
DevOps Agent Skillsの精度を評価するためのワークフローをStep Functionsで構築してみた
リテールアプリ共創部@大阪の岩田です。
DevOps Agentはとても便利なサービスですよね?
雑に調査を投げるだけでも色々と気を利かせて調べてくれる賢い子なのですが、DevOps Agent Skills(以降スキルと表記します)を整備することで、さらに調査の精度や効率が改善できます。また、スキルは適当に作成すれば良いというものではなく、DevOps Agentやプロンプトエンジニアリングのベストプラクティスに沿った形でスキルを作成することで効果が大きくなります。
そのため、スキルの書きっぷりをどう調整すれば最大限の効果が出るのか試行錯誤が重要になるのですが、スキルを書いてはテストし、またスキルを微調整し...を繰り返すのは骨の折れる作業です。これをうまく自動化するために、Step Functionsを活用したスキル評価のワークフローを構築してみたので、内容をご紹介します。
以降で紹介するコードはすべて以下のURLで公開しています。コード全体は解説しないので、詳細を確認したい場合はこちらをご参照ください。
注意点
概要
以下のようなワークフローを作ります。
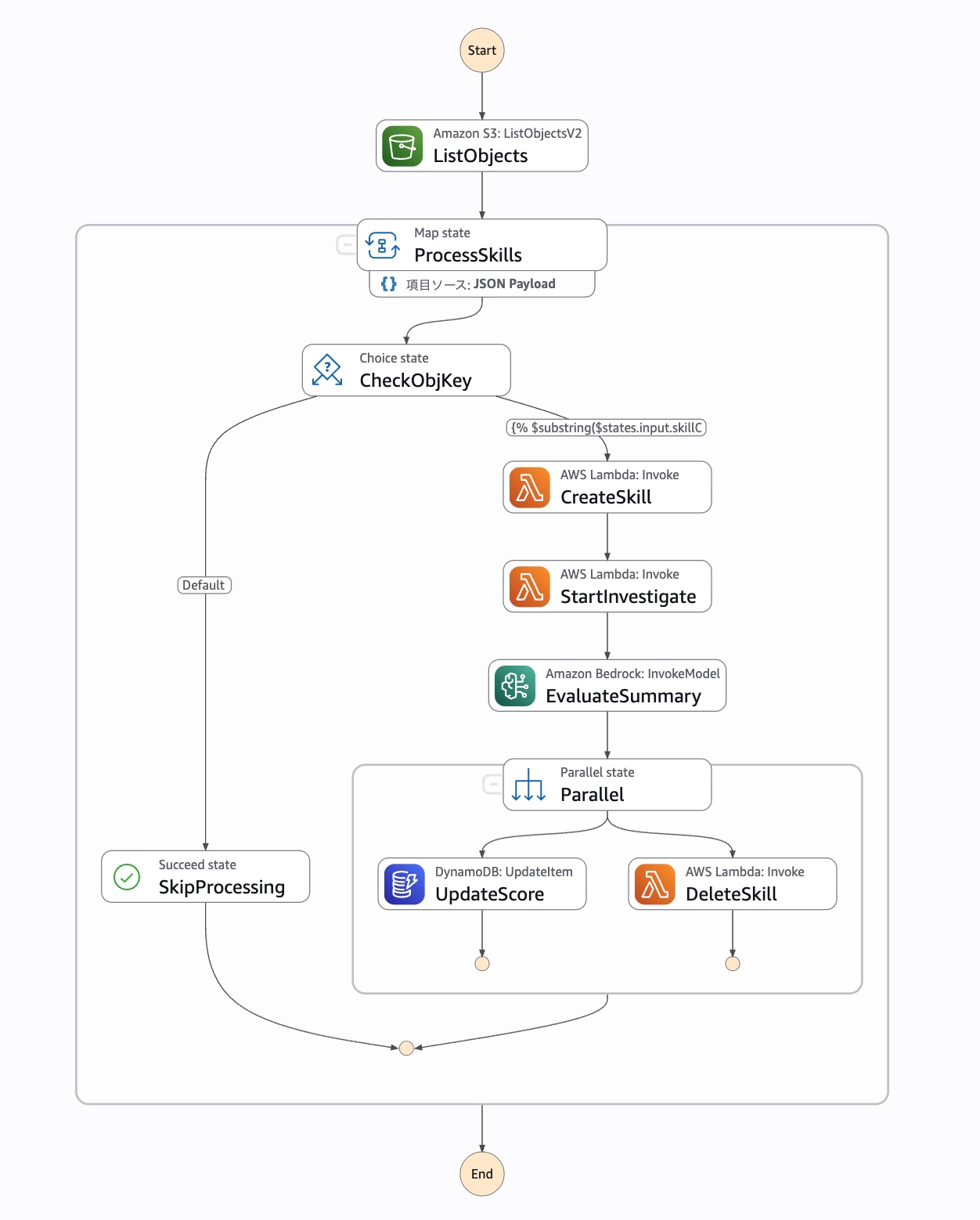
ワークフローの流れは以下の通りです。
- ListObjects: S3バケットからスキルの一覧を取得
- ProcessSkills: 取得した全スキル分ループしながら以下の処理を実行
- CreateSkill: スキルを作成し、DynamoDBに管理用のアイテムをPutItem
- StartInvestigate: 調査の開始
- EvaluateSummary: DevOps Agentの調査結果をBedrock(Sonnet-4.6)で評価し、スコアを付ける
- Parallel: 以下の処理を並列実行
- UpdateScore: EvaluateSummaryの評価結果をDynamoDBに保存
- DeleteSkill: CreateSkillで作成したスキルを削除
ワークフローが終了するとDynamoDBに以下のような情報が記録されています。

各属性には以下の情報が保存されているため、どのスキルが最も優秀だったか判断できます。
- skillObjKey: S3に保存しておいたスキルのオブジェクトキー
- score: Bedrock(Sonnet-4.6)が評価したDevOps Agentの調査結果のスコア
- scoreReason: Bedrock(Sonnet-4.6)が上記の値にスコアリングした理由
また、AIによるスコアリングだけだとハルシネーションの懸念もあるためinvestigationSummaryという属性にDevOps Agentの調査結果を保存しています。この属性を参照することで人間による判断や補正も可能です。
このワークフローを使うと、スキルの書きっぷりによってどのようにDevOps Agentの調査結果が変わるかを簡単に分析できるようになります。
解説
ここからはワークフローの要点に絞って解説していきます。前述の通りソースコード全体を確認したい場合はGitHubのリポジトリを参照してください。
boto3でエージェントスペースの各種操作を可能にする
DevOps Agentのエージェントスペース上での各種操作は通常AWS CLIやboto3では実現できません。
が、以前以下のブログで紹介したようにbotocoreのサービス定義ファイルを自前で作成すればAWS CLIやboto3からもaidevopsのAPIエンドポイント https://aidevops.<リージョン>.api.aws にリクエストを発行できます。
これを実現しているのが以下ファイルです。
これらのファイルをLambda Layerとしてデプロイし、ワークフロー内で読み出す各種Lambdaの環境変数AWS_DATA_PATHに/optを指定することでLambdaのコードがboto3でaidevopsのクライアントクラスを作成できるようにしています。
スキルの作成
スキルの作成はCreateSkillのStepで実行します。
サービス定義ファイルさえ準備できていれば特に難しいことはありません。contentのvalueにZIPファイルのバイナリデータを渡す必要があるので、s3.get_object(Bucket=bucket_name, Key=skill_obj_key)['Body'].read()の結果をそのまま渡しているぐらいです。
スキルが作成できたら後続処理の連携用にDynamoDBにPutItemしておきます。
DevOps Agentで調査の開始
調査の開始はStartInvestigateというStepで実行します。ポイントは調査に時間がかかるため、タスクの定義でlambda:invoke.waitForTaskTokenを指定して非同期実行としていることです。
これもLambdaからboto3を使って実行します。
APIのレスポンスから調査のタスクIDなどが返却されるので、これらの情報でDynamoDBのアイテムを更新しておきます。調査が終了するとEventBridgeにイベントが発行されるので、これをトリガーにStepを終了できるようStepのタスクトークンを保存しておくのがポイントです。
調査の終了
前述の通り調査の開始は非同期実行としているため、後続ステップに処理を進めるには調査完了をトリガーにsend_task_successしてやる必要があります。以下の指定でEventBridgeに発行されたイベントをトリガーにLambdaを起動するようにしています。
※本来はエージェントスペースIDの条件も追加した方がいいですが、省略しています。
イベントをトリガーに起動したLambda側での処理概要は以下の通りです。
調査結果のサマリーを取得し...
DynamoDBに保存
send_task_successして後続ステップの実行を継続
DevOps Agentの調査結果を評価
ここまででDevOps Agentの調査結果が取得できたので、調査結果をBedrockに渡して妥当性をチェックしてもらいます。
以下の通りシステムプロンプトを指定し、1.0 ~ 10の範囲でスコアリングするよう指示しています。
出力が確実にJSON形式になるようoutput_configでjson_schemaも指定しています。
後処理
調査結果のスコアリングが終わったらDynamoDBのサービス統合でUpdateItemを実行し、スコアリング結果とその理由をDynamoDBに保存します。
合わせて次のループに備えて作成したスキルを削除するためのLambdaを呼び出します。
後処理が終わったら次のループを実行、全スキル分ループすればワークフロー全体も終了になります。
ループする部分はMapを利用しているのですが、MaxConcurrency: 1を指定しているので実質ループしながらの直列実行となります。
MaxConcurrencyを2以上にしてしまうと同時に複数の調査が起動してスキルの使い分けができなかったり、調査自体がリンクされたりと、複数のスキルを比較するという目的が実現できなくなってしまうためです。
やってみる
概要は説明できたので、ここからは実際にワークフローを起動してスキルの優劣を比較してみましょう。今回は以前のブログでも試したサンプルと同様にLambdaのログにベリトランスのクレジットカード決済に関するログを出力し、このログの原因等をDevOps Agentに調査させてみます。ログはこんな感じです↓
2026-05-01T06:04:59.896Z d2ae9523-54be-4877-9a62-09d52a7c878b ERROR クレジットカード決済処理でエラーが発生 mdkLogger.INFO: response data ==>
{
"payNowIdResponse": {
"account": {
"accountId": "12345678"
},
"message": "リクエストされたカード情報について決済センターとの確認に失敗しました。有効性確認時の結果コード:AG41",
"processId": "6476521515",
"status": "failure"
},
"result": {
"vResultCode": "XH41000000000000",
"merrMsg": "リクエストされたカード情報について決済センターとの確認に失敗しました。有効性確認時の結果コード:AG41",
"mstatus": "failure",
"serviceType": "cardinfo",
"txnVersion": "2.0.0"
}
}
[] []
DevOps AgentはベリトランスのAPI仕様について詳しく知らないので、この情報を補完できるようなスキルを3パターン作成し、各スキルを比較してみます。
スキル1 適当な内容
まずは1つ目のスキルです。以下の内容でSKILL.mdを作成しました。
---
name: credit-card-payment-error-log-investigation
description: Use this skill when investigating error logs related to credit card payments.
---
このシステムは外部のサービスを使ってクレジット決済を行っている。
外部サービスからエラーが返却された場合はエラーログが出力される
すごく適当ですね...
いかにも役に立たなさそうなスキルです。
スキル2 ある程度詳細に言及した内容
続いて2つ目のスキルです。以下の内容でSKILL.mdを作成しました。
---
name: credit-card-payment-error-log-investigation
description: Use this skill when investigating error logs related to credit card payments.
---
このシステムはベリトランスのAPIを使ってクレジット決済を行っている。
ベリトランスからエラーが返却された場合はエラーログが出力される
## ベリトランスエラーログの仕様
エラーログは以下のような構造を持つ
```
mdkLogger.INFO: response data ==> {"payNowIdResponse":{"account":{"accountId":"12345678"},"message":"リクエストされたカード情報について決済センターとの確認に失敗しました。有効性確認時の結果コード:AG41","processId":"6476521515","status":"failure"},"result":{"vResultCode":"XH41000000000000","merrMsg":"リクエストされたカード情報について決済センターとの確認に失敗しました。有効性確認時の結果コード:AG41","mstatus":"failure","serviceType":"cardinfo","txnVersion":"2.0.0"}} [] []
```
- vResultCode:
- 16桁の処理結果コードです。
この処理結果コードは、4桁を基本単位としており、最大4つまで同時に処理結果を表現します。
それぞれの4桁のコードは、MStatusをより細分化した処理結果コードになる。
16桁を4桁ずつ4ブロックに分割し、第1ブロックを決済処理結果、第2ブロックから第4ブロックまでをオプションとする。
## 処理結果コード一覧
| MStatus | VResultCode | デフォルトメッセージ | 英語メッセージ | 説明 | 想定される原因 | 発生した場合の対処例 |
| ------- | ----------- | ------------------------------------------------------------ | -------------- | -------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
| failure | XH41 | リクエストされたカード情報について決済センターとの確認に失敗しました。有効性確認時の結果コード:{0} | - | 内部与信エラー | 「[5. カード](https://www.veritrans.co.jp/docs/mdk_guide/result_list.html#section5)」を参照してください。 | 「[5. カード](https://www.veritrans.co.jp/docs/mdk_guide/result_list.html#section5)」を参照してください。 |
スキル1と比較してだいぶ情報量を増やしましたが、「有効性確認時の結果コード」については特に記載せず外部リンクを参照するよう記載しています。
スキル3 一番詳細に言及した内容
最後に3つ目のスキルです。以下の内容でSKILL.mdを作成しました。
---
name: credit-card-payment-error-log-investigation
description: Use this skill when investigating error logs related to credit card payments.
---
## ベリトランスエラーログ調査の手順
このシステムはベリトランスのAPIを使ってクレジット決済を行っている。ベリトランスからエラーが返却された場合はエラーログが出力される
## ベリトランスエラーログの仕様
エラーログは以下のような構造を持つ
```
mdkLogger.INFO: response data ==> {"payNowIdResponse":{"account":{"accountId":"12345678"},"message":"リクエストされたカード情報について決済センターとの確認に失敗しました。有効性確認時の結果コード:AG41","processId":"6476521515","status":"failure"},"result":{"vResultCode":"XH41000000000000","merrMsg":"リクエストされたカード情報について決済センターとの確認に失敗しました。有効性確認時の結果コード:AG41","mstatus":"failure","serviceType":"cardinfo","txnVersion":"2.0.0"}} [] []
```
## 調査手順
- 出力されたログからaccountIdの値を抽出する
- 出力されたログからvResultCodeの値を抽出し、4桁ごとに分割する。
- [ベリトランス処理結果コード一覧](references/result-codes.md)を参照し、分割後の処理結果コードの詳細を確認する。
- 「想定される原因」と「発生した場合の対処例」を参照し、ユーザーに対してどのように案内すべきかを判断する
## 出力フォーマット
以下の情報を出力する
- 影響を受けたユーザーのaccountId
- vResultCodeから特定した「想定される原因」と「発生した場合の対処例」
出力例は以下の通り
<example>
{"アカウントID": "12364578", "想定される原因","入力されたセキュリティコードに誤りがあります。", "発生した場合の対処例":"消費者には、カード会社から与信が拒否されたことをご案内してください。その際に、セキュリティコードに誤りがあることを明確に伝えないようにしてください。"}
</example>
今度は出力フォーマットについても言及、「想定される原因」と「発生した場合の対処例」を出力するよう指示しています。記述量が多くなってきたので、処理結果コードの一覧は別ファイルに切り出して参照させるようにしました。
参照先の処理結果コード一覧です。
## ベリトランス処理結果コード一覧
| MStatus | VResultCode | デフォルトメッセージ | 英語メッセージ | 説明 | 想定される原因 | 発生した場合の対処例 |
| ------- | ----------- | ------------------------------------------------------------ | -------------------------- | ---------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
| failure | AG41 | セキュリティコード誤りです。 [G44] | Security code error. [G44] | セキュリティコード誤り | 入力されたセキュリティコードに誤りがあります。 | 消費者には、カード会社から与信が拒否されたことをご案内してください。その際に、**セキュリティコードに誤りがあることを明確に伝えないようにしてください。** |
| failure | XH41 | リクエストされたカード情報について決済センターとの確認に失敗しました。有効性確認時の結果コード:{0} | - | 内部与信エラー | 「有効性確認時の結果コード」によって異なるため、「有効性確認時の結果コード」で処理結果コード一覧を検索する | 「有効性確認時の結果コード」によって異なるため、「有効性確認時の結果コード」で処理結果コード一覧を検索する |
「有効性確認時の結果コード」についても記述し、AG41エラーはセキュリティコード誤りであることを明記しました。
ワークフローの実行
スキルが作成できたら各スキルをZIPファイルに圧縮し、スキル保存用のS3バケット配下にアップロードしておきます。
アップロードできたら以下の入力でワークフローを起動します。
{
"agentSpaceId": "<DevOps AgentのエージェントスペースID>",
"title": "Investigation of error logs during credit card payment execution",
"description": "## Time Period\nAround 2026-05-01T06:05:00.000Z\n## Points to Initiate the Investigation\narn:aws:lambda:ap-northeast-1:111111111111:function:devops-agent-test\n## Request\nAn error log was recorded when a credit card payment was executed.\nPlease analyze why this error occurred and tell us what impact it had on the user.",
"skillBucket": "<スキルをアップロードしたS3バケット名>",
"skillPrefix": "<スキルをアップロードしたS3のプレフィックス:今回であればlambda-error-log-skills/>"
}
指定したtitleとdescriptionがそのままDevOps Agentの調査に利用されます。
しばらく待つとDevOps Agentの調査✕3が終了し、ワークフローも実行完了します。

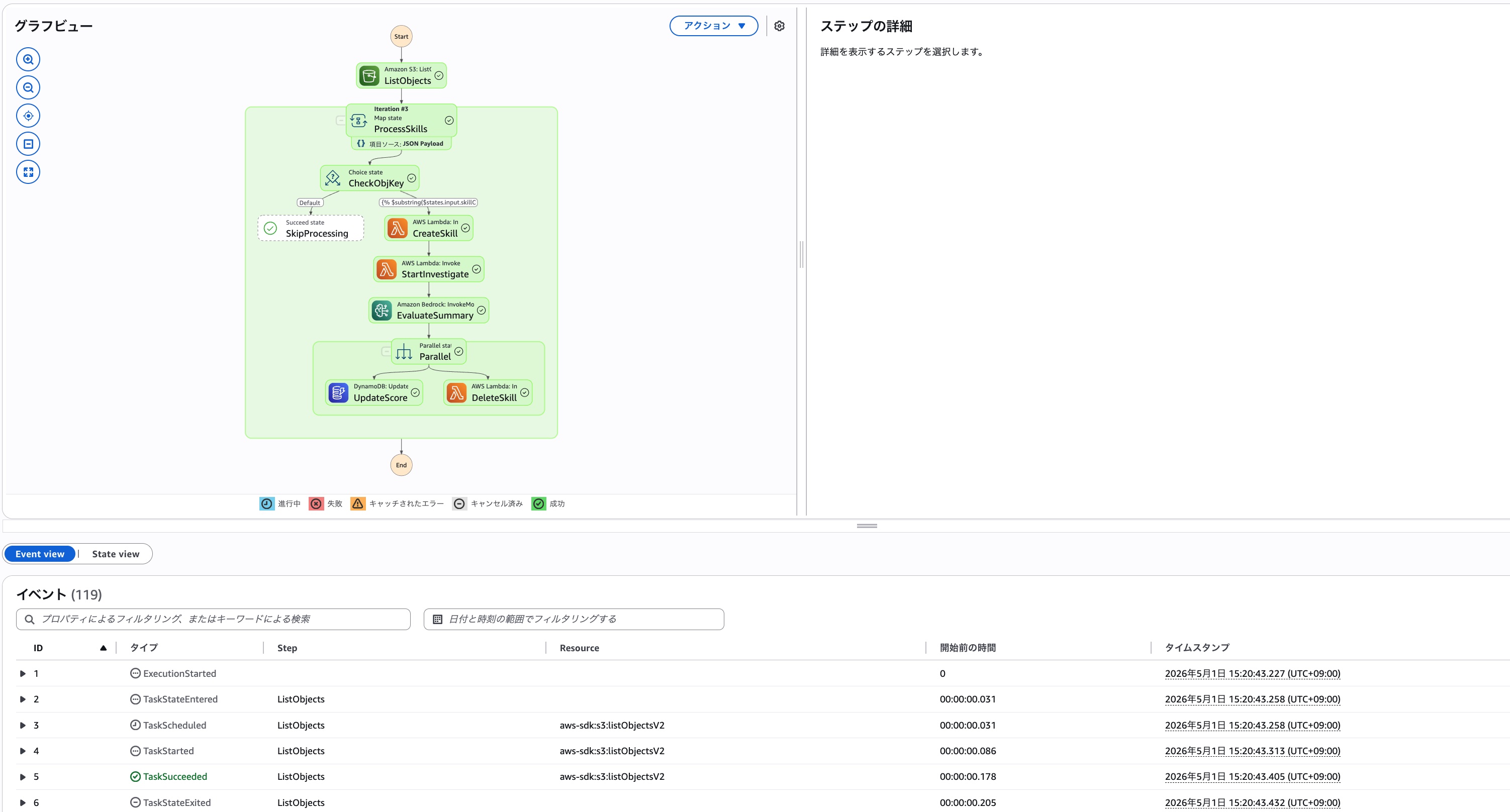
スキル1を使った調査結果
まずスキル1を使った調査結果です。履歴を確認するとちゃんとスキルが読み込まれていることが分かります。
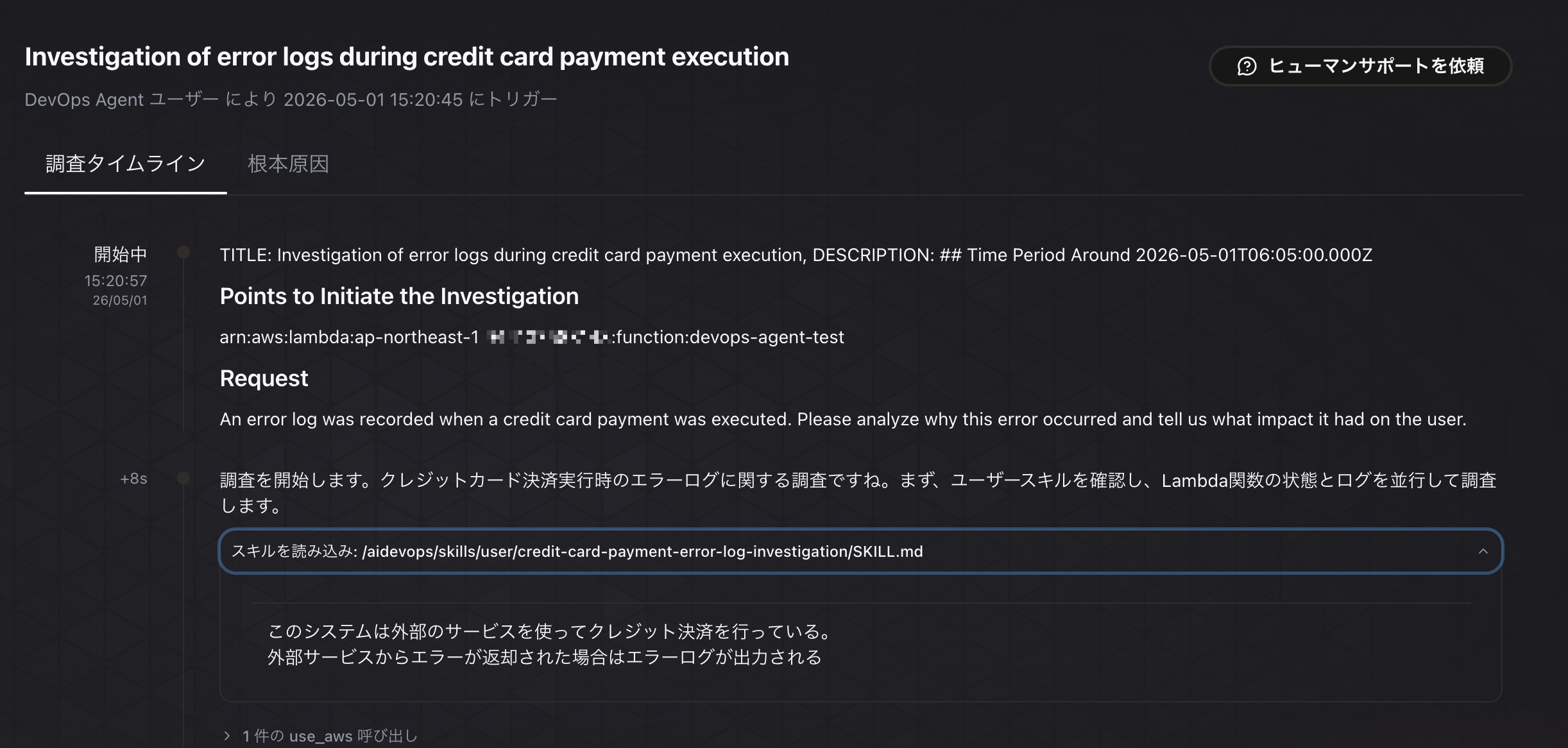
※実は最初はスキルのdescriptionの書き方がうまく調整できず、スキル評価のパイプラインなのにスキルを読み込んでくれないという問題があり、試行錯誤しました。

Bedrock(Sonnet-4.6)の評価では6.5というスコアが付きました。スコアの理由は以下の通りです。
調査結果はエラーログの内容を詳細に分析しており、ベリトランスAPIのエラーコード(AG41)や外部決済センターとの確認失敗という点は正確に捉えている。
Lambdaインフラ側の問題ではなくアプリケーションレベルのエラーであるという切り分けも適切。
しかし、真の原因である『ユーザーがセキュリティコードを誤入力した』という点には言及できておらず、カード期限切れ・利用停止・決済センター障害などの仮説を並列で挙げるに留まっている。
セキュリティコードの誤入力というユーザー起因のバリデーションエラーであることを特定できていないため、エンドユーザーへの案内(セキュリティコードを確認して再入力するよう促す)といった具体的なアクションにも言及できていない。
システム障害ではなくユーザー入力起因のエラーであるという本質的な切り分けが不十分であるが、調査の詳細さや構造的な分析は評価できる。
スキル2を使った調査結果
次はスキル2を使った調査結果です。
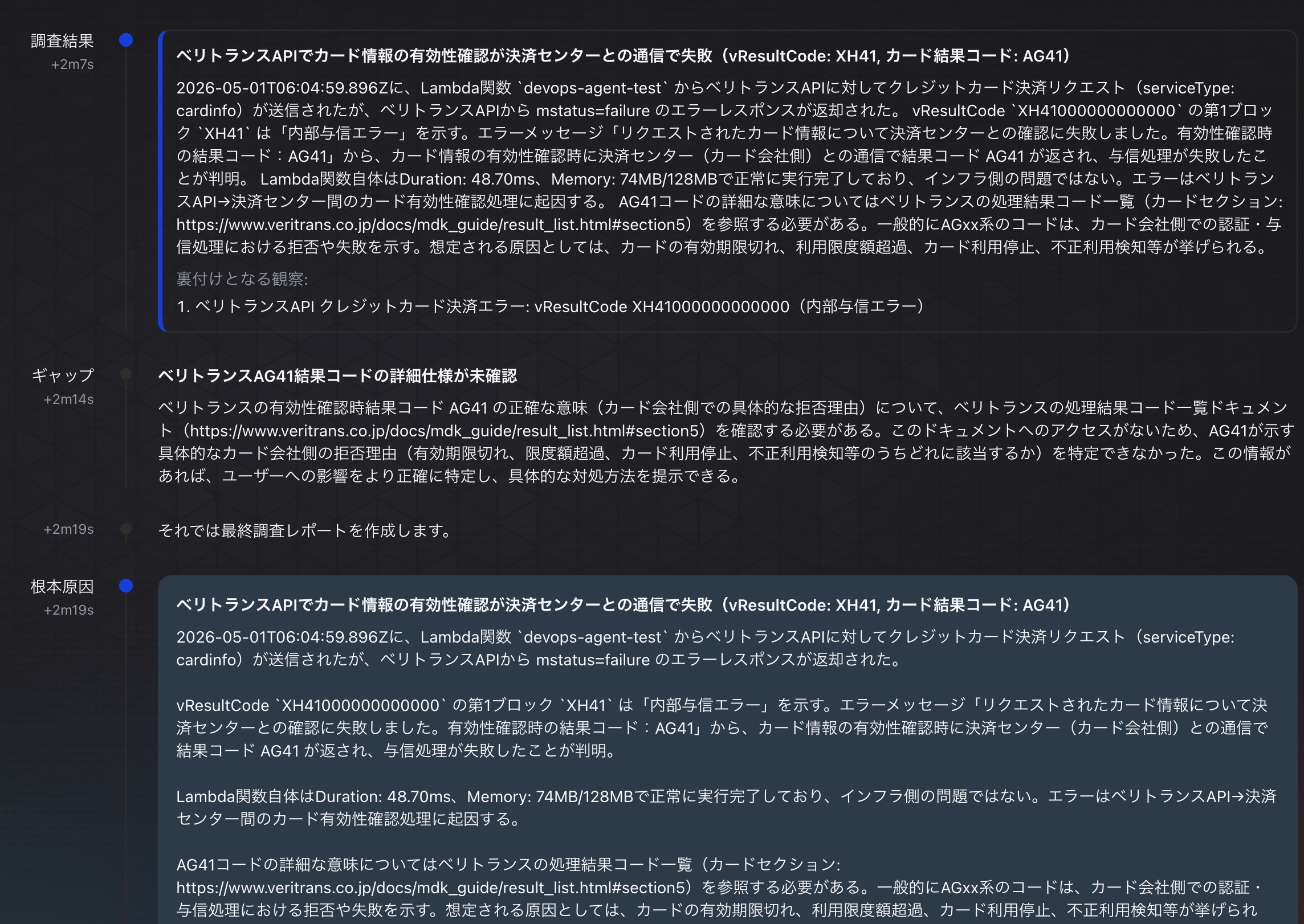
スコアは7.5で理由は以下の通りでした。
調査結果はベリトランスAPIがエラーコードを返却したことを正確に特定しており、エラーログの原因との類似度は高い。
Lambda関数自体の正常動作確認、インフラ側の問題排除、単発エラーであることの確認など具体的な調査が行われている点は評価できる。
ただし、エラーログの真の原因は「ユーザーがセキュリティコードを誤って入力した」というユーザー操作起因のバリデーションエラーであるのに対し、調査結果ではAG41を「カードの有効期限切れ、利用限度額超過、カード利用停止、不正利用検知等」と推測しており、セキュリティコード(CVV/CVC)の誤入力という正確な原因の特定には至っていない。
通常のユーザー入力誤りによるエラーかシステム障害かの切り分けは部分的にできているが(インフラ問題を排除している)、ユーザーへの具体的な案内内容(セキュリティコードを確認して再入力するよう促す)への言及が不足している点でスコアを下げた。
スキル3を使った調査結果
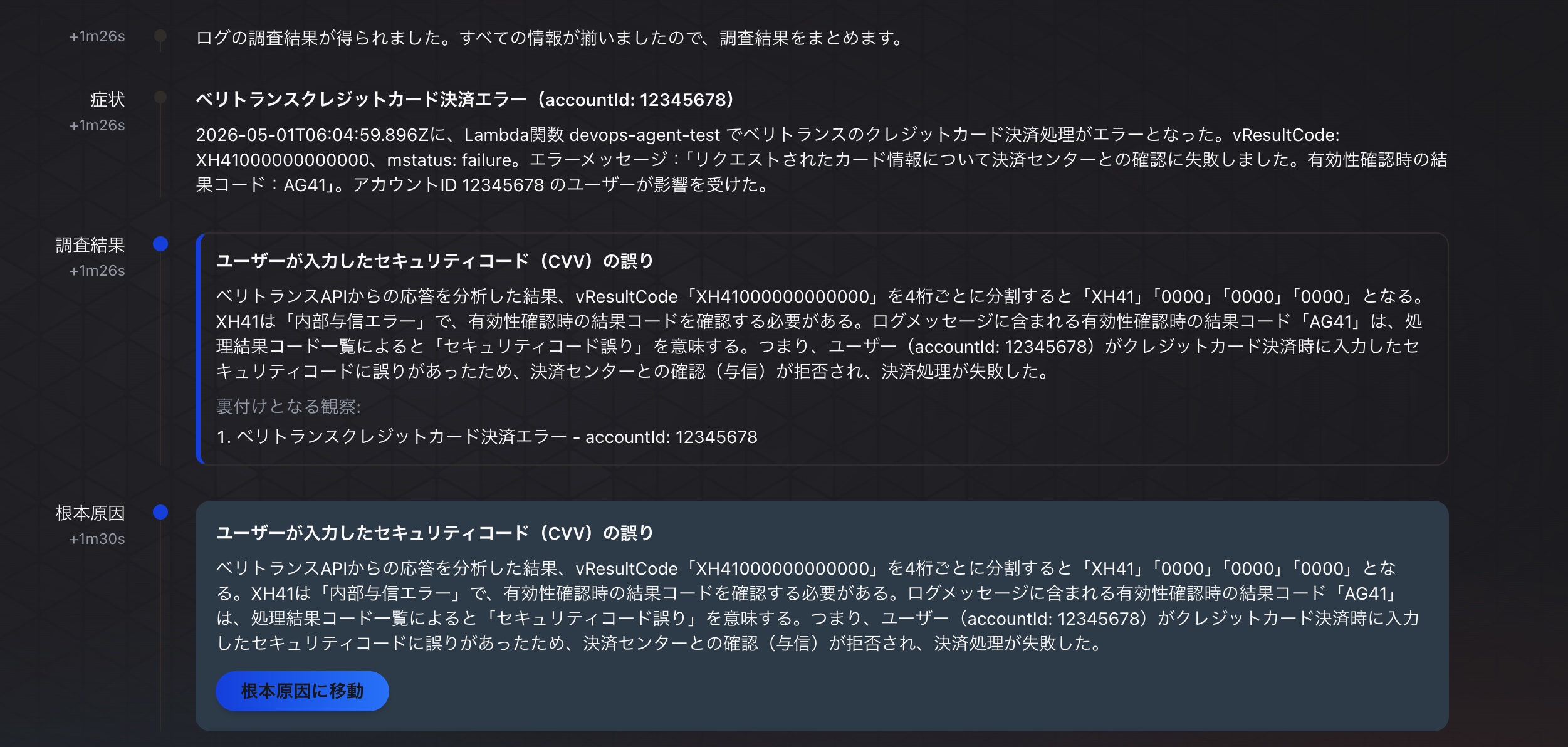
スコアは9.8で理由は以下の通りでした。
調査結果はエラーログの原因と非常に高い類似度を示している。
具体的には、(1)ユーザーが入力したセキュリティコードの誤りが根本原因であると正確に特定できている、
(2)ベリトランスAPIのエラーコード「XH41000000000000」および有効性確認結果コード「AG41」を詳細に分析し、『セキュリティコード誤り』であることを具体的なコード解析付きで説明できている、
(3)影響範囲がaccountId: 12345678の単一ユーザーへの単発エラーであることを特定し、システム障害ではなくユーザー入力起因のバリデーションエラーであることを明確に切り分けている、
(4)エンドユーザーへの影響(決済失敗)と原因(セキュリティコードの入力誤り)が具体的に記述されており、ユーザーへの案内内容(セキュリティコードを正しく入力し直す)が自然に導出できる内容になっている。
investigation_gapsも空であり、調査の網羅性も高い。
わずかにユーザーへの具体的な案内文言や再発防止策への言及がない点でわずかに減点するが、全体として非常に的確な調査結果といえる。
ワークフローの実行結果まとめ
以上の結果から、スキル3が最も優秀なスキルだと判断できます!!
まとめ
今回は結果が出やすいようにスキルの記述レベルを意図的に操作しており、実業務に適用するとこんなにきれいな結果は出ないとは思いますが、スキルを作っては調査を開始して評価して...という繰り返す労力を考えると、全スキル分ループしての調査実行やBedrockによる自動スコアリング、DevOps Agentの調査結果のDB保存といったアーキテクチャは十分実務でも活用できるのではないでしょうか。こういった工夫も取り入れながらスキルを育てて、DevOps Agentをフル活用していきたいですね。
欲を言うとDevOps Agent側でマネージドなサービスとしてこういうスキル評価のパイプライン的な機能が提供されると最高なので、今後のアップデートに期待したいです。









