![[レポート]Engineering Intelligence: Multi-Agent AI Systems for Industrialsに参加してきました #PEX402 #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/4pUQzSdez78aERI3ud3HNg/fe4c41ee45eccea110362c7c14f1edec/reinvent2025_devio_report_w1200h630.png?w=3840&fm=webp)
[レポート]Engineering Intelligence: Multi-Agent AI Systems for Industrialsに参加してきました #PEX402 #AWSreInvent
はじめに
こんにちは、おおはしりきたけです。3回目のre:Invent 2025に参加しております。
今回は、製造業でマルチエージェントをどのように実現しているかが気になったので、本セッションを受けてきました。セッション概要は以下になります。
セッション概要
In this session, discover best practices for modernizing manufacturing applications - such as SCADA, Historian, and MES - and integrating Operational Technology data into an Industrial Data Fabric. Through reference architectures and a live demonstration, we will show examples of how to accelerate data ingestion and contextualization in order to deploy a breadth of analytics and agentic capabilities to deliver outcomes such as improved process quality, cost productivity, and machine reliability.
日本語訳
スケーラブルなマルチエージェントAIアーキテクチャの実装について深く掘り下げる、エキスパートレベルの講演にぜひご参加ください。AWSパートナーによる実際の実装事例を通して、MCP、Strands Agents SDK、Amazon Bedrock AgentCoreを活用したAmazon Bedrockを用いたインテリジェントシステムの構築とオーケストレーションの方法をご紹介します。このテクニカルセッションでは、プロセス最適化とロール固有のタスク分散のための繰り返し可能なマルチエージェントパターンを探求し、ソフトウェアソリューションやコンサルティング業務の強化を支援します。顧客向けに高度なAIシステムを構築するために適用できる、アーキテクチャのベストプラクティスとPOCから本番環境実装戦略までをご紹介します。本番環境でマルチエージェントフレームワークを活用したいと考えているパートナー、アーキテクト、開発者に最適です。
登壇者
- Raja GT, WW Senior Solutions Architect, Manufacturing, Amazon Web Services
- Shing Poon, Senior Technical Account Manager, Amazon Web Services Australia Pty Ltd
- Gokul Bala, Global AWS Services Director, Crayon | AWS Ambassador
セッション内容
本セッションは、製造業および産業界が直面するAI導入の課題に対し、いかにしてスケーラブルで堅牢なマルチエージェントシステムを構築し、本番環境に展開するかを示す、専門家レベルの実践的な解説でした。
1. 産業用AIの根本的な課題
産業界のデータ環境は、AIエージェントの能力を制限する根本的な課題を抱えています。
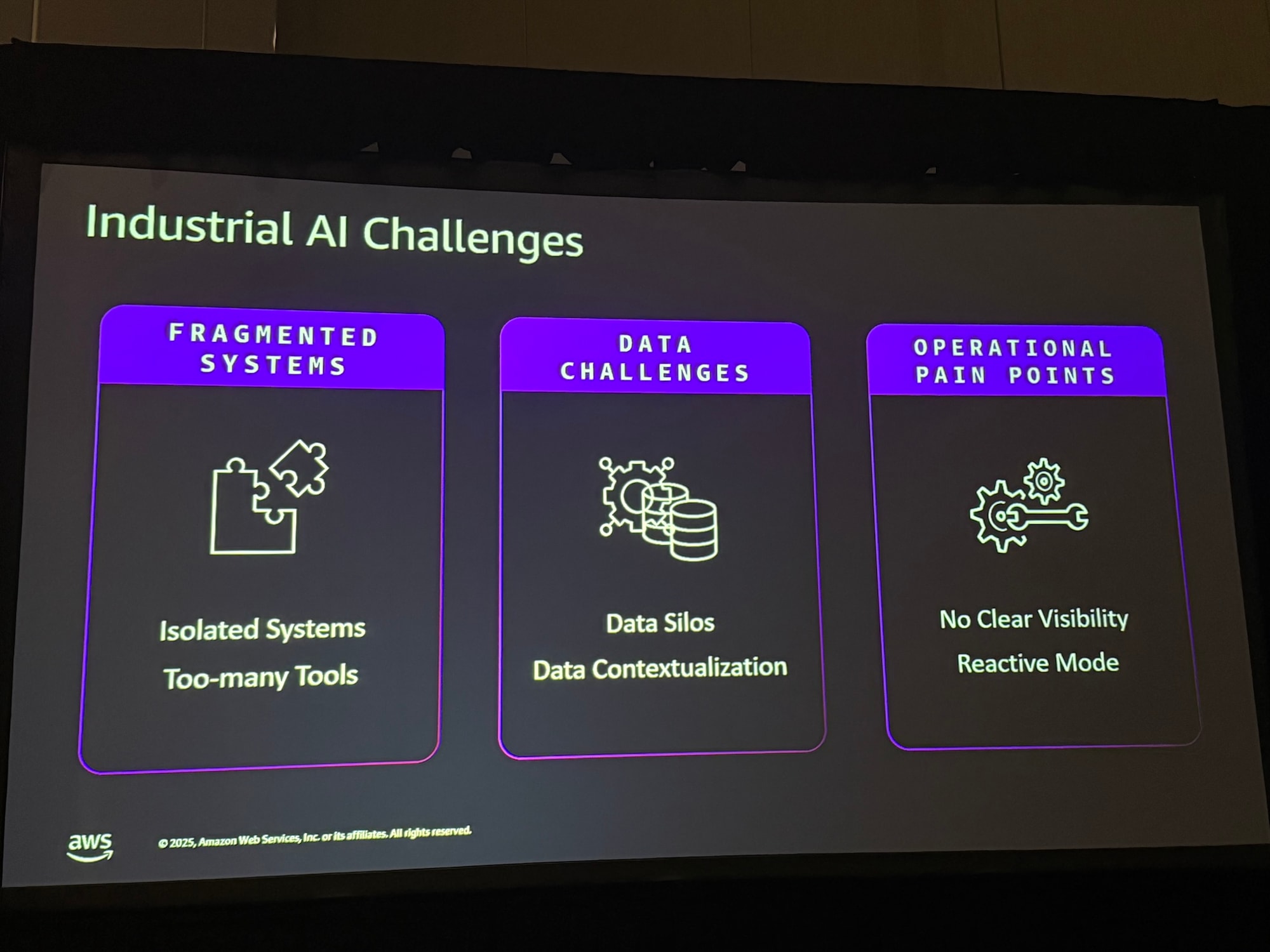
課題1:システムの断片化とデータサイロ
ERP、MES、CMMSなど多数のシステムが隔離されており、データがサイロ化しています。エージェントの性能は、その基盤となるデータの品質とコンテキストに完全に依存します。そのため、コンテキスト情報が不足したデータに基づいたエージェントの推奨は、誤った判断や悪い結果につながり、最終的にシステムへの信頼を失うことになります。
課題2:単一エージェントの限界
単一のエージェントに多くの機能を持たせようとすると、複雑さが指数関数的に増加し、開発の複雑化、単一障害点、そしてメンテナンスの悪夢を引き起こします。
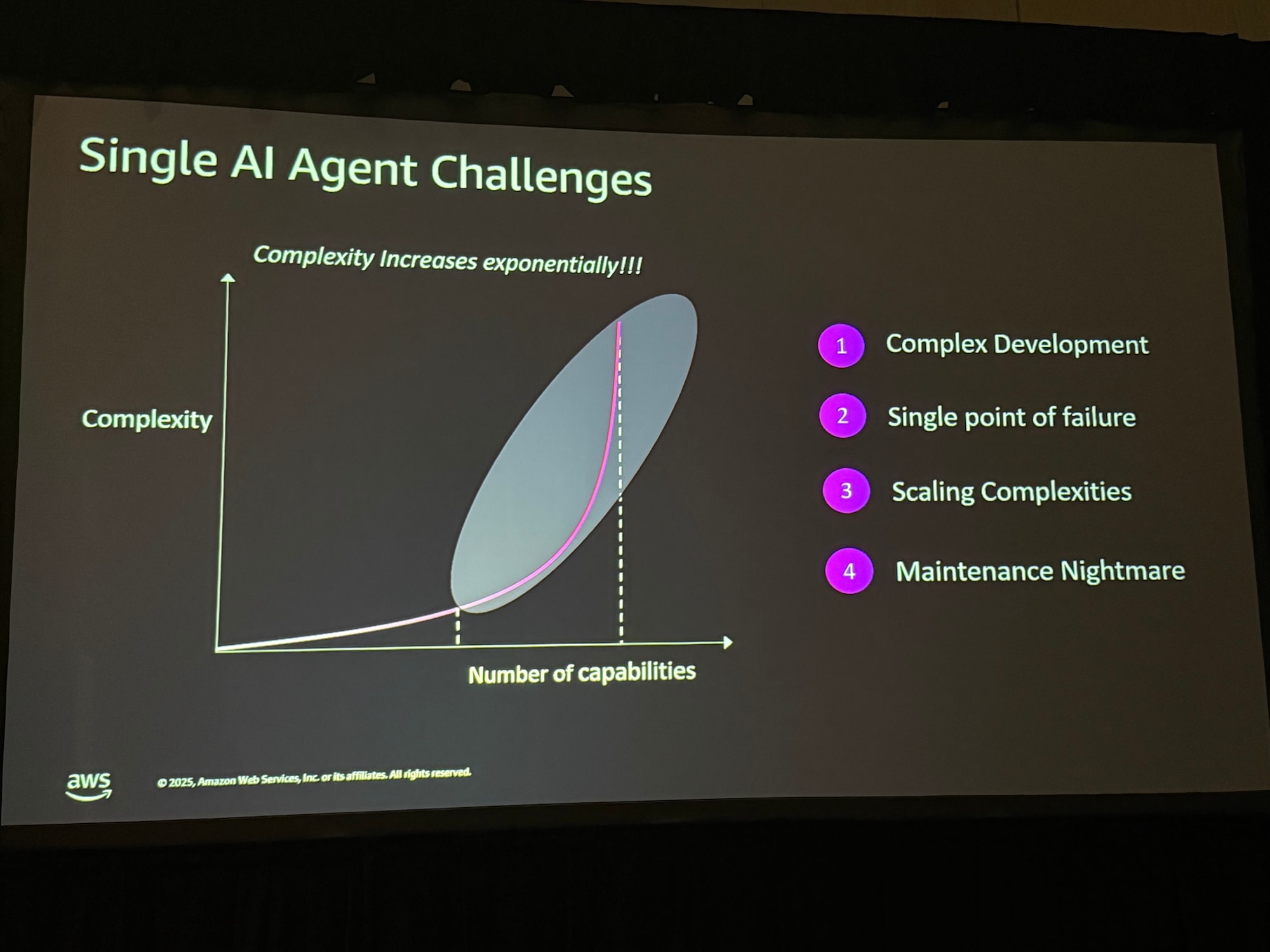
セッションでは、上記課題への解決策として、単一の包括的な「ジェネラリスト」ではなく、役割に特化した複数のエージェントが連携して動作するマルチエージェントアーキテクチャへの移行が提唱されていました。
2. POCから本番環境への移行を導く7ステップアプローチ
マルチエージェントシステムを成功裏に構築し、ビジネス価値を最大化するためには、体系的なアプローチが不可欠です。設計、実装、デリバリーの3つのフェーズからなる7つのステップが、その標準的なフレームワークとして提示されました。
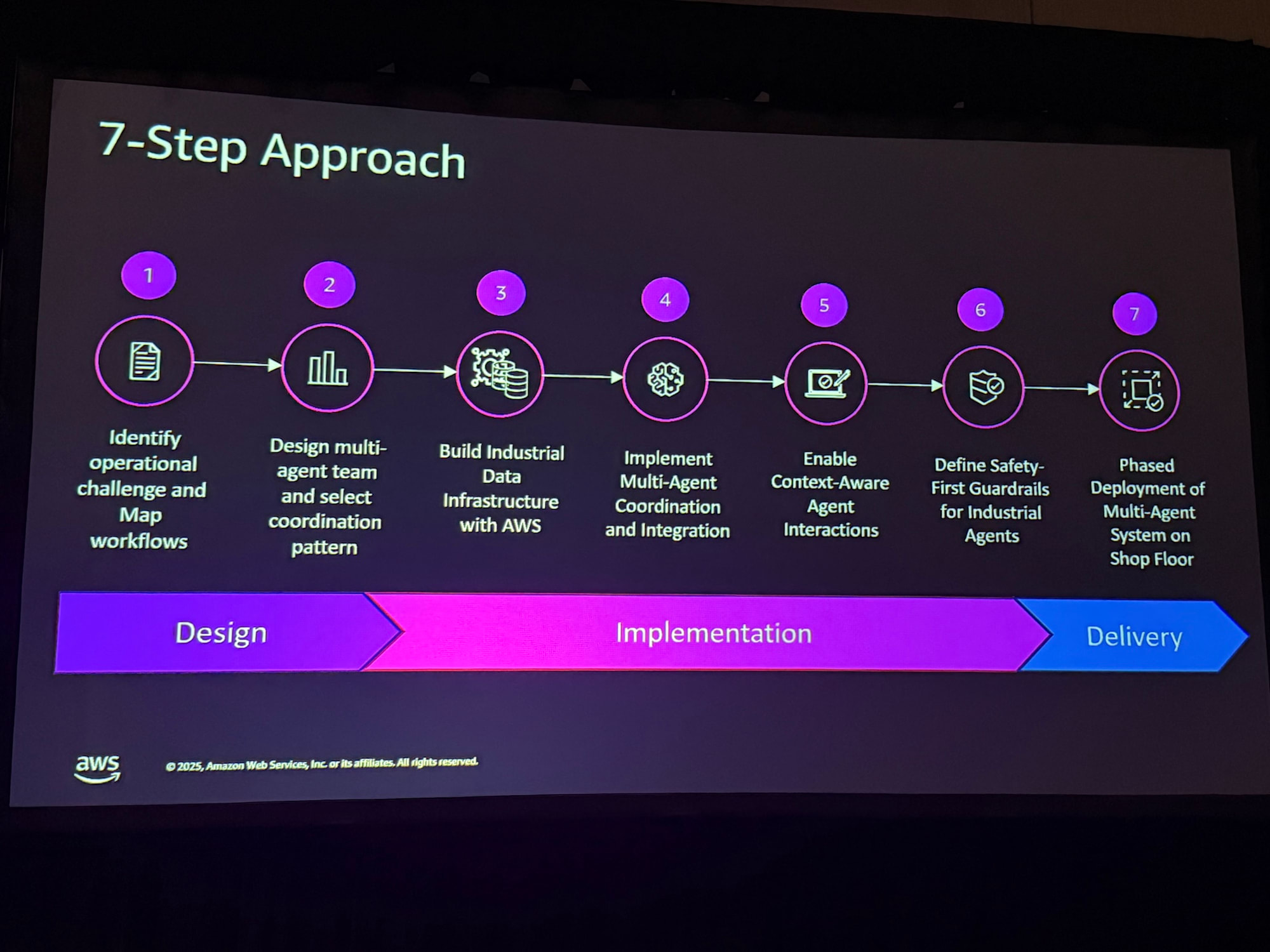
この7ステップアプローチは、単なる技術実装を超え、ビジネスプロセスのマッピングからセキュリティ設計、段階的展開に至るまでをカバーする、本番環境への移行を保証するためのロードマップとして、最も重要な成果と言えます。
【デザインフェーズ】
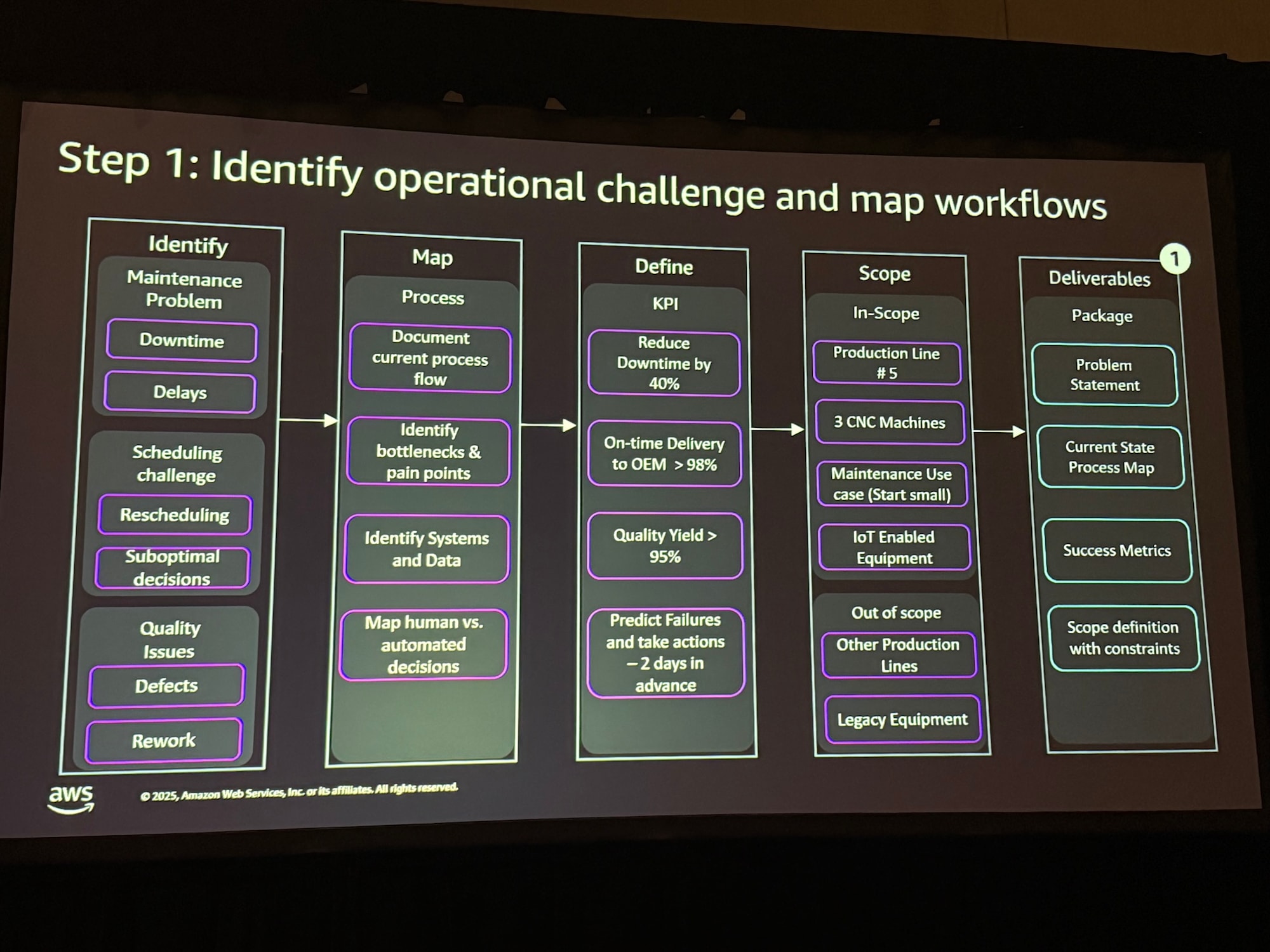
Step 1: 運用上の課題を特定し、ワークフローをマッピング
この最初のステップでは、プロジェクトの基盤を確立します。KPIを明確に定義し、インスコープ/アウトスコープを規定することで、スモールスタートための範囲を確立します。
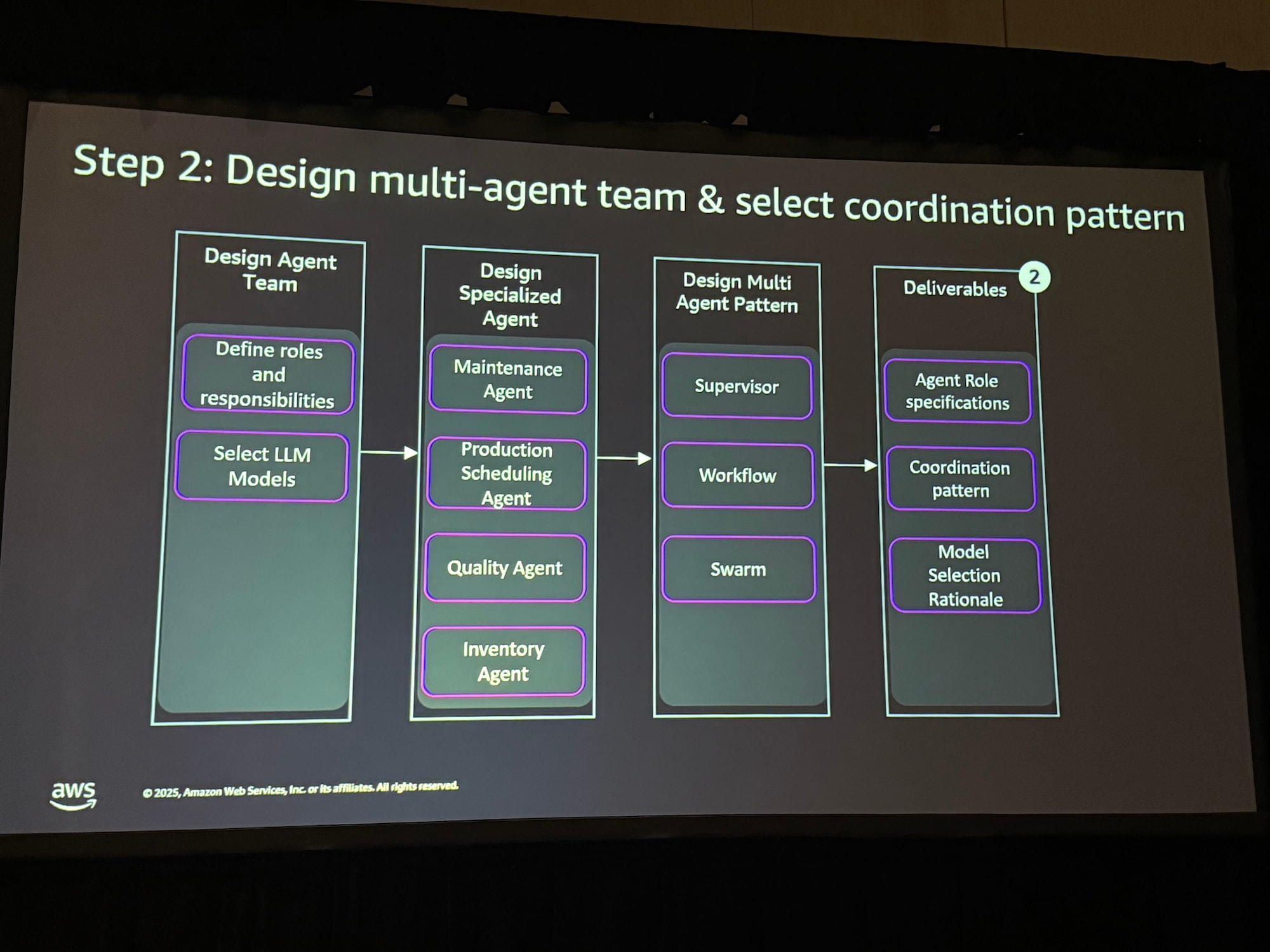
Step 2: マルチエージェントチームを設計し、調整パターンを選択
ここでは、システム全体の構造を定義します。メンテナンス、品質、在庫など専門化されたエージェントの役割と責任を定義し、スーパーバイザー、ワークフロー、スウォームなどの調整パターンを選択します。
【実装フェーズ】
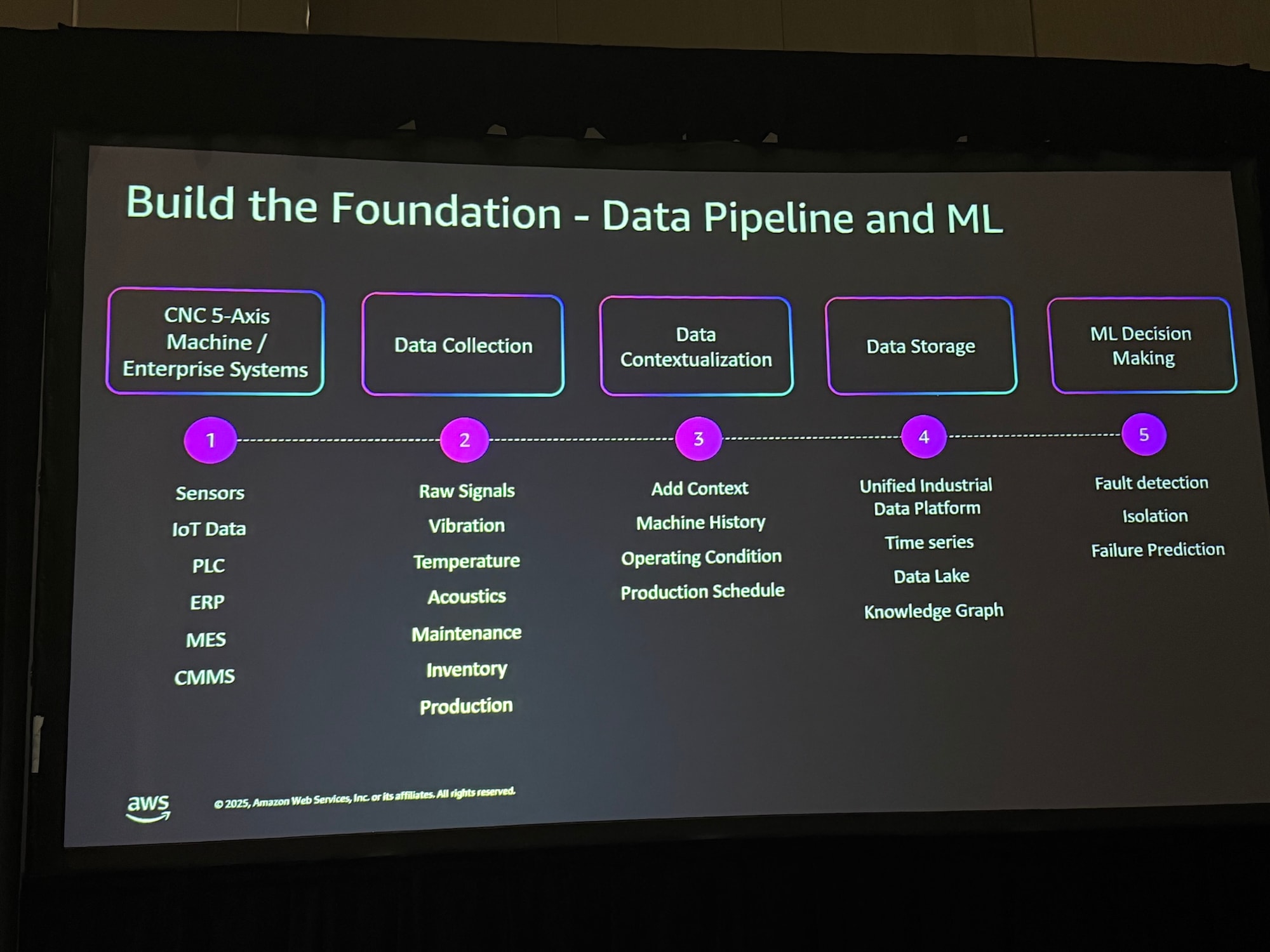
Step 3: 産業用データインフラストラクチャを構築
AIエージェントのインテリジェンスの源となるデータ基盤を構築します。ERP、CMMS、IoTデータなどを統合し、時系列データ、データレイク、コンテキストナレッジグラフを含む統一された産業用データプラットフォームを構築します。
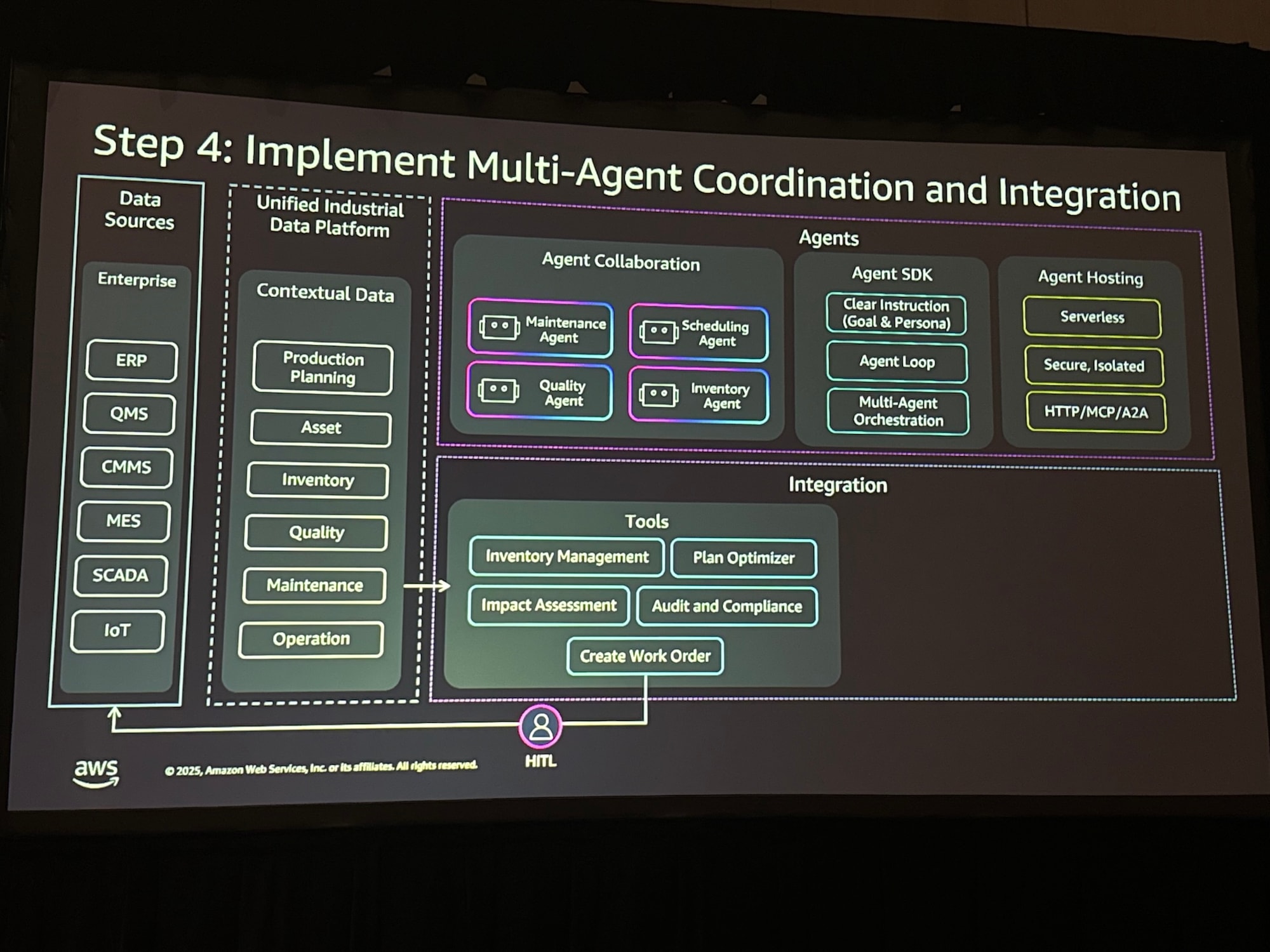
Step 4: マルチエージェントの調整と統合を実装
ここでは、設計された専門エージェントを実際に構築し、連携させます。Amazon Bedrock AgentCoreやStrands Agent SDKを活用し、エージェント間の協調的なワークフローと、外部システムへのツール統合のレイヤーを実装します。
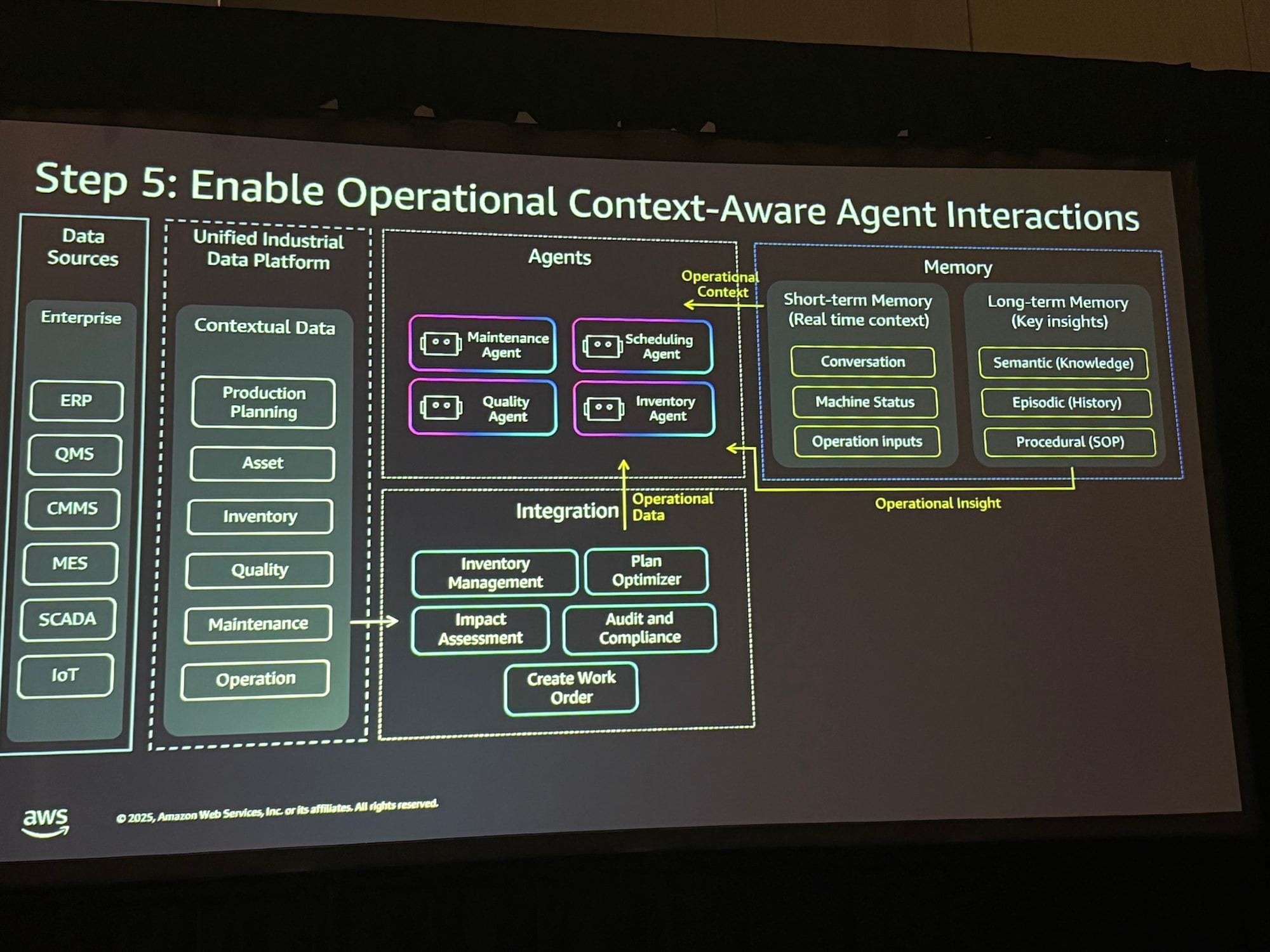
Step 5: コンテキストアウェアな相互作用の有効化
エージェントが状況を理解し、ステートフルな運用を行うためのメモリ機構を実装します。短期記憶と長期記憶を用いて、リアルタイムの運用状況を踏まえた意思決定を可能にします。
- 短期記憶:会話、リアルタイムコンテキスト
- 長期記憶:運用手順、履歴などの知識
Step 6: セーフティファーストのガードレールを定義
人命やクリティカルなシステムを扱う産業界において必須のステップです。プロンプトインジェクション保護、セッション隔離、アクセス制御に加え、Human-in-the-Loopを含めた多層的なセキュリティとガバナンスを適用します。この多層防御には、GenAIコンテンツ保護と一般システム保護が含まれます。

【デリバリーフェーズ】
Step 7: 現場でのマルチエージェントシステムの段階的展開
プロジェクトの最終段階です。専門家の検証と承認を得た後、ブルー/グリーンデプロイメントなどの戦略を用いて、段階的かつ安全に本番環境に展開し、継続的な監視と改善を行います。
7ステップアプローチのAWSリファレンスアーキテクチャ
7ステップアプローチにおいて、特に実装フェーズを完了することで実現される、Amazon Bedrockを核とした産業用マルチエージェントシステムの完全なリファレンスアーキテクチャが示されました。
この図は、データプラットフォーム、エージェントコア、統合、セキュリティ、オブザーバビリティの各要素がどのように連携するかを示しています。

3. 顧客成功事例とビジネス価値
Crayonによるエネルギー会社のメンテナンスサービス事例では、この7ステップアプローチの有効性が証明されました。
課題
- 複雑な製品クエリやメンテナンスサービス対応において、以下の課題を抱えていました。
- 応答に45分以上の長時間を要していた
- SMEへのエスカレーションが頻繁に発生し、対応のボトルネックとなっていた
- 必要な手順や知識が複数のシステムに散在しており、問い合わせごとに手動で情報を探し、統合する必要があった
- 対応プロセスが標準化されておらず、対応品質にばらつきが生じていた。
解決したソリューション
この課題に対し、同社は7ステップアプローチに基づき、マルチエージェントアーキテクチャを採用しました。
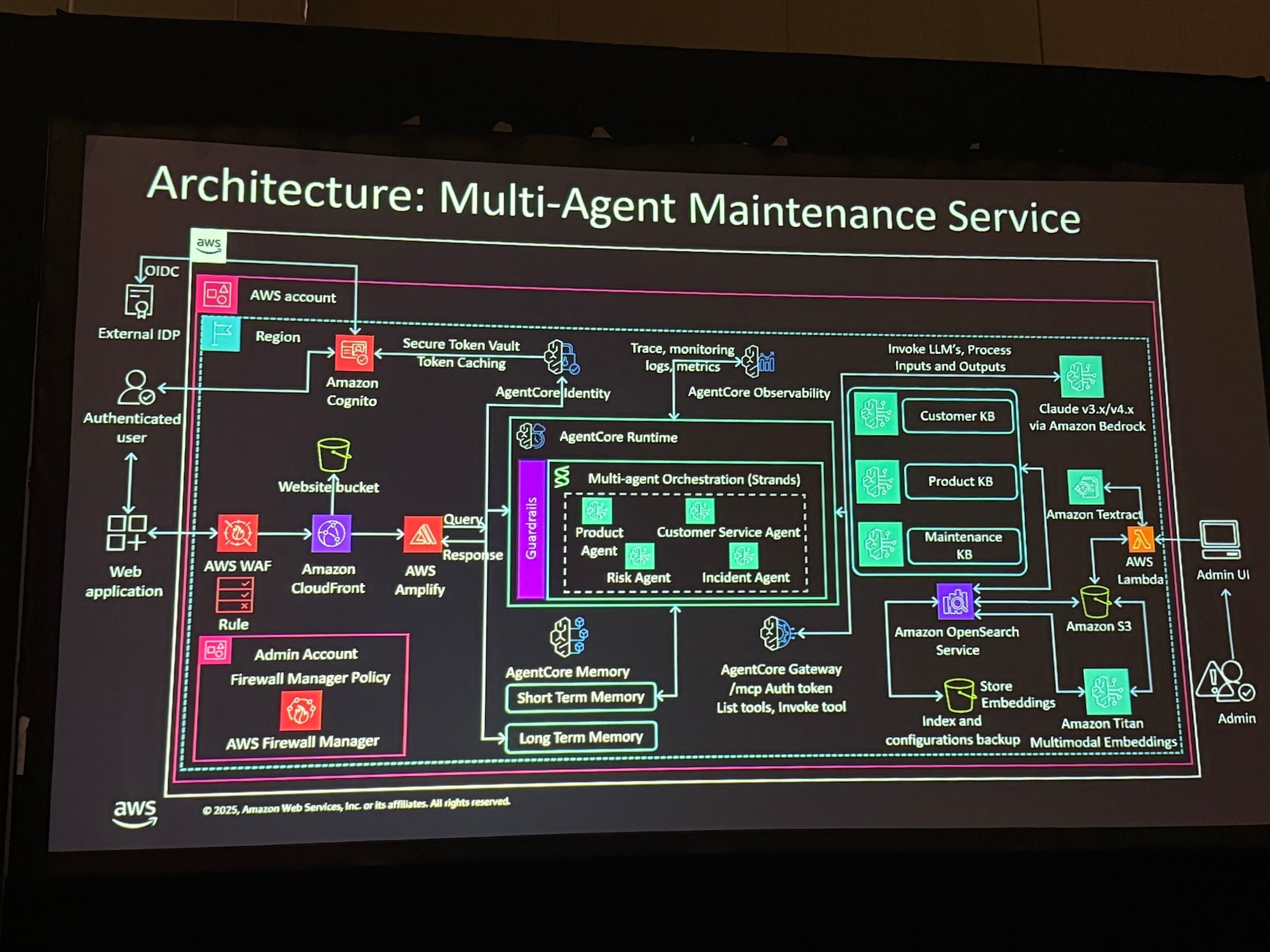
- 専門エージェントの配置
- 全体を調整するOrchestrator Agentの下に、Product Agent、Customer Service Agent、Risk Agent、Incident Agentといった役割を専門化した複数のエージェントを配置しました。
- 複数のナレッジベースの活用
- 各エージェントが複数のAmazon Bedrock Knowledge Baseにアクセスし、専門的な知識に基づいて迅速かつ正確に対応できる仕組みを構築しました。
- **ヒューマン・イン・ザ・ループ(HITL)
- 高リスクなアクションについては、人間による承認(HITL)を必須としました。
結果
- 複雑な製品クエリの解決時間が、専門家(SME)の介入なしで5分未満に短縮された。
- 全体の応答時間とエスカレーション回数が80%削減され、オペレーションの効率が大幅に向上した。
- エージェントシステムへの信頼性を確保するため、プロセス変更管理とHITLを組み合わせて導入した。
4. Q&A
チョークトークなので、セッションの質疑応答がありました。
-
Q エージェントの知識を最新に保つには、どのようなメモリ管理のベストプラクティスがあるか?
- A エージェントが運用中に得た「経験」そのものを理解し、それを運用標準手順(SOP)と経験の両方として長期記憶にキャプチャすることが推奨される。これにより、単なるドキュメント情報だけでなく、包括的で実用的な知識を持つことができる。
-
Q クロスエージェントコラボレーションを行っているエージェントを識別し、アクセスを制御するにはどうすればよいか?
- A エージェント間のコラボレーションは、エージェントSDKによって役割が定義される。各エージェントは明確な役割定義と独自のIDを持つため、長期記憶内での識別が可能。アクセス制御は、IAMサービスからのデータを使用し、必要なトークンと許可が整っていることを確認することで、セーフティファーストの原則の下で実行される。
5. 感想
本セッションは、技術的な理論に留まらず、産業界のAI導入における最も現実的な課題(データサイロ、単一障害点などなど)と、それに対する実践的な解決策を提示してくれた点で非常に価値がありました。
特に印象的だったのは、「マルチエージェントシステムの構築とスケーリングのための7ステップアプローチ」が、単なる技術的なガイドラインではなく、POC(概念実証)からROI(投資対効果)を伴う本番展開に至るまでのプロジェクト管理フレームワークとして機能している点です。Step 1でのKPI定義とスコープ設定から始まり、Step 6でのセーフティファーストのガードレール、そして段階的展開(Step 7)まで、体系的にリスクと複雑性に対処していることがよく理解できました。
この7ステップアプローチこそが、複雑な産業用AIプロジェクトを成功に導くための不可欠な設計原則であると強く感じました。
AIがよろしくやってくれるということは幻想で、地道にデータを正しくまとめ、業務プロセスを整備し、そこからAIにどのような専門性を与えて動いてもらうかというビジョンがないとAiエージェントをコントロールすることはできないのだなと改めて感じました。









