
【DuckDB×Python】 Redshiftの監査ログからユーザーが実行したクエリを抽出する
データ事業本部の荒木です。
先日Redshiftのテーブルアクセス状況を可視化するクエリについて記事を執筆しましたが、こちらの方法では直近1週間分しかアクセス状況の確認ができませんでした。
【Redshift】SQLでテーブルごとのアクセス状況を可視化する | DevelopersIO
長期的なテーブルの利用状況、例えば「過去1年でどのテーブルがどれくらい使われているか?」を把握するには、 Redshiftの監査ログ(ユーザーアクティビティログ) を解析する必要があります。
今回は、この監査ログをローカルPC環境で高速に処理するためDuckDBを活用し、ユーザーが実行したクエリから参照されているテーブル数を集計し、アクセス状況を可視化する方法を試してみたのでご紹介します。
前提
Redshiftの監査ログはS3に出力されますが、以下の課題があります。
- ファイルサイズが大きい:アクセス頻度によっては、1か月分で数GB以上になり、年単位のデータを集計しようとするとかなりの処理負荷がかかります。
- クエリ内の改行(\n):ユーザーが実行したクエリに改行が含まれていると、ログファイル内でも改行されてしまい、1つのログレコードが複数行に分断されてしまいます。そのままデータベースに取り込むと、おかしなデータになってしまいます。
Pythonでファイルサイズが大きいログから参照されているテーブル数を算出する処理が重くなってしまいました。
なのでPythonでは必要な加工処理のみ実施して、ローカル環境で完結できるDuckDBを使用し大量のCSVファイルをSQLで高速に取り込み・集計できるようにしました。
Step 1: 監査ログの整形(Python)
まずは、監査ログに含まれる改行問題を解決するため、Pythonでログファイルを加工します。
Redshiftのユーザーアクティビティログには、例えば以下のようにクエリの途中で改行が入ってしまい、そのままではCSVとして扱えません。
'2025-10-15T00:14:54Z UTC [ db=db_name user=rdsdb pid=1073873106 userid=1 xid=55006530 ]' LOG: /* hash: f0fb1255e667e7a30698bd3a4688ac174 */
WITH per_table AS (
SELECT
case
以下のPythonスクリプトでは、ログの先頭行('YYYY-MM-DDで始まりLOG:が含まれる行)を新しいレコードの開始とみなし、それ以外の行は前の行に結合しています。
import gzip, re
from pathlib import Path
# === 設定(必要ならここだけ変更) ===
BASE_DIR = Path("{監査ログを保管しているローカルパス}") # 入力の探索ルート
OUT_DIR = BASE_DIR / "merged_useractivitylog" # 出力先ディレクトリ
FILE_GLOB = "**/*useractivitylog_*.gz" # 探索パターン
# =====================================
# 先頭が 'YYYY-..T かつ 同行に LOG: がある行を新規レコード開始とみなす
START = re.compile(r"^'\d{4}-\d{2}-\d{2}T.*LOG:")
# 行連結時に挿入する区切り(← リテラルの「\n」を入れたいので raw 文字列に)
SEP = r"\n"
def one_line_logs(gz_path: Path, out_path: Path) -> int:
"""1つの .gz を「1ログ=1行」にまとめて out_path に書き出す。戻り値は出力行数。"""
out_path.parent.mkdir(parents=True, exist_ok=True)
buf, n = "", 0
with gzip.open(gz_path, "rt", encoding="utf-8", errors="replace") as f, \
out_path.open("w", encoding="utf-8", newline="\n") as w:
for s in f:
# 改行・CR除去、NBSP(不換空白)を通常スペースへ
s = s.rstrip("\n\r").replace("\u00A0", " ")
if not s.strip():
continue # 空行は無視
if START.match(s): # 新しいログの開始
if buf:
w.write(buf + "\n"); n += 1
buf = s
else: # 前のログに連結
buf = s if not buf else (buf + SEP + s)
if buf:
w.write(buf + "\n"); n += 1
return n
def main():
files = sorted(BASE_DIR.rglob(FILE_GLOB))
if not files:
print(f"対象ファイルが見つかりませんでした(検索ルート: {BASE_DIR}, パターン: {FILE_GLOB})")
return
total_rows = 0
print(f"処理開始:検索ルート={BASE_DIR}、出力先={OUT_DIR}、対象ファイル数={len(files)}")
for gz in files:
out = OUT_DIR / (gz.name[:-3] + ".csv") # .gz → .csv
print(f"処理中:{gz} → {out}")
total_rows += one_line_logs(gz, out)
print(f"処理完了:出力ディレクトリ={OUT_DIR}、処理ファイル数={len(files)}、出力行数合計={total_rows}")
if __name__ == "__main__":
main()
Step 2: DuckDBへのデータ取り込み
整形後のCSVファイル群をDuckDBに取り込みます。ここでは、監査ログ(all_logs)と、集計対象のテーブルリスト(table_list)の2つを取り込みます。
監査ログの取り込み(all_logs)
Step 1で出力された複数のCSVファイルをワイルドカードでまとめて取り込みます
con = duckdb.connect("./audit/logs.duckdb")
con.sql(f"""
CREATE OR REPLACE TABLE all_logs AS
SELECT *
FROM read_csv(
'./{OUT_DIR}/*.csv',
delim = '\x1F',
header = false, -- 先頭行ヘッダー扱いを禁止
columns = {{ 'line': 'TEXT' }},
quote = '', -- クオート無効
strict_mode = false, -- CSV厳格チェックを緩める
filename = true -- どのファイル由来か残す
);
""")
集計対象テーブルリストの取り込み(table_list)
アクセス状況を確認したいテーブル一覧を事前にCSVファイルとして作成し、それもDuckDBに取り込みます。CSVの中身は、schema_name.table_nameの形式です。
con.sql("""
CREATE OR REPLACE TABLE table_list AS
SELECT *
FROM read_csv(
'./audit/テーブル一覧.csv',
columns = { 'table_name': 'TEXT' }
);
""")
Step 3: テーブルアクセス数の集計と出力(SQL)
DuckDBで以下の集計クエリを実行し、テーブル単位、ユーザー単位、日付単位のアクセス数を集計してCSVファイルに出力します。
con.sql("""
COPY (
SELECT
s.fqtn_norm AS fqtn,
s.user_name,
s.activity_date,
SUM(s.occur_in_query) AS total_occurrences,
COUNT(DISTINCT s.qid_key) AS distinct_queries
FROM (
SELECT
b.qid_key,
tok.fqtn_norm,
COUNT(*) AS occur_in_query, -- 同一クエリ内での出現回数
b.user_name,
b.activity_date
FROM (
-- b_base + b_norm 相当(行ごとにメタ抽出&SQL正規化)
SELECT
hash(line) AS qid_key,
CAST(regexp_extract(split_part(line, ' LOG: ', 1), '^''([0-9]{4}-[0-9]{2}-[0-9]{2})', 1) AS DATE) AS activity_date,
regexp_extract(split_part(line, ' LOG: ', 1), '\suser=([^\s\]]+)', 1) AS user_name,
/* SQL本文: コメント除去 → 大文字化 → クォート除去 → ドット周りの空白縮約 */
regexp_replace(replace(upper(regexp_replace(regexp_replace(split_part(line, ' LOG: ', 2), '/\*[\s\S]*?\*/', ''),'--[^\n]*', '')), '"', ''),'\s*\.\s*', '.') AS sql_norm
FROM all_logs
) AS b
/* b.sql_norm から SCHEMA.TABLE / DB.SCHEMA.TABLE を抽出し、末尾2部に正規化 */
JOIN (
SELECT
qid_key,
regexp_extract(ref_raw, '([A-Z_][A-Z0-9_]*\.[A-Z_][A-Z0-9_]*)$', 1) AS fqtn_norm
FROM (
SELECT
qid_key,
UNNEST(regexp_extract_all(sql_norm,'([A-Z_][A-Z0-9_]*(?:\.[A-Z_][A-Z0-9_]*){1,2})' )) AS ref_raw
FROM (
-- 上の b と同じ集合を再利用したいのでそのまま参照
SELECT
hash(line) AS qid_key,
regexp_replace(replace(upper(regexp_replace(regexp_replace(split_part(line, ' LOG: ', 2), '/\*[\s\S]*?\*/', ''),'--[^\n]*', '')),'"', ''),'\s*\.\s*', '.') AS sql_norm
FROM all_logs
)
)
WHERE fqtn_norm IS NOT NULL
) AS tok
ON tok.qid_key = b.qid_key
/* table_list 由来の実在テーブルだけに限定(a_norm 相当) */
JOIN (
SELECT DISTINCT upper(replace(table_name, '"', '')) AS fqtn_norm
FROM table_list
) AS a
ON tok.fqtn_norm = a.fqtn_norm
GROUP BY b.qid_key, tok.fqtn_norm, b.user_name, b.activity_date
) AS s
GROUP BY s.fqtn_norm, s.user_name, s.activity_date
ORDER BY total_occurrences DESC, fqtn, s.activity_date, s.user_name
) TO './audit/table_usage_by_user_date.csv'
WITH (HEADER, DELIMITER ',', QUOTE '"', ESCAPE '"', FORCE_QUOTE *);
""")
集計用クエリの解説
1. ログの整形とメタ情報抽出(サブクエリ b)
役割: all_logsテーブルの 1行ログデータ(line) から、集計に必要なメタ情報(日付、ユーザー名)と、正規化されたSQL本文を抽出します。
- hash(line) AS qid_key: ログの行全体をハッシュ化し、クエリを一意に識別するためのID(qid_key)を作成しています。
- activity_date, user_name: regexp_extractやsplit_part関数を使い、ログのメタ部分(LOG:より前の部分)から実行日付やユーザー名を抽出しています。
- sql_norm:
- split_part(line, ' LOG: ', 2): ログからSQL本文の部分だけを取り出します。
- regexp_replace(...): コメント(/.../や--)を除去します。
- upper(...), replace(..., '"', ''): 大文字化し、クォート(")を除去して、テーブル名の表記揺れをなくします。
- regexp_replace(..., '\s*.\s*', '.'): schema . tableのようにドット前後の空白も除去し、SCHEMA.TABLE形式に統一します。
2. テーブル名の抽出と実在チェック(サブクエリ tok と a)
役割: 整形後のSQL本文(sql_norm)からテーブル名候補を抽出し、本当にRedshiftに存在するテーブル(table_list)だけに絞り込みます。
- tok サブクエリ:
- regexp_extract_all(...): sql_normから、SCHEMA.TABLEやDB.SCHEMA.TABLEのような形式の文字列(テーブル名候補)をすべて抽出します。
- UNNEST(...): 抽出したテーブル名候補のリストを、行に展開します(1つのクエリから複数のテーブル名候補が生まれる)。
- regexp_extract(..., '([A-Z_][A-Z0-9_].[A-Z_][A-Z0-9_])$', 1) AS fqtn_norm: 抽出した候補から、末尾2部(schema.table)だけを正規化されたテーブル名(fqtn_norm)として取り出します。
- a サブクエリ: table_listから、正規化された実在テーブル名リストを作成します。
- JOIN tok ON a: テーブル名候補 (tok) を実在テーブルリスト (a) で結合(JOIN)することで、SQL内で言及された、かつ実際に存在するテーブル名だけが残ります。
3. 最終的な集計(インナークエリ s と最終 SELECT)
役割: クエリIDとテーブル名でグループ化し、最終的にユーザー、日付、テーブル名で集計します。
- インナークエリ s:
- GROUP BY b.qid_key, tok.fqtn_norm, ...: クエリIDとテーブル名の組み合わせでグループ化し、同一クエリ内でのテーブルの出現回数(occur_in_query)をカウントします。
- 最終 SELECT:
- GROUP BY s.fqtn_norm, s.user_name, s.activity_date: テーブル名、ユーザー名、日付の組み合わせで最終的にグループ化します。
- SUM(s.occur_in_query) AS total_occurrences: 各テーブルの総言及回数(クエリ内で複数回登場した場合もカウント)。
- COUNT(DISTINCT s.qid_key) AS distinct_queries: そのテーブルを参照した異なるクエリの数(アクセス頻度の指標)。
最終的な実行ファイル(main関数)
上記のPythonによるログ整形処理とDuckDBへの取り込み・集計処理を合わせた最終的なコードです。
import gzip, re
from pathlib import Path
import duckdb
import pandas as pd
# === 設定(必要ならここだけ変更) ===
BASE_DIR = Path("{監査ログを保管しているローカルパス}") # 入力の探索ルート
OUT_DIR = BASE_DIR / "merged_useractivitylog" # 出力先ディレクトリ
FILE_GLOB = "**/*useractivitylog_*.gz" # 探索パターン
# =====================================
# 先頭が 'YYYY-..T かつ 同行に LOG: がある行を新規レコード開始とみなす
START = re.compile(r"^'\d{4}-\d{2}-\d{2}T.*LOG:")
# 行連結時に挿入する区切り(← リテラルの「\n」を入れたいので raw 文字列に)
SEP = r"\n"
def one_line_logs(gz_path: Path, out_path: Path) -> int:
"""1つの .gz を「1ログ=1行」にまとめて out_path に書き出す。戻り値は出力行数。"""
out_path.parent.mkdir(parents=True, exist_ok=True)
buf, n = "", 0
with gzip.open(gz_path, "rt", encoding="utf-8", errors="replace") as f, \
out_path.open("w", encoding="utf-8", newline="\n") as w:
for s in f:
# 改行・CR除去、NBSP(不換空白)を通常スペースへ
s = s.rstrip("\n\r").replace("\u00A0", " ")
if not s.strip():
continue # 空行は無視
if START.match(s): # 新しいログの開始
if buf:
w.write(buf + "\n"); n += 1
buf = s
else: # 前のログに連結
buf = s if not buf else (buf + SEP + s)
if buf:
w.write(buf + "\n"); n += 1
return n
def main():
files = sorted(BASE_DIR.rglob(FILE_GLOB))
if not files:
print(f"対象ファイルが見つかりませんでした(検索ルート: {BASE_DIR}, パターン: {FILE_GLOB})")
return
total_rows = 0
print(f"処理開始:検索ルート={BASE_DIR}、出力先={OUT_DIR}、対象ファイル数={len(files)}")
for gz in files:
out = OUT_DIR / (gz.name[:-3] + ".csv") # .gz → .csv
print(f"処理中:{gz} → {out}")
total_rows += one_line_logs(gz, out)
print(f"処理完了:出力ディレクトリ={OUT_DIR}、処理ファイル数={len(files)}、出力行数合計={total_rows}")
## DB接続
con = duckdb.connect("./audit/logs.duckdb")
## 監査ログの取り込み
con.sql(f"""
CREATE OR REPLACE TABLE all_logs AS
SELECT *
FROM read_csv(
'./{OUT_DIR}/*.csv',
delim = '\x1F',
header = false, -- 先頭行ヘッダー扱いを禁止
columns = {{ 'line': 'TEXT' }},
quote = '', -- クオート無効
strict_mode = false, -- CSV厳格チェックを緩める
filename = true -- どのファイル由来か残す
);
""")
## 集計対象テーブル格納用のテーブル作成
con.sql("""
CREATE OR REPLACE TABLE table_list AS
SELECT *
FROM read_csv(
'./audit/テーブル一覧.csv',
columns = { 'table_name': 'TEXT' }
);
""")
## 集計&CSVファイル作成
con.sql("""
COPY (
SELECT
s.fqtn_norm AS fqtn,
s.user_name,
s.activity_date,
SUM(s.occur_in_query) AS total_occurrences,
COUNT(DISTINCT s.qid_key) AS distinct_queries
FROM (
SELECT
b.qid_key,
tok.fqtn_norm,
COUNT(*) AS occur_in_query, -- 同一クエリ内での出現回数
b.user_name,
b.activity_date
FROM (
-- b_base + b_norm 相当(行ごとにメタ抽出&SQL正規化)
SELECT
hash(line) AS qid_key,
CAST(regexp_extract(split_part(line, ' LOG: ', 1), '^''([0-9]{4}-[0-9]{2}-[0-9]{2})', 1) AS DATE) AS activity_date,
regexp_extract(split_part(line, ' LOG: ', 1), '\suser=([^\s\]]+)', 1) AS user_name,
/* SQL本文: コメント除去 → 大文字化 → クォート除去 → ドット周りの空白縮約 */
regexp_replace(replace(upper(regexp_replace(regexp_replace(split_part(line, ' LOG: ', 2), '/\*[\s\S]*?\*/', ''),'--[^\n]*', '')), '"', ''),'\s*\.\s*', '.') AS sql_norm
FROM all_logs
) AS b
/* b.sql_norm から SCHEMA.TABLE / DB.SCHEMA.TABLE を抽出し、末尾2部に正規化 */
JOIN (
SELECT
qid_key,
regexp_extract(ref_raw, '([A-Z_][A-Z0-9_]*\.[A-Z_][A-Z0-9_]*)$', 1) AS fqtn_norm
FROM (
SELECT
qid_key,
UNNEST(regexp_extract_all(sql_norm,'([A-Z_][A-Z0-9_]*(?:\.[A-Z_][A-Z0-9_]*){1,2})' )) AS ref_raw
FROM (
-- 上の b と同じ集合を再利用したいのでそのまま参照
SELECT
hash(line) AS qid_key,
regexp_replace(replace(upper(regexp_replace(regexp_replace(split_part(line, ' LOG: ', 2), '/\*[\s\S]*?\*/', ''),'--[^\n]*', '')),'"', ''),'\s*\.\s*', '.') AS sql_norm
FROM all_logs
)
)
WHERE fqtn_norm IS NOT NULL
) AS tok
ON tok.qid_key = b.qid_key
/* table_list 由来の実在テーブルだけに限定(a_norm 相当) */
JOIN (
SELECT DISTINCT upper(replace(table_name, '"', '')) AS fqtn_norm
FROM table_list
) AS a
ON tok.fqtn_norm = a.fqtn_norm
GROUP BY b.qid_key, tok.fqtn_norm, b.user_name, b.activity_date
) AS s
GROUP BY s.fqtn_norm, s.user_name, s.activity_date
ORDER BY total_occurrences DESC, fqtn, s.activity_date, s.user_name
) TO './audit/table_usage_by_user_date.csv'
WITH (HEADER, DELIMITER ',', QUOTE '"', ESCAPE '"', FORCE_QUOTE *);
""")
if __name__ == "__main__":
main()
結果と考慮が必要な点
出力結果と可視化方法
上記の処理で出力したCSVデータは以下のようなフォーマットになります。
| fqtn | user_name | activity_date | total_occurrences | distinct_queries |
|---|---|---|---|---|
| SCHEMA1.TABLE_A | user1 | 2025-10-01 | 150 | 10 |
| SCHEMA1.TABLE_B | user2 | 2025-10-01 | 50 | 5 |
| SCHEMA1.TABLE_A | user1 | 2025-10-02 | 200 | 12 |
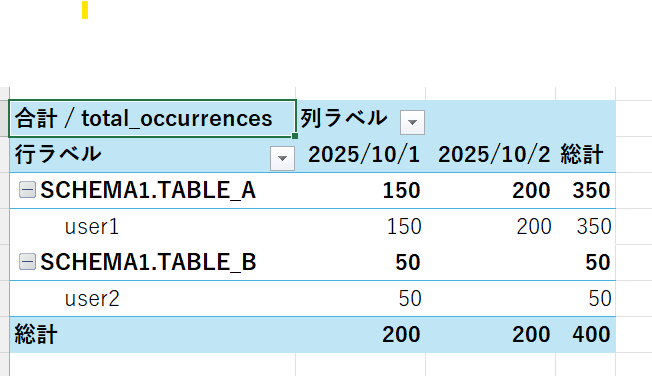
このCSVファイルをExcelなどで読み込み、ピボットテーブルを作成すれば、テーブル単位で日付ごとのアクセス頻度(distinct_queries)がとても見やすく可視化できます。
考慮が必要な点について
- Redshiftのアクセス頻度によって監査ログのファイルサイズが大きくなります。1ファイル解凍後のサイズが数GB以上になる場合、DuckDBへの取り込みや集計処理でメモリ不足になったり、処理が遅延したりする可能性があります。その場合は、ファイルを日付やサイズで分割するなど、一度に処理するデータ量を少なくするよう工夫が必要です。
まとめ
Redshift監査ログの実行クエリからテーブルのアクセス数を集計し、長期的な利用状況を把握する方法をご紹介しました。
今回のようにローカル環境でDuckDBを使えば、大規模なデータを手軽に分析できることが分かりました。一度にすべての監査ログを処理するのは大変ですが、PythonとDuckDBのスクリプトを日次で実行するようなワークフローを作成し、出力CSVをExcelだけでなくBIツールなどで可視化できるようにしておけば、テーブルのアクセス状況を常に確認できるデータ基盤として活用できそうです。
テーブルの利用実態に基づいたコスト最適化やデータ棚卸しの判断材料として、ぜひ参考にしていただければ幸いです。










