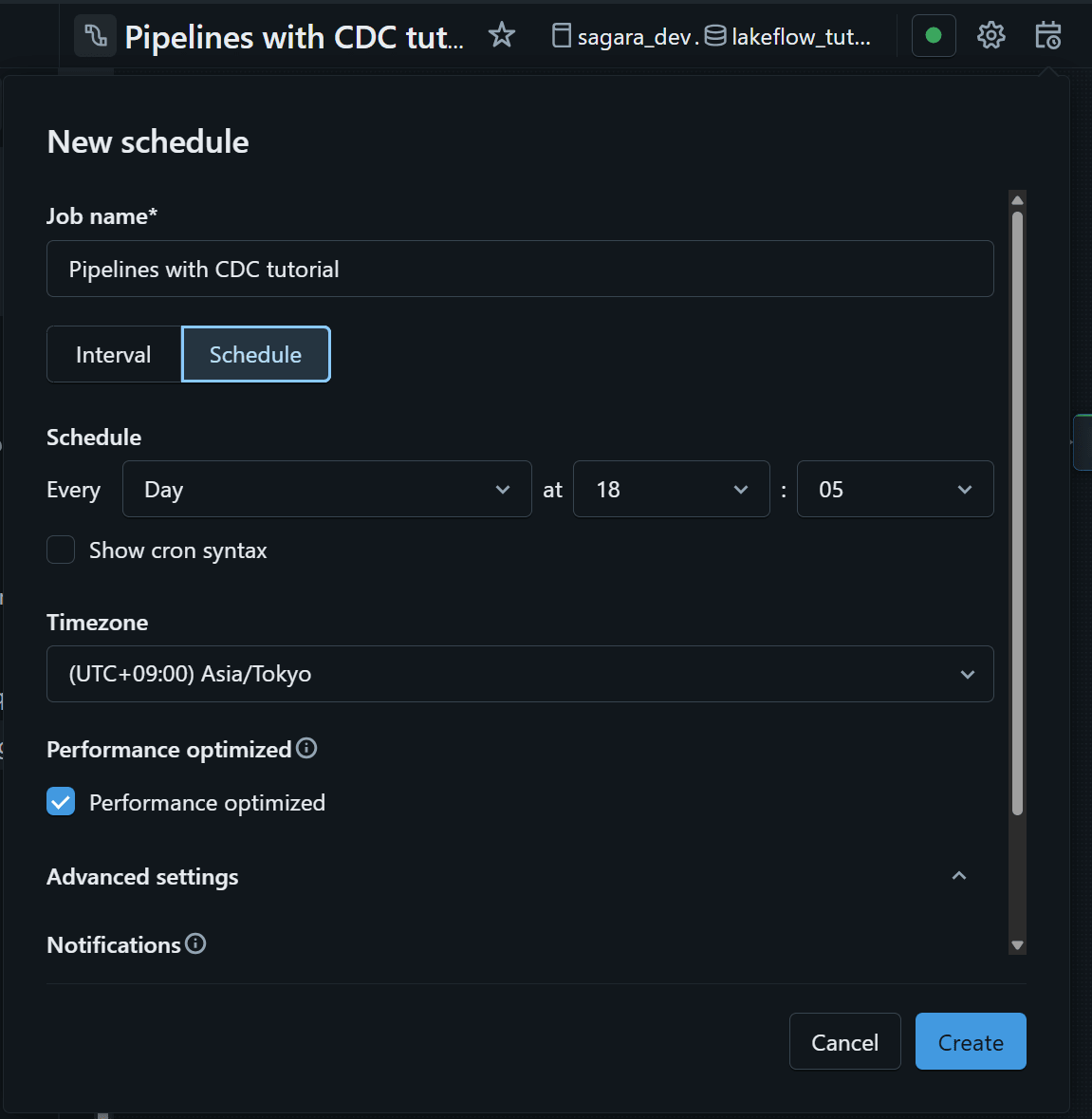
設定後は、再度 Schedule を開くことで schedule 一覧を確認できます。job 名をクリックすると Jobs & Pipelines 側の job 詳細に遷移し、実行履歴や Run now からの手動実行も確認できます。定期実行が正しく動いているかを確認したい場合は、ここで各 run の成否や実行時間をチェックするとよいです。
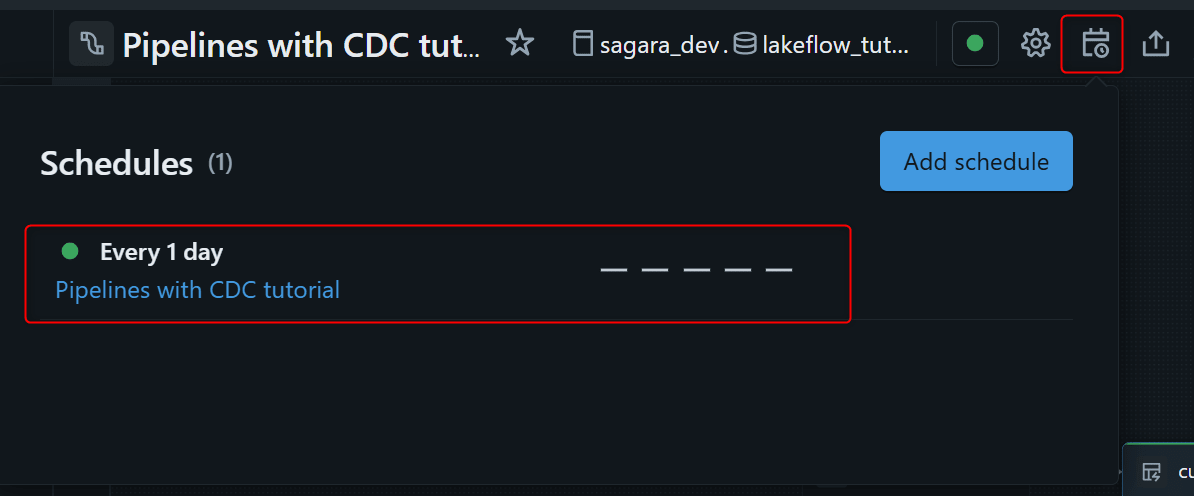
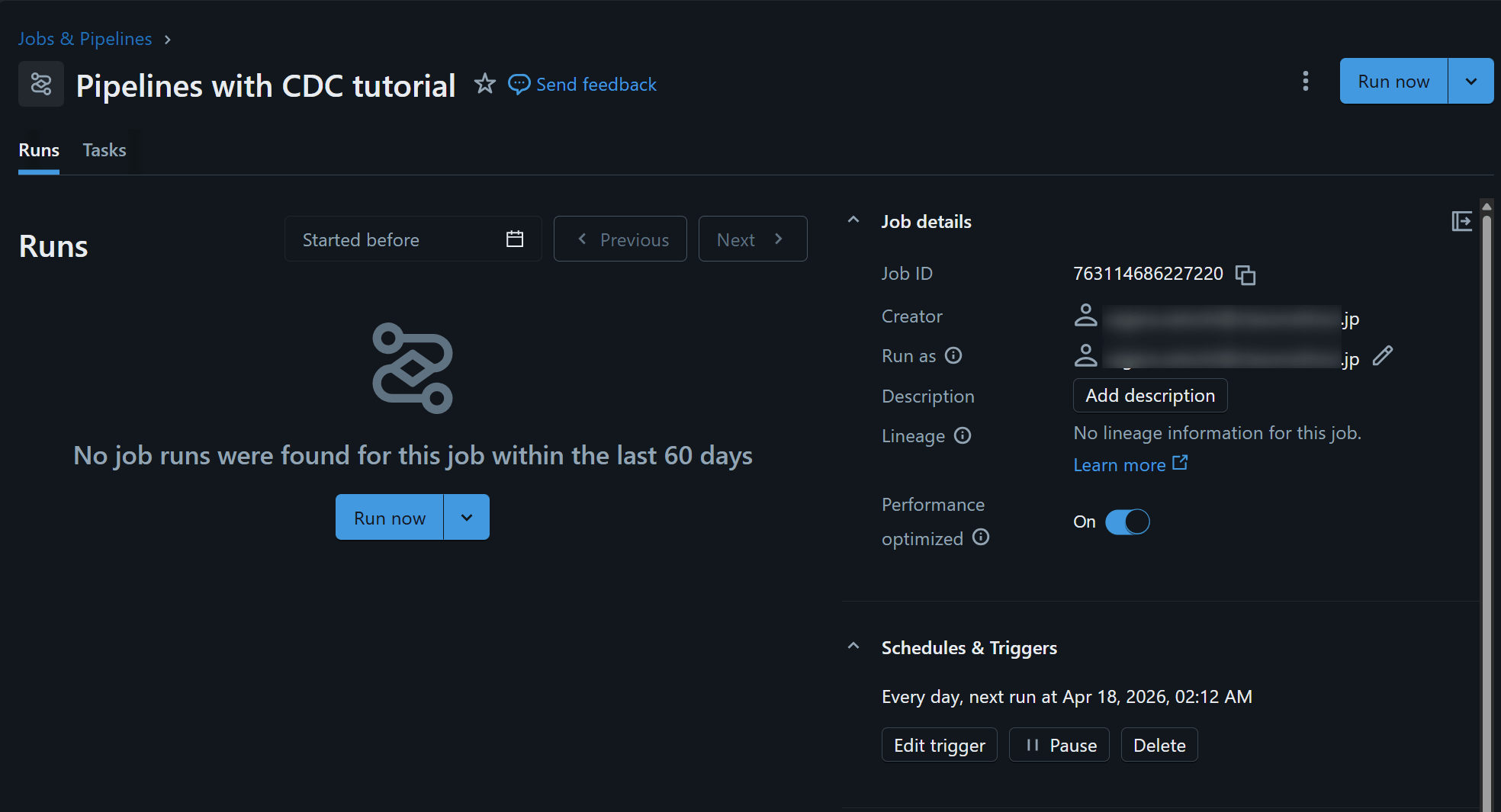
なお、この Schedule はあくまで一定間隔で pipeline update を起動する仕組みです。つまり、「新しいファイルが来た瞬間に起動するイベント駆動」ではなく、「指定した時刻・間隔で起動し、その時点までに到着している新規データを取り込む」方式になります。新規ファイル到着そのものを契機に自動実行したい場合は、次のおまけで触れる File arrival trigger を使う構成のほうが適しています。
おまけ. 新しいファイルの到着を契機に自動実行したい場合
ここまでの手順では、Schedule による定期実行で pipeline update を起動する方法を見てきました。ただしこの方法は、あくまで「5 分おき」「1 時間おき」といった一定間隔で実行する仕組みです。
そのため、新しいファイルが置かれたタイミングでだけ自動で動かしたい場合には、Schedule ではなく Jobs & Pipelines 側で File arrival trigger を使う構成にするのが適しています。
今回の pipeline では、Bronze レイヤーで Auto Loader により Volume 配下の JSON ファイルを増分取り込みしています。この構成で File arrival trigger を組み合わせると、新しいファイルが到着したことをきっかけに job が起動し、その中で pipeline update が実行されるようになります。結果として、Bronze への取り込みだけでなく、依存先である Silver / Gold の flow や Materialized View までまとめて更新されます。
設定の流れとしては、まず Jobs & Pipelines から新しい job を作成し、task の種類に Pipeline を選択して、今回作成した pipeline を指定します。
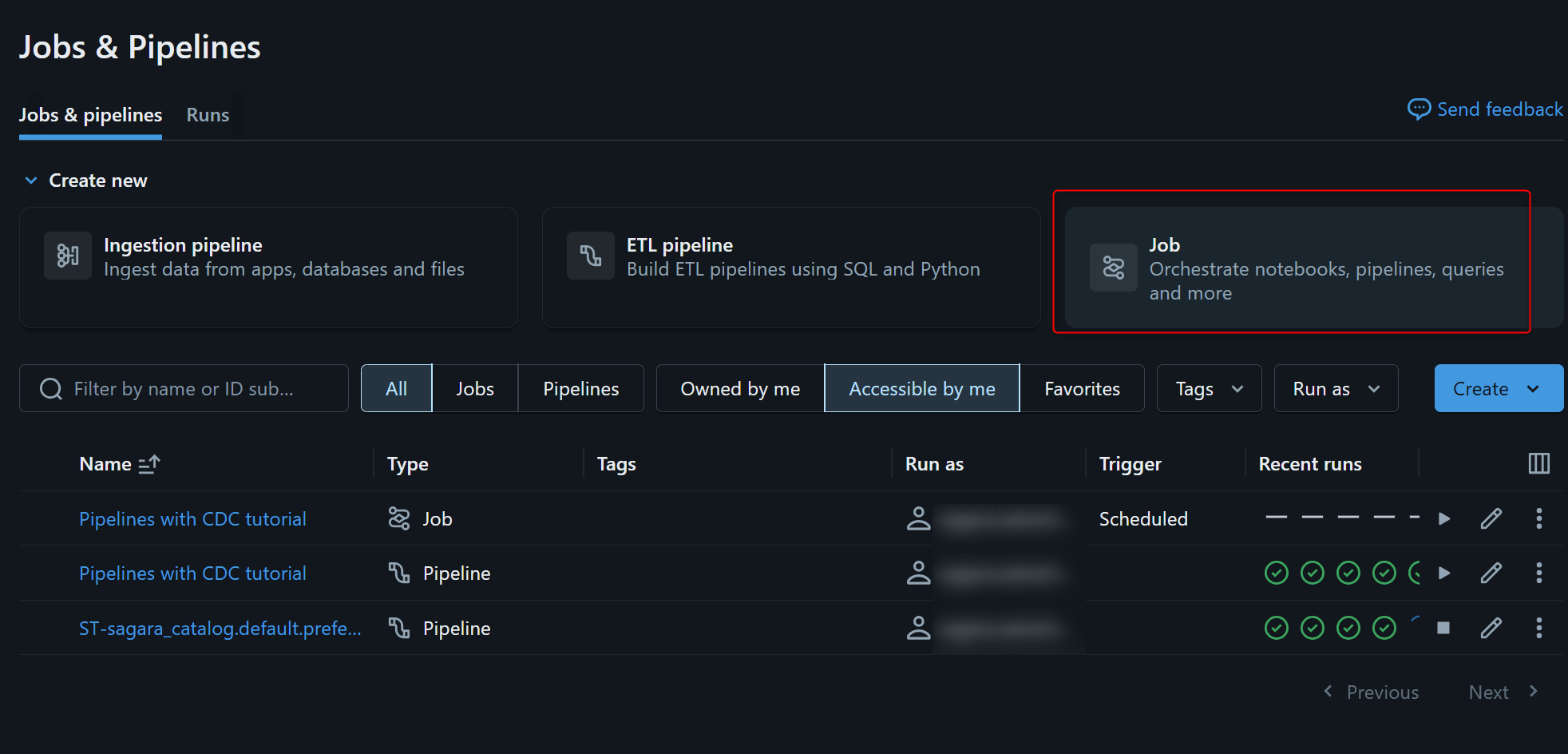
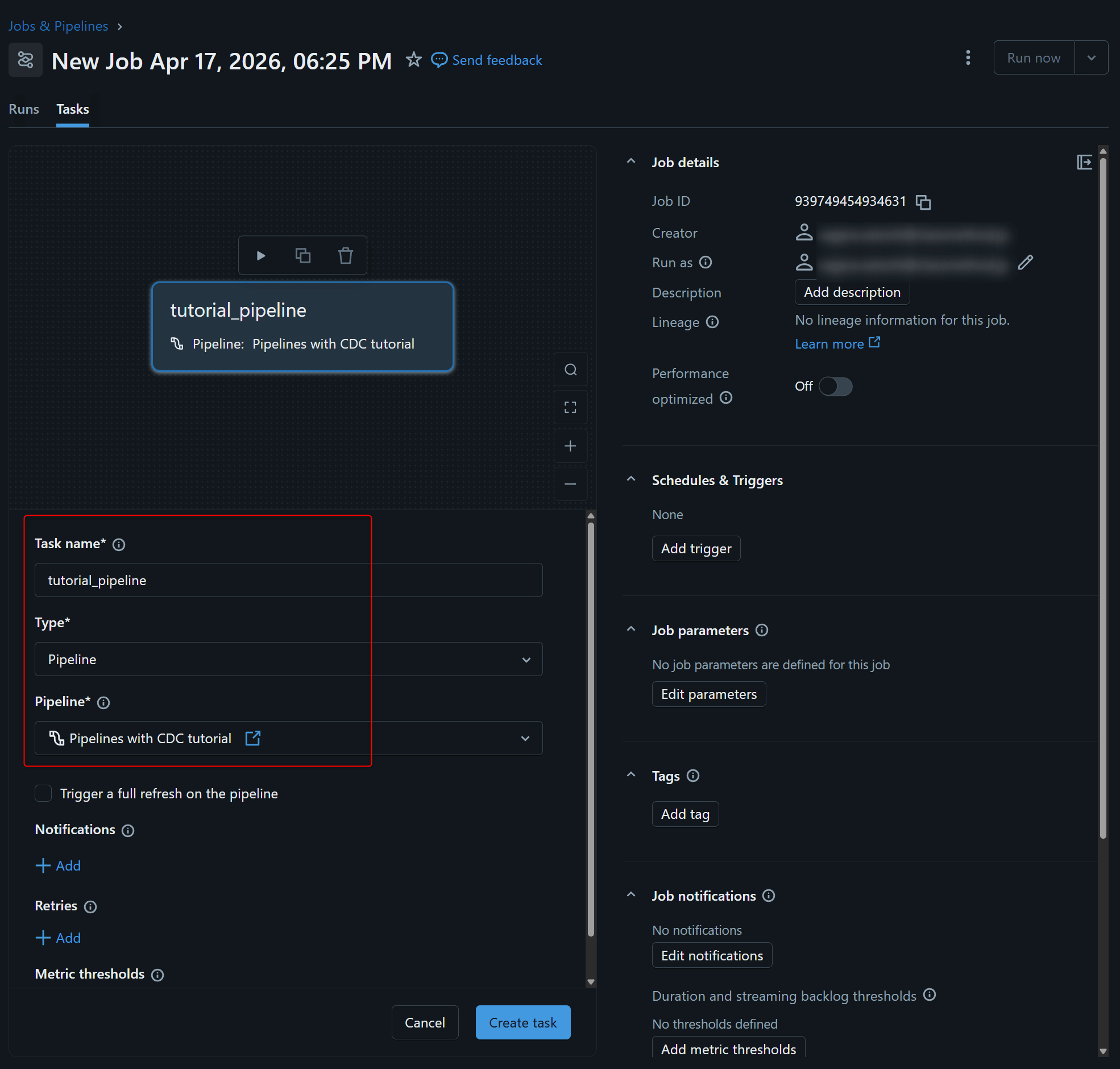
次に、その job に対して trigger を追加します。trigger の種類で File arrival を選び、監視対象のパスとして、たとえば今回であれば /Volumes/sagara_dev/lakeflow_tutorial/raw_data/customers/ を指定します。これにより、このパス配下に新しいファイルが配置されたときに job が自動で起動するようになります。
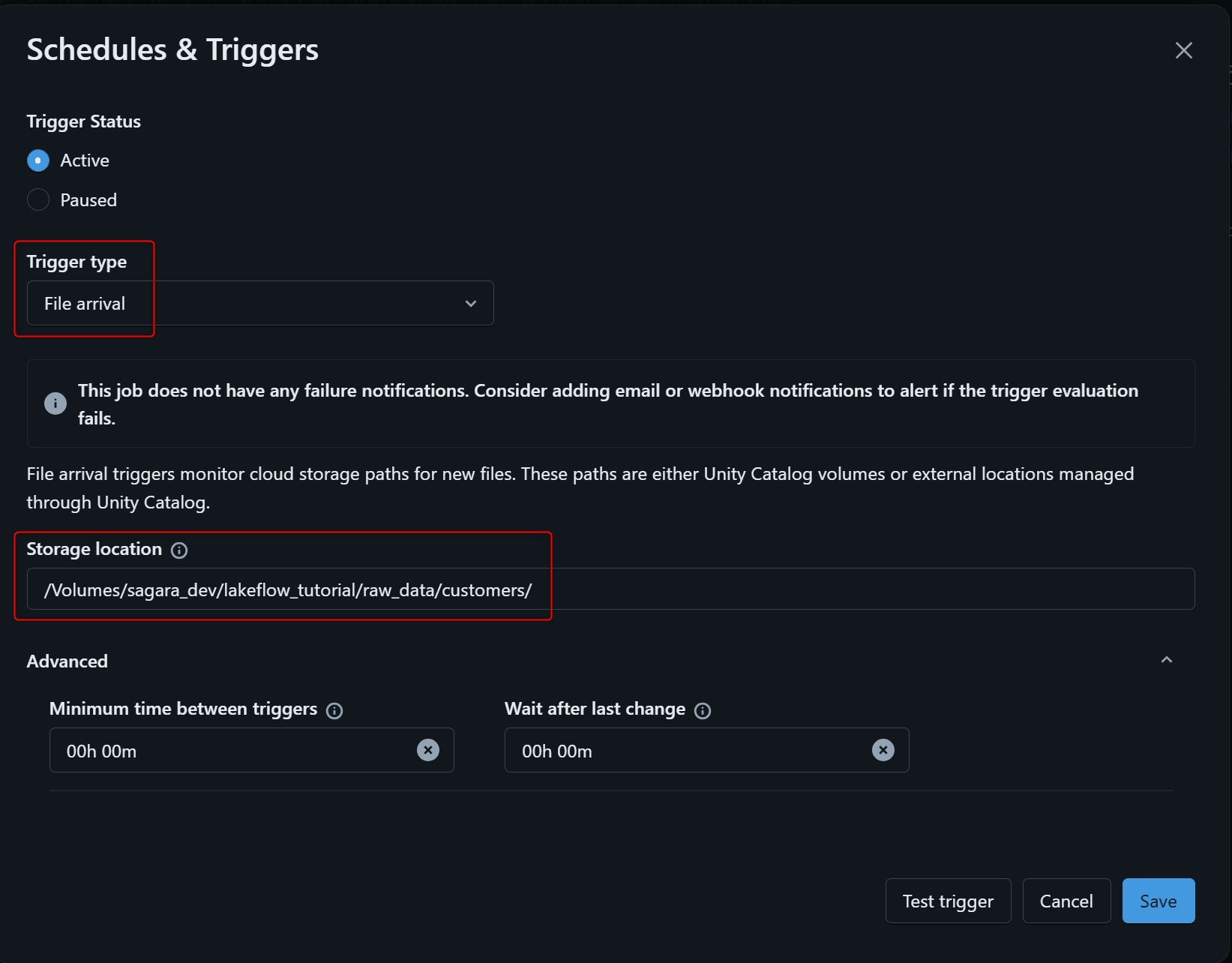
この方法を使うと、定期的に空振りで update を実行するのではなく、新しいファイルが来たときだけ pipeline を動かせるため、よりイベント駆動に近い運用ができます。特に、ファイルの到着タイミングが不定期な場合や、不要な実行回数を減らしたい場合に向いています。
一方で、File arrival trigger は「新しいファイルの到着」をきっかけに job を起動する仕組みであり、実際にどのファイルを取り込むかの管理は Bronze 側の Auto Loader が担います。つまり、トリガーは job の起動、増分判定は Auto Loader という役割分担になります。今回のように Bronze で STREAM read_files(...) を使っている構成とは相性がよく、取り込み済みファイルを再処理しすぎずに運用できます。
整理すると、運用方法の考え方は次のようになります。
- 一定間隔でまとめて更新したい: Schedule
- 新しいファイルが来たときだけ自動実行したい:
File arrival trigger
今回のチュートリアルの構成で「ファイル到着をきっかけに自動で Bronze → Silver → Gold まで更新したい」のであれば、Jobs & Pipelines で pipeline task を作成し、File arrival trigger を設定すると理解しておくと分かりやすいです。
最後に
Lakeflow Spark Declarative Pipelines の CDC チュートリアルを SQL で最後まで試してみました。Auto Loader による取り込み、expectations による品質管理、AUTO CDC による SCD Type 1 / Type 2、さらに Materialized View による集計まで、かなり少ない記述量で組めるのがよく分かりました。
Lakeflow Spark Declarative Pipelines を試す最初の題材としてはかなり良いチュートリアルだったので、興味のある方はぜひ試してみてください。









