Fivetran Managed Data Lake Service で構築した S3 データレイクを DuckDB / Snowflake / Databricks から参照してみた
はじめに
Fivetran の Managed Data Lake Service で、ソースから取り込んだデータを S3 上に Iceberg / Delta 両形式のメタデータとともに保存し、Fivetran がホストする Apache Polaris カタログ経由で外部クエリエンジンから参照できます。
本機能を使って S3 上にデータレイクを構築し、DuckDB、Snowflake、Databricks の3エンジンから同一テーブルを参照した際の内容を記事としました。
Fivetran Managed Data Lake Service の概要
Managed Data Lake Service は、Fivetran が宛先(Destination)として S3 などのオブジェクトストレージを使用し、データ連携とあわせて Iceberg / Delta のメタデータを Fivetran 側で管理できる機能です。
本機能については以下に記載があります。
主な特徴は以下の通りです。
- データの実体は Parquet 形式で S3 に保存され、Iceberg と Delta Lake の両方のメタデータが同期して維持される
- テーブルの操作・管理は Fivetran によって管理され、外部のクエリエンジンに対して読み取り専用として提供されます
- カタログは Fivetran がホストする Apache Polaris カタログ(Iceberg REST Catalog)での実装として提供される
- カタログ側で credential vending に対応しており、クライアント側に AWS クレデンシャルを持たせる必要がない
本記事では、メタデータカタログとしてデフォルトの Fivetran Iceberg REST Catalog(Apache Polaris)を使用しますが、Destination の設定として、AWS Glue / Databricks Unity Catalog / BigLake metastore / OneLake も選択できます。
AWS Glue を使用する例は以下をご参照ください。
前提条件
以下の環境を使用しています。
- AWS:S3 バケット(リージョン:ap-northeast-1)
- データソース:Google Sheets
- クエリエンジン
- DuckDB:v1.5.2 (Variegata)
- Snowflake:Enterprise エディション(トライアルアカウント)
- Databricks:Free アカウント
Fivetran 側の設定
はじめに Fivetran の Destination, Connection に関する設定を行います。
S3 バケット用 IAM ポリシーの作成
Fivetran が S3 へ書き込みするためのポリシーを作成します。
内容は以下のようにしました。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowListBucketOfASpecificPrefix",
"Effect": "Allow",
"Action": ["s3:ListBucket"],
"Resource": ["arn:aws:s3:::<バケット名>"],
"Condition": {
"StringLike": {
"s3:prefix": ["datalake/*"]
}
}
},
{
"Sid": "AllowAllObjectActionsInSpecificPrefix",
"Effect": "Allow",
"Action": [
"s3:DeleteObjectTagging",
"s3:ReplicateObject",
"s3:PutObject",
"s3:GetObjectAcl",
"s3:GetObject",
"s3:GetObjectTagging",
"s3:DeleteObjectVersion",
"s3:PutObjectTagging",
"s3:DeleteObject",
"s3:PutObjectAcl"
],
"Resource": ["arn:aws:s3:::<バケット名/datalake/*"]
}
]
}
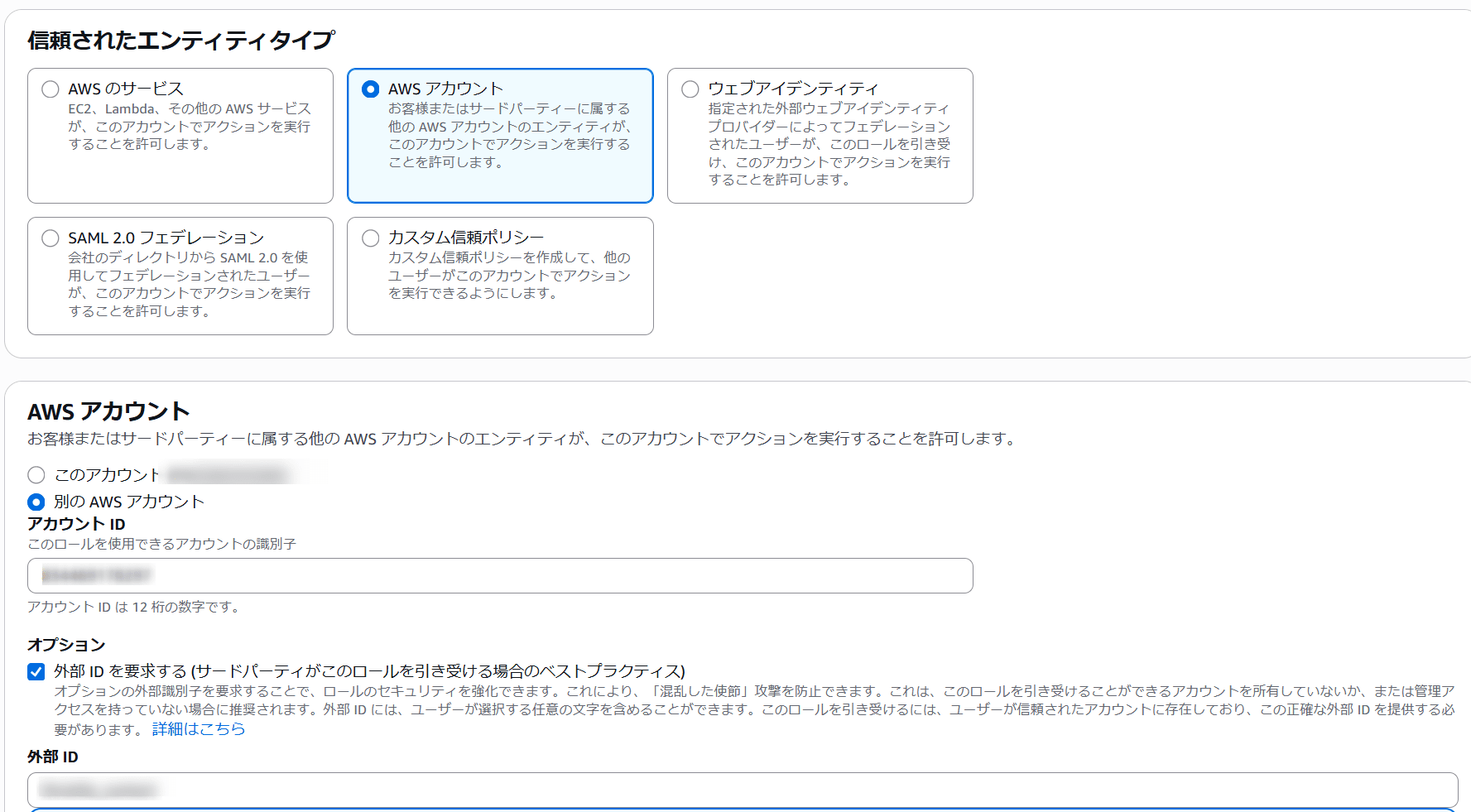
Fivetran 用 IAM ロールの作成
「別の AWS アカウント」を信頼されたエンティティとして選択し、Fivetran のアカウント ID を入力します。「外部 ID を要求する(Require external ID)」にチェックを入れ、Fivetran 側で取得した External ID を入力します。
※いずれも Destination の設定画面から確認できます。
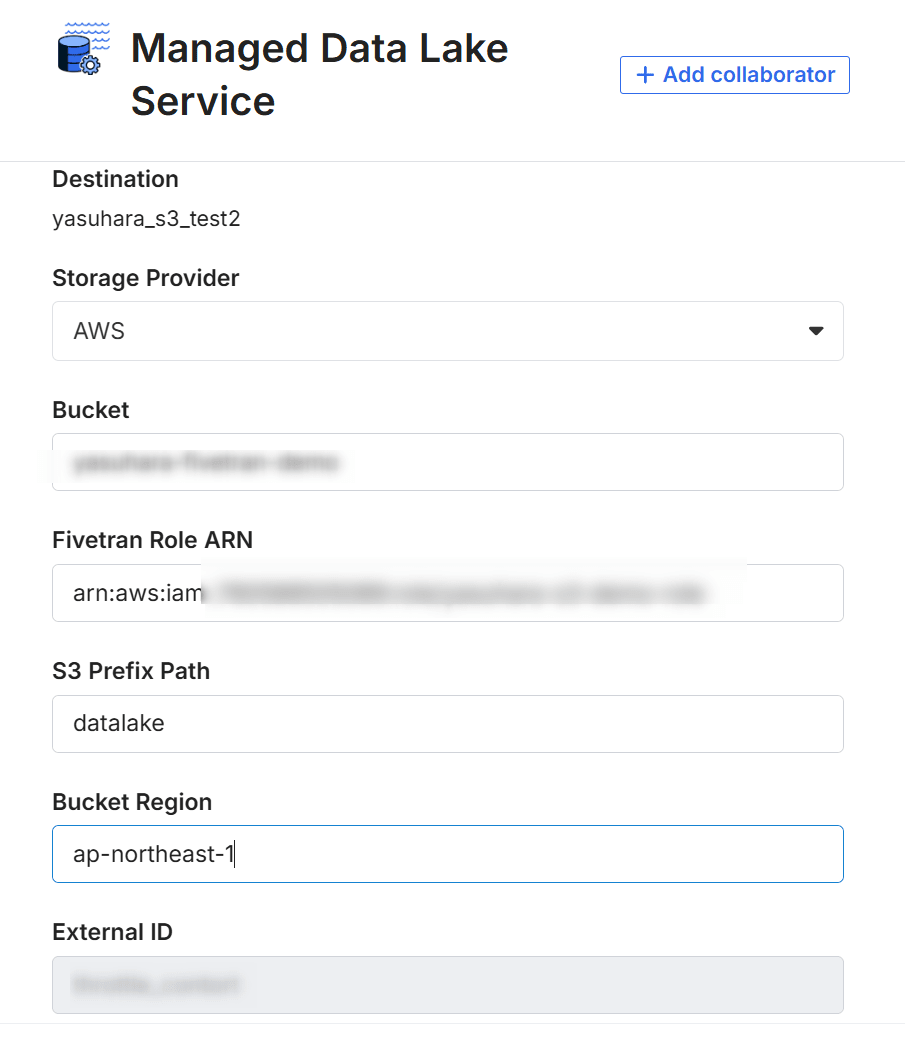
Fivetran Destination の作成
Fivetran 側で Destination を作成し、作成した IAM ロール ARN とバケットを指定します。
接続テストを行い、成功することを確認します。
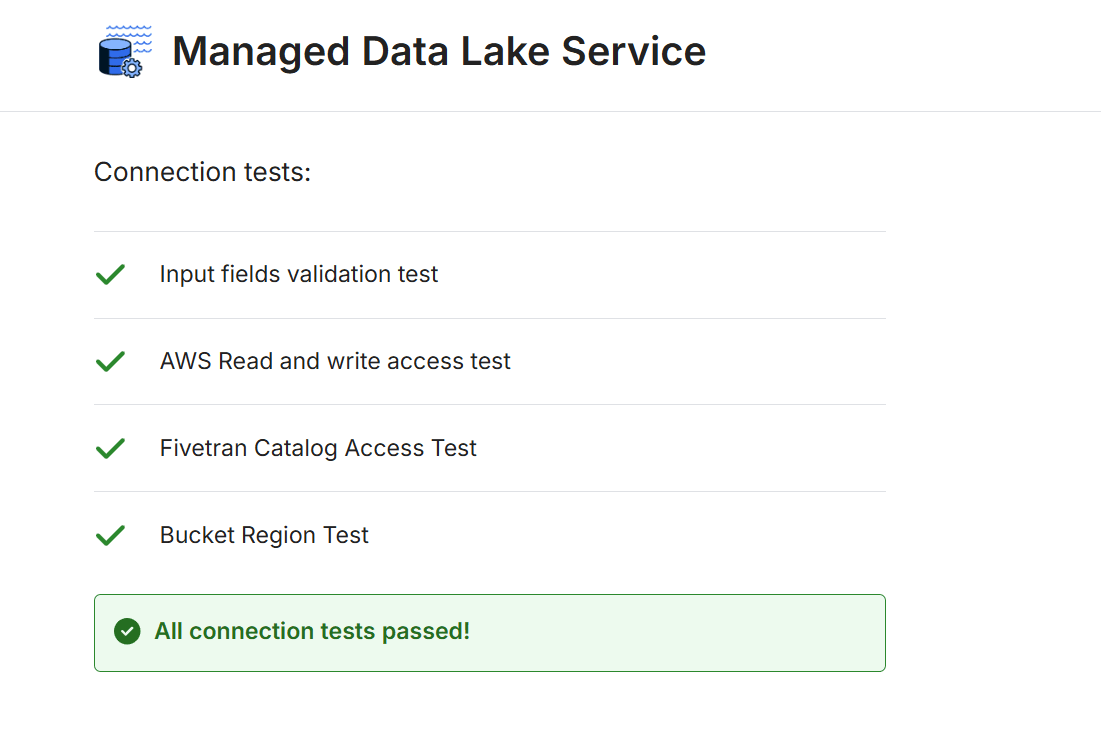
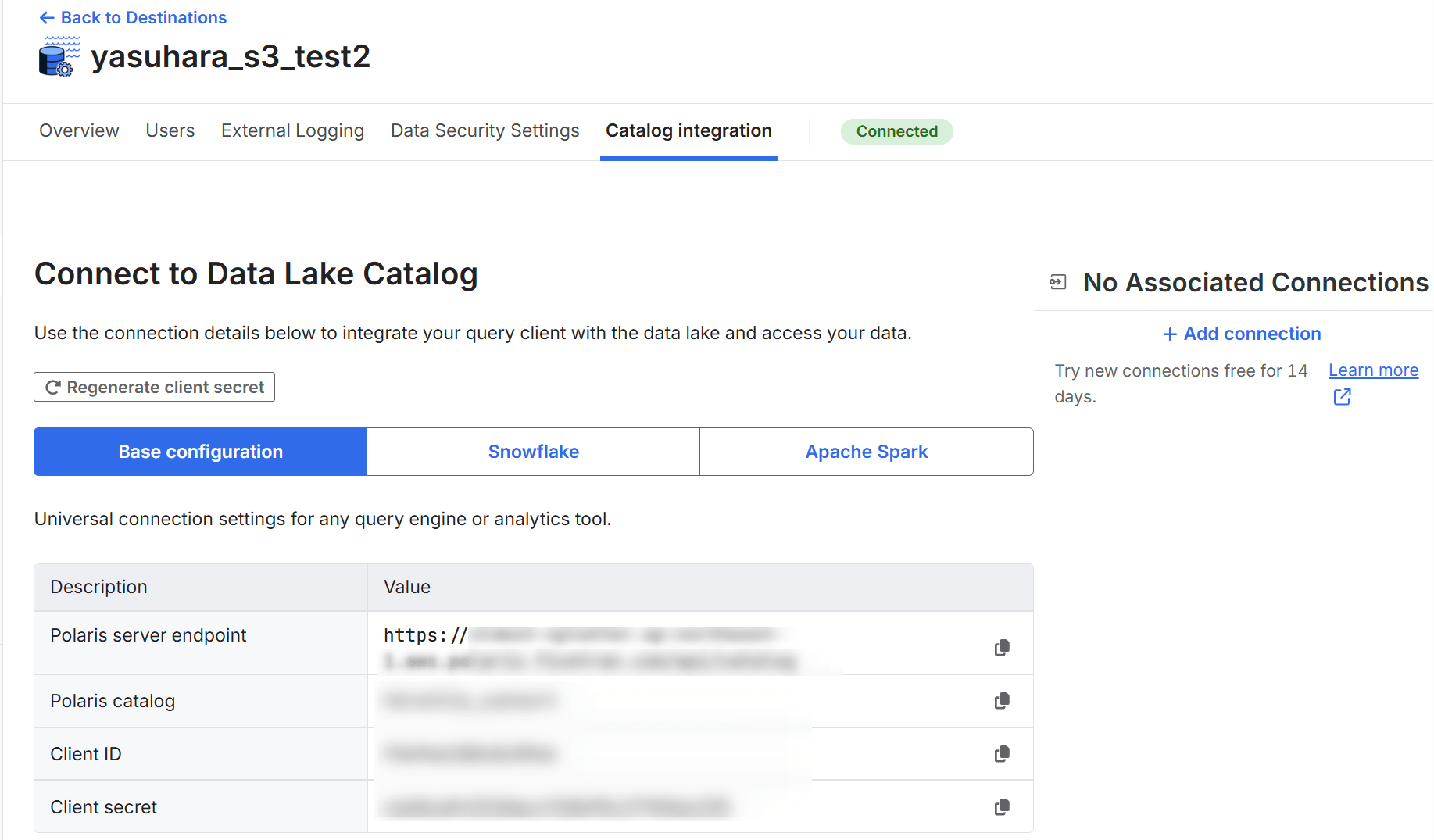
Destination 詳細の「Catalog integration」タブで、後続の検証で使用する Polaris カタログへの接続情報として以下を確認できます。
- Polaris server endpoint
- Polaris catalog
- Client ID
- Client secret
データソースの接続
データソースとして Google Sheets を接続します。
初期同期完了後、S3 バケットを確認すると、Parquet データファイルとあわせて Iceberg メタデータ(metadata/*.json)と Delta Lake トランザクションログ(_delta_log/)が同時に作成されていることが分かります。
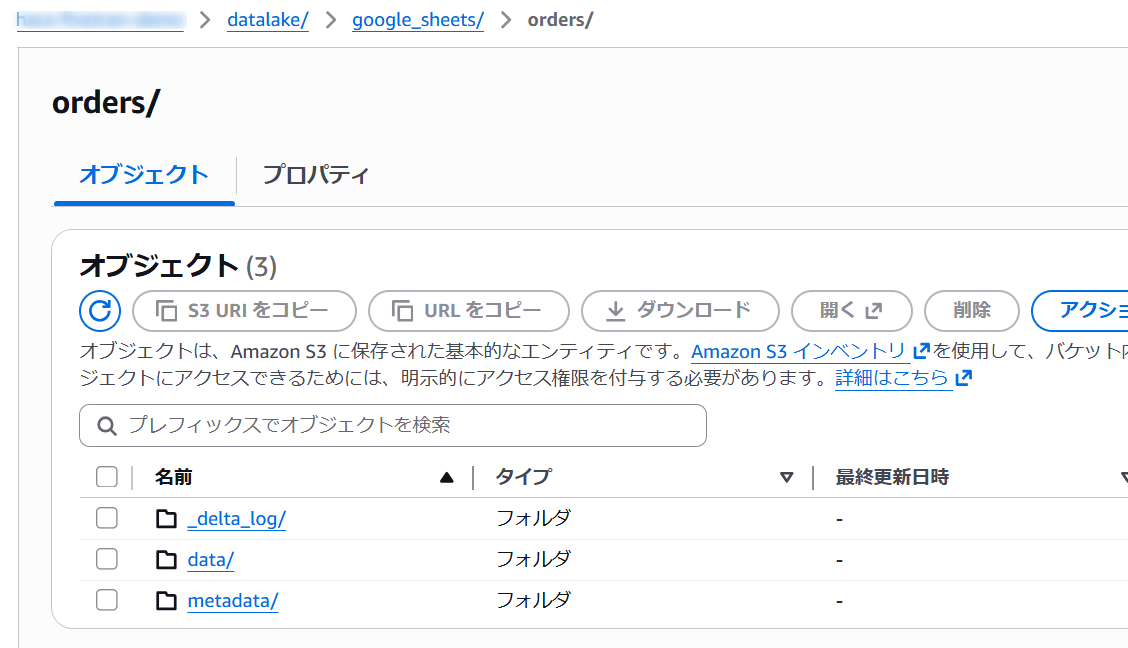
両フォーマットが同時に維持されることで、後続のクエリエンジンの選択肢を Iceberg / Delta のどちらにも寄せられる構成になっています。
DuckDB から参照
DuckDB の Iceberg 拡張機能を使い、Polaris カタログ経由でテーブルを参照します。
拡張機能のロード
以下のコマンドで拡張機能を追加します。
INSTALL iceberg;
INSTALL httpfs;
LOAD iceberg;
LOAD httpfs;
icebergは Apache Iceberg のメタデータを読み、テーブルを参照するために必要ですhttpfsは HTTPS/S3 ファイルシステムを扱う拡張です。データ実体の Parquet が S3 にあるため必要となります
認証情報を SECRET に登録
Fivetran の Catalog integration タブから取得した値を使い、CREATE SECRETで Iceberg REST Catalog 用の SECRET を登録します。
CREATE SECRET polaris_secret (
TYPE iceberg,
CLIENT_ID '<Client ID>',
CLIENT_SECRET '<Client Secret>',
OAUTH2_SERVER_URI '<Polaris endpoint>/v1/oauth/tokens',
OAUTH2_SCOPE 'PRINCIPAL_ROLE:ALL'
);
OAUTH2_SERVER_URI はエンドポイントに /v1/oauth/tokens を足したものになります。
カタログを ATTACH
ATTACHで Iceberg REST Catalog に接続します。
ATTACH '<Polaris catalog 名>' AS polaris_catalog (
TYPE iceberg,
SECRET polaris_secret,
ENDPOINT '<Polaris endpoint>',
DEFAULT_REGION 'ap-northeast-1'
);
Polaris が credential vending(一時 AWS クレデンシャルをカタログ側が発行)で S3 アクセス権を渡してくれますが、このためには、DEFAULT_REGION の指定が必須でした。指定しないと No region was provided via the vended credentials... というエラーになります。
クエリ
ATTACH後、実際にデータを参照できます。
-- カタログ配下のテーブル一覧
D SHOW ALL TABLES;
┌─────────────────┬───────────────┬─────────┬───┬──────────────┬───────────┐
│ database │ schema │ name │ … │ column_types │ temporary │
│ varchar │ varchar │ varchar │ … │ varchar[] │ boolean │
├─────────────────┼───────────────┼─────────┼───┼──────────────┼───────────┤
│ polaris_catalog │ google_sheets │ orders │ … │ [UNKNOWN] │ false │
└─────────────────┴───────────────┴─────────┴───┴──────────────┴───────────┘
-- テーブル参照
D SELECT * FROM polaris_catalog.google_sheets.orders;
┌───────┬───────────────────────────┬────────────┬───┬────────────┬───────┬─────────────┐
│ _row │ _fivetran_synced │ order_date │ … │ product_id │ id │ customer_id │
│ int64 │ timestamp with time zone │ date │ … │ int32 │ int32 │ int32 │
├───────┼───────────────────────────┼────────────┼───┼────────────┼───────┼─────────────┤
│ 5 │ 2026-05-15 10:04:00.656+… │ 2024-08-09 │ … │ 4 │ 5 │ 104 │
│ 10 │ 2026-05-15 10:04:00.657+… │ 2024-08-18 │ … │ 2 │ 10 │ 107 │
│ 3 │ 2026-05-15 10:04:00.656+… │ 2024-08-05 │ … │ 3 │ 3 │ 103 │
│ 8 │ 2026-05-15 10:04:00.657+… │ 2024-08-13 │ … │ 4 │ 8 │ 102 │
│ 1 │ 2026-05-15 10:04:00.462+… │ 2024-08-01 │ … │ 1 │ 1 │ 101 │
│ 6 │ 2026-05-15 10:04:00.656+… │ 2024-08-10 │ … │ 2 │ 6 │ 105 │
│ 4 │ 2026-05-15 10:04:00.656+… │ 2024-08-07 │ … │ 1 │ 4 │ 101 │
│ 9 │ 2026-05-15 10:04:00.657+… │ 2024-08-15 │ … │ 1 │ 9 │ 103 │
│ 2 │ 2026-05-15 10:04:00.656+… │ 2024-08-03 │ … │ 2 │ 2 │ 102 │
│ 7 │ 2026-05-15 10:04:00.657+… │ 2024-08-12 │ … │ 3 │ 7 │ 106 │
└───────┴───────────────────────────┴────────────┴───┴────────────┴───────┴─────────────┘
メタデータの確認には以下の関数が使えます。
-- メタデータ確認
D SELECT * FROM iceberg_metadata('polaris_catalog.google_sheets.orders');
┌───────────────────────────────┬──────────────────────┬───┬─────────────┬──────────────┐
│ manifest_path │ manifest_sequence_n… │ … │ file_format │ record_count │
│ varchar │ int64 │ … │ varchar │ int64 │
├───────────────────────────────┼──────────────────────┼───┼─────────────┼──────────────┤
│ s3://<バケット名>/… │ 1 │ … │ PARQUET │ 10 │
└───────────────────────────────┴──────────────────────┴───┴─────────────┴──────────────┘
D SELECT * FROM iceberg_snapshots('polaris_catalog.google_sheets.orders');
┌─────────────────┬────────────────────┬────────────────────────┬───────────────────────┐
│ sequence_number │ snapshot_id │ timestamp_ms │ manifest_list │
│ uint64 │ uint64 │ timestamp │ varchar │
├─────────────────┼────────────────────┼────────────────────────┼───────────────────────┤
│ 1 │ 743968456275639064 │ 2026-05-15 01:04:32.45 │ s3://<バケット名> │
│ │ │ │ /datalake/googl │
│ │ │ │ e_sheets/orders/metad │
│ │ │ │ ata/snap-743968456275 │
│ │ │ │ 639064-1-d350dfd3-fbc │
│ │ │ │ 6-45da-8345-59ed06ab9 │
│ │ │ │ 9b2.avro │
└─────────────────┴────────────────────┴────────────────────────┴───────────────────────┘
Snowflake から参照
Snowflake ではカタログ統合作成時にCATALOG_SOURCE = POLARISとすることで、Polaris カタログを参照できます。
Catalog Integration の作成
Polaris を外部 Iceberg カタログとして Snowflake に登録します。
USE ROLE ACCOUNTADMIN;
CREATE OR REPLACE CATALOG INTEGRATION fivetran_polaris_ci
CATALOG_SOURCE = POLARIS
TABLE_FORMAT = ICEBERG
ENABLED = TRUE
REFRESH_INTERVAL_SECONDS = 30 -- デフォルト
REST_CONFIG = (
CATALOG_URI = '<Polaris endpoint>'
WAREHOUSE = '<Polaris catalog 名>'
ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS
)
REST_AUTHENTICATION = (
TYPE = OAUTH
OAUTH_TOKEN_URI = '<Polaris endpoint>/v1/oauth/tokens'
OAUTH_CLIENT_ID = '<Client ID>'
OAUTH_CLIENT_SECRET = '<Client Secret>'
OAUTH_ALLOWED_SCOPES = ('PRINCIPAL_ROLE:ALL')
);
ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS を指定することで、S3 アクセスを Polaris から発行される一時クレデンシャル経由にできます。
Catalog-Linked Database の作成
Catalog-Linked Database としてデータベースを作成することで、外部の Iceberg REST カタログに接続された Snowflake データベースとして機能します。
CREATE OR REPLACE DATABASE FIVETRAN_LAKE
LINKED_CATALOG = (
CATALOG = 'fivetran_polaris_ci'
);
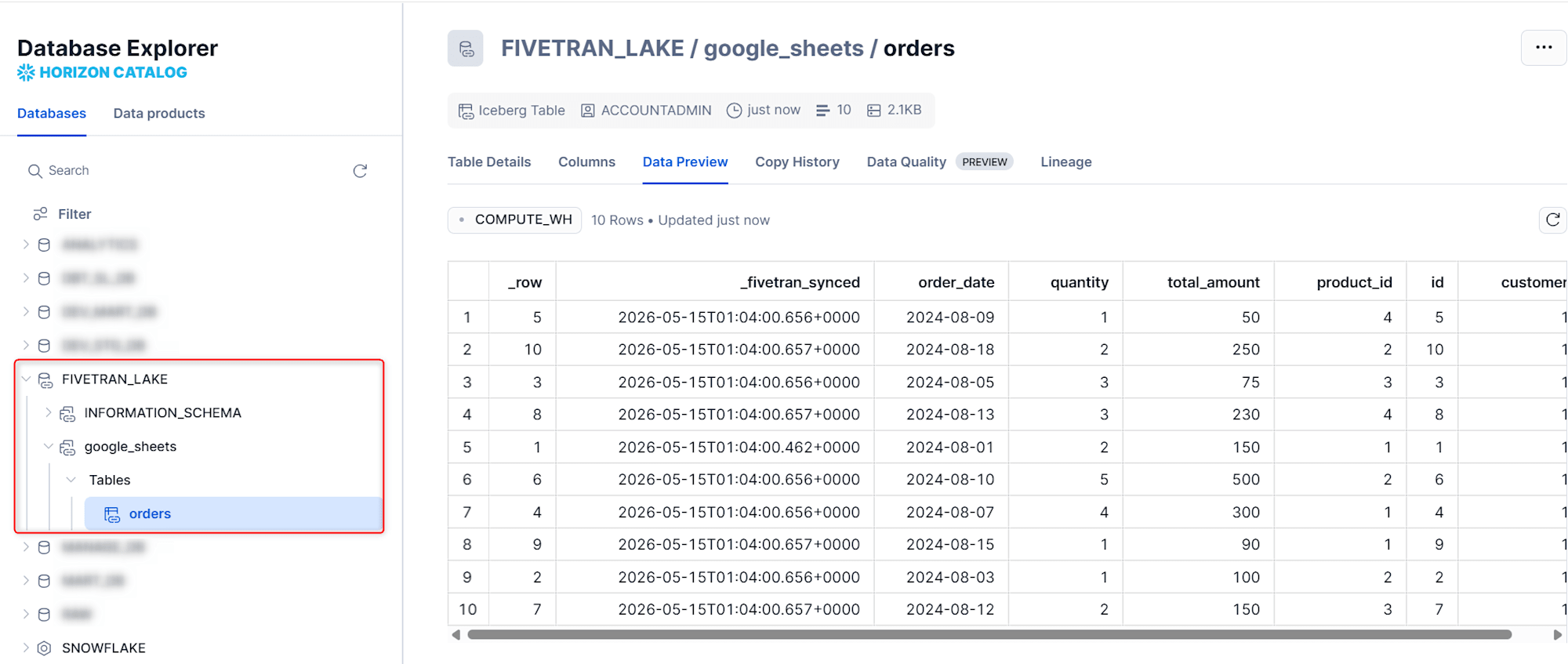
クエリ
以下のようにクエリできました。
> SHOW SCHEMAS;
+--------------------+---------------+--------------+
| name | database_name | owner |
|--------------------+---------------+--------------|
| INFORMATION_SCHEMA | FIVETRAN_LAKE | |
| google_sheets | FIVETRAN_LAKE | ACCOUNTADMIN |
+--------------------+---------------+--------------+
2 Row(s) produced.
> SHOW TABLES IN SCHEMA google_sheets;
+--------+---------------+---------------+-------+------+-------+--------------+------------+
| name | database_name | schema_name | kind | rows | bytes | owner | is_iceberg |
|--------+---------------+---------------+-------+------+-------+--------------+------------|
| orders | FIVETRAN_LAKE | google_sheets | TABLE | 10 | 2149 | ACCOUNTADMIN | Y |
+--------+---------------+---------------+-------+------+-------+--------------+------------+
1 Row(s) produced.
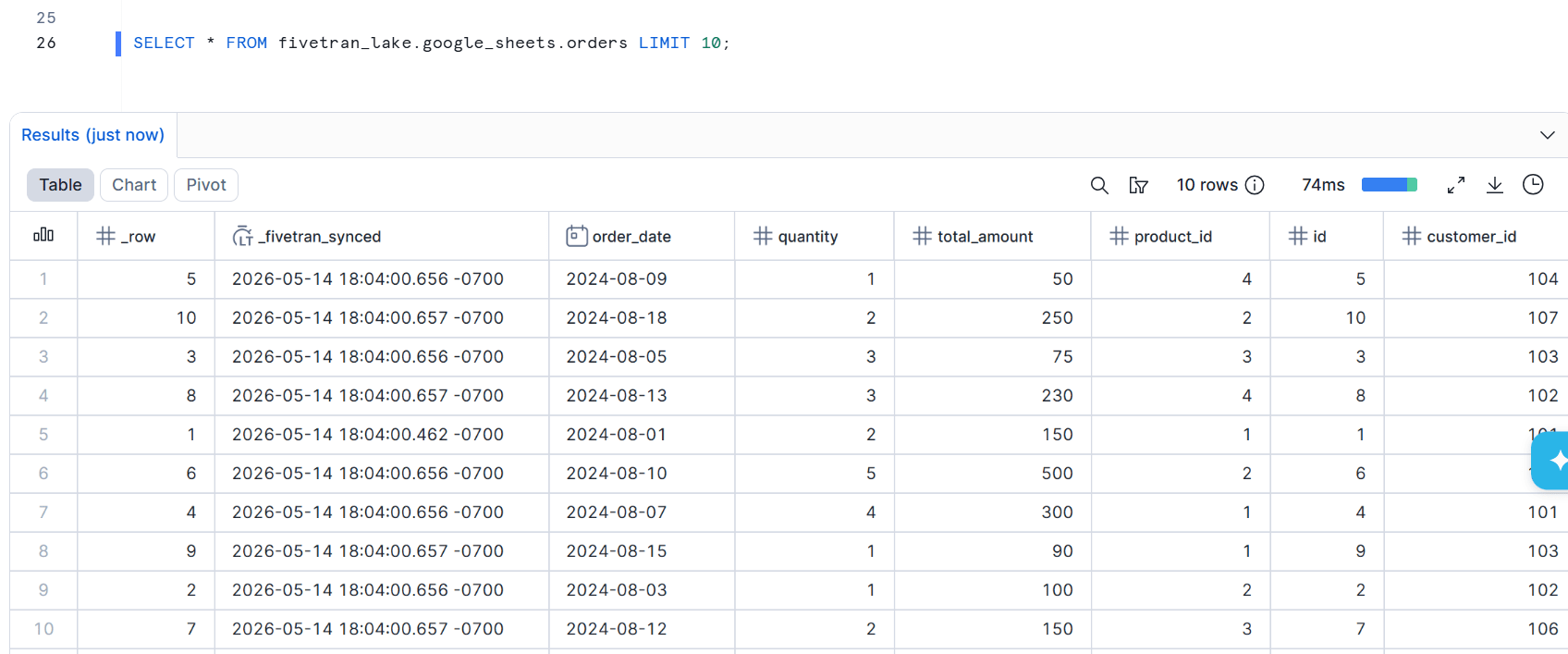
> SELECT * FROM google_sheets.orders LIMIT 10;
+------+-------------------------------+------------+----------+--------------+------------+----+-------------+
| _row | _fivetran_synced | order_date | quantity | total_amount | product_id | id | customer_id |
|------+-------------------------------+------------+----------+--------------+------------+----+-------------|
| 5 | 2026-05-14 18:04:00.656 -0700 | 2024-08-09 | 1 | 50 | 4 | 5 | 104 |
| 10 | 2026-05-14 18:04:00.657 -0700 | 2024-08-18 | 2 | 250 | 2 | 10 | 107 |
| 3 | 2026-05-14 18:04:00.656 -0700 | 2024-08-05 | 3 | 75 | 3 | 3 | 103 |
| 8 | 2026-05-14 18:04:00.657 -0700 | 2024-08-13 | 3 | 230 | 4 | 8 | 102 |
| 1 | 2026-05-14 18:04:00.462 -0700 | 2024-08-01 | 2 | 150 | 1 | 1 | 101 |
| 6 | 2026-05-14 18:04:00.656 -0700 | 2024-08-10 | 5 | 500 | 2 | 6 | 105 |
| 4 | 2026-05-14 18:04:00.656 -0700 | 2024-08-07 | 4 | 300 | 1 | 4 | 101 |
| 9 | 2026-05-14 18:04:00.657 -0700 | 2024-08-15 | 1 | 90 | 1 | 9 | 103 |
| 2 | 2026-05-14 18:04:00.656 -0700 | 2024-08-03 | 1 | 100 | 2 | 2 | 102 |
| 7 | 2026-05-14 18:04:00.657 -0700 | 2024-08-12 | 2 | 150 | 3 | 7 | 106 |
+------+-------------------------------+------------+----------+--------------+------------+----+-------------+
10 Row(s) produced. Time Elapsed: 2.748s
SHOW TABLESの結果から is_iceberg = Y となっていることが確認でき、Snowflake 側でも Iceberg テーブルとして認識されていることがわかります。
参考までに、Iceberg メタデータのフォーマットバージョンも確認しておきます。
> SHOW PARAMETERS LIKE 'ICEBERG_VERSION' IN TABLE fivetran_lake.google_sheets.orders;
+-----------------+-------+---------+-------+----------------------------------------------------------------------------------------------------------------------------------------------+--------+
| key | value | default | level | description | type |
|-----------------+-------+---------+-------+----------------------------------------------------------------------------------------------------------------------------------------------+--------|
| ICEBERG_VERSION | 2 | 2 | | Iceberg metadata format version for Iceberg tables. Note: the default value must be synced with the default value of ICEBERG_VERSION_DEFAULT | NUMBER |
+-----------------+-------+---------+-------+----------------------------------------------------------------------------------------------------------------------------------------------+--------+
value = 2 となっており、Fivetran Managed Data Lake のテーブルが Iceberg v2 仕様で書かれていることが確認できます。
Databricks から参照
Databricks の Catalog Federation 機能は、現時点で Hive metastore / AWS Glue / Salesforce Data 360 / Snowflake をサポートしており、Apache Polaris は公式の対応カタログ一覧には含まれていません。
Fivetran Managed Data Lake は同じ Parquet 群に対して Iceberg と Delta の両方のメタデータを同期書き込みしているため、Databricks 側からは Delta テーブルとして S3 上のデータを直接参照してみます。
より具体的には、Unity Catalog の External Location を経由して Delta テーブルを参照してみます。
外部ロケーションの作成
こちらは以下の記事の「S3 を使用する外部ロケーションの作成」と同様の手順で作成しました。詳細はこちらをご参照ください。
クエリ
外部ロケーション作成後は、「delta.s3://...」形式で、パス指定で直接 Delta テーブルとして参照できます。
SELECT *
FROM delta.`s3://<バケット名>/datalake/google_sheets/orders`;
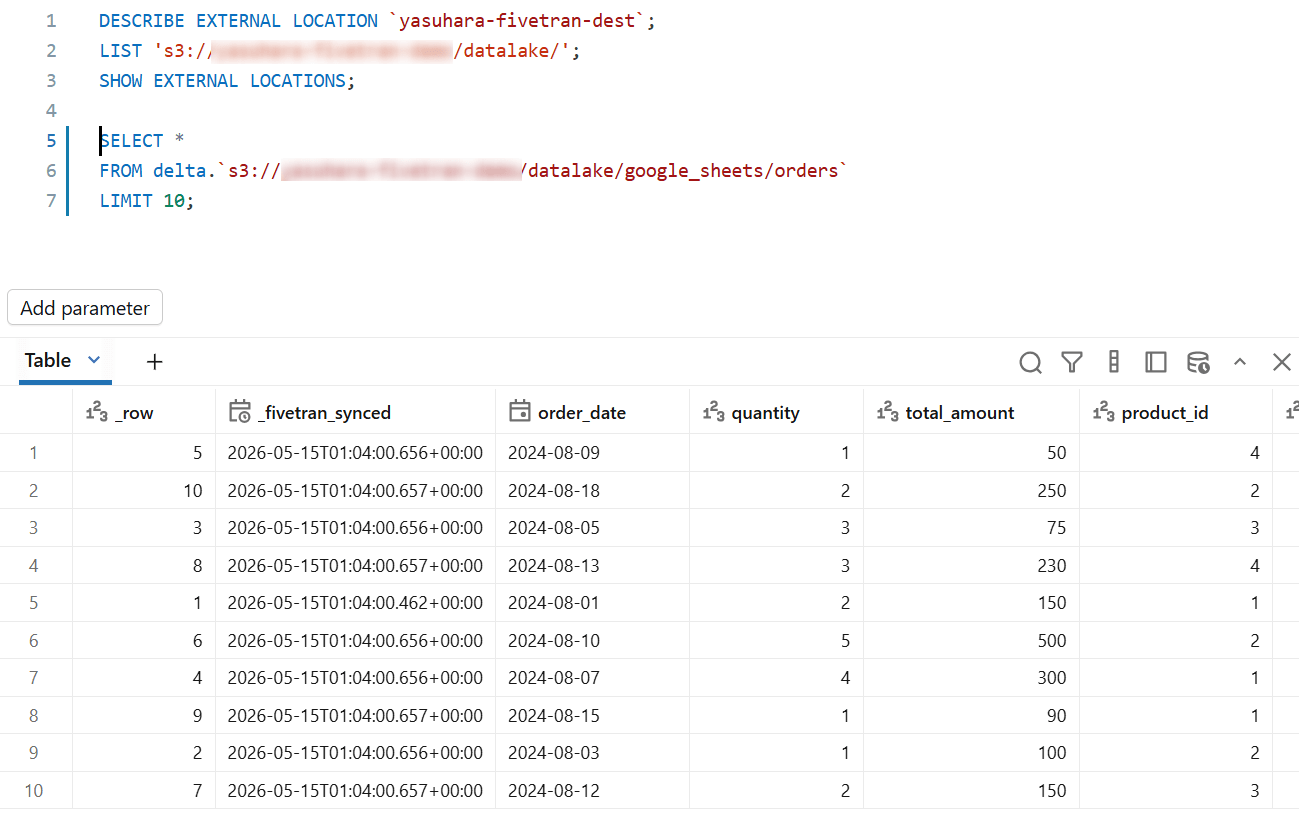
DuckDB / Snowflake で取得した結果と件数・値が一致していることが確認できます。同一の S3 上 Parquet を、それぞれのエンジンが Iceberg メタデータ経由(DuckDB / Snowflake)と Delta メタデータ経由(Databricks)で読み取っている形になっています。
Unity Catalog のテーブルとして登録して扱いたい場合は、で外部テーブルを定義する方法もあります。
CREATE TABLE workspace.default.orders
LOCATION 's3://<バケット名>/datalake/google_sheets/orders';
SELECT * FROM workspace.default.orders;
レコードを追加
最後に、データソース側(Google Sheets)でレコードを追加し再度同期し、データを各クエリエンジンから参照してみます。
DuckDB
D SELECT * FROM polaris_catalog.google_sheets.orders;
────────────────────────────┬────────────┬───┬───────┬─────────────┐
│ _row │ _fivetran_synced │ order_date │ … │ id │ customer_id │
│ int64 │ timestamp with time zone │ date │ … │ int32 │ int32 │
├───────┼────────────────────────────┼────────────┼───┼───────┼─────────────┤
│ 5 │ 2026-05-15 13:53:18.38+09 │ 2024-08-09 │ … │ 5 │ 104 │
│ 10 │ 2026-05-15 13:53:18.38+09 │ 2024-08-18 │ … │ 10 │ 107 │
│ 3 │ 2026-05-15 13:53:18.38+09 │ 2024-08-05 │ … │ 3 │ 103 │
│ 8 │ 2026-05-15 13:53:18.38+09 │ 2024-08-13 │ … │ 8 │ 102 │
│ 13 │ 2026-05-15 13:53:18.381+09 │ 2024-08-22 │ … │ 13 │ 109 │
│ 1 │ 2026-05-15 13:53:18.189+09 │ 2024-08-01 │ … │ 1 │ 101 │
│ 6 │ 2026-05-15 13:53:18.38+09 │ 2024-08-10 │ … │ 6 │ 105 │
│ 11 │ 2026-05-15 13:53:18.38+09 │ 2024-08-21 │ … │ 11 │ 108 │
│ 4 │ 2026-05-15 13:53:18.38+09 │ 2024-08-07 │ … │ 4 │ 101 │
│ 9 │ 2026-05-15 13:53:18.38+09 │ 2024-08-15 │ … │ 9 │ 103 │
│ 2 │ 2026-05-15 13:53:18.38+09 │ 2024-08-03 │ … │ 2 │ 102 │
│ 7 │ 2026-05-15 13:53:18.38+09 │ 2024-08-12 │ … │ 7 │ 106 │
│ 12 │ 2026-05-15 13:53:18.381+09 │ 2024-08-21 │ … │ 12 │ 108 │
└───────┴────────────────────────────┴────────────┴───┴───────┴─────────────┘
13 rows use .last to show entire result 8 columns (5 shown)
Snowflake
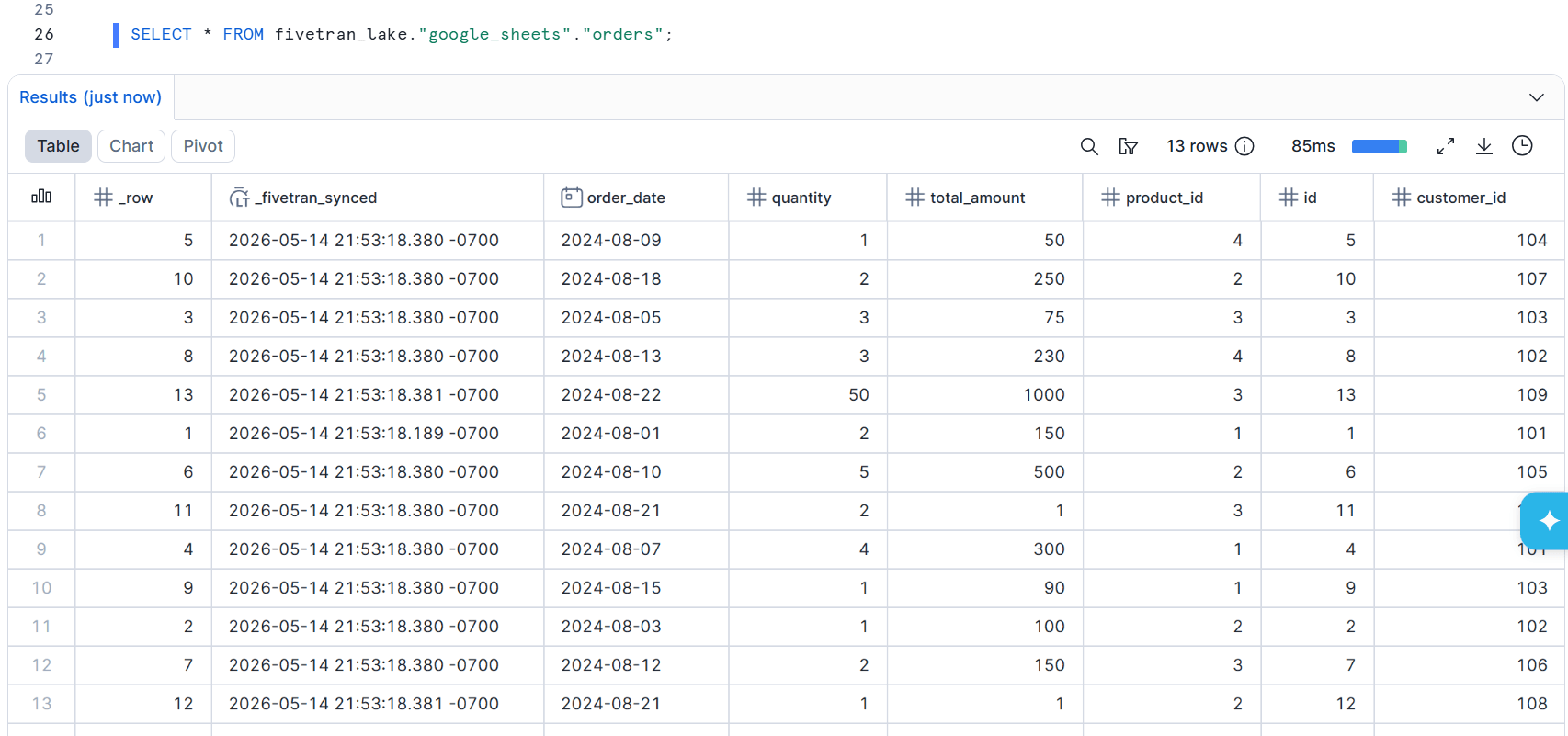
Databricks
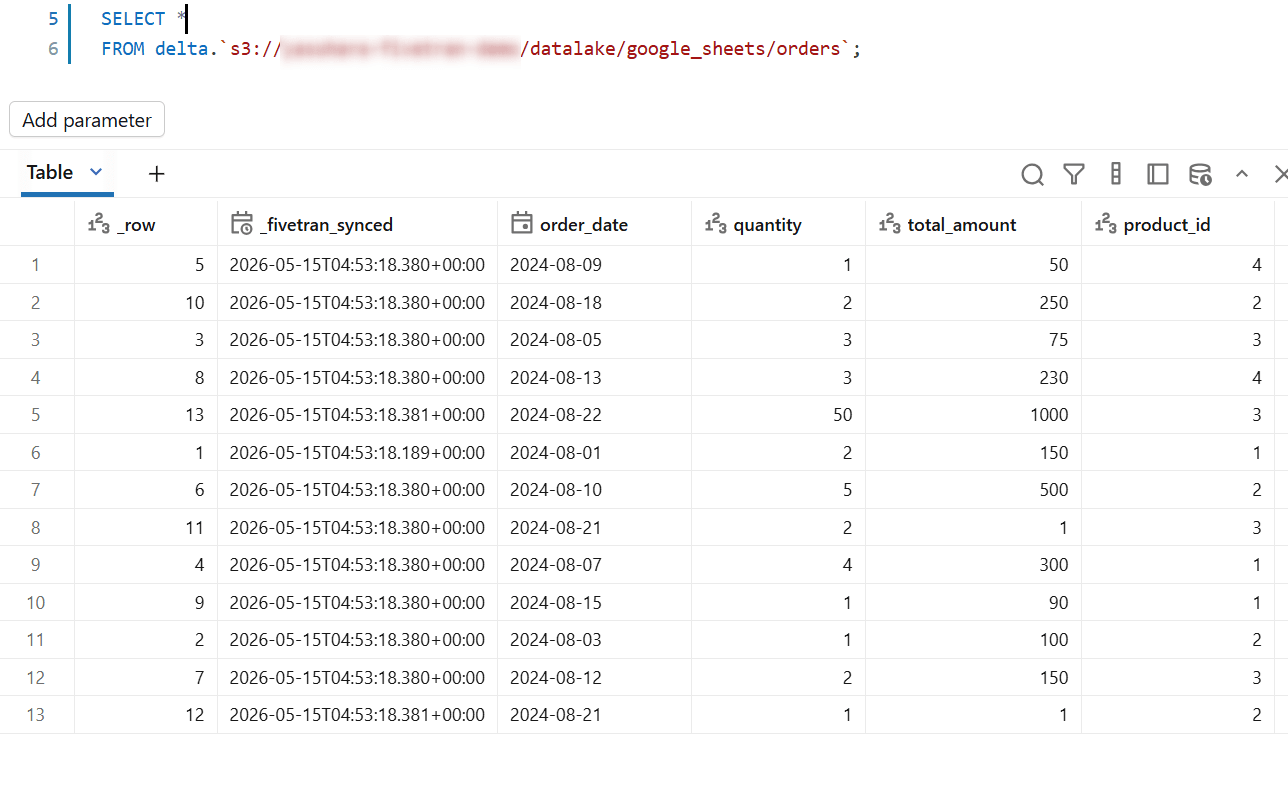
各クエリエンジンで更新後の結果を確認できました。
さいごに
Fivetran Managed Data Lake Service で構築した S3 上のテーブルを、DuckDB / Snowflake / Databricks の3エンジンから参照する手順を確認してみました。
Iceberg と Delta の両メタデータが同時に維持されることで、各エンジンの得意な経路を選びつつ、同一データレイクをマルチエンジンで活用できることが分かりました。
こちらの内容がどなたかの参考になれば幸いです。









