AWS Step Functionsで大規模な並列処理を実施できるDistributed Mapを試してみた #reinvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部 IoT事業部の若槻です。
先日開催されたAWS re:Invent 2022で、AWS Step Functionsで大規模な並列処理を実施できるStep Functions Distributed Mapが発表されました。
- AWS Step Functions launches large-scale parallel workflows for data processing and serverless applications
- Step Functions Distributed Map – A Serverless Solution for Large-Scale Parallel Data Processing | AWS News Blog
S3 Bucket内のオブジェクトをもとに大規模なMap処理が行えるとのことで、実際に現地会場でKeynoteを聞いていた時にとても興奮したのを覚えています。
今回は、Step Functions Distributed Mapを使用したWorkflowを実際に作成して試してみました。
やってみた
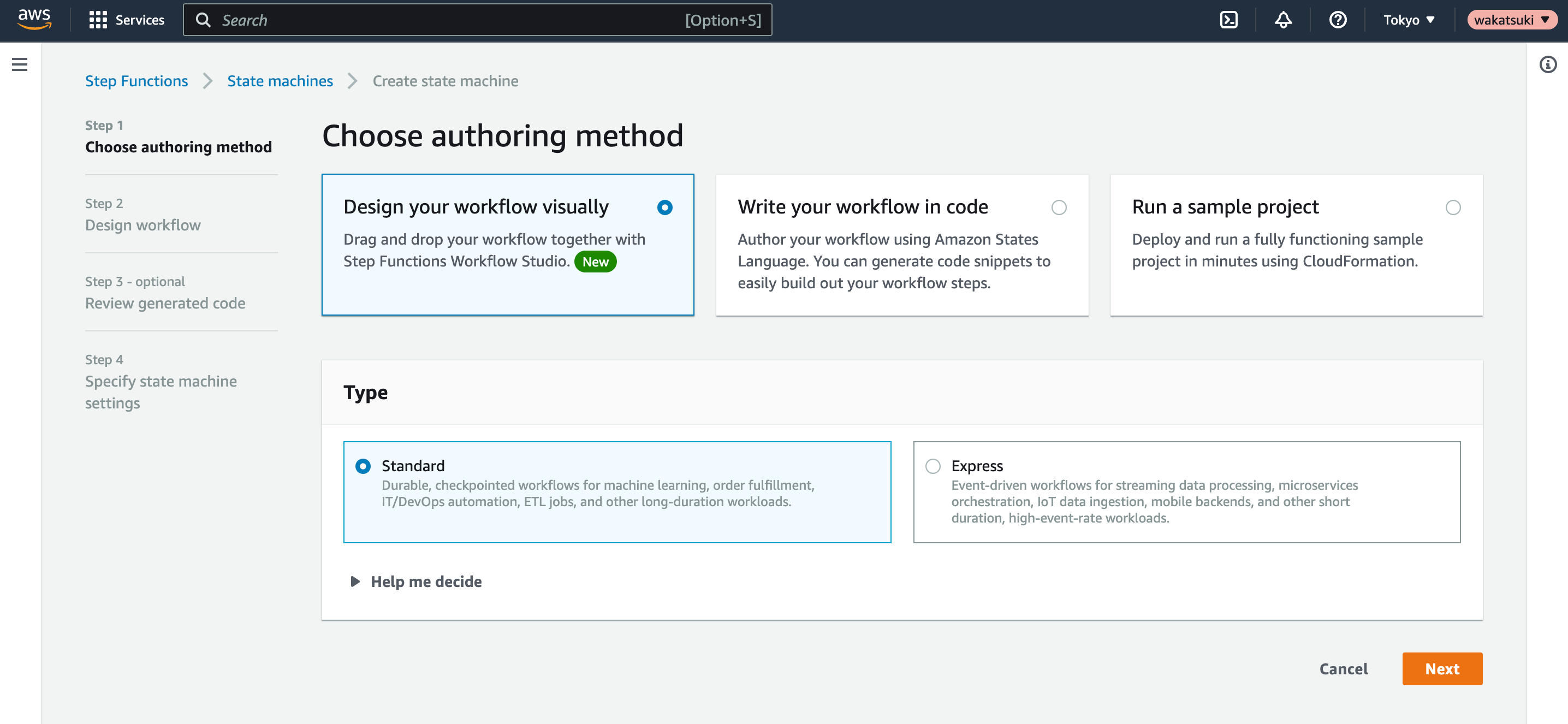
Workflow作成
Workflow Studioで作成していきます。
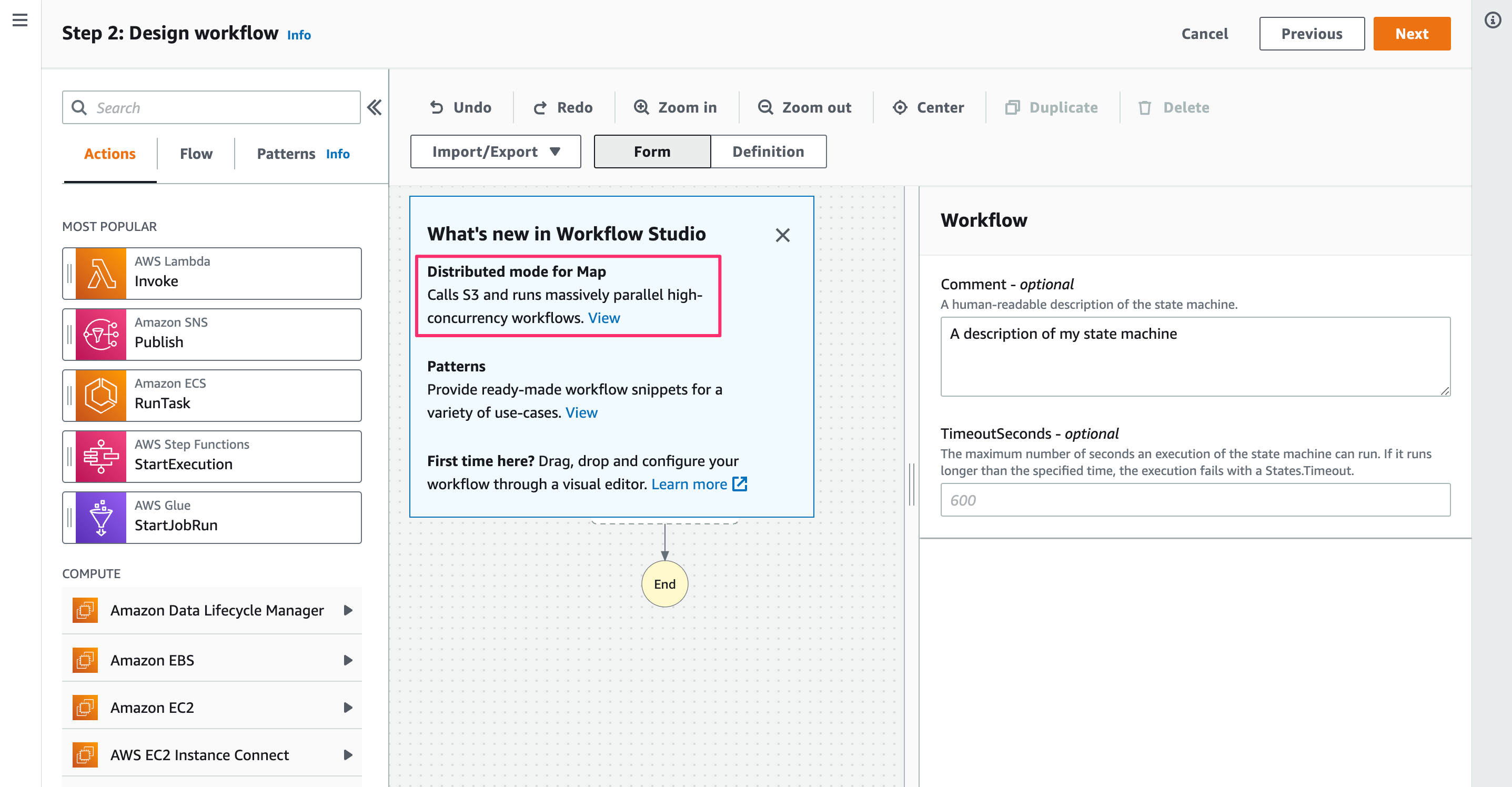
What's newとしてDistributed mode for Mapが示されています。[View]をクリック。
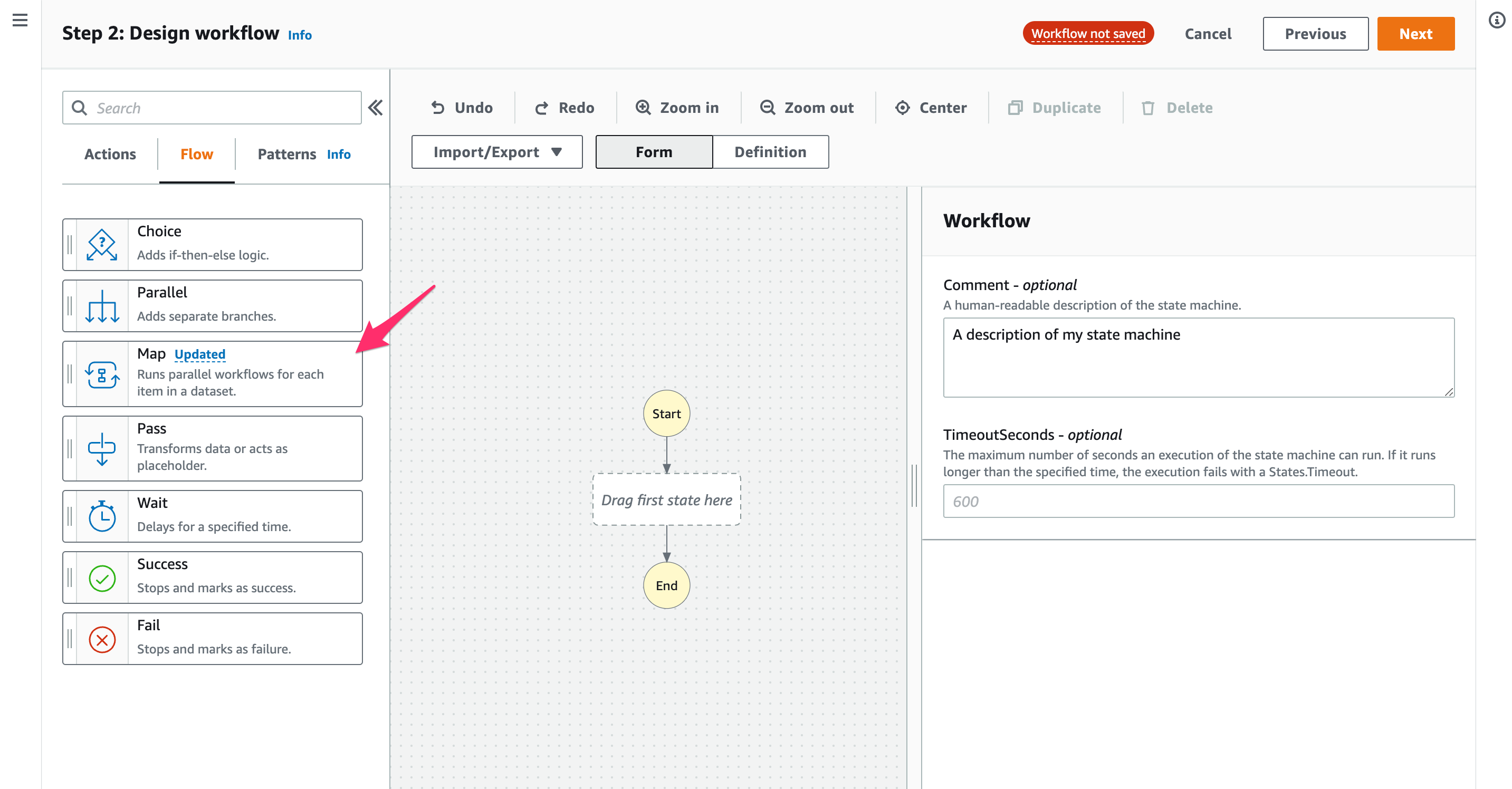
[Flow]でMapがUpdatedとなっていますね。[Updated]をクリック。
するとポップアップでDistributed Mapの軽い解説が出ます。さらにリンクをクリック。
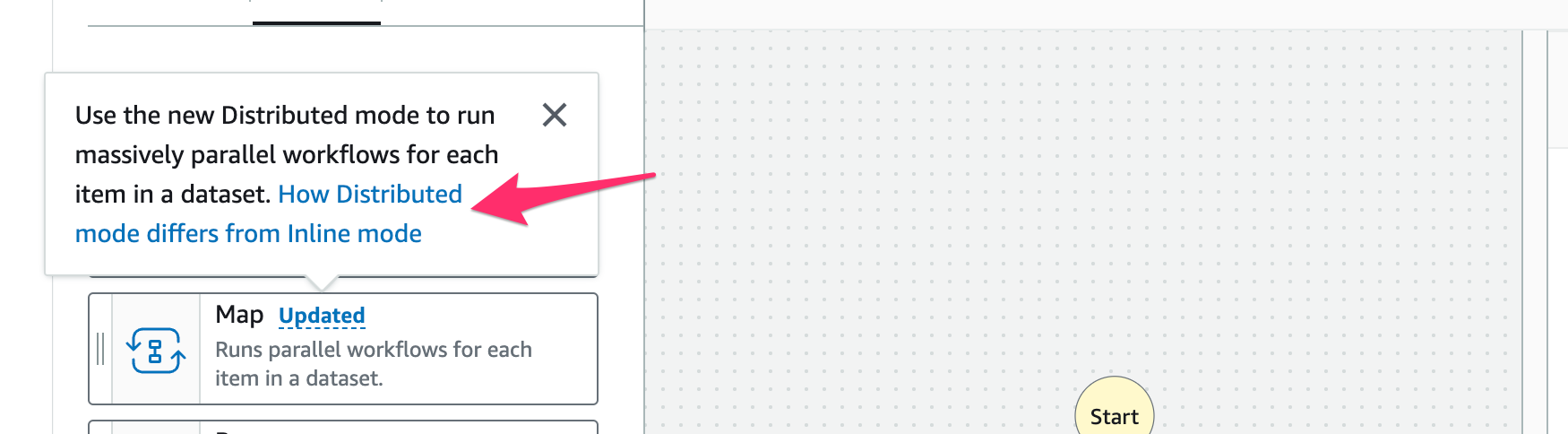
すると従来のMap(Inline mode)と新しいMap(Distributed mode)の比較表が出てきました。分かりやすい。

MapをキャンバスにD&Dすると、Formで今までは無かった「Processing mode」というメニューが出るようになっていました。ここでMapのモードを指定するようです。
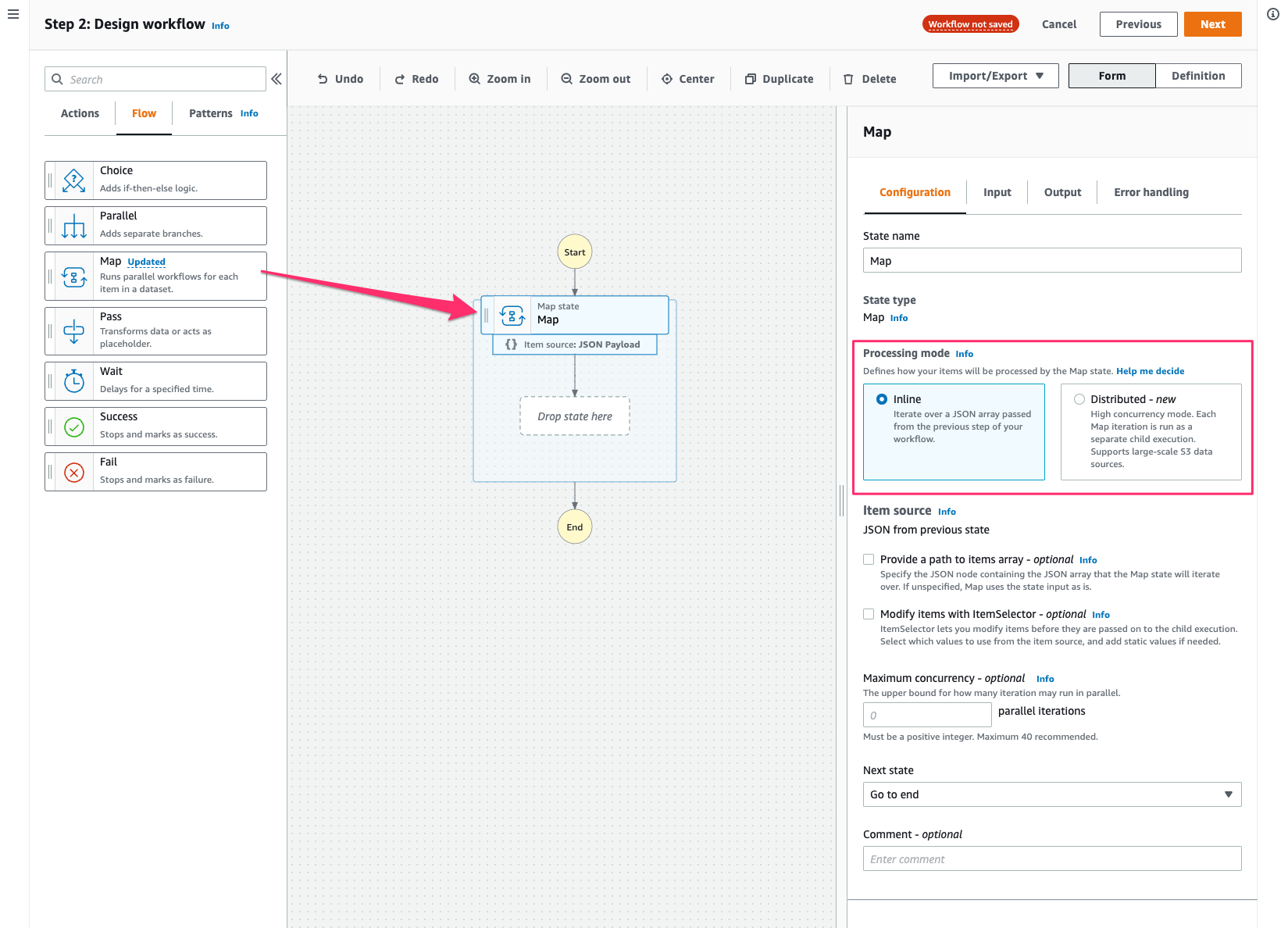
[Processing mode]でDistributedを選択するとメニューがガラリと変わりました。
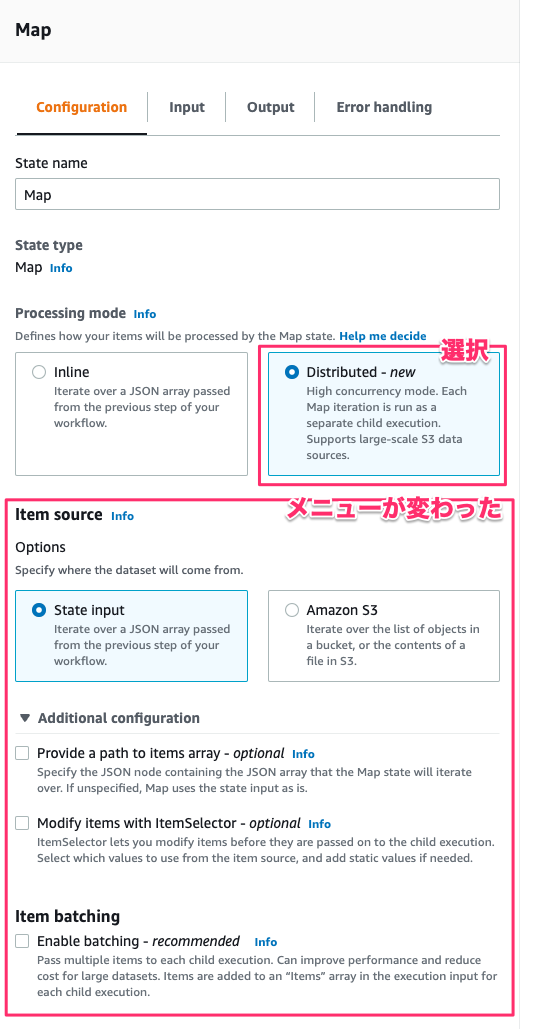

ここから、メニューの各パラメータでどのような設定ができるのか確認してみます。
[Item source]では、Map stateが入力データをどこから受け取るかを定義します。State inputを選択すると直前のステップから渡されたJSON配列データが使用されます。またオプションとして[Provide a path to items array]を設定すると渡されるデータのパスを指定でき、[Modify items with ItemSelector]を設定すると渡されるデータを加工できます。
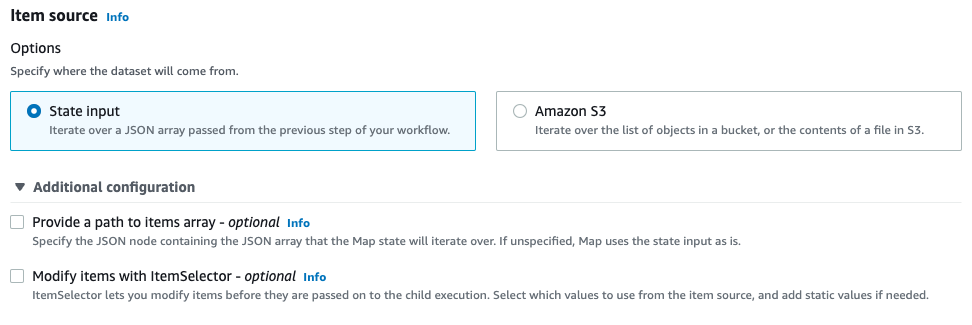
Amazon S3を選択するといずれか(後述)のAmazon S3データソースから取得されたアイテムのコレクションが使用されます。オプションとして[Limit number of items]を設定すると取得されるアイテム数の上限を指定でき、[Modify items with ItemSelector]を設定すると渡されるデータを加工できます。
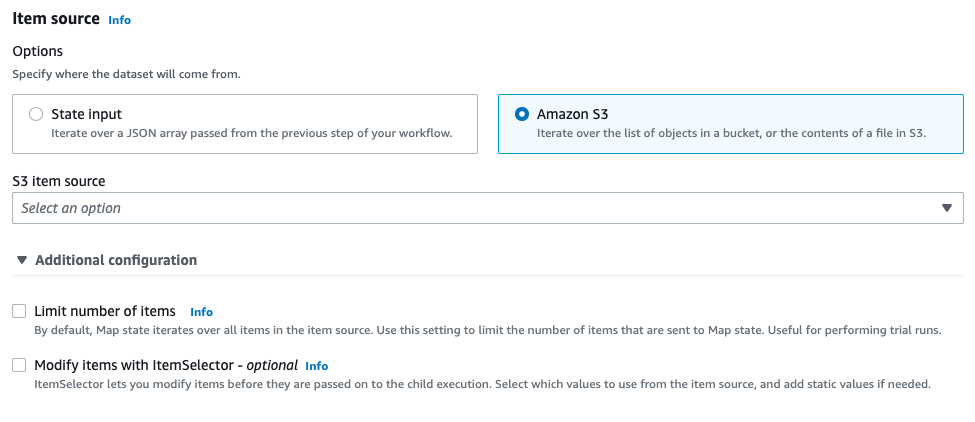
Amazon S3データソースはS3 object list、JSON file in S3、CSV file in S3およびS3 Inventoryの4つから選択できます。
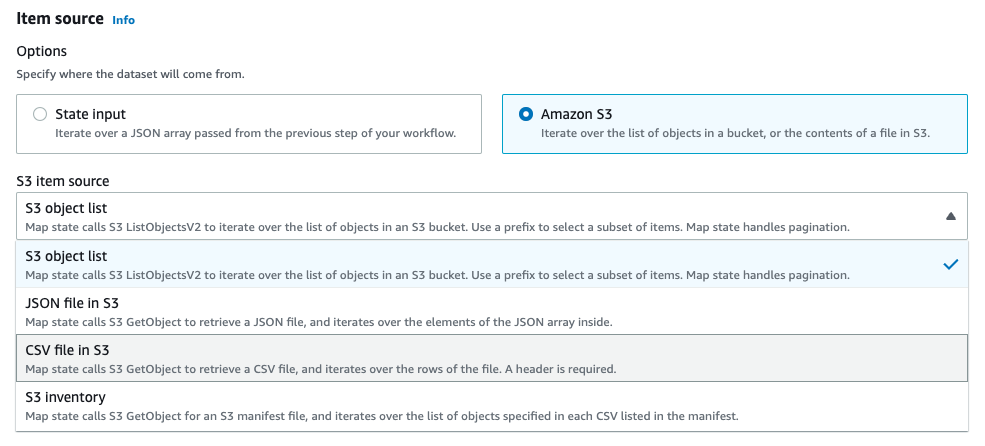
S3 object listを選択した場合は対象のBucketおよびPrefixを指定します。
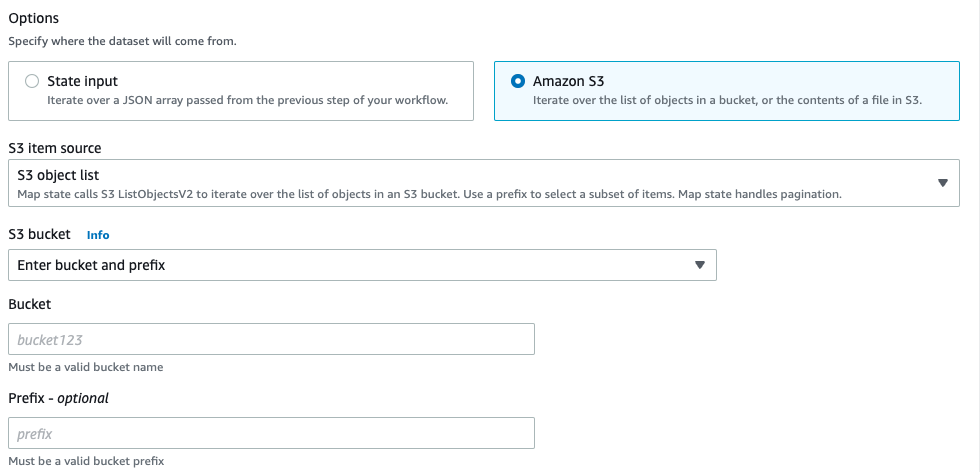
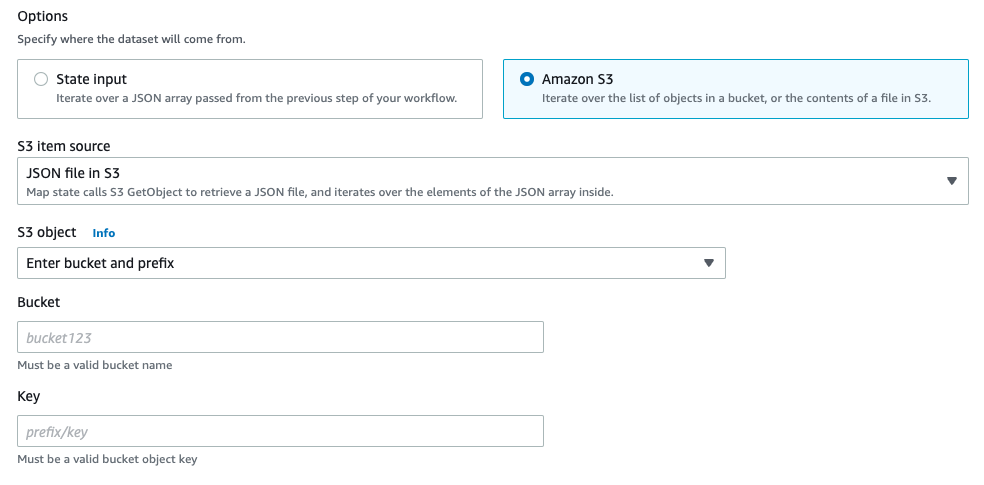
JSON file in S3、CSV file in S3またはS3 Inventoryを選択した場合は、対象のオブジェクトが格納されたBucketおよびKeyを指定します。
ここでS3 Inventoryとは、S3 Bucketに格納されたオブジェクトのメタ情報(スキーマなど)を示すmanifest fileです。詳細は以下を参考ください。
[Item batching]を有効にすると、子実行毎に複数のアイテムをバッチ処理させることができ、有効化が推奨されています。

有効にした場合はバッチ毎の最大アイテム数、最大サイズおよびグローバルなJSON入力を指定できます。
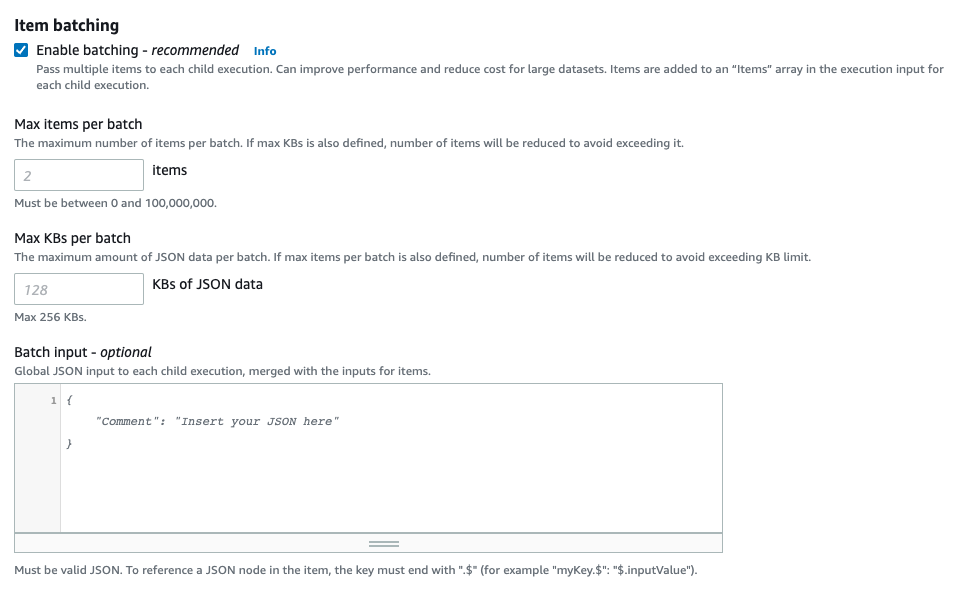
Map Run内で実行されるLambda関数の同時実行数(既定は1,000)や、Distributed Map自体の子実行の同時実行数(10,000)を超える恐れがある場合はItem batchingを設定すれば良さそうですね。
[Set concurrency limit]を有効にしたい場合は子実行の同時最大実効数を制限できます。

[Child execution type]では、子実行のタイプを指定できます。

[Runtime settings]の追加設定として、[Set a tolerated failure threshold]ではMap Runでの子実行の許容失敗量を指定できます。既定では1つ以上失敗するとMap Runは失敗します。[Use state name as label in Map Run ARN]ではMap Run ARNにカスタムラベルを指定できます。既定ではMap stateの名前が使用されます。
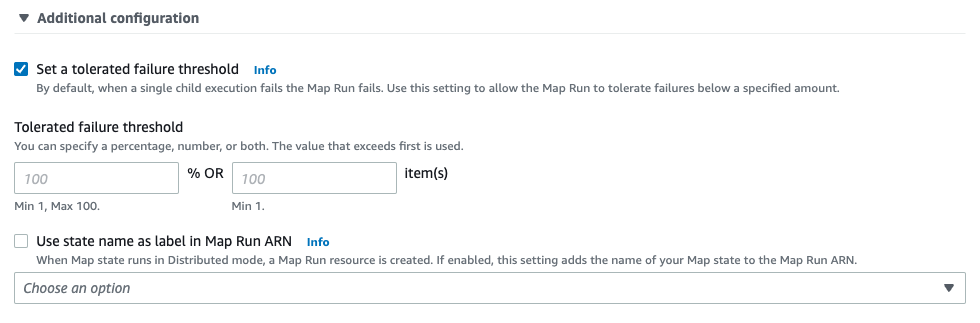
[Export Map state results to Amazon S3]を有効にすると、Map Runの実行結果をS3 Bucketの指定の場所に格納できます。

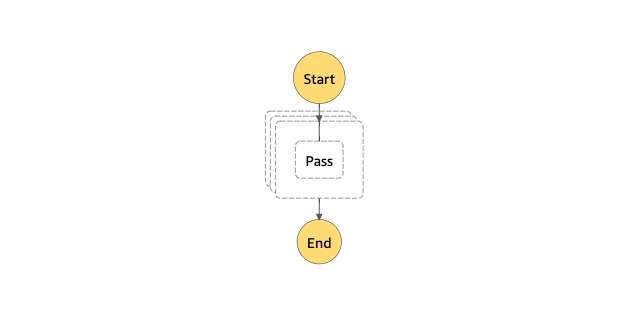
今回はCSVファイルに記述された内容をもとにDistributed Mapを実施する次のようなWorkflowを作成しました。Map state内ではPassタスクを1つ実行するだけです。
{
"Comment": "A description of my state machine",
"StartAt": "Map",
"States": {
"Map": {
"Type": "Map",
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "DISTRIBUTED",
"ExecutionType": "STANDARD"
},
"StartAt": "Pass",
"States": {
"Pass": {
"Type": "Pass",
"End": true
}
}
},
"End": true,
"ItemReader": {
"Resource": "arn:aws:states:::s3:getObject",
"Parameters": {
"Bucket": "20221212-cmwakatsuki",
"Key": "data.csv"
},
"ReaderConfig": {
"InputType": "CSV",
"CSVHeaderLocation": "FIRST_ROW"
}
},
"MaxConcurrency": 1000,
"Label": "Map"
}
}
}
グラフビューはこんな感じ。
S3 Bucketには3つのアイテムを記述した次のCSVファイルを格納しています。
id,name,value
d001,デバイス1,10
d002,デバイス2,5
d003,デバイス3,8
動作確認
Workflowを実行してみます。
実行が成功しました。CSVファイルから取得された3つのアイテムがWorkflowの出力結果として取得できています。
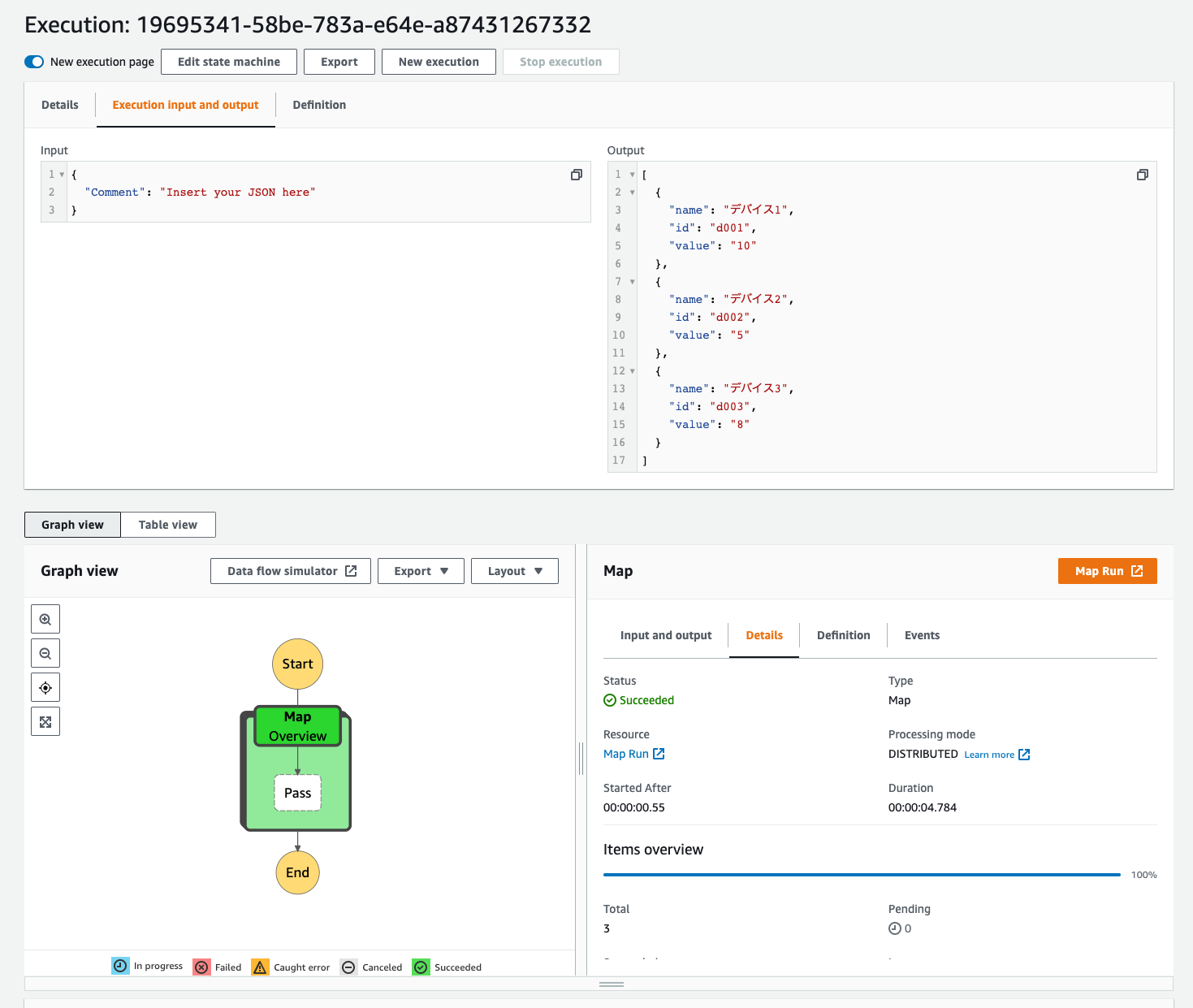
Event viewではMap Runが別途ページで見れるようです。開いてみます。
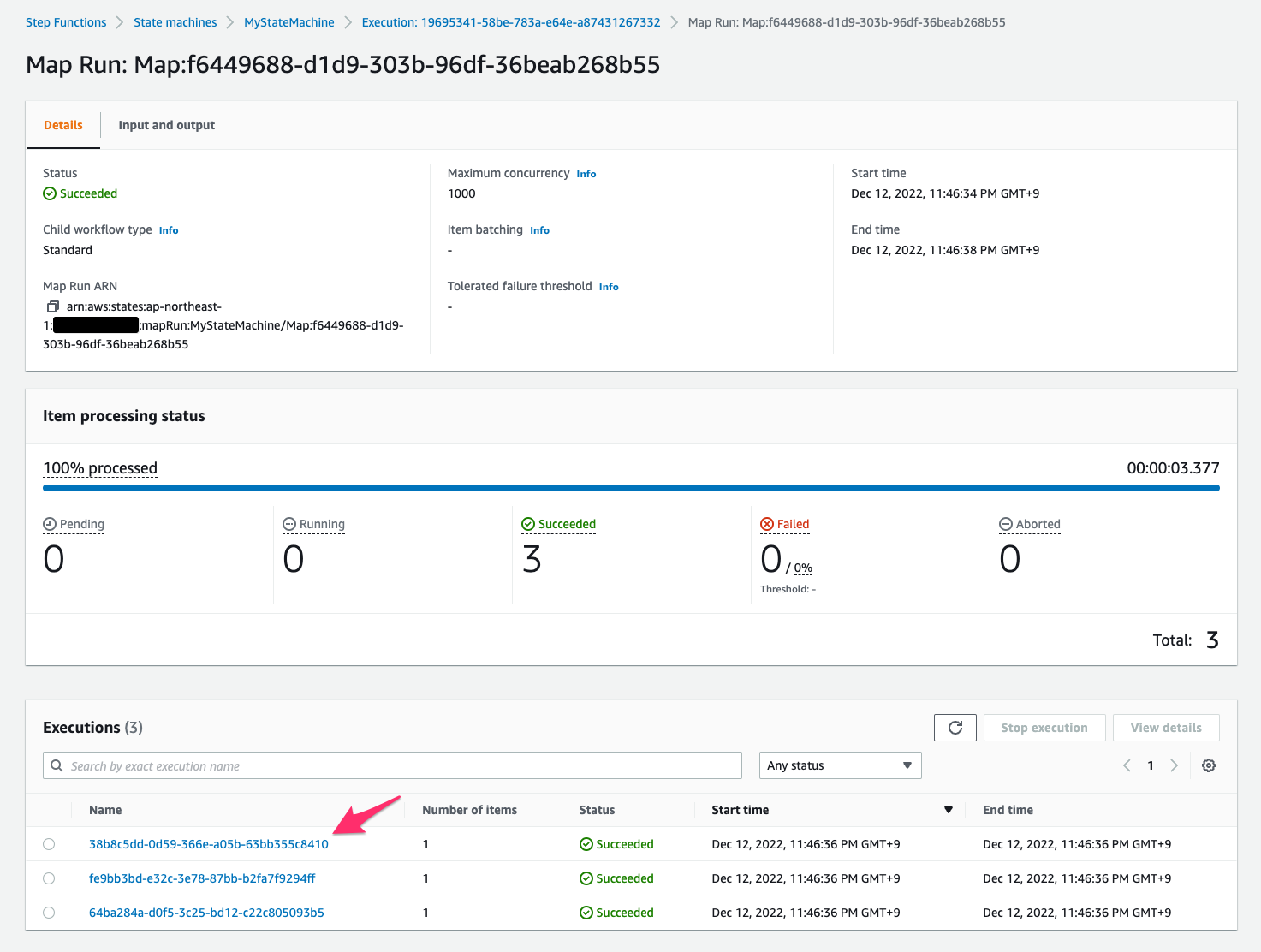
遷移先でMap Runの実行結果の詳細が確認できました。子実行の一覧もありますね。そのうち1つを開いてみます。
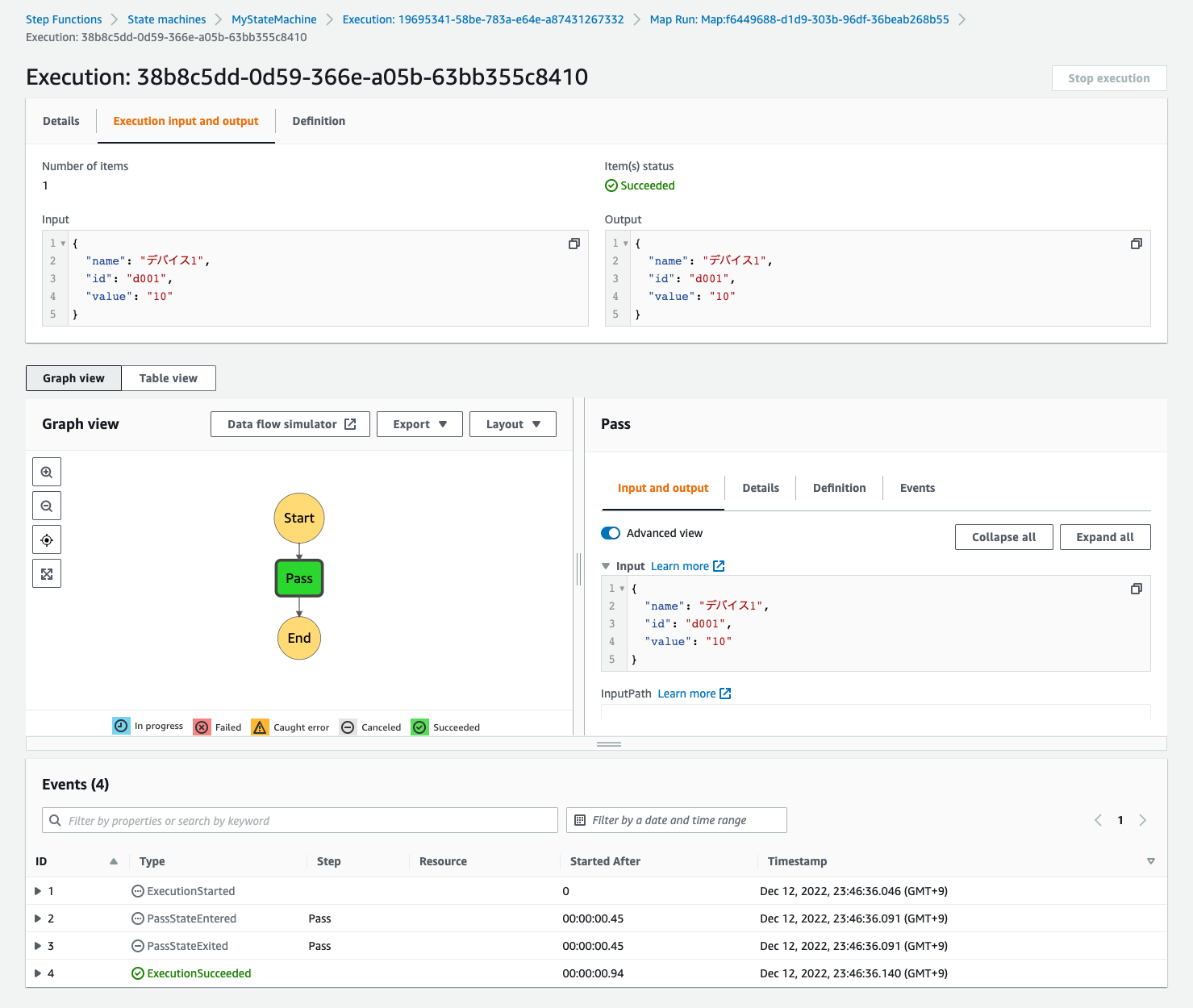
すると遷移先で子実行の個別の実行内容を確認できました。
おわりに
Step Functions Distributed Mapを使用したWorkflowを実際に作成して試してみました。
Step Functionsは今までの通常のMap Stateにおいてもある程度大きな並列実行には対応できましたが、今回のアップデートによりさらに大規模な実行に対応できるようになった形です。またS3 Bucketのオブジェクトを直接指定して実行できるのも素晴らしいですね。
またWorkflow作成時に確認した通りDistributed Mapの設定パラメータは今回試したほかにも様々あるので、今後ほかのパターンでも検証をやってみたいと思います。
参考
以上