
Cloud SQL for PostgreSQL の CDC データを Datastream で BigQuery に転送してみた
データ事業本部のはんざわです。
みなさんは機械学習などの用途でトランザクション DB のデータをリアルタイムにデータウェアハウスへ連携させたいと思ったことはありませんか?
Google Cloud には、このようなユースケースに対して、各種 RDBMS の CDC(Change Data Capture)データを BigQuery にシームレスかつリアルタイムに同期・転送できる Datastream というサービスがあります。
今回のブログでは、この Datastream を使って、Cloud SQL for PostgreSQL のデータを BigQuery にリアルタイムに連携する方法を実際に試してみたいと思います。
Datastream の概要
前述のとおり、Datastream は各種 RDBMS の CDC データをサーバーレスで BigQuery にシームレスかつリアルタイムに同期・転送できるサービスです。
様々なソースからほぼリアルタイムにデータを取り込み、複数の書き込み先に反映することが可能です。
投稿日時点で対応している取り込み元と書き込み先は、以下のとおりです。
-
取り込み元
- データベース
- アプリケーション
-
書き込み先
Datastream の構成要素
Datastream は、大きく分けて「接続構成」「接続プロファイル」「ストリーム」の 3 つの要素で構成されています。
接続構成
接続構成には、Datastream がプライベートネットワーク経由でデータソースと通信するための情報が含まれます。パブリックインターネット経由での接続で問題がない場合は、設定不要です。
プライベート接続の方式としては、Private Service Connect もしくは VPC ピアリングを利用します。
詳細は、上記ドキュメントを参照してください。
接続プロファイル
接続プロファイルでは、取り込み元と書き込み先に必要な接続情報を設定します。
たとえば、PostgreSQL データベース用の接続プロファイルには、ホスト名・ユーザー名・データベース名などを登録します。書き込み先である BigQuery 用の接続プロファイルも別途作成が必要です。
また、ネットワークの接続方法も接続プロファイルで指定します。プライベートネットワーク経由で接続する場合は、前述した 接続構成 を利用します。一方、パブリックインターネット経由であれば、IP 許可リストかフォワード SSH トンネルで接続することができます。
ストリーム
ストリームでは、接続プロファイルを基に取り込み元と書き込み先を組み合わせて、実際のデータ転送処理を定義します。
ここで、取り込み元データソースのうちどのスキーマ・テーブルを対象にするか、書き込み先のデータセット、書き込み方式などを設定します。
試してみる
それでは、さっそく Datastream を試してみたいと思います。今回の検証は以下の条件で行います。
- 取り込み元:Cloud SQL for PostgreSQL
- 書き込み先:BigQuery
- Cloud SQL の構成
- DB のバージョン:PostgreSQL 18
- パブリック IP 接続を許可
- Datastream の構成
- 接続方法:IP 許可リスト
1. Cloud SQL のセットアップ
まずは、Cloud SQL のインスタンスを立ち上げます。構成内容は以下の通りです。
| 設定項目 | 設定内容 |
|---|---|
| インスタンス ID | cloudsql-for-datastream |
| Cloud SQL のエディション | Enterprise |
| リージョン | asia-northeast1(東京) |
| DB のバージョン | PostgreSQL 18 |
| vCPU | 1 vCPU |
| RAM | 3.75 GB |
| ストレージ | 10 GB SSD |
| 接続方法 | パブリック IP |
インスタンスの立ち上げが完了したら、以下のクエリで検証用のデータを準備します。
-- 検証用のデータベースを作成
CREATE DATABASE bq_test_db;
-- 検証用のテーブルを作成
CREATE TABLE sales (
sale_date DATE,
product_id INT,
amount NUMERIC(10,2)
);
-- 検証用のデータを追加
INSERT INTO sales (sale_date, product_id, amount)
VALUES
('2025-12-01', 1, 1000.00),
('2025-12-02', 2, 2000.50);
検証用のデータが準備できたら、以下のクエリで Datastream が使用するパブリケーションとレプリケーションスロットを作成します。
ALTER USER postgres WITH REPLICATION;
-- パブリケーションを作成
CREATE PUBLICATION datastream_pub FOR ALL TABLES;
-- レプリケーションスロットを作成
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('datastream_slot', 'pgoutput');
2. Datastream のセットアップ
まずは、PostgreSQL と BigQuery 用の接続プロファイルを準備します。
2.1. PostgreSQL の接続プロファイル
PostgreSQL の接続プロファイルの構成内容は以下のとおりです。
| 設定項目 | 設定内容 |
|---|---|
| 接続プロファイルの名前 | cloud-sql-for-postgresql |
| リージョン | asia-northeast1(東京) |
| ホスト名または IP | Cloud SQL のパブリック IP アドレス |
| ポート | 5432(デフォルト) |
| ユーザー名 | postgres(デフォルト) |
| データベース | bq_test_db |
| 暗号化のタイプ | なし |
| 接続方法 | IP 許可リスト |
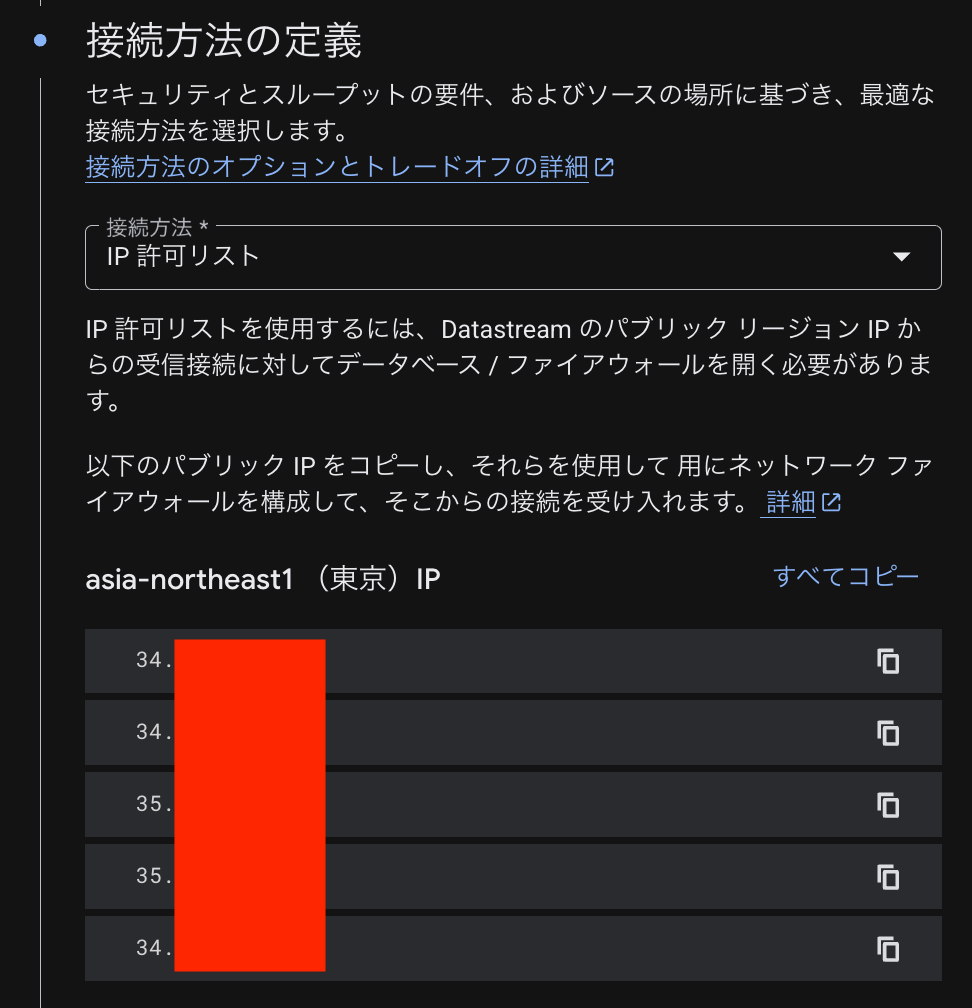
以下のように、接続方法の設定箇所で IP 許可リスト を選択すると、Datastream が使用する IP が表示されます。
Cloud SQL インスタンスの 接続 タブにある 承認済みネットワーク にこれらの IP を登録します。
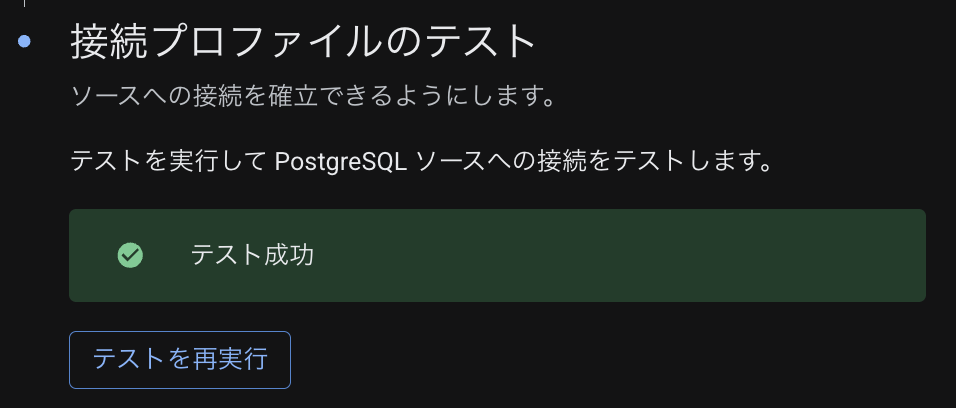
最後に、プロファイルの接続テストを実行し、以下のように テスト成功 の表示が出れば OK です。
2.2. BigQuery の接続プロファイル
BigQuery の接続プロファイルの構成内容は以下のとおりです。
| 設定項目 | 設定内容 |
|---|---|
| 接続プロファイルの名前 | bigquery |
| リージョン | asia-northeast1(東京) |
BigQuery の接続プロファイルの設定はシンプルです。
2.3. ストリームの作成
最後に、ストリームを作成します。
| 設定項目 | 設定内容 |
|---|---|
| ストリームの名前 | postgresql-to-bigquery |
| リージョン | asia-northeast1(東京) |
| 読み込み元の接続プロファイル | cloud-sql-for-postgresql |
| レプリケーションスロット名 | datastream_slot |
| パブリケーション名 | datastream_pub |
| 読み込みに含めるオブジェクト | 特定のスキーマとテーブル(salesのみを選択) |
| 書き込み先の接続プロファイル | bigquery |
| スキーマのグループ化 | 各スキーマのデータセット |
| データセットのリージョン | asia-northeast1(東京) |
| ストリームの書き込みモード | 追加のみ |
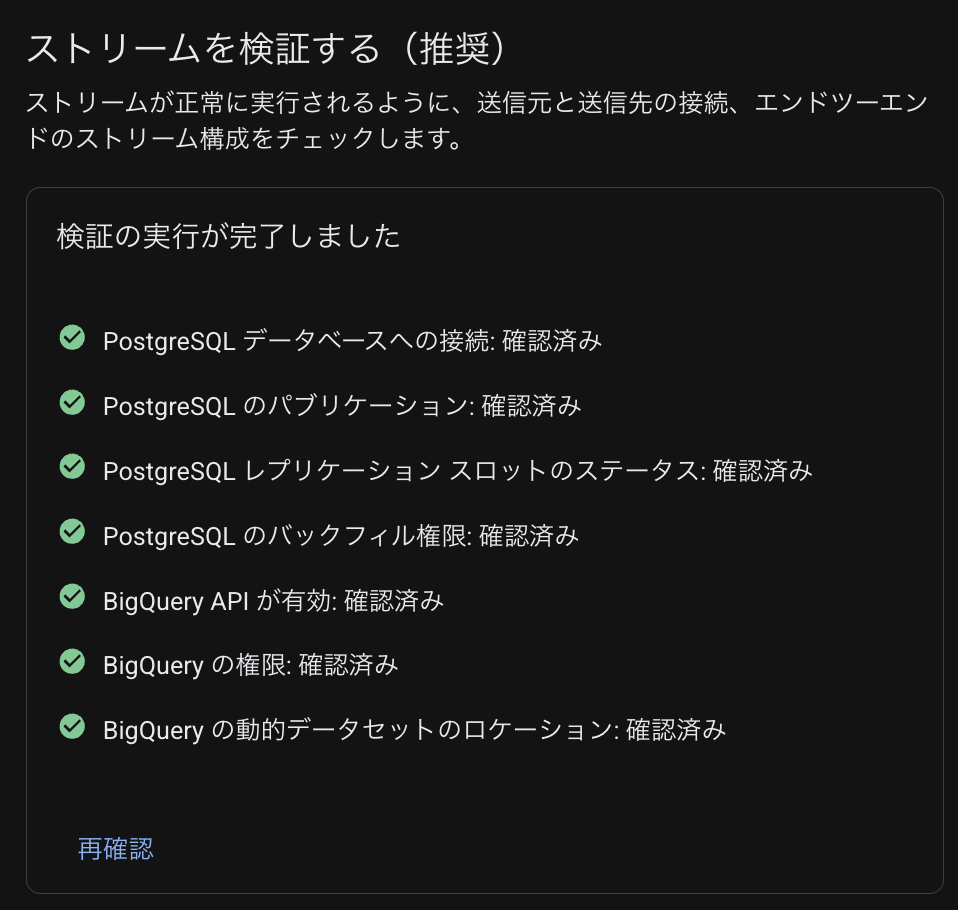
ここまでの設定が完了したらストリームの接続確認を実行し、以下のように問題なければ OK です。
動かしてみる
まず、作成したストリームを選択し、開始 をクリックします。
しばらく待ち、ステータスが 実行中 になればストリームの起動は完了です。

続いて、BigQuery 側にデータが書き込まれているかを確認します。
Datastream が自動的に作成したデータセットとテーブルを確認すると、Cloud SQL の sales テーブルのデータが BigQuery に反映されていることが確認できました。

まとめ
本記事では、Datastream の概要を簡単に紹介しつつ、Cloud SQL for PostgreSQL から BigQuery へデータを連携する手順を実際に試しました。
今後は、Datastream の料金体系や運用時の注意点などもう少し踏み込んだ内容も紹介していけたらと思っています。








