
Google Cloudで「AthenaからS3に対してクエリ」みたいなことをやるにはどうやる?
はじめに
こんにちは、データ事業本部の渡部です。
普段はAWSでデータ基盤の構築をしています。
機会があってGoogle Cloudでの基盤構築をやることになったので、触っていきます。
AIやとてもまとまったブログが世に溢れていて、学習には困らないです。本当にありがとうございます。
やりたいこと
本当に簡単に「S3のファイルをAthenaでクエリ」のようなことをGoogle Cloudでするところから始めます。
まずは基本を抑えるために小さく始めようという次第です。
AIに聞く
ある程度ブログや社内の勉強会でGoogle Cloudの初歩的な知識をつけてきたので、試しにAIに聞いてみました。
私
AWSでS3のCSVファイルをAthenaでクエリをするように、Google Cloudで同じことをしたいです。どのような構成となるか一言でズバッと教えてください。
Gemini 2.5 Flash Preview
Cloud StorageにCSVを置き、BigQueryの外部テーブルとしてクエリします。
なんとなくそうだろうなと思っていた回答でした。
AWSではS3のデータを分析用途でクエリするには、主にAthenaやRedshift Spectrumが思い浮かびますが、Google CloudはBigQueryに集約されていそうです。
今回はBigQueryの外部テーブルを使用することにしますが、実際はもっと詳しくAIに質問をしていて、「BigLakeを使用した外部テーブル」という選択肢もありました。
BigLakeは簡単にいうと、いろんな計算エンジンからいろんなところにあるデータをアクセスしやすくしつつアクセス管理を一元化してくれるもの、という理解です。
ドキュメントを見る限り、これがLake Formationの役割を担いそうですが、それはまた今度にして、今回はノーマルな外部テーブルを使います。
準備
プロジェクト・ユーザーアカウントは払い出し済みです。
Google Cloud CLIのインストール
コンソールでの操作でもいいのですが、CLIやTerraformでやってみたかったので、インストールします。
このあと使用するTerraformと合わせてCLIのコマンドなどがまとまっている記事がありましたので、こちらもご参考ください。
Terraform実行
GCSバケットとサンプルファイル、BigQueryデータセットを作成するTerraformを実行します。
# ローカル変数
locals {
project_id = var.project_id
}
# Terraform プロバイダ設定
terraform {
required_providers {
google = {
source = "hashicorp/google"
version = "~> 5.0"
}
}
required_version = ">= 1.3.0"
}
provider "google" {
project = var.project_id
region = var.region
}
# 変数定義
variable "project_id" {
description = "Google Cloud Project ID"
type = string
}
variable "region" {
description = "Google Cloud Region"
type = string
default = "us-central1"
}
variable "bucket_name" {
description = "Name for the GCS bucket"
type = string
}
variable "dataset_id" {
description = "ID for the BigQuery dataset"
type = string
}
# リソース定義
resource "google_storage_bucket" "main" {
name = var.bucket_name
location = var.region
force_destroy = true
storage_class = "STANDARD"
uniform_bucket_level_access = true
}
resource "google_bigquery_dataset" "main" {
dataset_id = var.dataset_id
location = var.region
}
# CSVファイルをローカルファイルから読み込んでGCSバケットにアップロード
resource "google_storage_bucket_object" "sample_data" {
name = "data/sample_sales.csv"
bucket = google_storage_bucket.main.name
source = "./sample_sales.csv"
content_type = "text/csv"
}
# Google Cloud Project ID
project_id = "watanabe-koki"
# Google Cloud Region
region = "us-central1"
# GCS Bucket Name
bucket_name = "cm-watanabe-data-lake-bucket"
# BigQuery Dataset ID
dataset_id = "cm_watanabe_dataset"
id,product_name,price,quantity,sale_date,customer_id
1,Apple iPhone 14,89800,2,2024-01-15,101
2,Samsung Galaxy S23,85000,1,2024-01-16,102
3,Google Pixel 8,72000,3,2024-01-17,103
4,Sony WH-1000XM5,45000,1,2024-01-18,101
5,AirPods Pro,35000,2,2024-01-19,104
6,MacBook Air M2,148000,1,2024-01-20,105
7,Dell XPS 13,135000,1,2024-01-21,102
8,iPad Pro,118000,2,2024-01-22,106
9,Surface Pro 9,165000,1,2024-01-23,103
10,Nintendo Switch,32000,3,2024-01-24,107
11,Lenovo ThinkPad X1,175000,1,2024-01-25,108
12,HP Spectre x360,155000,2,2024-01-26,109
13,Bose QuietComfort,42000,1,2024-01-27,110
14,Magic Mouse,9800,4,2024-01-28,105
15,Logitech MX Master,12000,2,2024-01-29,106
外部テーブルの作成
外部テーブルもTerraformで作成しても良かったのですが、今回は触ってみたかったbqコマンドで作成します。bqコマンドはGoogle Cloud CLIインストール時に同時にインストールされています。
今回はbqコマンドでしたが、資材管理の意味でも基本はSQLで作成することになりそうです。
# テーブル定義作成
bq mkdef --source_format=CSV --autodetect \
gs://cm-watanabe-data-lake-bucket/data/sample_sales.csv > mytable_def
# 外部テーブル作成
bq mk --table --external_table_definition=mytable_def \
watanabe-koki:cm_watanabe_dataset.sample_sales_external \
bqコマンドを使用した外部テーブルの作成方法は色々ありましたが、一度自動スキーマ検知でテーブル定義をローカルファイルに作成してそれを読み込み作成する方法をとりました。
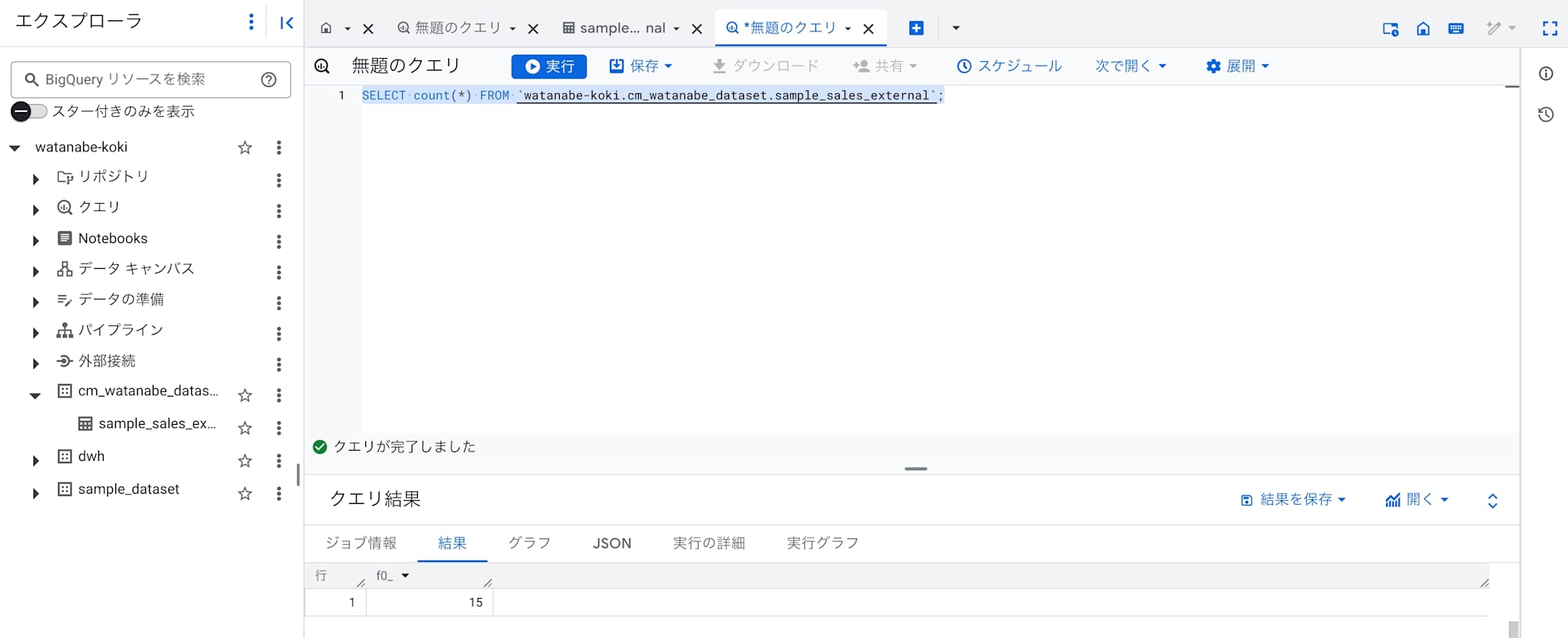
クエリ
クエリすることができました。
特にBigQueryでの設定が必要なく、すぐにクエリできるのがいいですね。
権限
なお今回の実行ユーザーアカウントに対しては、プロジェクトレベルでの基本ロール(オーナー)を与えていたので特に権限を考えずともアクセスできました。最小権限を考えると基本ロールの使用は推奨されないとのことです。そりゃそうですね。
じゃあどうすればいいかというと、GCSとかBigQueryといったリソースレベルでIAM権限を付与するか、プロジェクトレベルでIAM権限を付与しつつIAM Condition(リソース名など)で制御する方法の2種類があるようです。
GCSを例にとると、以下ブログで語られているようにリソースレベルの権限付与が基本的には良さそうに思えつつ、一方でリソース数が多くなってくると一つ一つに設定するのは大変のようにも思えるので、ケースバイケースで検討していくのがいいのかなと現状では思いました。
S3のバケットポリシーのようなリソースベースポリシーではなく、あくまでIAMで制御するんだな という理解を今回できたのは収穫です。
さいごに
AWSと一番違うのはIAMまわりですね。
リソースについてはAWSと基本は同じなので、IAMについておさえるのがGoogle Cloudをおさえる第一歩だと感じています。
今後もGoogle Cloudを触っていきます。
色々AWSでいうあのサービスはどうなんだろうというのが気になりつつ、データレイクハウスに興味があるので、そのあたりを試していこうと思います。








