
dbt platform でセマンティックレイヤーの基本を試してみた
はじめに
dbt platform でセマンティックレイヤーを試すための基本的な手順を記事としました。
セマンティックレイヤー
セマンティックレイヤーは、DWH 上のテーブルと、BI ツールなどの利用者との間に位置し、「売上」などのビジネス指標の定義を一元管理するレイヤーです。
組織で集計・分析を行う際、単に「売上」といっても、その具体的な定義が BI ツールやユーザーによって異なることがあります。
セマンティックレイヤーでは、こういった指標定義を一元管理するレイヤーとして機能することで、指標の定義が分散されているという課題の解決を目指します。
ユーザーや BI ツールは、このレイヤーを経由することで、一か所で定義された内容を複数箇所から再利用できるようになります。
セマンティックレイヤーの機能は dbt にも組み込まれており、dbt platform では MetricFlow がプラットフォームに組み込まれています。
MetricFlow は、dbt セマンティックレイヤーの SQL クエリ生成エンジンで、YAML で定義された指標を基に、適切な SQL を自動的に生成します。
dbt platform の Studio や dbt CLI、VS Code の拡張機能から、dbt slコマンドを使ってセマンティックレイヤーに対して直接クエリできます。
ここでは、簡単に単一のテーブルに対してセマンティックモデルを定義し、セマンティックレイヤーに対してdbt slコマンドによるクエリ、BI ツールからの参照を試してみます。
前提条件
検証環境
以下の環境を使用しています。
- DWH:Snowflake
- BIツール:Tableau Desktop 2026.1
また、セマンティックレイヤーの記法について、この記事では dbt Fusion エンジンおよび dbt platform Latest リリーストラックで利用可能な新しい YAML 記法を使用しています。
事前準備
検証用の新規プロジェクトを作成し、公式のクイックスタートをベースに以下のデータ、テーブルを用意しておきました。
create database raw;
create schema raw.jaffle_shop;
create schema raw.stripe;
create table raw.jaffle_shop.customers
( id integer,
first_name varchar,
last_name varchar
);
copy into raw.jaffle_shop.customers (id, first_name, last_name)
from 's3://dbt-tutorial-public/jaffle_shop_customers.csv'
file_format = (
type = 'CSV'
field_delimiter = ','
skip_header = 1
);
create table raw.jaffle_shop.orders
( id integer,
user_id integer,
order_date date,
status varchar,
_etl_loaded_at timestamp default current_timestamp
);
copy into raw.jaffle_shop.orders (id, user_id, order_date, status)
from 's3://dbt-tutorial-public/jaffle_shop_orders.csv'
file_format = (
type = 'CSV'
field_delimiter = ','
skip_header = 1
);
create table raw.stripe.payment
( id integer,
orderid integer,
paymentmethod varchar,
status varchar,
amount integer,
created date,
_batched_at timestamp default current_timestamp
);
copy into raw.stripe.payment (id, orderid, paymentmethod, status, amount, created)
from 's3://dbt-tutorial-public/stripe_payments.csv'
file_format = (
type = 'CSV'
field_delimiter = ','
skip_header = 1
);
上記の生データに対して、Source 定義とステージングレイヤーに該当するモデルを作成します。
Source 定義:
sources:
- name: jaffle_shop
description: This is a replica of the Postgres database used by our app
database: raw
schema: jaffle_shop
tables:
- name: customers
description: One record per customer.
- name: orders
description: One record per order. Includes cancelled and deleted orders.
モデル:
-- models/stg_orders.sql
select
id as order_id,
user_id as customer_id,
order_date,
status
from {{ source('jaffle_shop', 'orders') }}
上記の設定後、本番環境でもジョブとして実行しておきました。
dbt CLI のインストール
後述する手順でセマンティックレイヤーをクエリする際、ここでは dbt CLI を使用しました。dbt CLI は dbt platform で使用でき、ローカルから開発環境用の作業を行える CLI ツールです。
以下のドキュメントおよびリリースページを参考にインストールします。
インストール後、dbt コマンドをどのディレクトリからでも実行できるよう、バイナリをパスの通った場所に配置します。ここでは~/.local/binに配置しました。
# バイナリを移動
mv ./dbt ~/.local/bin/dbt
chmod +x ~/.local/bin/dbt
# PATHを通す
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc
# インストールの確認
$ dbt --version
dbt Cloud CLI - 0.40.15 (bcc3d4fb0158fe4f8df1b6339896f73a34263555 2026-03-02T18:03:57Z)
認証設定
ローカルから開発環境で使用できよう設定します。dbt platform にログインし「AccountSettings > CLI」を選択します。
Configure Cloud authentication 内の「Download CLI configuration file」をクリックし dbt_cloud.yml をダウンロードし~/.dbt/dbt_cloud.ymlに配置します。
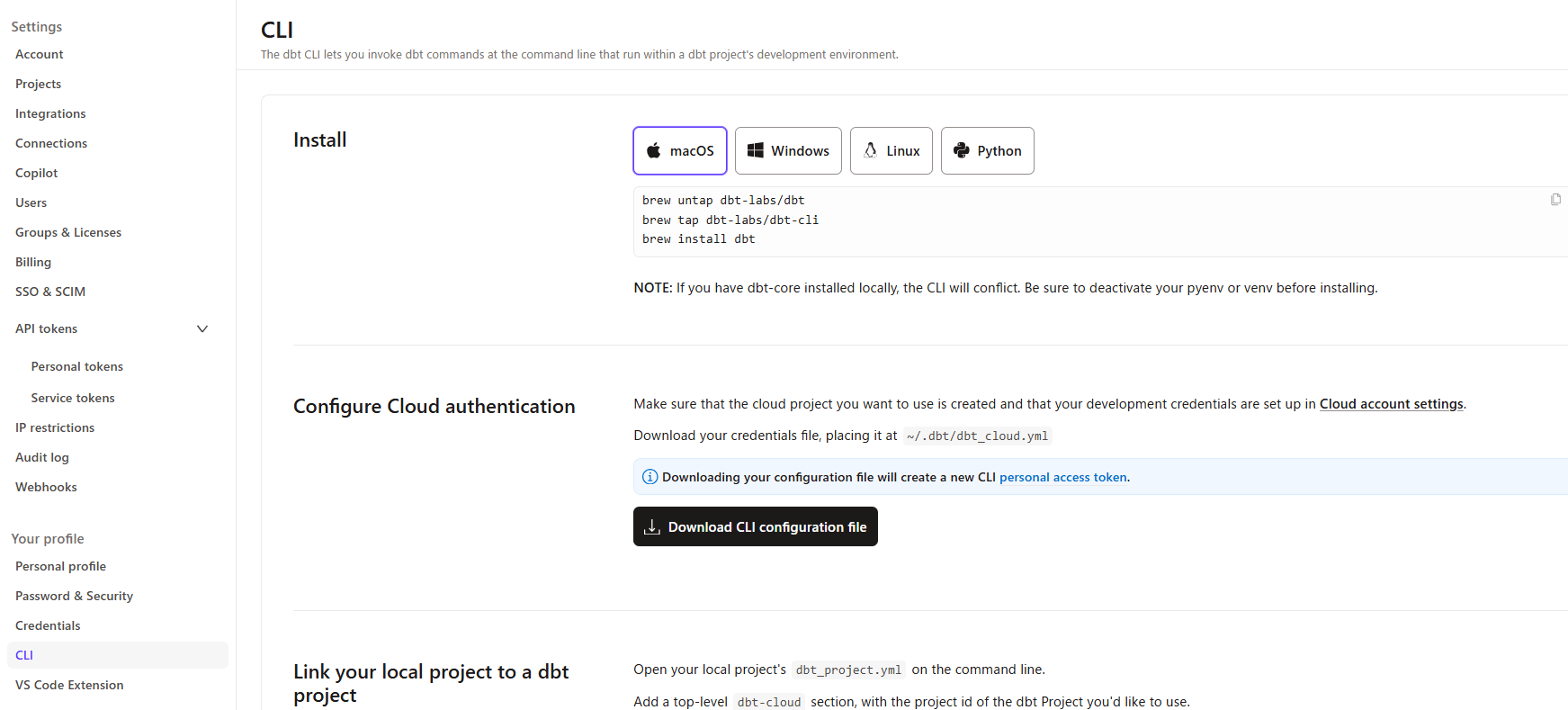
続けて、上図の「Link your local project to a dbt project」内にある記載を参考に対象となる dbt プロジェクトのdbt_project.yml に以下を追記します。
# dbt_project.yml
name:
version:
...
dbt-cloud:
project-id: xxxxxx
その後、dbt_project.yml のあるディレクトリでコンパイル等が問題なく実行できることを確認します。
$ dbt compile
Created invocation id 3d38cf90-69ea-4826-adfb-941b9286e616
06:42:59 Cloud CLI invocation created: 3d38cf90-69ea-4826-adfb-941b9286e616
06:43:03 Running with dbt-fusion=2.0.0-preview.154
06:43:03 dbt-fusion 2.0.0-preview.154
06:43:03 Loading profiles.yml
06:43:03 Artifact written to target/semantic_manifest.json
06:43:05 Downloaded raw.jaffle_shop.orders (schema)
06:43:05 Started model dbt_tyasuhara.stg_orders
06:43:05 Succeeded [ 0.04s] model dbt_tyasuhara.stg_orders (table)
06:43:05 Artifact written to target/manifest.json
06:43:05
==================== Execution Summary =====================
Finished 'compile' successfully for target 'dev' [2.5s]
Processed: 1 model
Summary: 1 total | 1 success
セマンティックモデルの定義
ここではstg_orders.sql で作成したモデル(テーブル)に対してセマンティックモデルを定義します。
セマンティックモデルは、YAML ファイル上で設定できます。モデルのプロパティを定義する YAML を作成し、以下のように記述しました。
# models/stg_orders.yml
version: 2
models:
- name: stg_orders
semantic_model:
enabled: true
agg_time_dimension: order_date # このセマンティックモデルで時間軸の集計に使う列を指定
# metric_time として自動公開される
columns:
- name: order_id
entity:
type: primary
name: orders # ※"order はSQL予約語のため "orders" を使用
- name: customer_id
entity:
type: foreign
name: customer
- name: order_date
granularity: day # 最小粒度。week/month/year への集計も可能
dimension:
type: time
- name: status
dimension:
type: categorical
metrics:
- name: order_count
type: simple
label: 注文数
agg: count
expr: 1 # expr は集計対象を指定するフィールド。列名のほか SQL 式も記述できる。
# expr: 1 は「各行を1件としてカウントする」という意味
- name: distinct_customers
type: simple
label: ユニーク顧客数
agg: count_distinct
expr: customer_id
設定の主なポイントは以下の通りです。
agg_time_dimensionでは、メトリクスを時間軸で集計する際に使用する際の、基準の時間ディメンションを指定します(このモデルにおけるデフォルトの時間軸として使用できます)- ここでは
order_dateを指定しており、後述の手順でクエリする際、metric_timeとしてこちらが使用されます
- ここでは
- エンティティはテーブル間の結合キーを定義するフィールドです。
order_idを主キー(primary)、customer_idを外部キー(foreign)として指定しました。複数のセマンティックモデルを結合してメトリクスを計算する際に使用されます - ディメンションには
order_date(時間)とstatus(カテゴリ)を定義しましたorder_dateの最小粒度はdayとしています- これにより、
week/month/yearへの集計にも対応できます
- メトリクスには
order_count(注文数)とdistinct_customers(ユニーク顧客数)を定義しました
YAML 定義後、開発環境でdbt parseを実行します。
# マニフェスト再生成
dbt parse
Created invocation id 3e4fd662-08fb-4f60-8c57-40422a866bb2
06:53:50 Cloud CLI invocation created: 3e4fd662-08fb-4f60-8c57-40422a866bb2
06:53:51 Running with dbt-fusion=2.0.0-preview.154
06:53:51 dbt-fusion 2.0.0-preview.154
06:53:51 Loading profiles.yml
06:53:51 Artifact written to target/semantic_manifest.json
06:53:53 Downloaded raw.jaffle_shop.orders (schema)
06:53:53 Started model dbt_tyasuhara.stg_orders
06:53:53 Succeeded [ 0.04s] model dbt_tyasuhara.stg_orders (table)
06:53:53 Artifact written to target/manifest.json
06:53:53
==================== Execution Summary =====================
Finished 'compile' successfully for target 'dev' [2.5s]
Processed: 1 model | 2 metrics | 1 semantic model
Summary: 1 total | 1 success
続けてdbt sl validateを実行し、セマンティックレイヤーの整合性検証を行います。
# セマンティックレイヤーの整合性検証
$ dbt sl validate
Created invocation id e8339cc2-9678-476c-a2a4-3a119436e394
06:54:23 Cloud CLI invocation created: e8339cc2-9678-476c-a2a4-3a119436e394
06:54:24 Running with dbt-fusion=2.0.0-preview.154
06:54:24 dbt-fusion 2.0.0-preview.154
06:54:24 Loading profiles.yml
06:54:24 Artifact written to target/semantic_manifest.json
06:54:26 Downloaded raw.jaffle_shop.orders (schema)
06:54:27 error: dbt1015: MetricFlow Server returned errors:
- At least one time spine must be configured to use the semantic layer, but none were found.
06:54:27
==================== Execution Summary =====================
Finished 'sl' with 1 error for target 'dev' [2.4s]
Invocation has finished
ここでは「At least one time spine must be configured to use the semantic layer, but none were found.」と表示され、タイムスパインが未設定というエラーとなりました。
タイムスパイン
タイムスパインとは、MetricFlow が時間軸での集計を行う際に参照する、連続した日付の一覧を持つテーブルです。
MetricFlow はメトリクスを時間軸で集計する際、このタイムスパインテーブルを参照して日付の軸を生成します。そのため、セマンティックレイヤーを使用するには最低1つのタイムスパインの設定が必須となります。
先のエラーメッセージはこのタイムスパインが未設定であることを示していました。以降の手順でタイムスパインテーブルを設定します。
タイムスパインテーブルを追加:
-- models/time_spine_daily.sql
{{
config(
materialized = 'table',
)
}}
with
base_dates as (
{{
dbt.date_spine(
'day',
"DATE('2000-01-01')",
"DATE('2030-01-01')"
)
}}
),
final as (
select
cast(date_day as date) as date_day
from base_dates
)
select *
from final
where date_day > dateadd(year, -5, current_date())
and date_day < dateadd(day, 30, current_date())
YAML:
# models/time_spine.yml
version: 2
models:
- name: time_spine_daily
description: MetricFlow 用タイムスパイン。過去5年〜30日後までの日付を1行ずつ持つテーブル。
time_spine:
standard_granularity_column: date_day
columns:
- name: date_day
description: 日次の基準日カラム
granularity: day
この上で、再度検証すると以下のようになりました。
$ dbt sl validate
Created invocation id 05a5d4ea-769b-4136-a459-473db54a78d3
07:02:03 Cloud CLI invocation created: 05a5d4ea-769b-4136-a459-473db54a78d3
07:02:04 Running with dbt-fusion=2.0.0-preview.154
07:02:04 dbt-fusion 2.0.0-preview.154
07:02:04 Loading profiles.yml
07:02:04 Artifact written to target/semantic_manifest.json
07:02:07 Downloaded raw.jaffle_shop.orders (schema)
07:02:08
07:02:08 Artifact written to target/manifest.json
07:02:08
==================== Execution Summary =====================
Finished 'sl' successfully for target 'dev' [3.7s]
Invocation has finished
セマンティックレイヤーをクエリ
dbt slコマンドを使用することで、セマンティックレイヤーをクエリできます。ここでは dbt CLI を使用しますが、Studio(dbt platform IDE)経由でも同様に実行できます。
以降で基本的なコマンドを試してみます。
メトリクスの一覧:
$ dbt sl list metrics
The list below shows metrics in the format of 'metric: dimensions'
- distinct_customers: metric_time,orders__order_date,orders__status
- order_count: metric_time,orders__order_date,orders__status
dbt sl list metrics でセマンティックモデルで定義したメトリクスを表示できます。
ここでは、定義している2つのメトリクスが表示されました。見方は'metric: dimensions' となっており、それぞれのメトリクスが3つのディメンションで集計可能であることがわかります。
- distinct_customers
- metric_time
- orders__order_date
- orders__status
ここでorders__ となっている「orders」はエンティティを表します(YAML ファイルではorder_idカラムをordersと定義しています)。
metric_timeはagg_time_dimensionで指定したカラムを指す予約名となります。
メトリクスをクエリしてみます。
総注文数:
dbt sl query --metrics order_count
+-------------+
| ORDER_COUNT |
+-------------+
| 99 |
+-------------+
--compile を指定すると実際に実行される SQL がわかります。
$ dbt sl query --metrics order_count --compile
SELECT
SUM(1) AS order_count
FROM dbt_sl_db.dbt_tyasuhara.stg_orders stg_orders_src_10000
LIMIT 100
ユニーク顧客数:
dbt sl query --metrics distinct_customers
+--------------------+
| DISTINCT_CUSTOMERS |
+--------------------+
| 62 |
+--------------------+
ディメンションを確認する際は、メトリクスに紐づくメトリクスとして確認でます。
$ dbt sl list dimensions --metrics order_count
The list of available dimensions:
- metric_time
- orders__order_date
- orders__status
ディメンション追加し、集計軸別に集計してみます。この際、group-by オプションを追加し「entity名__dimension名」の形式で参照します。
ステータス別の注文数:
dbt sl query --metrics order_count --group-by orders__status
+----------------+-------------+
| ORDER__STATUS | ORDER_COUNT |
+----------------+-------------+
| completed | 67 |
| shipped | 13 |
| return_pending | 2 |
| placed | 13 |
| returned | 4 |
+----------------+-------------+
# SQLを確認
$ dbt sl query --metrics order_count --group-by orders__status --compile
SELECT
order__status
, SUM(__order_count) AS order_count
FROM (
SELECT
status AS order__status
, 1 AS __order_count
FROM dbt_sl_db.dbt_tyasuhara.stg_orders stg_orders_src_10000
) subq_3
GROUP BY
order__status
LIMIT 100
metric_time による集計(注文数):
$ dbt sl query --metrics order_count --group-by metric_time
+-------------------------+-------------+
| METRIC_TIME__DAY | ORDER_COUNT |
+-------------------------+-------------+
| 2018-01-01T00:00:00.000 | 1 |
| 2018-03-24T00:00:00.000 | 2 |
| 2018-02-17T00:00:00.000 | 3 |
・
・
| 2018-03-11T00:00:00.000 | 3 |
| 2018-04-06T00:00:00.000 | 1 |
+-------------------------+-------------+
一部抜粋ですが上記のようになります。ここでのmetric_timeはagg_time_dimensionで指定したorder_date 軸での集計となります。
- name: stg_orders
semantic_model:
enabled: true
agg_time_dimension: order_date # metric_time として使用される
agg_time_dimension とメトリクスごとの時間軸
agg_time_dimensionは対象のセマンティックモデルにおけるデフォルトの時間軸として使用できますが、特定のメトリクスでは別の時間軸を使いたい場面もあるかと思います。この場合は、各メトリクスで個別に定義すればよいです。
- name: total_amount
type: simple
label: 合計金額
agg: sum
expr: amount
agg_time_dimension: paid_date
具体的には、1つのモデルに複数の時間軸(created_date , paid_date , shipped_dateなど)がある場合などは、以下のようにメトリクスによって集計の基準日が異なることがあります。
- 注文件数 →
created_date - 売上計上額 →
paid_date - 出荷件数 →
shipped_dateなど
このような場合は、個別のメトリクスで定義することで、指定の軸を使用できます。
時間粒度を変えて集計する
クエリ時にagg_time_dimension の粒度を変えることも可能です。この場合は、クエリ時の group-by でmetric_time__<granularity> の形式で指定します。
基本的には order_date のような時間軸を基準に、より粗い粒度への適用が可能です。
# 月次
$ dbt sl query --metrics order_count --group-by metric_time__month
+-------------------------+-------------+
| METRIC_TIME__MONTH | ORDER_COUNT |
+-------------------------+-------------+
| 2018-03-01T00:00:00.000 | 35 |
| 2018-04-01T00:00:00.000 | 8 |
| 2018-01-01T00:00:00.000 | 29 |
| 2018-02-01T00:00:00.000 | 27 |
+-------------------------+-------------+
# 年次
$ dbt sl query --metrics order_count --group-by metric_time__year
+-------------------------+-------------+
| METRIC_TIME__YEAR | ORDER_COUNT |
+-------------------------+-------------+
| 2018-01-01T00:00:00.000 | 99 |
+-------------------------+-------------+
# 週次
$ dbt sl query --metrics order_count --group-by metric_time__week
+-------------------------+-------------+
| METRIC_TIME__WEEK | ORDER_COUNT |
+-------------------------+-------------+
| 2018-01-15T00:00:00.000 | 7 |
| 2018-04-09T00:00:00.000 | 1 |
| 2018-02-19T00:00:00.000 | 7 |
| 2018-01-29T00:00:00.000 | 7 |
| 2018-01-22T00:00:00.000 | 8 |
| 2018-04-02T00:00:00.000 | 7 |
| 2018-03-26T00:00:00.000 | 8 |
| 2018-01-08T00:00:00.000 | 5 |
| 2018-01-01T00:00:00.000 | 6 |
| 2018-02-05T00:00:00.000 | 6 |
| 2018-03-19T00:00:00.000 | 8 |
| 2018-02-26T00:00:00.000 | 9 |
| 2018-03-12T00:00:00.000 | 6 |
| 2018-02-12T00:00:00.000 | 6 |
| 2018-03-05T00:00:00.000 | 8 |
+-------------------------+-------------+
# 四半期
$ dbt sl query --metrics order_count --group-by metric_time__quarter
+-------------------------+-------------+
| METRIC_TIME__QUARTER | ORDER_COUNT |
+-------------------------+-------------+
| 2018-01-01T00:00:00.000 | 91 |
| 2018-04-01T00:00:00.000 | 8 |
+-------------------------+-------------+
なお繰り返しになりますが、metric_time は agg_time_dimension で指定した列の予約名のため、以下の2つは同じ結果になります。
dbt sl query --metrics order_count --group-by metric_time
dbt sl query --metrics order_count --group-by orders__order_date
粒度を指定する場合も同様に、どちらの書き方でも同じ結果が得られます。
dbt sl query --metrics order_count --group-by metric_time__month
dbt sl query --metrics order_count --group-by orders__order_date__month
+--------------------------+-------------+
| ORDER__ORDER_DATE__MONTH | ORDER_COUNT |
+--------------------------+-------------+
| 2018-03-01T00:00:00.000 | 35 |
| 2018-04-01T00:00:00.000 | 8 |
| 2018-02-01T00:00:00.000 | 27 |
| 2018-01-01T00:00:00.000 | 29 |
+--------------------------+-------------+
粒度の設定と注意点
YAML でのgranularityはそのディメンションで使用できる最小粒度を定義します。そのため、設定した粒度より細かい単位での集計はエラーになります。
例えば、以下のディメンションでgranularityをmonthとしてみます。
- name: order_date
granularity: month # 最小粒度を month に設定
dimension:
type: time
この状態でより細かな粒度(weekなど)での集計はエラーとなります。
# エラー:month より細かい week は使用不可
dbt sl query --metrics order_count --group-by orders__order_date__week
特別な理由がない限り、granularity: day のように細かい粒度で定義しておく方が柔軟に集計できます。
エンティティ軸での集計
group-by にはディメンションだけでなく、エンティティ名も指定できます。YAML でエンティティとして定義した名前(列名やnameを使用した場合は、ここで指定した値)を使用します。
# 顧客別の注文数(customer_id 列を customer エンティティとして定義)
dbt sl query --metrics order_count --group-by orders__customer
# 注文別の注文数(order_id 列を orders エンティティとして定義)
dbt sl query --metrics order_count --group-by orders__orders
セマンティックレイヤーを公開する
開発環境での動作確認ができたら、デプロイメント環境のジョブを実行し、セマンティックレイヤーを外部から利用できる状態にします。以下を参考に進めます。
「Account Settings > Projects」から、設定するプロジェクトを選択します。Semantic Layer の項目から、「Configure Semantic Layer」を選択し認証設定を進めます

セマンティックレイヤーを有効化するデプロイメント環境を指定します。

続けてクレデンシャル・シークレットの生成画面に遷移するので、「Add Semantic Layer credential」をクリックします。
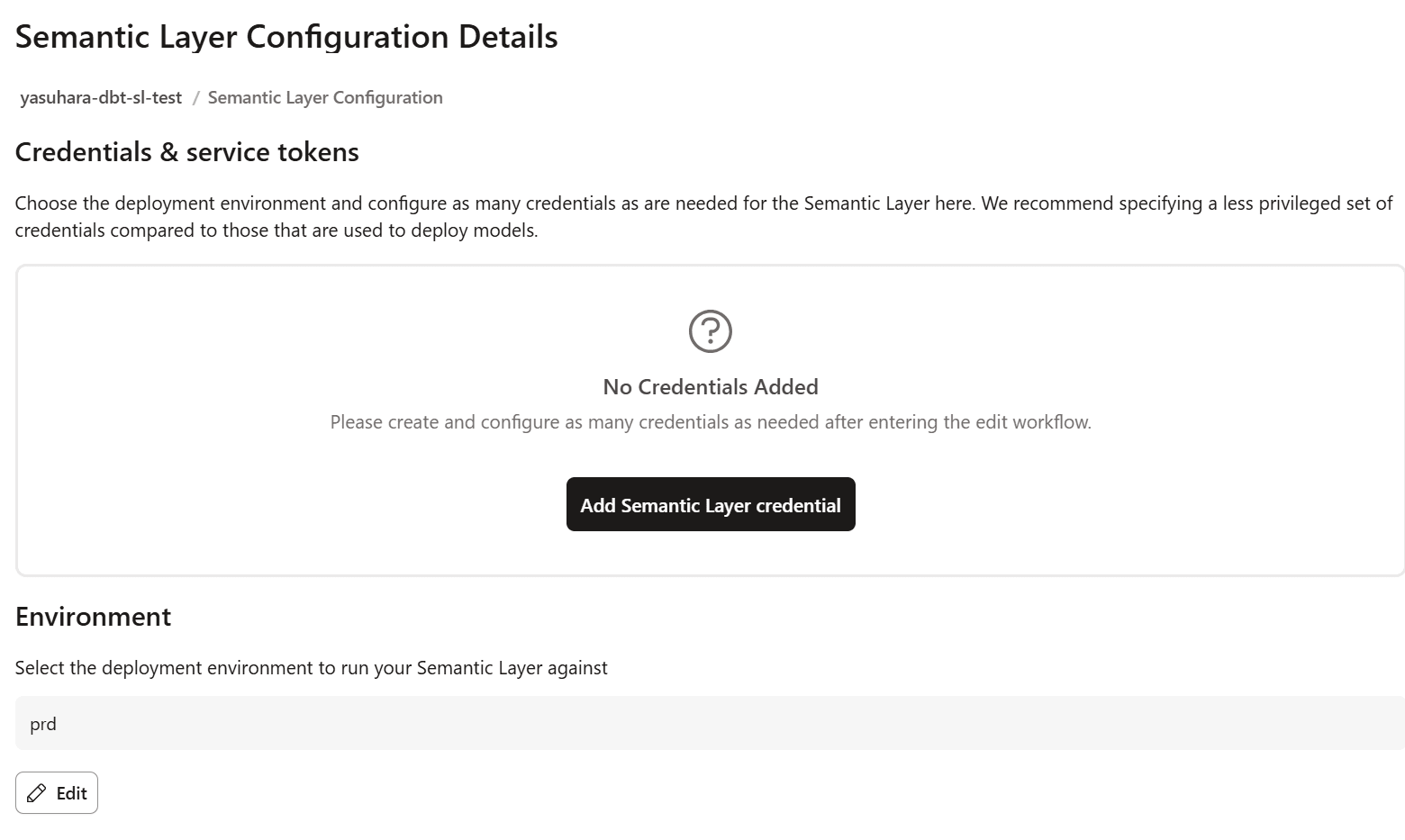
ここでは、セマンティックレイヤーを介して接続するユーザーの認証情報を設定します。接続するユーザーには、セマンティックモデルが参照する dbt モデルのスキーマへの読み取り権限が必要です。
トークンに任意の名前を付け、権限を「セマンティックレイヤーのみ」および「メタデータのみ」に設定して「保存」をクリックします。
保存するとトークンが表示されるので、控えておきます。
この際、dbt platform の Starter プランではプロジェクトにつき1つのクレデンシャルのみ設定可能です。Enterprise プランでは複数のクレデンシャルを追加でき、それぞれにサービストークンをマッピング可能です。
これにより、複数の BI ツールからなど、各アクセス用に認証資格情報や権限を分離できます。
設定後、Project details(プロジェクトの詳細)ページに戻ると下図のように、BIツールなど)に接続するための詳細情報が表示されます。
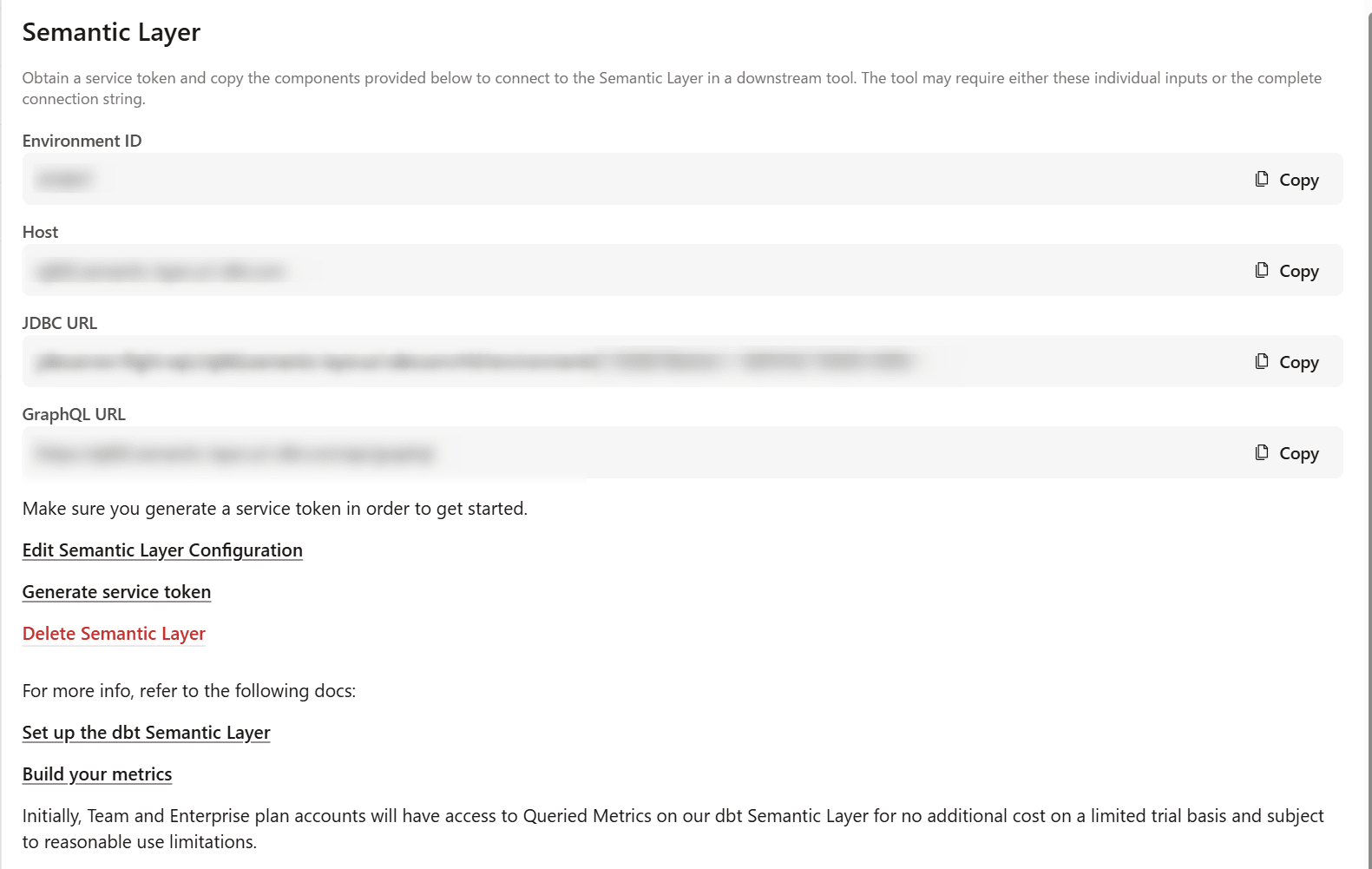
Tableau Desktop からの接続
こちらは以下に記載があります。
接続時は、先ほどの Project details ページに表示された値を指定します。
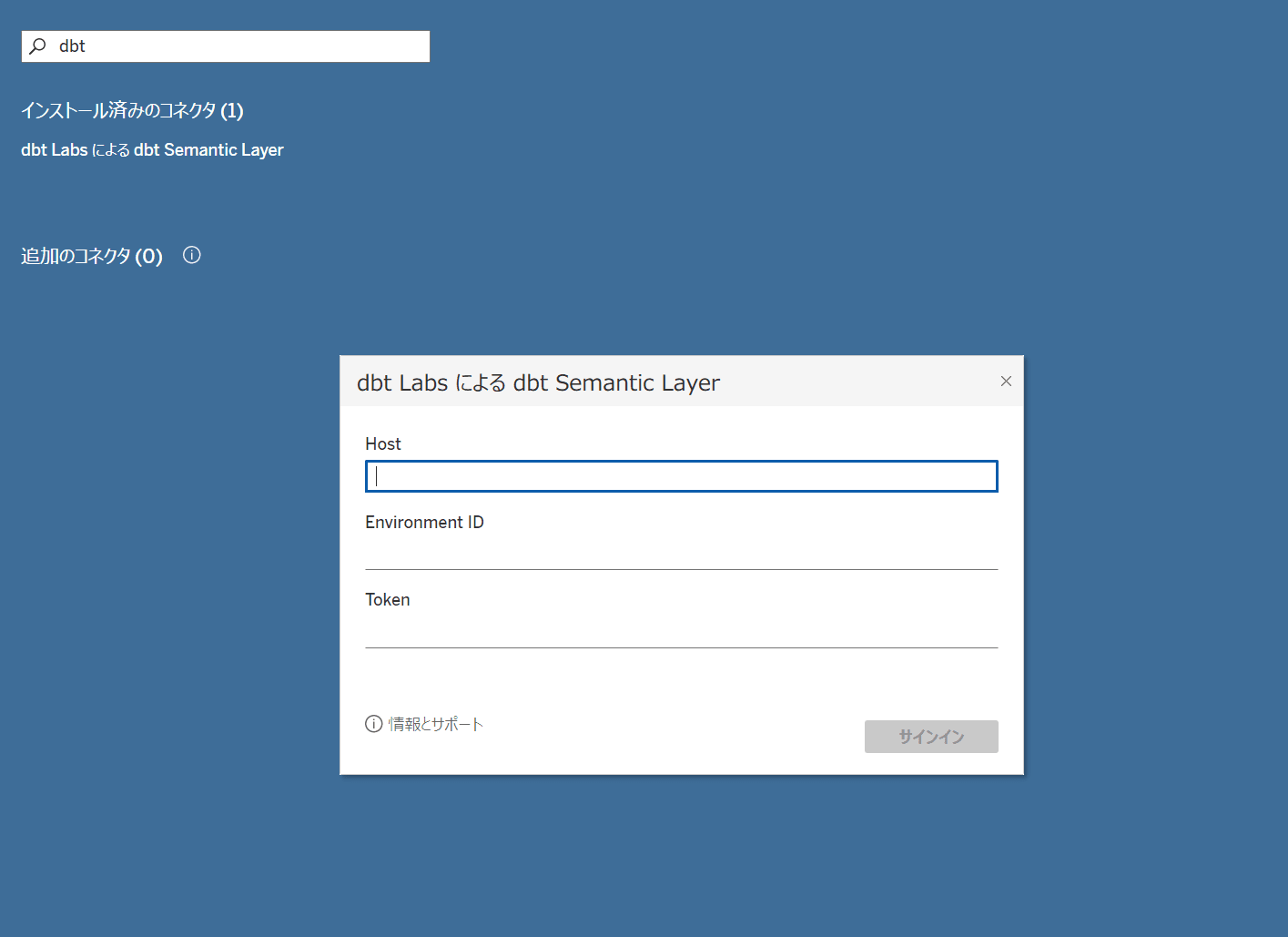
Tableau 利用時の注意点
Tableau から dbt Semantic Layer を利用する際、いくつか制限があります。
特に注意が必要な点として、Tableau の UI 上ではすべてのメトリクスがデフォルトで「SUM(合計)」という集計タイプで表示されます。この集計タイプは Tableau 側では変更できず、dbt Semantic Layer 側の定義によって制御されています。メトリクスの集計方法を変えたい場合は、YAML 側で定義を変更する必要があります。
ワークシートからセマンティックレイヤーを参照
下図のように月ごとのオーダー数を集計してみます。
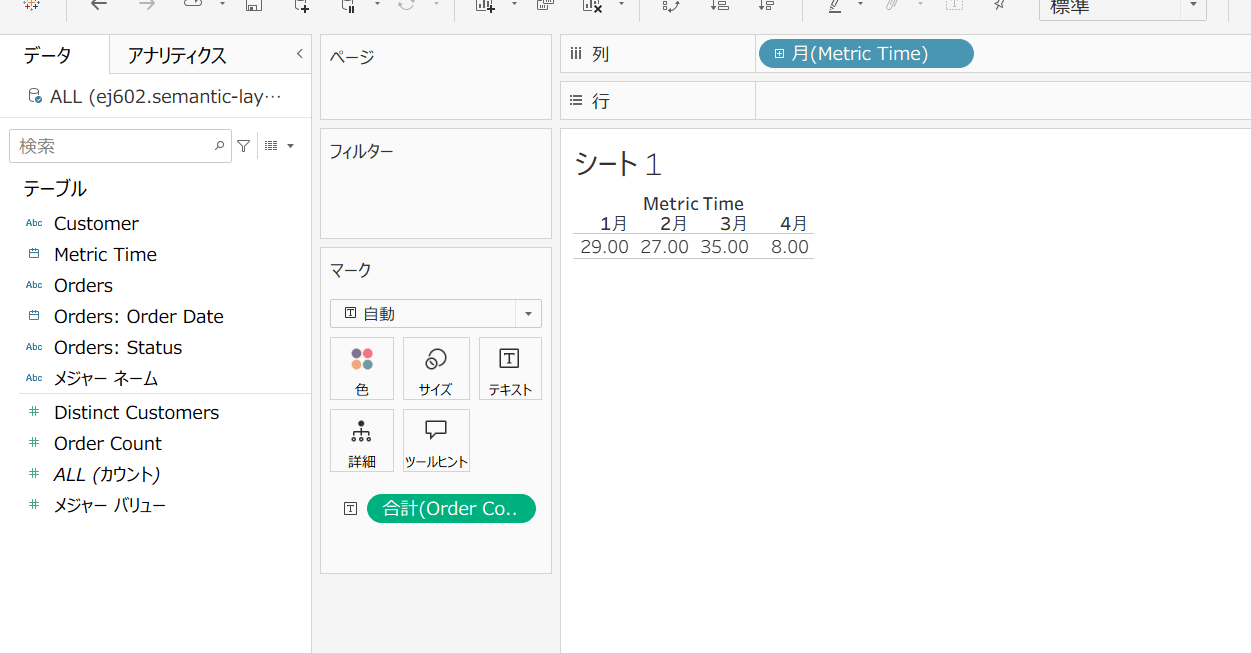
上記は以下のクエリと同様です。
$ dbt sl query --metrics order_count --group-by metric_time__month
+-------------------------+-------------+
| METRIC_TIME__MONTH | ORDER_COUNT |
+-------------------------+-------------+
| 2018-03-01T00:00:00.000 | 35 |
| 2018-04-01T00:00:00.000 | 8 |
| 2018-01-01T00:00:00.000 | 29 |
| 2018-02-01T00:00:00.000 | 27 |
+-------------------------+-------------+
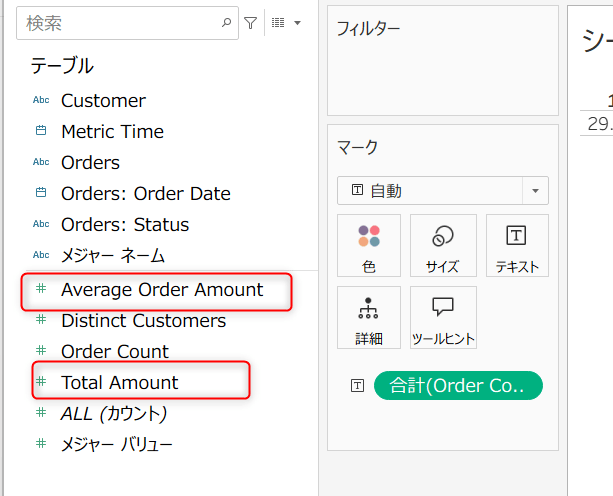
メジャーの追加
最低限、Tableau からセマンティックレイヤーを参照できたので、新たなメトリクスを追加してみます。サンプルデータには金額に関する項目がないため、以下のようにモデルにダミーの金額カラムを追加しました。
select
id as order_id,
user_id as customer_id,
order_date,
status,
abs(hash(id)) % 9901 + 100 as amount -- ダミー金額(order_id ベースの決定論的な値、100〜10000)
from {{ source('jaffle_shop', 'orders') }}
これに伴い、YAMLでも以下のメトリクスを追加します
- name: total_amount
type: simple
label: 合計金額
agg: sum
expr: amount
- name: average_order_amount
type: simple
label: 平均注文金額
agg: average
expr: amount
追加後、開発環境で動作を確認します。この際、--metrics には複数のメトリクスをカンマ区切りで指定できます。
$ dbt sl query --metrics total_amount --group-by metric_time__month
+-------------------------+--------------+
| METRIC_TIME__MONTH | TOTAL_AMOUNT |
+-------------------------+--------------+
| 2018-01-01T00:00:00.000 | 144180 |
| 2018-03-01T00:00:00.000 | 174846 |
| 2018-02-01T00:00:00.000 | 131195 |
| 2018-04-01T00:00:00.000 | 35769 |
+-------------------------+--------------+
$ dbt sl query --metrics total_amount,average_order_amount --group-by orders__status
+----------------+----------------------+--------------+
| ORDERS__STATUS | AVERAGE_ORDER_AMOUNT | TOTAL_AMOUNT |
+----------------+----------------------+--------------+
| shipped | 4452.615385 | 57884 |
| completed | 5237 | 350879 |
| return_pending | 2733 | 5466 |
| returned | 3386.75 | 13547 |
| placed | 4478 | 58214 |
+----------------+----------------------+--------------+
デプロイメント環境でのジョブ実行後、Tableau でデータソースを更新すると、追加したメトリクスが反映されます。
この状態で下図のようにワークシートを作成します。開発環境でのクエリ時と同じ数値となっていることが確認できました。
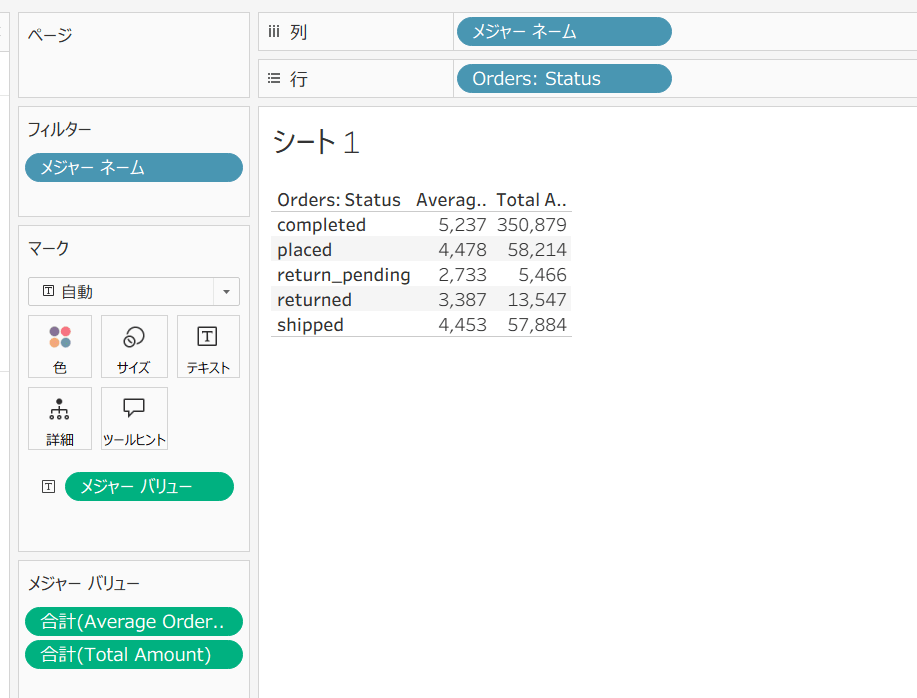
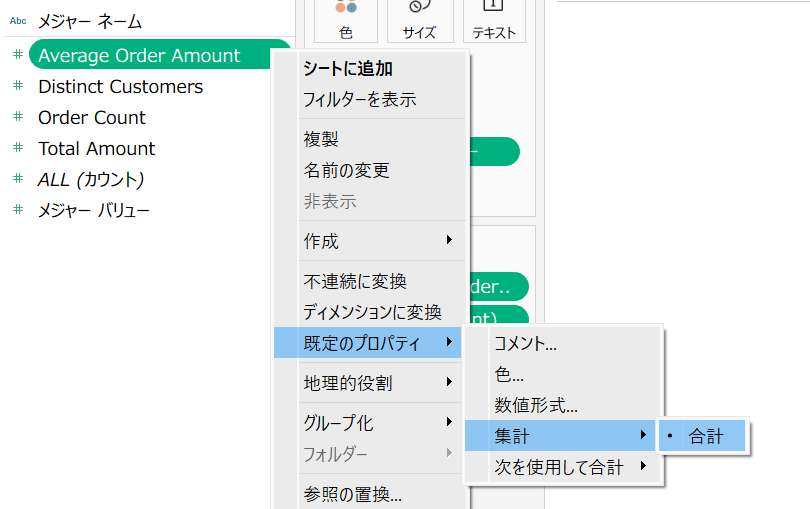
メジャーの既定のプロパティを確認すると、average_order_amount など各メトリクスが「合計」として表示されています。前述の通り、Tableau 側での集計タイプの変更はできないため、集計方法は dbt 側の定義が反映されます(average_order_amount は平均として集計されているが、表示は「合計」となっている)。
さいごに
最低限ですが dbt platform でセマンティックレイヤーを試すための基本的な手順を記事としました。
こちらの内容がどなたかの参考になれば幸いです。








