
Amazon Forecastにwhat-if分析機能が追加:関連する時系列データが変化した際の動きを分析可能になりました
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんちには。
データアナリティクス事業本部機械学習チームの中村です。
今回はAmazon Forecastの新機能であるwhat-if分析についてご紹介します。
AWS公式ブログでは以下の記事で紹介されています。
Amazon Forecastの概要
まずAmazon Forecastの概要をおさらいします。
Amazon Forecastは時系列データを予測するサービスです。
入力できる情報には以下の3種類があります。
- TARGET_TIME_SERIES(TTS)
- 予測対象(ターゲット)となる時系列データ。(例: 需要予測の場合は需要のデータ)
- 時系列で変化しない情報(例: 店舗ID)を含めることで分析軸を追加可能。
- RELATED_TIME_SERIES(RTS)
- 関連する時系列データ。(例: 需要予測の場合は価格など)
- TTSに付加した分析軸はこちらにも追加が必要。
- ITEM_METADATA
- アイテムのメタデータを追加することが可能。(例: 商品のブランドなど)
TTSは全てのケースでおいて必須のデータですが、what-if分析ではRTSも必要となります。
what-if分析とは
what-if分析はRTSが変化した際に、TTSがどのように変化するかを分析するための機能です。
例えば「需要予測」の場合は、「需要(TTS)」とは別の関連する時系列データである「価格(RTS)」を過去に遡って下げたと仮定した場合に、 予測した「需要(TTS)」がどの程度変化するのかを分析することが可能になります。
また、Amazon Forecastにかかる費用は以下の通りです。
- データのインポート
- Predictorのトレーニング
- 予測したデータポイント数
- 予測の説明
このうち、What-if分析はデータポイントを予測するため、「予測したデータポイント数」の部分にコストが掛かってくるのでご注意ください。
(実際本記事の通りに実行すると、60ドル程度は必要になりますので留意頂ければと思います)
what-if分析のトライ
今回関連するリソースは以下のような階層構造になっています。
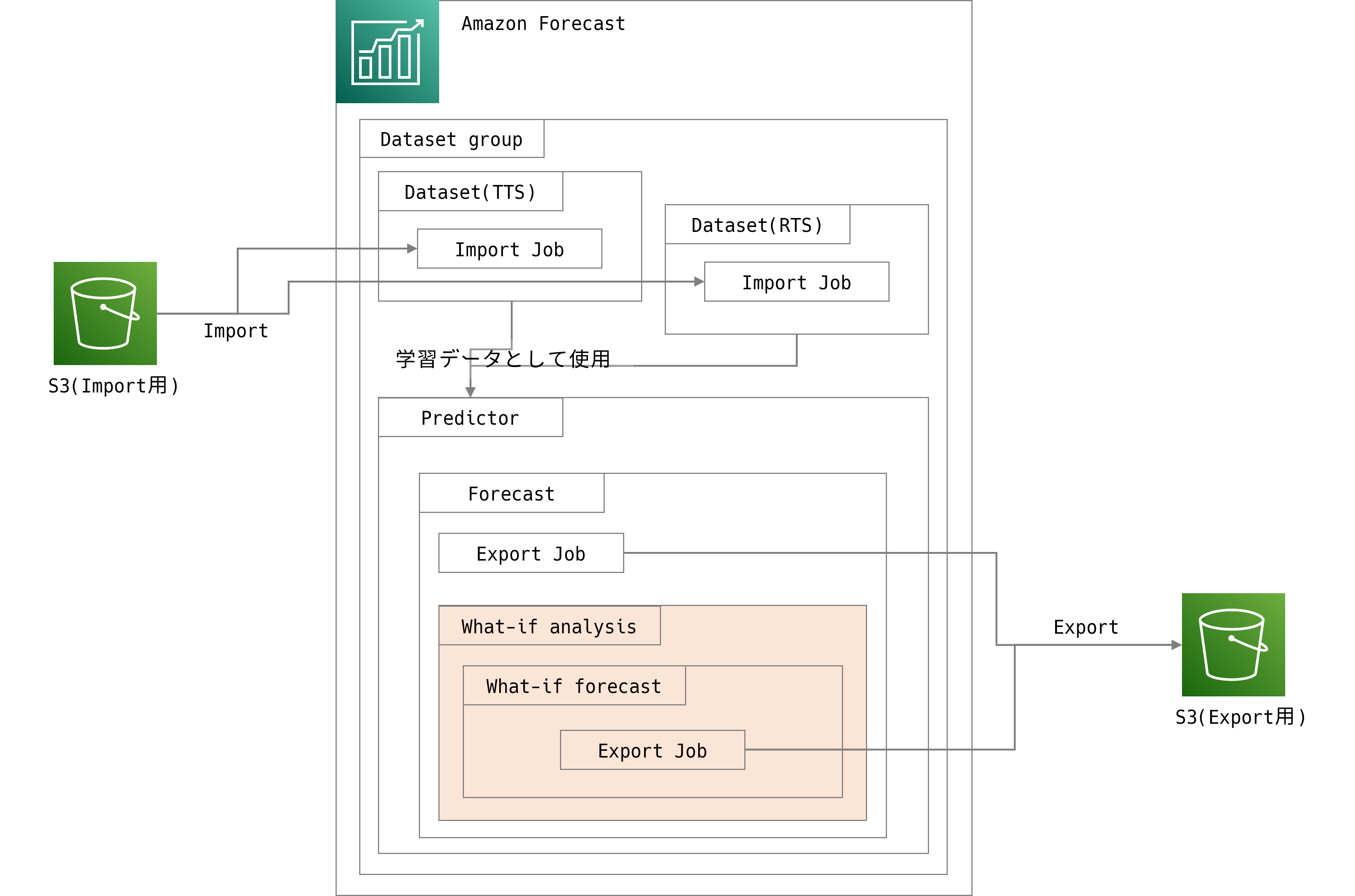
What-if分析に相当するのは、オレンジ部分で、一旦Forecastまで作成した上で構築する必要があります。
S3の準備
事前にバケット作成しておきます。(今回は以下)
- バケット名: sample-nakamura-2022-09-09-forecast
以下のGitHubに、公開されているデータセットがあります。
ここから以下の2つのファイルをダウンロードします。
- consumer_electronics_TTS.csv
- consumer_electronics_RTS.csv
これらをS3のそれぞれアップロードしておきます。(今回は以下)
- s3://sample-nakamura-2022-09-09-forecast/target/consumer_electronics_TTS.csv
- s3://sample-nakamura-2022-09-09-forecast/related/consumer_electronics_RTS.csv
Dataset group作成
「View dataset groups」を押下し、データセットグループ一覧を表示します。

「Create dataset group」を押下します。
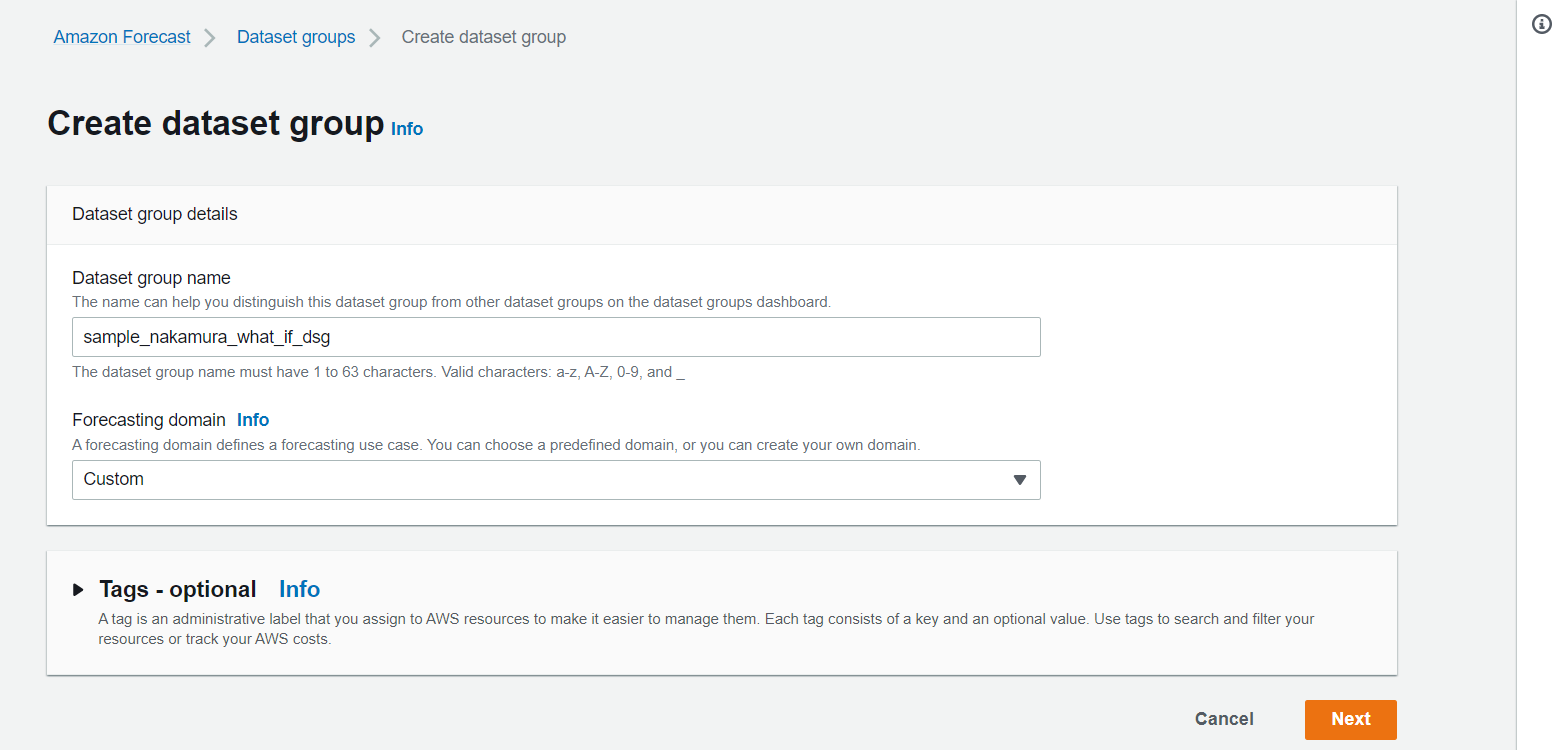
Dataset groupの情報を以下のように入力し、末尾の「Next」を押下します。
- Dataset group name: sample_nakamura_what_if_dsg
- Forecasting domain: Custom
Dataset(ターゲット側)作成
Datasetの情報を以下のように入力します。
- Dataset name: sample_nakamura_what_if_tts
- Frequency of your data: 1 months
- Data schema: JSON builderをチェック
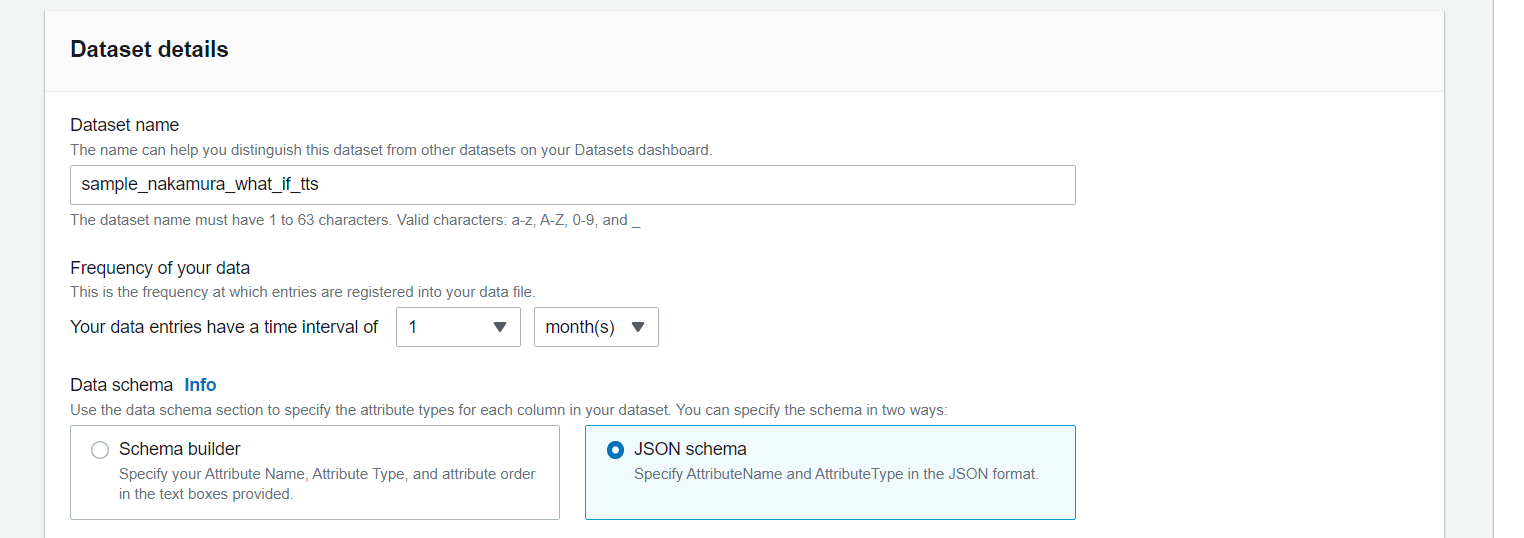
またJSON schemaには以下を設定し、Timestamp formatにはyyyy-MM-ddを設定します。
{
"Attributes": [
{
"AttributeName": "item_id",
"AttributeType": "string"
},
{
"AttributeName": "store_id",
"AttributeType": "string"
},
{
"AttributeName": "timestamp",
"AttributeType": "timestamp"
},
{
"AttributeName": "target_value",
"AttributeType": "float"
}
]
}
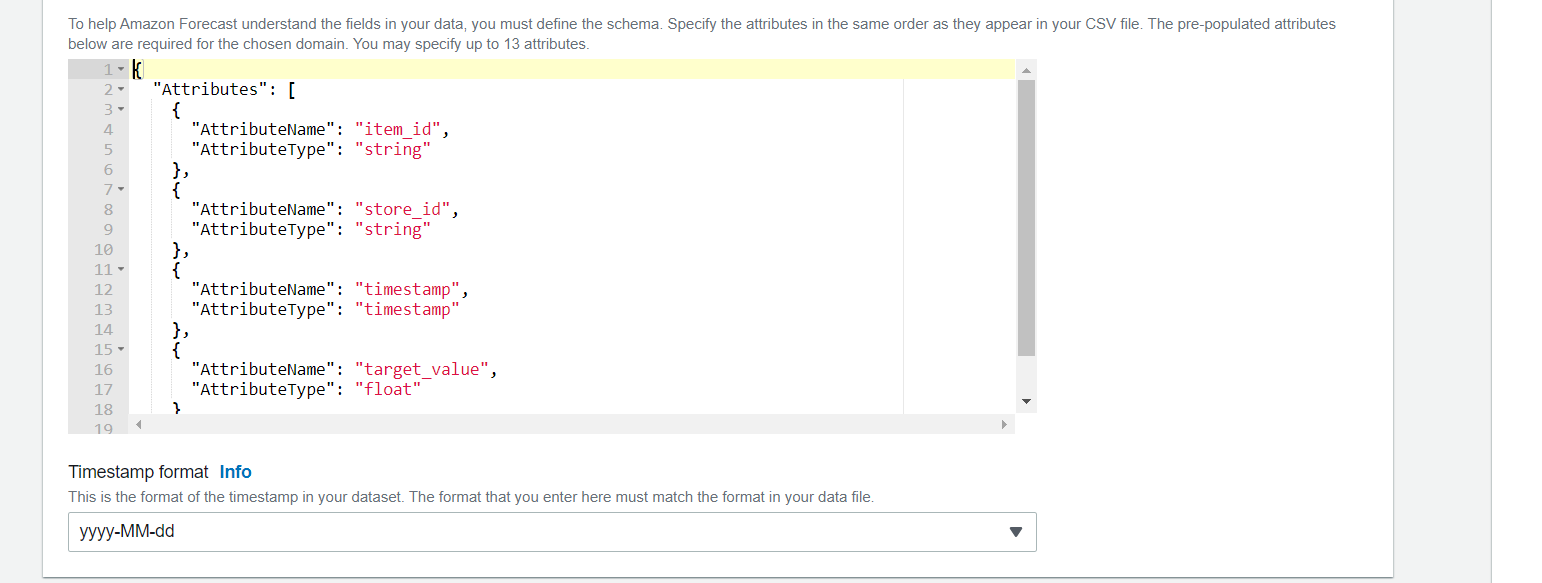
Dataset importの設定は以下とします。
- Dataset import name: sample_nakamura_what_if_tts_import
- Select time zone: Do not use time zone
- Import file type: CSV
- Data location: s3://sample-nakamura-2022-09-09-forecast/target/consumer_electronics_TTS.csv
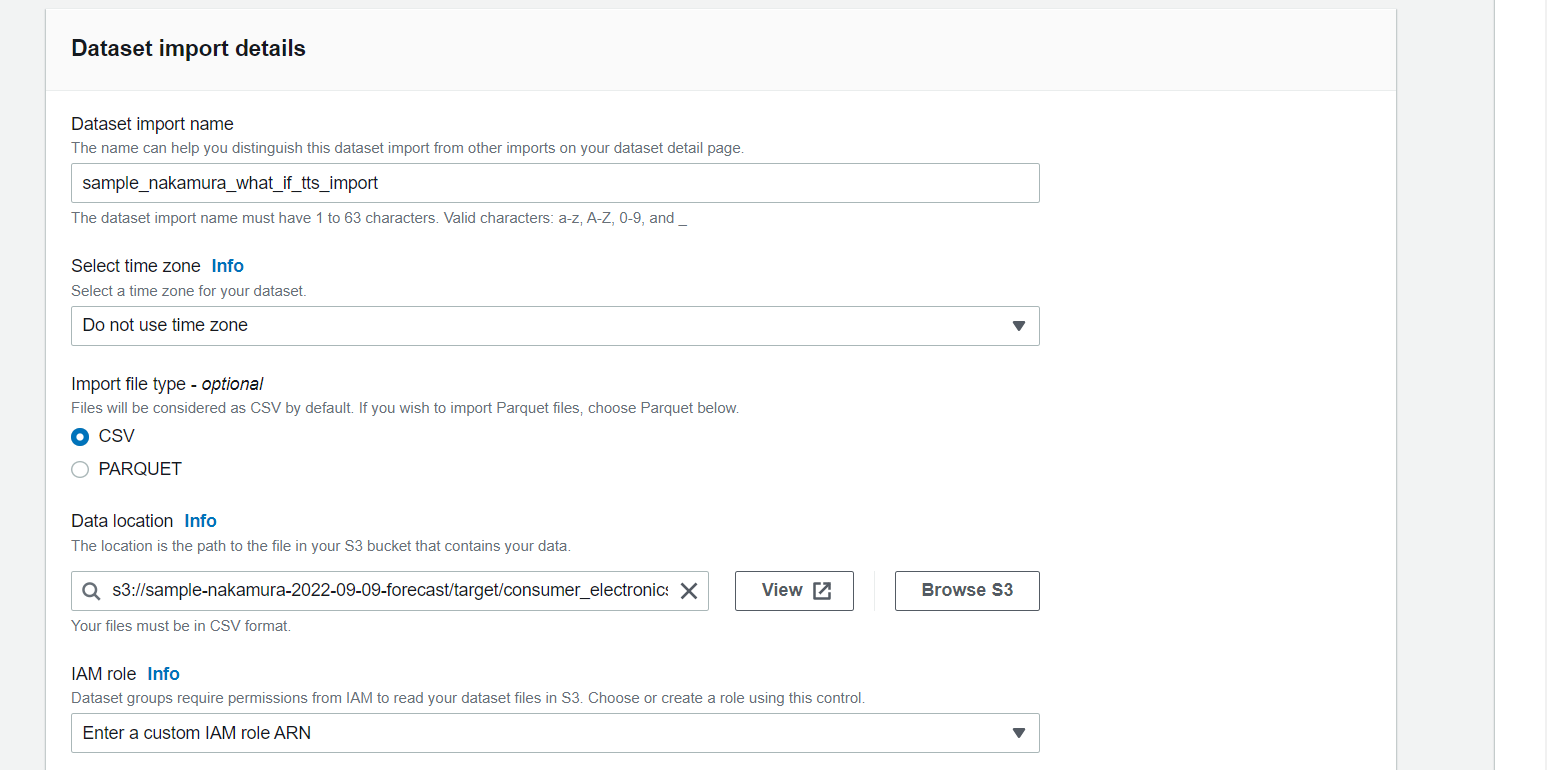
IAM roleは、Create a New Roleを選択すると以下のダイアログがでるので、
Specific S3 bucketsを以下のように設定して、「Create role」を押下します。
- sample-nakamura-2022-09-09-forecast
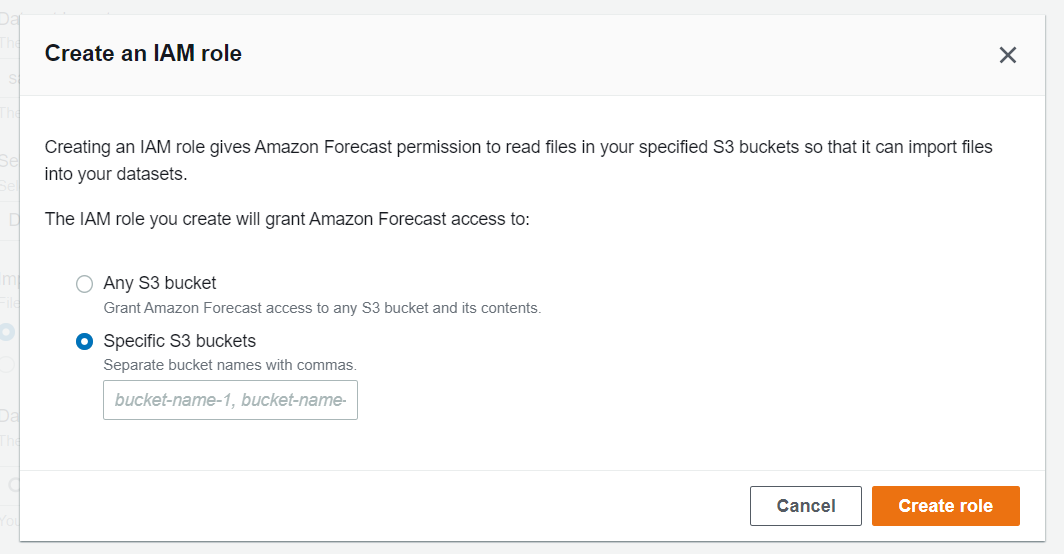
ちなみに作成されるロールにアタッチされるポリシーは以下のようになります。
(書き込み権限もあるので、後述のエクスポート時もこちらを使用していきます。)
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3:ListBucket"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::sample-nakamura-2022-09-09-forecast"
]
},
{
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::sample-nakamura-2022-09-09-forecast/*"
]
}
]
}
ロールが作成されるので、その後「Start」を押下します。
その後Importが開始されます。
Dataset group一覧から作成したDataset groupを選択すると、
直後は「Create pending」となっているため、以下のようにActiveとなるまで待ちます。
Dataset(関連データ側)作成
what-if分析には、Related time series dataが必要となるため、上記の画面で「Import」を押下します。
Datasetの情報を以下で入力します。
- Dataset name: sample_nakamura_what_if_rts
- Frequency of your data: 1 months
- Data schema: JSON builderをチェック
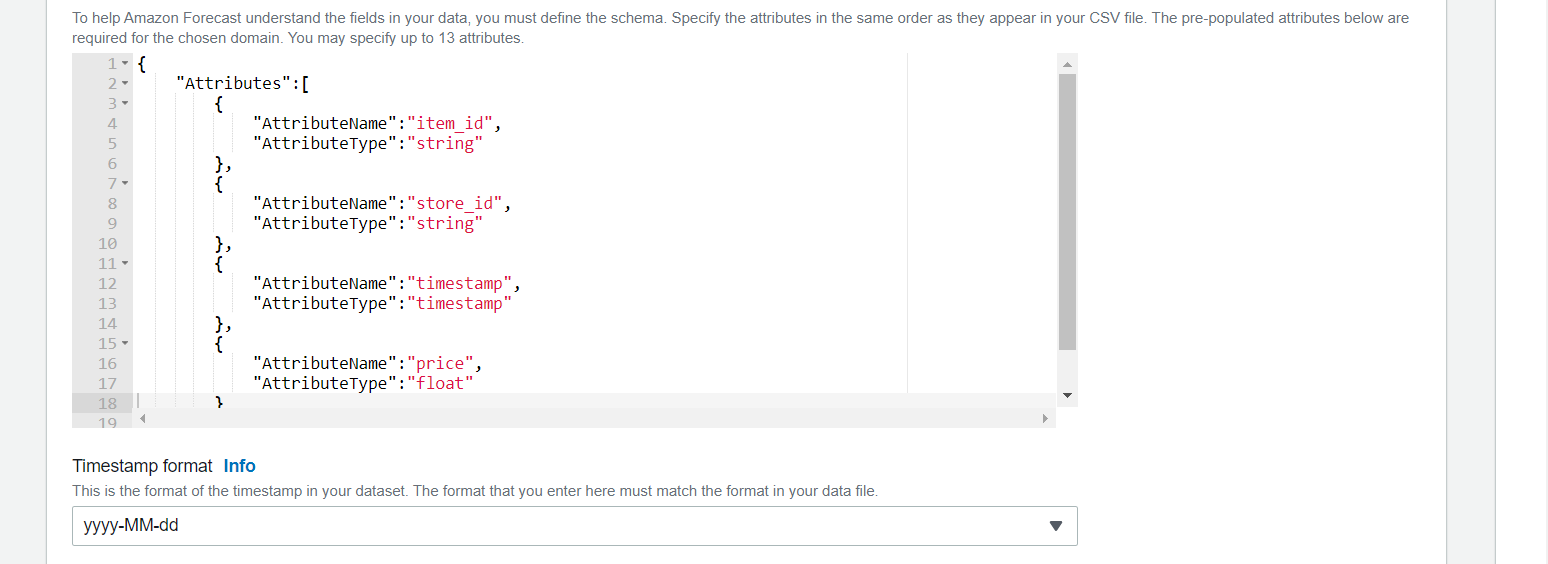
またJSON schemaには以下を設定し、Timestamp formatにはyyyy-MM-ddを設定します。
{
"Attributes":[
{
"AttributeName":"item_id",
"AttributeType":"string"
},
{
"AttributeName":"store_id",
"AttributeType":"string"
},
{
"AttributeName":"timestamp",
"AttributeType":"timestamp"
},
{
"AttributeName":"price",
"AttributeType":"float"
},
]
}
Dataset importの設定は以下とします。
- Dataset import name: sample_nakamura_what_if_rts_import
- Select time zone: Do not use time zone
- Import file type: CSV
- Data location: s3://sample-nakamura-2022-09-09-forecast/target/consumer_electronics_RTS.csv
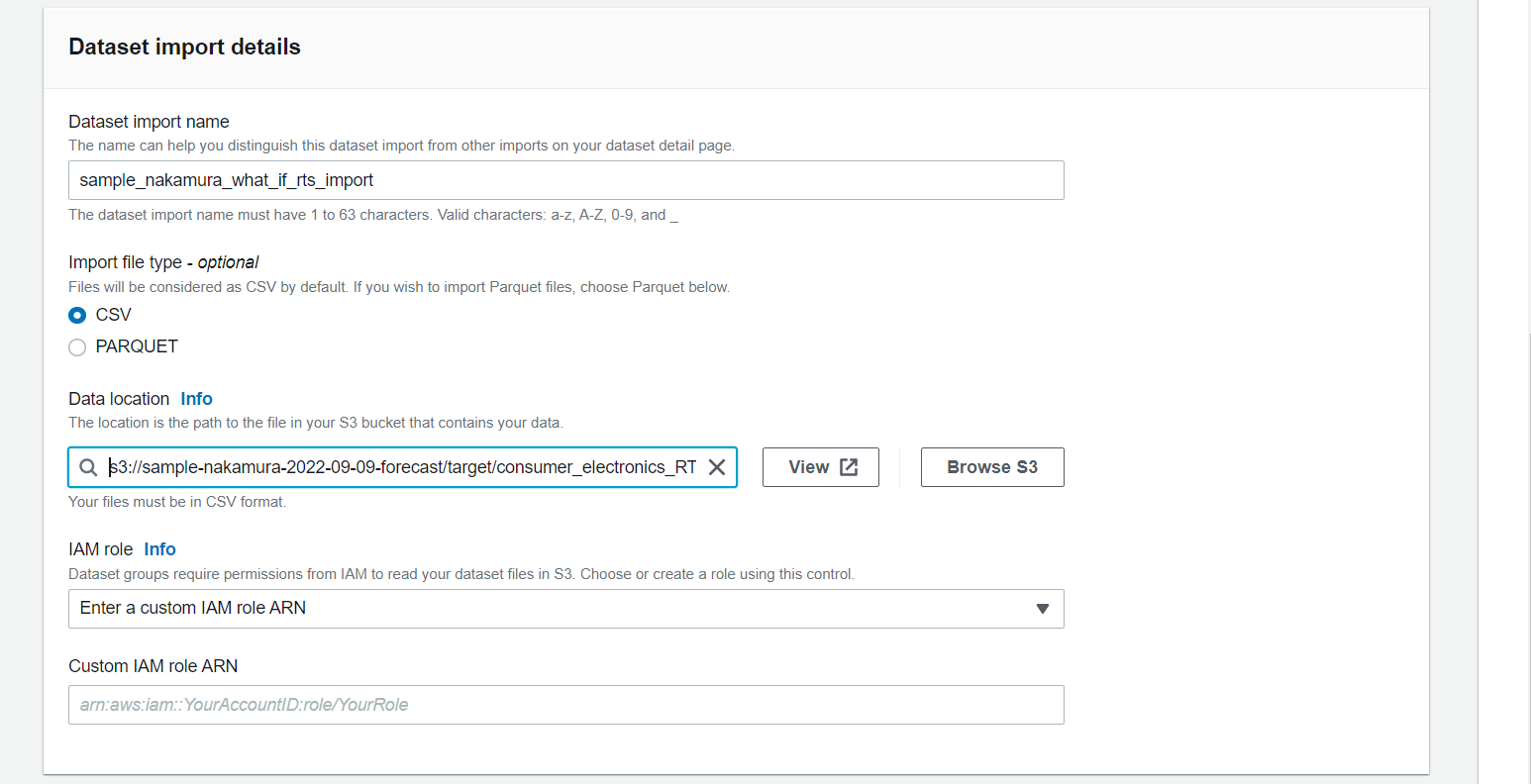
IAM roleは、先ほどと同じロールを指定します。(データ格納先のバケットは同じの場合)
その後「Start」を押下します。

Importが始まるので、先ほどと同様にRelated time series dataが「Active」となるまで待ちます。
Predictor作成
次にPredictorを作成します。先ほどの画面で、Predictor trainingの横にある「Start」を押下します。
Predictor settingsは以下の値で設定します。
- Predictor name: sample_nakamura_what_if_predictor
- Forecast frequency: 1 month(s)
- Forecast horizon: 3
- Forecast dimensions: store_id
- Forecast quantiles:
- Forecast quantile: Forecast quantile 1, Value: 0.10
- Forecast quantile: Forecast quantile 2, Value: 0.50
- Forecast quantile: Forecast quantile 3, Value: 0.90
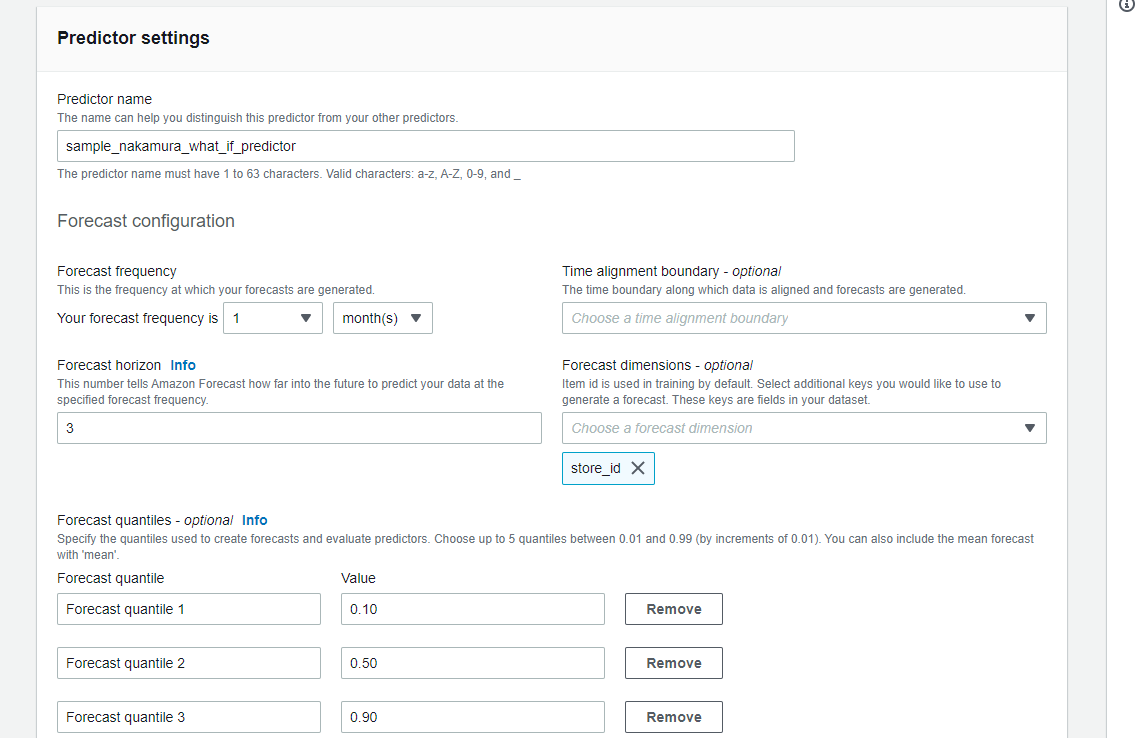
他はデフォルトのまま、ページ下部の「Create」を押下します。
すると、Trainingが開始され、Predictor一覧で残り時間が表示されます。
(今回は2時間程度必要でした)
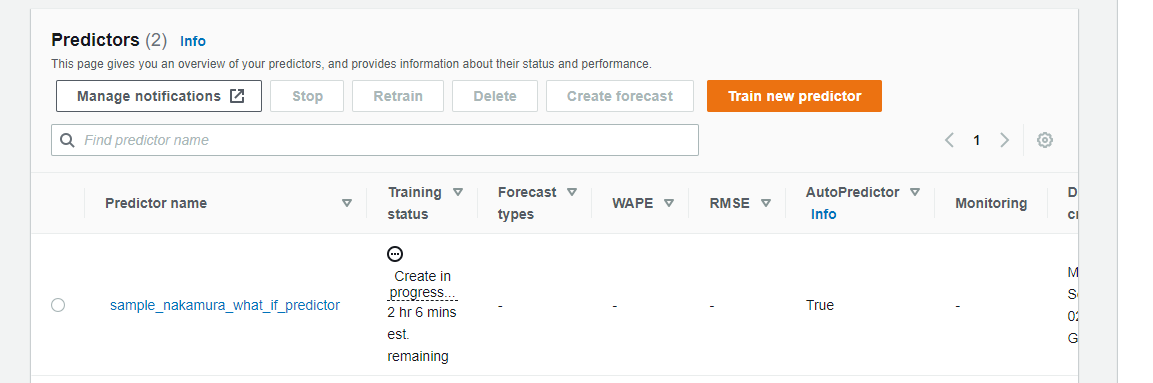
Forecast作成(予測の実行)
Predictor一覧から作成したPredictorを選択すると、「Create forecast」ボタンがありますので、
そこで予測を実行します。
Forecast detailsは以下の値で設定します。
- Forecast name: sample_nakamura_what_if_forecast
- Predictor: sample_nakamura_what_if_predictor
- Item for generating forecasts: All Items
作成が開始されるので、結果を待ちます。
(残り時間が表示され、今回は40分程度かかりました)
作成が終わったら、forecastを選択し、以下の「Create forecast export」を押下します。
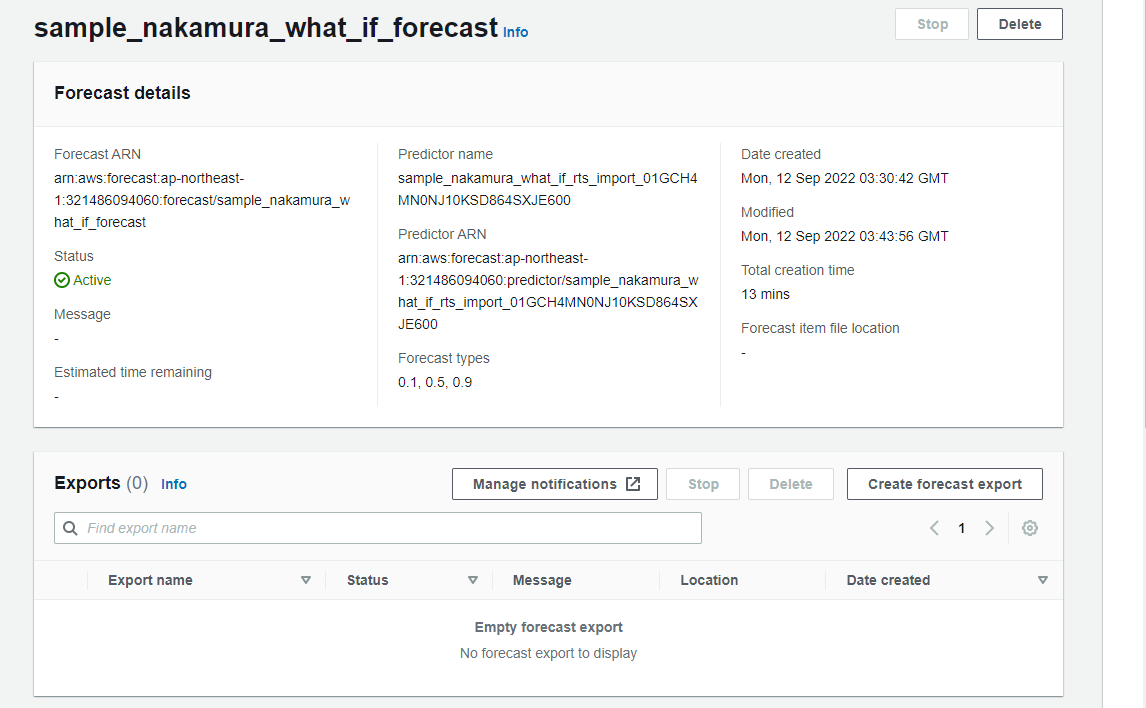
Export detailsで以下を入力します。
- Export name: sample_nakamura_what_if_forecast_export
- IAM role: インポート時に作成したものと同じロールを指定
- Export file type: CSV
- S3 forecast export location: s3://sample-nakamura-2022-09-09-forecast/export
ページ下部の「Create Export」を押下して完了を待ちます。
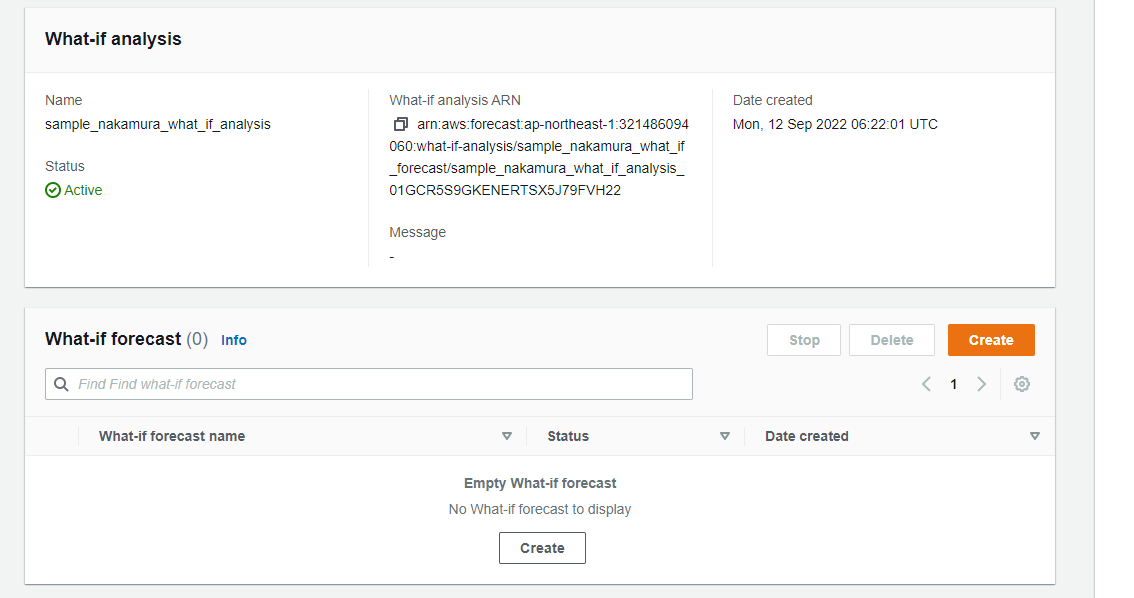
what-if分析の作成
ダッシュボード画面からwhat-if分析が作成できます。「Explore what-if analysis」を押下します。
「Create」を押下します。
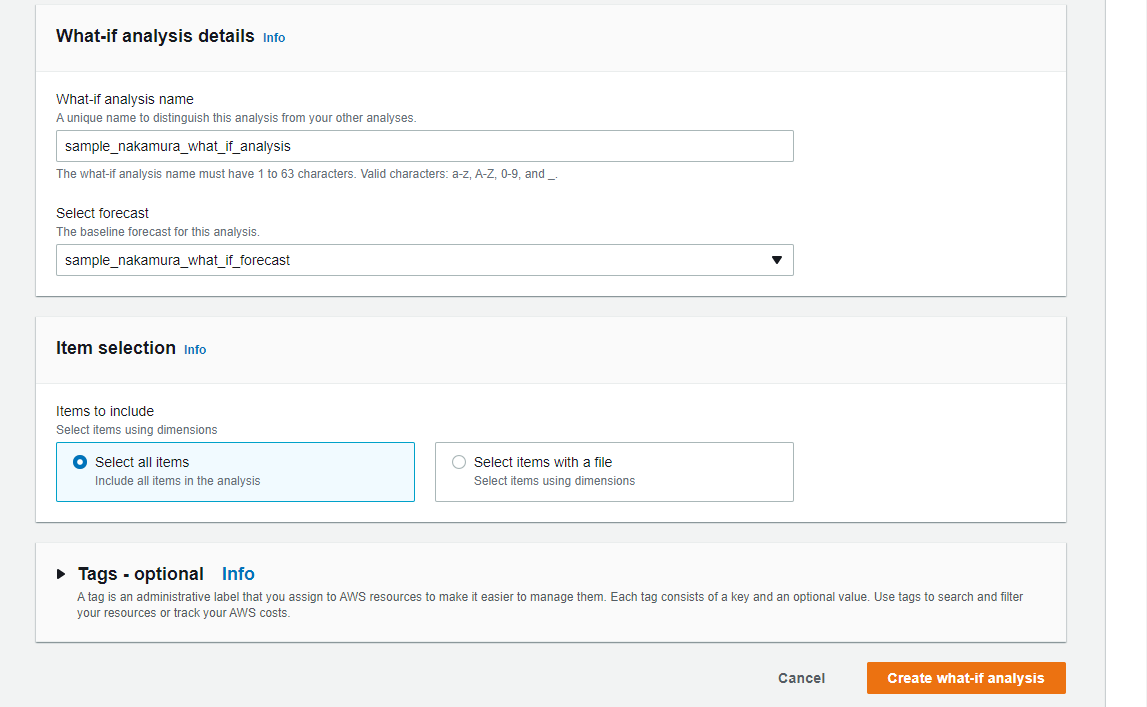
What-if analysis detailsを以下のように設定します。
- What-if analysis name: sample_nakamura_what_if_analysis
- Select forecast: sample_nakamura_what_if_forecast
- Item selection: Select all items
ページ下部の「Create what-if analysis」を押下します。
しばらく経過すると、What-if analysisのStatusがActiveとなります。
what-if分析のForecast作成(予測の実行)
上記の画面から、What-if forecastの「Create」を押下して進みます。
What-if forecast detailsに以下を入力します。
- What-if forecast name: sample_nakamura_what_if_analysis_forecast
- What-if forecast definition method: Use transformation functions
- Transformation function builder:
- Action
- Operation: MULTIPLY, AttributeName: price, Value: 0.90
- Conditions:
- AttributeName: timestamp, AttributeValue: 2019-09-01, Condition: GREATER_THAN
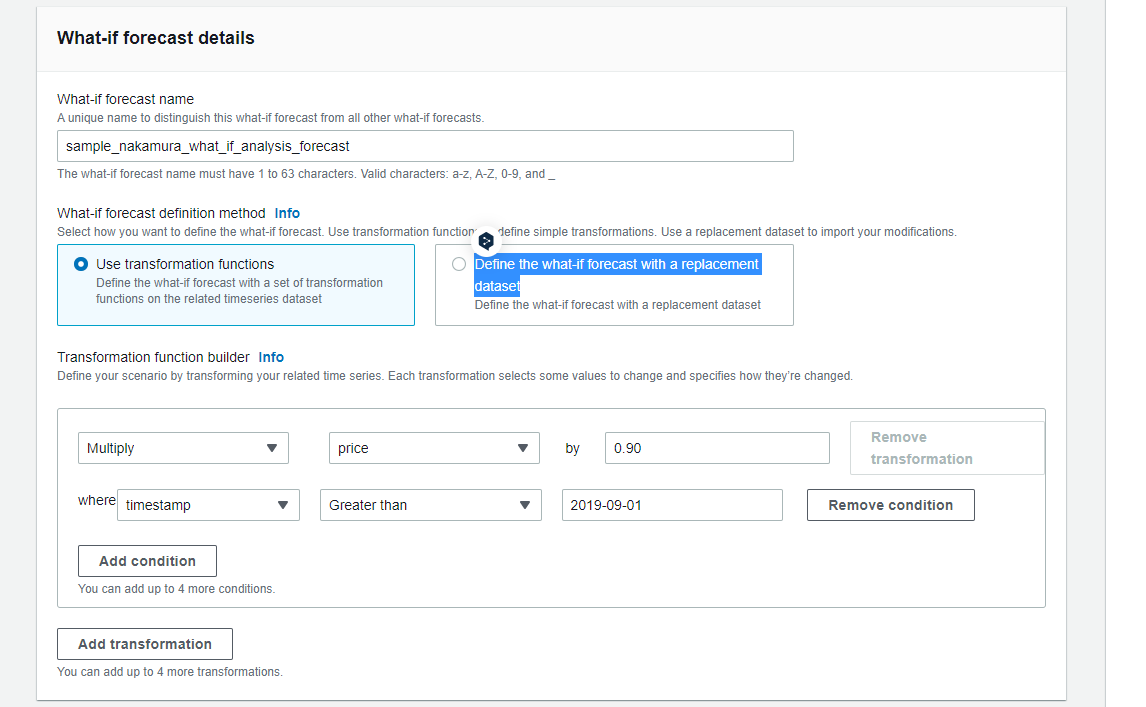
上記の設定内容は、2019-09-01以降のpriceデータに0.9を乗算した場合に、
Targetがどのように変化するかを、What-if分析するような記述となっています。
なお、数式で表現できないような値を設定したい場合は、
definition methodに「Define the what-if forecast with a replacement dataset」を選択し、
データを置き換えたRelated Time SeriesデータをS3からImportすることで、What-if分析をすることが可能です。
入力をしたらページ下部の「Create」を押下します。
すると以下のように作成中となるので、しばらく待ちます。

StatusがActiveとなったら、ページ下部に移動し、以下のWhat-if forecast exportで
「Create export」を押下します。
インポート時に作成したものと同じロールを指定
Export detailsで以下を入力します。
- Export name: sample_nakamura_what_if_analysis_forecast_export
- What-if forecasts: sample_nakamura_what_if_analysis_forecast
- S3 forecast export location: s3://sample-nakamura-2022-09-09-forecast/export_what_if
- IAM role: インポート時に作成したものと同じロールを指定
ページ下部の「Create Export」を押下して完了を待ちます。
結果の比較
エクスポート結果をダウンロードして比較していきます。
aws s3 cp s3://sample-nakamura-2022-09-09-forecast/export ./export --recursive aws s3 cp s3://sample-nakamura-2022-09-09-forecast/export_what_if ./export --recursive
可視化のため、Pythonのコードを準備しました。
import pathlib
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
sns.set(style='darkgrid')
from datetime import datetime
# 学習データ読み込み
tts_df = pd.read_csv("./consumer_electronics_TTS.csv")
# 推論結果読み込み
def read_csv_files(src_path: str):
df = pd.DataFrame([])
for p in pathlib.Path(src_path).glob("*.csv"):
# print(p)
_df = pd.read_csv(p)
if len(df)==0:
df = _df
else:
df = pd.concat([df, _df], axis=0)
df = df.sort_values(['item_id', 'store_id', 'date']).reset_index(drop=True)
df['yyyy-mm-dd'] = [i[:10] for i in df['date']]
return df
base_df = read_csv_files("./export")
whatif_df = read_csv_files("./export_what_if")
# 描画
query_str = 'item_id == "item_001" and store_id == "store_001"'
fig, axes = plt.subplots(2, 1, figsize=(10, 6), dpi=100, sharex="col")
fig.suptitle(query_str)
ax = axes[0]
sns.lineplot(data=tts_df.query(query_str), x='timestamp', y='demand', marker="o", ax=ax, label="train(target)", color=colors[0])
sns.lineplot(data=base_df.query(query_str), x='yyyy-mm-dd', y='p50', marker="o", ax=ax, label="forecast(p50)", color=colors[1])
sns.lineplot(data=whatif_df.query(query_str), x='yyyy-mm-dd', y='sample_nakamura_what_if_analysis_forecast_p50', marker="o", ax=ax, label="what-if-forecast(p50)", color=colors[2])
ax.set_ylim([100, 500])
ax = axes[1]
sns.lineplot(data=rts_df.query(query_str), x='timestamp', y='price', marker="o", ax=ax, label="train(related)", color=colors[0])
sns.lineplot(data=rts_df.query(query_str).query('timestamp > "2019-09-01"'), x='timestamp', y='price_whatif', marker="o", ax=ax, label="what-if", color=colors[2])
[i.set_rotation(90) for i in ax.get_xticklabels()]
ax.set_ylim([40, 150])
plt.tight_layout()
plt.tight_layout()
結果は以下のようになります。(item_id: "item_001", store_id: "store_001"の場合)
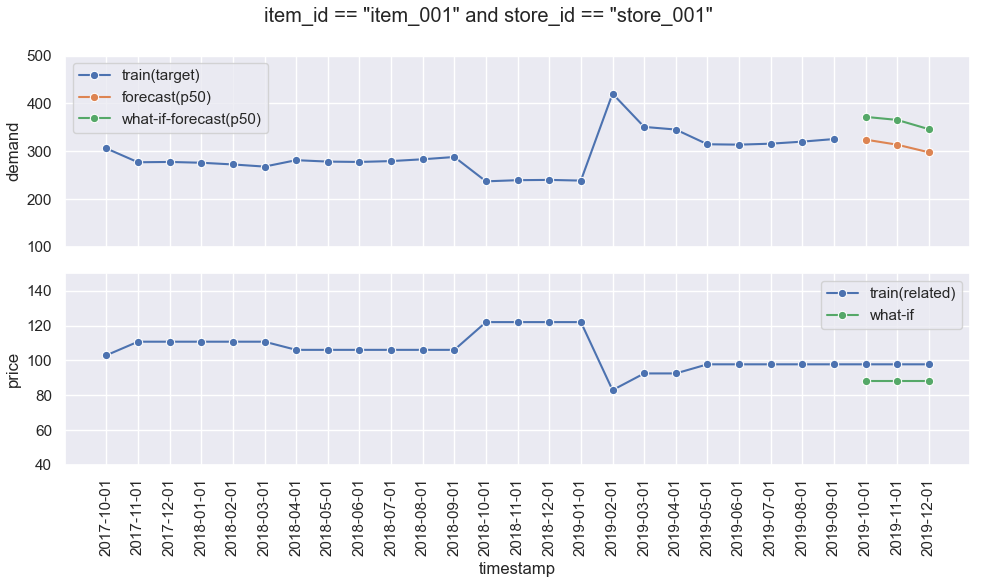
上のdemandが予測対象となる時系列データで、下のpriceがRelatedな時系列データとなる情報です。
demand, priceそれぞれ青線で描かれている箇所がPredictorの学習に使用されています。
オレンジ線は、通常のPredictorのForecast結果(p50)で、これがベースラインとなります。
グリーン線がwhat-if分析に関するデータで、priceが0.9掛けだったら、
demandにどのような影響がでるかを確認できます。
影響としては、priceが低下すると、demandが上昇するといったような予測をしているようです。
これは、学習に使用したdemandとpriceが逆相関を持っていることをうまく反映しています。
この結果は、item_id、store_idごとにそれぞれ影響度を確認することが可能です。
興味のある方は他のケースも確認してみてください。
まとめ
いかがでしたでしょうか?
what-if分析で、過去を振り返って様々な仮説を検証することができるので、分析の幅が広がりそうですね。
Amazon Forecastをご利用の方は是非お試しください。
こちらの記事がAmazon Forecastを活用する際の参考になれば幸いです。









