
dbtを用いてソースデータに削除レコードが発生した場合にsnapshotで管理テーブルを作成しincremental modelsの既存データを削除する仕組みを考えてみた
かわばたです。
前回の記事でRow timestampsを活用したdbtのincremental modelを紹介しましたが、「ソースでレコードが削除された場合、既存データに残ってしまう」という課題がありました。
dbt run --full-refreshを行えば問題ないですが、削除レコードの量に対して既存データの件数が膨大でdbt run --full-refreshを行いたくないケースについて考えていきます。
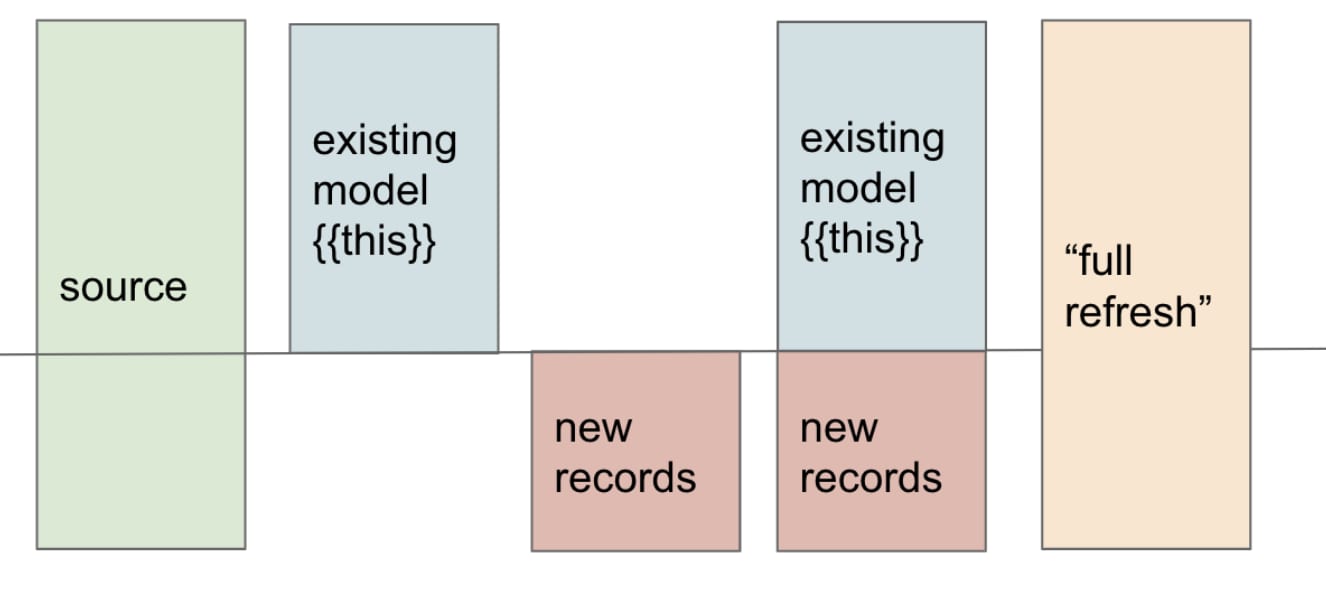
※ 上記画像のexisting model部分が既存データに該当
【引用】
今回はdbtのsnapshotとpost-hookを組み合わせて、削除されたレコードを自動的に同期する方法を検証しました。
【公式ドキュメント】
dbt snapshot
dbt incremental model
前回記事
対象読者
- dbtのincremental modelで削除レコードの同期に困っている方
- dbtのsnapshotの
hard_deletes機能を知りたい方
検証環境
- dbt platform Enterprise版
- Latestバージョン
- Snowflakeトライアルアカウント Enterprise版
課題
incremental modelは効率的な差分更新が可能ですが、以下の問題があります。
- ソーステーブルでレコードが削除されても、既存データには残り続ける
- ソーステーブルでレコードが更新されても、
unique_keyを使わない場合は古いデータが残る full-refreshを毎回実行するとコストが高い
【課題のイメージ】
ソース: [A, B, C] → [A, C] (Bを削除)
既存データ: [A, B, C] → [A, B, C] (Bが残る)
課題に対するアプローチ
snapshotのhard_deletes='new_record'を活用し、削除されたレコードを検知してpost-hookで削除します。
【処理フロー】
1. snapshot: ソースの変更を追跡(削除も検知)
2. snapshotのhard_deletes: 削除対象のORDER_IDを特定
3. orders_incremental: post-hookで削除を実行
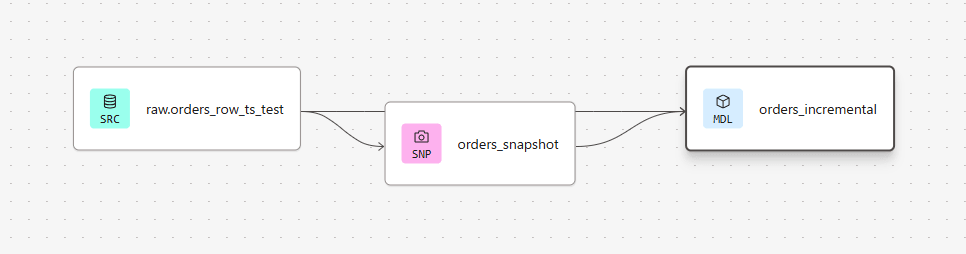
実際に試してみた
プロジェクト構成
dbt_snapshot_test/
├── dbt_project.yml
├── models/
│ ├── sources.yml
│ └── orders_incremental.sql # post-hookで削除実行
└── snapshots/
├── orders_snapshot.sql # hard_deletes='new_record'
└── schema.yml #snapshotの設定
sourcesの設定
今回使用するソースデータをymlファイルで定義しています。
version: 2
sources:
- name: raw
database: KAWABATA_MART_DB
schema: DBT_TKAWABATA
tables:
- name: orders_row_ts_test
description: "注文テーブル(削除・更新が発生する)"
snapshotの設定
hard_deletes='new_record'の設定により、ソースから消えたレコードに対してDBT_IS_DELETED='True'の新しいレコードが追加されます。
version: 2
snapshots:
- name: orders_snapshot
config:
unique_key: ORDER_ID
strategy: check
check_cols: all
hard_deletes: new_record
{% snapshot orders_snapshot %}
SELECT * FROM {{ source('raw', 'orders_row_ts_test') }}
{% endsnapshot %}
incremental model(Row timestamps + post-hook)
METADATA$ROW_LAST_COMMIT_TIMEを使用して新規・更新レコードを効率的に検知し、post-hookで削除を実行します。
※METADATA$ROW_LAST_COMMIT_TIMEについて確認したい方は前回記事を参照ください。
{{
config(
materialized='incremental',
unique_key='ORDER_ID',
incremental_strategy='merge',
post_hook=[
"DELETE FROM {{ this }} WHERE ORDER_ID IN (SELECT ORDER_ID FROM {{ target.database }}.{{ target.schema }}.ORDERS_SNAPSHOT WHERE DBT_IS_DELETED = 'True')"
]
)
}}
SELECT
ORDER_ID,
LOCATION_ID,
CUSTOMER_ID,
SUBTOTAL,
TAX_PAID,
ORDER_TOTAL,
ORDER_DATE,
ORDER_COST,
COUNT_ORDER_ITEMS,
IS_FOOD_ORDER,
IS_DRINK_ORDER,
CUSTOMER_ORDER_NUMBER,
{# Row timestamps: ソースのコミット時刻を保持 #}
METADATA$ROW_LAST_COMMIT_TIME AS ROW_TIMESTAMP
FROM {{ source('raw', 'orders_row_ts_test') }}
{% if is_incremental() %}
WHERE
{#
条件1: 前回実行以降にコミットされたレコード(新規・更新)
- METADATA$ROW_LAST_COMMIT_TIME: ソースの各行のコミット時刻
- ROW_TIMESTAMP: ターゲットに保存済みの最新コミット時刻
#}
METADATA$ROW_LAST_COMMIT_TIME > (
SELECT COALESCE(MAX(ROW_TIMESTAMP), '1900-01-01'::TIMESTAMP_LTZ)
FROM {{ this }}
)
{% endif %}
{#
【処理フロー】
1. 初回: フルロード(全レコード + ROW_TIMESTAMP)
2. 2回目以降:
- Row timestamps比較で新規・更新を検知
- snapshotのDBT_IS_DELETEDで削除を検知
3. MERGE: ORDER_IDで既存データと照合・更新
4. POST-HOOK: 削除対象を物理削除
#}
削除シナリオの検証
1. 初期状態の確認
ソースデータの件数を確認します。
SELECT COUNT(*) AS source_count
FROM KAWABATA_MART_DB.DBT_TKAWABATA.ORDERS_ROW_TS_TEST

次にsnapshotを実行します。
dbt snapshot
次にorders_incrementalを実行します。
dbt run --select orders_incremental
下記のとおりの件数となりました。
| テーブル | 件数 |
|---|---|
| source | 112 |
| incremental | 112 |
| snapshot | 112 |
2. ソースから2件削除
DELETE FROM KAWABATA_MART_DB.DBT_TKAWABATA.ORDERS_ROW_TS_TEST
WHERE ORDER_ID IN (
'528273e8-4c5b-4f98-91c2-31dfb99d3e00',
'5dcd1dc2-bf9e-485a-86aa-3e78dee5a41a'
);

3. snapshot実行で削除を検知
dbt snapshot
snapshotが2件の削除を検知し、DBT_IS_DELETED='True'の新しいレコードを追加します。
4. dbt run実行で削除を同期
dbt run --select orders_incremental
-- 3テーブルの件数確認
SELECT
'ORDERS_INCREMENTAL' AS table_name,
COUNT(*) AS total_count,
NULL AS deleted_count
FROM KAWABATA_MART_DB.DBT_TKAWABATA.ORDERS_INCREMENTAL
UNION ALL
SELECT
'ORDERS_ROW_TS_TEST',
COUNT(*),
NULL
FROM KAWABATA_MART_DB.DBT_TKAWABATA.ORDERS_ROW_TS_TEST
UNION ALL
SELECT
'ORDERS_SNAPSHOT',
COUNT(*),
SUM(CASE WHEN DBT_IS_DELETED = 'True' THEN 1 ELSE 0 END)
FROM KAWABATA_MART_DB.DBT_TKAWABATA.ORDERS_SNAPSHOT;
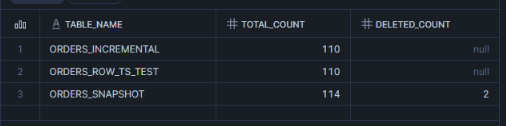
削除が正しく同期されました!
運用時のポイント
実行順序
必ずsnapshot → runの順で実行してください。dbt buildであれば依存関係によりsnapshot→modelの実行順序となるため問題ありませんが、細かい制御を行っている場合は注意が必要です。
unique_keyの重要性
snapshotおよびincremental modelはunique_keyが重要です。
incremental modelにおいて、更新レコードに関してもunique_keyを指定し、incremental_strategy='merge'とすることで既存データのunique_keyで変更があった内容を更新することができます。
最後に
今回の検証で、dbtのsnapshotとpost-hookを組み合わせることで、incremental modelでも削除レコードを同期できることが確認できました。
Row timestampsと組み合わせることで、更新・削除の両方に対応したパイプラインを構築でき、事前予告なくレコードが削除・更新されるテーブルを扱う場合に活用できます。
この記事が何かの参考になれば幸いです!









