
Google Chat Bot に Vertex AI RAG Engine を繋いでナレッジベース検索を実装した話
はじめに
第1回で Google Chat Bot を Cloud Functions + Python + uv で構築し、第2回で cardsV2 のプログレッシブ更新 UX を実装しました。
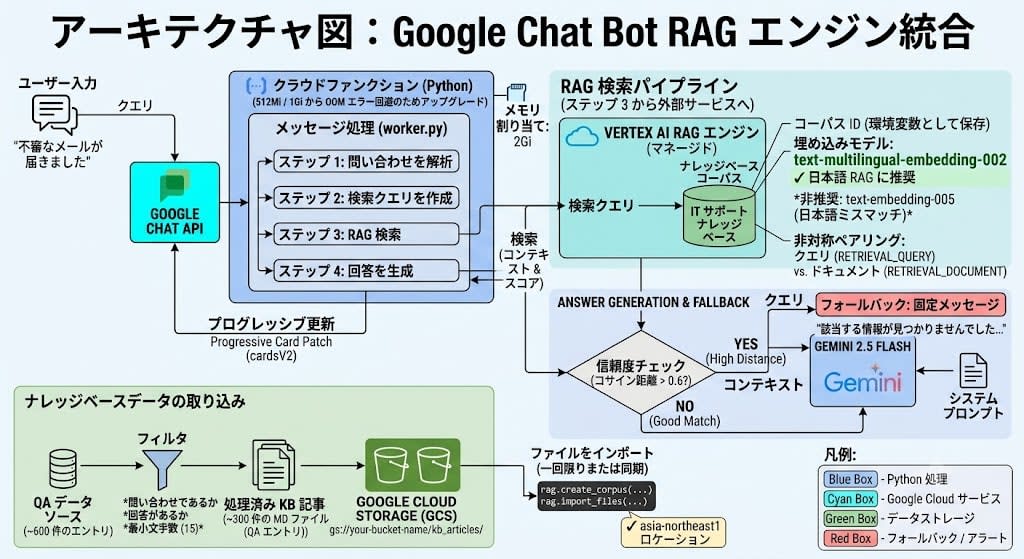
今回はいよいよ本題 — ボットにナレッジベース検索(RAG) を組み込みます。社内ナレッジデータ約 300 件を整理し、Vertex AI RAG Engine に投入して、ユーザーの質問に自動回答できるようにするまでの全工程を紹介します。
結論から言うと、RAG Engine 自体のセットアップは簡単でしたが、埋め込みモデルの選定で日本語特有のハマりポイントがあり、原因特定のプロセスが一番学びになりました。
構成
| 項目 | 選択 |
|---|---|
| RAG バックエンド | Vertex AI RAG Engine(マネージド) |
| 埋め込みモデル | text-multilingual-embedding-002 |
| 生成モデル | Gemini 2.5 Flash |
| ナレッジベース | 約 300 件の QA エントリ(Markdown) |
| ストレージ | Google Cloud Storage |
| フォールバック | 固定メッセージ(担当部署への案内) |
データの整理: QA データ → KB エントリ
元データの品質評価
今回のケースでは、社内に蓄積された約 600 件の QA データ(質問と回答のペア)を元データとしました。元データは担当者の作業メモ形式であり、ユーザー向けの手順書ではありません。
品質フィルタリング
まず明らかにナレッジとして不適切なものを除外しました。
| フィルタ | 条件 | 例 |
|---|---|---|
| 質問以外 | 種別が問い合わせでないもの | 作業依頼、物品受け渡し |
| 回答なし | 回答欄が空 | — |
| 情報不足 | 回答が短すぎる | 15 文字未満 |
結果、約半数の「質問 + 意味のある回答」ペアが残りました。
個別エントリとして保持する方針
QA ペアを個別の KB エントリとして保持する方針を採りました。当初はソリューションパターンでグルーピングし統合記事を作成するアプローチを検討しましたが、以下の理由で個別保持に切り替えました。
- バリエーションの保存 — 同じ症状でも状況ごとに解決策が異なる。統合すると個別コンテキストが失われる
- パイプラインの簡素化 — ルールベースのマッチングや手動の記事作成が不要になり、新しいデータの追加が容易
- Gemini による合成 — 同じパターンの複数エントリが検索でヒットした場合、Gemini がシステムプロンプトの指示に従って共通する対応方法をまとめて回答する
元データがメモ形式の場合の対処
元データが担当者の作業メモ(「〇〇の設定を変更して解決」等)の場合、そのままユーザーに見せるのではなく、システムプロンプトで Gemini に変換を指示できます。
## ナレッジベースの形式について
- ナレッジベースには対応記録(スタッフのメモ)が含まれています
- 「〇〇して解決」等の記録形式の場合、ユーザーに対して分かりやすい手順として言い換えてください
- 複数の類似した記録が検索結果に含まれる場合、共通する対応方法をまとめて回答してください
回答品質は元データの品質に直接依存します。より良い回答を得るには、元データ自体の記述を改善するのが最も効果的です。
KB エントリのフォーマット
各エントリは Markdown ファイルとして保存しています。
# Excelのマクロが実行できない。
**カテゴリ**: office
## 対応
トラストセンターの設定を変更してください。
質問をタイトル(= ベクトル検索でのマッチ対象)、回答を対応セクションに配置しています。質問を残す理由は、回答だけでは検索クエリとの語彙的な一致が弱くなるためです(例: 回答に「マクロ」という単語が含まれない場合がある)。
最終的に約 600 件 → 約 300 件の KB エントリに整理しました。
Vertex AI RAG Engine のセットアップ
なぜ RAG Engine を選んだか
300 件超のエントリがあるため、全文をプロンプトに詰め込む「コンテキストスタッフィング」は現実的ではありません。以下の理由で Vertex AI RAG Engine(マネージド RAG) を採用しました。
- KB が成長しても構成変更なしでスケールする
- チャンキング・埋め込み・検索がマネージドで管理不要
- Vertex AI エコシステム内で完結し、追加の外部サービス不要
コーパス(Corpus)とは
RAG Engine におけるコーパスは、検索対象となるドキュメントのコンテナです。アップロードしたファイルはコーパス内でチャンク分割・ベクトル化され、検索可能な状態で保持されます。OpenSearch でいうインデックスに相当するもので、用途別に複数のコーパスを作成できます(例: IT サポート用、人事用、技術ドキュメント用)。
OpenSearch では自分でエンベディングパイプラインや k-NN 設定を構築する必要がありますが、RAG Engine ではファイルを指定してエンベディングモデルを選ぶだけで、チャンキング・ベクトル化・検索インデックスの構築がすべてマネージドで処理されます。
GCS バケットの作成とアップロード
まず KB 記事を GCS にアップロードします。
# GCS バケット作成
gcloud storage buckets create gs://YOUR_BUCKET_NAME \
--location=asia-northeast1
# KB 記事をアップロードするスクリプト
uv run python scripts/upload_kb.py \
--project YOUR_PROJECT_ID \
--bucket YOUR_BUCKET_NAME
upload_kb.py は KB 記事の .md ファイルを GCS にアップロードし、RAG コーパスを作成してファイルをインポートするスクリプトです。
from google.cloud import aiplatform, storage
from vertexai import rag
LOCATION = "asia-northeast1"
def main():
# SDK の初期化は最初に1回だけ
aiplatform.init(project=project_id, location=LOCATION)
# 1. GCS にアップロード
client = storage.Client(project=project_id)
bucket = client.bucket(bucket_name)
for md_file in KB_DIR.glob("*.md"):
blob = bucket.blob(f"kb_articles/{md_file.name}")
blob.upload_from_filename(str(md_file))
# 2. コーパス作成(初回のみ)
corpus = rag.create_corpus(
display_name="my-it-support-kb",
description="IT Support Knowledge Base",
)
# 3. ファイルインポート
rag.import_files(corpus_name=corpus.name,
paths=[f"gs://{bucket_name}/kb_articles/"])
aiplatform.init()でlocationを省略すると、デフォルトでus-central1が使われます。コーパスがasia-northeast1にある場合、rag.import_files()呼び出し時に以下のエラーになります:FAILED_PRECONDITION: Request resource location asia-northeast1 does not match service location us-central1.
rag.list_corpora() や rag.create_corpus() は正常に動作するのに import_files() だけ失敗するため、原因の特定に時間がかかりました。aiplatform.init(location=...) は rag.* を呼ぶ前に必ず実行してください。
検索の実装
RAG Engine からの検索は rag.retrieval_query() で行います。
from vertexai import rag
def retrieve_context(query: str) -> list[dict]:
response = rag.retrieval_query(
text=query,
rag_resources=[rag.RagResource(rag_corpus=corpus_name)],
rag_retrieval_config=rag.RagRetrievalConfig(
top_k=5,
filter=rag.Filter(vector_distance_threshold=0.6),
),
)
results = []
for context in response.contexts.contexts:
results.append({
"text": context.text,
"score": context.score,
"source": context.source_uri,
})
return results
vector_distance_threshold はコサイン距離で、値が小さいほど関連性が高いです。0.6 を閾値として、それ以上は「信頼度が低い」と判断します。
混同しやすいので整理します。コサイン類似度は -1〜1 の範囲で、1 に近いほど意味が近いことを示します。コサイン距離はその逆で
1 - 類似度で計算され、0〜2 の範囲で 0 に近いほど意味が近いです。RAG Engine が返すスコアはコサイン距離なので、値が小さい = 良い一致です。
指標 範囲 良い方向 コサイン類似度 -1 〜 1 高い(1 = 同一) コサイン距離 0 〜 2 低い(0 = 同一)
回答生成とフォールバック戦略
検索結果の信頼度に応じて、2 つの戦略を使い分けます。
def query(question: str) -> str:
# 1. KB から検索
contexts = retrieve_context(question)
# 2. 信頼度チェック
if not contexts or all(c["score"] > 0.6 for c in contexts):
# 低信頼度 → KB に情報なしと正直に返す
return "該当する情報が見つかりませんでした。担当部署にお問い合わせください。"
# 3. KB の情報で回答生成
return generate_answer(question, contexts)
| 検索スコア | 戦略 | 理由 |
|---|---|---|
| < 0.6(良い一致) | KB の情報で Gemini が回答 | 自社固有の正確な手順を提供 |
| ≥ 0.6(低信頼度) | 固定メッセージ | KB にない情報で推測しない。担当部署へ案内 |
ここで重要な設計判断があります。 低信頼度の場合に Google Search grounding(Gemini が Google 検索結果を元に回答する機能)にフォールバックするアーキテクチャも技術的には可能です。しかし今回はナレッジベースにない情報では回答しない方針を採りました。社内向けボットでは、不正確な一般情報よりも「わからないので担当者に聞いてください」のほうが安全です。
壁: 日本語の検索品質が壊滅的だった
セットアップは順調でしたが、いざテストすると一部のクエリで検索結果がまったく的外れでした。
症状
=== 「VBAマクロが実行できない」 ===
0.26 | office_macro_blocked.md ✅ 正しい
=== 「社内システムにログインできません」 ===
0.18 | system_user_lock.md ✅ 正しい
=== 「不審なメールが届きました」 ===
0.44 | smartphone_google_photos.md ❌ 完全に間違い
VBA、Google Drive などの英語・カタカナの技術用語を含むクエリは正確に検索できるのに、「不審なメール」のような純粋な日本語のクエリは完全に失敗していました。
しかも記事のタイトルは「不審なメールが届いた場合の対応」— クエリとほぼ同一のテキストです。
原因の切り分け: チャンキングか、埋め込みか?
原因は 2 つ考えられました。
- チャンキングの問題 — RAG Engine がファイルを不適切に分割し、タイトルと本文が分離している
- 埋め込みモデルの問題 — デフォルトの
text-embedding-005が日本語の意味的類似性を正しく捉えられていない
チャンキングの検証
特定のファイルだけを対象に検索を実行し、RAG Engine が作成したチャンクを確認しました。
response = rag.retrieval_query(
text="不審なメールが届きました",
rag_resources=[rag.RagResource(
rag_corpus=corpus,
rag_file_ids=["<suspicious_email_file_id>"],
)],
rag_retrieval_config=rag.RagRetrievalConfig(
top_k=5,
filter=rag.Filter(vector_distance_threshold=1.0),
),
)
結果、チャンクには記事全文が含まれていました。ファイルが小さい(約 30 行)ため、1 ファイル = 1 チャンクで分割されておらず、チャンキングは問題なし。
埋め込みモデルの検証
次に、同じテキストを手動で埋め込んでコサイン距離を計算しました。
from vertexai.language_models import TextEmbeddingModel, TextEmbeddingInput
model = TextEmbeddingModel.from_pretrained("text-embedding-005")
query = "不審なメールが届きました"
article = "不審なメールが届いた場合の対応..."
unrelated = "スマートフォンのGoogleフォト同期設定..."
# タスクタイプなし(デフォルト)で埋め込み
embeddings = model.get_embeddings([query, article, unrelated])
# → query vs article: 0.27 (良い!)
# → query vs unrelated: 0.46
デフォルトのタスクタイプでは 0.27 で正しく識別できている。 では RAG Engine で 0.46 になるのはなぜか?
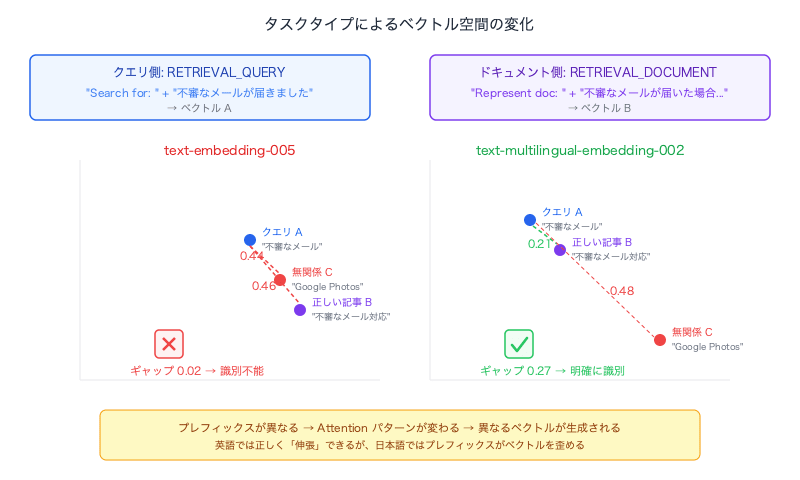
真の原因: タスクタイプの非対称ペアリング
text-embedding-005 にはタスクタイプという概念があり、同じテキストでもタスクタイプによって異なるベクトルが生成されます。
タスクタイプの仕組み
タスクタイプはモデルの構造やウェイトを切り替えるものではありません。内部的には、タスクタイプに応じたプレフィックス(指示文)がテキストの前に付加されるだけです。概念的にはこうなります:
RETRIEVAL_QUERY + "不審なメール" → ベクトル A
RETRIEVAL_DOCUMENT + "不審なメール" → ベクトル B
(プレフィックスなし)+ "不審なメール" → ベクトル C
同じモデル、同じウェイト、同じ Transformer ですが、プレフィックスが異なるため注意機構(Attention)のパターンが変わり、最終的に異なるベクトルが生成されます。LLM に「要約して」と「翻訳して」で異なる出力が得られるのと同じ原理です。
この非対称ペアリング(クエリとドキュメントに異なるタスクタイプを使う)は、短い検索クエリと長いドキュメントの性質の違いを吸収するために設計されています。クエリ側のプレフィックスは「意図を拡張してドキュメント領域に近づく」よう学習され、ドキュメント側は「関連するクエリが到達しやすい位置に配置される」よう学習されます。
ただし、この学習は訓練データに依存します。text-embedding-005 は英語のクエリ・ドキュメントペアで主に訓練されているため、英語では正しく「伸張」できますが、日本語ではプレフィックスの影響がベクトルを助けるどころか歪めてしまうのが今回の問題の本質です。
タスクタイプの適用タイミング
重要なのは、タスクタイプはインジェスト時とクエリ時の両方で適用されることです。
- インジェスト時(ファイルをコーパスにインポートする際): 各チャンクが
RETRIEVAL_DOCUMENTで埋め込まれ、インデックスに保存される - クエリ時(
retrieval_query()を呼ぶ際): 検索クエリがRETRIEVAL_QUERYで埋め込まれ、保存済みのドキュメントベクトルと比較される
つまり非対称性はインデックスに焼き込まれています。ドキュメント側のタスクタイプを変更するには、コーパスを再作成してファイルを再インポートする必要があります。
RAG Engine は内部的に以下のペアリングを使用します。
- クエリ:
RETRIEVAL_QUERY - ドキュメント:
RETRIEVAL_DOCUMENT
この組み合わせで手動テストしたところ:
q_input = TextEmbeddingInput(text=query, task_type="RETRIEVAL_QUERY")
d_input = TextEmbeddingInput(text=article, task_type="RETRIEVAL_DOCUMENT")
# → コサイン距離: 0.4605 ← RAG Engine の結果と完全一致!
| クエリ側タスクタイプ | ドキュメント側タスクタイプ | コサイン距離 |
|---|---|---|
| RETRIEVAL_QUERY | RETRIEVAL_DOCUMENT | 0.46(識別不能) |
| RETRIEVAL_DOCUMENT | RETRIEVAL_DOCUMENT | 0.26(良い) |
| SEMANTIC_SIMILARITY | SEMANTIC_SIMILARITY | 0.30(良い) |
text-embedding-005 の RETRIEVAL_QUERY / RETRIEVAL_DOCUMENT ペアは、純粋な日本語テキストの意味的類似性を正しく捉えられていないことが判明しました。英語やカタカナの技術用語が含まれるクエリは問題なく動作するため、気づきにくい問題です。
Vertex AI の埋め込みモデル比較
解決策に入る前に、Vertex AI が提供する埋め込みモデルを整理します。
| モデル | 次元数 | 言語 | 特徴 |
|---|---|---|---|
text-embedding-005 |
768 | 英語最適化 | 最新の英語モデル。タスクタイプ対応。日本語の RETRIEVAL ペアに弱点あり |
text-multilingual-embedding-002 |
768 | 100+ 言語(CJK に強い) | 多言語特化。タスクタイプ対応。日本語 RAG にはこちらを推奨 |
text-embedding-004 |
768 | 英語中心 | 005 の前世代 |
textembedding-gecko@003 |
768 | 英語 | 旧世代。新規プロジェクトでは選ぶ理由なし |
textembedding-gecko-multilingual@001 |
768 | 多言語 | 旧世代の多言語モデル |
005 と multilingual-002 は出力次元数の削減にも対応しており、コスト・速度のトレードオフが可能です。新規プロジェクトでは基本的にこの 2 つから選ぶことになります。
解決: text-multilingual-embedding-002 への移行
text-multilingual-embedding-002 で同じテストを実行しました。
model = TextEmbeddingModel.from_pretrained("text-multilingual-embedding-002")
q_input = TextEmbeddingInput(text=query, task_type="RETRIEVAL_QUERY")
d_input = TextEmbeddingInput(text=article, task_type="RETRIEVAL_DOCUMENT")
# → コサイン距離: 0.2090 ← 大幅改善!
| モデル | クエリ→正しい記事 | クエリ→無関係な記事 | 識別ギャップ |
|---|---|---|---|
| text-embedding-005 | 0.46 | 0.44 | 0.02(識別不能) |
| text-multilingual-embedding-002 | 0.21 | 0.48 | 0.27(明確に識別) |
RAG Engine のコーパスを text-multilingual-embedding-002 で再作成しました。
corpus = rag.create_corpus(
display_name="my-it-support-kb-v2",
backend_config=rag.RagVectorDbConfig(
rag_embedding_model_config=rag.RagEmbeddingModelConfig(
vertex_prediction_endpoint=rag.VertexPredictionEndpoint(
publisher_model="publishers/google/models/text-multilingual-embedding-002",
),
),
),
)
再作成後の検索結果:
=== 「不審なメールが届きました」 ===
0.21 | suspicious_email.md ✅
=== 「VBAマクロが実行できない」 ===
0.19 | office_macro_blocked.md ✅
=== 「パソコンの動作が重い」 ===
0.18 | pc_slow_troubleshooting.md ✅
=== 「Salesforceにログインできない」 ===
0.18 | salesforce_login.md ✅
すべてのクエリで正しい記事が top-1 に来るようになりました。
worker.py への RAG パイプライン統合
前回の記事で構築したプログレッシブカードの 4 ステップに、実際の RAG 処理を組み込みました。
def process_message(space_name, user_text, sender, ...):
# Step 1: 問い合わせを解析中
_advance_step(state, "analyze", patcher, message_name)
# Step 2: 検索クエリを作成中
_advance_step(state, "build_query", patcher, message_name)
# Step 3: ナレッジベースを検索中
contexts = retrieve_context(user_text)
# Step 4: 回答を生成中
if not contexts or all(c["score"] > 0.6 for c in contexts):
answer = NO_RESULT_MESSAGE
else:
answer = generate_answer(user_text, contexts)
# 回答を段落ごとにカードに追加
for para in answer.split("\n\n"):
state.content_paragraphs.append(para.strip())
patcher.patch(build_progressive_card(state))
デプロイ時の注意: メモリ不足
512Mi → 1Gi(初回デプロイ)
初回デプロイ後、カードが「問い合わせを解析中」で止まる問題が発生しました。
ログを確認すると:
Memory limit of 512 MiB exceeded with 529 MiB used.
google-cloud-aiplatform SDK が重く、512Mi では OOM で Kill されていました。1Gi に増やして一旦解決しました。
1Gi → 2Gi(本番運用後)
しかし 1Gi でも十分ではありませんでした。運用開始後、クエリを連続送信すると回答が返ってこない事象が発生しました。
症状と難しさ
症状は「クエリを連投すると回答が返ってこないことがある」という曖昧なもの。毎回ではなく「ことがある」という点が厄介です。アプリケーション側のエラーハンドリングは正常に動作しており、コード上のバグではなさそうでした。
デバッグの手順
まず Cloud Logging でエラーレベルのログを確認しました。
gcloud logging read \
'resource.type="cloud_run_revision"
AND resource.labels.service_name="YOUR_SERVICE_NAME"
AND severity>=ERROR' \
--limit=50 \
--format='table(timestamp,severity,textPayload)'
すると 2 種類のエラーが見つかりました。
1. OOM(メモリ上限超過)
Memory limit of 1024 MiB exceeded with 1033 MiB used.
Memory limit of 1024 MiB exceeded with 1029 MiB used.
これがインスタンス強制終了の直接原因です。
2. Chat API への接続エラー
ssl.SSLError: [SSL: WRONG_VERSION_NUMBER] wrong version number
http.client.IncompleteRead: IncompleteRead(290 bytes read, 400 more expected)
Failed to create initial card
OOM でインスタンスが Kill された後、新しいインスタンスが起動しますが、前のインスタンスの HTTP コネクションプールが破損した状態で引き継がれることがあり、SSL エラーや不完全な読み取りエラーが連鎖的に発生していました。つまり OOM → 接続プール破損 → Chat API 呼び出し失敗 → 初期カードすら作成できず無応答、という障害の連鎖です。

3. タイムラインの確認
エラー前後の全ログ(INFO 含む)を確認し、障害の流れを時系列で把握しました。
12:06:49 ERROR Memory limit of 1024 MiB exceeded with 1029 MiB used
12:06:50 INFO Starting new instance (AUTOSCALING)
...(正常稼働)...
12:26:33 ERROR Failed to create initial card (SSLError)
12:26:33 ERROR Failed to create initial card (IncompleteRead)
...
12:29:56 ERROR Memory limit of 1024 MiB exceeded with 1033 MiB used
12:29:57 INFO Starting new instance (AUTOSCALING)
OOM → 復旧 → しばらく正常 → 再び OOM、というパターンを繰り返していました。「たまに回答が返ってこない」という報告と一致します。
メモリ使用率の可視化
原因が OOM だとわかったので、次は適切なメモリ上限を決めるために Cloud Monitoring API でメモリ使用率の推移を取得しました。
curl -s -H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://monitoring.googleapis.com/v3/projects/PROJECT_ID/timeSeries?filter=..." \
| python3 -c "..." # 分布データから平均値を抽出
結果:
| フェーズ | メモリ使用量 | 1Gi に対する割合 |
|---|---|---|
| コールドスタート直後 | ~89 MiB | 9% |
| SDK 初期化後(アイドル) | ~700 MiB | 70% |
| クエリ処理中 | ~880 MiB | 86% |
| ピーク(1分平均の最大値) | ~1011 MiB | 98.8% |
アイドル状態ですでに 70% を消費しており、クエリ処理で僅かにメモリが増加するだけで OOM に達していました。
なぜサイレント障害になるのか
このボットはバックグラウンドスレッドで処理を行い、HTTP レスポンスは即座に {} を返します。OOM でインスタンスが Kill されると、バックグラウンドスレッドも一緒に消滅しますが、Google Chat から見ると HTTP リクエストは成功(200 OK)しているため、「アプリが応答しません」等のエラー表示もされません。ユーザーには何も通知されず、ただ回答が返ってこないだけです。
メモリサイジングの考え方
Google Cloud のベストプラクティスでは、ピーク時のメモリ使用率を割り当て上限の 50〜80% に収めることが推奨されています。50% 以下は過剰なコスト、80% 以上はスパイク時の OOM リスクがあります。
| メモリ上限 | アイドル時 | ピーク時 | 判定 |
|---|---|---|---|
| 512Mi | 137% | 197% | OOM |
| 1Gi | 70% | 98.8% | OOM 発生 |
| 1.5Gi | 46% | 67% | ギリギリ(サブ秒のスパイクで OOM リスク) |
| 2Gi | 34% | 49% | 推奨範囲内 |
| 4Gi | 17% | 25% | 過剰 |
2Gi に増加することで、ピーク使用率が約 50% に収まり、十分なヘッドルームを確保できました。
Python(CPython)の内部メモリアロケータ(pymalloc)は、解放されたオブジェクトのメモリプールを保持し、OS にはほとんど返却しません。つまり、処理完了後にスレッドが終了しても、プロセスの RSS(Resident Set Size)は下がりません。明示的に
gc.collect()を呼んでも、Python 内部のオブジェクトは解放されますが、OS から見たメモリ使用量は変わりません。このため、ピーク時のメモリ使用量がそのまま常駐メモリとなり、メモリ上限はピークに合わせて設定する必要があります。
デプロイコマンド
gcloud functions deploy YOUR_FUNCTION_NAME \
--gen2 --runtime=python312 --region=asia-northeast1 \
--source=. --entry-point=handle_chat \
--trigger-http --no-allow-unauthenticated \
--memory=2Gi --cpu=1
# 初回のみ: CPU スロットリングを無効化(バックグラウンドスレッド用)
gcloud run services update YOUR_FUNCTION_NAME \
--region=asia-northeast1 --no-cpu-throttling
Cloud Run のアノテーション
run.googleapis.com/cpu-throttling: 'false'は一度設定すると以降のデプロイでも維持されます。gcloud run services update --no-cpu-throttlingは初回セットアップ時に一度だけ実行すれば OK です。
環境変数の管理
RAG の設定値は環境変数で管理しています。Cloud Functions の --set-env-vars で一度設定すれば、以降のデプロイで引き継がれます。
# 初回のみ
gcloud functions deploy YOUR_FUNCTION_NAME \
... \
--set-env-vars="GCP_PROJECT_ID=your-project,GCP_LOCATION=asia-northeast1,RAG_CORPUS_ID=your-corpus-id,GEMINI_MODEL_ID=gemini-2.5-flash"
| 変数 | 用途 |
|---|---|
GCP_PROJECT_ID |
Vertex AI SDK の初期化に使用するプロジェクト ID |
GCP_LOCATION |
リージョン指定(例: asia-northeast1) |
RAG_CORPUS_ID |
検索対象の RAG コーパス ID |
GEMINI_MODEL_ID |
回答生成に使用する Gemini モデル |
まとめ
Google Chat Bot に Vertex AI RAG Engine を繋いでナレッジベース検索を実装しました。
| ステップ | 内容 |
|---|---|
| データ整理 | QA データ → 約 300 KB エントリに整理 |
| RAG Engine セットアップ | GCS → コーパス作成 → ファイルインポート |
| 埋め込みモデル選定 | text-embedding-005 → text-multilingual-embedding-002 に変更 |
| パイプライン統合 | 検索 → 信頼度判定 → 生成(低信頼度は固定メッセージ) |
| デプロイ | メモリ 512Mi → 1Gi → 2Gi に段階的に増加 |
一番の学びは、日本語コンテンツで RAG を構築する場合、text-embedding-005 ではなく text-multilingual-embedding-002 を使うべきということです。text-embedding-005 は英語やカタカナ技術用語では問題なく動作するため、テストケースによっては気づけない罠です。
もう一つの学びは、KB データの品質が回答品質の上限を決めるということです。元データが担当者のメモ形式である以上、システムプロンプトで Gemini に変換を指示しても限界があります。より良い回答を得るには、元データ自体の品質を改善するのが最も効果的です。










