
Google CloudのColab EnterpriseでHugging Faceに公開されているオープンソースなLLMを動かしてみる
データ事業本部の鈴木です。
この記事はServerless Advent Calendar 2025の8日目の記事です。
Hugging Faceでは多くのオープンソースなLLMが公開されています。
例えばOpenAIもオープンウェイトモデルであるgpt-oss-20bを公開しており、ダウンロードして誰でも簡単にこのLLMを実行することが可能です。
ただ、じゃあどこで動かすの?となったときに、自宅に強力なGPUサーバーがあったり、普段からGoogle Colabの有料プランを契約してたりする場合はともかく、実行インフラの選定で困ってしまい、そのまま実際には動かしてみなかった方も多いのではないかと思います。
そんなときに、Google CloudのColab Enterpriseが使いやすかったのでご紹介します!
Colab Enterpriseとは
Google CloudのVertex AIの機能の一つです。Vertex AIのコンソールより、非常に多くの機械学習ユーザーが利用しているであろうGoogle Colabと類似のノートブックインターフェースを使って、機械学習などに関するPythonプログラムの開発を行うことができます。
BigQueryを普段から使われている方は、BigQuery Studioから使えるノートブック機能と同じものです。Google Colabを普段から使われている方は、そのGoogle Cloud版、というイメージです。
Colab Enterpriseを使うことで、非常に簡単にサーバレスなノートブック環境を起動できます。また、大きな特徴として、ノートブック環境のランタイムを柔軟にカスタマイズできます。マシンタイプとアクセラレータの個数を自分で指定し、必要なスペックのランタイムを作成できるのです。
これが非常に便利で、アクセラレータの種類や数を調整できるため、実行したいLLMで求められるスペックのGPUを選んだり、数を変えたりできます。
マシンタイプにもよりますが、以下のように2枚挿しなども可能です。
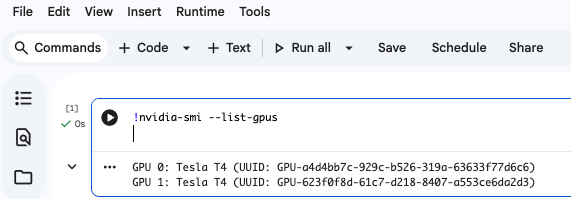
やってみる
今回は以下のチュートリアルを参考に、vLLMでgpt-oss-20bを実行しました。
Hugging Faceの記載によると、gpt-oss-20bは16GBメモリ以上のGPUが必要です。
1. ランタイムテンプレートの作成
今回はデフォルトのGPU向けランタイムテンプレートを使いましたが、カスタマイズする際のためにランタイムテンプレートの作成をみておきます。
Colab Enterpriseにランタイムテンプレートのメニューがあるので選択し、ランタイムテンプレートを作成します。
マシンタイプやアクセラレータはランタイムテンプレートで設定します。
実際のランタイムはノートブックを実行する際にランタイムテンプレートをもとに作成するという流れになります。
ランタイムテンプレート名やリージョンはRuntime basicsで設定します。
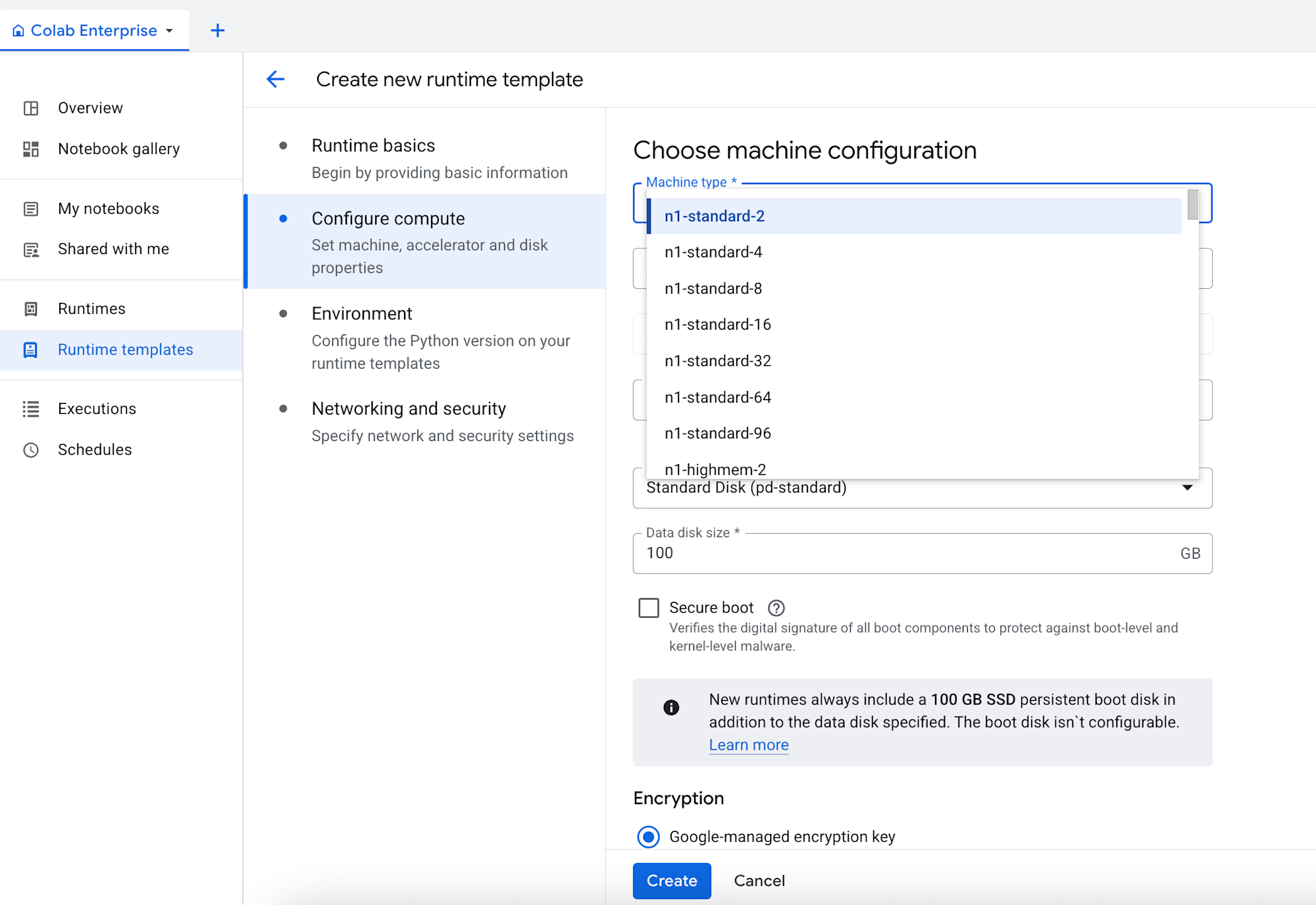
Configure computeの設定でマシンタイプとアクセラレータを設定します。
以下のようにマシンタイプを設定します。
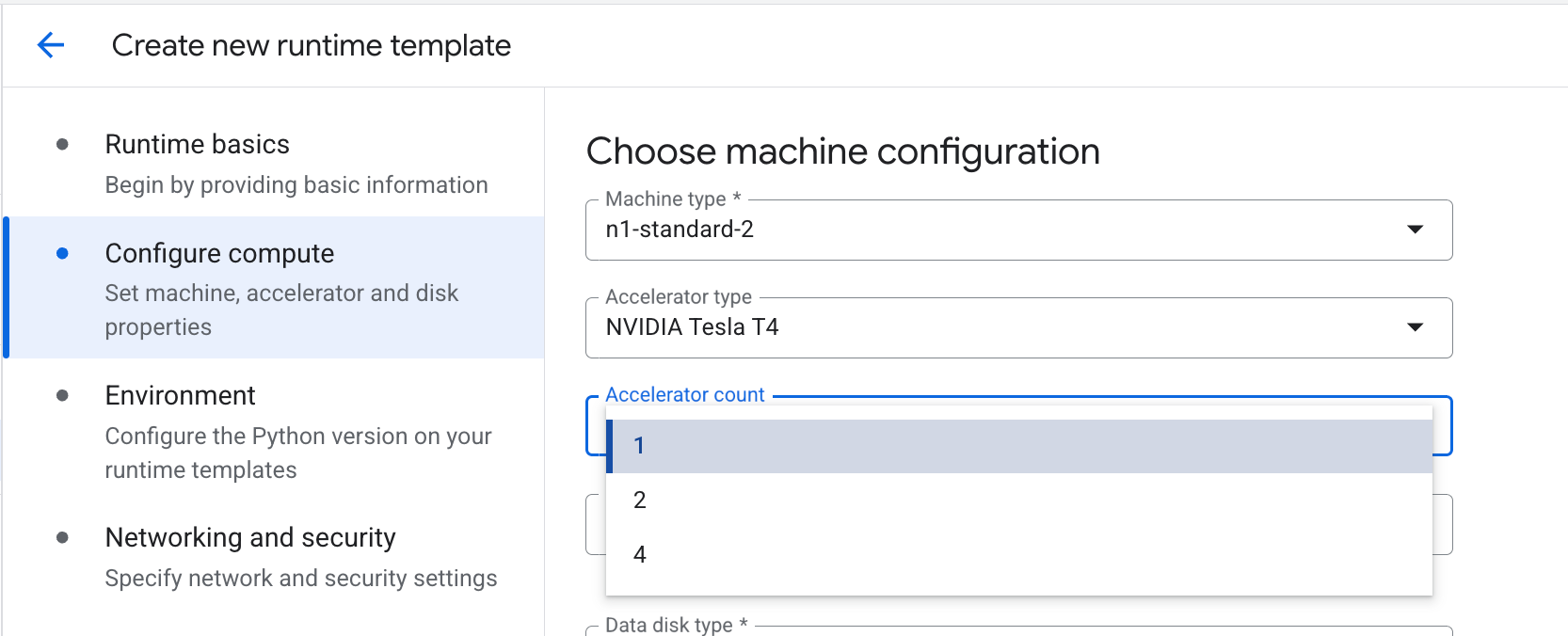
マシンタイプによりますが、アクセラレータ数も設定します。N1マシンシリーズではアクセラレータ数も変更可能です。G2マシンシリーズではアクセラレータ数はマシンタイプに対して固定のようでした。
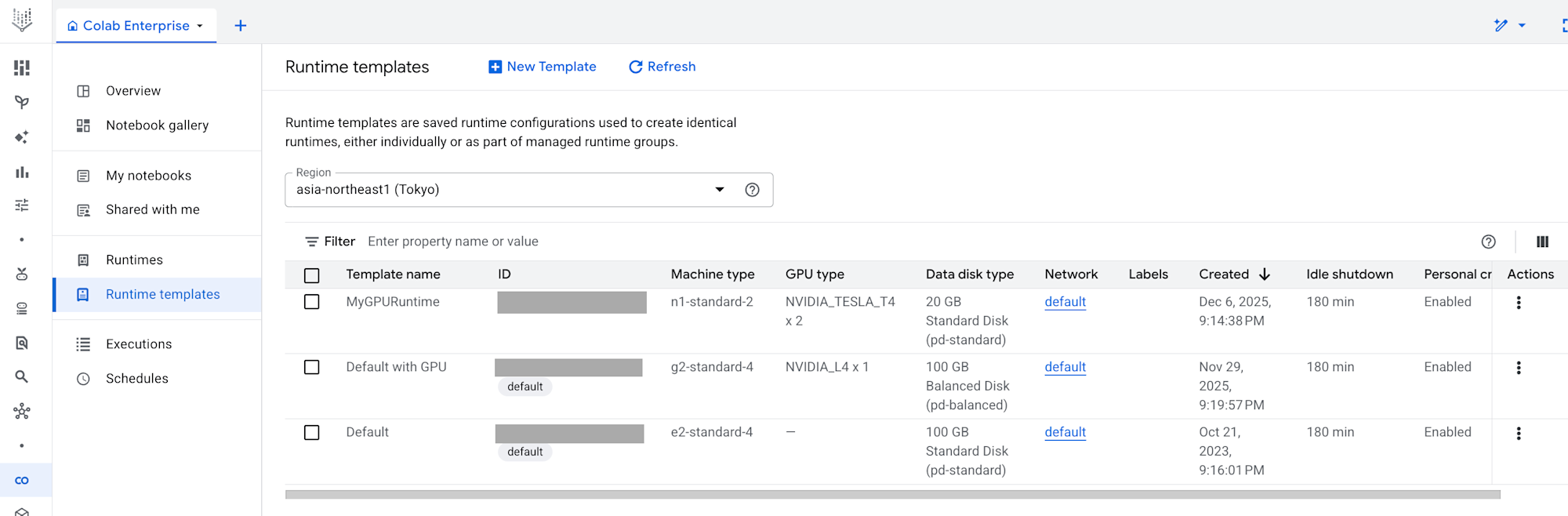
テンプレートを作成すると、以下のように一覧でみられます。
2. ランタイムの作成とノートブックからの接続
ノートブックを作成したら、セルを実行するか、右上のConnectボタンでデフォルトのランタイムを起動して接続できます。

独自のランタイムを作成している場合は、▼のConnect to a runtimeから接続できます。
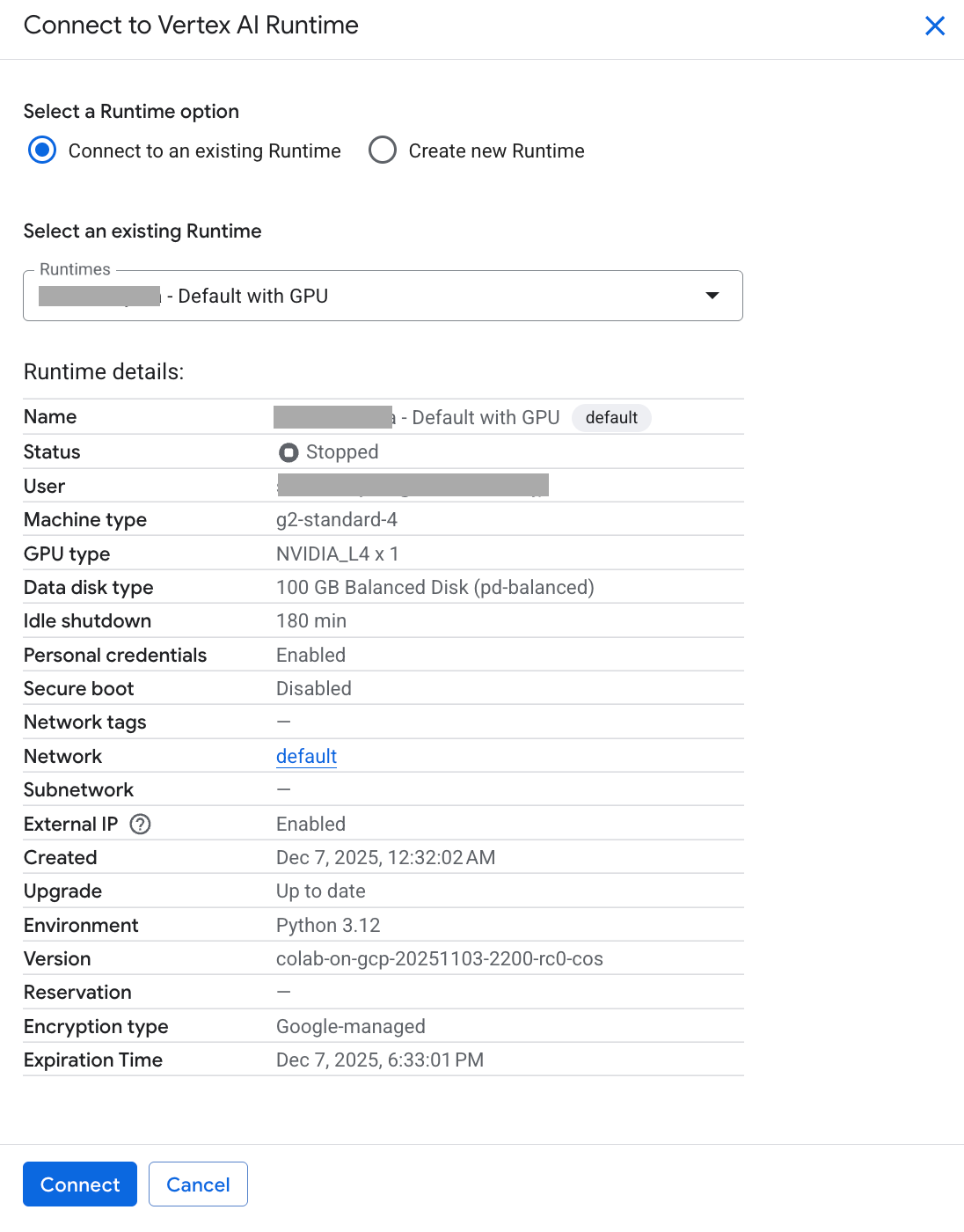
今回はデフォルトのGPUランタイムが作成できていたのでこれを使いました。g2-standard-4マシンタイプでNVIDIA_L4が1枚アクセラレータとして利用可能です。
接続方法について細かいところは以下のガイドにも記載があるのでご確認ください。
3. ノートブックの実行
今回はvLLMを使って動作させてみます。
vLLMに対応しているかはHugging Faceで確認できました。
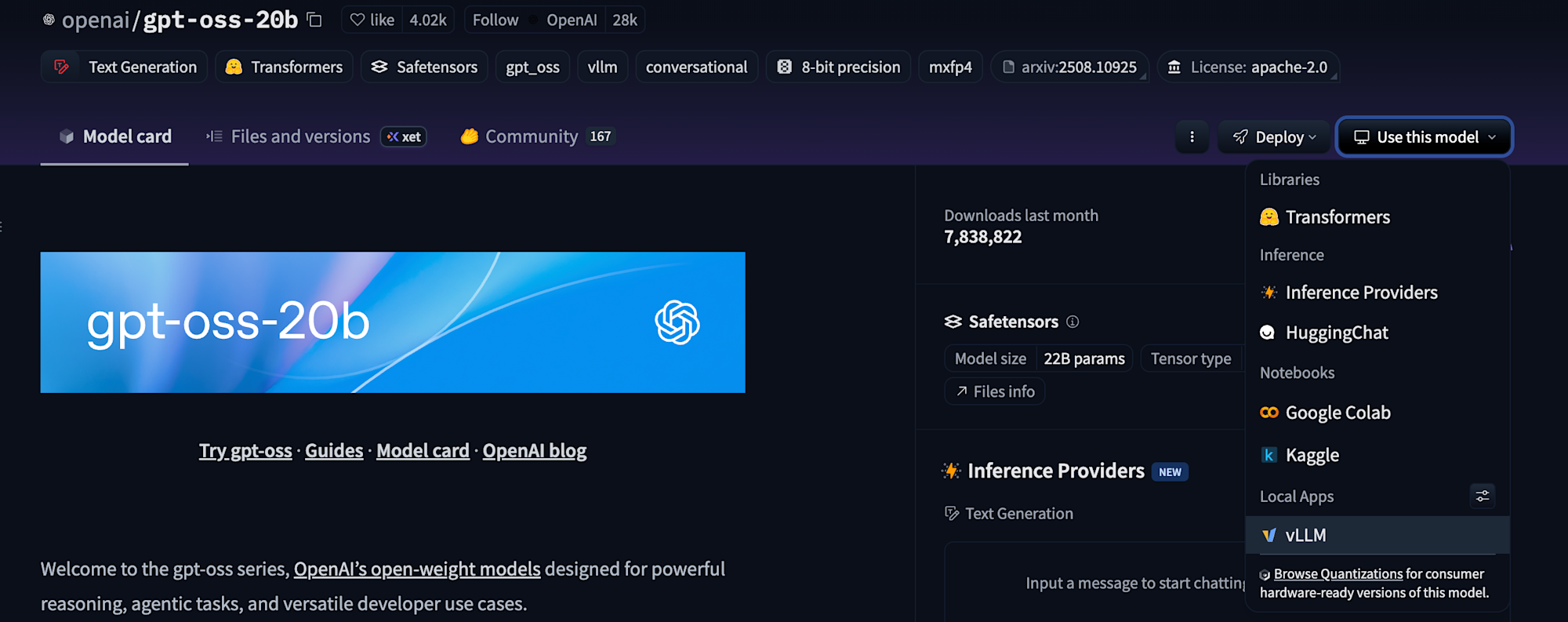
g2-standard-4マシンタイプでNVIDIA_L4が1枚アクセラレータのランタイムに接続の上、以下のコードを実行しました。
!uv pip install vllm --torch-backend=auto
vllmを実行してインストールされていることを確認しました。
!uv run --with vllm vllm --help
from vllm import LLM, SamplingParams
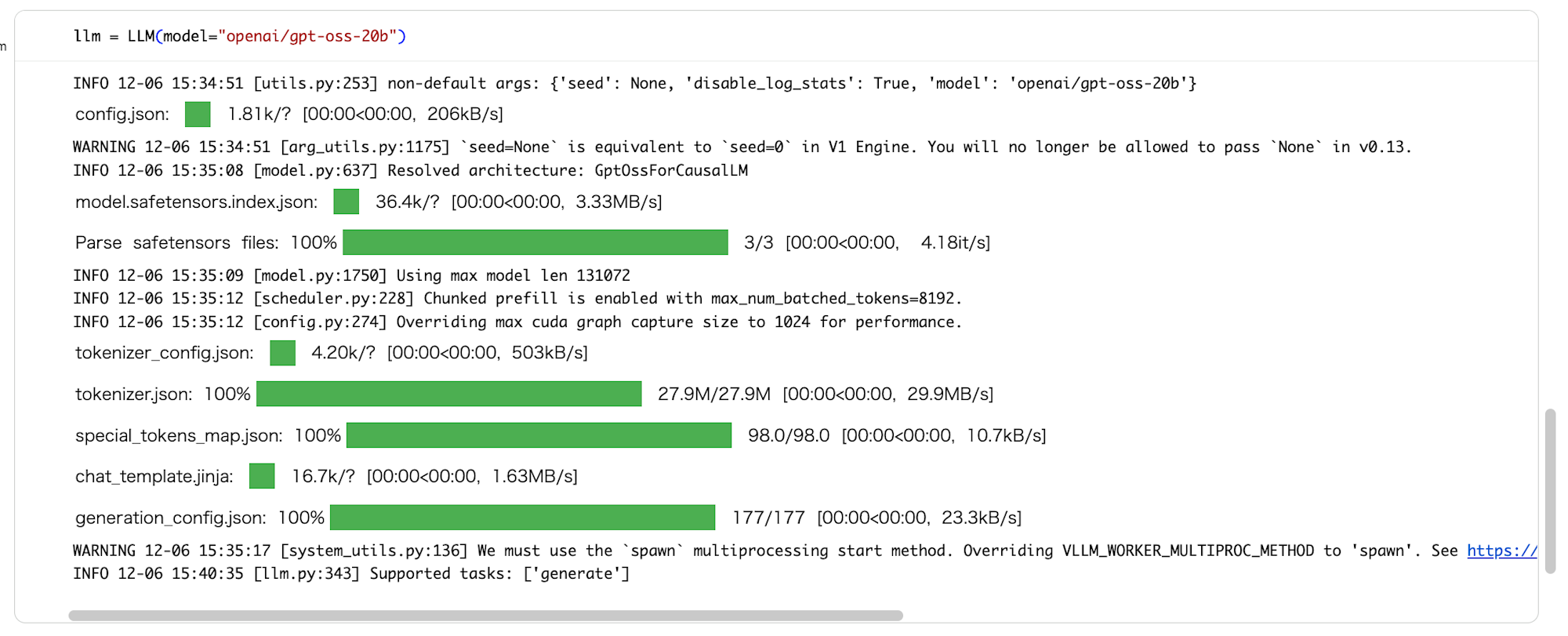
llm = LLM(model="openai/gpt-oss-20b")
ダウンロードは流石にしばらくかかります。
プロンプトを作成し、リクエストしてみます。
prompts = [
"Hi, please tell me your name!",
"How are you?",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
テキストが生成されました!
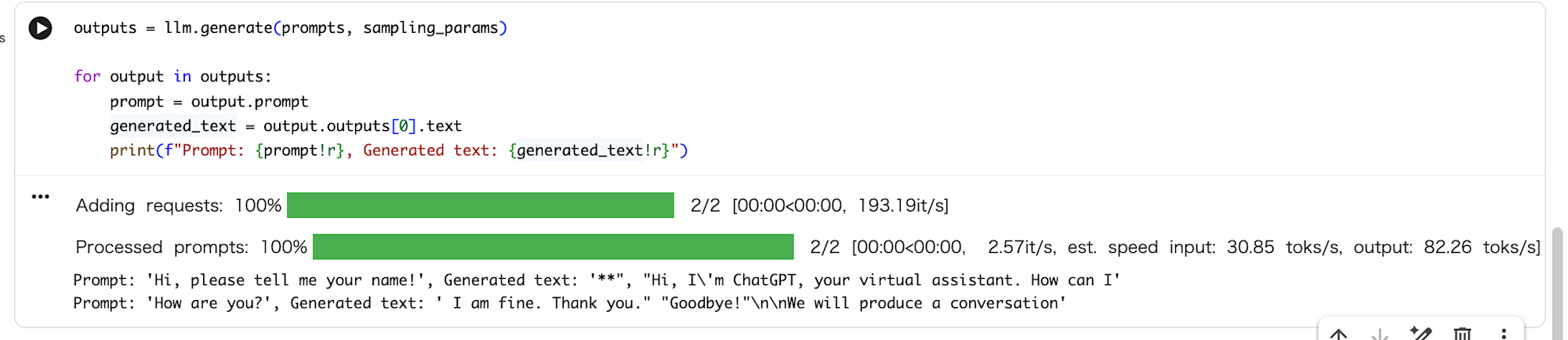
ここまで、ランタイムテンプレートとランタイムの理解は必要でしたが、非常に簡単にGPU環境をセットアップし、Hugging Faceからモデルをダウンロードして実行できました。
最後に
サーバレスなGPUノートブック環境ということで、Google CloudのColab Enterpriseを紹介しました!
自分でGPU環境を準備しようとしたことのある方にとって、驚くべきほど簡単に環境が用意できたのではないでしょうか。
Google Cloudユーザーの方はぜひ使ってみてください。
補足
マシンタイプについて
ランタイムテンプレート作成時にはGPUに対応したマシンタイプを選択する必要があります。
マシンタイプおよびマシンシリーズについては以下のガイドが参考になります。
料金について
ランタイムの構成要素に対する実行時間に対する課金になります。
以下の料金表をご確認ください。










