
【パブリックプレビュー】 Google Cloudのデータ分析AIエージェントを簡単に構築できるConversational Analytics APIの紹介
データ事業本部の鈴木です。
Google Cloud Next 25で発表されたConversational Analytics APIですが、8月末からパブリックプレビューになっています。
サポートされるGoogle Cloudサービスにデータを置いている場合には、このAPIを使うとGoogle Cloud側でエージェントの作成と実行をしてくれるかなり強力な機能です。
簡単に分析用のエージェントを作成できるため個人的には非常に注目していますが、プレビュー提供なのもあってか日本語の情報が少なめだったので概要をまとめてみました。
パブリックプレビュー中ですので、GAに向けていろいろ変更点もあると思うため、細かい実装などは今回はあまり紹介しません。
Conversational Analytics APIについて
LookerやBigQueryデータキャンバスなどGoogle Cloudの自然言語によるデータ分析のエンジンとして使われている自然言語クエリ機能をAPIとして提供するものです。
このAPIを使うことで、自身のアプリケーションにもGoogle Cloudの自然言語クエリ機能を搭載することができます。
Google Cloud Next 25時点ではLookerの流れで紹介されていたので、Looker関連の機能なのかなと思っていたのですが、現在の位置付けとしてはこのAPIからBigQueryやLookerに自然言語で問い合わせができるものと考えておくとよいと思います。
ガイドは以下で公開されています。必用な情報が網羅的に整理されています。
このガイドにGoogle Colab向けのサンプルノートブックのリンクがありましたので、興味がある方は簡単に試すことができます。
私はPythonをよく使いますが、SDKのAPIリファレンスは以下にありました。操作自体はサンプルノートブックにも網羅的に書かれていました。
使用イメージ
分析の実行はざっくり以下の流れとなっていました。
- データエージェントの作成
- Conversationの作成
- 自然言語による分析の実行
今回はBigQueryのデータ向けに試してみましたが、自然言語による分析の実行時には「エージェントが使えるテーブルの定義を取得」→「SQLを作成・実行」→「プロットの作成」→「最終的な回答の生成」と進みました。
個人的には、SQL生成時にテーブルのテーブル定義を取得させるところが自分でエージェントを作る場合に大変で、AエージェントがBigQueryの情報を見てSQLを生成してくれるのは非常に良いなと思いました。
分析実行のイメージとしては、例えば以下のように質問を送って回答を取得することができます。
## サンプルノートブックより2025/10/2に引用、questionのみ改変しました。
## データエージェント、conversationはこれより前に作成しているため、詳しくはサンプルノートブックをご確認ください。
# Create a request containing a single user message -- your question.
# fmt: off
question = "空港の総数が多い上位5州の棒グラフを作成してください" # @param {type:"string"}
# fmt: on
# Create the user message
messages = [
geminidataanalytics.Message(
user_message=geminidataanalytics.UserMessage(text=question)
)
]
data_agent_id = "data_agent_1" # @param {type:"string"}
conversation_id = "conversation_1" # @param {type:"string"}
# Create a conversation_reference
conversation_reference = geminidataanalytics.ConversationReference(
conversation=data_chat_client.conversation_path(
billing_project, location, conversation_id
),
data_agent_context=geminidataanalytics.DataAgentContext(
data_agent=data_chat_client.data_agent_path(
billing_project, location, data_agent_id
),
# credentials=credentials # Uncomment if using Looker datasource
),
)
# Form the request
request = geminidataanalytics.ChatRequest(
parent=f"projects/{billing_project}/locations/{location}",
messages=messages,
conversation_reference=conversation_reference,
)
# Make the request
stream = data_chat_client.chat(request=request)
# Handle the response
for response in stream:
show_message(response)
BigQuery Notebook(Colab Enterprise)から実行して回答を確認しました。
▼テーブル定義の取得
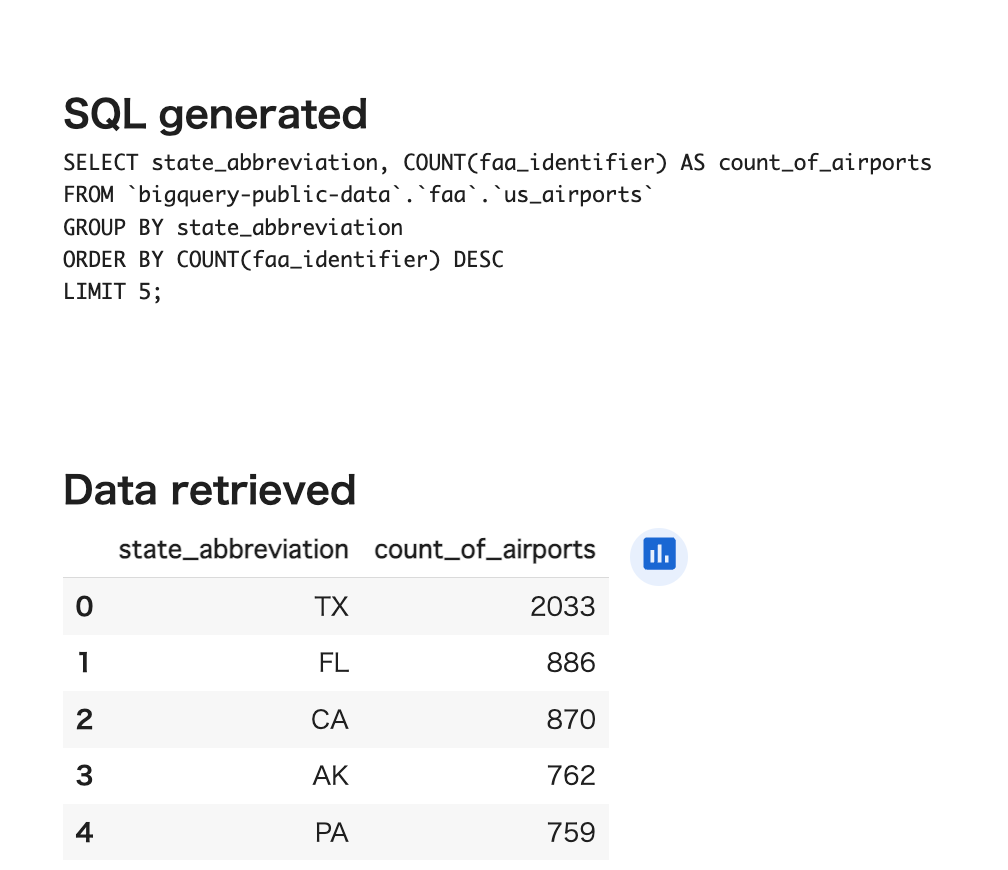
▼SQLの生成
▼プロットの作成

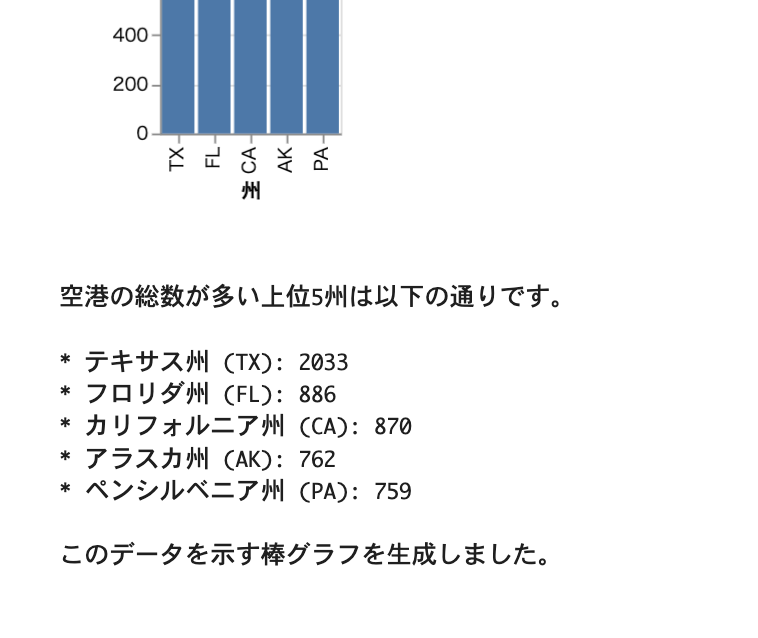
▼最終的な回答
ADK (Agent Development Kit) との使い分け
ADK (Agent Development Kit) からBigQueryやLookerに分析を行うことも可能です。
Conversational Analytics APIとは異なり、ADKの場合は自分でAIエージェントを実装するところからになります。Conversational Analytics APIの最終的な仕様次第ではありますが、一般的にはエージェント内のプロンプトは全て見られた方が細かな制御はしやすいため、より素に近いところから実装したかったり、高いカスタマイズ性が求められる際にはADKを使って実装するような使い分けになると思います。
なお、ADKのBigQueryツールセットのうち、ask_data_insightsツールはConversational Analytics APIをベースとしており、必ずどちらかを選ぶというよりは、合わせて使うことも可能です。
現時点のConversational Analytics APIの個人的推しポイント
魅力的なAPIですが、個人的に良いなと思ったポイントを3つご紹介します。
1. エージェントが参照するデータを指定する方法が分かりやすい
エージェントが分析対象とするデータを指定する方法が分かりやすいです。
例えば、Python SDKからデータエージェントを作成する場合に、BigQueryテーブルは以下のように指定できます。
# 以下ガイドより2025/10/2に引用・抜粋
# https://cloud.google.com/gemini/docs/conversational-analytics-api/build-agent-sdk#connect_to_a_data_source
# データソースの作成
bigquery_table_reference = geminidataanalytics.BigQueryTableReference()
bigquery_table_reference.project_id = "my_project_id"
bigquery_table_reference.dataset_id = "my_dataset_id"
bigquery_table_reference.table_id = "my_table_id"
# データソースへの接続
datasource_references = geminidataanalytics.DatasourceReferences()
datasource_references.bq.table_references = [bigquery_table_reference]
# コンテキストの作成
published_context = geminidataanalytics.Context()
published_context.system_instruction = system_instruction
published_context.datasource_references = datasource_references
# エージェントへのコンテキストの指定
data_agent = geminidataanalytics.DataAgent()
data_agent.data_analytics_agent.published_context = published_context
LookerおよびLooker Studioも同様です。
これだけで自然言語からテーブルを分析してくれるため、とても手早く利用が開始できました。
また、より正確に分析をさせたい場合は、次のようにsystem_instructionパラメータから情報を渡すことが可能です。
ただYAMLファイルを作り込むのも大変ではあるので、とりあえずどのテーブルかを渡すだけで分析をしてくれるのは始めやすさや分かりやすさという点でとても良いなと思いました。
2. ビジネス用語やmeasureをsystem_instructionに渡すことが可能
AIエージェントにデータ分析をさせる際にはユーザーが書いたテキスト内のビジネス用語をテーブル定義や集計ロジックに正確に対応づけさせることが非常に重要です。
system_instructionパラメータでYAML形式の文字列としてこの情報を渡すことで回答の精度を上げられるよう設計されており、非常に良いです。
3. BigQueryに対する個々のクエリのスキャン量制限が可能
big_query_max_billed_bytesを渡してエージェントがBigQueryに対してクエリを実行する際のスキャン量制限ができるのがとても良いです。
BigQueryはオンデマンド料金の場合、クエリで処理されたバイト数に基づいての課金になるため、エージェントにクエリを実行される際は大きなクエリを誤って投げないかは気になります。このAPIではオプションで制限が可能であるのは非常に嬉しいです。
最後に
パブリックプレビュー中のConversational Analytics APIを使った自然言語によるデータ分析をご紹介しました。
自分でデータ分析用のAIエージェントを作らずとも手軽にBigQueryやLookerのデータを分析できる点に大きな強みがあり、既にADKでエージェントを作っている場合でもAKDからツールセット経由で組み合わせて使える点も魅力的です。
一般提供がとても楽しみですね。









