
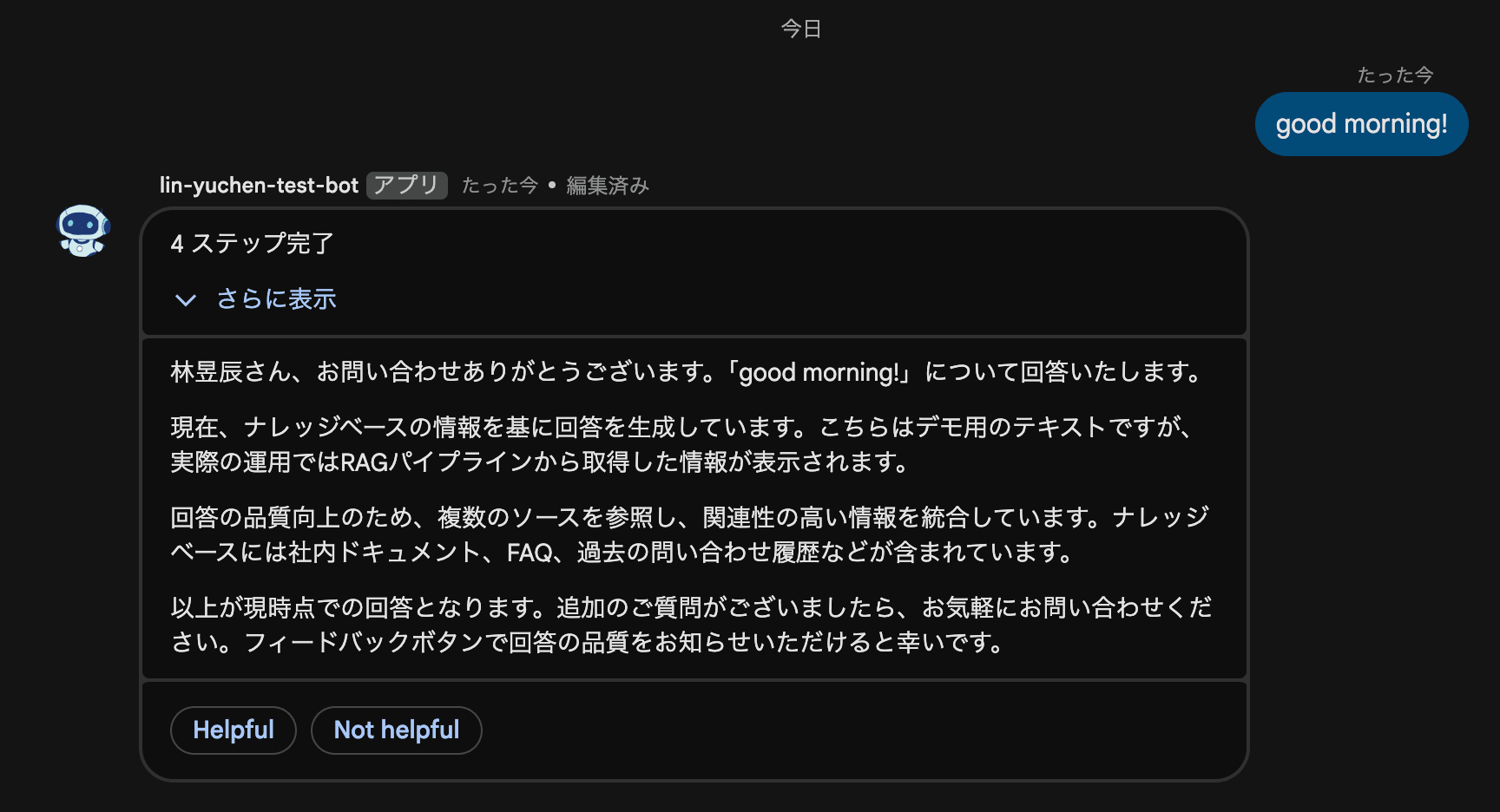
Google Chat Bot で cardsV2 のプログレッシブ UX を実装したら壁だらけだった話
はじめに
前回の記事では、Google Chat Bot を Cloud Functions + Python + uv で最小構成のエコーボットとして構築しました。
今回はそのボットを RAG(Retrieval-Augmented Generation)パイプライン化しようとしたところ、Google Chat の制約に次々とぶつかり、最終的に cardsV2 のプログレッシブ更新 UX にたどり着くまでの試行錯誤を紹介します。
構成
| 項目 | 選択 |
|---|---|
| ランタイム | Cloud Functions 第2世代 |
| 言語 | Python 3.14 |
| パッケージマネージャー | uv |
| リージョン | asia-northeast1(東京) |
| CPU | 1 vCPU(--no-cpu-throttling) |
| メモリ | 512Mi |
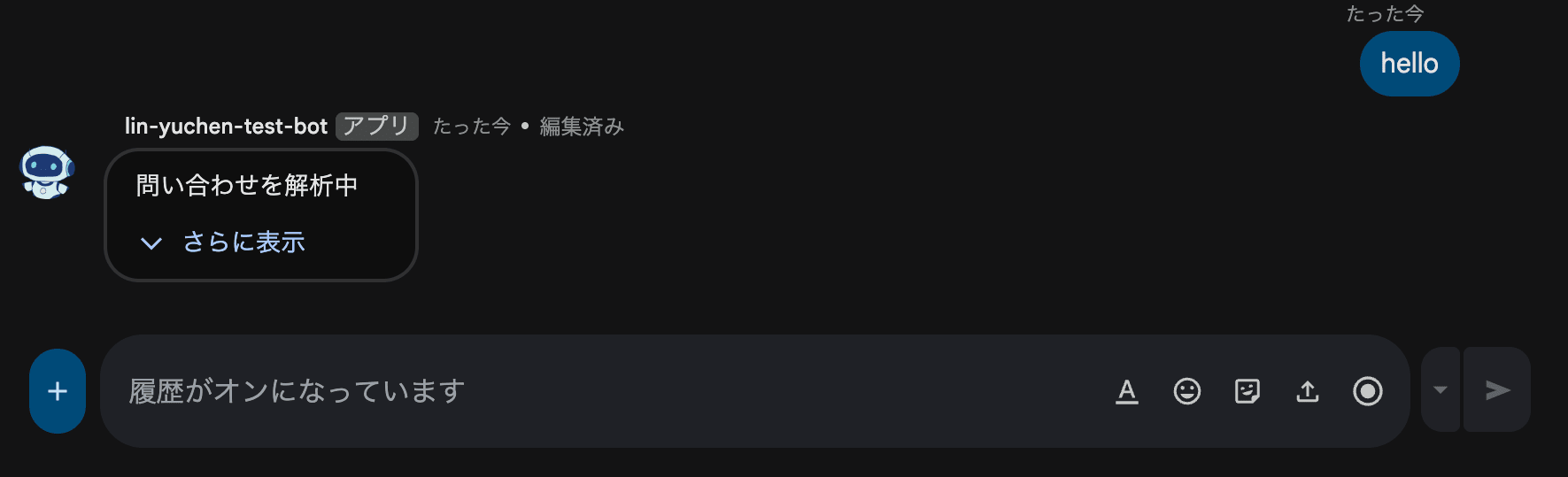
壁1: Google Chat のメッセージ API は同期的
RAG ボットを作ろうとして最初にぶつかった壁がこれでした。
普段 AI アプリケーションを開発するときは、ストリーミングレスポンスで「生成中...」のテキストがリアルタイムに流れる UX を当たり前のように実装します。Discord Bot なら、メッセージを送ったあとにリアクション(👀)をつけて「処理中」を示し、完了したらメッセージを編集する、といったことも簡単にできます。
しかし Google Chat の HTTP エンドポイント方式では:
- ストリーミングは非対応 — HTTP リクエストに対して1回のレスポンスを返すだけ
- 同期レスポンスでしかメッセージを作成できない — HTTP レスポンス = ボットの返答
- ボットからのリアクション追加は不可 — Chat API の
reactions.createはユーザー認証(OAuth)のみ対応で、ボット認証(chat.botスコープ)では呼べない。Discord のように「👀 をつけて処理中を示す」パターンは使えない
実際に chat.messages.reactions.create スコープを追加して試しましたが、ACCESS_TOKEN_SCOPE_INSUFFICIENT で 403 エラーになりました。ドキュメントを確認すると、リアクションは明確に「Requires user authentication」と記載されています。ボットがリアクションを追加するには、ユーザーの OAuth 認証情報か、Workspace 管理者によるドメイン全体の委任が必要になります。
つまり、RAG パイプラインのように数秒〜数十秒かかる処理では、ユーザーはその間ずっと何のフィードバックもなく待つことになります。
ユーザー: 「社内規定について教えて」
↓
(5〜10秒の沈黙)
↓
ボット: 「回答テキスト」
これでは UX として厳しい。何か方法がないか調べ始めました。
壁2: cardsV2 と Chat API の「パッチ」パターン
調べてみると、Google Chat には cardsV2 というリッチな UI コンポーネントがあり、Chat API を使えばメッセージの作成後にパッチ(更新) できることがわかりました。
つまり、こういうフローが実現できます:
1. HTTP レスポンスで {} を返す(即座にレスポンスを返してタイムアウトを回避)
2. バックグラウンドスレッドで Chat API を呼び、「処理中...」カードを作成
3. パイプラインが進むたびにカードをパッチして進捗を表示
4. 完了時に最終結果でカードをパッチ
Chat API をコードから呼ぶ
Chat API を Python から使うには google-api-python-client の build() を使います。
from googleapiclient.discovery import build
import google.auth
SCOPES = ["https://www.googleapis.com/auth/chat.bot"]
credentials, _ = google.auth.default(scopes=SCOPES)
service = build("chat", "v1", credentials=credentials)
これでメッセージの作成・更新ができるようになります。
# メッセージ作成
response = service.spaces().messages().create(
parent="spaces/SPACE_ID",
body={"cardsV2": [{"cardId": "my-card", "card": {...}}]}
).execute()
# メッセージ更新(パッチ)
service.spaces().messages().patch(
name=response["name"],
updateMask="cardsV2",
body={"cardsV2": [{"cardId": "my-card", "card": {...}}]}
).execute()
cardsV2 の collapsible セクション
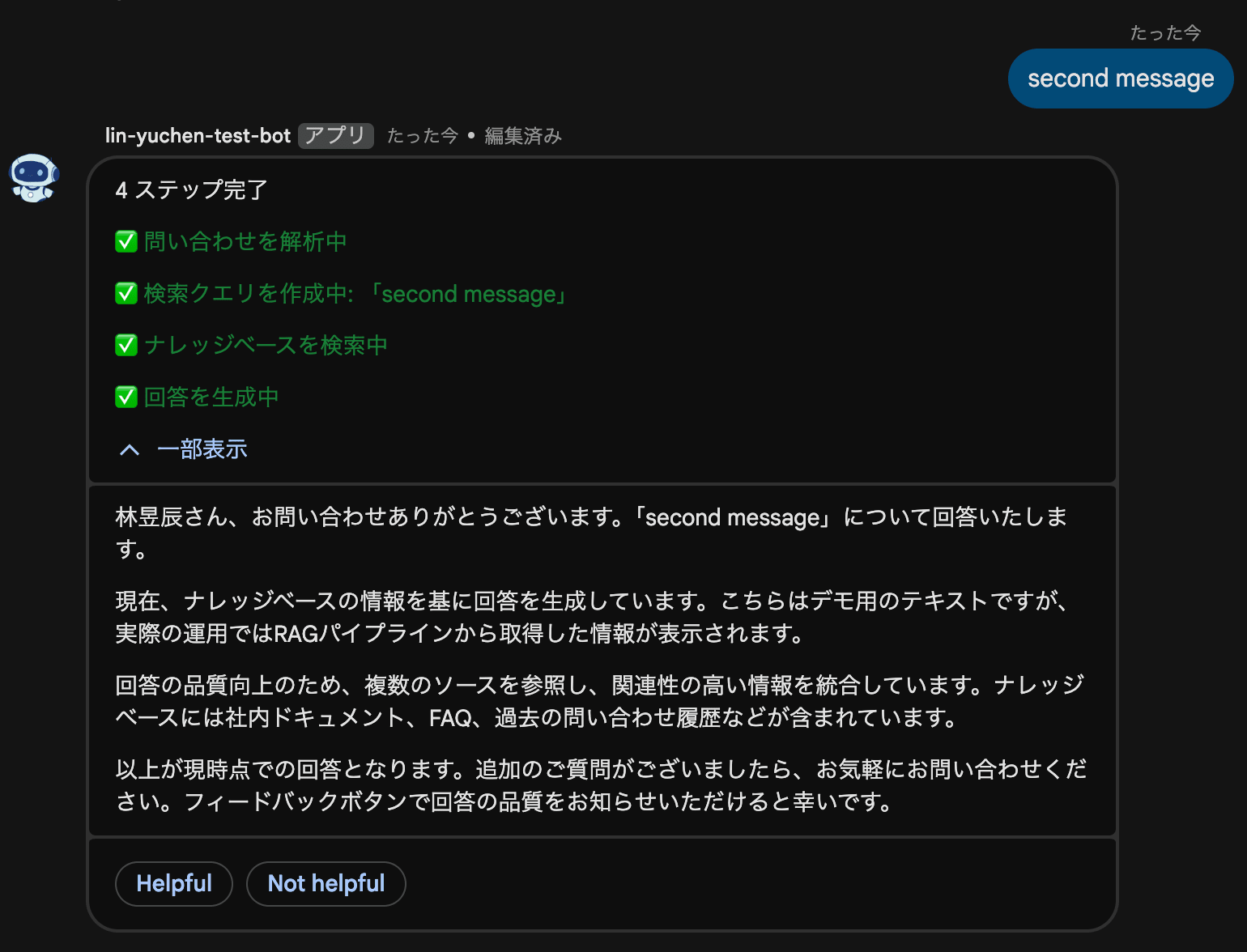
cardsV2 には collapsible というプロパティがあり、セクション内のウィジェットを折りたたみ可能にできます。これを使えば、パイプラインのステップ履歴をアコーディオンで表示しつつ、現在のステータスだけは常に表示する UI が作れます。
{
"collapsible": True,
"uncollapsibleWidgetsCount": 1, # 最初の1つは常に表示
"widgets": [
# ↓ 常に表示(ステータス)
{"decoratedText": {"text": "回答を生成中..."}},
# ↓ 折りたたみ内(ステップ履歴)
{"decoratedText": {"text": '<font color="#00C853">✅ 問い合わせを解析中</font>'}},
{"decoratedText": {"text": '<font color="#00C853">✅ 検索クエリを作成中</font>'}},
{"decoratedText": {"text": '<font color="#2979FF">⏳ 回答を生成中</font>'}},
]
}
レートリミット: 1 write/sec/space
ここで注意点があります。Google Chat API は 1スペースあたり1秒に1回の書き込み というレートリミットがあります。create と patch の両方がこのクォータを共有します。
つまり、LLM のトークンストリーミングのように1トークンごとにパッチを送ることはできません。ステップの遷移やパラグラフ単位など、適切な粒度でパッチする必要があります。
これに対応するため、ThrottledPatcher というクラスを作りました。
class ThrottledPatcher:
def __init__(self, chat_client, message_name, min_interval=1.0):
self._chat_client = chat_client
self._message_name = message_name
self._min_interval = min_interval
self._last_patch_time = 0.0
self._buffered_body = None
def patch(self, body, force=False):
now = time.monotonic()
elapsed = now - self._last_patch_time
if force or elapsed >= self._min_interval:
if force and elapsed < self._min_interval:
time.sleep(self._min_interval - elapsed)
self._chat_client.patch_message(
self._message_name, body, "cardsV2"
)
self._last_patch_time = time.monotonic()
self._buffered_body = None
else:
self._buffered_body = body # latest-wins バッファ
def flush(self):
if self._buffered_body is not None:
remaining = self._min_interval - (
time.monotonic() - self._last_patch_time
)
if remaining > 0:
time.sleep(remaining)
self._chat_client.patch_message(
self._message_name, self._buffered_body, "cardsV2"
)
self._buffered_body = None
ポイントは "latest-wins" バッファ戦略 です。レートリミット内で複数回パッチが発生した場合、最新の状態だけを保持し、次のパッチ可能なタイミングで送信します。中間状態をすべて送る必要はなく、ユーザーには常に最新の進捗が見えればよいからです。
壁3: Discovery Document のダウンロードでコールドスタートが遅い
cardsV2 + パッチパターンが動くようになり、喜んでデプロイしたところ、コールドスタート時に最初のカードが表示されるまで約2分かかる ことに気づきました。
前回の記事でプレーンテキストメッセージを返していたときは、コールドスタートでもほぼ即座にレスポンスが返っていました。何が違うのか?

原因は build("chat", "v1") でした。
google-api-python-client の build() は、API の定義情報(Discovery Document)を Google のサーバーからネットワーク経由でダウンロード します。このファイルは約 410KB あり、Cloud Functions の低スペック環境(デフォルト 0.17 vCPU)ではダウンロードに時間がかかります。
HTTP レスポンス返却(即座) → バックグラウンドスレッド開始
→ build("chat", "v1") で Discovery Document をダウンロード(~2分)
→ カード作成 API 呼び出し
→ ユーザーにカードが表示される
最初の試み: 同期メッセージ + 非同期カード
最初に試したのは、コールドスタート時はまず同期レスポンスでプレーンテキストを返し、Chat API の準備ができたら改めて cardsV2 メッセージを作成する というアプローチでした。
@functions_framework.http
def handle_chat(request):
body = request.get_json(silent=True)
# ...
if not is_warm():
# コールドスタート: 同期でテキストメッセージを返す
thread = threading.Thread(target=process_message, args=(...,))
thread.start()
return create_message("処理を開始しました。少々お待ちください...")
else:
# ウォーム: バックグラウンドでカードを作成
thread = threading.Thread(target=process_message, args=(...,))
thread.start()
return {}
ところが、これも動きませんでした。

壁4: Cloud Functions Gen 2 の CPU スロットリング
デプロイして試してみると、同期メッセージは即座に返るものの、バックグラウンドスレッドの処理が一切実行されない という状態でした。エラーも出ません。ただ沈黙。
Cloud Run のログを確認すると、リクエストは受信されているのに、そのあとの Chat API 呼び出しのログが一切ありませんでした。
原因を調べたところ、Cloud Functions 第2世代(Cloud Run ベース)の CPU スロットリング でした。
gcloud run services describe google-chat-bot --region=asia-northeast1 \
--format="yaml(spec.template.metadata.annotations)"
annotations:
run.googleapis.com/cpu-throttling: "true" # ← これが原因
Cloud Functions Gen 2 = Cloud Run
ここで重要な前提知識として、Cloud Functions 第2世代は Cloud Run そのもの です。AWS で例えると、Lambda のような独自ランタイムではなく、Fargate に近い位置づけです。gcloud functions deploy でデプロイすると、内部的には Cloud Run サービスとしてデプロイされます。
# Cloud Function のはずが、Cloud Run サービスとして見える
gcloud run services list --region=asia-northeast1
# NAME: google-chat-bot ← 同じ名前で Cloud Run サービスが存在する
そして Cloud Run にはデフォルトで CPU スロットリング が有効になっています。これは、HTTP リクエストを処理している間だけ CPU リソースを割り当て、レスポンスを返した後は CPU をほぼゼロまで削減する仕組みです。
なぜバックグラウンドスレッドに影響するのか
ボットのアーキテクチャを思い出してください:
1. HTTP リクエスト受信
2. バックグラウンドスレッドを起動
3. HTTP レスポンス {} を即座に返却 ← ここで CPU 割り当てが激減
4. バックグラウンドスレッドで Chat API を呼ぶ ← CPU がほぼない状態
CPU スロットリングはスレッドを「フリーズ」させるわけではありません。スレッドは生き続けますが、割り当てられる CPU が激減 します。デフォルトの 0.17 vCPU からさらにほぼゼロに近い状態になるため、ネットワーク I/O やレスポンスのパースなどの処理が極端に遅くなります。
実際、前回の記事で実装したシンプルなパターン(thinking カード作成 → 1回パッチ)では、API 呼び出しが2回だけだったため、この制約でもなんとか動いていました。しかしプログレッシブカードでは10回以上のパッチが数秒にわたって発生するため、CPU 不足で処理が極端に遅延し、事実上応答なしに見える状態でした。
| パターン | API 呼び出し回数 | CPU スロットリング下での動作 |
|---|---|---|
| thinking → patch(v0.1.0) | 2回 | 遅いがなんとか完了 |
| プログレッシブカード | 10回以上 | 極端に遅延、事実上応答なし |
解決: CPU の常時割り当て
--no-cpu-throttling を設定すると、HTTP レスポンス返却後も CPU が割り当てられ続けます。バックグラウンドスレッドが確実にフル CPU で動作するようになります。
ただし、--no-cpu-throttling を使うには 最低 1 vCPU が必要です。--cpu=1 は性能のために必要なのではなく、--no-cpu-throttling を有効化するための前提条件です。
# Step 1: CPU とメモリを増やしてデプロイ
gcloud functions deploy google-chat-bot \
--gen2 \
--runtime=python314 \
--region=asia-northeast1 \
--source=. \
--entry-point=handle_chat \
--trigger-http \
--no-allow-unauthenticated \
--memory=512Mi \
--cpu=1
# Step 2: CPU スロットリングを無効化
gcloud run services update google-chat-bot \
--region=asia-northeast1 \
--no-cpu-throttling
注意: --no-cpu-throttling は gcloud functions deploy コマンドではサポートされていないため、gcloud run services update で別途設定する必要があります。Cloud Functions Gen 2 が Cloud Run そのものだからこそ、gcloud run コマンドで直接設定できるわけです。
コスト面での判断
CPU を 0.17 vCPU → 1 vCPU に上げ、さらに常時割り当てにすることで、コストは増加します。ただし、min-instances=0(デフォルト)のままであれば、リクエストがない間はインスタンスがゼロになるため、実際のコストは非常に低く抑えられます。
| 設定 | min-instances | 月額コスト(東京リージョン) |
|---|---|---|
| 0.17 vCPU, 256Mi(デフォルト) | 0 | ほぼ無料 |
1 vCPU, 512Mi, --no-cpu-throttling |
0 | 約 $0.55 USD/月(リクエスト時のみ課金) |
1 vCPU, 512Mi, --no-cpu-throttling |
1 | 約 $50 USD/月(常時起動) |
今回は min-instances=0 を採用しています。1リクエストあたりの処理時間が約10秒として、1日100リクエスト程度の利用であれば月額 $0.55 USD 程度に収まります。コールドスタートのレイテンシ(数秒)は許容し、コストを最小限に抑える判断です。
本番で常時低レイテンシが必要な場合は min-instances=1 にすることで解決できますが、約 $50 USD/月のコストが発生します。
壁3の解決: Discovery Document のバンドル
CPU スロットリングを解決してバックグラウンドスレッドが動くようになっても、コールドスタート時の Discovery Document ダウンロードに2分かかる問題は残ります。
解決策は単純で、Discovery Document を静的ファイルとしてプロジェクトにバンドル しました。
# Discovery Document をダウンロード
curl -o chat_discovery.json \
'https://chat.googleapis.com/$discovery/rest?version=v1'
import json
from pathlib import Path
from googleapiclient.discovery import build_from_document
_DISCOVERY_DOC_PATH = Path(__file__).parent / "chat_discovery.json"
def _get_default_service():
credentials, _ = google.auth.default(scopes=SCOPES)
doc = json.loads(_DISCOVERY_DOC_PATH.read_text())
return build_from_document(doc, credentials=credentials)
build() の代わりに build_from_document() を使うことで、ネットワークアクセスを完全に排除できます。コールドスタートでもカードの初回表示が数秒以内に収まるようになりました。
このファイルは約 410KB です。なお、--cpu=1 に上げたことで build() のダウンロードも2分→数秒程度に短縮されますが、それでも build_from_document() の < 100ms には遠く及びません。CPU の増強とは別に、この最適化は引き続き有効です。
Discovery Document が古くなったら?
Discovery Document は API の URL パス、パラメータ名、リクエスト/レスポンスのスキーマを記述した「地図」のようなものです。Google の REST API は厳格な後方互換性を維持しているため、既存のメソッド(spaces.messages.create や spaces.messages.patch)のシグネチャが変わることはまずありません。
古い Discovery Document でも既存の機能はそのまま動き続けます。新しい API 機能が使えないだけです。数ヶ月〜1年程度であれば問題なく動作しますが、以下のタイミングで再ダウンロードすると安心です:
# 定期的に再ダウンロード
curl -o chat_discovery.json \
'https://chat.googleapis.com/$discovery/rest?version=v1'
google-api-python-clientをアップグレードしたとき- 新しい Chat API 機能を使いたくなったとき
- 数ヶ月に1回の定期メンテナンスとして
壁5: フィードバックボタンの罠(3重の罠)
プログレッシブカードが動くようになったので、ユーザーが回答の品質をフィードバックできるボタンを追加しました。ところが、このボタンを動かすまでに 3つの罠 を踏み抜くことになりました。
罠1: action.function はエンドポイントの完全 URL でなければならない
最初に書いたボタン定義はこうでした:
# ❌ 動かない — function に関数名を指定
{
"onClick": {
"action": {
"function": "feedback",
"parameters": [
{"key": "vote", "value": "up"},
]
}
}
}
ボタンをクリックすると 「〇〇 ではリクエストを処理できません」 というエラーが表示されました。エンドポイントにログも届きません。
原因は、HTTP エンドポイント方式の Workspace Add-ons では、action.function に ボットのエンドポイント URL そのもの を指定する必要があることでした。Google Chat はこの URL に対して CARD_CLICKED イベントを POST します。
# ✅ 正しい — function に完全な HTTPS URL を指定
{
"onClick": {
"action": {
"function": "https://asia-northeast1-PROJECT.cloudfunctions.net/google-chat-bot",
"parameters": [
{"key": "action", "value": "feedback"},
{"key": "vote", "value": "up"},
]
}
}
}
Apps Script 方式や Dialogflow 方式では function に関数名を指定しますが、HTTP エンドポイント方式では URL を指定するという違いがあります。ドキュメントでもこの区別は見つけにくいポイントです。
なお、invokedFunction にはこの URL がそのまま入ってくるため、ルーティングは parameters に action キーを追加して判別しています。
罠2: Cloud Functions の裏側で正しい URL を組み立てる
エンドポイント URL をハードコードするのは避けたいので、リクエストから動的に組み立てようとしました。
# ❌ request.base_url は内部 URL を返す
endpoint_url = request.base_url
# → "http://localhost:8080/" (Cloud Run の内部プロキシの URL)
Cloud Functions Gen 2 は Cloud Run の上で動いており、Flask が受け取るリクエストは内部プロキシから転送されたものです。request.base_url は外部 URL ではなく内部の localhost:8080 を返します。
X-Forwarded-Host と X-Forwarded-Proto ヘッダーを使えばホスト名は取れますが、もう一つ罠があります:
# ❌ request.path は "/" を返す
host = request.headers.get("X-Forwarded-Host") # "asia-northeast1-PROJECT.cloudfunctions.net"
scheme = request.headers.get("X-Forwarded-Proto") # "https"
path = request.path # "/" ← "/google-chat-bot" ではない!
Cloud Functions のランタイムは、リクエストを Flask に渡す前に 関数名のパスプレフィックスを除去 します。外部 URL が /google-chat-bot でも、Flask から見える request.path は / です。
解決策は K_SERVICE 環境変数を使うことです。Cloud Functions Gen 2(= Cloud Run)では、この環境変数にサービス名(= 関数名)が自動的に設定されます。
import os
host = request.headers.get("X-Forwarded-Host") or request.headers.get("Host", "")
scheme = request.headers.get("X-Forwarded-Proto", "https")
service = os.environ.get("K_SERVICE", "")
endpoint_url = f"{scheme}://{host}/{service}" if host else ""
# → "https://asia-northeast1-PROJECT.cloudfunctions.net/google-chat-bot"
罠3: レスポンス形式は actionResponse
URL が正しくなりイベントがエンドポイントに届くようになっても、レスポンス形式が間違っていると動きません。
// ❌ renderActions はダイアログ用
{"renderActions": {"action": {"navigations": [{"updateCard": {...}}]}}}
// ❌ updateMessageAction は同期レスポンスのメッセージ更新用
{"hostAppDataAction": {"chatDataAction": {"updateMessageAction": {"message": {...}}}}}
CARD_CLICKED イベントへの正しいレスポンス形式は actionResponse です:
// ✅ CARD_CLICKED に対する正しいレスポンス
{
"actionResponse": {"type": "UPDATE_MESSAGE"},
"cardsV2": [{
"cardId": "progressive-card",
"card": {
"sections": [{
"widgets": [{
"textParagraph": {"text": "フィードバックありがとうございます!"}
}]
}]
}
}]
}
整理すると:
| 操作 | レスポンス形式 |
|---|---|
| 同期メッセージ作成 | hostAppDataAction.chatDataAction.createMessageAction |
| CARD_CLICKED でメッセージ更新 | actionResponse: {type: "UPDATE_MESSAGE"} + cardsV2 |
| ダイアログ表示 | renderActions.action.navigations[].pushCard |
壁6: スレッド返信が新規スレッドになる
プログレッシブカードが完成し、フィードバックボタンも動くようになったところで、次の問題が発覚しました。ユーザーがボットの回答に対してスレッド内で返信すると、ボットの応答が同じスレッドではなく新規のトップレベルメッセージとして作成される のです。
ユーザー: 「社内規定について教えて」
ボット: [プログレッシブカードで回答] ← スレッド①
ユーザー: 「もう少し詳しく教えて」 ← スレッド①内で返信
ボット: [新しいカードで回答] ← スレッド②(新規!)← ここが問題
これでは会話の流れが崩れてしまいます。
原因: messageReplyOption のデフォルト値
Google Chat API の spaces.messages.create には messageReplyOption というパラメータがあります。このパラメータを指定しない場合、デフォルトの MESSAGE_REPLY_OPTION_UNSPECIFIED が適用され、常に新規スレッドとしてメッセージが作成 されます。
つまり、受信メッセージに含まれるスレッド情報を取得して、返信時に渡す必要がありました。
解決: thread.name の引き継ぎ
受信イベントのメッセージオブジェクトには thread.name(スレッドのリソース名)が含まれています。これを抽出して spaces.messages.create に渡すだけで解決しました。
# 受信イベントからスレッド情報を抽出
thread_name = message.get("thread", {}).get("name")
# メッセージ作成時にスレッド情報を付与
kwargs = {"parent": space_name, "body": body}
if thread_name:
kwargs["body"] = {**body, "thread": {"name": thread_name}}
kwargs["messageReplyOption"] = "REPLY_MESSAGE_FALLBACK_TO_NEW_THREAD"
service.spaces().messages().create(**kwargs).execute()
REPLY_MESSAGE_FALLBACK_TO_NEW_THREAD は、指定されたスレッドが存在すればそのスレッド内に返信し、存在しなければ新規スレッドを作成するという安全なフォールバック動作をします。DM でも新規メッセージでもスレッド返信でも、この1つのオプションで正しく動作します。
最終的なアーキテクチャ
すべての壁を乗り越えた最終的な構成です。
main.py → HTTP ハンドラ({} を返却、スレッド起動、CARD_CLICKED ルーティング)
worker.py → パイプラインオーケストレーション(ステップ追跡付き)
cards.py → cardsV2 ビルダー(プログレッシブカード)
models.py → パイプラインデータモデル(StepStatus, PipelineState)
throttle.py → レートリミット対応パッチャー(1 write/sec/space)
feedback.py → CARD_CLICKED イベントハンドラ
chat_api.py → Chat API ラッパー(静的 Discovery Document)
chat_discovery.json → バンドル済み Chat API v1 Discovery Document
パイプラインのフロー
1. HTTP リクエスト受信 → {} を即座に返却
2. バックグラウンドスレッドでパイプライン開始
3. 初期カード作成(4ステップ表示、すべて PENDING)
4. 各ステップの進行に合わせてカードをパッチ
- 問い合わせを解析中 → ✅
- 検索クエリを作成中 → ✅
- ナレッジベースを検索中 → ✅
- 回答を生成中 → ✅
5. レスポンス段落を追加しながらパッチ
6. 完了時にフィードバックボタンを表示
デプロイ
# Step 1: 関数デプロイ
gcloud functions deploy google-chat-bot \
--gen2 \
--runtime=python314 \
--region=asia-northeast1 \
--source=. \
--entry-point=handle_chat \
--trigger-http \
--no-allow-unauthenticated \
--memory=512Mi \
--cpu=1
# Step 2: CPU スロットリング無効化(バックグラウンドスレッドに必須)
gcloud run services update google-chat-bot \
--region=asia-northeast1 \
--no-cpu-throttling
まとめ
Google Chat Bot で RAG パイプラインのプログレッシブ UX を実装するまでに、6つの壁にぶつかりました。
| 壁 | 原因 | 解決策 |
|---|---|---|
| メッセージ API が同期的 | ストリーミング非対応 | cardsV2 + Chat API パッチ |
| コールドスタートが遅い | build() が Discovery Document をダウンロード |
build_from_document() で静的ファイルを使用 |
| バックグラウンドスレッドが動かない | Cloud Functions Gen 2 の CPU スロットリング | --cpu=1 + --no-cpu-throttling |
| レートリミット | 1 write/sec/space | ThrottledPatcher(latest-wins バッファ) |
| フィードバックボタンのエラー(3重の罠) | action.function に関数名を指定 / URL 組み立てミス / レスポンス形式違い |
完全 URL + K_SERVICE + actionResponse |
| スレッド返信が新規スレッドになる | messageReplyOption 未指定で常に新規スレッド |
thread.name 引き継ぎ + REPLY_MESSAGE_FALLBACK_TO_NEW_THREAD |
正直なところ、Discord Bot や Slack Bot と比較すると、Google Chat Bot の開発体験はまだ荒削りです。ドキュメントが Workspace Add-ons 形式に追いついていない箇所が多く、レスポンス形式の使い分け(createMessageAction / actionResponse / renderActions)や action.function に完全 URL が必要なことなど、試行錯誤でしか分からない部分が多数ありました。
一方で、cardsV2 のプログレッシブ更新は、動くとかなり良い UX になります。ユーザーにパイプラインの進捗がリアルタイムで見え、フィードバックも収集できる。Google Workspace を使っている組織には、この投資は十分に見合うものだと思います。
次のステップ: Cloud Tasks への移行
現在のアーキテクチャはバックグラウンドスレッド + --no-cpu-throttling で動作していますが、本格的な RAG パイプラインにスケールする際は Cloud Tasks への移行を検討しています。
現在: HTTP リクエスト → {} 返却 → 同じインスタンスでバックグラウンドスレッド実行
将来: HTTP リクエスト → Cloud Tasks にエンキュー → 別リクエストとしてワーカーが処理
Cloud Tasks に移行すると、以下のメリットがあります:
| 観点 | 現在(バックグラウンドスレッド) | Cloud Tasks |
|---|---|---|
| CPU 設定 | --cpu=1 + --no-cpu-throttling が必須 |
デフォルト設定のまま動作 |
| 同時実行 | 1インスタンス内でスレッドが CPU を奪い合う | タスクごとに別インスタンスで実行 |
| 失敗時 | サイレントに失敗、リトライなし | 自動リトライ + Dead Letter Queue |
| タイムアウト | HTTP タイムアウトに制約される | タスク単位で最大30分 |
特に RAG パイプラインでは LLM 呼び出しやベクトル検索など重い処理が入るため、同時リクエスト時のリソース競合が問題になります。Cloud Tasks なら Cloud Run のオートスケーリングに自然に乗れるため、スケーラビリティの心配がなくなります。
なお、Discovery Document (chat_discovery.json) はコンテナイメージにバンドルされた静的ファイルなので、同じデプロイから起動するワーカーインスタンスでもそのまま利用でき、追加の設定は不要です。









