![[初心者向け] Glue で簡単なデータ加工してみた](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-545ba5dfbc8fa4c7760dd9872ef835f9/665944e579f487b4434cb289305767b3/aws-glue?w=3840&fm=webp)
[初心者向け] Glue で簡単なデータ加工してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS Glue について実際にどんな使い方がをするのか分からなかったので触ってみました。
今回は、最も簡単と思われる S3 -> Glue -> S3 の構成を試しながら、Glue がどういうものなのか感じてみます。
具体的にやることはソース S3 バケットにある以下の CSV データから device_name カラムを削除し、さらに author カラムの名字と名前の空白を削除し、ターゲットバケットに保存することです。
加工前の CSV ファイル
device_id,device_name,installed_at,author
device1,デバイス1,2022-04-25 12:12:12,山田 太郎
device2,デバイス2,2022-05-15 09:30:45,鈴木 花子
device3,デバイス3,2022-06-03 14:25:33,佐藤 一郎
device4,デバイス4,2022-07-18 11:45:20,田中 美咲
device5,デバイス5,2022-08-22 16:08:55,伊藤 健一
加工後の CSV ファイル
device_id,installed_at,author
device1,2022-04-25 12:12:12,山田太郎
device2,2022-05-15 09:30:45,鈴木花子
device3,2022-06-03 14:25:33,佐藤一郎
device4,2022-07-18 11:45:20,田中美咲
device5,2022-08-22 16:08:55,伊藤健一
(準備) Glue から S3 にアクセスする用の IAM ロールの作成
Glue に付与する IAM ロールを作成します。今回は、Glue から S3 へアクセスするため、S3FullAccess ポリシーがアタッチされた IAM ロールを作成しました。
※今回は、検証のため S3FullAccess をアタッチしていますが、本番環境の場合は適宜権限を絞ってください。
信頼ポリシー
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "glue.amazonaws.com"
},_
"Action": "sts:AssumeRole"
}
]
}
許可ポリシー(AmazonS3FullAccess)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:*",
"s3-object-lambda:*"
],
"Resource": "*"
}
]
}
(準備) S3 バケットの作成
ソースバケットとターゲットバケットの2つをデフォルト設定で作成します。

ソースバケットにテストデータをアップロード
以下のテストデータを作成し、アップロードします。
device_id,device_name,installed_at,author
device1,デバイス1,2022-04-25 12:12:12,山田 太郎
device2,デバイス2,2022-05-15 09:30:45,鈴木 花子
device3,デバイス3,2022-06-03 14:25:33,佐藤 一郎
device4,デバイス4,2022-07-18 11:45:20,田中 美咲
device5,デバイス5,2022-08-22 16:08:55,伊藤 健一
Glue の設定/実行
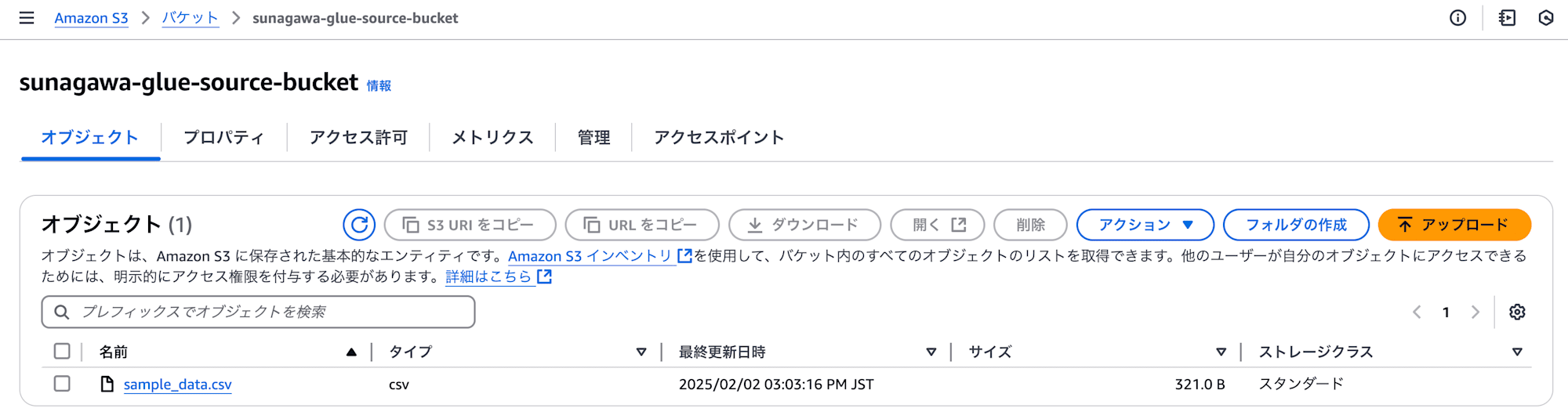
Glue コンソールを開き、左のナビゲーションペインから "ETL jobs" を選び、その後 "Script editor" を選択します。
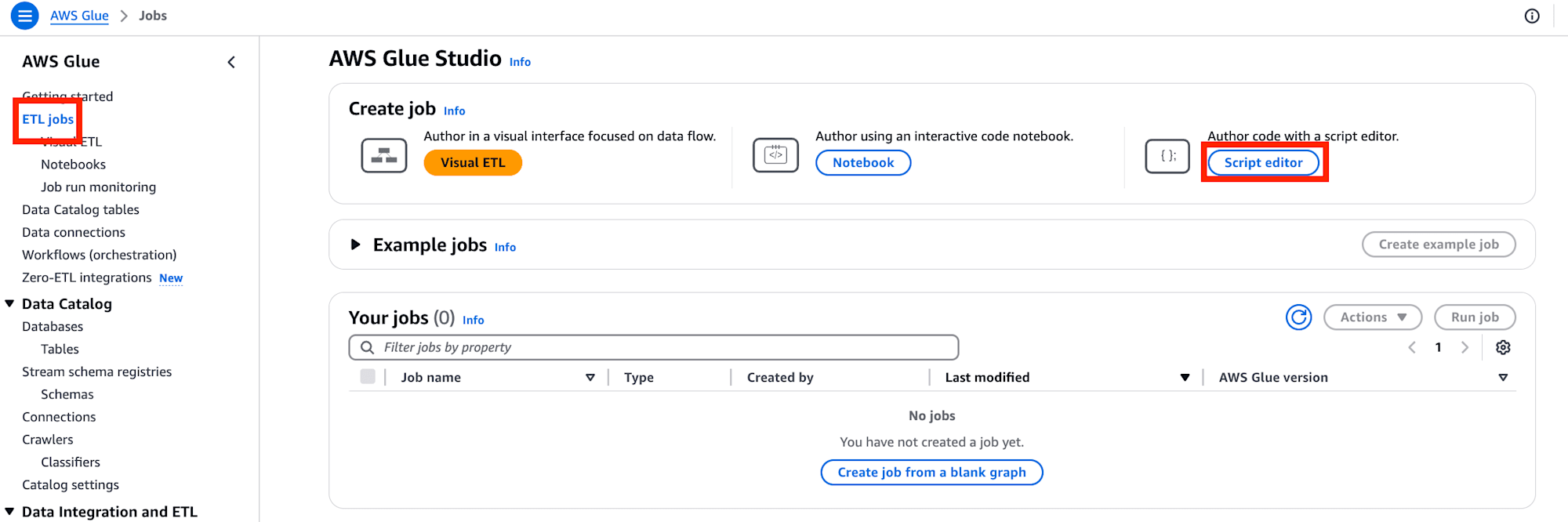
エンジンを "Python shell"、オプションは "Start fresh" とし、右下の "Create script" を実行します。
Job 名を任意の名前に設定し、IAM Role は前項にて作成したロールを選びます。
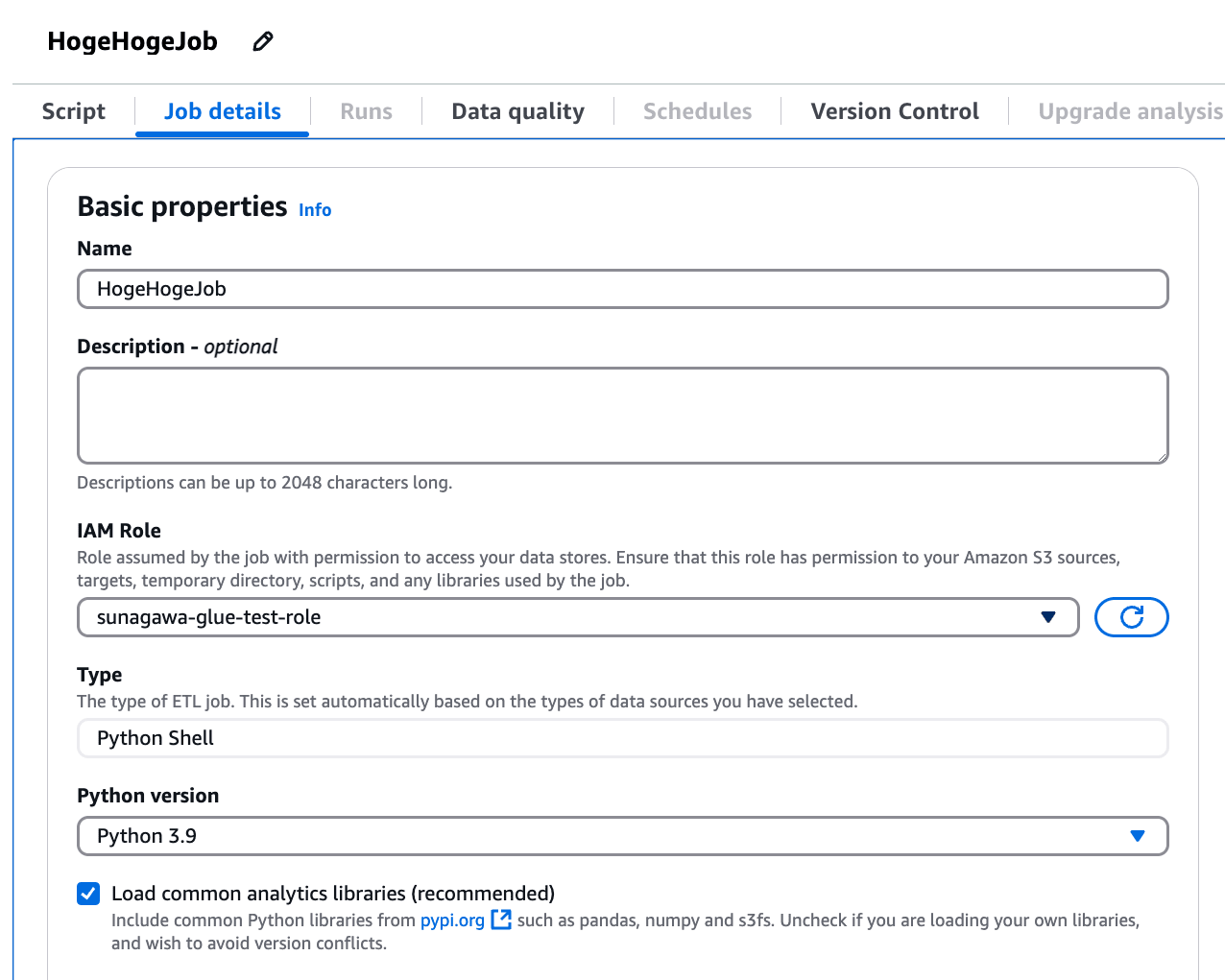
ちなみに "Advanced properties" の項目では、作成する Python Shell スクリプトの保存先 S3 を指定できます。
今回はデフォルトのまま利用しますが、作成するスクリプトの保存先を変えたい方はここから変更してください。
なお、ここで指定されたデフォルトの S3 バケットは新規作成されますため、ご留意ください。

設定ができたら右上の "Save" を実施し、保存します。

Python スクリプトを書く
次に Glue で ETL 処理を実行するための Python スクリプを書きます。
"Script" タブのエディタにコードを書いていきます。

今回作成したスクリプトは以下です。
処理内容としては、ソースバケットからサンプルデータを読み込み、device_name カラムの削除、author カラムの名字と名前の間の空白を削除し、最後にターゲットバケットに書き込むものとなっています。
import pandas as pd
source_file = "s3://sunagawa-glue-source-bucket/sample_data.csv"
target_file = "s3://sunagawa-glue-target-bucket/processed_data.csv"
## 以下、ETL 処理
## Extract(データ読み込み)
test_data_df = pd.read_csv(source_file)
## Transform(変形)
# device_name カラムの削除
test_data_df = test_data_df[["device_id", "installed_at", "author"]]
# author カラムの名字と名前の間の空白を削除
test_data_df["author"] = test_data_df["author"].str.replace(" ", "")
## Load (書き出し)
test_data_df.to_csv(target_file, index=False)
スクリプトを書いたら、右上の "Save" タブよりスクリプトを保存、その後 "Run" でスクリプトを実行します。
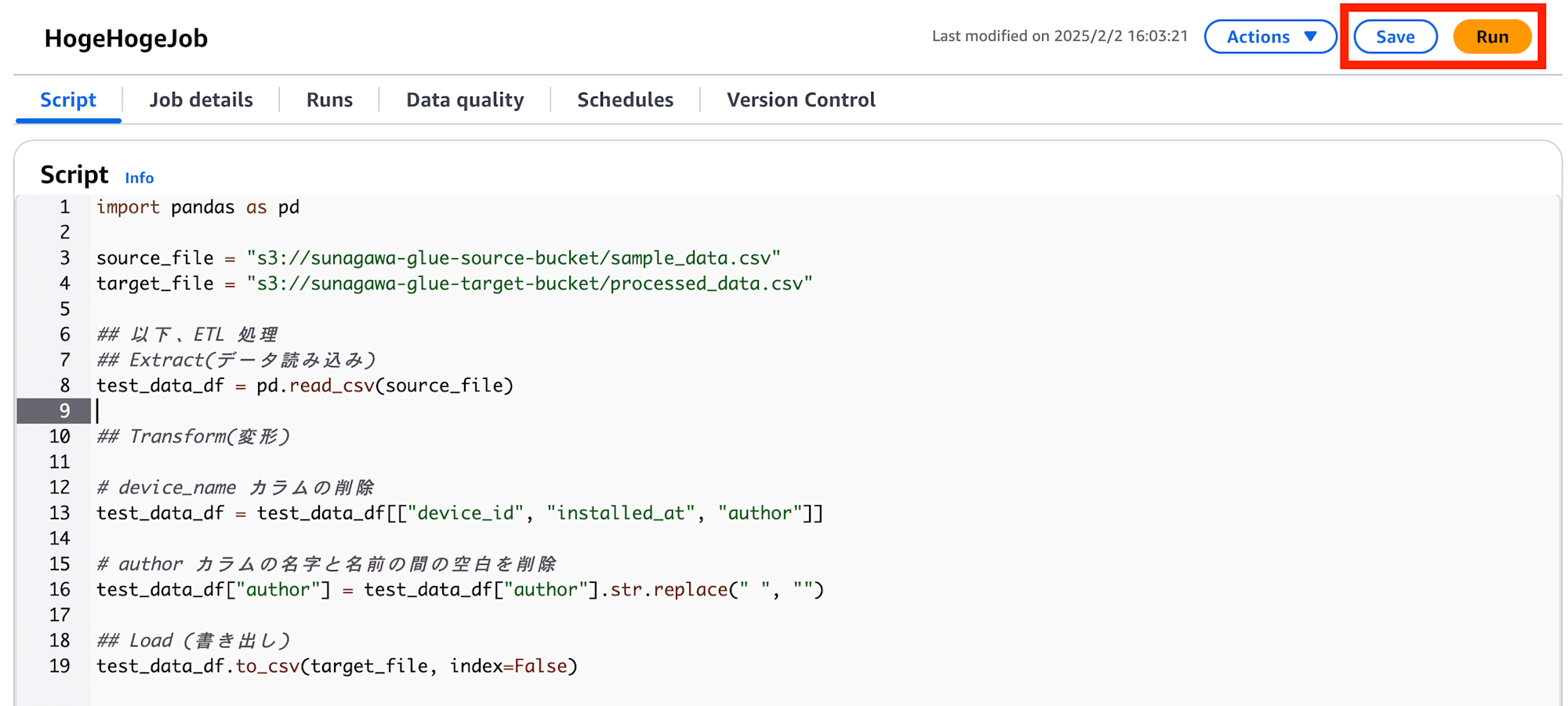
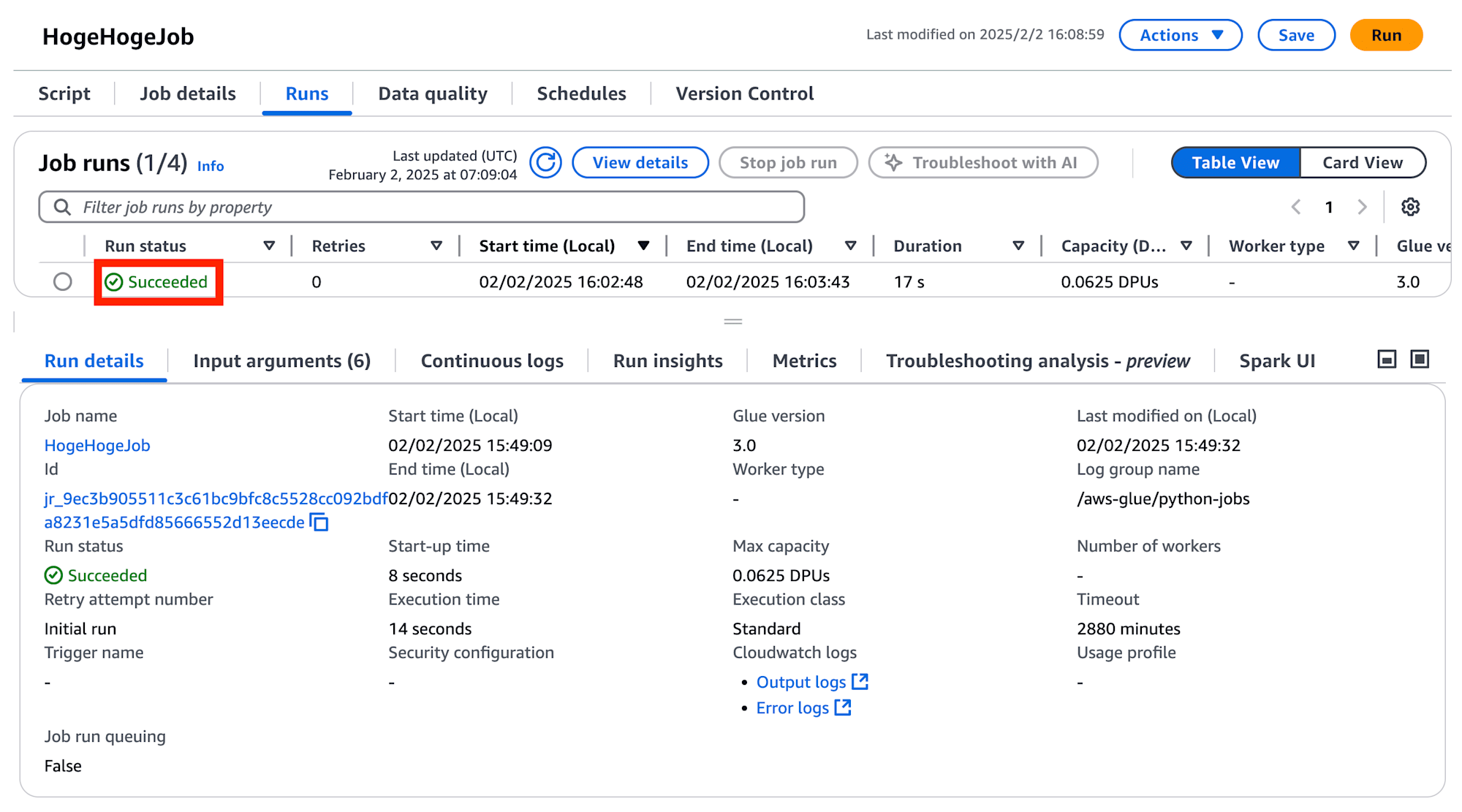
スクリプトを実行したら、"Runs" タブより、実行した Glue Job の詳細を確認できます。
ジョブの Status が Runnning -> Succeeded となれば実行完了です。
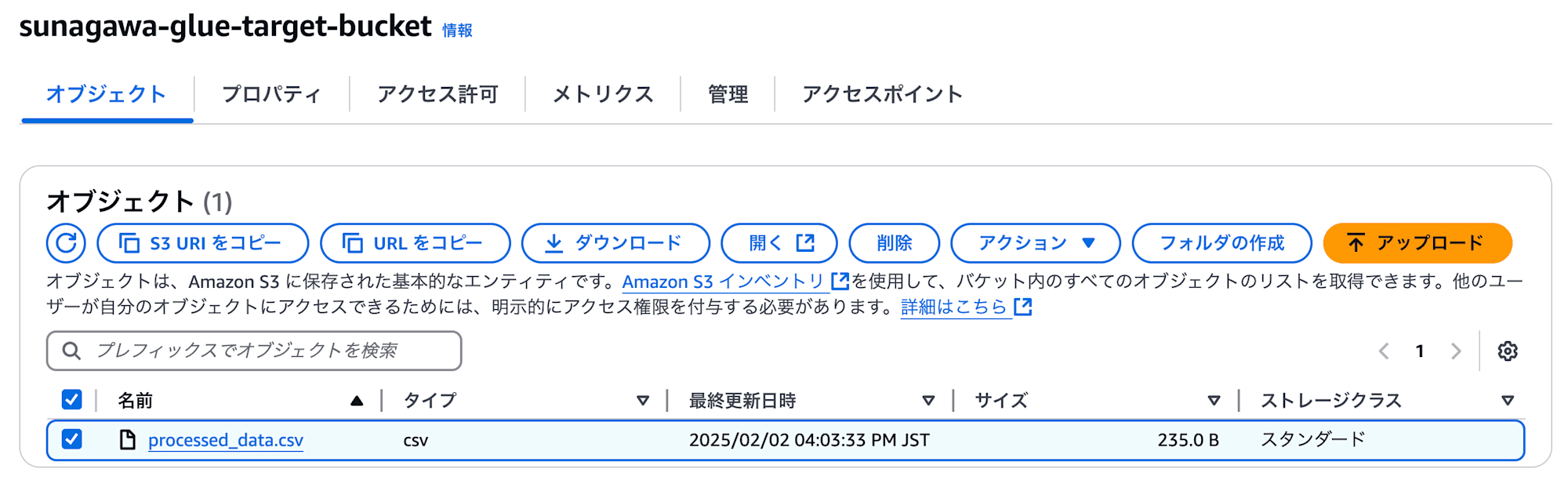
実際にターゲットバケットを見ると、スクリプトで指定した "processed_data.csv" が保存されており、ダウンロードした結果、中身も想定通り(device_name カラムの削除, author の空白削除)となっていることが確認できました。
S3
device_id,installed_at,author
device1,2022-04-25 12:12:12,山田太郎
device2,2022-05-15 09:30:45,鈴木花子
device3,2022-06-03 14:25:33,佐藤一郎
device4,2022-07-18 11:45:20,田中美咲
device5,2022-08-22 16:08:55,伊藤健一
終わりに
今回は、Glue で簡単な ETL 処理を実行してみました。
最初は Glue で ETL ってどういうもの?って思っていましたが Python が書けるのかと驚きでした。
Glue ではその他にもコードを書かずに UI だけで ETL 設定したり、クローラーでデータを持ってきたりと様々なことができるようです。今後少しずつ触っていけたらと思います。
本記事がお役に立てば幸いです。
参考文献









