
dbt CloudのCanvas機能を使ってGUIでデータ変換してみた
かわばたです。
dbt CloudのCanvasは、SQLコードを直接記述することなく、GUIを通じてデータ変換モデルを構築・編集できる機能です。ドラッグ&ドロップの直感的な操作でデータパイプラインを視覚的に組み立てることができ、幅広いユーザーによるdbtの活用が期待できます。
この記事では、dbt CloudのCanvas機能を基本的な使い方からデータ加工・GitHubのマージまで試していきます。
【公式ドキュメント】
対象読者
- dbt CloudのCanvas機能や基本的な操作について興味のある方
- SQLの学習コストを下げて、自身でデータマートを作りたい方
事前準備と検証環境
Canvasを試すには、いくつかの準備が必要です。
必要な環境
dbt Cloudのプラン: Canvas機能はEnterpriseプラン以上で利用可能です。
接続設定済みのデータウェアハウス: Snowflake, BigQuery, Redhift, Databricksなどのデータウェアハウスへの接続が完了している必要があります。かわばたはSnowflakeのトライアルアカウントEnterprise版で試しています。
サンプルプロジェクト: この記事では、生成AIで作成したダミーデータを例に進めますが、ご自身のプロジェクトでも問題ありません。
使用するデータ
使用データの概要は下記です。
顧客データ 25行
| user_id | user_name | created_at |
|---|---|---|
| 101 | 田中 太郎 | 2024-01-15 |
| 102 | 鈴木 花子 | 2024-02-20 |
| 103 | 佐藤 次郎 | 2024-03-10 |
| 104 | 高橋 三郎 | 2024-04-05 |
| 105 | 伊藤 四郎 | 2024-05-21 |
| ~~~ | ~~~ | ~~~ |
製品データ 25行
| product_id | product_name | price |
|---|---|---|
| 201 | リンゴ | 150 |
| 202 | バナナ | 100 |
| 203 | オレンジ | 120 |
| 204 | 牛乳 | 250 |
| 205 | パン | 180 |
| ~~~ | ~~~ | ~~~ |
注文データ 100行
| order_id | user_id | product_id | quantity | order_date | status |
|---|---|---|---|---|---|
| 3001 | 101 | 201 | 5 | 2024-06-01 | completed |
| 3002 | 102 | 204 | 1 | 2024-06-01 | completed |
| 3003 | 101 | 205 | 2 | 2024-06-02 | shipped |
| 3004 | 103 | 202 | 10 | 2024-06-03 | completed |
| 3005 | 104 | 203 | 3 | 2024-06-05 | shipped |
| 3006 | 102 | 201 | 2 | 2024-06-05 | pending |
| 3007 | 105 | 205 | 1 | 2024-06-08 | completed |
| 3008 | 101 | 204 | 1 | 2024-06-10 | pending |
| ~~~ | ~~~ | ~~~ | ~~~ | ~~~ | ~~~ |
Canvasでデータモデルを構築
それでは、実際にCanvasを使って新しいデータモデルを構築していきます。
今回は「製品ごとの売上金額」を集計するモデルを作成します。
Canvasへのアクセス方法
- dbt CloudのIDEを開き、左側のファイルエクスプローラーの上部にある
Canvasボタンをクリックすると、Canvasのインターフェースが起動します。
+Create new workspaceをクリックします。すると下記ワークスペースに遷移します。
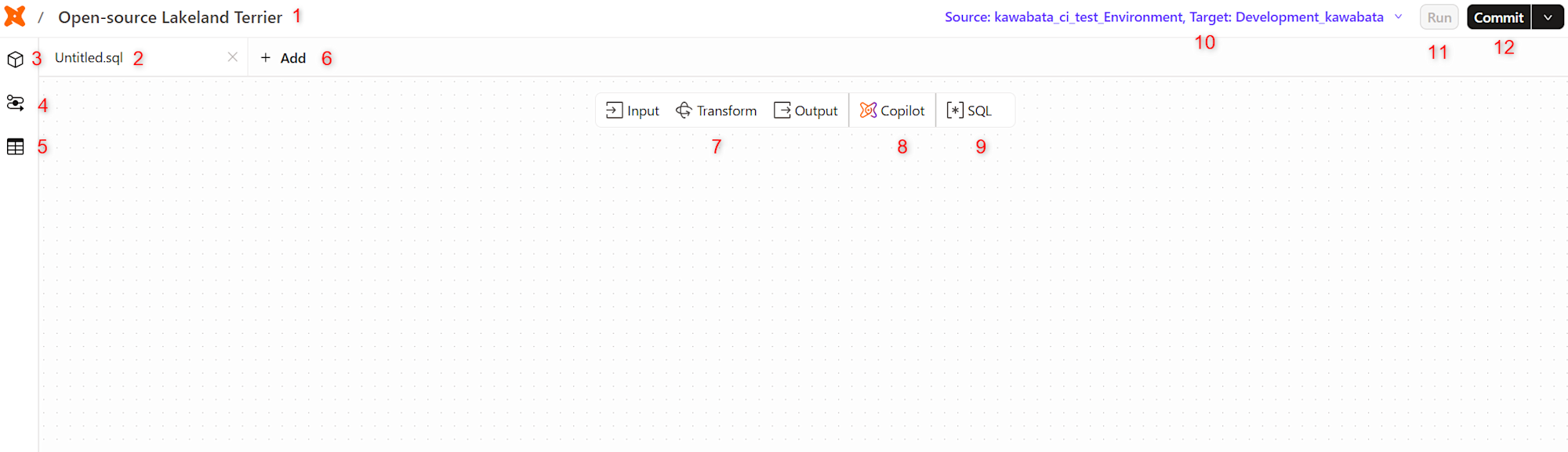
| 番号 | 内容 |
|---|---|
| 1 | メインメニュー(dbtロゴ)とワークスペースのタイトル。タイトルはデフォルトでランダムに設定されますが、クリックすることでいつでも編集できます。 |
| 2 | モデルタブ。モデル名はOutputオペレーターで設定できます。 |
| 3 | モデルアイコン。ワークスペースでモデルを管理します。 |
| 4 | Runsアイコン。警告やエラーなどの実行データが表示されます。 |
| 5 | プレビューアイコン。データのプレビューを表示します。 |
| 6 | 追加オプション。新しいモデルの作成、既存のモデル編集、シードファイルの追加が可能です。 |
| 7 | オペレーターツールバー。ワークスペースでモデルを作成するための構成要素が含まれています。 |
| 8 | Copilotアイコン。自然言語を使用してCanvasモデルを構築できます。 |
| 9 | SQLコードアイコン。モデルをコンパイルするSQLが表示されます。 |
| 10 | ソースタブ。ソースとなるEnvironmentを設定できます。 |
| 11 | Runアイコン。モデルに対してdbt runを実行します。 |
| 12 | Commitアイコン。プロジェクトに対してセットアップしたGitリポジトリにCommitを行う。 |
新しいモデルを作成
-
Inputの選択
まず、モデルの元となるテーブルを選択します。
オペレーターツールバーの「Input」セクションからModel Explorerをワークスペースにドラッグ&ドロップします。
-
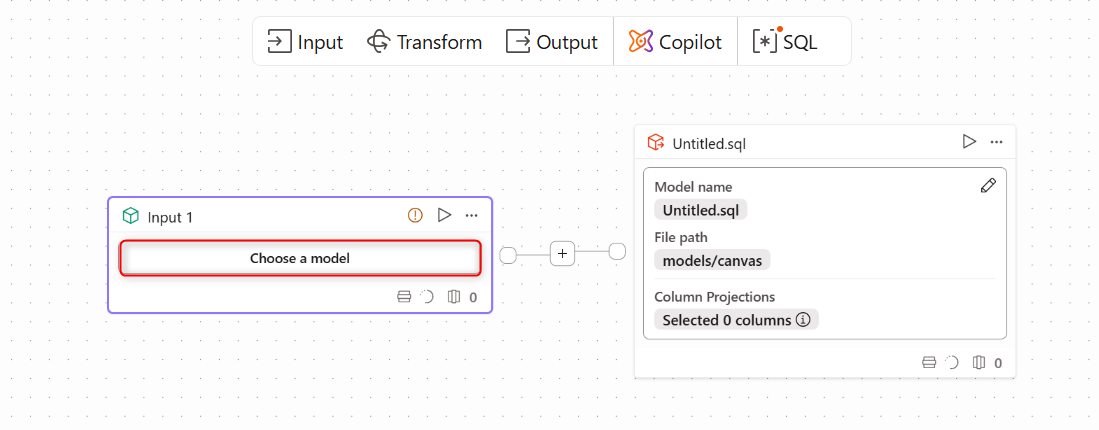
下記画面のようにinputとoutputを設定する画面が表示されます。inputの
Choose a modelをクリックします。
- モデル一覧が表示されるので、使用したいモデルを選択し
Select modelをクリックします。
ここでは赤枠で囲った3つのモデルをそれぞれ選択しますが、ordersから選択しています。
※余談ですが、descriptionでモデルの説明を書いてあると表記されるのは分かりやすくて良いですね!
同様の処理をproduct,usersについても行い下記のようにソースとなるモデルを定義できました。
【小ネタ】
赤枠のアイコンをクリックするとコメントが記載できます。
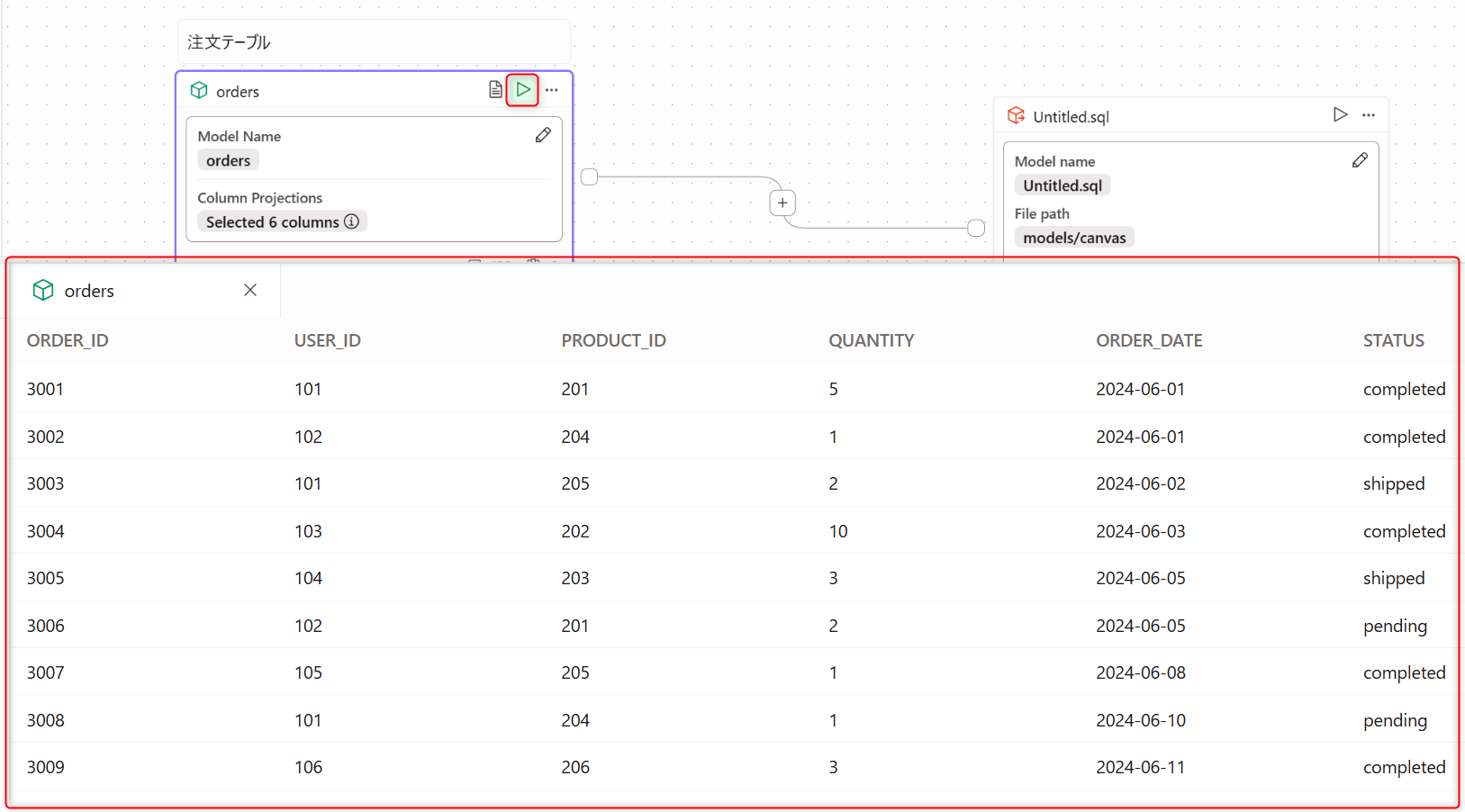
赤枠のアイコンをクリックするとデータのプレビューを確認することが出来ます。
結合
次に、3つのテーブルを結合していきます。
1.「Transform」セクションからJoinオペレーターをドラッグし、ワークスペースにドロップします。
もしくは、赤枠のアイコンをクリックするとAdd operatorが表示されるのでjoinを選択しても問題ありません。
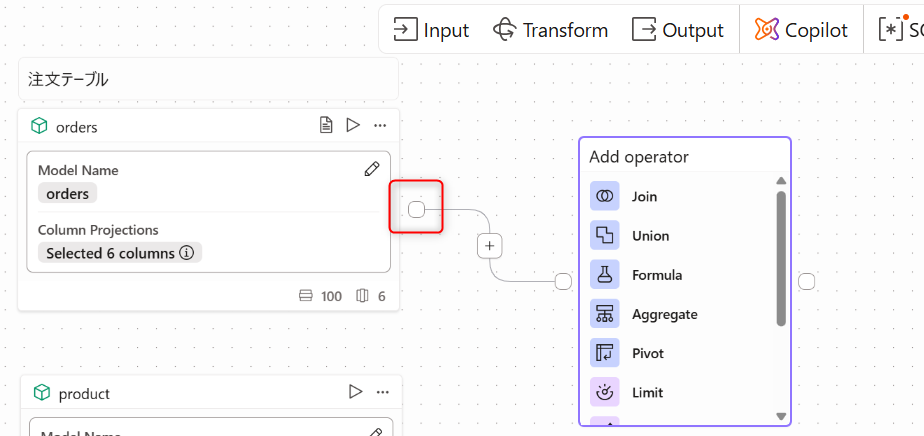
2.下記のようにjoinオペレーターをL側にorders,R側にproductを紐づけます。
続いて、Combine inputsをクリックします。
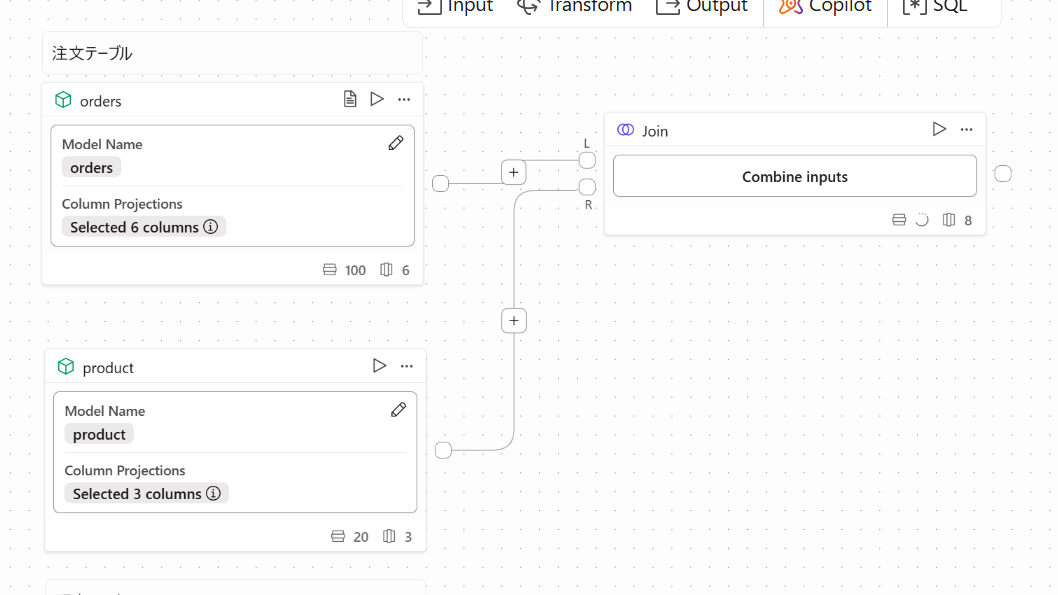
- すると下記項目が表示されるので
JoinTypeと結合キーを選択します。
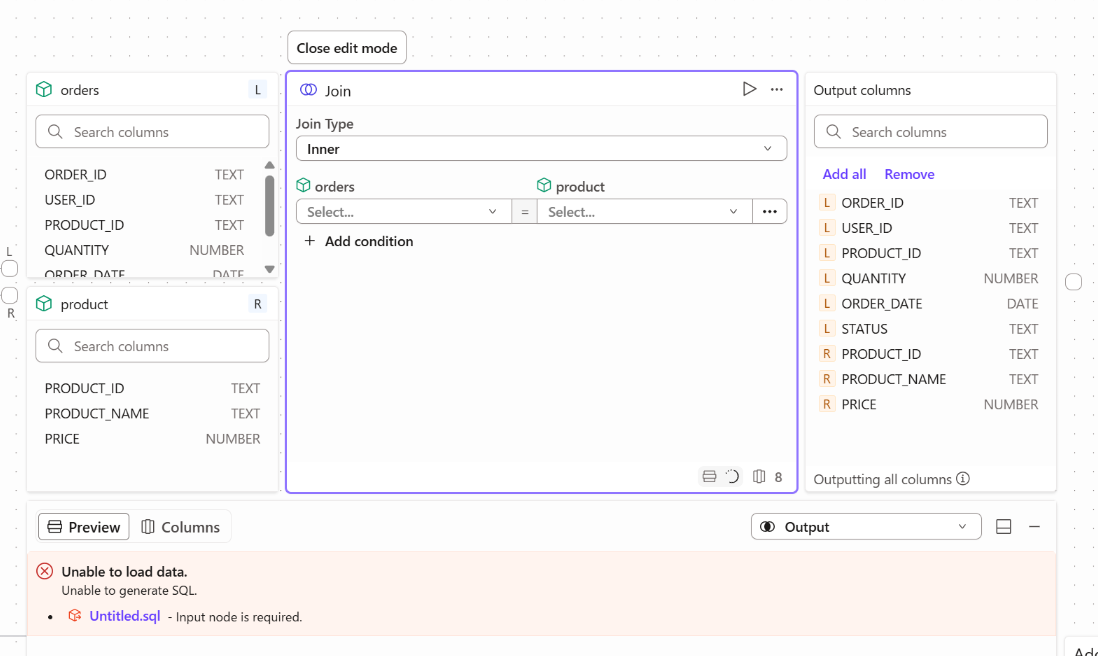
今回はJoinTypeはLeft,結合キーはProduct_IDとしました。
下記のように紐づけることが出来ました。
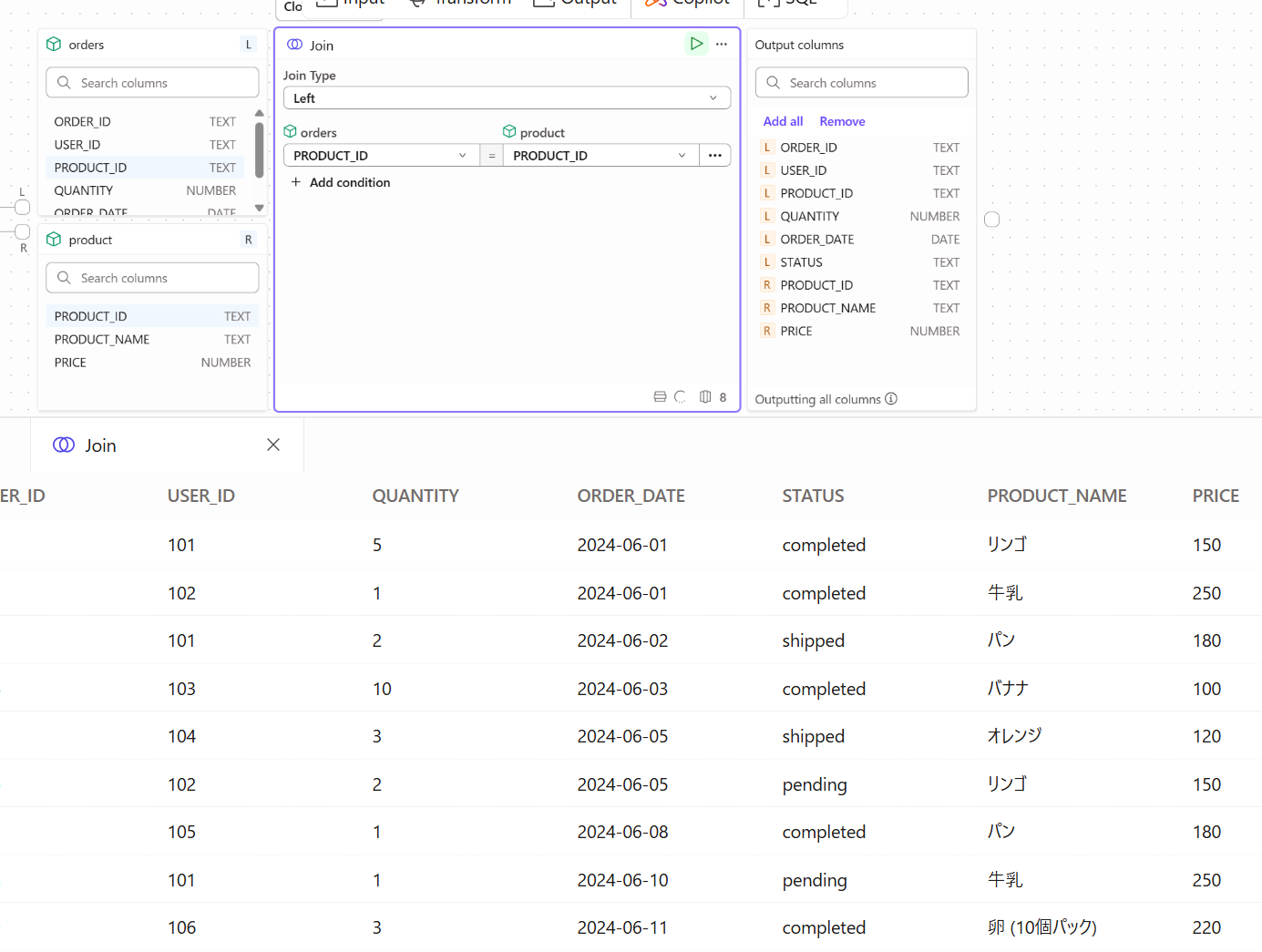
上記内容とusersも同様に結合し下記のようになりました。
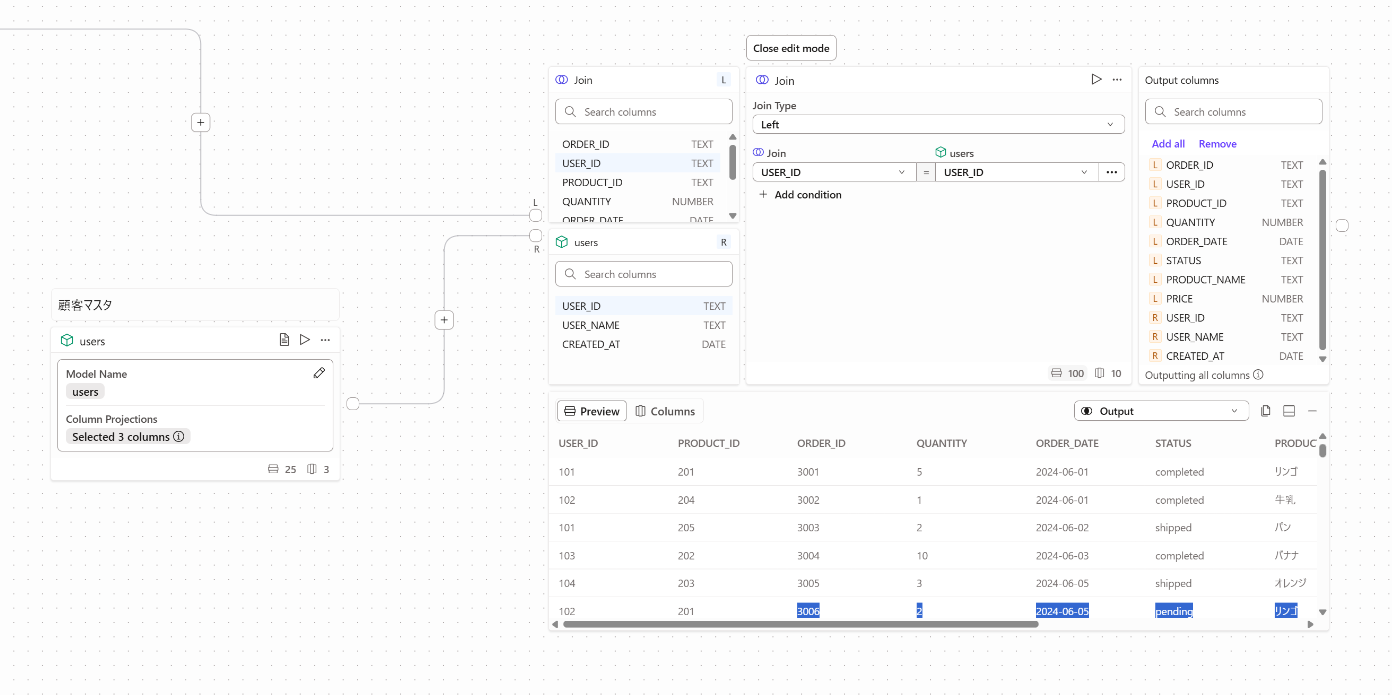
集計
次に、Product_IDごとに金額を集計します。
PRICEカラムは存在しますが、QUANTITYカラムも存在するので、合計の金額を新しくカラムとして追加したいです。そのため下記Formulaオペレーターをさきほど作成したJoinオペレーターに接続します。
-
Formulaオペレーターを下記のように設定します。
Expressionに計算式であるPRICE*QUANTITYをいれAliasにカラム名total_priceを記載しました。
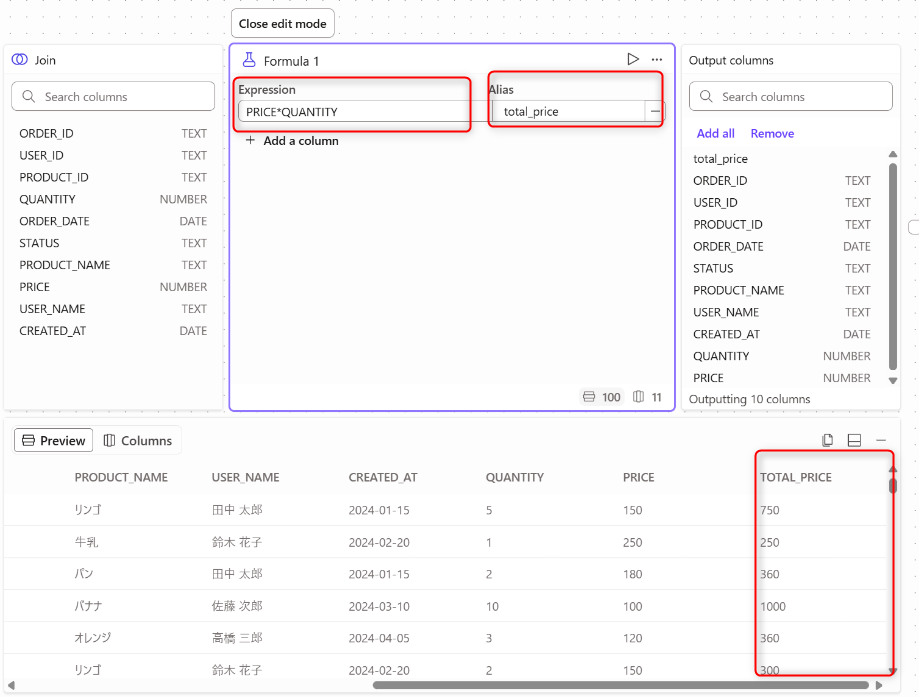
-
続いて金額を算出するために、Aggregateオペレーターを接続します。
-
Configure aggregationをクリックします。

-
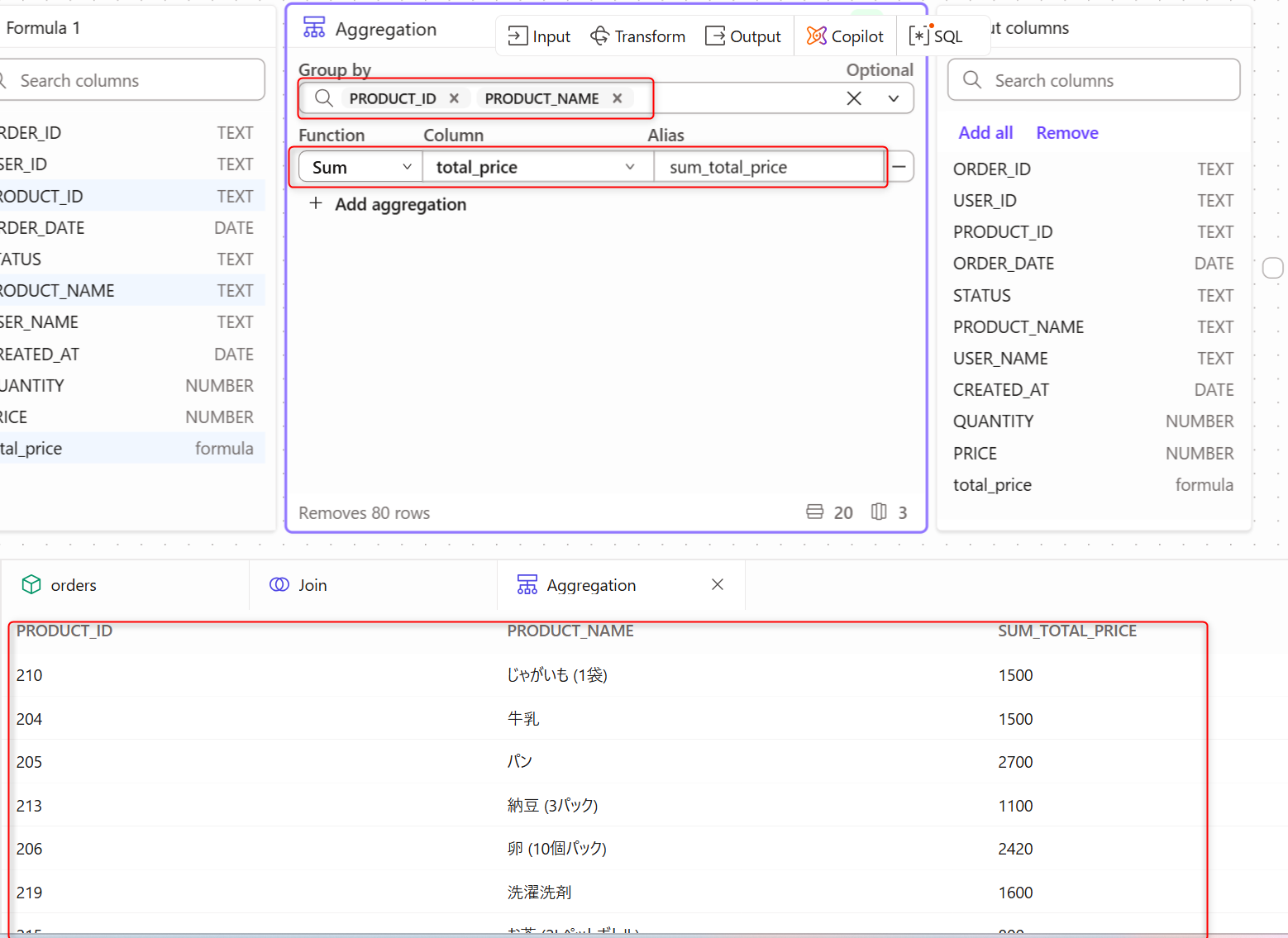
下記画面が表示されるので、
Group byの項目にPRODUCT_IDとPRODUCT_NAMEを追加。FunctionタブでSumを選択。Columnタブで先ほど作成したtotal_priceを選択します。
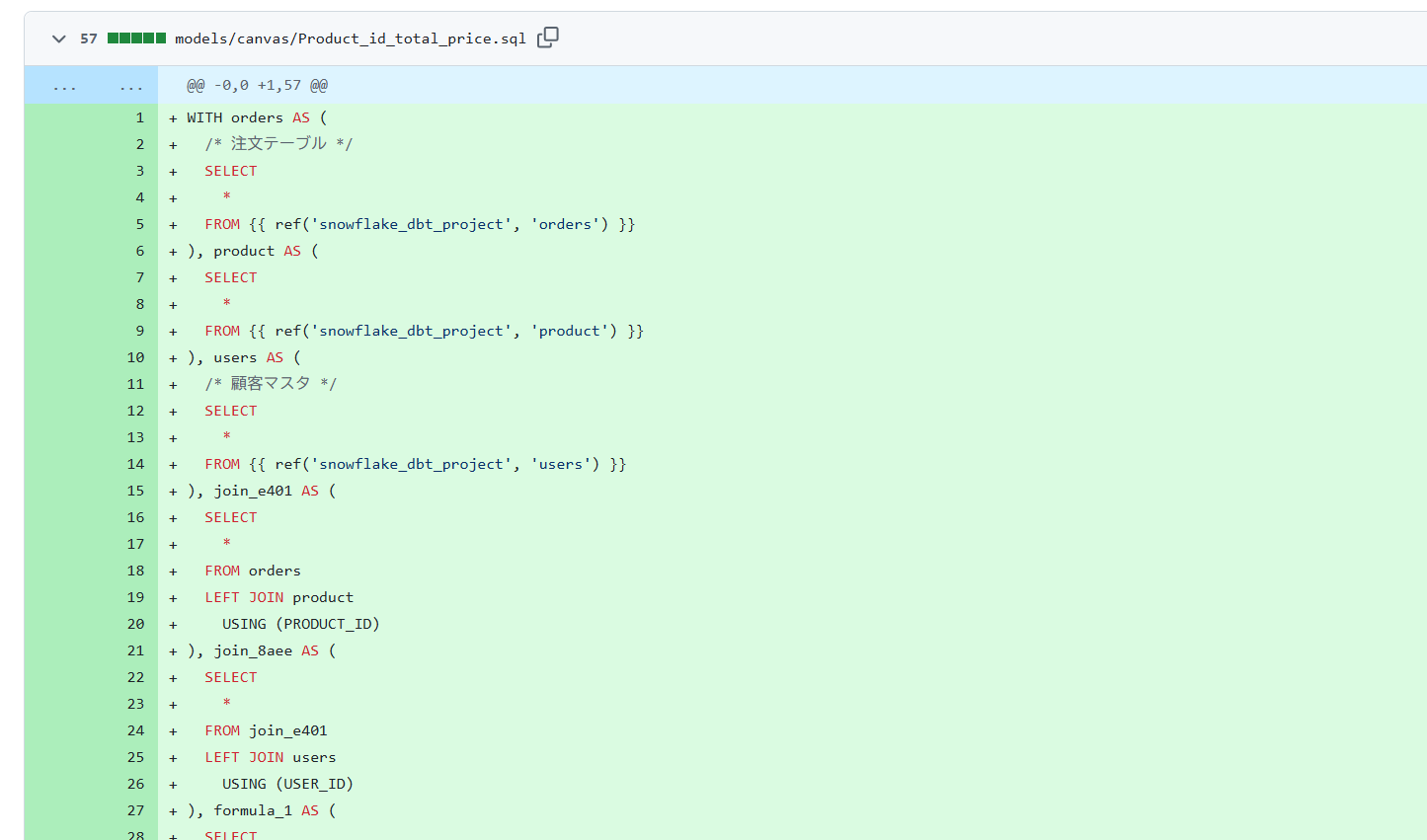
生成されたSQLの確認
Canvasの素晴らしい点の一つが、GUIでの操作がリアルタイムでSQLコードに変換されることです。
各オペレーターを選択した状態で、設定パネルの「SQL」タブをクリックすると、その時点までに生成されたSQLを確認できます。これにより、「GUIの裏で、どのようなロジックが組まれているのか」が一目瞭然となり、エンジニアも安心して利用できます。
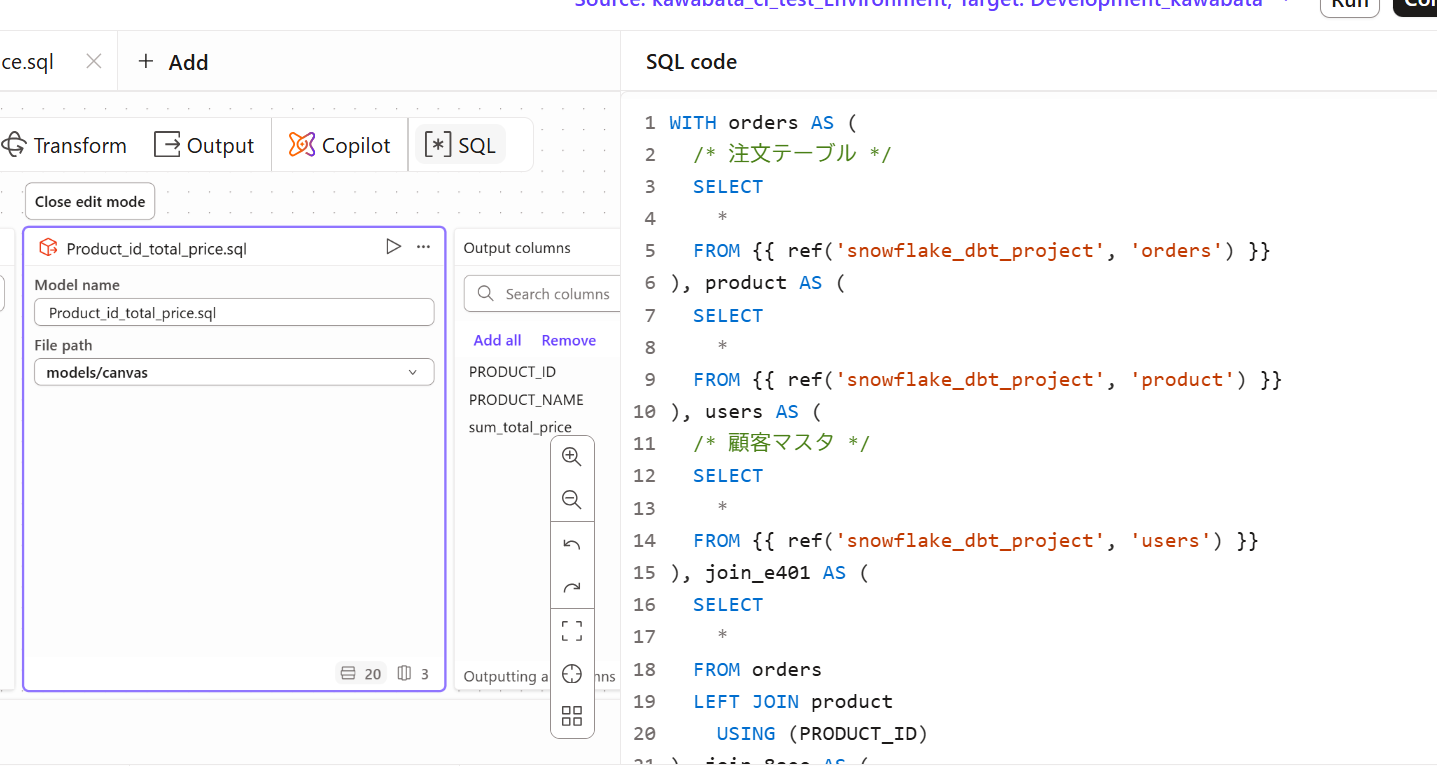
※試していて気づいたのですが、オペレーターでコメントを追加した箇所はSQL側にもコメントが反映されていて良いですね。より可読性が上がるので積極的にコメントを入れていきたいです。
モデルの保存と実行
最後に、「Output」セクションからOutputオペレーターをAggregateオペレーターの後に接続し、モデル名をProduct_id_total_priceなどと設定します。
File pathはモデルを保存する場所を指しています。デフォルトではmodels/canvasとなっています。
実際に実行していきます。
右上部にあるRunをクリックします。
画面下部に下記画面が表示され、成功していることが確認できました。
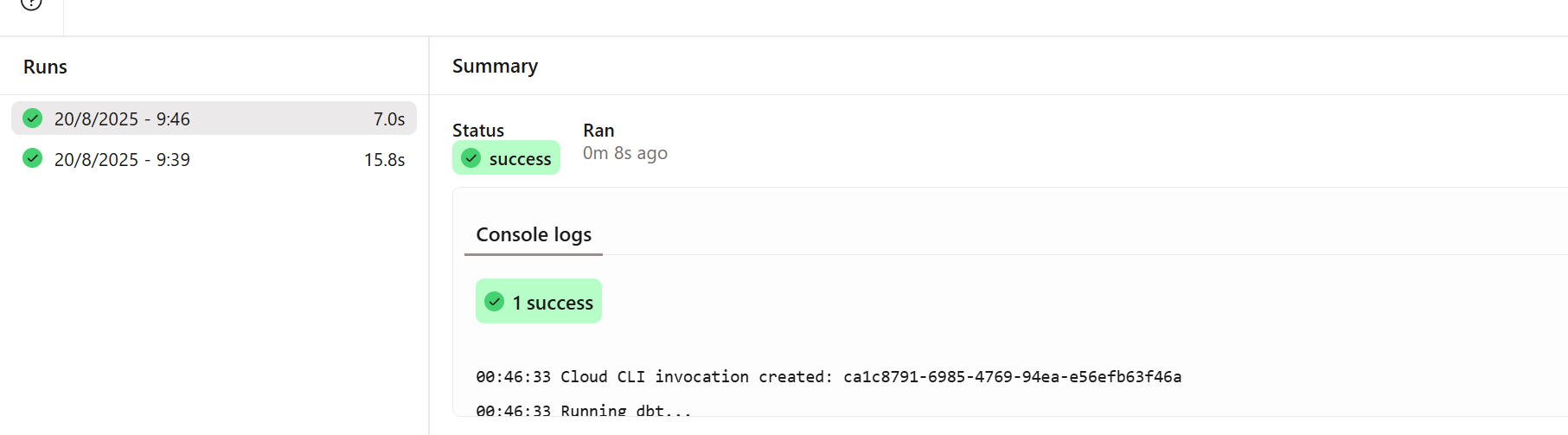
連携しているSnowflakeにも保存が確認できました。

GitHubへMerge
Canvasで作成したモデルをGitHubへMergeしていきます。
右上部にあるCreate a pull requestをクリックします。
GitHub画面へ遷移するので、通常通りレビューを行いMerge処理を行います。
GitHubのmainへ反映することが出来ました。
まとめ
dbt Cloud Canvasは、データエンジニアリングの専門知識の有無にかかわらず、より多くの人がデータ変換のプロセスに参加できるようにするツールであると思います。広く展開するためにも、権限回りやデータ基盤の整備がますます重要になってくると感じました。
ぜひ試してみてください!









