【小ネタ】dbt project on Snowflakeで内部ステージのCSVファイルを直接モデルのFROM句で指定してみた
かわばたです。
こちらの記事でdbt_external_tablesを試しました。
外部ステージにあるファイルで外部テーブルを作成し、sourceとして定義してくれるマクロですが、内部ステージのファイルを直接dbtのモデルのFROM句で参照できないか試してみました。
対象読者
- dbt project on Snowflakeで内部ステージのファイルを直接モデルのFROM句で参照したい方
検証環境と事前準備
検証環境
- Snowflakeトライアルアカウント Enterprise版
事前準備
Titanic - Machine Learning from Disasterのデータを活用しています。
データベースおよびステージの作成
-- 自分のデータベース・スキーマを作成
CREATE DATABASE IF NOT EXISTS dbt_external;
CREATE SCHEMA IF NOT EXISTS dbt_external.stage;
-- データを格納する内部ステージを作成
CREATE STAGE dbt_external
DIRECTORY = ( ENABLE = true )
ENCRYPTION = ( TYPE = 'SNOWFLAKE_SSE' );
-- ファイルフォーマットの作成
CREATE OR REPLACE FILE FORMAT my_csv_format
TYPE = 'CSV'
FIELD_DELIMITER = ',' -- カンマ区切り
FIELD_OPTIONALLY_ENCLOSED_BY = '"' -- ダブルクォートで囲まれた値を正しく処理(必須)
SKIP_HEADER = 1 -- 1行目のヘッダーをスキップ
NULL_IF = ('', 'NULL', 'null') -- 空文字などをNULLとして扱う
TRIM_SPACE = TRUE -- フィールド前後の余計な空白を除去(推奨)
ERROR_ON_COLUMN_COUNT_MISMATCH = TRUE; -- 列数が合わない場合にエラーにする
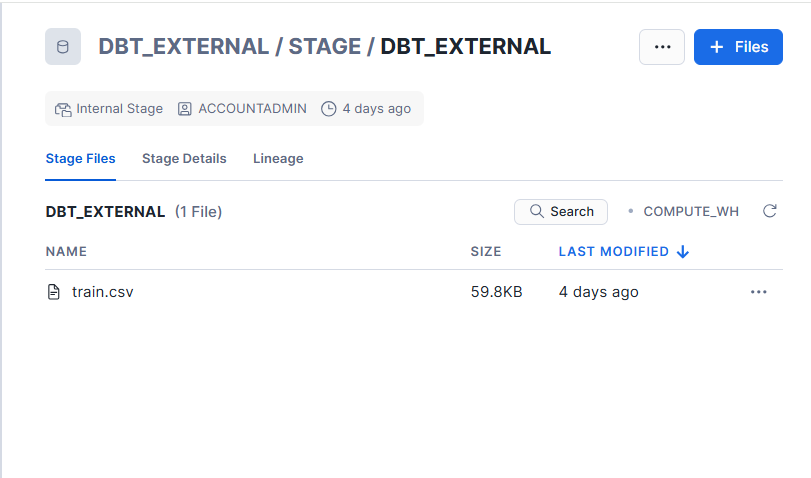
ステージには下記のようにtrain.csvが格納されています。
実際に試してみた
指定のCSVファイルを参照
直接指定する場合はカラム名ではなく$数字で指定する必要があります。
(カラム名で指定するとエラーとなりました。)
今回は下記のようにモデルを設定してみます。
SELECT
$1 AS passenger_id, -- 1列目
$2 AS survived, -- 2列目
$3 AS pclass, -- 3列目
$4 AS name,
$5 AS sex,
$6 AS age,
$7 AS sibsp,
$8 AS parch,
$9 AS ticket,
$10 AS fare,
$11 AS cabin,
$12 AS embarked
FROM @DBT_EXTERNAL.STAGE.DBT_EXTERNAL/train.csv
(file_format => 'DBT_EXTERNAL.STAGE.my_csv_format')
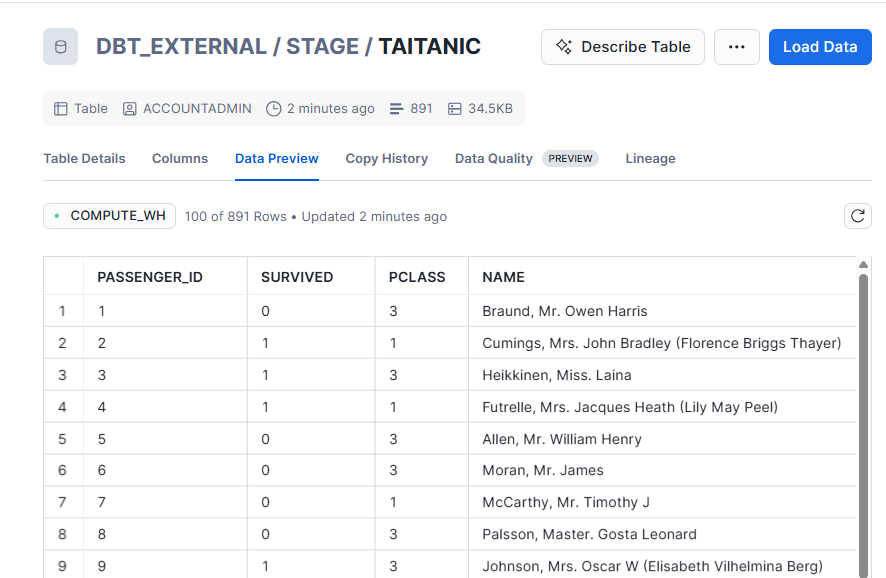
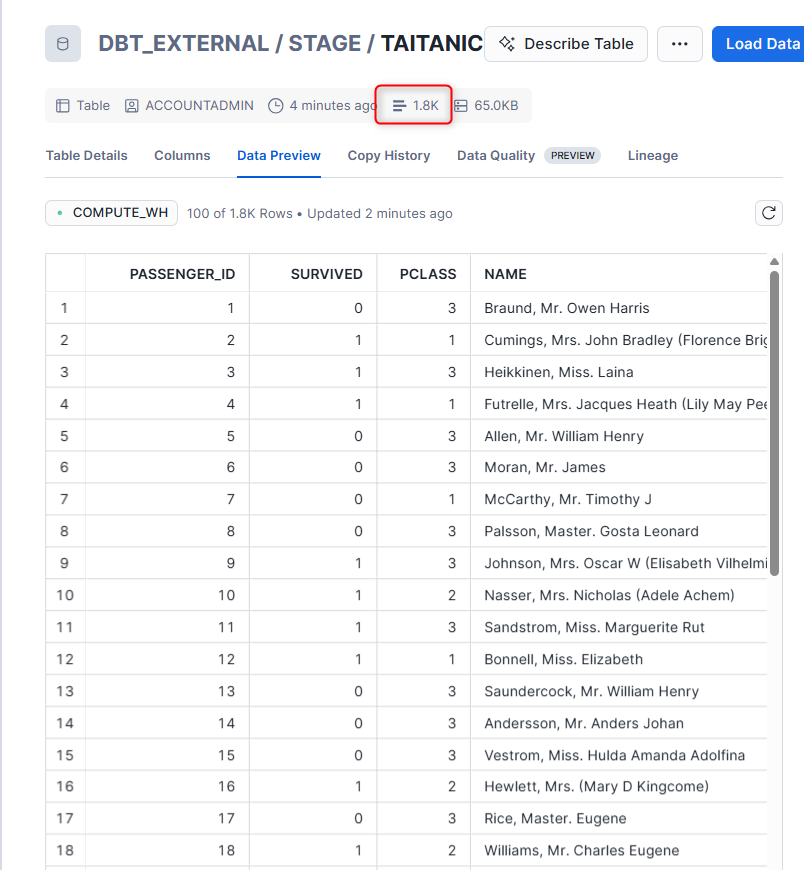
dbt runを実行すると下記のようにモデルを実行できました。
ただし、上記の設定ではすべてデータ型はVarcharとなります。
データ型を指定する場合は下記のように指定します。
SELECT
$1::INT AS passenger_id,
$2::INT AS survived,
$3::INT AS pclass,
$4::STRING AS name,
$5::STRING AS sex,
$6::FLOAT AS age,
$7::INT AS sibsp,
$8::INT AS parch,
$9::STRING AS ticket,
$10::FLOAT AS fare,
$11::STRING AS cabin,
$12::STRING AS embarked
FROM @DBT_EXTERNAL.STAGE.DBT_EXTERNAL/train.csv
(file_format => 'DBT_EXTERNAL.STAGE.my_csv_format')
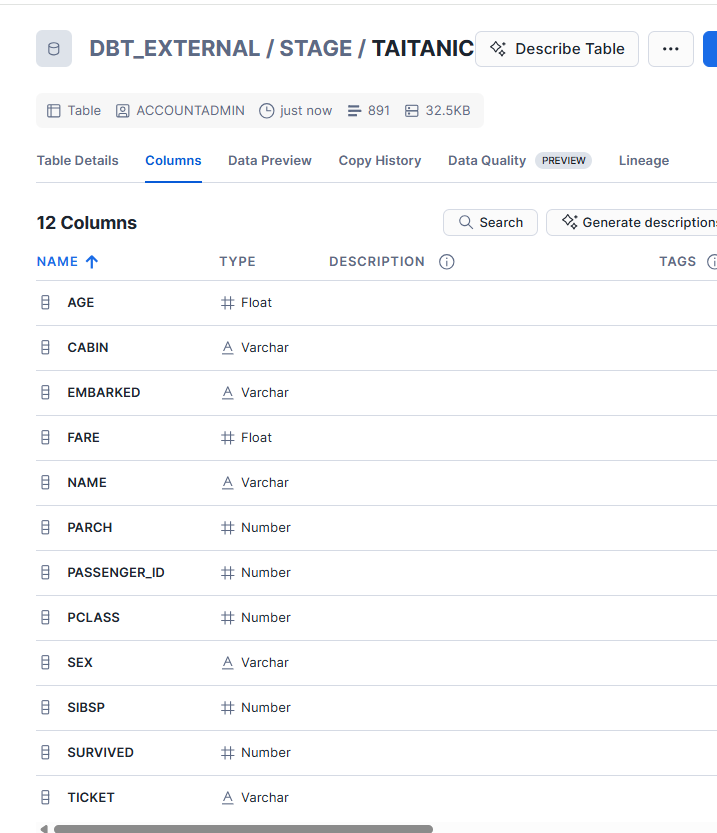
データ型を指定して実行することができました。
ステージ内の全ファイルを参照
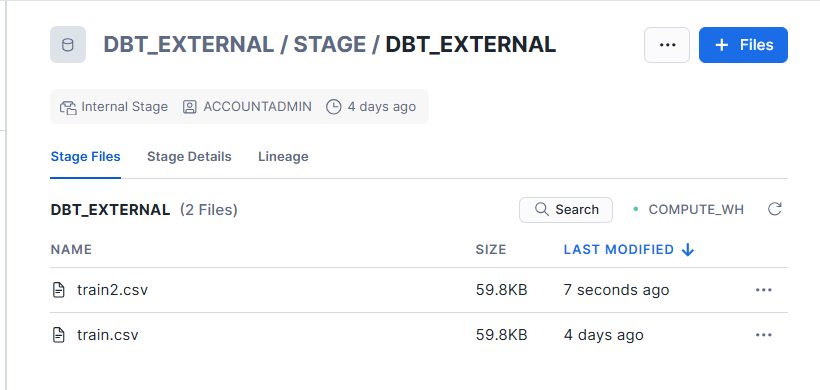
ステージにはtrain.csvと同じデータである、train2.csvを格納しました。
全て実行すると2倍のデータ量となります。
今回は下記のようにモデルを設定しました。
SELECT
$1::INT AS passenger_id,
$2::INT AS survived,
$3::INT AS pclass,
$4::STRING AS name,
$5::STRING AS sex,
$6::FLOAT AS age,
$7::INT AS sibsp,
$8::INT AS parch,
$9::STRING AS ticket,
$10::FLOAT AS fare,
$11::STRING AS cabin,
$12::STRING AS embarked
FROM @DBT_EXTERNAL.STAGE.DBT_EXTERNAL
(file_format => 'DBT_EXTERNAL.STAGE.my_csv_format')
先ほどの2倍のデータ量となったので、ステージ内すべて実行することができました。
最後に
内部ステージのデータを直接FROM句で試してみました。
ただ、静的なCSVデータ(マスタデータや学習データ)をdbtで扱う場合、seeds機能を使うのがベストプラクティスです。これにより、自動的にテーブルが作成され、gitでのバージョン管理も可能です。
基本的にはseedsの機能を使用し、やむを得ないケースのみご紹介した形を試してみると良いかと思います。
【seeds機能の参考ブログ】
この記事が何かの参考になれば幸いです!









