
dbt FusionのPrivate Preview機能であるState-aware orchestrationをdbt platformで試してみた
かわばたです。
2026年5月のアップデートで、dbt platform(旧 dbt Cloud)上での Fusion と Snowflake の接続機能(Fusion + Snowflake connection experience)が一般提供となりました。
下記ブログにて内容がまとめられているので、ぜひご確認ください!
今回はState-aware orchestrationについて、各種判定条件の挙動を確認してみたので、手順と確認結果をまとめます。
機能概要
State-aware orchestration は、dbt Core の state:modified+ や source_status:fresher+ のような「前回 artifacts との差分セレクタ」とは異なり、環境内で共有されるモデル単位のリアルタイム状態を使い、各ジョブ実行時に「そのモデルを再ビルドすると結果が変わる可能性があるか」を判定して、必要なモデルだけを実行します。
コア原則
State-aware orchestration は以下の4つの原則に基づいています。
| 原則 | 説明 |
|---|---|
| Real-time shared state | すべてのジョブがモデル単位のリアルタイムshared state に読み書きし、変更されたモデルのみを再ビルド |
| Model-level queueing | モデル単位でキューイングし、同時実行による collision を防止、冗長な再ビルドを回避 |
| State-aware and state-agnostic support | 動的(state-aware)にも明示的(state-agnostic)にも deploy job を構成でき、どちらもshared state を更新 |
| Sensible defaults | 追加設定なしでそのまま動作し、必要に応じて高度な設定が可能 |
再ビルド判定のフロー
State-aware orchestration の基本的な判定フローは、概念的には以下のようになります。
ジョブ開始
↓
対象 DAG / job command を解釈
↓
各モデルについてshared state を参照
↓
以下を判定:
- モデルの compiled SQL が実質的に変わったか
- upstream source / upstream model に新しいデータがあるか
- freshness.build_after の条件を満たすか
- updates_on: any / all の条件を満たすか
- 前回 data test 失敗など、再評価が必要な状態か
- warehouse 上の期待テーブルが消えていないか
↓
必要なら build queue に入れる
不要なら Reused として再利用
↓
ビルド完了後、モデル単位のshared state を更新
つまり、ジョブ単位ではなくモデル単位で「ビルドする / 既存結果を再利用する」を決めるのが重要です。すべてのジョブが同じリアルタイムshared state に読み書きするため、あるモデルが別ジョブで既に最新化されていれば、後続ジョブではそのモデルを再ビルドせず再利用できます。
再ビルド判定条件の一覧
| 判定対象 | 再ビルドされる条件 | 補足 |
|---|---|---|
| コード変更 | モデルの compiled SQL が実質的に変わった場合 | whitespace やコメントのような非意味的変更は無視 |
| 上流データ変更 | source または dbt Mesh の upstream model に新しいデータがある場合 | デフォルトでは warehouse metadata を使って検知 |
| freshness / build_after | 新データがあり、かつ最後の build から指定時間が経過した場合 | count / period で制御 |
| updates_on | any なら上流のいずれか、all なら全 direct upstream に新データがある場合 |
デフォルトは any |
| テーブル削除 | warehouse 上の期待テーブルが消えている場合 | コード・データ変更がなくても再ビルド対象 |
| data test 失敗 | 前回そのモデルの data test が失敗している場合 | 古い state を再利用せず再評価 |
| 同時実行 | 同じモデルに複数ジョブが到達した場合、片方が待機し、完了後に再判定 | 衝突防止 |
dbt Core のセレクタとの違い
dbt Core の state:modified+ と source_status:fresher+ は、単一のジョブ実行内で前回の run artifacts との差分を見るものです。一方、State-aware orchestration は以下の点で異なります。
- compiled SQL の意味的な差分(whitespace やコメントを無視)
- 実行時の上流データ状態を評価
- モデル単位の freshness 設定
- 複数ジョブをまたいだshared state
制限事項
- 2026年5月5日時点では Enterprise / Enterprise+ 向け Private preview です
- deploy job のみ対応です(CI job / merge job は非対応)
- SQL models のみ対応です(Python models は非対応)
前提条件
- dbt platform: Enterprise / Enterprise+ アカウント
- ライセンス: Developer seat license
- Fusion engine: 対象 environment で有効化済み
- Environment: production または staging の deployment environment
- データプラットフォーム: Snowflake などの data platform に接続済みプロジェクト
- ジョブ: deploy job を使用すること(CI job / merge job は非対応)
- 権限: ジョブの表示・作成・編集・実行権限
- 本機能のステータス: 2026年5月5日時点で Private preview
事前準備
Fusion engine の有効化
State-aware orchestration は Fusion engine 上で動作するため、事前に Fusion へのアップグレードが必要です。Fusion の有効化手順については、以下の公式ドキュメントを参照してください。
検証用プロジェクトの準備
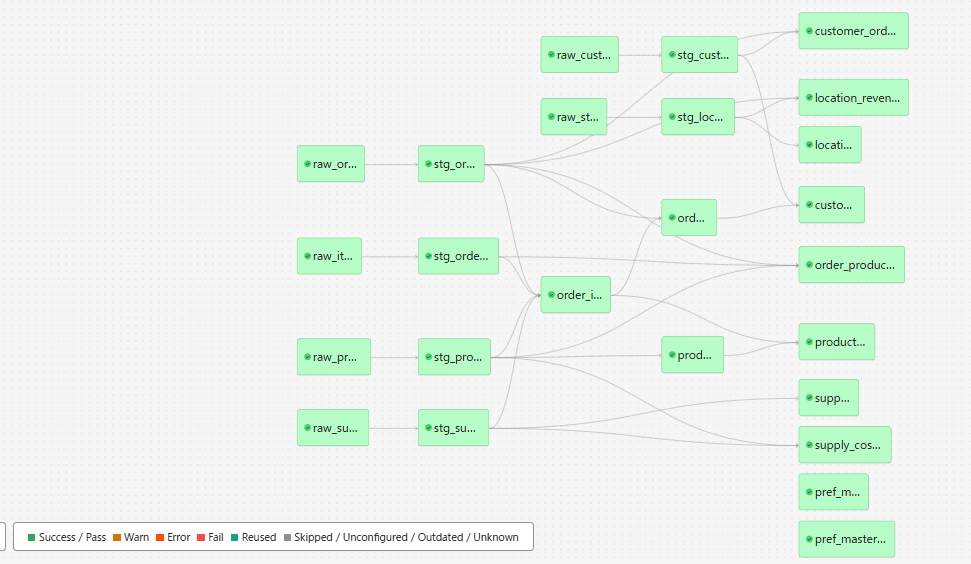
State-aware orchestration の各種判定条件を確認するため、以下の構成で検証用プロジェクトを準備します。本記事では Jaffle Shop のサンプルデータをベースに、intermediate レイヤーを追加したプロジェクトを使用しています。
source がテーブルの場合、Snowflake・BigQuery・Redshift・Databricks などの warehouse metadata 対応アダプターでは、追加設定なしで自動的に freshness を追跡できます。本記事ではこの warehouse metadata による自動検知を利用しています。
source が view の場合や、より明示的に freshness を制御したい場合は loaded_at_field または loaded_at_query を設定できます。
DAG 構成(staging → intermediate → mart):
上記のディレクトリ構成に従い、検証用に以下のようなモデル構成を用意します。
stg_orders: sourceraw.ordersを参照する staging モデルstg_customers: sourceraw.customersを参照する staging モデルint_order_customers:stg_ordersとstg_customersを JOIN する intermediate モデル(updates_onの検証に使用)mart_orders:int_order_customersを参照する mart モデル
State-aware orchestration の有効化
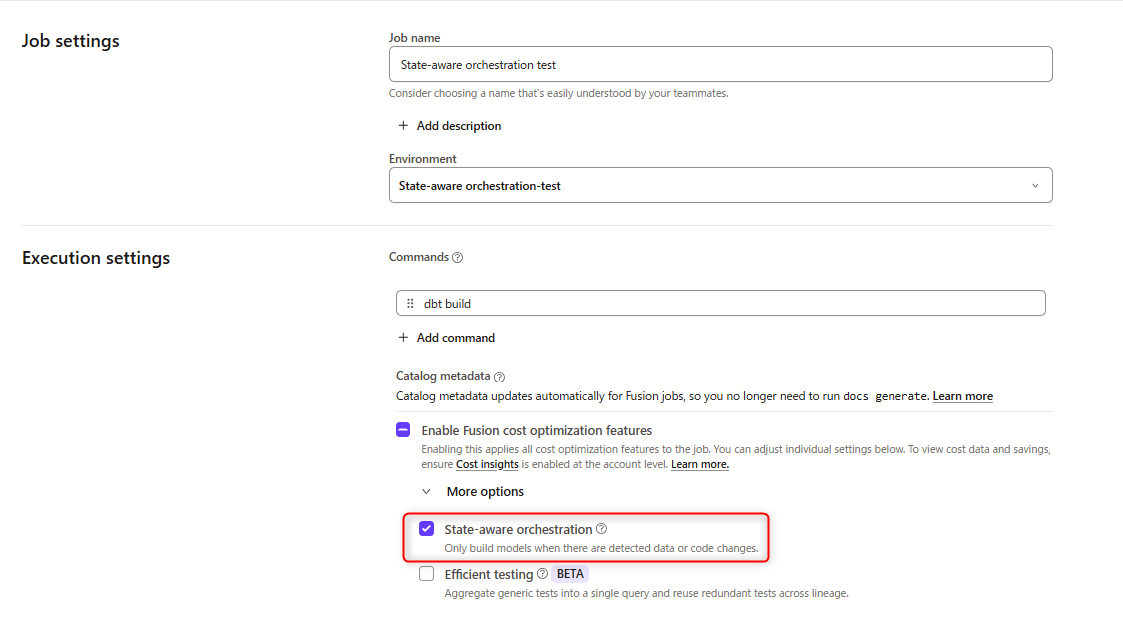
State-aware orchestration へのアクセスが有効なアカウントでは、Fusion environment 上で新規作成した deploy job はデフォルトで state-aware になります。既存の deploy job では、以下の手順で有効化します。
Orchestration→Jobsを開く- 対象の deploy job を選択し、
Editをクリック Execution Settingsセクションで 「Enable Fusion cost optimization features」 にチェックSaveをクリック
試してみた
State-aware orchestration を有効化してジョブを実行
State-aware orchestration を有効化した deploy job で、初回の dbt build を実行します。
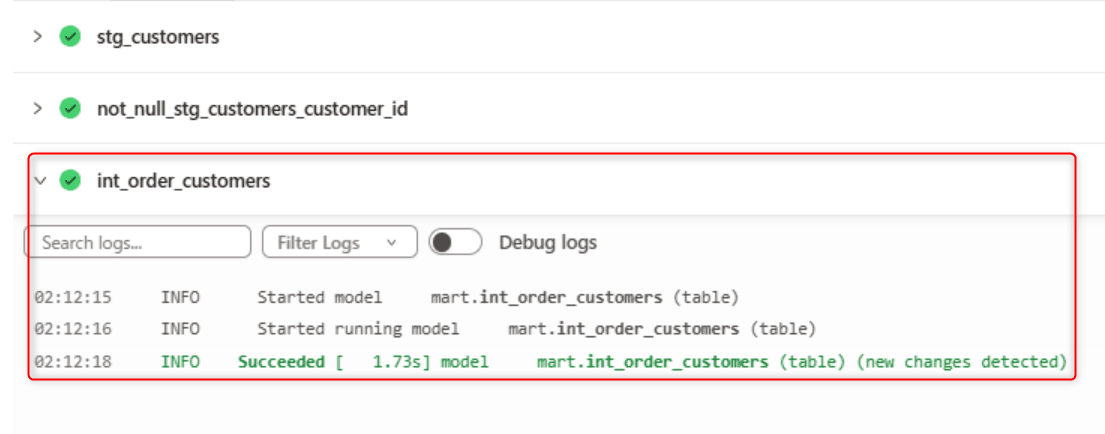
環境内の shared state にまだ対象モデルの情報がない初回実行では、基本的に対象モデルがビルドされます。ただし、State-aware orchestration の state はジョブ単位ではなく環境内で共有されるため、別の deploy job が既に同じモデルを最新化している場合は、新しいジョブの初回実行でも Reused になる可能性があります。
1回目のjob実行はSuccess
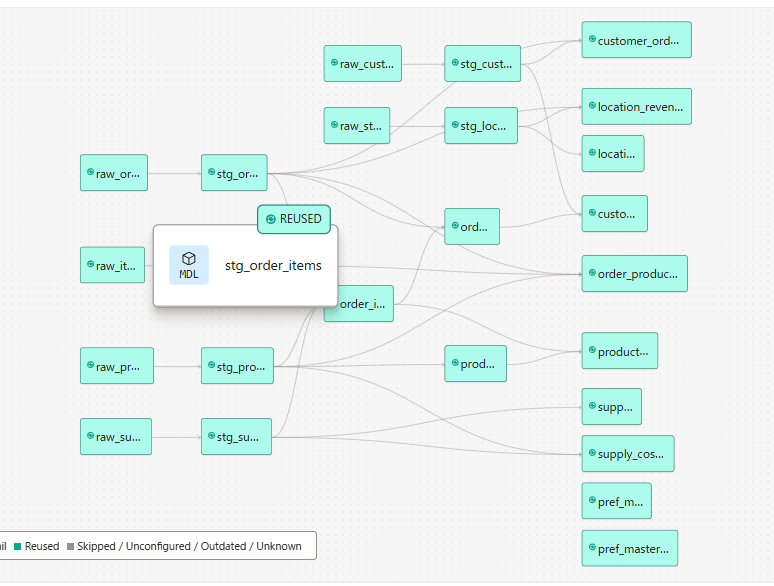
Run summary を確認すると、Reused タブが存在していることがわかります。初回はすべてビルドされているため Reused のモデルはありませんが、以降の実行ではここにスキップされたモデルが表示されます。

2回目のjob実行はReused
コード変更の検知を確認
State-aware orchestration は、compiled SQL の実質的な差分に基づいてコード変更を検知します。raw SQL ファイルの単純な文字列差分ではなく、Jinja、macro、ref の解決後の compiled SQL が変わったかどうかで判定します。
SQL を変更して再実行:
stg_orders モデルとstg_customersの SQL にカラムの追加やロジックの変更を加えてコミットし、ジョブを再実行します。
変更したモデル stg_orders とstg_customersのその下流モデル(int_order_customers、mart_orders)が再ビルドされ、変更のないモデルは Reused になっていればOKです。
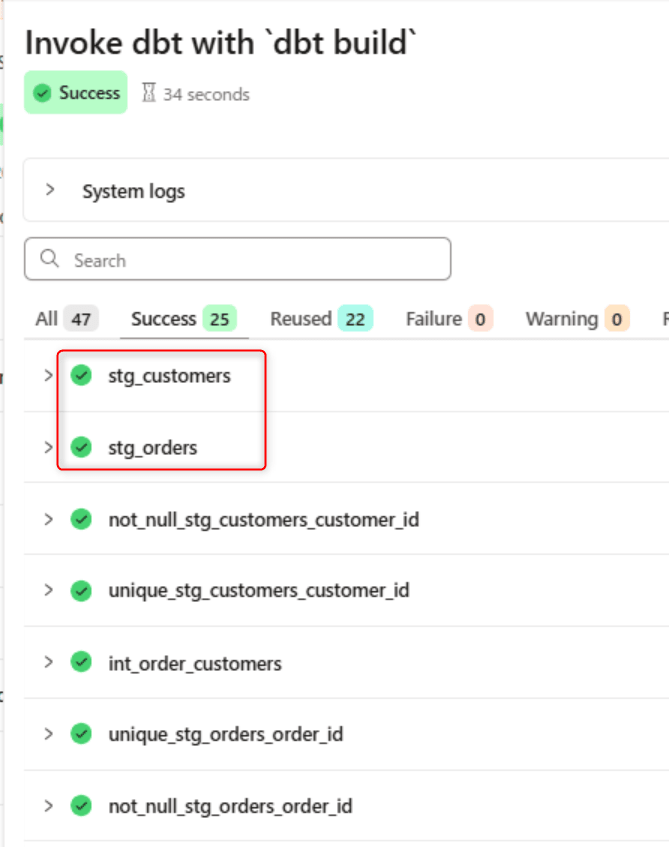
whitespace やコメントのみの変更:
次に、stg_orders モデルに whitespace の追加やコメントの変更のみを加えてコミットし、ジョブを再実行します。
下記のように注文データとコメントを記載しました。
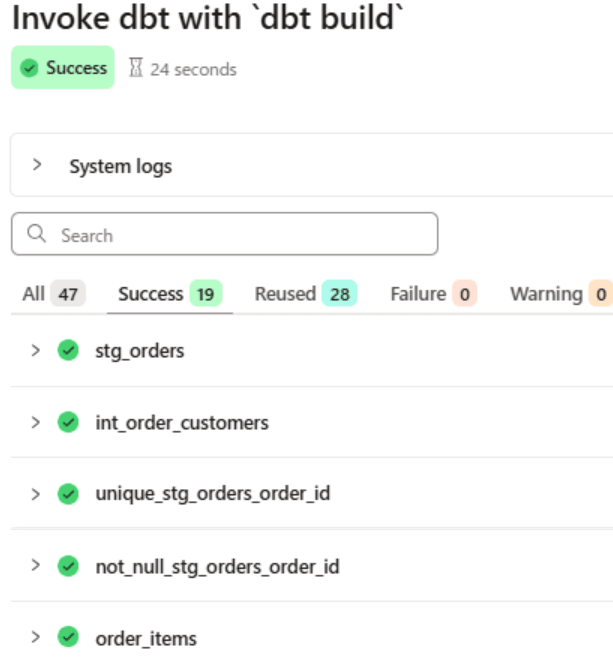
ジョブを再実行したところ、下記のような形でコメント記載の影響で、stg_orders モデルに関連するモデルが実行されているように見えます。
上流データ変更の検知を確認
デフォルトでは、dbt は warehouse metadata を使って source の freshness / 更新有無を確認します。追加設定なしでも、source の新データを検知した場合に必要なモデルをビルドします。
source テーブルにデータを INSERT:
Snowflake 上で raw.orders テーブルに新しいレコードを INSERT し、ジョブを実行します。
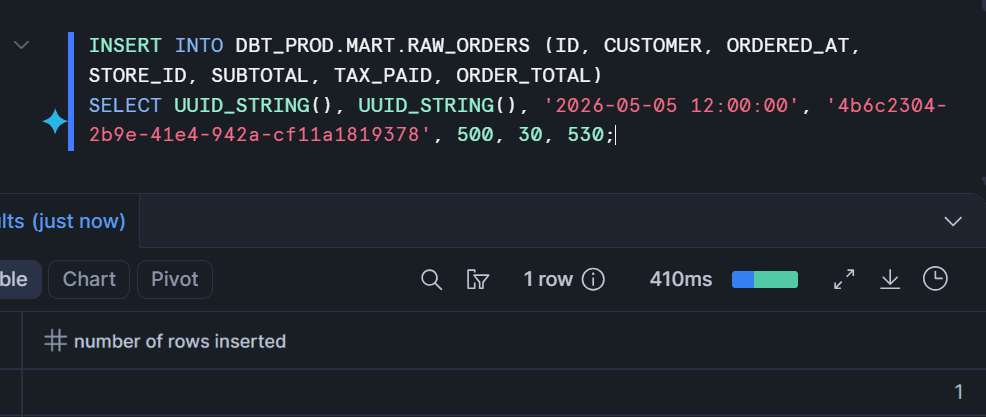
INSERT INTO RAW_ORDERS (ID, CUSTOMER, ORDERED_AT, STORE_ID, SUBTOTAL, TAX_PAID, ORDER_TOTAL)
SELECT UUID_STRING(), UUID_STRING(), '2026-05-05 12:00:00', '4b6c2304-2b9e-41e4-942a-cf11a1819378', 500, 30, 530;
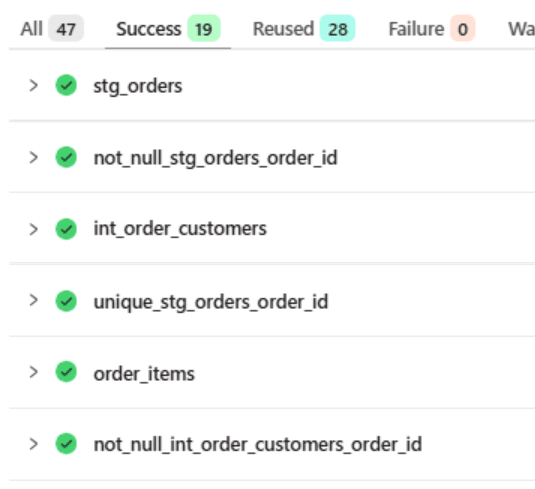
stg_orders とその下流モデルが再ビルドされ、stg_customers は Reused になっていればOKです。
build_after による再ビルド頻度の制御を確認
freshness.build_after は、新しいデータがある場合でも、最後の build から指定時間が経過するまでは再ビルドしないための制御です。
int_order_customers モデルに以下の設定を追加します。build_after の挙動のみを検証するため、updates_on は any(デフォルト)にしておきます。
models:
- name: int_order_customers
config:
freshness:
build_after:
count: 4
period: hour
updates_on: any
この設定の場合、int_order_customers は以下の条件をすべて満たしたときだけ再ビルドされます。
上流に新しいデータがある
AND
前回 int_order_customers をビルドしてから 4 時間以上経過している
AND
updates_on の条件を満たしている(any の場合はいずれかの direct upstream)
検証手順:
build_after設定を追加した状態でジョブを実行し、baseline の state を作る- 4 時間以内に source へ新しいデータを INSERT する
- ジョブを再実行する
- upstream に新データがあるにもかかわらず、
int_order_customersがReusedになることを確認する
build_after の時間が経過していないことが Reused の理由であることを、Run summary の Reused タブで確認できればOKです。
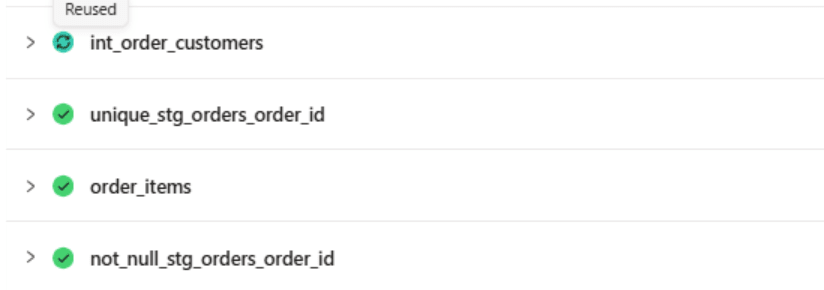
raw.orders テーブルにinsertし、関連のモデルは更新されていますが、int_order_customersのみReusedであることが確認できます。
デフォルトの挙動:
build_after のデフォルトは count: 0, period: minute, updates_on: any です。つまり、新しいデータがあればスケジュールジョブのたびにビルドされやすい挙動です。頻繁に実行されるジョブでは build_after を設定することで、不要な再ビルドを抑制できます。
updates_on: any と all の動作差を確認
updates_on は、複数の direct upstream を持つモデルに対して、どの上流更新をトリガーにするかを決めます。
updates_on の挙動を単独で確認するため、build_after の影響を排除します。build_after をデフォルトに近い値にするか、前回ビルドから十分な時間が経過した状態で検証します。
updates_on: any の場合:
models:
- name: int_order_customers
config:
freshness:
build_after:
count: 0
period: minute
updates_on: any
direct upstream のどれか1つに新データがあれば再ビルドされます。
raw.orders のみにデータを INSERT し、raw.customers は変更しない状態でジョブを実行します。int_order_customers は stg_orders の更新を検知して再ビルドされることを確認します。
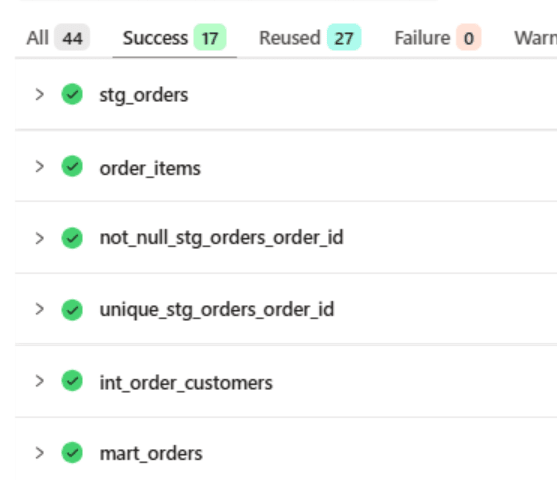
updates_on: all の場合:
models:
- name: int_order_customers
config:
freshness:
build_after:
count: 0
period: minute
updates_on: all
すべての direct upstream に新データがある場合のみ再ビルドされます。
raw.orders のみにデータを INSERT し、raw.customers は変更しない状態でジョブを実行します。int_order_customers は stg_customers が更新されていないため Reused になっていればOKです。
次に、raw.customers にもデータを INSERT してジョブを実行すると、全 direct upstream が更新されたため int_order_customers が再ビルドされることを確認します。
INSERT INTO RAW_CUSTOMERS (ID, NAME)
SELECT UUID_STRING(), 'Test User';
コスト最適化の観点では all の方が不要な中間ビルドを減らしやすいです。一方で、データ鮮度を優先するモデルでは any が適しています。
テーブル削除時の再ビルドを確認
warehouse 上で dbt が期待しているテーブルが削除されていた場合、State-aware orchestration はコード変更やデータ変更がなくても、そのモデルを再ビルド対象にします。
Snowflake 上で stg_orders のテーブルを直接 DROP します。
-- スキーマ名はご自身の環境の target schema に合わせてください
DROP TABLE IF EXISTS <target_schema>.stg_orders;
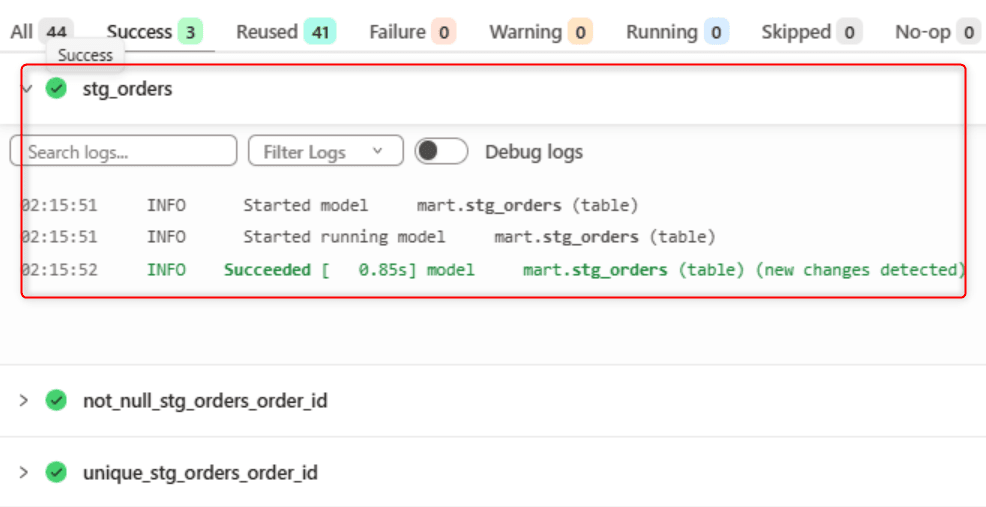
ジョブを実行すると、dbt は期待テーブルが missing である warning を出し、stg_orders を rebuild queue に入れます。
これは、shared state だけを見ると「前回 build 済み・変更なし」に見えても、実 warehouse の実体が消えていれば downstream が壊れるためです。
Data test 失敗後の再ビルドを確認
あるモデルが data test に失敗した場合、State-aware orchestration はそのモデルを過去 state から再利用せず、後続 run で再ビルド・再評価します。
意図的にデータ品質問題を作成します。例えば、raw.orders テーブルに order_id が NULL のレコードを INSERT します。
INSERT INTO RAW_ORDERS (ID, CUSTOMER, ORDERED_AT, STORE_ID, SUBTOTAL, TAX_PAID, ORDER_TOTAL)
VALUES (NULL, 1, '2026-05-05', 'completed', 503, 33, 533);
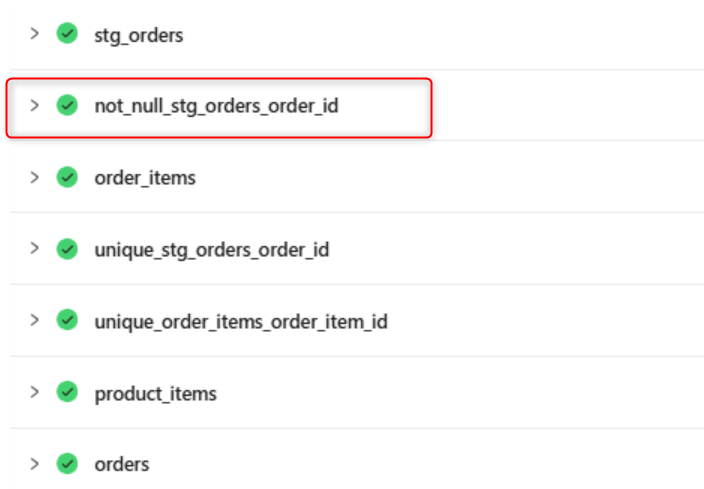
ジョブを実行すると、stg_orders の not_null テストが失敗します。

次回のジョブ実行時、stg_orders は data test 失敗状態のため Reused にならず、再ビルド・再テスト対象になることを確認します。これにより、未解決のデータ品質問題があるモデルを「最新だから reuse」と誤って扱わない安全側の挙動が確保されます。
最後に
dbt Fusion の State-aware orchestration を試してみて、各種判定条件の挙動を確認しました。
導入・運用上は以下のポイントを確認するとよいです。
- 頻繁に実行されるジョブでは
build_afterを設定して、不要な再ビルドを抑制する - 複数 source が揃ってから build したい mart 系モデルでは
updates_on: allを検討する(デフォルトはanyのため、上流の一部だけが更新されても build されやすい) - source が view の場合は
loaded_at_fieldまたはloaded_at_queryを明示的に設定する(warehouse metadata だけでは view の更新を正しく追えないケースがある)
現時点では Enterprise / Enterprise+ 向けの Private preview ですが、warehouse コストの最適化とジョブ実行時間の短縮に大きく貢献する機能だと感じました。特に、大規模な DAG を持つプロジェクトや、頻繁にジョブが実行される環境では効果が大きいと思います。
参考








