Fivetran で BigQuery に同期するテーブルのパーティション分割とクラスタ化を行う
はじめに
Fivetran で BigQuery を宛先にデータをロードしテーブルのパーティション分割とクラスタ化を実施してみたので、本記事で内容をまとめてみます。
パーティション分割とクラスタ化
Fivetran は BigQuery 上のテーブルについて、以下の機能をサポートしています。
- パーティション
- 取り込み時間パーティション テーブル
- 日付でパーティション化されたテーブル
- ※時間単位、月単位、年単位の粒度はサポートしていない
- 整数範囲パーティション テーブル
- クラスタリング
- パーティション分割されたテーブルとパーティション分割されていないテーブルのクラスタリング
Fivetran でのデータロード時には、標準の BigQuery テーブルとして作成されるため、パーティション化やクラスタ化テーブルとする場合は、BigQuery 側でも別途作業が必要です。
ここでは「日付でパーティション化されたテーブル」とテーブルのクラスタ化の手順をまとめます。
前提条件
宛先として BigQuery を設定する際の手順は以下の記事をご参照ください。
また、ここではデータソースとして Google スプレッドシートを使用します。
こちらの設定手順は以下の記事をご参照ください。
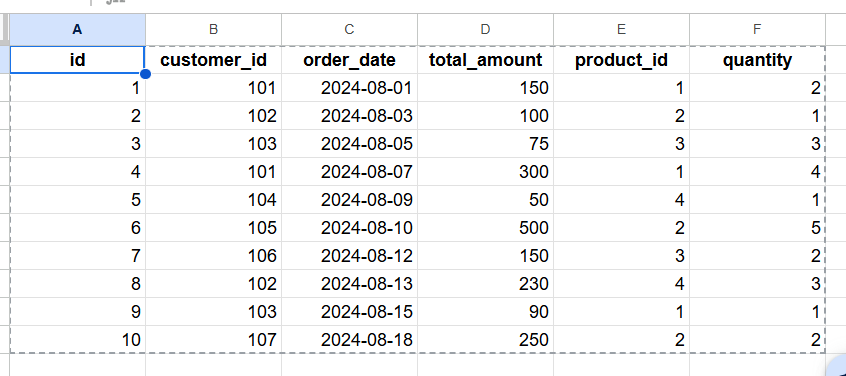
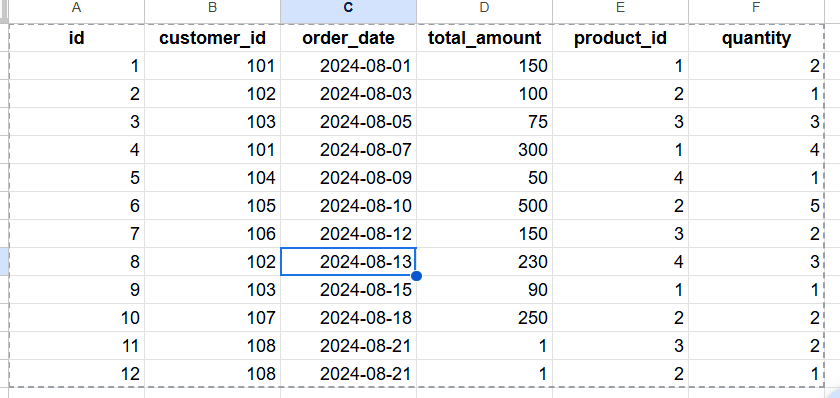
下図のテーブルを使用します。
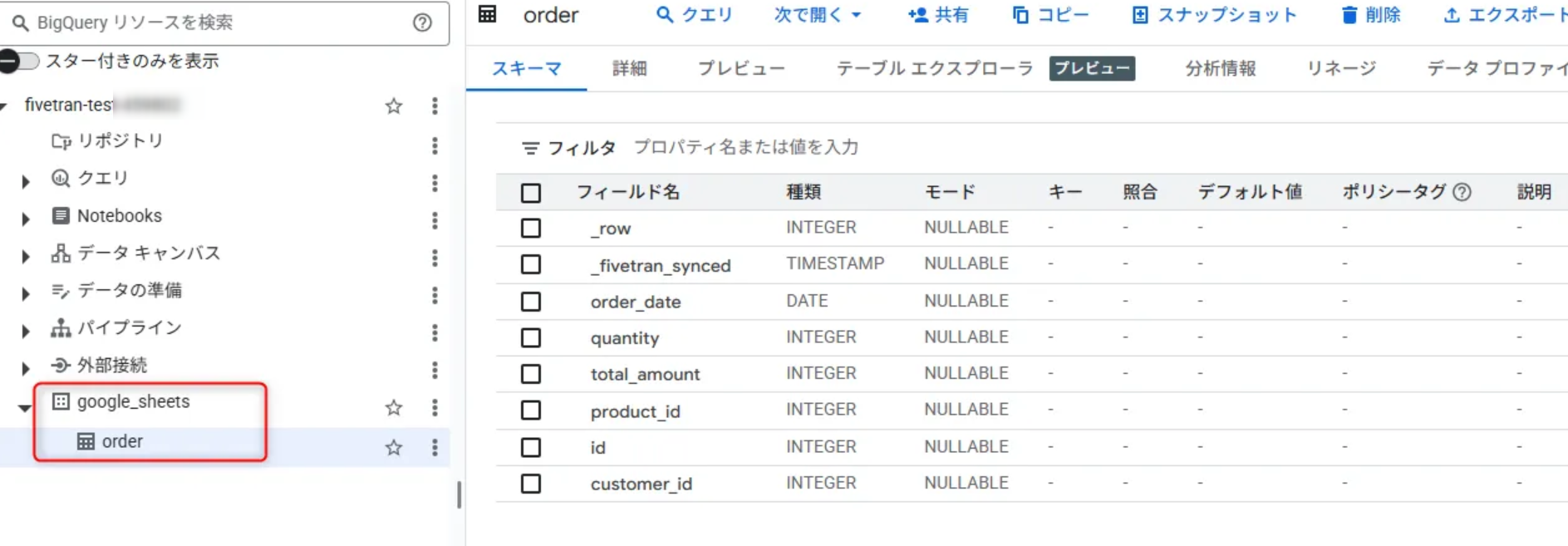
特に何もせずにデータロードすると、図のように標準の BigQuery テーブルとして作成されていることが確認できます。
時間単位の列パーティションまたは整数範囲パーティションのテーブルの作成
それぞれ同様の手順となるので、ここでは「時間単位の列パーティション」テーブルを作成します。ドキュメントには以下に手順の記載があります。
手順としては Fivetran で対象のテーブルを同期し、その後同期したテーブルからパーティション化テーブルを作成、置き換えるという流れです。
コネクションを一時停止する
作業中はコネクションを停止し、Fivetran による同期処理が実行されないようにしておきます
既存のテーブルをパーティション化テーブルに変換
BigQuery 側で SQL を実行し、すでにロードされた既存のテーブルからパーティション化したテーブルを作成します。ここでは copy の名称で DATE 列に基づいてパーティション分割したテーブルを作成しています。
CREATE TABLE `google_sheets`.copy
PARTITION BY order_date
AS
SELECT *
FROM `google_sheets`.`order`;
パーティション化テーブルとして既存のテーブルをコピーしたので、オリジナルのテーブルを削除します。
DROP TABLE `google_sheets`.order;
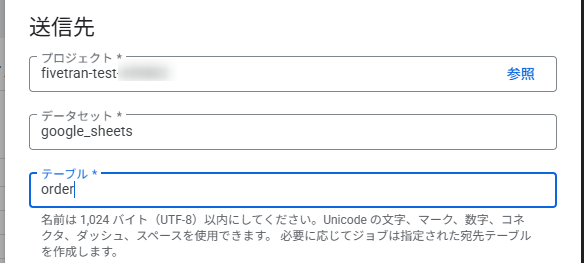
コピーしたパーティション化テーブルをオリジナルの名称でコピーします。この際「テーブル」にオリジナルのテーブル名を入力し「コピー」します。
オリジナルの名称でパーティション化テーブルが作成されたので、はじめに作成したコピー テーブルを削除します
DROP TABLE `google_sheets`.copy;
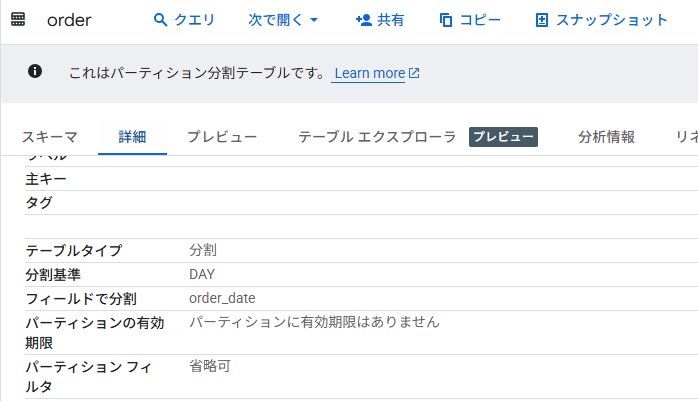
テーブルを確認するとパーティション化テーブルとして作り変えたので、下図のようになっています。
これで Fivetran 側の同期を再開します。レコードを追加して再度同期します。
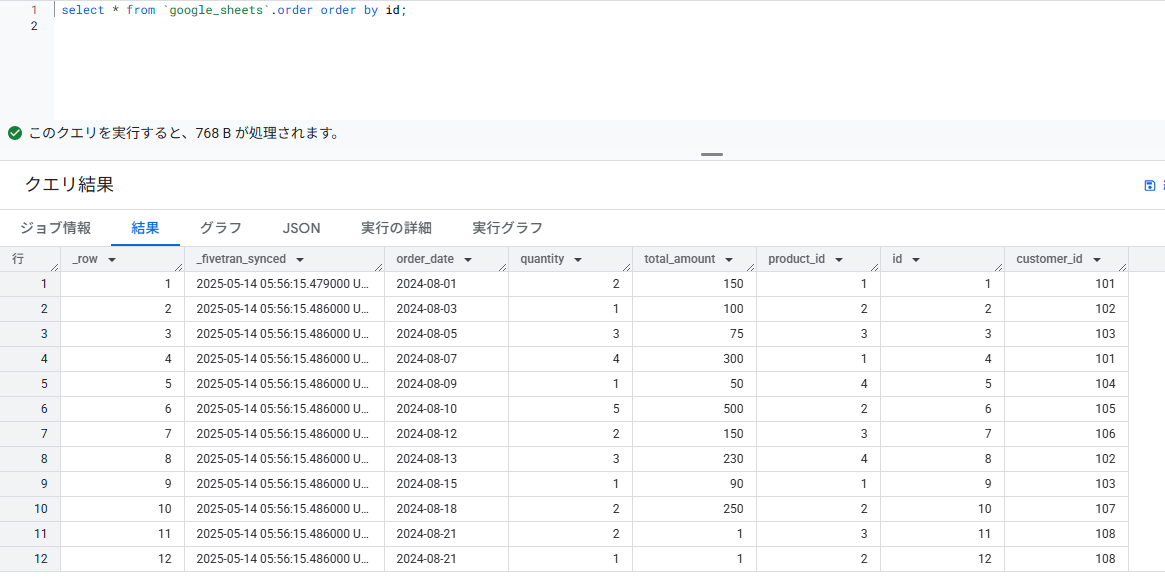
同期完了後、レコードを確認します。テーブル名が正しく設定されていれば問題なく同期できます。
クラスタ化テーブルの作成
こちらの手順は以下に記載があります。
大まかな流れは時間単位の列パーティションまたは整数範囲パーティションのテーブルの時と同様で、既存のテーブルをクラスタ化テーブルに変換することで作成します。
コネクションを一時停止する
作業中はコネクションを停止し、Fivetran による同期処理が実行されないようにしておきます。
既存のテーブルをクラスタ化されたテーブルに変換
BigQuery 側で SQL を実行し、既存のテーブルをクラスタ化テーブルに変換します。以下は上記のドキュメントからの引用ですが、パーティション化の有無は Fivetran としてもいずれでも問題ありません。
- パーティション化されていないテーブルの例
create table [schema-name].copy
cluster by [column_names_upto_4]
as select * from [schema-name].[table-name];
drop table [schema-name].[table-name];
- パーティション化されたテーブルの例
create table [schema-name].copy
partition by date([timestamp-column])
cluster by [column_names_upto_4]
as select * from [schema-name].[table-name];
drop table [schema-name].[table-name];
ここでは先の手順でパーティション化したテーブルをさらにクラスタリングしてみます。
CREATE TABLE `google_sheets`.copy
PARTITION BY order_date
CLUSTER BY id
AS
SELECT *
FROM `google_sheets`.order;
既存のテーブルを削除します。
DROP TABLE `google_sheets`.order;
作成したコピーテーブルから元のテーブル名と同じ名称でコピーを作成します。
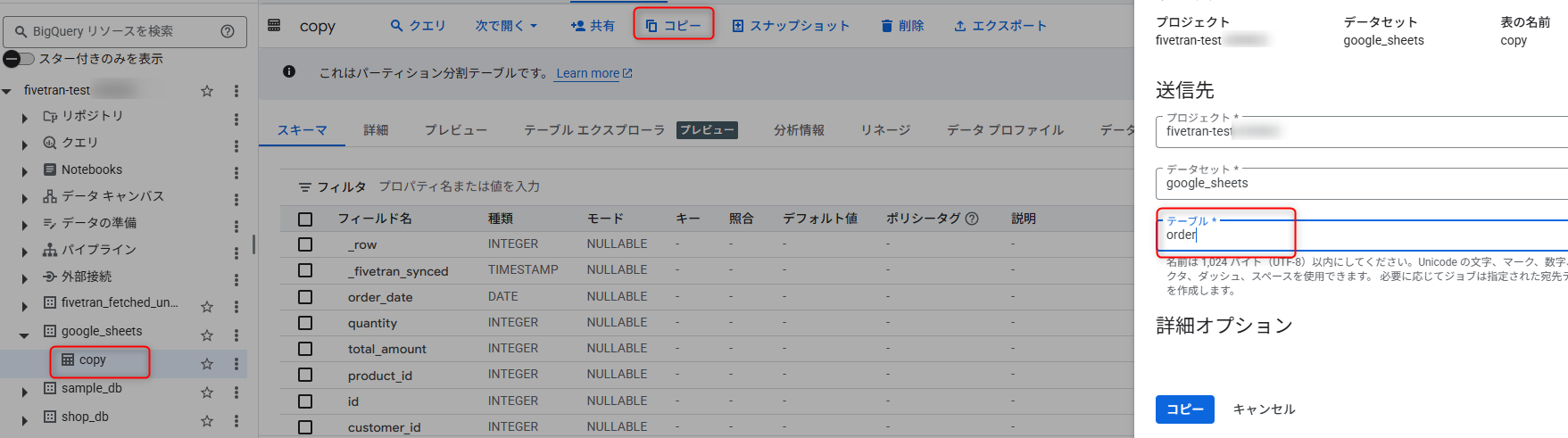
コピー テーブルを削除します。
DROP TABLE `google_sheets`.copy;
この時点でテーブルの詳細を確認すると、パーティション化とクラスタ化されているテーブルであることを確認できます。
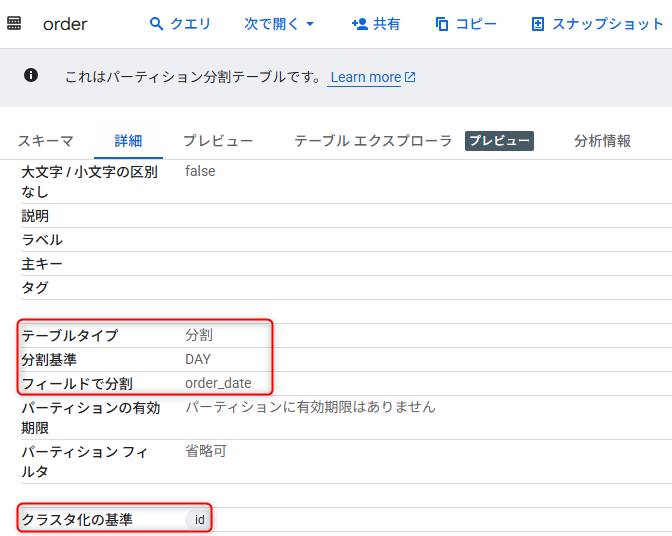
データを確認
$ bq query --use_legacy_sql=false 'SELECT * FROM `google_sheets.order` ORDER BY 1'
+------+---------------------+------------+----------+--------------+------------+----+-------------+
| _row | _fivetran_synced | order_date | quantity | total_amount | product_id | id | customer_id |
+------+---------------------+------------+----------+--------------+------------+----+-------------+
| 1 | 2025-05-14 05:56:15 | 2024-08-01 | 2 | 150 | 1 | 1 | 101 |
| 2 | 2025-05-14 05:56:15 | 2024-08-03 | 1 | 100 | 2 | 2 | 102 |
| 3 | 2025-05-14 05:56:15 | 2024-08-05 | 3 | 75 | 3 | 3 | 103 |
| 4 | 2025-05-14 05:56:15 | 2024-08-07 | 4 | 300 | 1 | 4 | 101 |
| 5 | 2025-05-14 05:56:15 | 2024-08-09 | 1 | 50 | 4 | 5 | 104 |
| 6 | 2025-05-14 05:56:15 | 2024-08-10 | 5 | 500 | 2 | 6 | 105 |
| 7 | 2025-05-14 05:56:15 | 2024-08-12 | 2 | 150 | 3 | 7 | 106 |
| 8 | 2025-05-14 05:56:15 | 2024-08-13 | 3 | 230 | 4 | 8 | 102 |
| 9 | 2025-05-14 05:56:15 | 2024-08-15 | 1 | 90 | 1 | 9 | 103 |
| 10 | 2025-05-14 05:56:15 | 2024-08-18 | 2 | 250 | 2 | 10 | 107 |
| 11 | 2025-05-14 05:56:15 | 2024-08-21 | 2 | 1 | 3 | 11 | 108 |
| 12 | 2025-05-14 05:56:15 | 2024-08-21 | 1 | 1 | 2 | 12 | 108 |
+------+---------------------+------------+----------+--------------+------------+----+-------------+
ソース側でレコードの追加とあわせて Fivetran 側の同期を再開します。
テーブル名が正しく設定されていれば、問題なく同期され、追加されたレコードを確認できました。
$ bq query --use_legacy_sql=false 'SELECT * FROM `google_sheets.order` ORDER BY 1'
+------+---------------------+------------+----------+--------------+------------+----+-------------+
| _row | _fivetran_synced | order_date | quantity | total_amount | product_id | id | customer_id |
+------+---------------------+------------+----------+--------------+------------+----+-------------+
| 1 | 2025-05-19 00:53:05 | 2024-08-01 | 2 | 150 | 1 | 1 | 101 |
| 2 | 2025-05-19 00:53:05 | 2024-08-03 | 1 | 100 | 2 | 2 | 102 |
| 3 | 2025-05-19 00:53:05 | 2024-08-05 | 3 | 75 | 3 | 3 | 103 |
| 4 | 2025-05-19 00:53:05 | 2024-08-07 | 4 | 300 | 1 | 4 | 101 |
| 5 | 2025-05-19 00:53:05 | 2024-08-09 | 1 | 50 | 4 | 5 | 104 |
| 6 | 2025-05-19 00:53:05 | 2024-08-10 | 5 | 500 | 2 | 6 | 105 |
| 7 | 2025-05-19 00:53:05 | 2024-08-12 | 2 | 150 | 3 | 7 | 106 |
| 8 | 2025-05-19 00:53:05 | 2024-08-13 | 3 | 230 | 4 | 8 | 102 |
| 9 | 2025-05-19 00:53:05 | 2024-08-15 | 1 | 90 | 1 | 9 | 103 |
| 10 | 2025-05-19 00:53:05 | 2024-08-18 | 2 | 250 | 2 | 10 | 107 |
| 11 | 2025-05-19 00:53:05 | 2024-08-21 | 2 | 1 | 3 | 11 | 108 |
| 12 | 2025-05-19 00:53:05 | 2024-08-21 | 1 | 1 | 2 | 12 | 108 |
| 13 | 2025-05-19 00:53:05 | 2024-08-22 | 50 | 1000 | 3 | 13 | 109 |
+------+---------------------+------------+----------+--------------+------------+----+-------------+
さいごに
BigQuery と Fivetran を使用する際の宛先テーブルのパーティション分割・クラスタ化を試してみました。
こちらの内容が何かの参考になれば幸いです。







