
DatabricksのリソースをIaCで管理するための機能「Declarative Automation Bundles」を試してみた
さがらです。
DatabricksをIaCで管理するための仕組みとして、Declarative Automation Bundles(旧称:Databricks Asset Bundles)があります。databricks.ymlに、BundlesでサポートされているJob・Pipeline・Catalog・Schemaなどのリソースを宣言的に記述し、databricks bundle deployコマンドでDatabricksワークスペースに一括デプロイできるフレームワークです。
公式Docはこちらです。
このDeclarative Automation Bundlesを実際に試してみたので、手順と確認結果をまとめます。
機能概要
Declarative Automation Bundlesは、Databricks上のリソース(Job / Pipeline / Catalog / Schema / Notebook など)をdatabricks.ymlで宣言的に定義し、databricks bundle ...コマンドで一括デプロイ・実行できるDatabricks公式のIaCフレームワークです。
主な特徴は以下の通りです。
databricks.ymlにリソースをコードで宣言し、Gitでバージョン管理できるtargets機能で、dev / prodなどの環境を1つのBundle内で管理できる- Bundle variables機能により、
${var.<variable_name>}構文で値を変数化できる bundle init/validate/plan/deploy/run/destroyなどのCLIコマンドで管理できる
特にBundle variablesは、「環境ごとに値が変わる項目」「Gitに含めたくない項目」をdatabricks.ymlから外すために便利な機能です。
制限事項
Declarative Automation Bundlesのresources:には、Databricks上の任意のオブジェクトを自由に定義できるわけではありません。公式Docの「Supported resources」に掲載されているリソースタイプが対象となります。
2026年4月28日時点では、job、pipeline、catalog、schema、volume、external_location、cluster、sql_warehouse、dashboard、model_serving_endpoint、registered_model、experiment、secret_scopeなどがBundle resourceとしてサポートされています。
一方で、一般的なUnity CatalogのTableをresources.tablesのように宣言して作成する形は、少なくとも現時点のSupported resourcesには含まれていません。そのため本記事では、Catalog / SchemaはBundle resourceとして作成し、TableはBundleでデプロイしたJobのNotebook内でSQLにより作成する形にしています。つまり、今回のTable作成は「TableをBundle resourceとして管理している」のではなく、「Bundleで管理しているJobを実行してTableを作成している」という整理になります。
前提条件
以下の前提で実施します。
- Databricks: Free EditionのServerless Workspace、Unity Catalog有効化済み
- 今回は 1つのWorkspace内 でCatalog単位でdev / prodを分ける構成で試します
- JobのNotebook taskはserverless computeで実行するため、Cluster IDは指定しません
- Free Editionではserverless compute resourcesのみ利用可能で、カスタムCompute構成はサポートされません
- ユーザー管理 S3: Storage Credential / External Location として Databricks Free Edition に連携済み
- 詳細はこちらの記事をご覧ください
- Databricks CLI: バージョン0.279.0以上(direct deployment engineのため)
- ローカル環境: WSL2のUbuntu 24.04 LTS(macOS / Linuxでも同様の手順で実行可能です)
- 認証方式: OAuth U2M(
databricks auth loginで対話的にログイン)
なお、Databricks CLI自体のセットアップ手順は以下のブログでまとめていますので、未導入の方はあわせてご覧ください。
事前準備
Databricks CLIを設定する
まず、ローカルから利用するDeclarative Automation BundlesはDatabricks CLIが必須となります。
以下のブログでセットアップ手順をまとめているため、参考になると幸いです。
Databricks CLIで認証する
OAuth U2Mで、対象Workspaceに対して認証を行います。
databricks auth login --host https://<workspace-url>
今回は1つのWorkspaceを共通利用するため、認証は1回行えば済みます。Workspaceレベルでdev / prodを分ける構成に切り替える場合は、それぞれのWorkspaceに対してdatabricks auth loginを実施してください。
Databricks unified authenticationの仕様については以下の公式Docが参考になります。
Bundleプロジェクトのフォルダを作成する
Databricksにはdatabricks bundle initコマンドでテンプレートファイルを生成する仕組みもありますが、今回はbundle initは使わず、必要なフォルダ・ファイルを手動で作っていきます。(テンプレートの詳細についてはこちらの公式Docをご覧ください。)
任意の作業ディレクトリで以下を実行してください。
mkdir -p uc_target_bundle_demo/src
cd uc_target_bundle_demo
最終的なフォルダ構成は以下となります。databricks.ymlとsrc/create_table.pyは次のセクションでまとめて作成します。
uc_target_bundle_demo/
├── databricks.yml
└── src/
└── create_table.py
External Location の事前確認
resources.catalogs.storage_root に指定する S3 パスが External Location の配下にあることを事前に確認します。Databricks SQL Editor または Notebook から以下の SQL を実行してください。
SHOW EXTERNAL LOCATIONS;
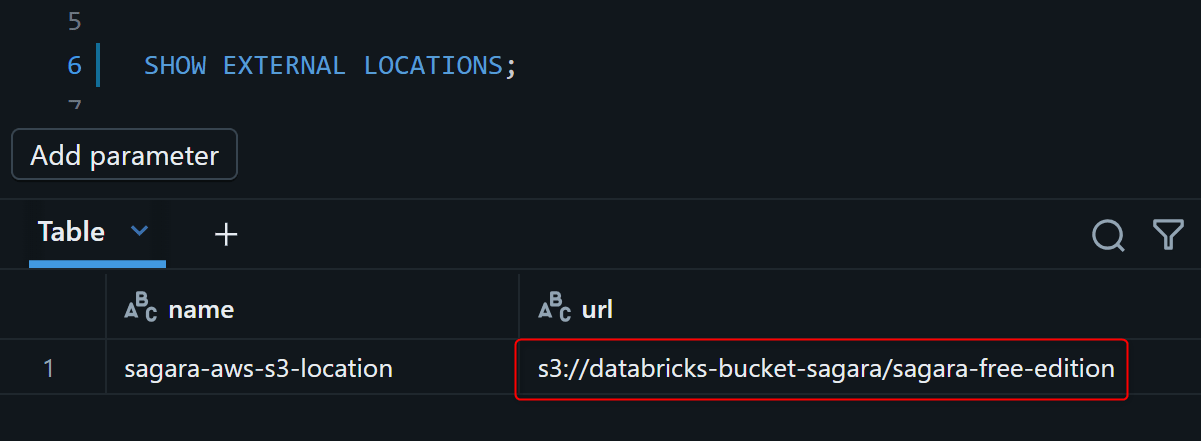
例えば上図のように、 External Location の URL が s3://databricks-bucket-sagara/sagara-free-edition/ であれば、Catalog の storage_root として以下のような配下パスを指定できます。
s3://databricks-bucket-sagara/sagara-free-edition/uc-bundle-dev-catalog
試してみた
1. databricks.ymlを作成する
uc_target_bundle_demo/直下に、以下の内容でdatabricks.ymlを作成します。
bundle:
name: uc_target_bundle_demo
engine: direct
variables:
catalog_name:
description: "Unity Catalog catalog name for this target"
catalog_storage_root:
description: "Managed storage root for this catalog"
schema_name:
description: "Unity Catalog schema name for this target"
table_name:
description: "Table name to create"
default: target_test_table
resources:
catalogs:
target_catalog:
name: ${var.catalog_name}
storage_root: ${var.catalog_storage_root}
comment: "Catalog created by Databricks Bundle for target ${bundle.target}"
properties:
managed_by: databricks_bundle
bundle_name: ${bundle.name}
bundle_target: ${bundle.target}
lifecycle:
prevent_destroy: true
schemas:
target_schema:
name: ${var.schema_name}
catalog_name: ${resources.catalogs.target_catalog.name}
comment: "Schema created by Databricks Bundle for target ${bundle.target}"
properties:
managed_by: databricks_bundle
bundle_name: ${bundle.name}
bundle_target: ${bundle.target}
lifecycle:
prevent_destroy: true
jobs:
create_uc_table:
name: ${bundle.name}_${bundle.target}_create_uc_table
tags:
bundle_name: ${bundle.name}
bundle_target: ${bundle.target}
tasks:
- task_key: create_table
notebook_task:
notebook_path: ./src/create_table.py
base_parameters:
catalog_name: ${resources.catalogs.target_catalog.name}
schema_name: ${resources.schemas.target_schema.name}
table_name: ${var.table_name}
bundle_target: ${bundle.target}
targets:
dev:
default: true
variables:
catalog_name: uc_bundle_dev_catalog
catalog_storage_root: s3://databricks-bucket-sagara/sagara-free-edition/uc-bundle-dev-catalog
schema_name: bundle_dev_schema
table_name: target_test_table
prod:
variables:
catalog_name: uc_bundle_prod_catalog
catalog_storage_root: s3://databricks-bucket-sagara/sagara-free-edition/uc-bundle-prod-catalog
schema_name: bundle_prod_schema
table_name: target_test_table
ポイントは下記の通りです。
- Serverless computeのためCompute指定なし
- 今回はDatabricks Free EditionのServerless WorkspaceでNotebook taskを実行するため、Job taskには
existing_cluster_id、new_cluster、job_cluster_keyなどのCompute指定を書いていません。serverless computeのCompute設定はDatabricks側で管理されます。
- 今回はDatabricks Free EditionのServerless WorkspaceでNotebook taskを実行するため、Job taskには
- Catalog の
storage_rootを target ごとに変数化- ユーザー管理 S3 の External Location 配下のパスを
catalog_storage_root変数に切り出し、dev / prod で別々の S3 prefix を使えるようにしています storage_rootに指定するのは__unitystorage以降を含まない root path です(DESCRIBE DETAILで表示される table の location 全体ではありません)
- ユーザー管理 S3 の External Location 配下のパスを
- Catalog / Schema / Tableのdev / prod分岐は
targetsで管理
2. テーブル作成用のNotebookを作成する
src/create_table.pyを以下の内容で作成します。bundle_targetをテーブルに書き込んでおくことで、後でdev / prodどちらから実行されたかが確認できるようにしています。
# Databricks notebook source
import re
dbutils.widgets.text("catalog_name", "")
dbutils.widgets.text("schema_name", "")
dbutils.widgets.text("table_name", "")
dbutils.widgets.text("bundle_target", "")
catalog_name = dbutils.widgets.get("catalog_name")
schema_name = dbutils.widgets.get("schema_name")
table_name = dbutils.widgets.get("table_name")
bundle_target = dbutils.widgets.get("bundle_target")
def validate_identifier(value: str, name: str):
if not re.match(r"^[A-Za-z_][A-Za-z0-9_]*$", value):
raise ValueError(f"Invalid {name}: {value}")
validate_identifier(catalog_name, "catalog_name")
validate_identifier(schema_name, "schema_name")
validate_identifier(table_name, "table_name")
full_table_name = f"`{catalog_name}`.`{schema_name}`.`{table_name}`"
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {full_table_name} (
id BIGINT,
bundle_target STRING,
message STRING,
created_at TIMESTAMP
)
USING DELTA
""")
spark.sql(f"""
INSERT INTO {full_table_name}
SELECT
1 AS id,
'{bundle_target}' AS bundle_target,
'created from Databricks Asset Bundle target' AS message,
current_timestamp() AS created_at
""")
display(spark.sql(f"SELECT * FROM {full_table_name}"))
3. dev targetでvalidate / plan / deploy / runを順に実行する
各コマンドに-t devを指定して実行していきます。
まずはvalidateでdatabricks.ymlの構文チェックを行います。
databricks bundle validate -t dev
エラーが出ずに完了すればOKです。

次に、bundle planでdeploy前に作成・更新されるリソースの一覧を確認します。Catalog・Job・Schemaが作られることがわかります。
databricks bundle plan -t dev

問題なければ、bundle deployでdev環境にデプロイします。
databricks bundle deploy -t dev

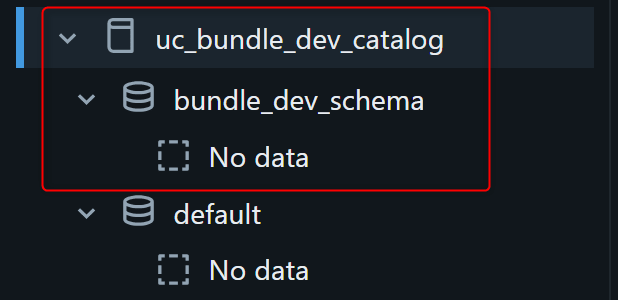
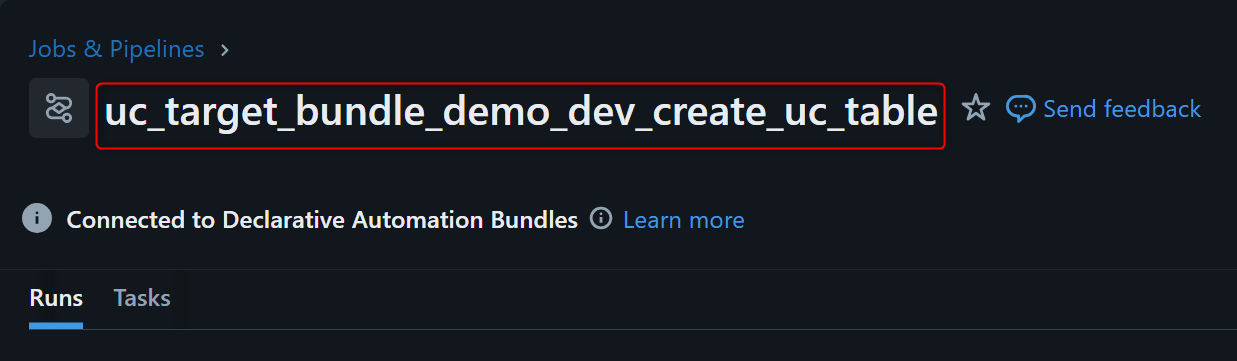
deployに成功すると、以下のリソースが作成されているはずです。
Catalog: uc_bundle_dev_catalog
Schema : uc_bundle_dev_catalog.bundle_dev_schema
Job : uc_target_bundle_demo_dev_create_uc_table
最後に、deployしたJobをbundle runで実行します。
databricks bundle run -t dev create_uc_table

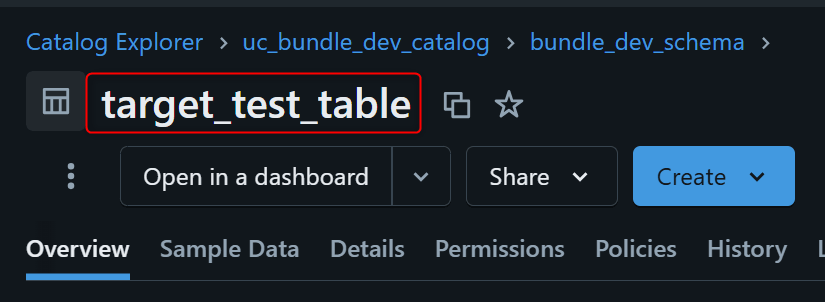
Job実行が成功すると、以下のテーブルが作成されます。
uc_bundle_dev_catalog.bundle_dev_schema.target_test_table
4. prod targetでも同じ流れで実行する
prod向けも、-tに渡すtarget名をdevからprodに切り替えるだけです。(各種実行ログの画像は省略します。)
databricks bundle validate -t prod
databricks bundle plan -t prod
databricks bundle deploy -t prod
databricks bundle run -t prod create_uc_table
deploy / run後は、以下のリソースが作成されているはずです。
Catalog: uc_bundle_prod_catalog
Schema : uc_bundle_prod_catalog.bundle_prod_schema
Job : uc_target_bundle_demo_prod_create_uc_table
Table : uc_bundle_prod_catalog.bundle_prod_schema.target_test_table

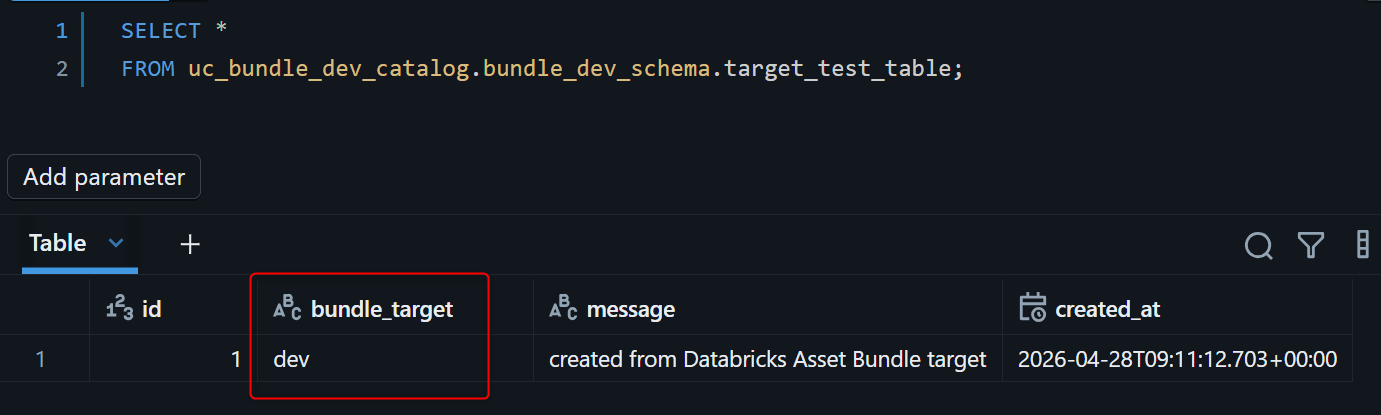
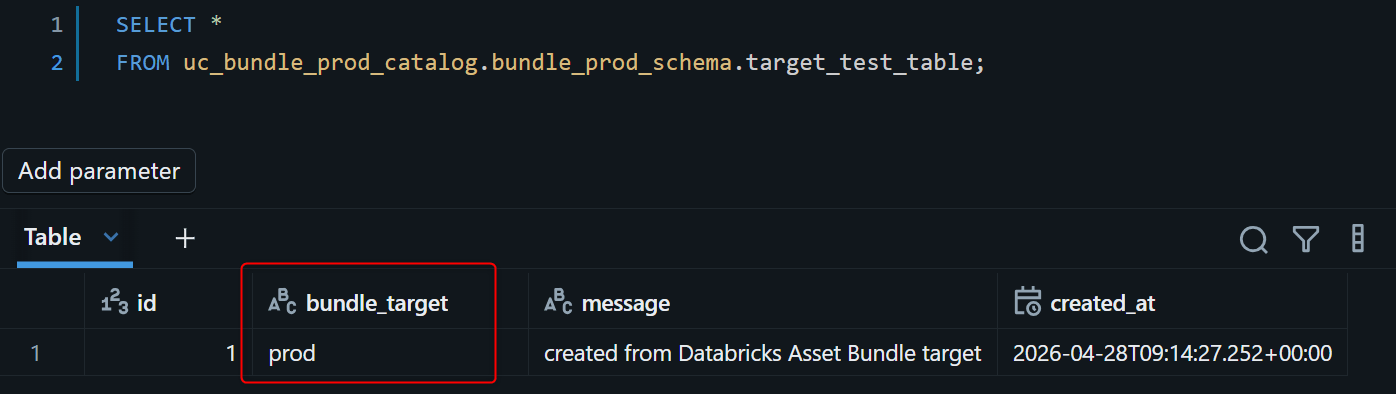
5. 確認SQLでdev / prodそれぞれのTableを確認
Databricks SQL EditorまたはNotebookから、dev / prodそれぞれのTableをクエリして確認します。
Jobの内容の通り、bundle_targetカラムがtargetの値ごとに分かれて入っていることが確認できました!
6. 後片付け
今回のdatabricks.ymlでは、Catalog / Schemaに以下を付けています。
lifecycle:
prevent_destroy: true
これにより、誤ってbundle destroyを実行してもCatalog / Schemaが削除されないようにしています。検証後に明示的にCatalog / Schemaを削除する場合は、Databricks SQLから以下を実行してください。
-- dev側
DROP TABLE IF EXISTS uc_bundle_dev_catalog.bundle_dev_schema.target_test_table;
DROP SCHEMA IF EXISTS uc_bundle_dev_catalog.bundle_dev_schema;
DROP CATALOG IF EXISTS uc_bundle_dev_catalog;
-- prod側
DROP TABLE IF EXISTS uc_bundle_prod_catalog.bundle_prod_schema.target_test_table;
DROP SCHEMA IF EXISTS uc_bundle_prod_catalog.bundle_prod_schema;
DROP CATALOG IF EXISTS uc_bundle_prod_catalog;
最後に
Databricks Declarative Automation Bundlesを実際に試してみました。今回の検証を通じて、この機能が特に役立つと感じた場面をまとめます。
- チームでDatabricksリソースをコードで管理したいとき
databricks.ymlにJob・Pipeline・Catalog・Schemaを宣言的に記述し、Gitで管理できます。リソースの変更差分がコードとして明確になるため、コードレビューのプロセスに乗せやすく、「誰かしか設定内容を知らない」という属人化の解消にも役立ちます。
- dev / prodなどの環境を安全に切り替えたいとき
targetsとvariablesの組み合わせで、環境ごとのCatalog名・Schema名・storage_rootなどの差分をdatabricks.yml内で一元管理できます。デプロイ時に-t devや-t prodを指定するだけで切り替えられるため、環境間の設定ミスや混在を防ぎやすくなります。
- CI/CDパイプラインへのDatabricksデプロイを自動化したいとき
bundle validate→bundle plan→bundle deploy→bundle runの一連のフローがCLIコマンドで完結します。GitHub ActionsやGitLab CIとの連携も自然で、コードのpushをトリガーにした自動デプロイ・自動実行を実現しやすくなります。
この記事がどなたかの参考になると幸いです!










