
Glue DataBrew のハンズオンをやって操作感を掴んでみた & Athena 経由で加工済みデータを QuickSight で可視化してみた
コーヒーが好きな emi です。
Excel や Google スプレッドシートを使っていて、容量が 700MB~1000MB 程度に大きくなってくると操作が重くなります。
Glue DataBrew であれば Excel や Google スプレッドシートのように GUI でデータをフィルタしたり加工したりできるのか?と疑問に思うことがあったので、触ってみて操作感を掴んでみました。
先に操作して分かったこと
- DataBrew は Excel のような即時反映ではなく、サンプリングデータに対して Web UI で操作→バッチ処理で全体に適用 という流れです。
- プレビューはサンプリングデータのみで、Excel のように全件を即時編集・即時反映することはできません。
- サンプリングデータで操作内容を確認し、問題なければ全データにバッチ適用する、という 「ETLツール的な使い方」 になります。
- 700MB 程度ならサンプリング・プレビュー・レシピ作成は快適ですが、「全件をその場で編集・即時保存」 はできません。
構成イメージ
実施したハンズオンは以下のものです。
全体の流れはこんな形です。
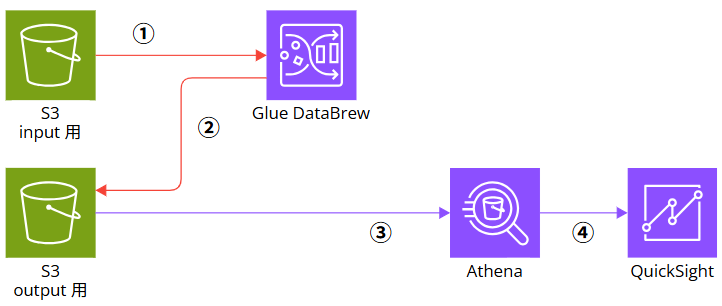
- S3 バケット input 用に、元になる Excel ファイルをアップロードする
- Glue DataBrew で S3 input 用にアップロードした Excel ファイルを加工する(①)
- Glue DataBrew で 加工したファイルを S3 バケット output 用に出力する(②)
- S3 バケット output 用に出力されたファイルを Athena でクエリする(③)
- Athena をデータソースとする QuickSight データセットを作成し可視化する(④)
Glue DataBrew の中で行う操作のイメージ(①~②)は以下です。
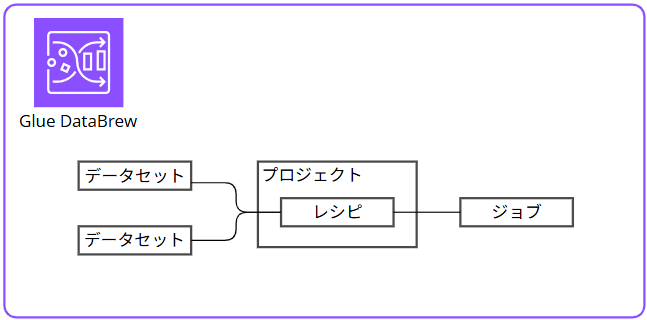
- データセットを作成
- プロジェクトでレシピを作成
- ジョブでレシピを実行し加工する
事前準備
事前にインプット用の S3 バケットとアウトプット用の S3 バケットを作成しておきます。
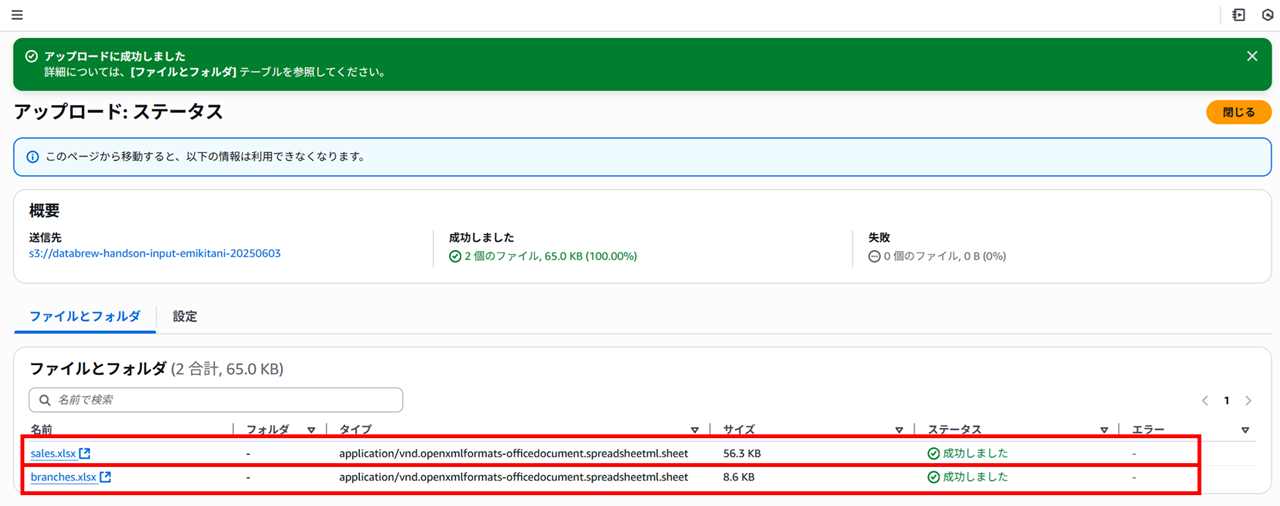
以下 2 種類のサンプルデータが Excel 形式で用意されているのでインプット用の S3 バケットにアップロードします。
- sales.xlsx(60KB)
- branches.xlsx(9KB)
Glue DataBrew の操作
データセットの作成
マネジメントコンソールで Glue DataBrew を開くとこんな感じです。少し他のサービスと印象が違いますね。ちなみに Glue と Glue DataBrew のマネジメントコンソールは別で、アイコンも別です。
データセットを開きます。

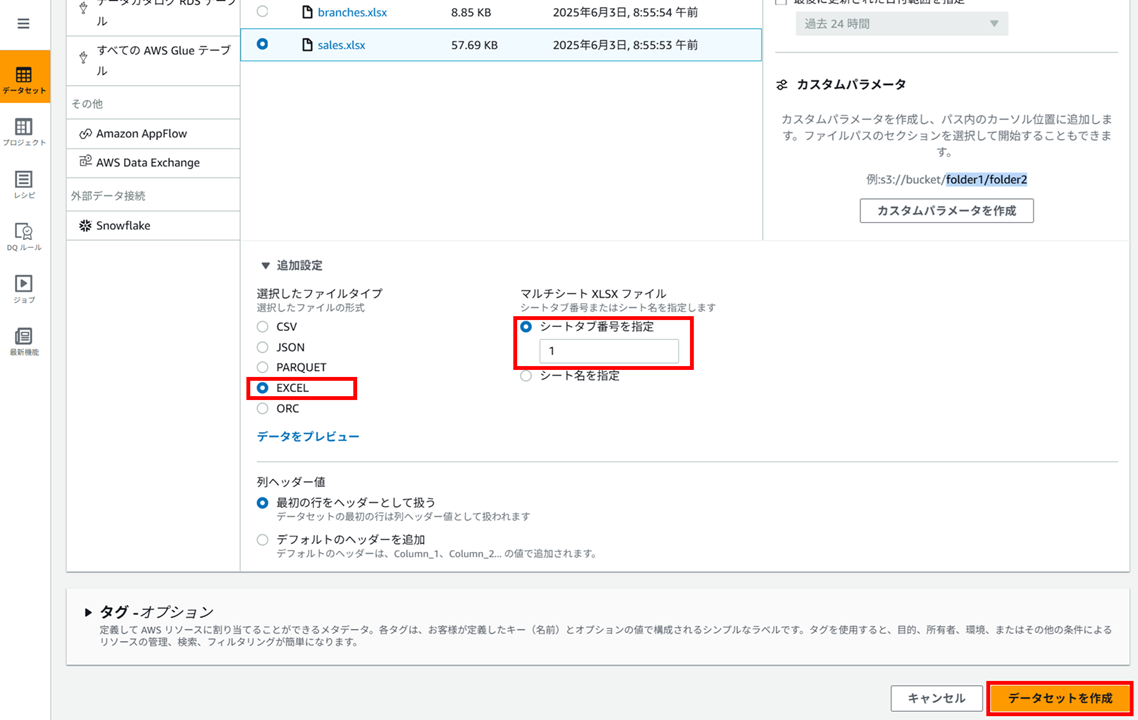
データセットの名前、Excel を格納した S3 バケットのパスで sales.xlsx を選択し、
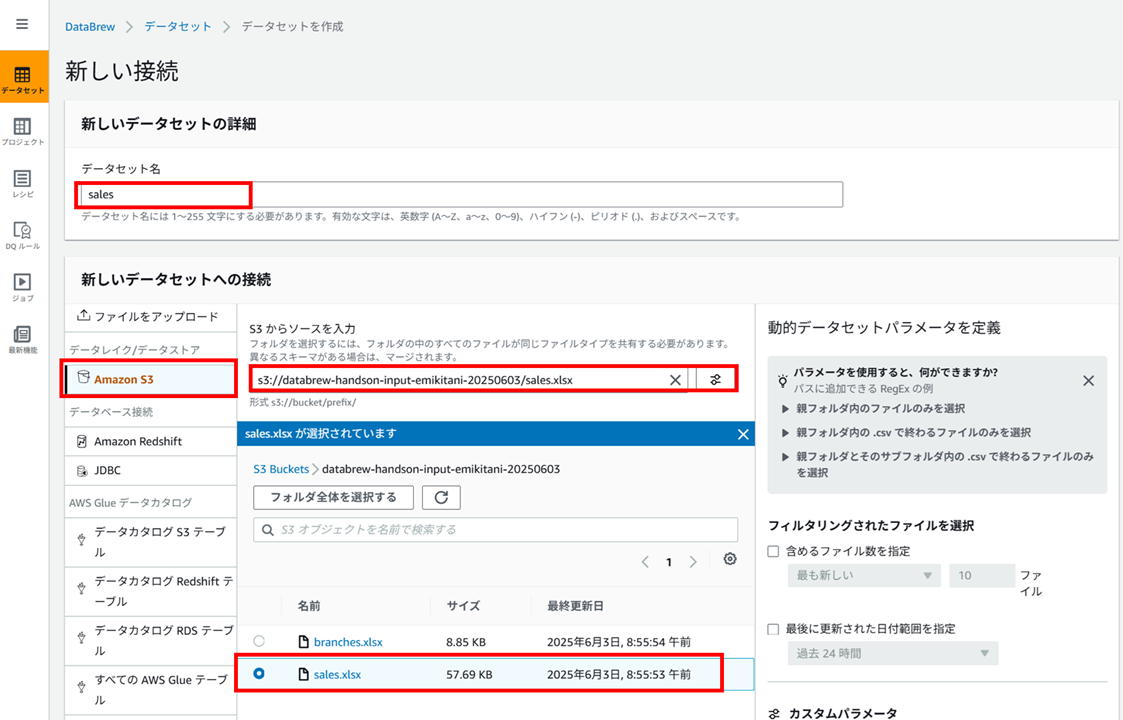
ファイルタイプは Excel、シートタブ番号は 1 としてデータセットを作成します。
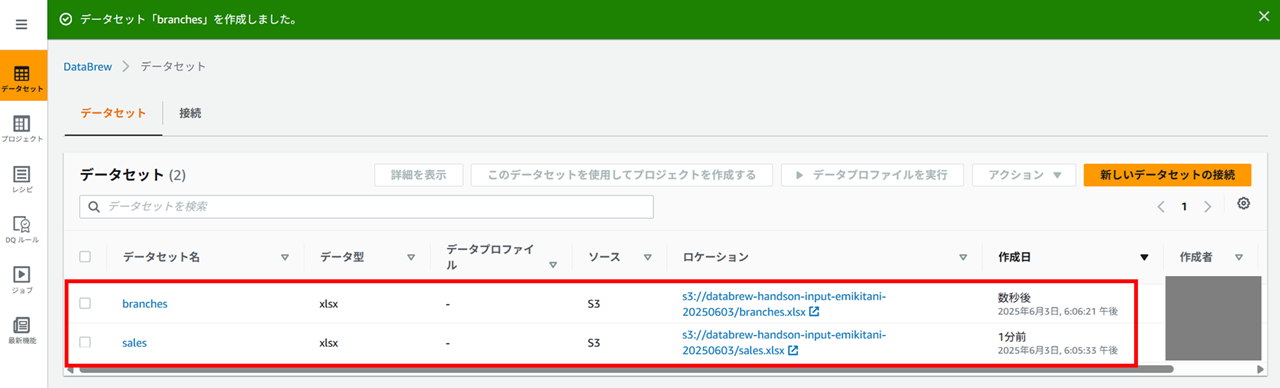
データセットを作成しました。同様に branches.xlsx でもデータセットを作成しまして、データセットが二つできた状態にします。
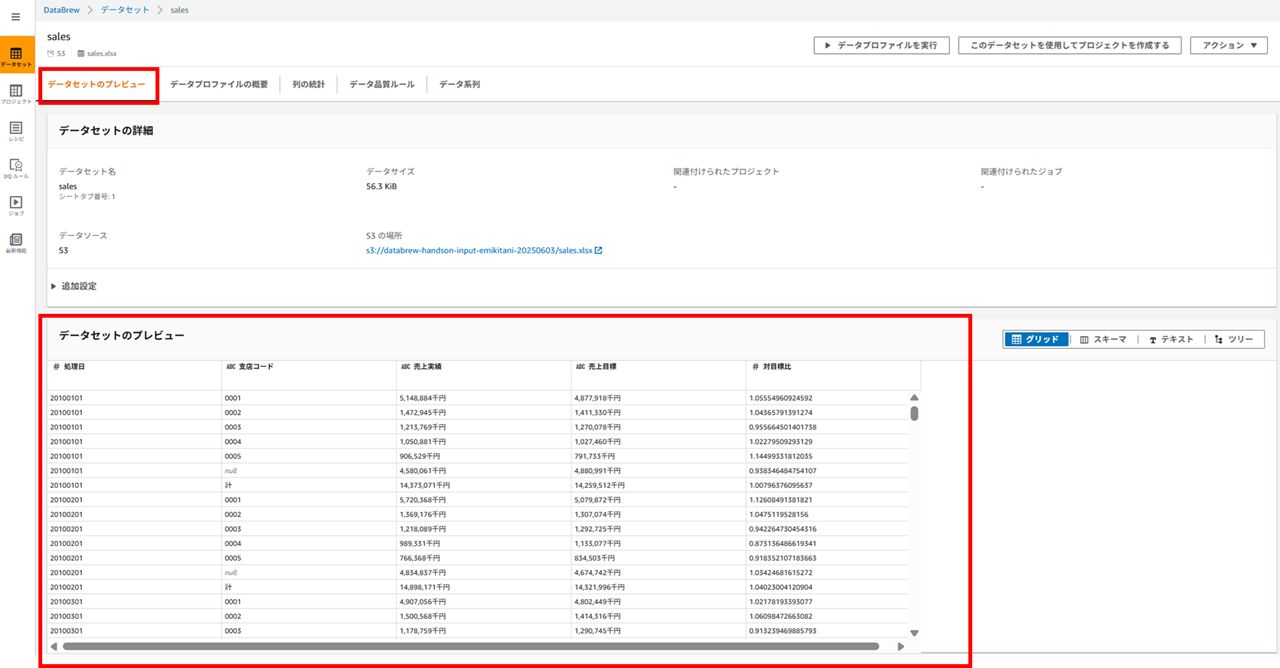
こんな感じでデータ内容がプレビューできます。
プロジェクトの作成
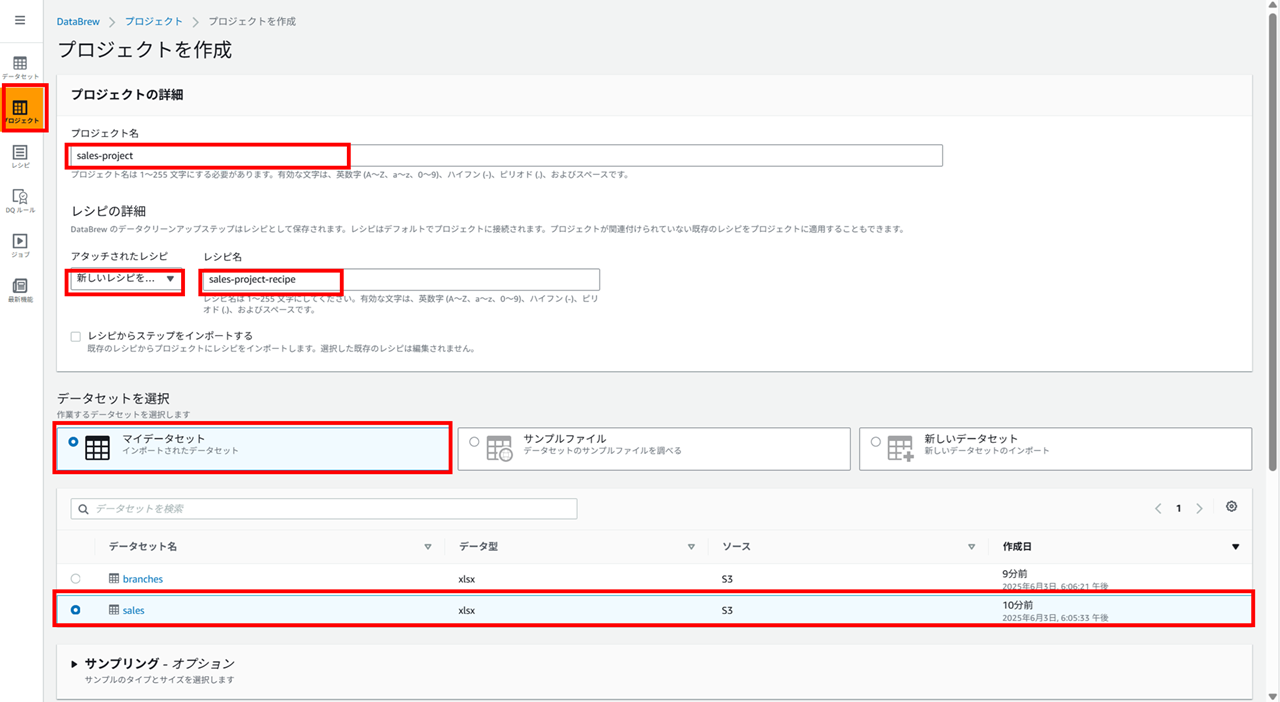
プロジェクトを作成します。プロジェクトではデータの加工を行うためのレシピを作成します。
- 任意のプロジェクト名を入力
- 新しいレシピを作成する、任意のレシピ名の入力
- マイデータセットで sales.xlsx を選択
Glue DataBrew プロジェクト用の IAM ロールは新しいロールを作成します。
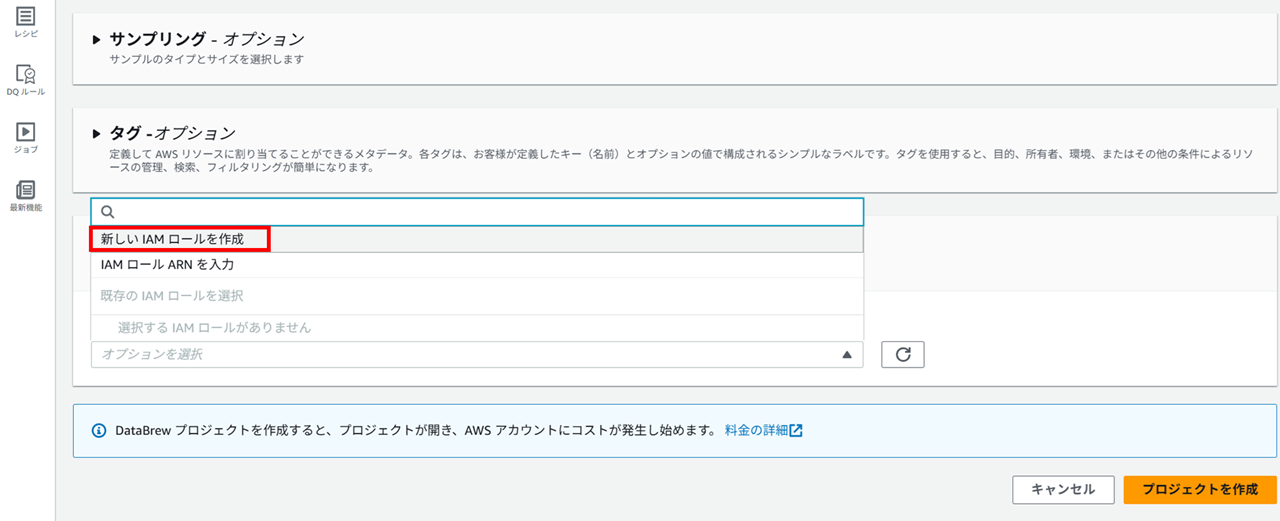
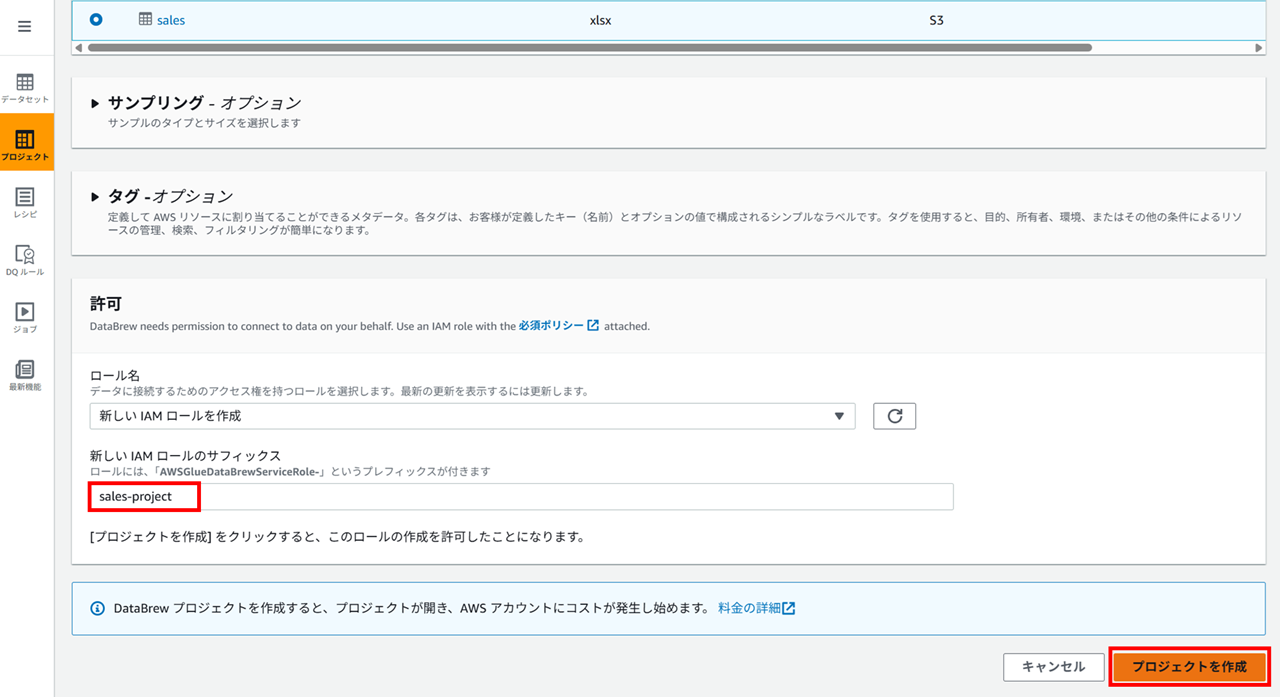
新しいロールのサフィックス(語尾につける文字列)を指定してプロジェクトを作成します。
プロジェクトが作成されるのを 1 分程度待ちます。
作成されると、以下のようにデータのプレビューが表示されます。
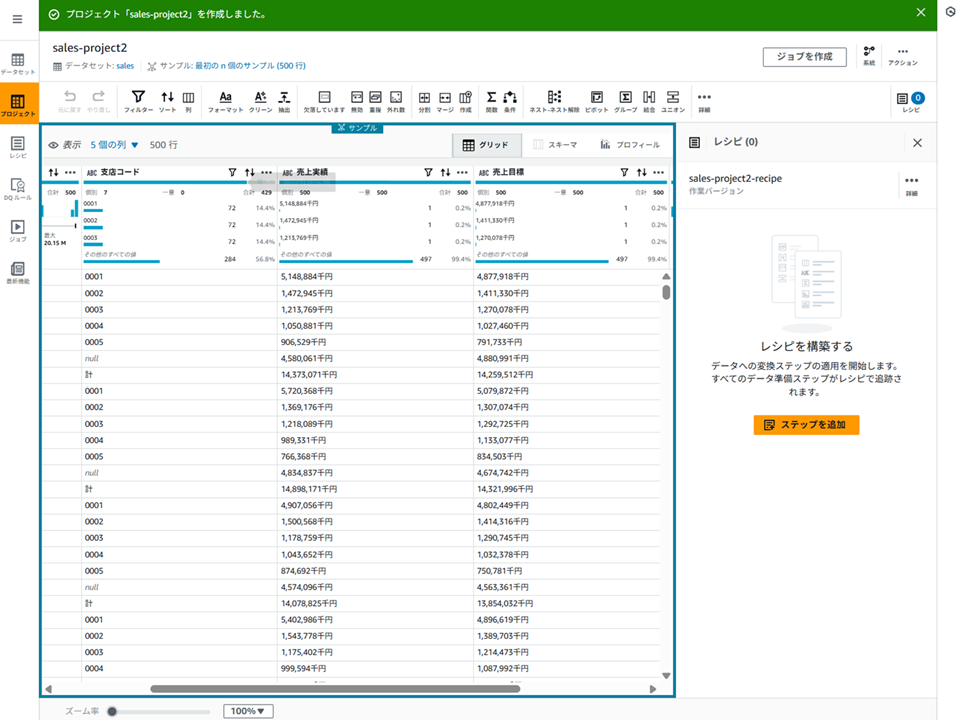
プロジェクトのデータプレビューについて
プロジェクトビューに表示されるデータはデータセットの一部がサンプリングされたものです。
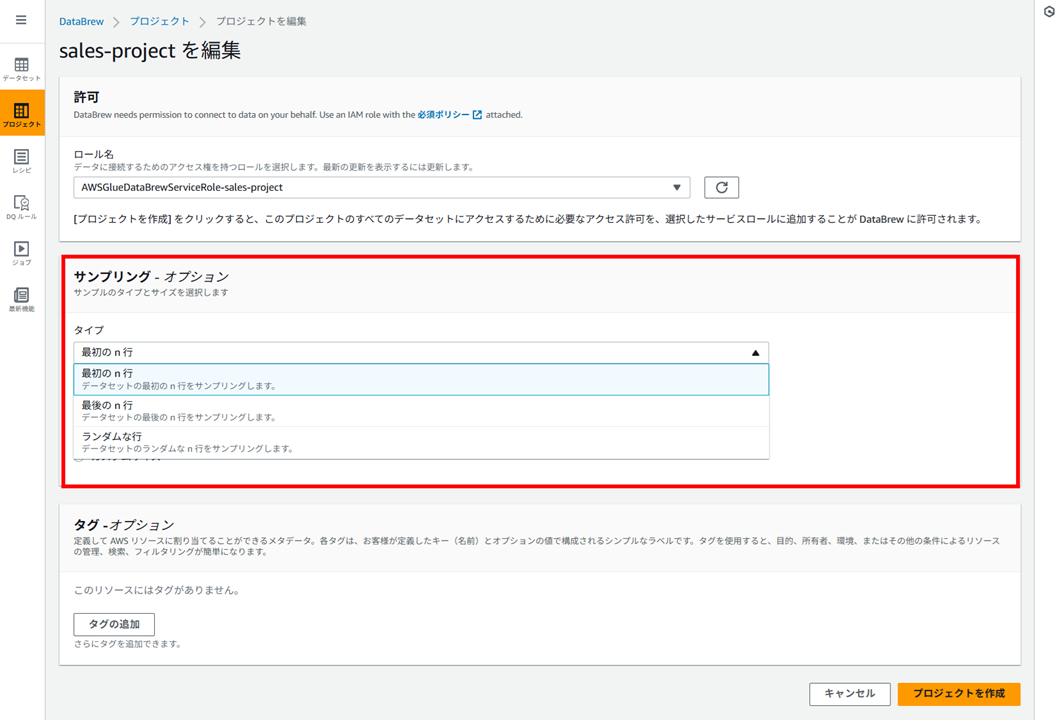
デフォルトではデータセットの最初の 500 行でサンプリングされます。サンプリングサイズや選択される行は 「プロジェクトを編集」 から変更できます。

「サンプリング」 で、サンプリングする行をどのように抽出するか選択します。
- 最初の n 行
- 最後の n 行
- ランダムな行
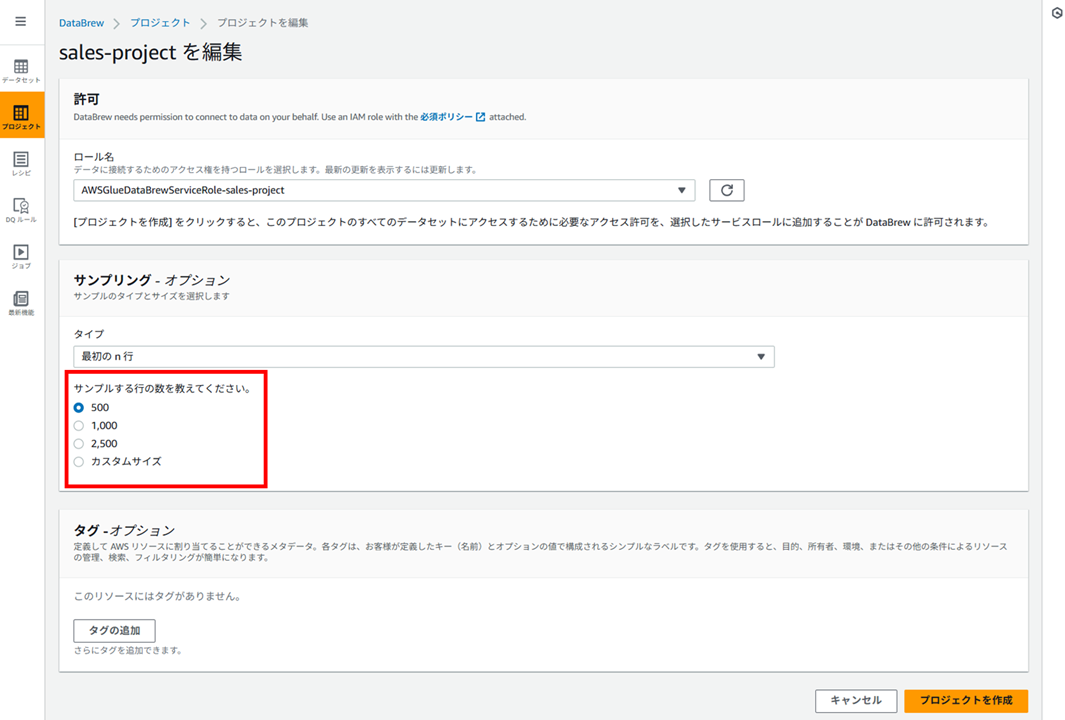
サンプリングする行数は以下から選択できます。
- 500
- 1,000
- 2,500
- カスタムサイズ(最大 5,000 行)
レシピの作成
DataBrew のレシピとは、 DataBrew に処理させたい一連の加工操作の集まりのようなものです。
例えば、
- 日付のフォーマットを変更
- 空欄(null)の削除
- カンマの削除
…などのステップをレシピに登録しておいて、後からジョブでこのレシピを実行することでデータを加工できます。
レシピはダウンロードして他のプロジェクトで再利用したり、レシピをバージョン管理することも可能です。
ハンズオンでは以下のステップをレシピに登録します。
- 空欄(null)の行、「計」の行を削除
- 支店コードをキーに branches を結合
- 「千円」を「000」に置換
- カンマを削除
- カラムを削除
- 日付のフォーマットを変更
- 文字列型から数値に変換
レシピの作成は Excel ライクに粛々と加工していくだけなので、トグルにしまっておきます。
レシピの作成
不要な行の削除(空欄(null)の行、「計」の行を削除)
支店コードの右の 「…」 をクリックし [欠落した値の削除または入力] - [欠落した行を削除] をクリックします。
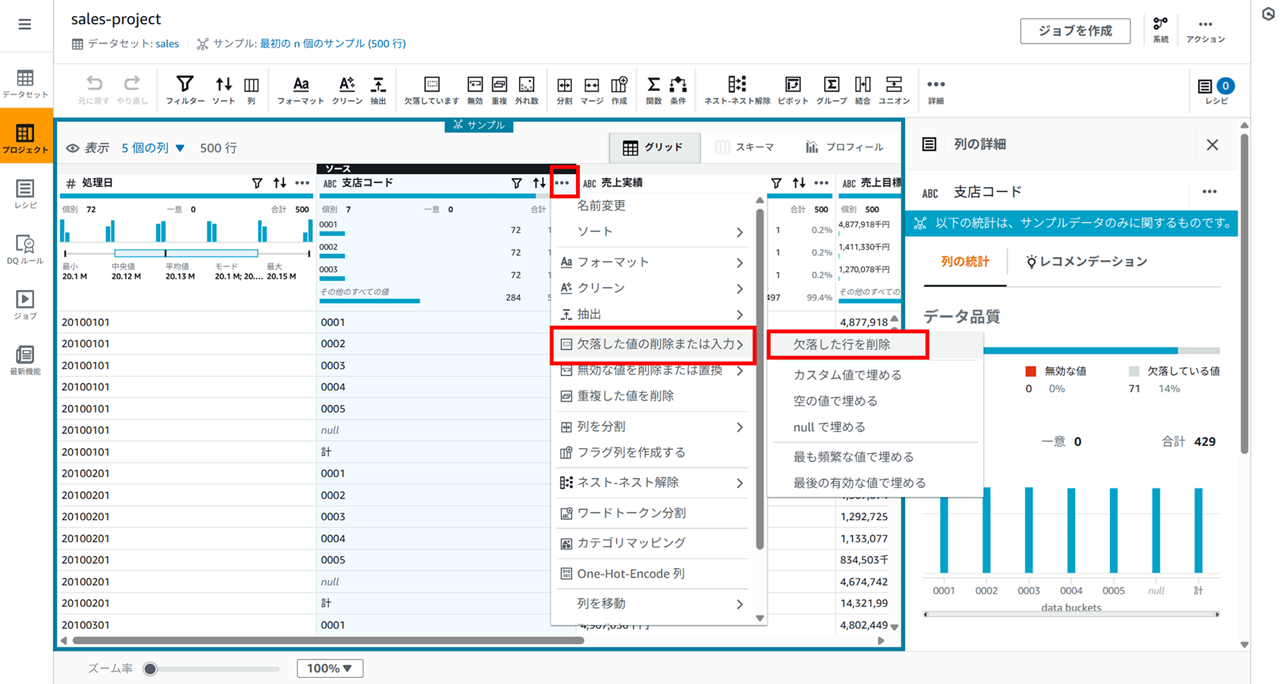
- 支店コードをキーに branches を結合- 欠落した値がある行を削除する
- すべての行
を選択した状態でプレビューすると、
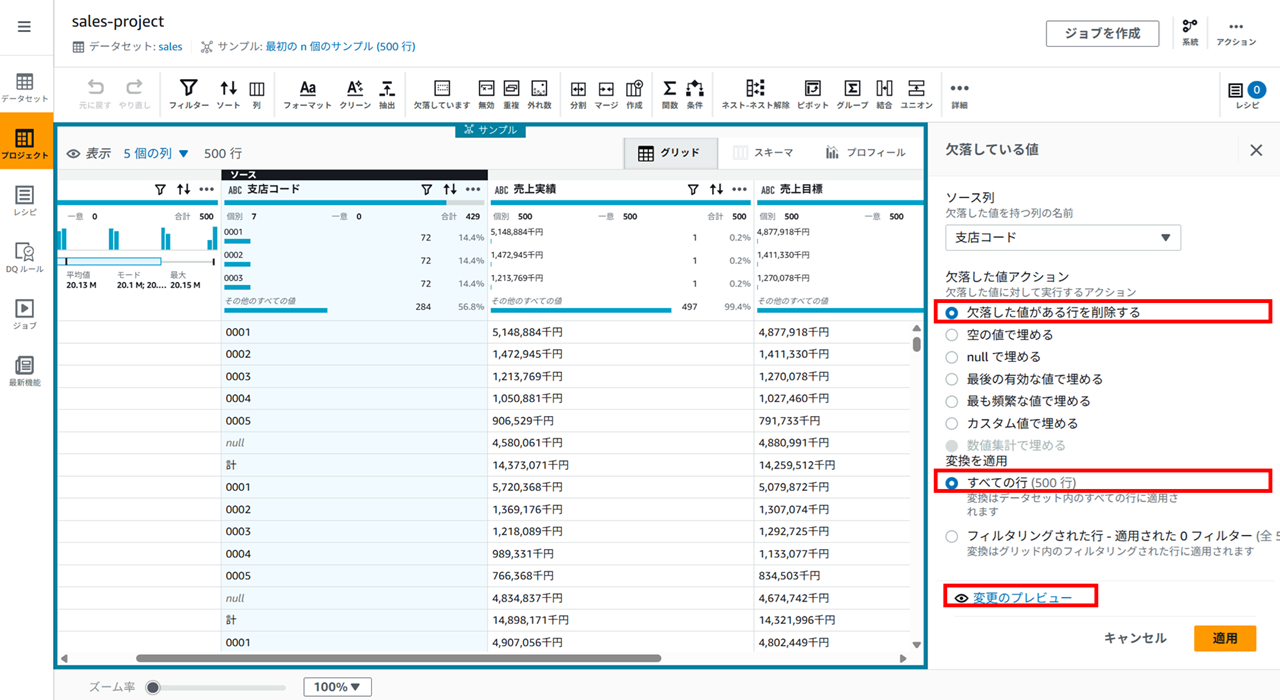
削除される行がこのようにオレンジで表示されます。問題なければ適用します。
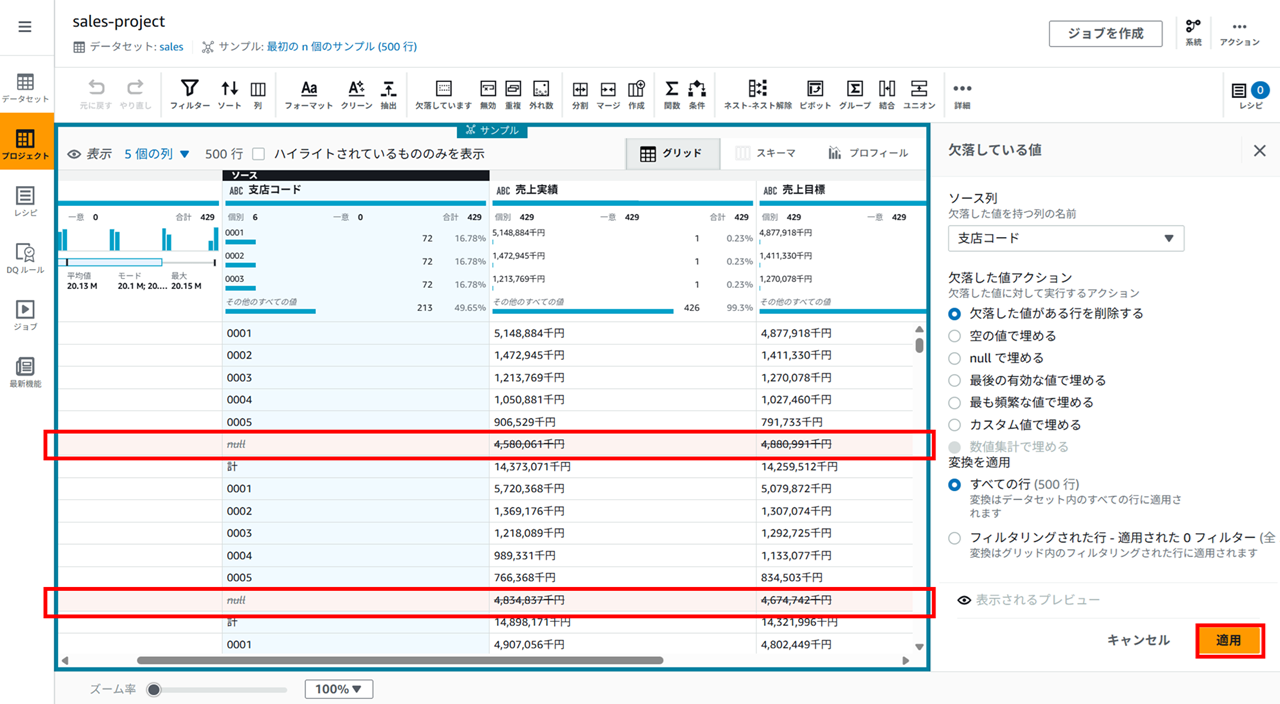
適用すると、レシピにステップが追加されます。
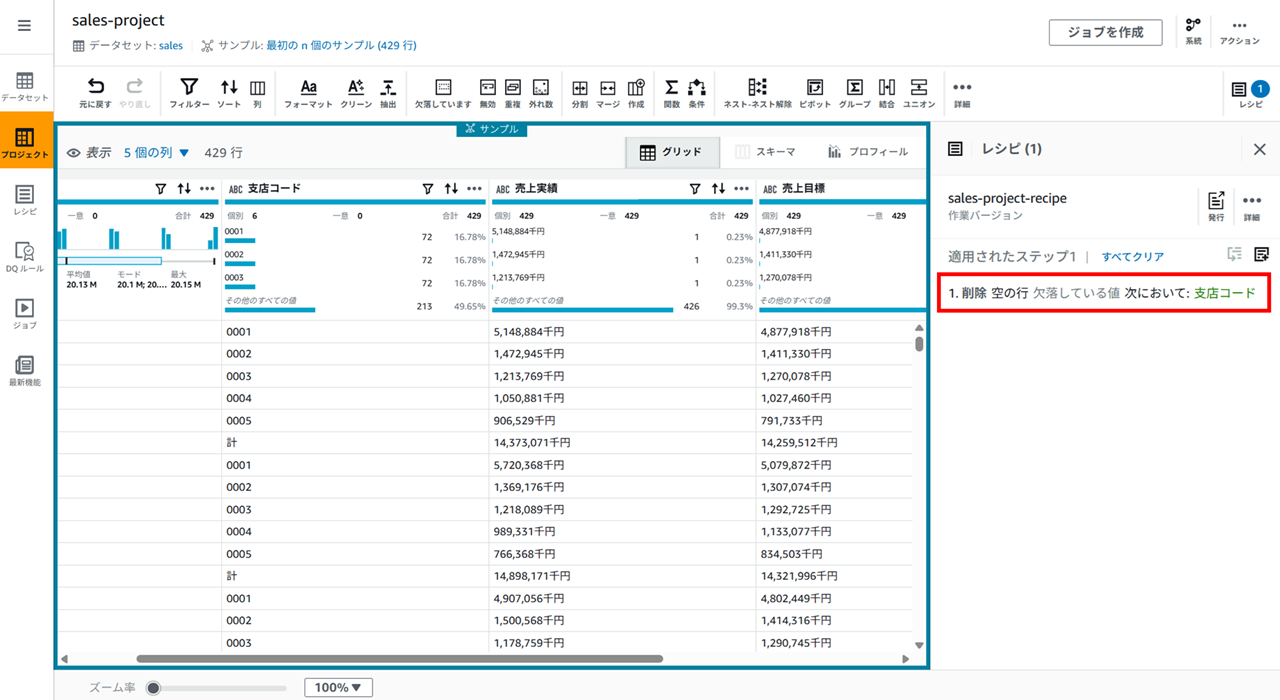
「計」 になっている行の削除もできます。支店コードの列フィルターアイコンをクリックし、
以下のようにフィルタを設定して、
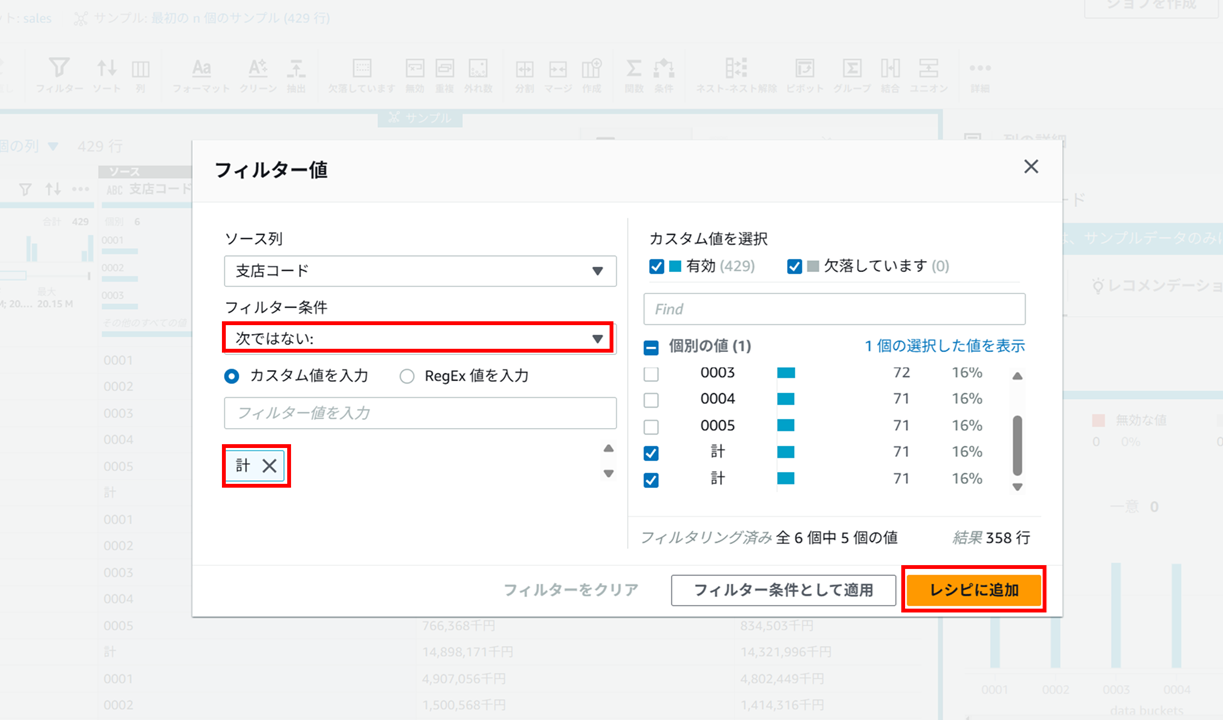
適用すると、
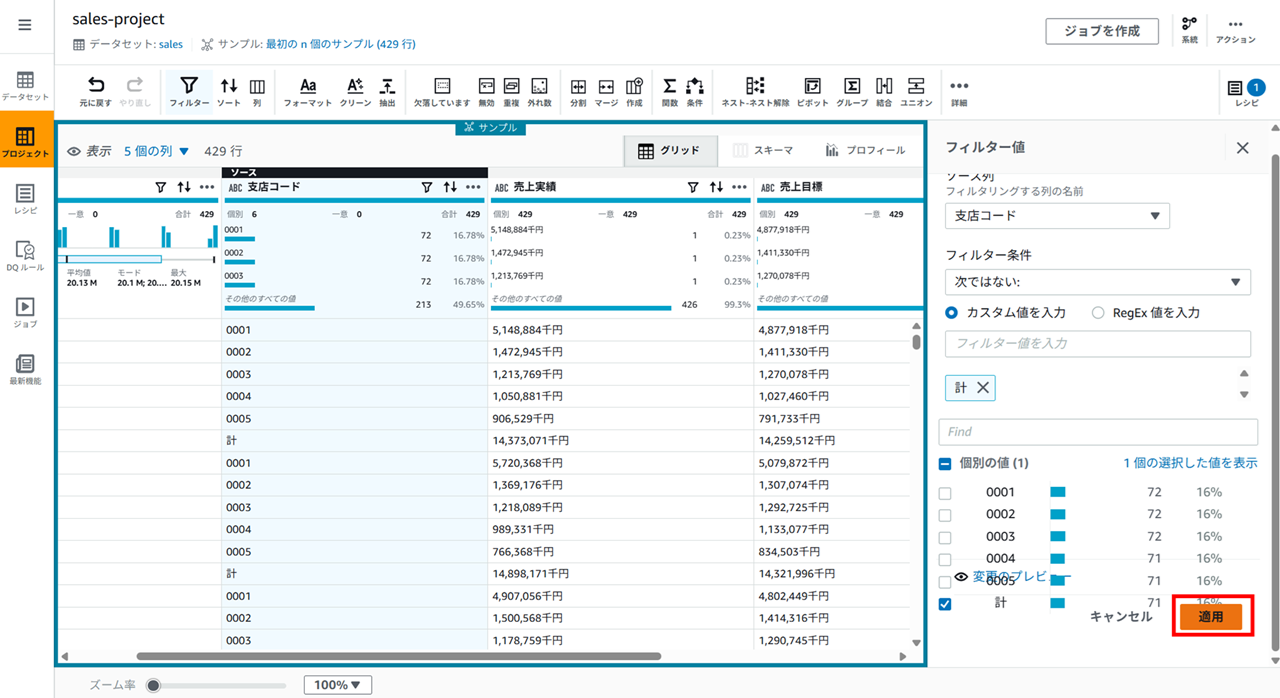
レシピに追加されます。
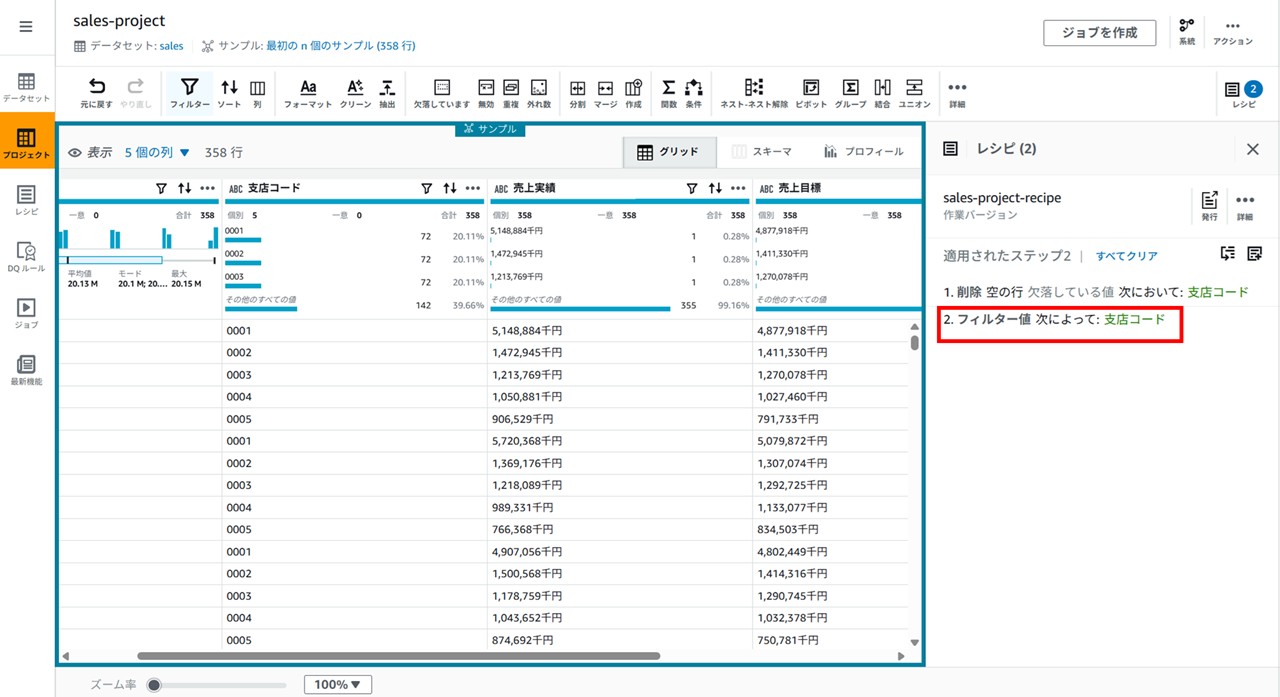
データセットの結合(支店コードをキーに branches を結合)
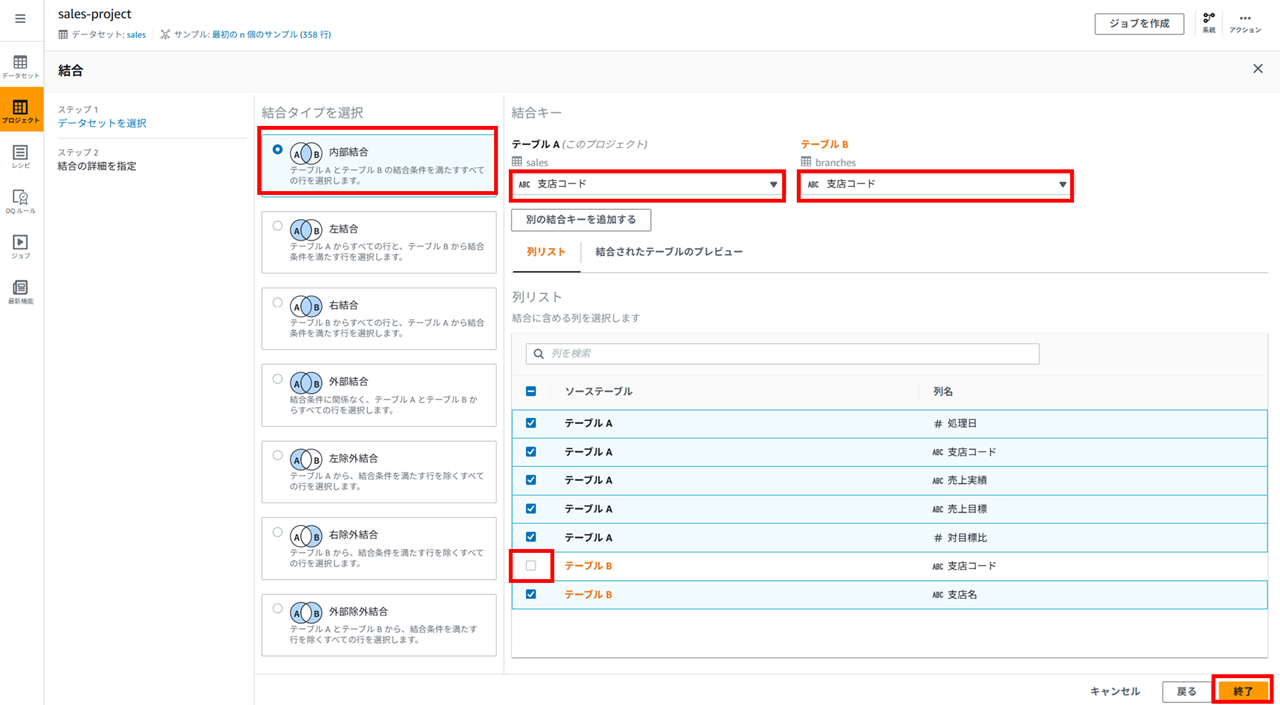
データセット同士の結合も可能です。上部バーの 「結合」 をクリックし、
結合するデータセットを選択して、
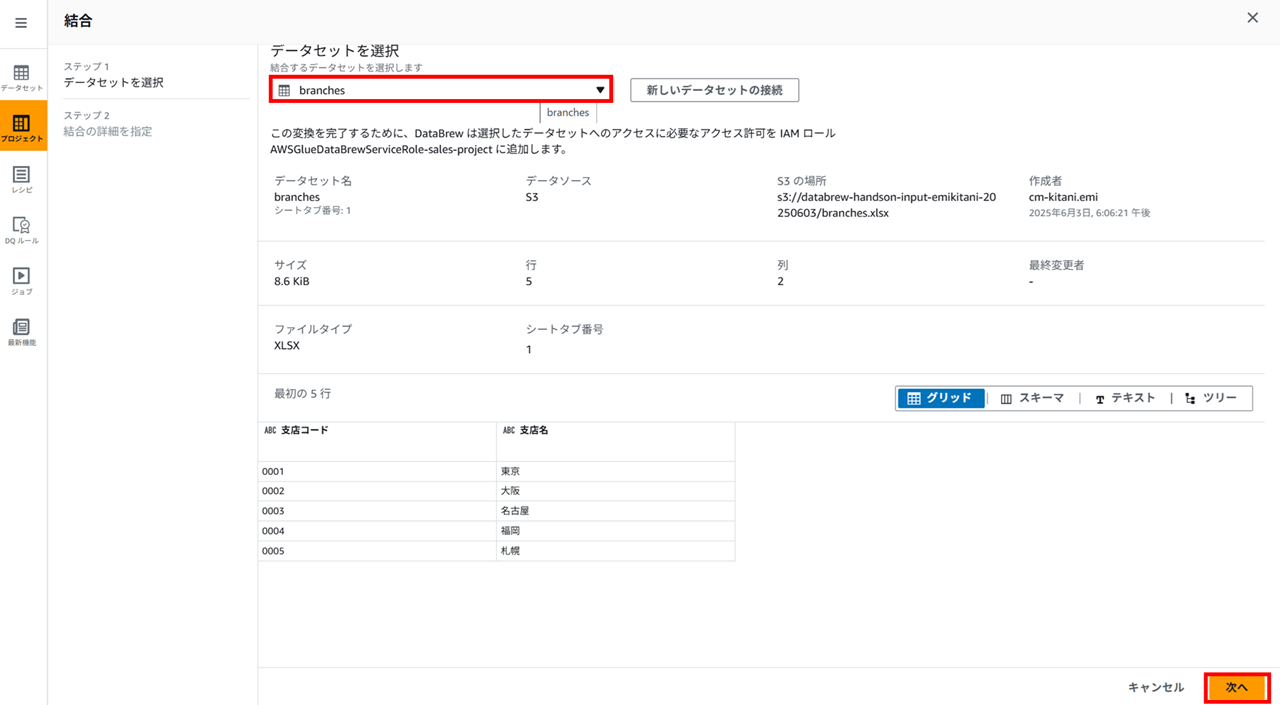
結合タイプと結合キーを指定します。
今回の内部結合タイプだと結合元と結合先で同じカラムができるので、片方の支店コードは外しておきます。
データ値の加工
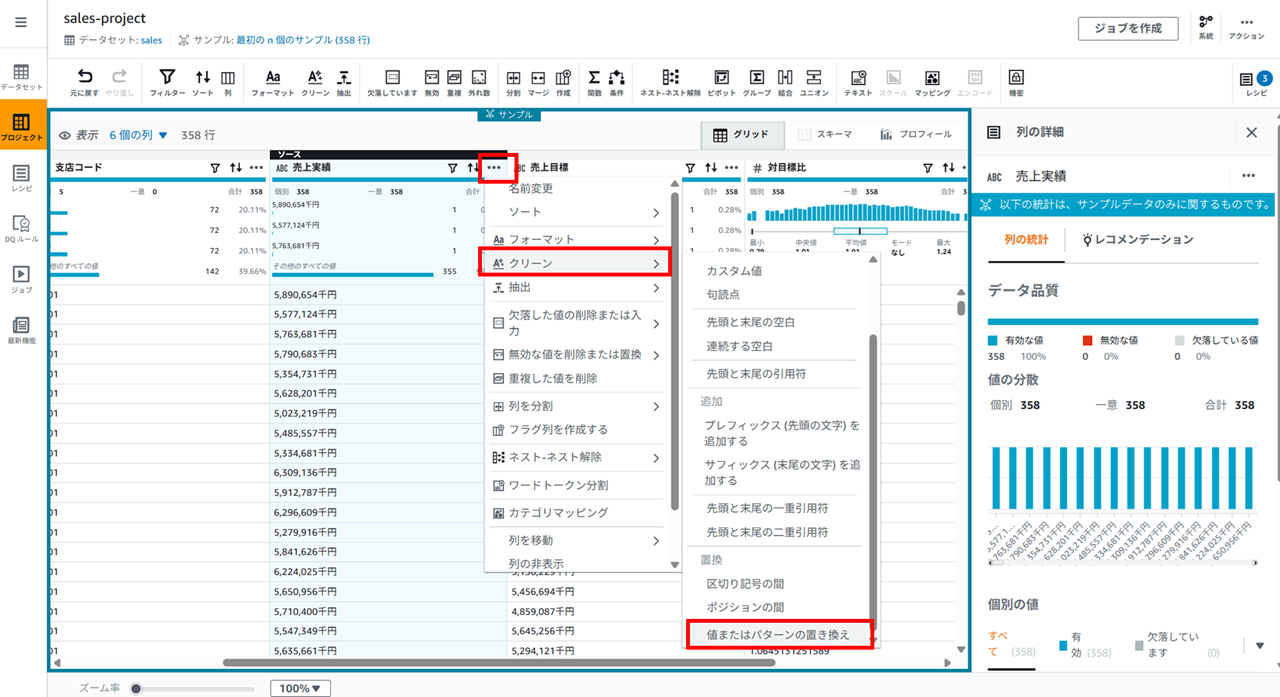
「千円」を「000」に置換
売上実績の 「…」 アイコンをクリックし、[クリーン] - [値またはパターンの置き換え] をクリックします。
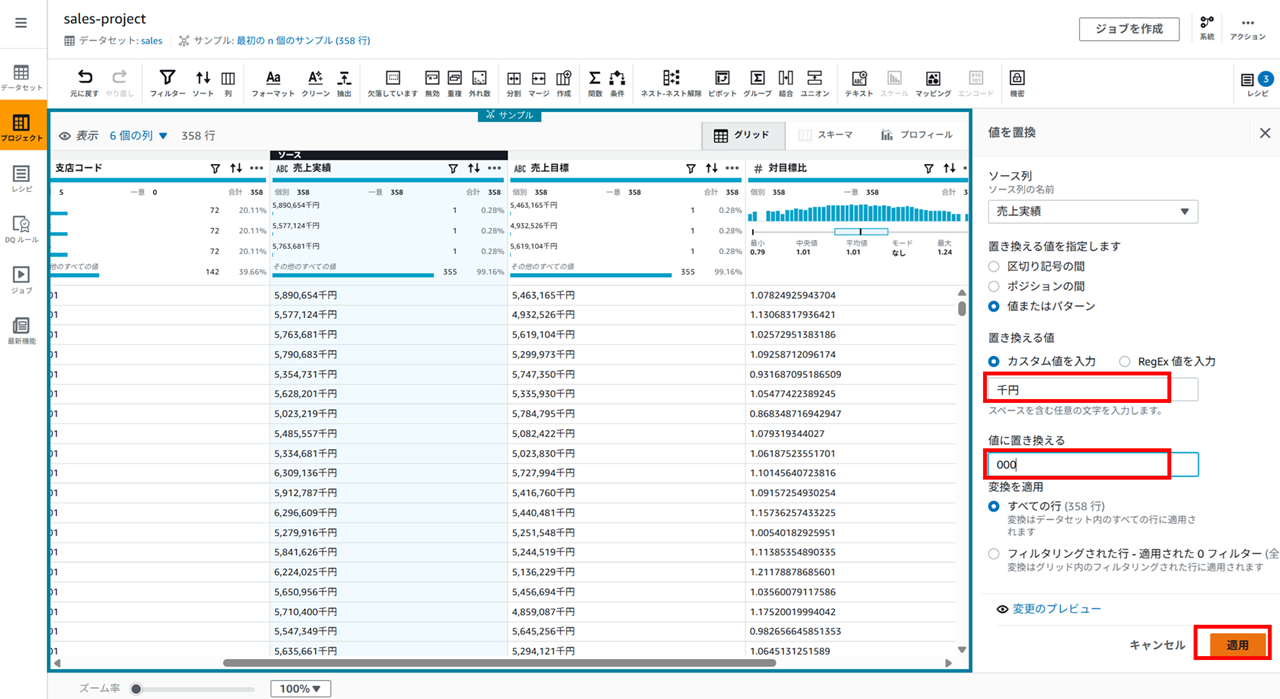
- 置き換える値に 「千円」
- 値に置き換える 「000」
として適用します。
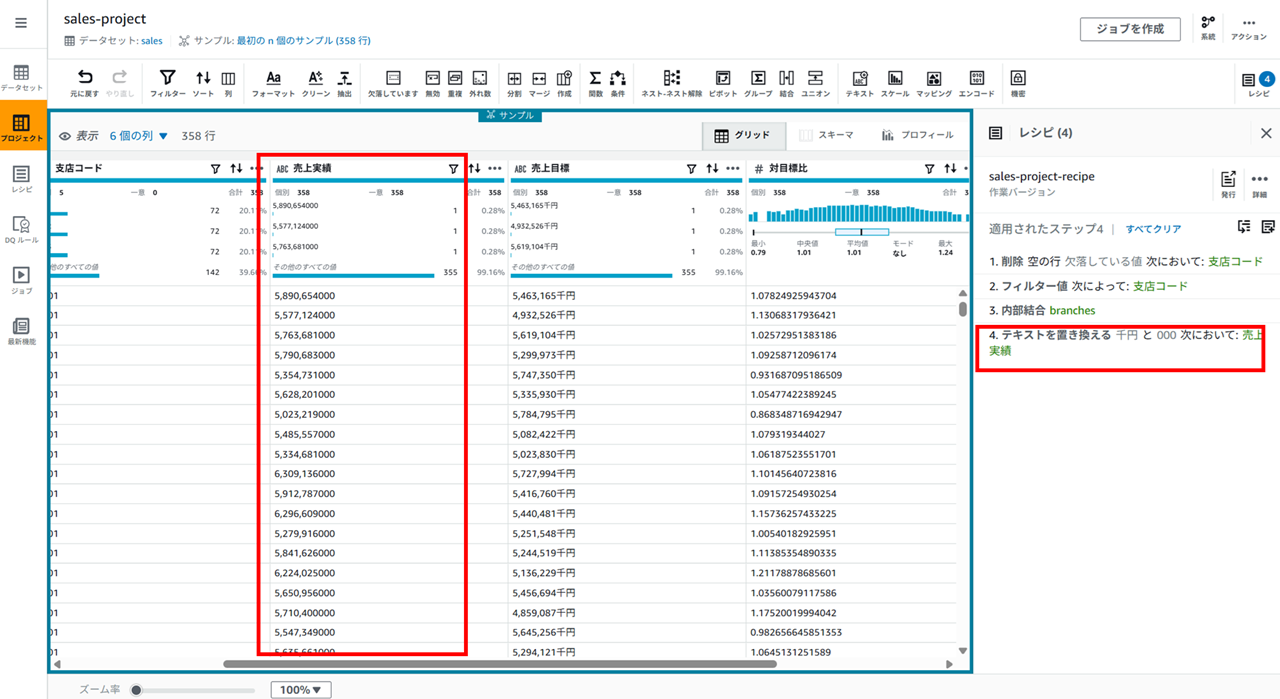
置き換わります。
カンマを削除
売上実績の 「…」 アイコンをクリックし、[クリーン] - [カスタム値] をクリックします。
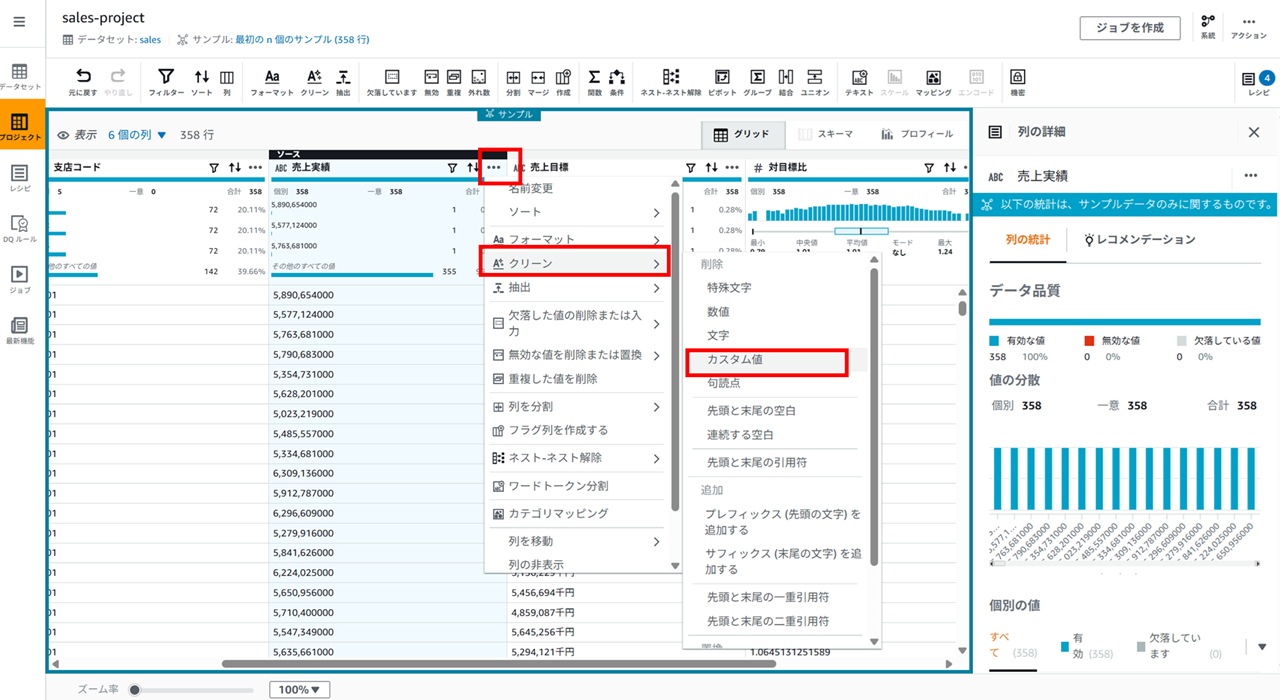
削除する値にカンマ (,) を入力して、
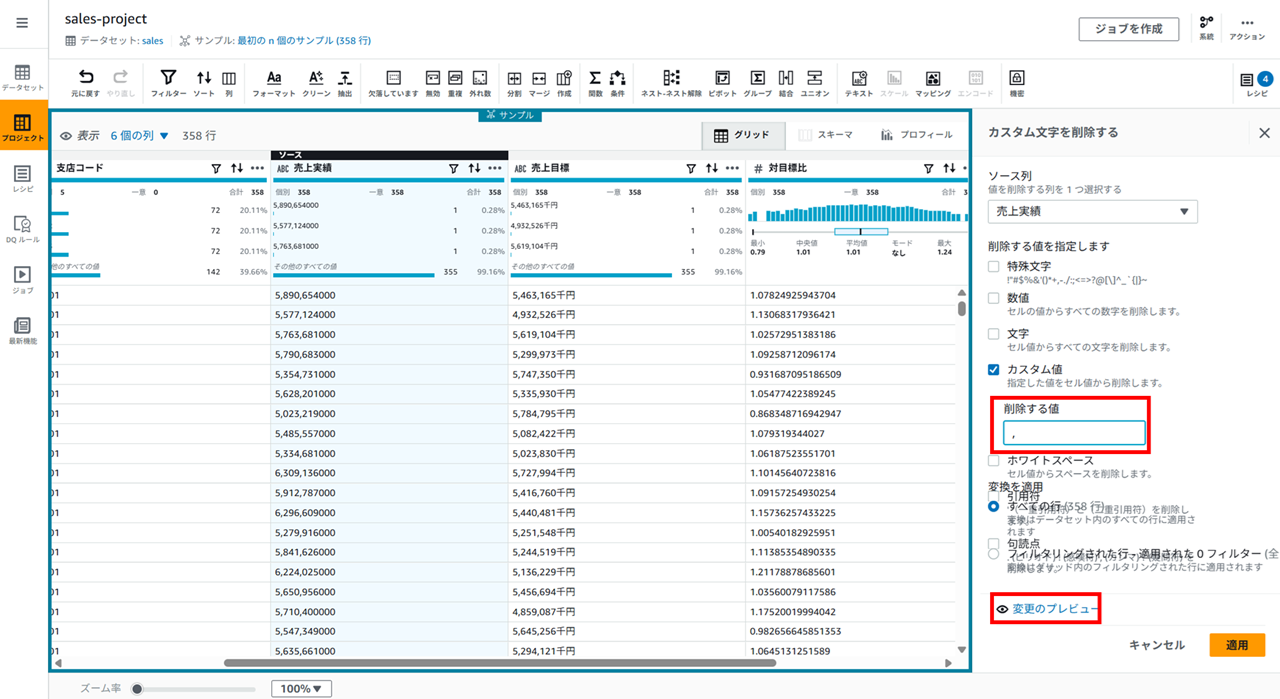
プレビューを確認して適用します。
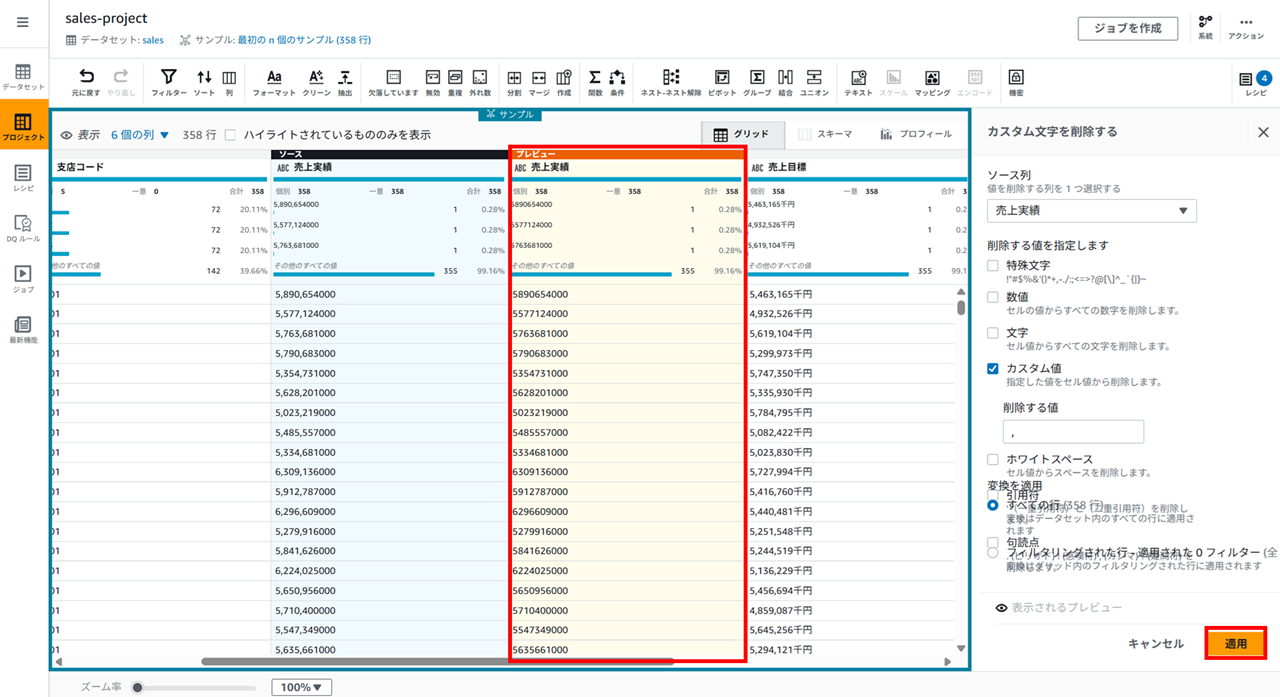
カラムの削除
カラムのメニューから不要なカラムの削除もできます。

日付の書式変更
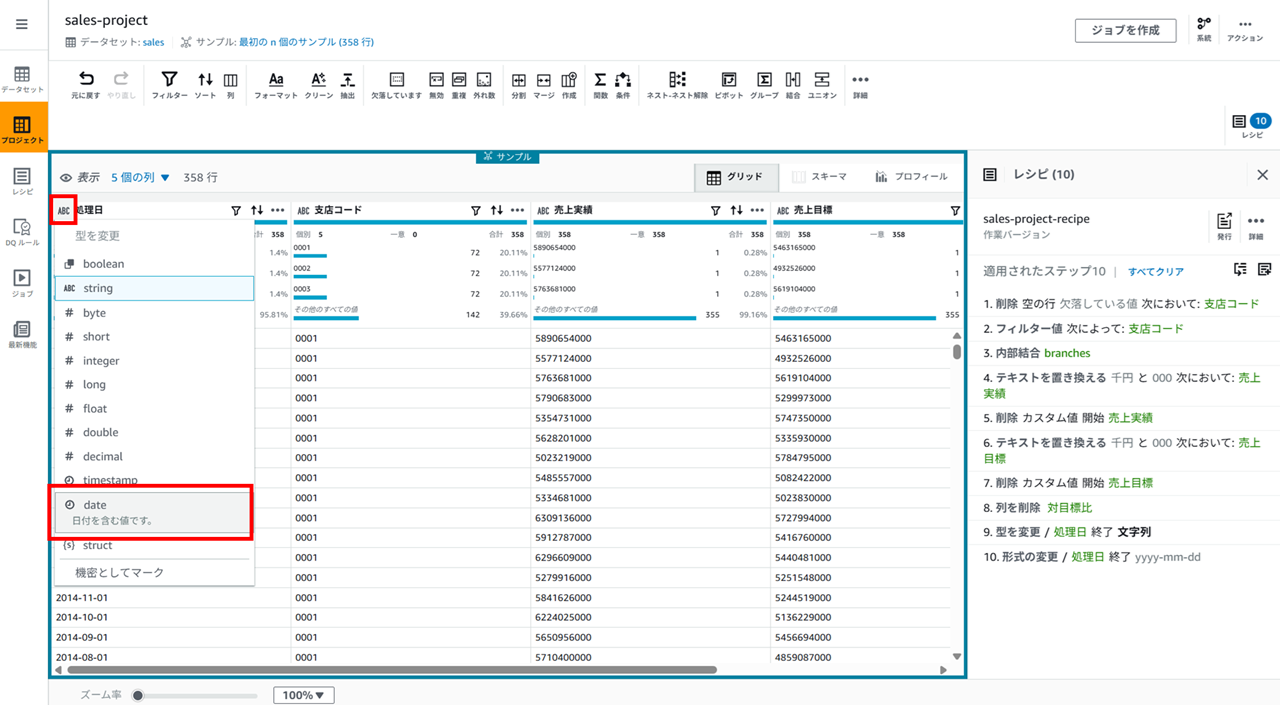
カラム名の左のアイコンをクリックすると、string 型、long 型など型を変更できます。処理日カラムを一旦文字列(string)型にします。
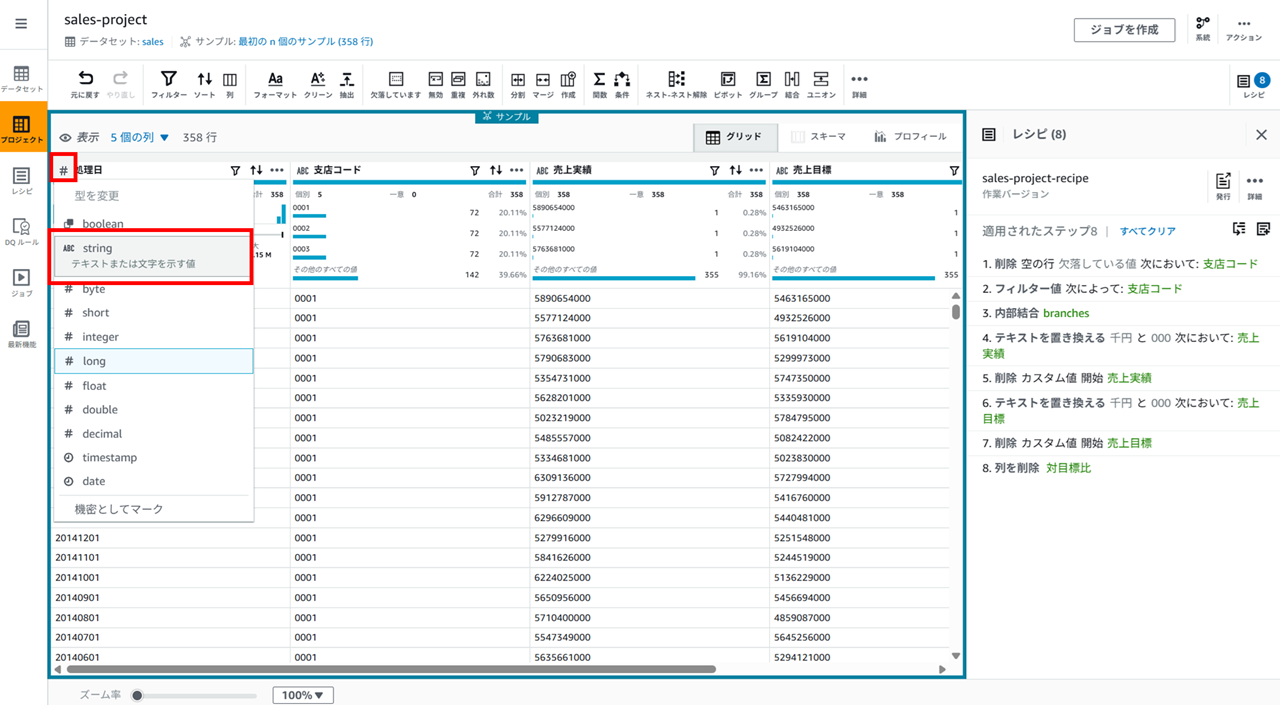
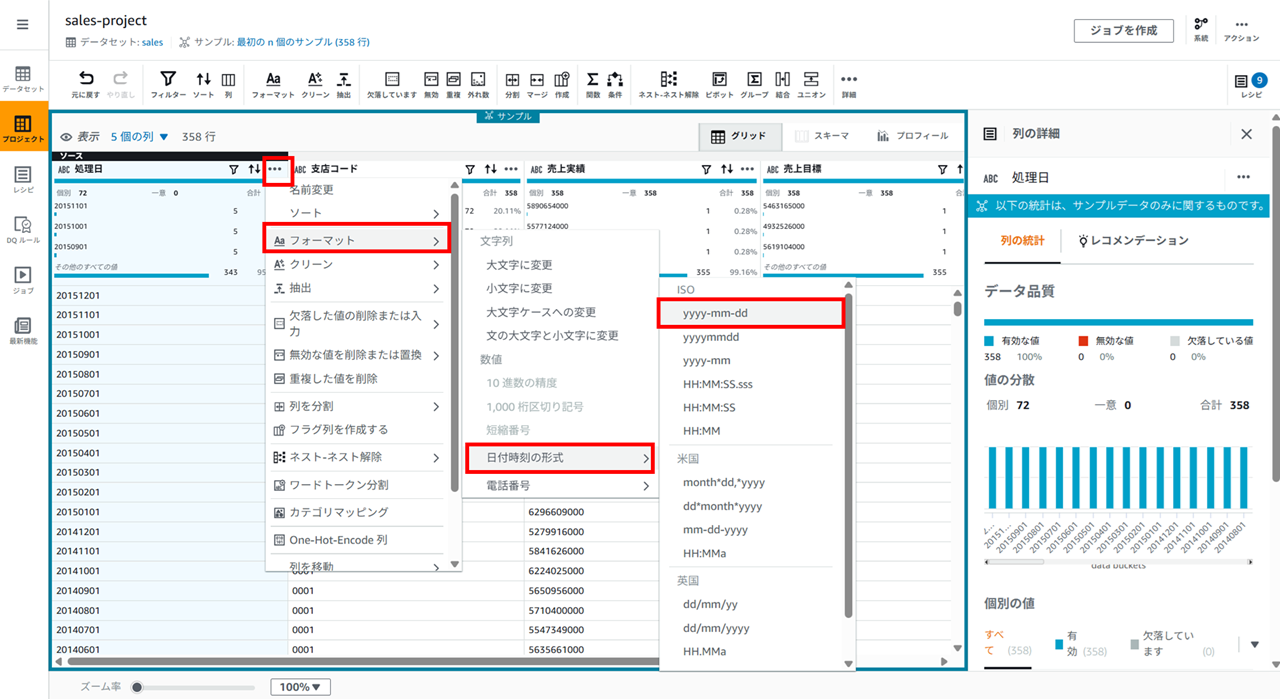
処理日カラムの 「…」 メニューから [フォーマット] - [日付時刻の形式] - [yyyy-mm-dd] を選択します。
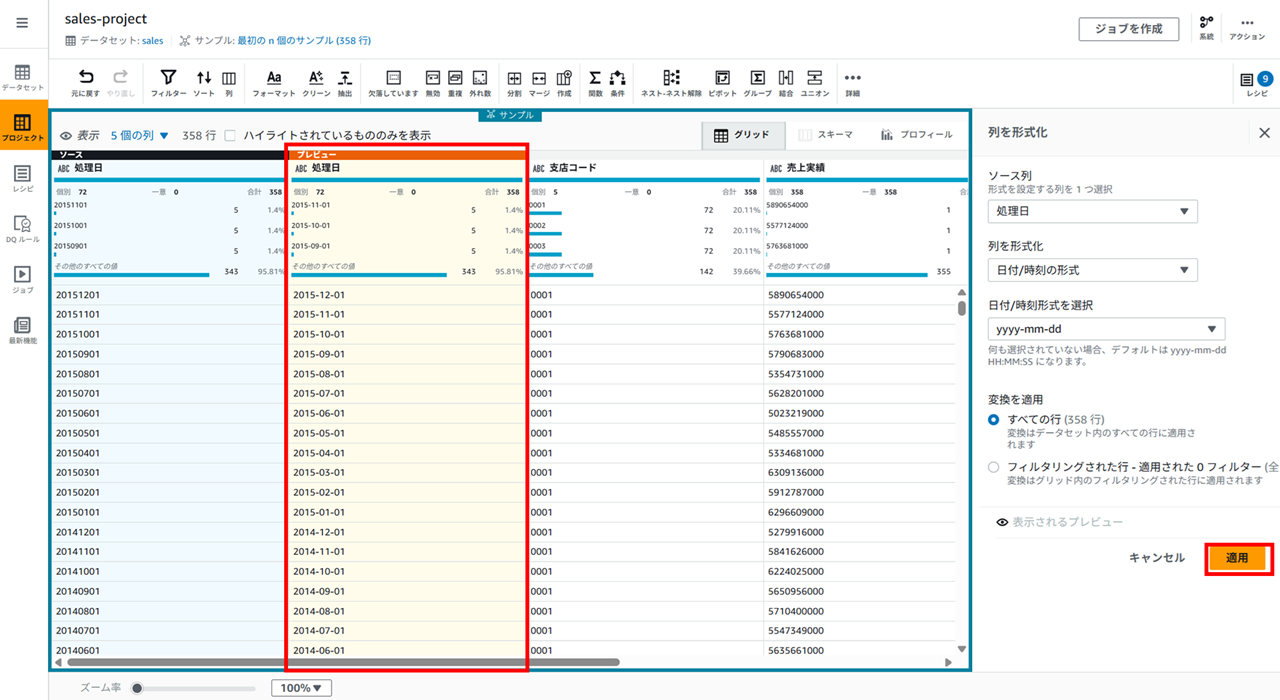
処理日を date 型にします。
セッション切れ
一部 DataBrew プロジェクトの操作と操作の間で時間を置いたのですが、再度プロジェクトを開くと以下のように待ち時間が発生しました。
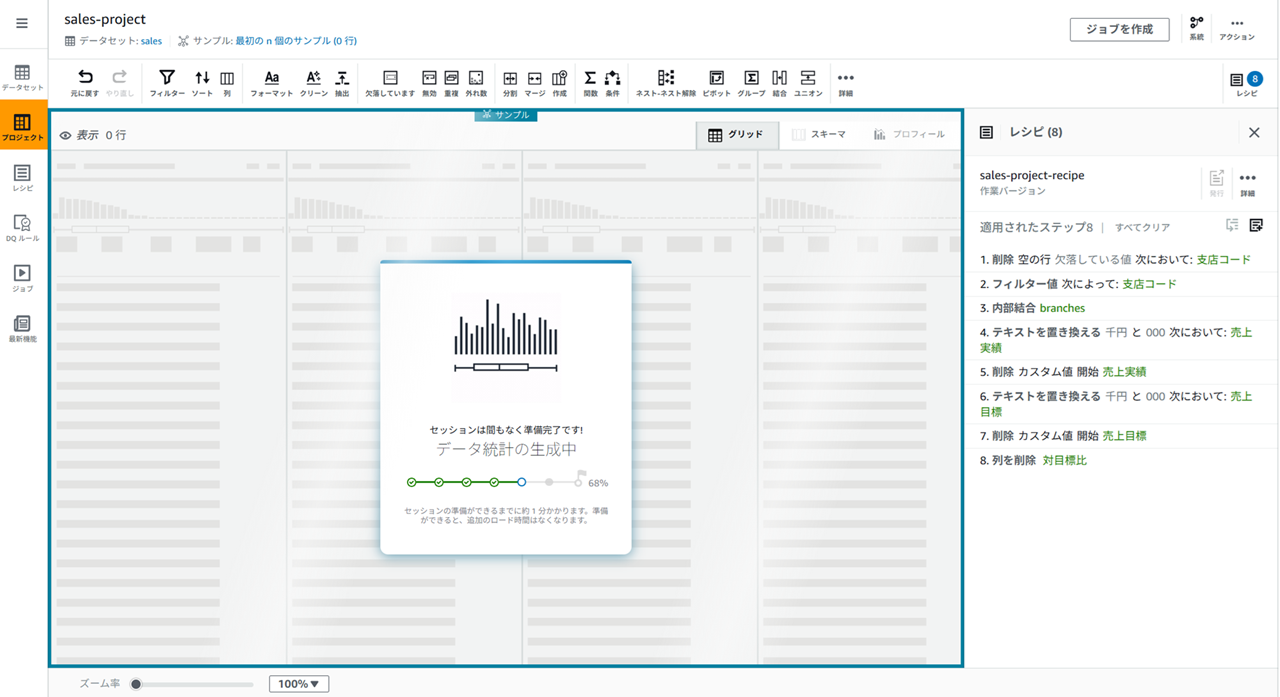
DataBrew プロジェクトには接続に インタラクティブセッション の概念があり、30 分操作せずに放置するとセッションが切れるそうです。30 分以上操作しないと再度プロジェクトを開くのに毎回 1 分程度待つことになります。
料金は 1 ユーザー 1 セッション 1 USD となっています。
ジョブの作成
DataBrew ジョブでは作成したレシピを実行します。
ジョブ名、加工したデータの出力先 S3 バケットのパスを指定します。
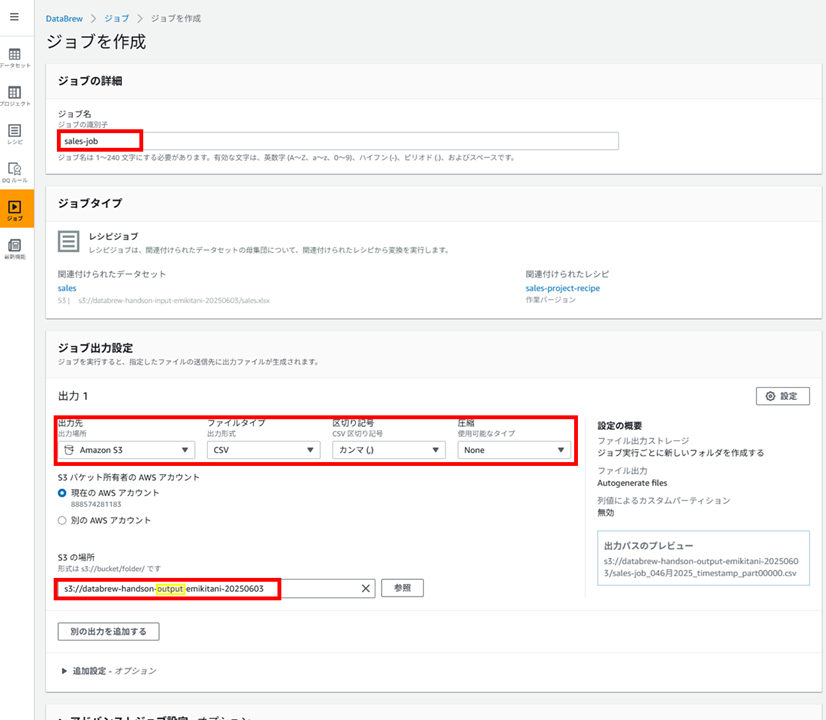
出力するファイルタイプは以下から選択できました。
- CSV
- Parquet
- GlueParquet
- Avro
- ORC
- XML
- JSON
- Tableau Hyper
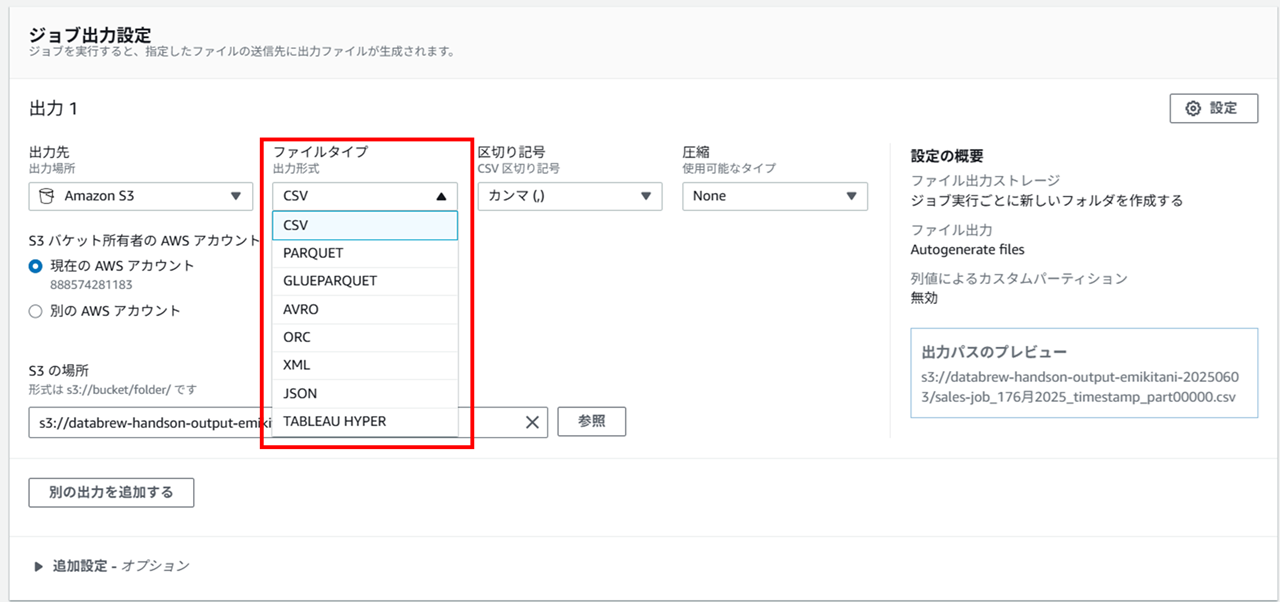
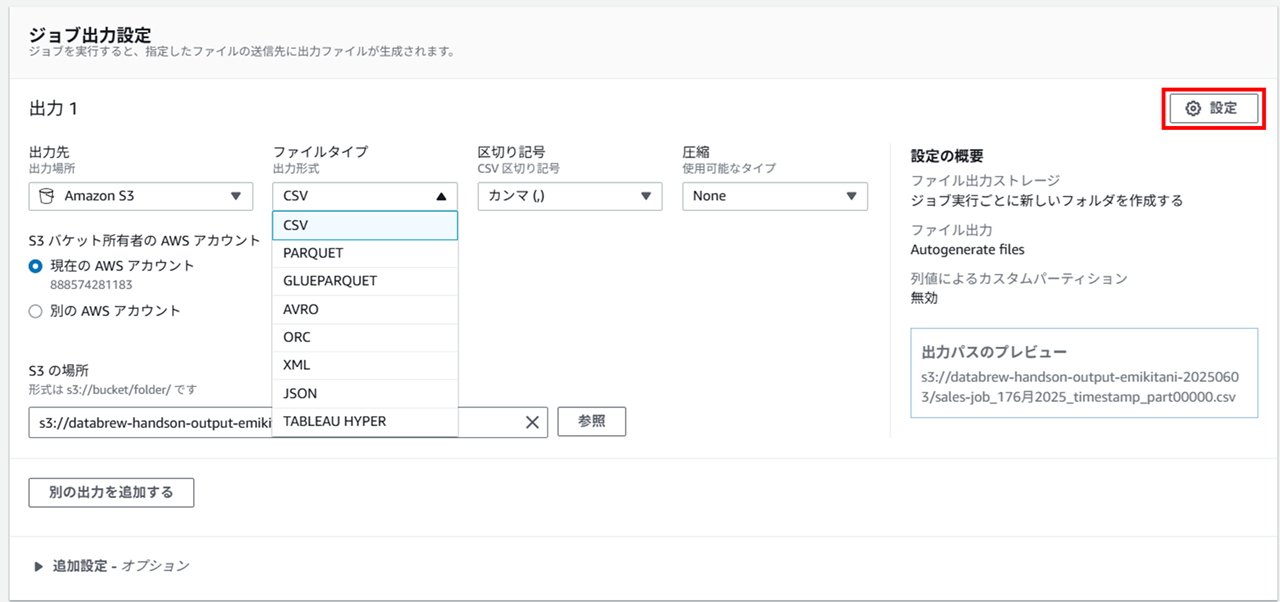
加工済みデータファイルの出力形式について
ジョブの出力設定右上の 「設定」 を開くと、
「ファイルパーティショニング」 で出力ファイルの分割形式を選択できます。ちょっと Excel ファイルを加工して加工後も CSV を Excel で開きたい、みたいな場合は単一ファイル出力にしておくと便利そうです。
ただし、単一ファイル出力にするとジョブの実行時間が長くなる可能性があります。
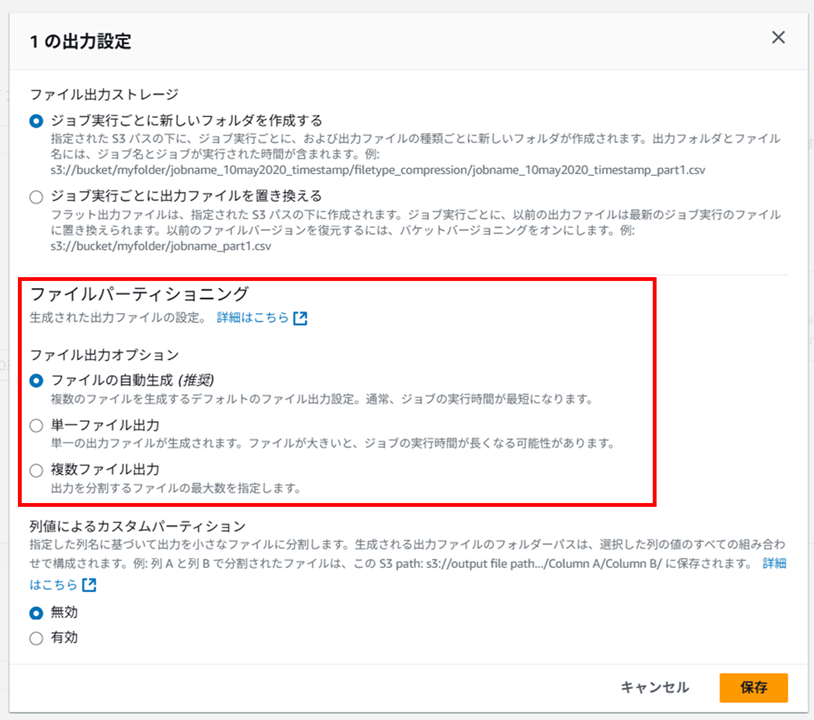
さて、ジョブの作成に戻ります。
ジョブ用の IAM ロールを新規作成します。IAM ロール名のサフィックスを指定しジョブを作成します。
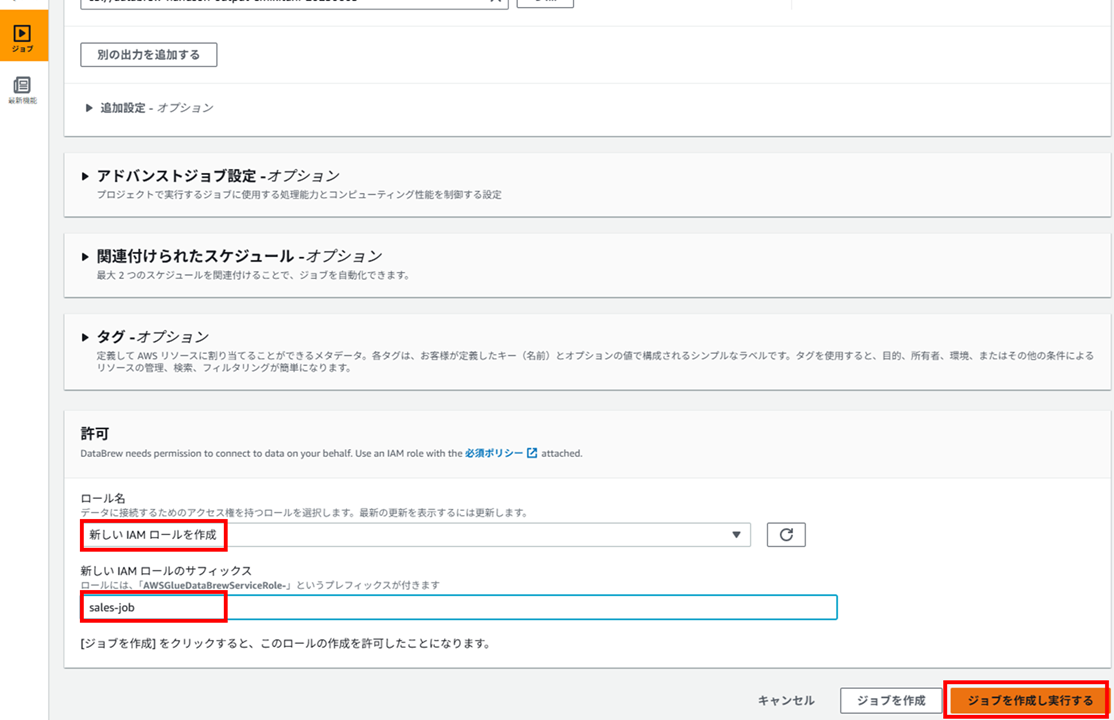
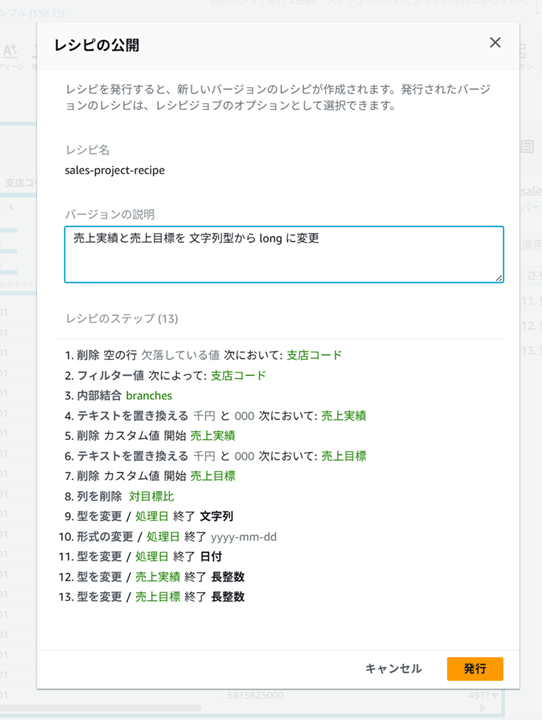
説明を入力してレシピを発行します。
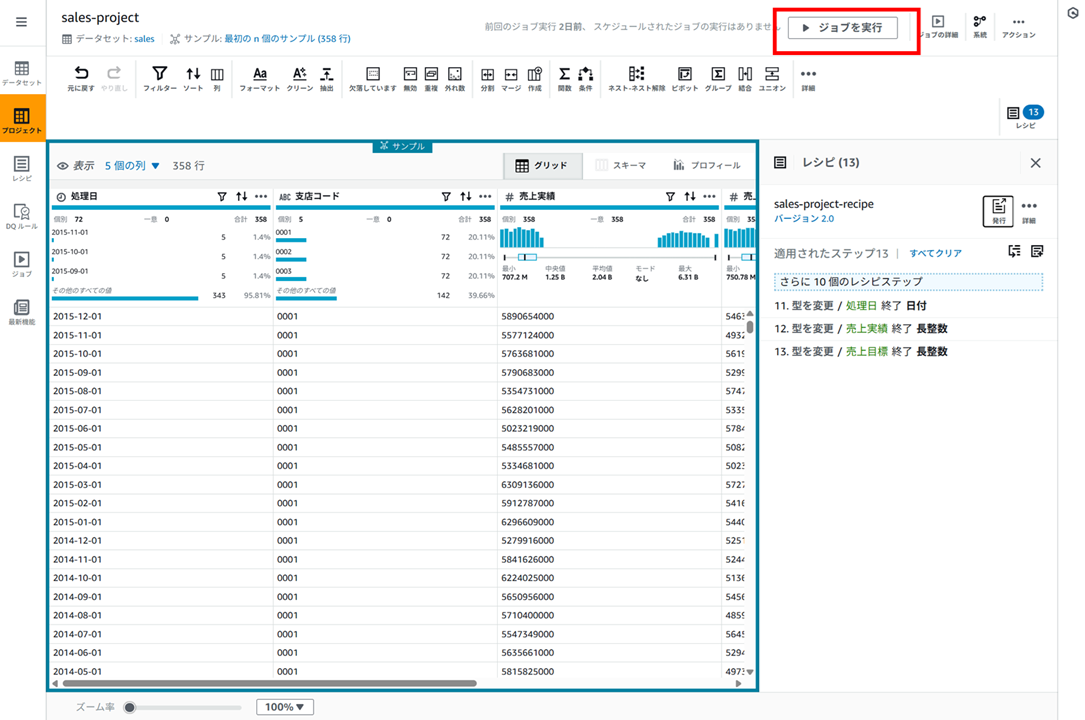
ジョブの実行
右上の 「ジョブを実行」 をクリックし、
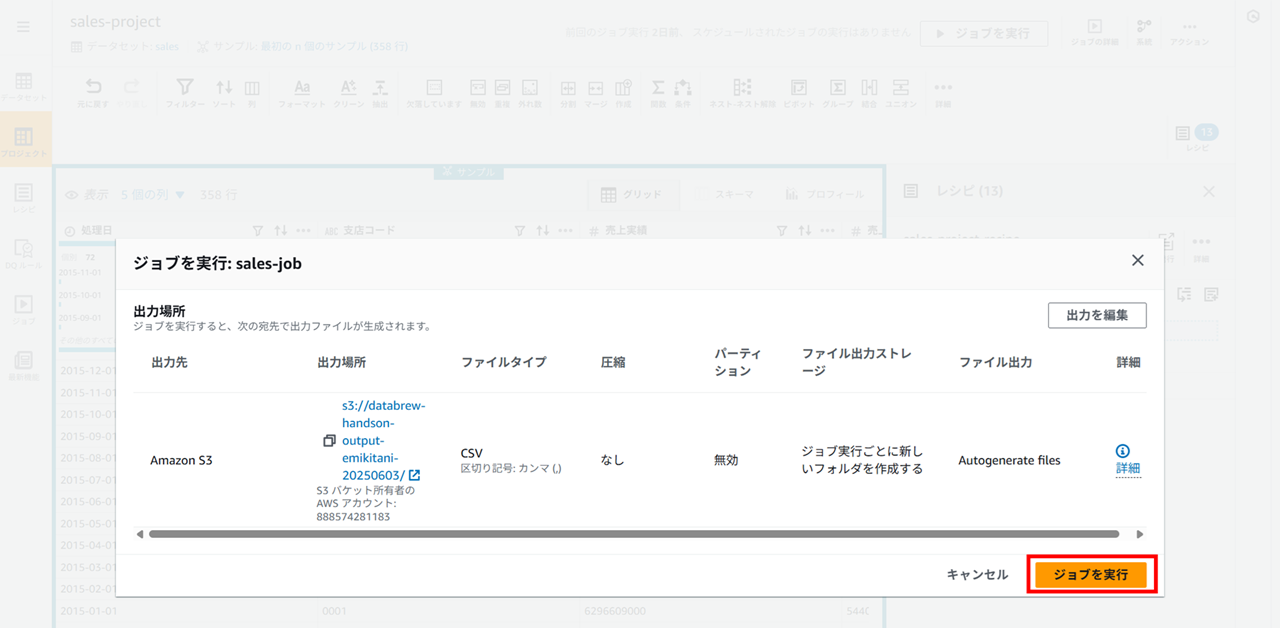
ジョブを実行し、データを実際に加工します。
ジョブ完了までに 3~5 分程度かかりました。
参考ですが、sales.xlsx が 60KB で、branches.xlsx が 9KB でした。
アウトプット用の S3 バケットを確認すると、
以下のように複数のファイルの分かれて出力されました。
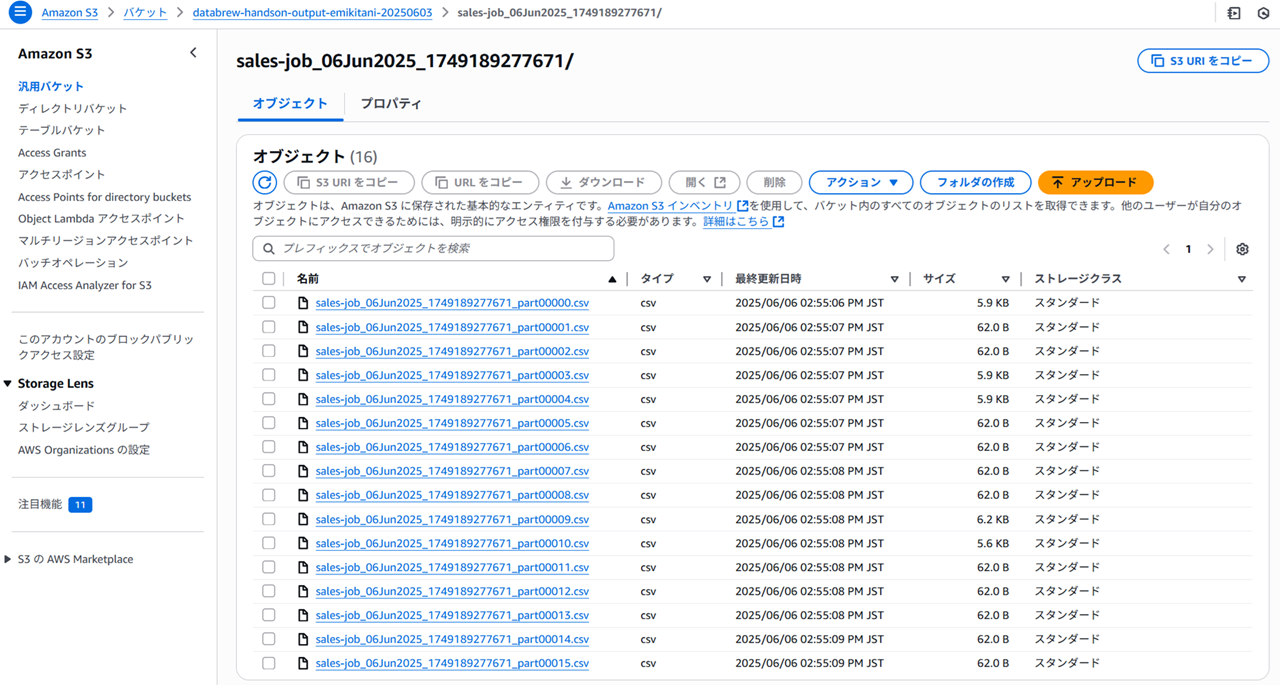
ファイルが複数だったので、AWS CLI でまとめてローカルにダウンロードして内容を確認します。
実行コマンド
aws s3 sync s3://databrew-handson-output-emikitani-20250603/sales-job_06Jun2025_1749189277671/ ./ --profile cm-kitani.emi
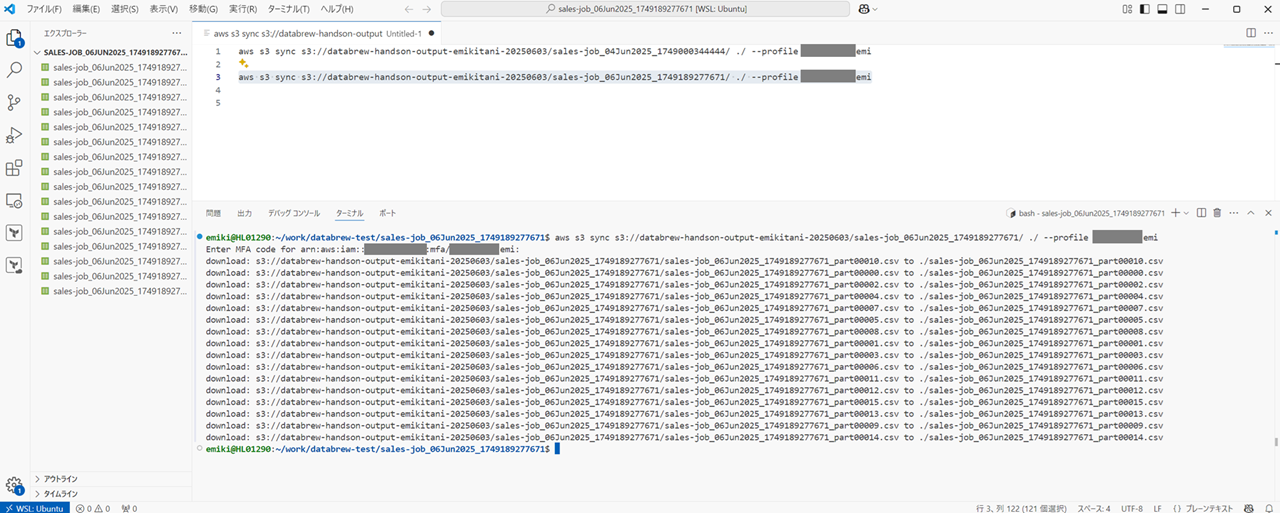
ちなみに私の手元の端末は Windows 11 でして、Windows 11 にインストールした WSL に 更に AWS CLI をインストールしてクレデンシャルをセットアップし、WSL を VSCode 拡張を使って VSCode で操作しています。
WSL 内にダウンロードすると以下のようになっています。1KB のファイルと 6KB のファイルがあります。
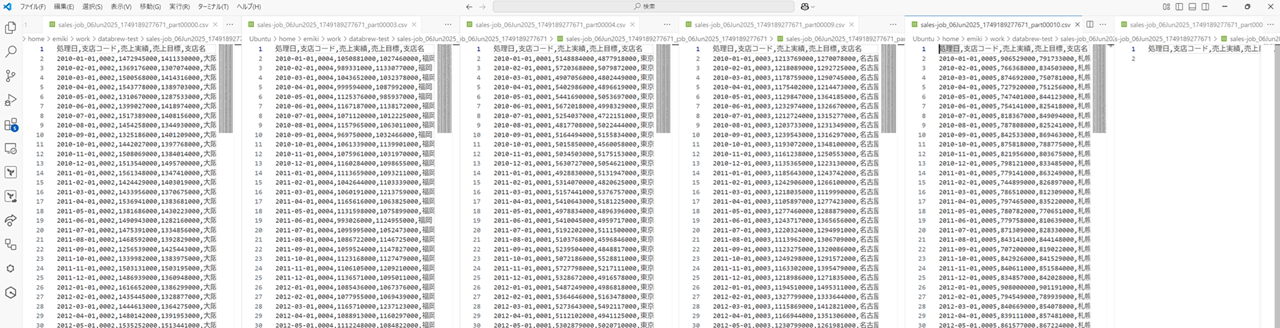
6KB のファイルを開くと以下のようになっていました。対象都道府県ごとにファイルが分かれているようです。ちなみに 1KB のファイルを開くとカラム名だけでした。
Glue DataBrew で加工済のデータを Athena 経由でクエリする
さて、S3 バケット output 要に格納できたこの加工済みファイルを Athena 経由で QuickSight で可視化していきます。
まずは Athena で S3 バケット output 用にクエリしていきます。
まずはデータベースを作成します。Athena から作成しても良いのですが、Glue のコンソールから手動で作成しました。名前は sales-db としています。
この後ハンズオンの Glue クローラーの手順を実施したのですがどうにもうまくいかず… Athena 側からおとなしく外部テーブルを作成する SQL 文を書きました。
ハンズオンの Glue クローラーの手順を実施したがうまくいかず、1 つのテーブルにデータが出てほしいのに、分散した CSV ファイルごとにテーブルが作成されてしまった様子
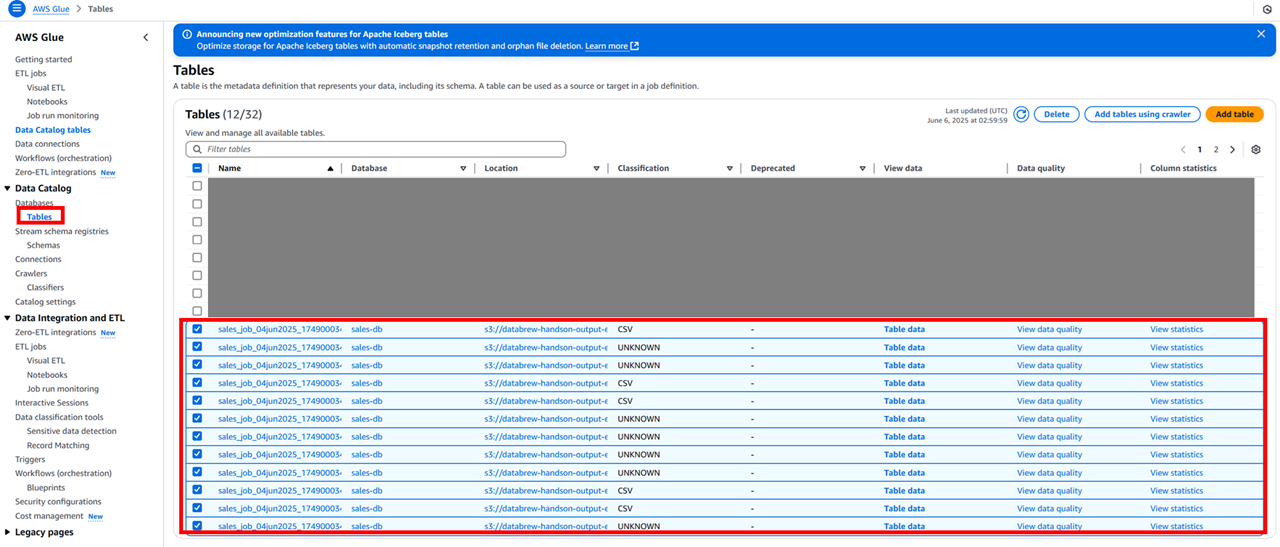
あれあれ…
Athena テーブル作成失敗クエリ
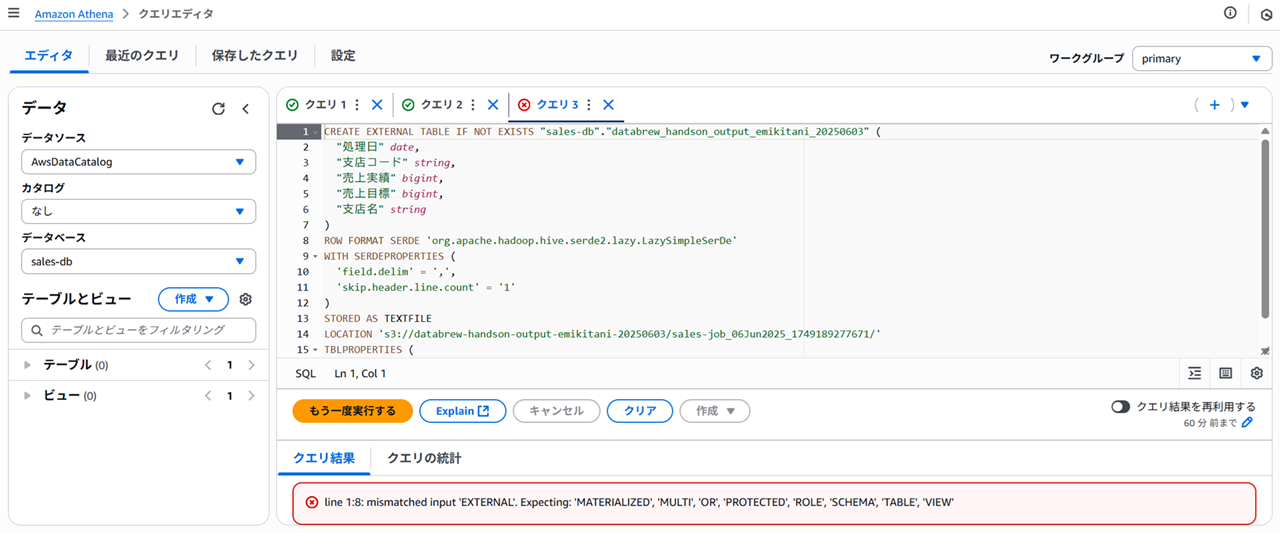
- 失敗クエリその1
- ダブルクォーテーション(”)だと
line 1:8: mismatched input 'EXTERNAL'. Expecting: 'MATERIALIZED', 'MULTI', 'OR', 'PROTECTED', 'ROLE', 'SCHEMA', 'TABLE', 'VIEW’と言うエラーになる
- ダブルクォーテーション(”)だと
CREATE EXTERNAL TABLE IF NOT EXISTS "sales-db"."databrew_handson_output_emikitani_20250603" (
"処理日" date,
"支店コード" string,
"売上実績" bigint,
"売上目標" bigint,
"支店名" string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim' = ',',
'skip.header.line.count' = '1'
)
STORED AS TEXTFILE
LOCATION 's3://databrew-handson-output-emikitani-20250603/sales-job_06Jun2025_1749189277671/'
TBLPROPERTIES (
'has_encrypted_data'='false'
);
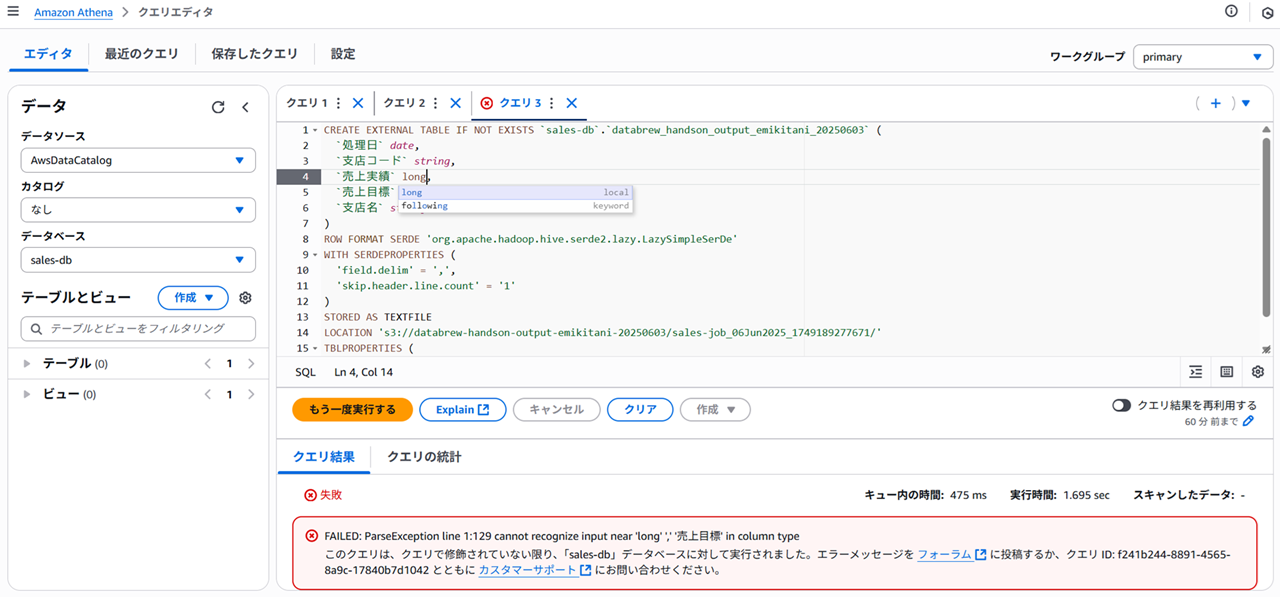
- 失敗クエリその2
- long 型だと
FAILED: ParseException line 1:129 cannot recognize input near 'long' ',' '売上目標' in column typeになる。候補に出るのになぜ…
- long 型だと
CREATE EXTERNAL TABLE IF NOT EXISTS `sales-db`.`databrew_handson_output_emikitani_20250603` (
`処理日` date,
`支店コード` string,
`売上実績` long,
`売上目標` long,
`支店名` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim' = ',',
'skip.header.line.count' = '1'
)
STORED AS TEXTFILE
LOCATION 's3://databrew-handson-output-emikitani-20250603/sales-job_06Jun2025_1749189277671/'
TBLPROPERTIES (
'has_encrypted_data'='false'
);
S3 の内容をクエリするための Athena 外部テーブル作成成功クエリは以下です。
CREATE EXTERNAL TABLE IF NOT EXISTS `sales-db`.`databrew_handson_output_emikitani_20250603` (
`処理日` date,
`支店コード` string,
`売上実績` bigint,
`売上目標` bigint,
`支店名` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim' = ',',
'skip.header.line.count' = '1'
)
STORED AS TEXTFILE
LOCATION 's3://databrew-handson-output-emikitani-20250603/sales-job_06Jun2025_1749189277671/'
TBLPROPERTIES (
'has_encrypted_data'='false'
);
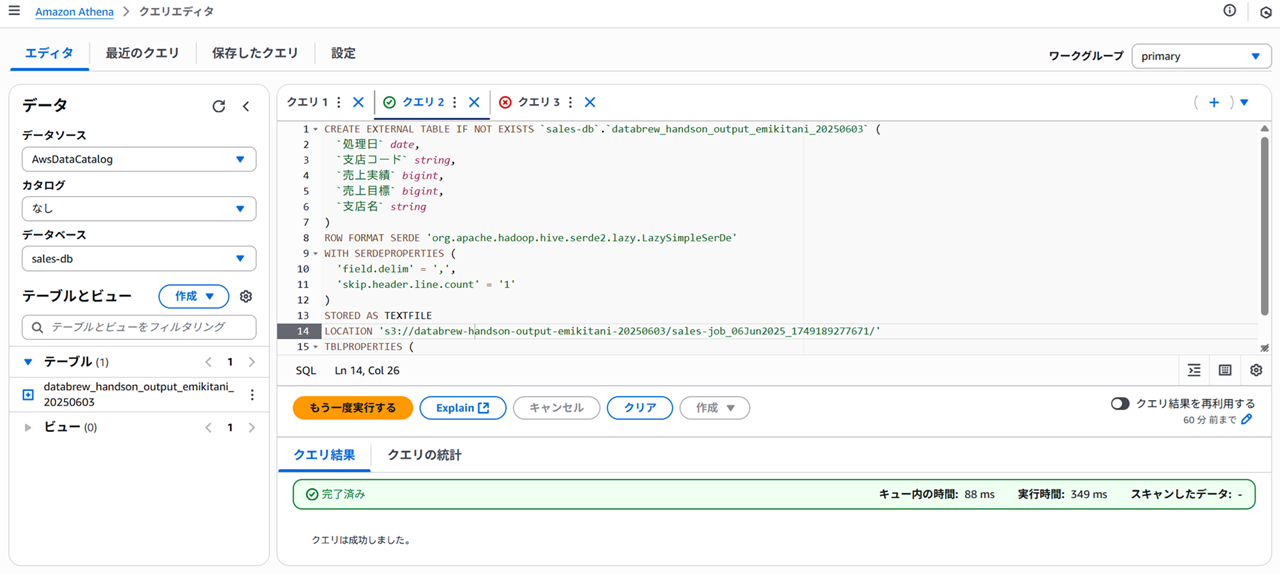
「テーブルをプレビュー」 で確認すると、以下のようにちゃんと S3 バケット output 用に出力された CSV ファイルの中身がクエリできています。

QuickSight で可視化する
QuickSight で可視化します。
可視化する前に、QuickSight の管理から S3 バケット output 用へのアクセスを許可しておきます。
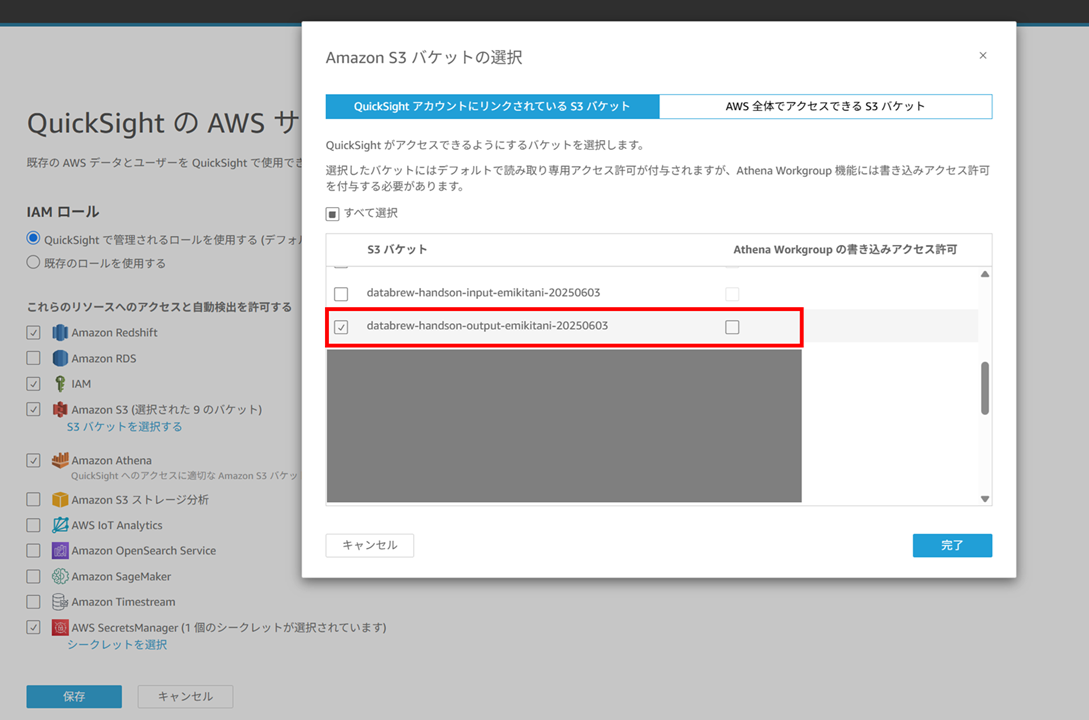
では Athena をデータソースとしてデータセットを作成していきます。データソース名を指定します。ワークグループは primary を使っていたので primary を選択したまま進めます。
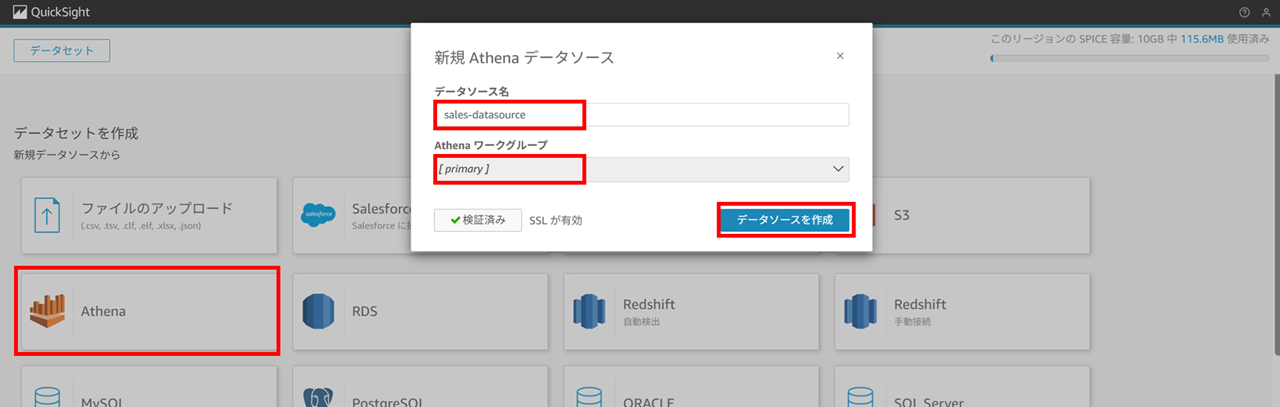
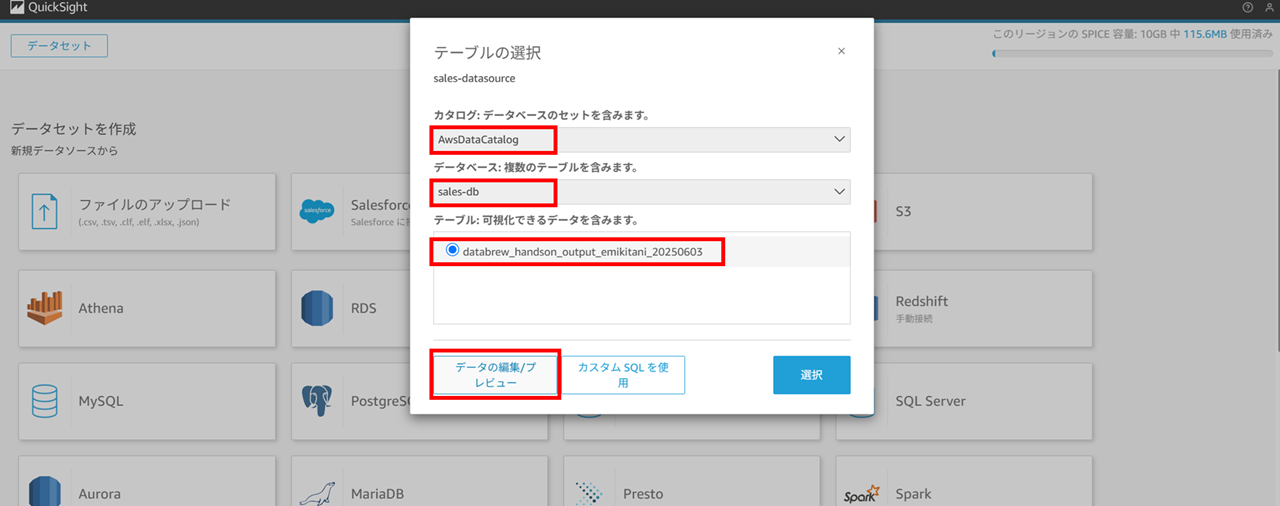
カタログはデフォルトの AwsDataCatalog を選択します。するとデータベースで先ほど作成した sales-db が選択できるはずですので、選択し、「データの編集/プレビュー」 を押下します。
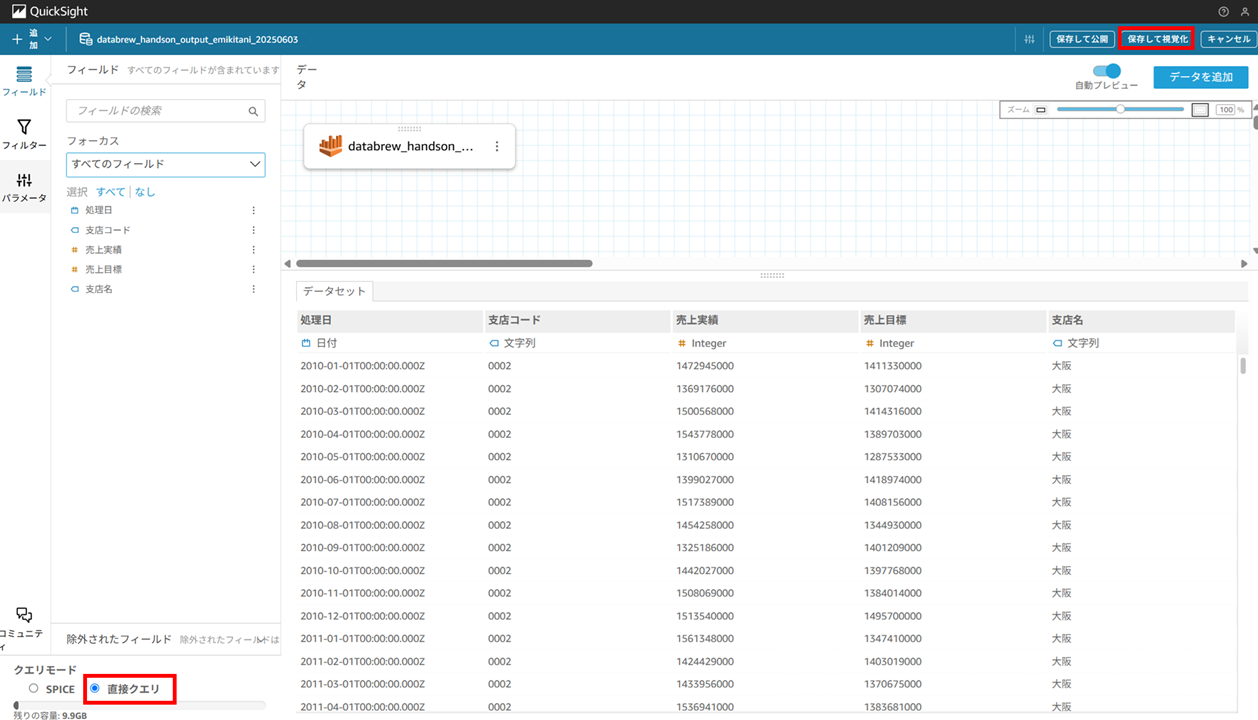
データのプレビューが 1000 行表示されます。今回は直接クエリ(ダイレクトクエリ)のまま、「保存して視覚化」 でデータセットを保存し、分析を作成します。
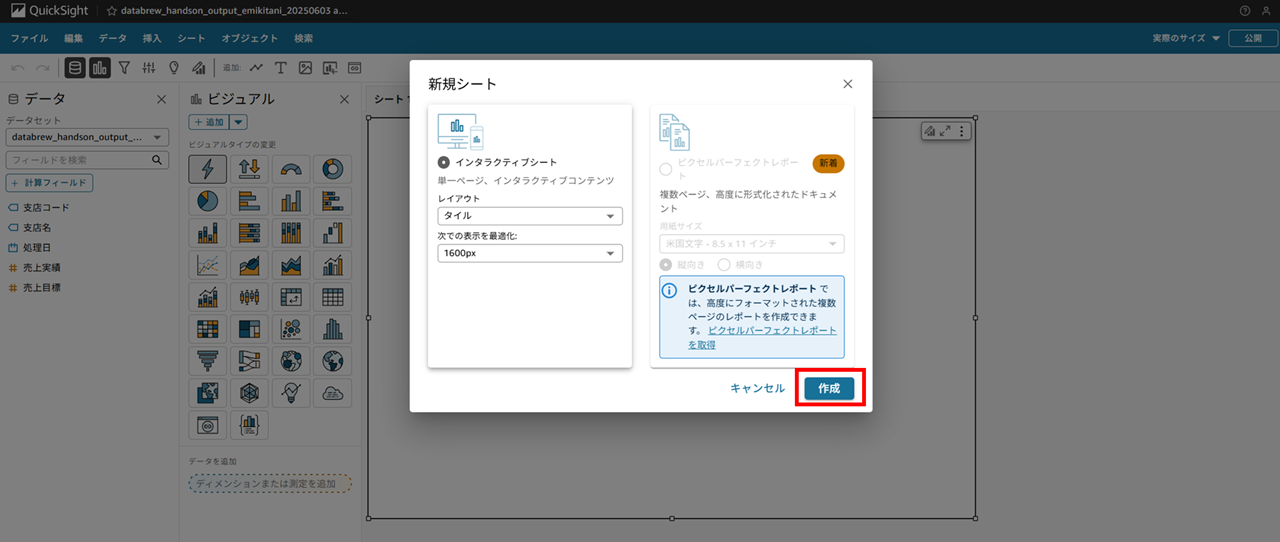
作成で進めます。
垂直棒グラフのビジュアルを作成し、画像のように X 軸、値、グループ/色 を設定します。
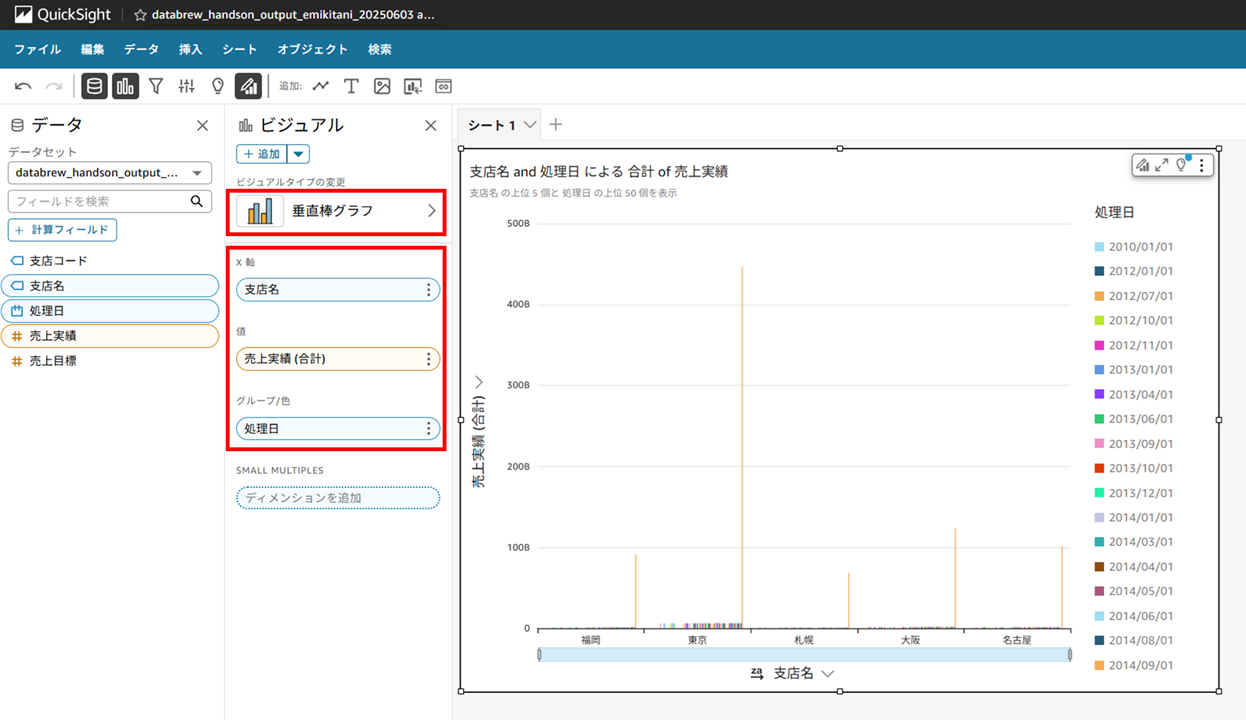
画面上のバーのフィルターから処理日を選択し、
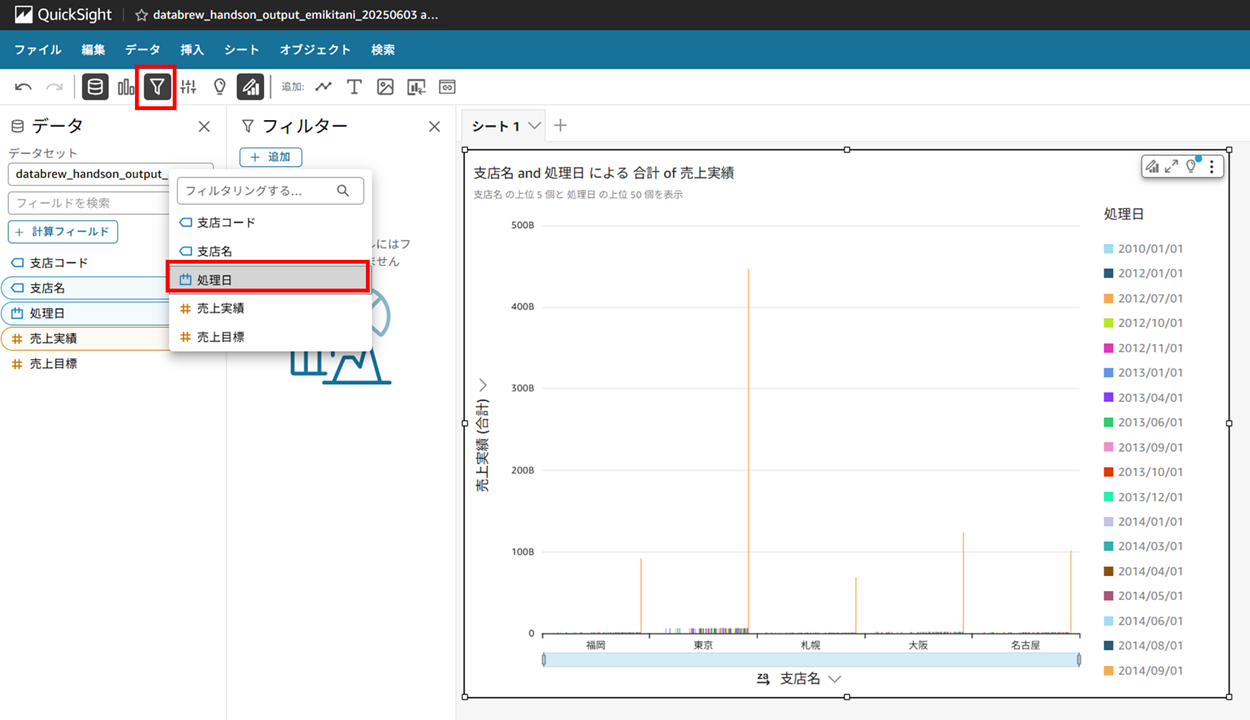
処理日が追加できたらコントロールを追加します。
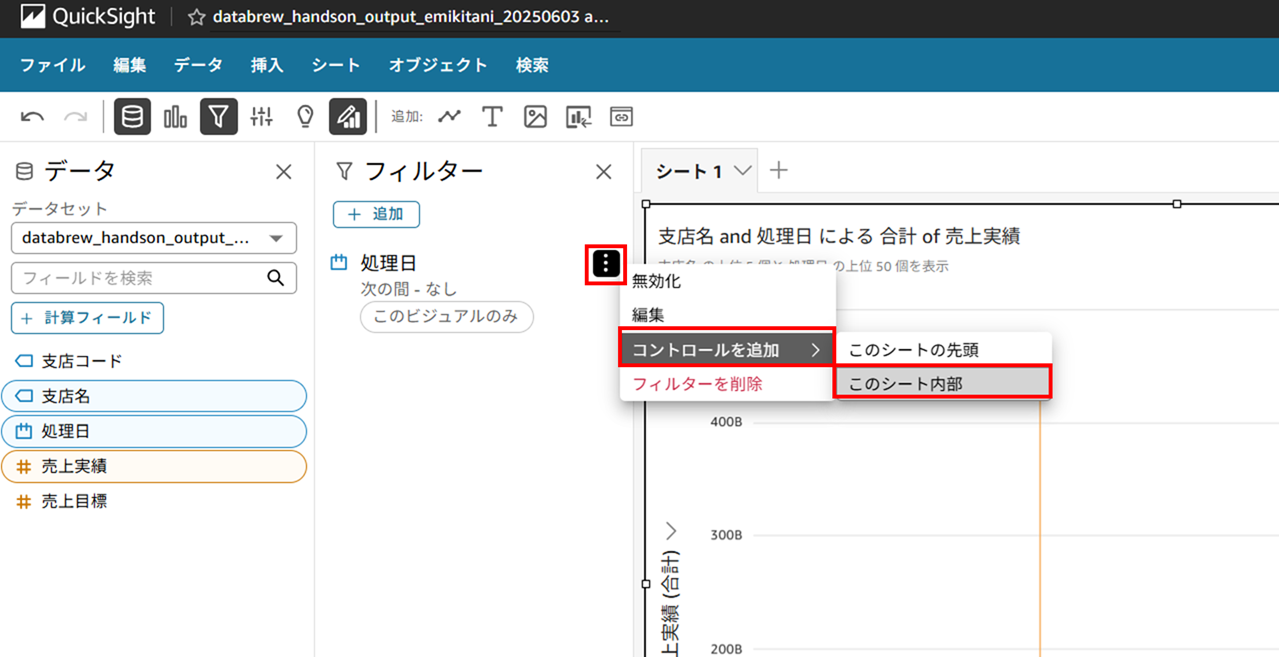
再度フィルタを編集します。
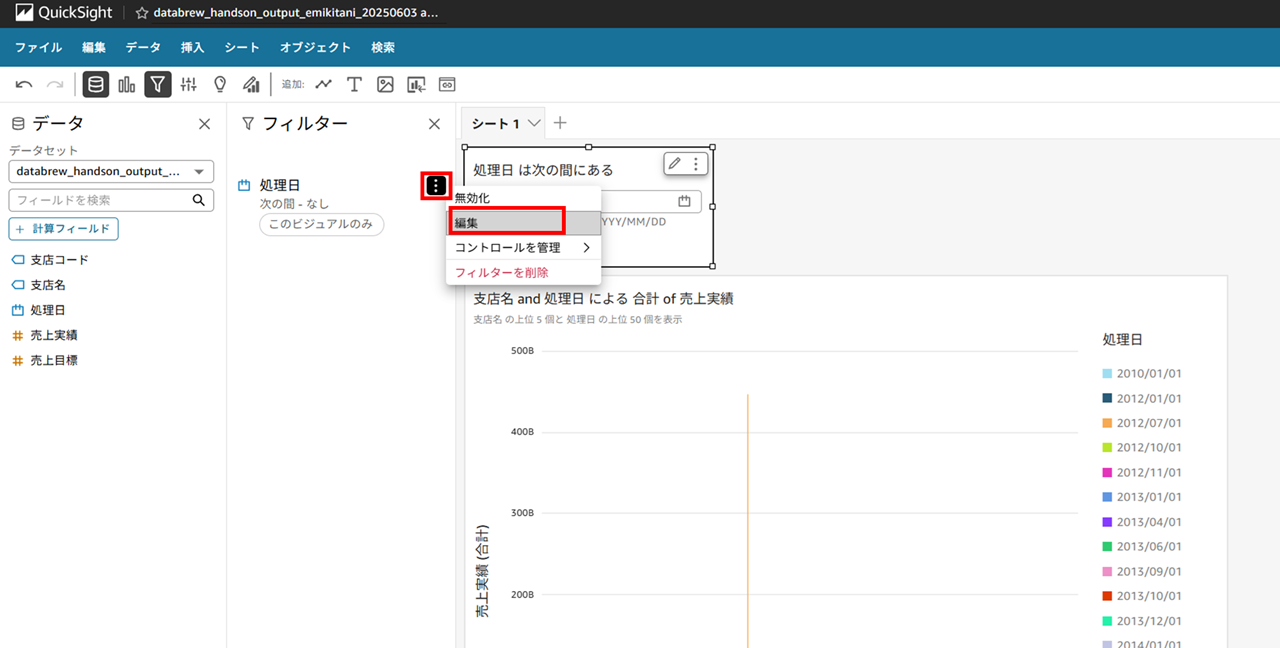
処理日を範囲で選択できるようにします。
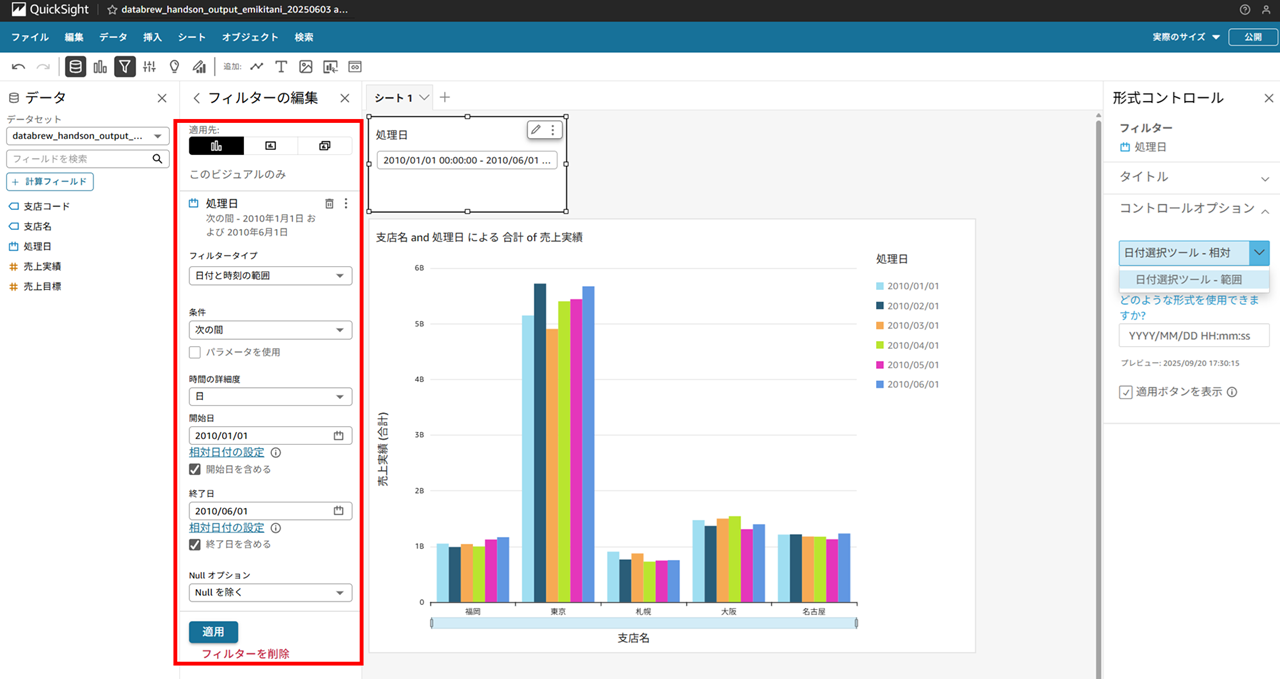
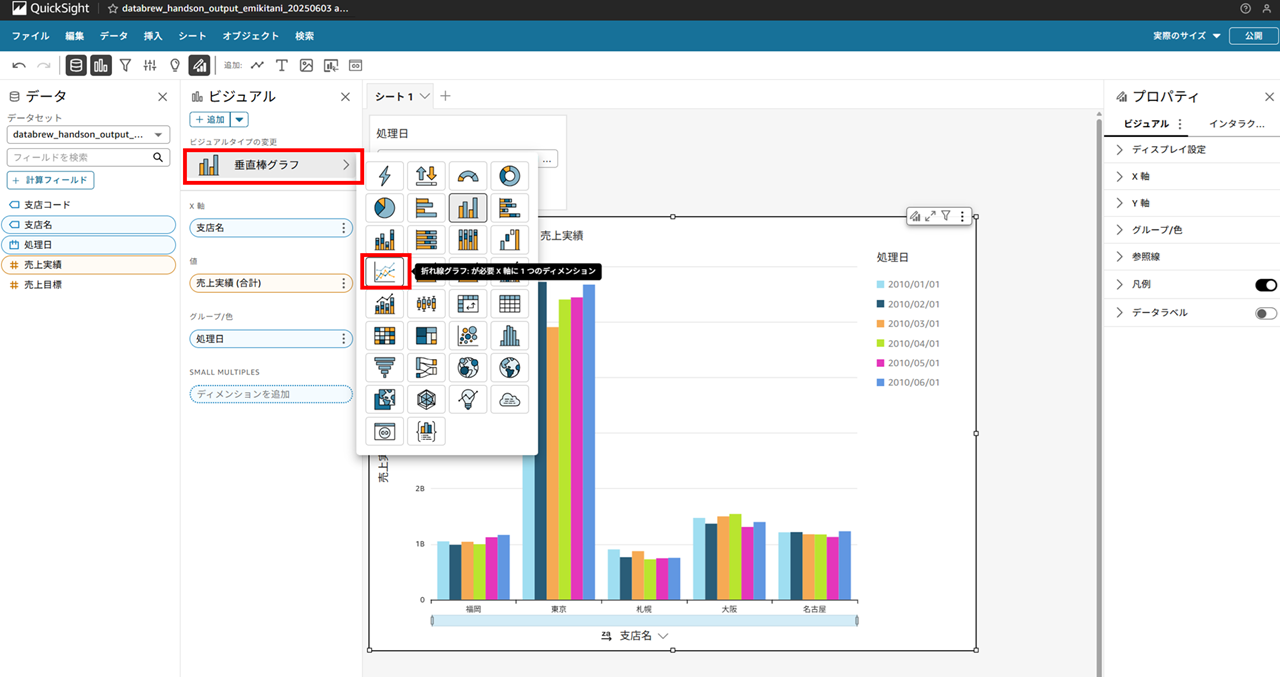
ビジュアルの変更もできます。
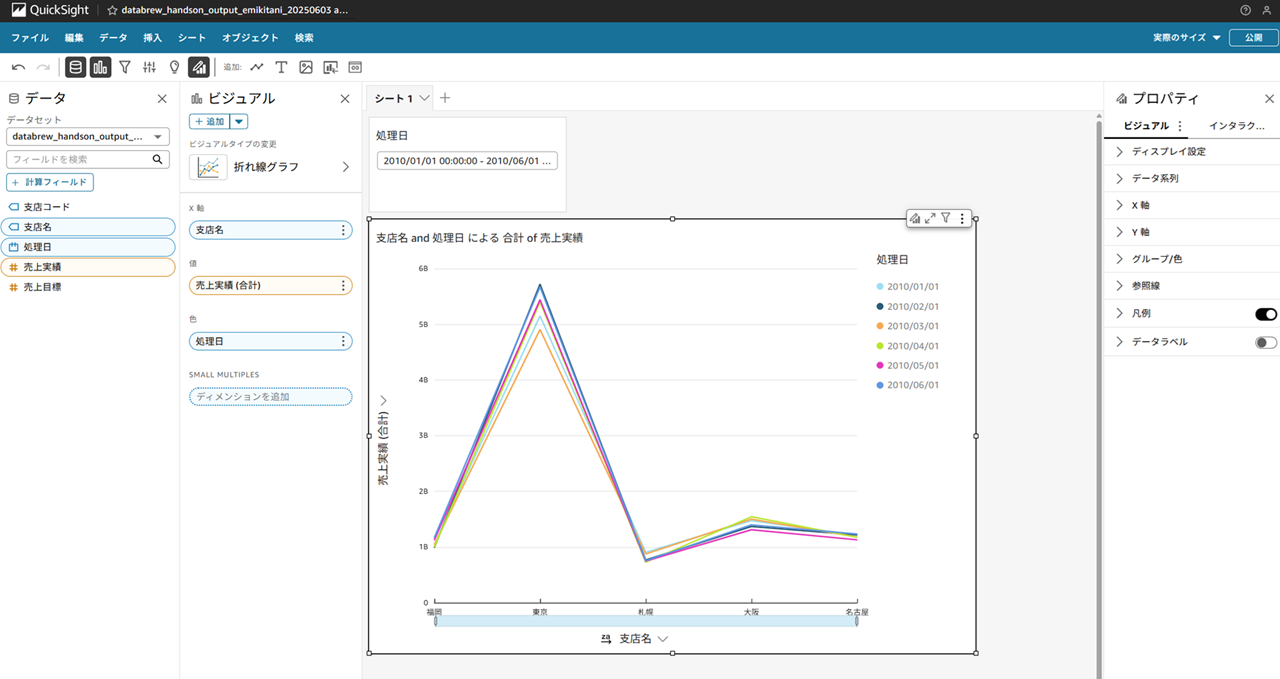
折れ線グラフにしてみました。
DataBrew 料金
DataBrew は以下の料金が発生します。詳細は料金ページを参照ください。
- Glue DataBrew インタラクティブセッション
- DataBrew ジョブ
おわりに
本記事への質問やご要望については画面下部のお問い合わせ「DevelopersIO について」からご連絡ください。記事に関してお問い合わせいただけます。










