[新機能]Fivetranが日本語カラムにも対応!Fivetranの命名規則「Source Naming」を試してみた
さがらです。
Fivetranのコネクタセットアップ時に選択できる命名規則である「Source Naming」を使って、日本語カラムをそのままDestinationのDWHにロードすることを検証してみたので、その内容について本記事でまとめます。
Source Namingとは
Source Namingとは、Fivetranがソース(データ取得元)のスキーマ名、テーブル名、カラム名をそのまま変更せずにDestination(DWH)にロードする命名規則オプションです。
通常、FivetranはDestinationにデータをロードする際に独自の命名規則(Fivetran Naming)を適用しますが、Source Namingを有効にすると、UTF-8の値を持つ元のソース名がそのまま保持されます。これにより、日本語のカラム名やテーブル名をそのままDWHに反映させることが可能になります。
Source Namingの注意点
以下のような注意点があるため、ご注意ください。
- 初期同期前にのみ設定可能:一度初期同期が開始されると、Source Namingへの変更や既存コネクタのSource Namingへの移行はできません
- Destinationの制約:Destination側で予約語や制限がある場合、該当するスキーマ、テーブル、カラムは同期から除外され、警告メッセージが表示されます
- QuickStart transformationsとの非互換:Source Namingを有効にすると、QuickStart transformationsは自動的に無効化されます
- サポートしているコネクタやDestinationは一部のみ:詳細はこちらの公式Docをご覧ください。
- スキーマ名・テーブル名・カラム名が全て
"で囲われたDDL文でテーブルが作成される ※詳細は末尾の「今回の検証で気になった点」をご覧ください。
「Source Namingって前からありましたよね?」と感じた方へ
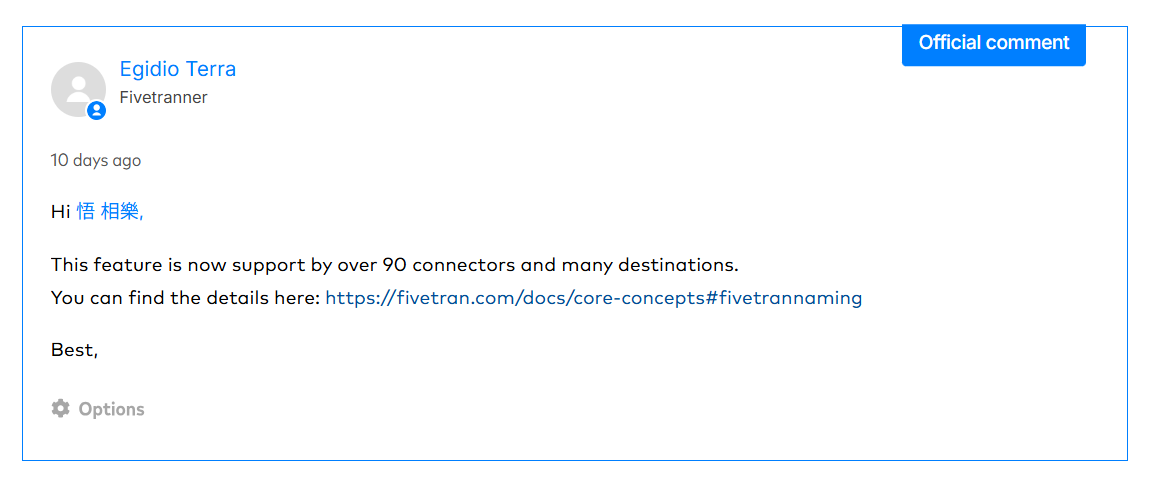
実はその通りで、以下の2025年4月の記事でも記述があります。そのため、完全な新機能ではないのですが、2025年4月時点では対応コネクタが数個しかありませんでした。
しかし直近のアップデートで、90種以上のコネクタにSource Namingが対応したと以下のFeature Requestsで回答がありました!そのため、改めて試してみようと思った次第です。
試してみた
ということで、実際にSource Namingを試してみます。
事前準備:DWHの準備とDestinationの設定
DestinationとなるDWHは、Snowflakeを使用します。
Destinationのセットアップについては触れませんが、以下の公式Docやブログが参考になると思います。
事前準備:データソース
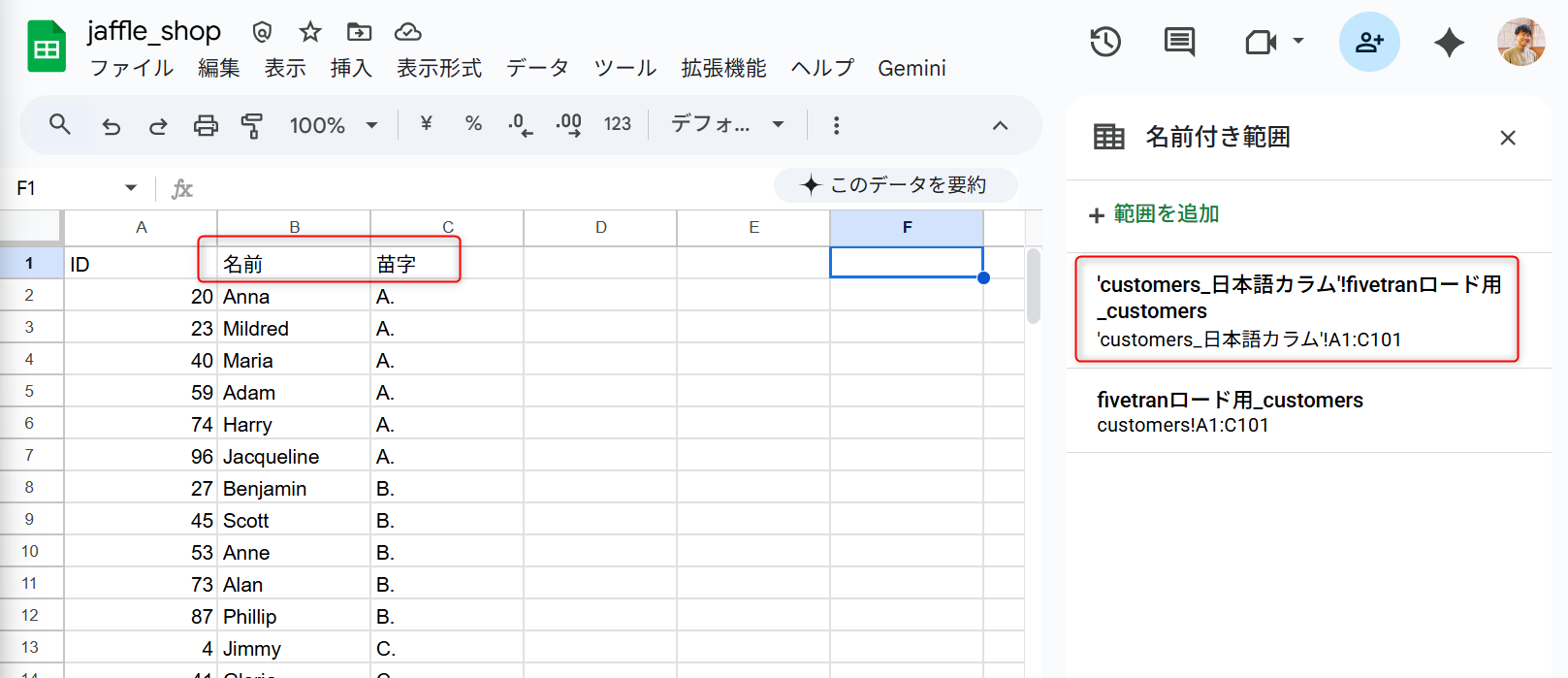
今回データソースとして、Googleスプレッドシートを用意しました。
以下のようにカラム名を名前と苗字にして、Fivetranでロードするために必要な名前付き範囲も作成しておきます。
Source Namingを設定して、コネクタを作成
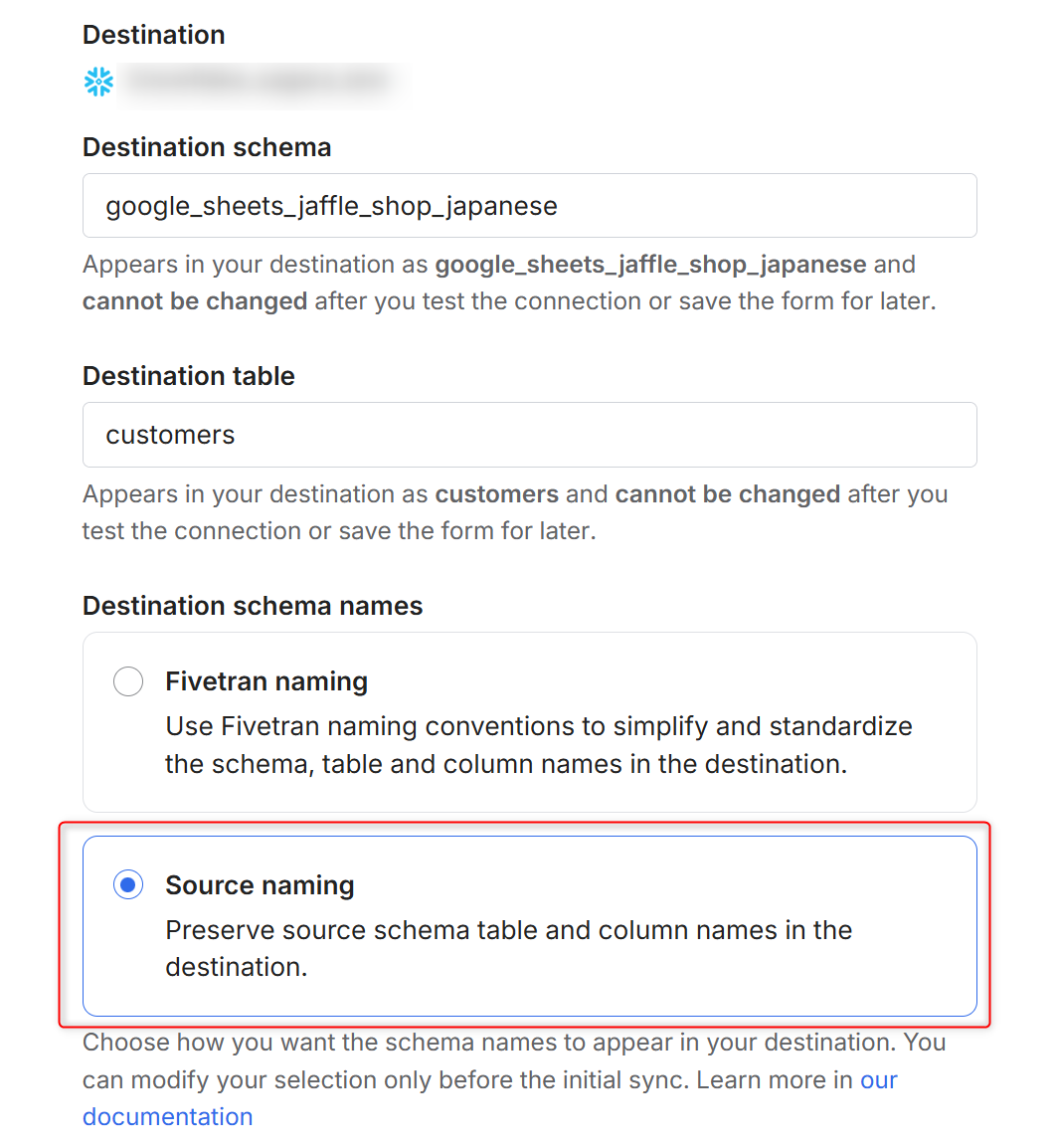
続いてGoogleスプレッドシート用のコネクタを作成するのですが、下図のようにDestination schema namesでSource namingを選択するのがポイントです。
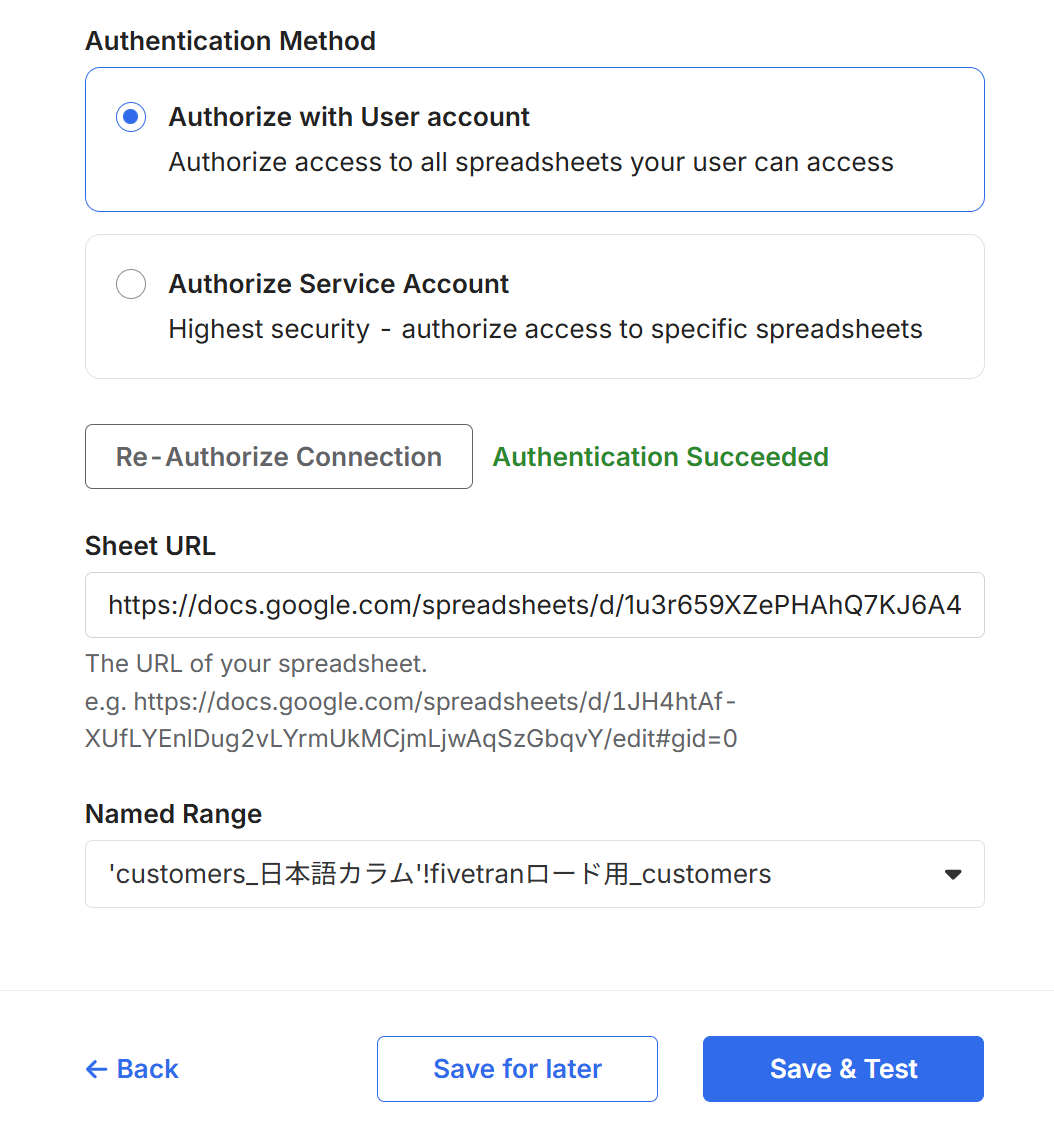
後は通常のGoogleスプレッドシートのコネクタのセットアップと同じ手順ですので、認証を行って名前付き範囲を設定して、Save&Testを押します。
Initial Sync後の動作確認
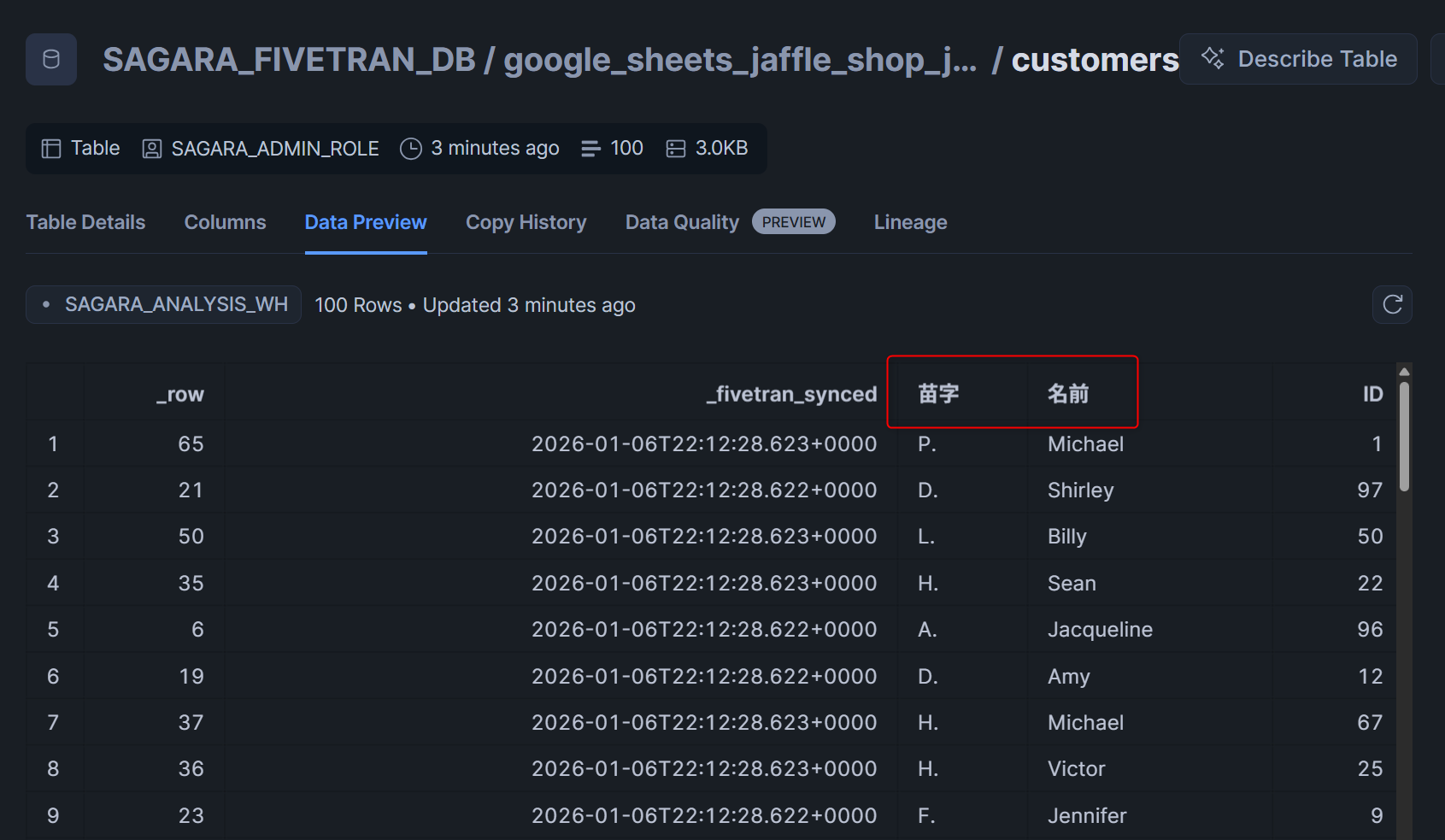
Initial Syncが完了したら、どのようにデータがロードされたかを確認してみます。
確認すると、下図のように日本語カラムがそのままの形でロードされていました!
今回の検証で気になった点
いつも通り何も気にせず、Fivetranのコネクタ設定時にスキーマ名もテーブル名も小文字で入力していたのですが、Source Namingの場合のみ、スキーマ名・テーブル名・カラム名が"で囲われたDDL文になっていることに気づきました。 確かに日本語カラムに対応させるにはこうするしかないのですが、カラム名が日本語でもスキーマ名やテーブル名は半角英数字であることも多いと思いますので、ロード後にクエリを発行する際に注意が必要となってきます。
実際の様子は下図をご覧ください。このため現状はSource Namingを使用する場合は、「コネクタの設定でスキーマ名とテーブル名を大文字で入力しておく」、「データソースのテーブルで日本語カラムと英語カラムが混じっている場合は、英語カラムは半角大文字で定義しておく」を行っておくと、クエリで参照する際に"をつけなくて済むようになります。
※ただ、上記の対策を行ってもFivetranによって作られるシステムカラムは全て小文字で"で囲われてしまうため、これはFeature Requestsをしておきます。
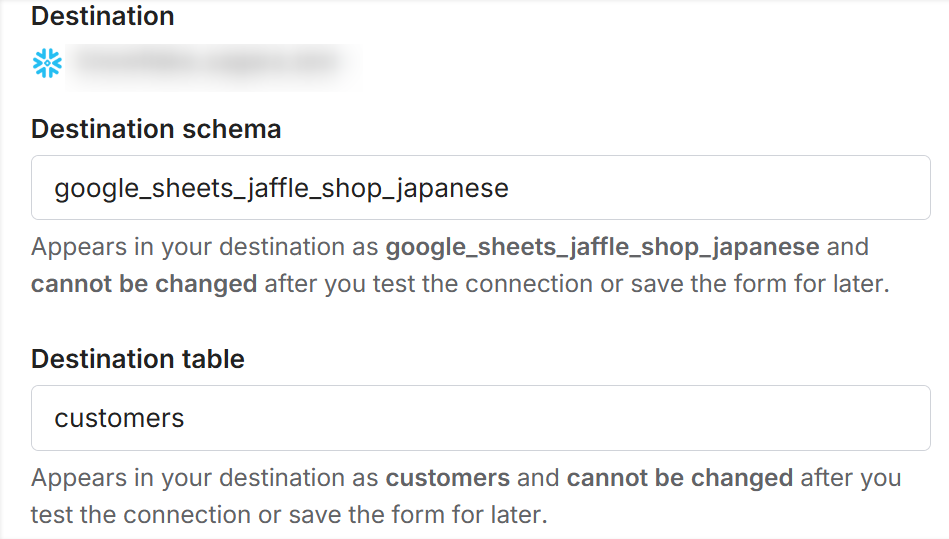
- Fivetranのコネクタ設定時の入力(スキーマ名もテーブル名も小文字)
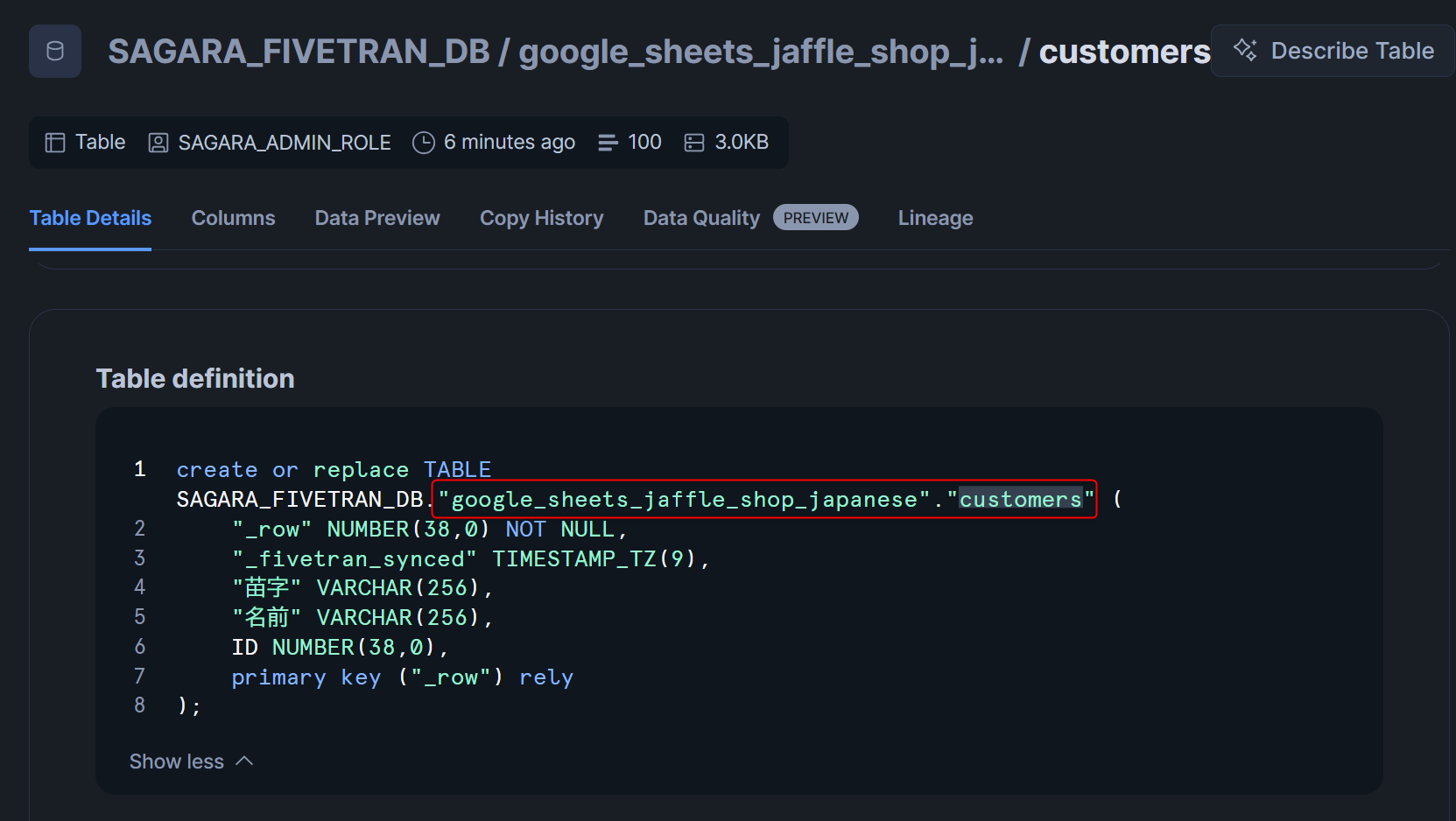
- Source Namingでロードした場合のDDL文:スキーマ名とテーブル名が
"で囲われているため、クエリ発行時に"でスキーマ名とテーブル名を囲んで小文字で参照しないといけない
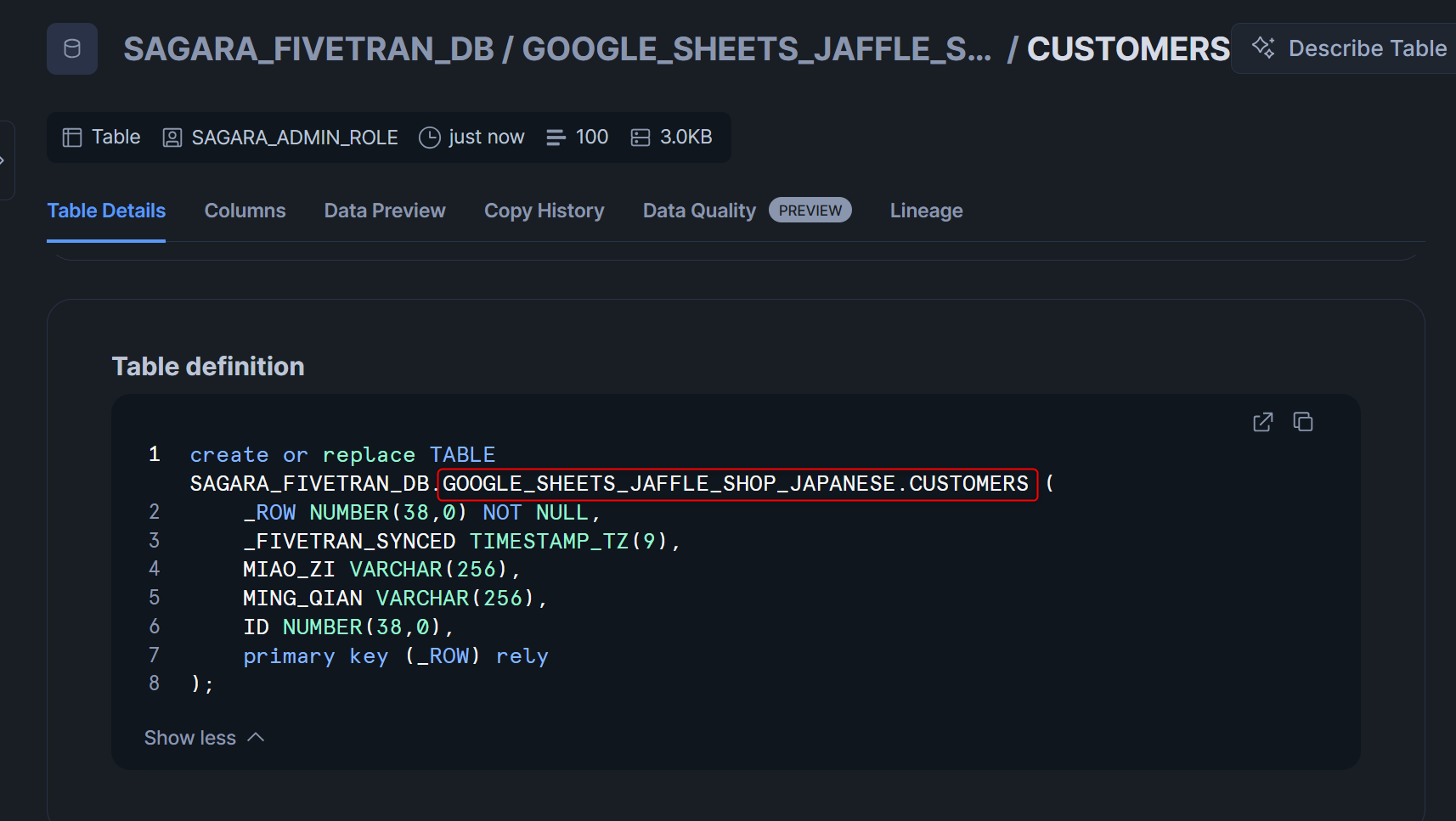
- Fivetran Namingでロードした場合のDDL文
最後に
Fivetranのコネクタセットアップ時に選択できる命名規則である「Source Naming」を使って、日本語カラムをそのままDestinationのDWHにロードすることを検証してみました。
注意点はいくつかありますが、データソースで日本語カラムが使われている場合には役立つ機能だと思います。ぜひご活用ください!







