
レポート「全エンジニアがオンコール対応するGrafana Labsの開発組織と、オープンソーススタンダード」 #grafanaJP
「めっちゃええなこれ…GrafanaのLabの開発組織、こんな赤裸々に話してくれるのか…」
2026年3月18日に開催された「Grafana Meetup Japan #8」に運営側として参加してきました。今回のテーマは「Grafanaの開発組織とオープンスタンダード」。ゲストスピーカーとして、Grafana LabsのVP of EngineeringであるDee Kitchenさんと、OpenTelemetryの共同創設者でGrafana LabsのDeveloper Programs DirectorであるTed Youngさんが、先日開催のObservabilityCon on the Road Tokyoに引き続き登壇し、普段はなかなか聞けないGrafana Labsの開発組織の内情やOSSプロジェクトの哲学について語ってくれました。
Dee KitchenはGrafana LabsのデータベースチームであるLoki、Mimir、Tempo、Pyroscopeを統括するVPoE、Ted YoungはOpenTelemetryの共同創設者であり、Governance Committeeのメンバーでもある、オブザーバビリティ業界のキーパーソンです。
この二人が一堂に会して、Grafana Labsのエンジニアリング組織やOSSプロジェクトの始め方について語るという、めっちゃ贅沢なイベントだったので、その内容をお届けします。
なお、本記事はイベント当日の内容を文字起こしからまとめたものです。英語でのトークに対して通訳が入る形式でしたが、できるだけ発表者の言葉のニュアンスを活かす形で構成しています。
セッション1:How Grafana Builds Software — Grafanaはどうやってプロダクトを開発しているのか

セッション1はDee Kitchenさん(Grafana Labs VP of Engineering)による、Grafana Labsのエンジニアリング組織と開発プロセスの紹介。
エンジニアリングの原則: 自律性とオーナーシップ
私たちは自律性(Autonomy)とオーナーシップ(Ownership)を非常に重視しています。マネージャーがトップダウンで意思決定をすることはありません。エンジニアに対して、ボトムアップで「何が正しいのか」「どのツールを使うべきか」を教えてくれることを期待しています。
ちなみに、右側を見てください。私たちはJiraを使っていません。
これらの原則の一つ一つを極端に推し進めれば、大惨事になります。私たちが目指しているのは、すべての原則を通じて調和とバランスを実現すること。エンジニアリング環境は、エンジニアが最高のパフォーマンスを発揮できる場でなければなりません。マネージャーのためではありません。
グローバル分散型の組織構造
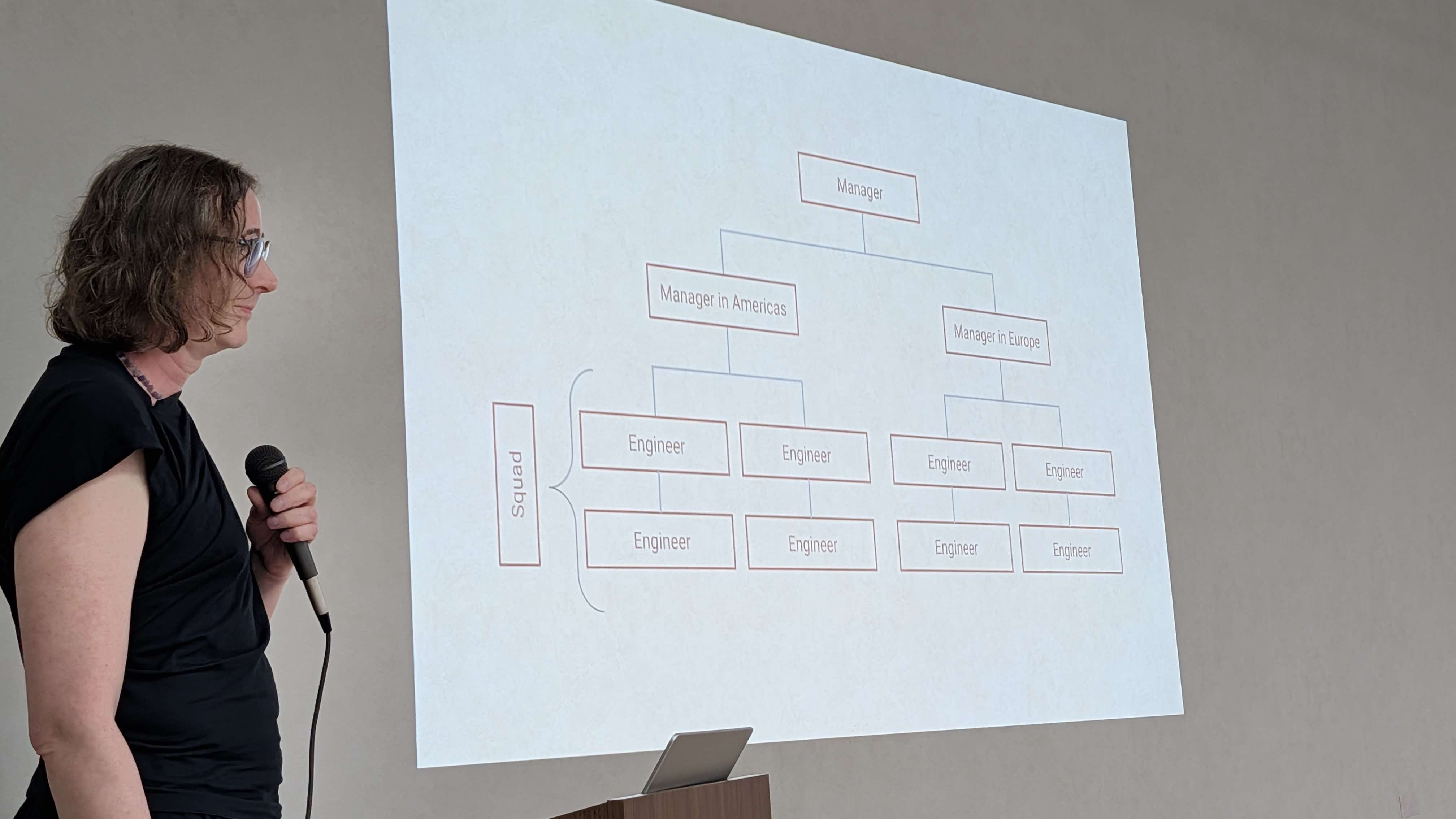
では、これらの原則が組織構造にどう表れているか、具体例をお見せしましょう。
あるスクワッド(チーム)があるとします。私たちはそのチームを世界中に分散させます。一つのリージョンには3〜4人しかいないこともあり、そのリージョンがアメリカ大陸全体をカバーしていたりします。
しかし私たちは、オンコールをFollow the Sun(太陽を追いかける方式)で運用します。エンジニアが日中の時間帯だけオンコールを担当するには、最低2つのリージョンが必要です。月に1回はオンコールに入る必要があるので、1リージョンに最低4人は必要。つまり、1つのスクワッドは最低でも6〜8人、2リージョン以上でなければなりません。
さらに、私たちの原則ではすべてのエンジニアは自分のリージョンにマネージャーがいなければならない。つまり各スクワッドに複数のマネージャーがいることになります。これは面白いですよ。多くのマネージャーは、スクワッドで唯一のマネージャーであることに慣れていましたから。新しく入ったマネージャーはまず「リーダーシップを共有しなきゃいけないって、どういうこと?」と戸惑います。
マネージャーが権力を集中させないよう、1人あたりのダイレクトレポートは平均8〜10人に設定しています。一見すると4人しか部下がいないように見えても、意図的に多くの人数を割り当てることで、マネージャーが細かくコントロールすることを防いでいます。
ここまでの話を理解していただけたなら、気づいたと思います。マネージャーには権力(power)がありません。あるのは影響力(influence)だけです。
単一リポジトリによるデプロイメント
次は、この環境を理解するためのもう一つの要素として、デプロイメントの仕組みについて話します。
私たちは単一のGitHubリポジトリを使っています。社内では「Deployment Tools」と呼んでいます。エンジニアの皆さんならすぐ気づくと思いますが、26,500のブランチと72万のコミットがあります。この単一のリポジトリが記述しているのは、本質的には一つだけ。「Grafana Cloudがどうあるべきか」の定義です。
私たちはGrafana CloudをAWS、GCP、Azureにデプロイしています。25の物理リージョンに50の論理リージョンです。エンジニアはクラウドサービスプロバイダーのことを考える必要がありません。

Deployment Toolsは2つの技術で構成されています。一つ目はJsonnet。Googleから生まれたプロジェクトで、JSONの拡張言語です。おそらく大規模OSSとして私たちが最大のユーザーでしょう。JSONを形式的に記述できるので、何を書いたかが明確になります。
二つ目はTanka。Jsonnetで書いた定義を、クラウドプロバイダーが実際に実行できるものに変換するツールです。Kubernetesの設定やスケジューリングの制御、変更の可読性の高いdiffの生成もできます。
変更の80%はボットによって実行されています。はっきり言っておきますが、これはAIではありません。例えばテナントのリミット更新。サポートチケットを発行して物理的な設定を変更する代わりに、ボットが安全に変更を行います。
この仕組みの目的はシンプルです。エンジニアがエンジニアリングに集中できるようにすること。運用に集中させないこと。これはエンジニアたちを幸せにします。なぜなら、彼らは自分が書いたすべてのコードに対してオンコールで責任を持っているからです。
ハッカソン: プロダクト機能の半分はここから生まれる
エンジニアにこれだけの権限を与えた結果、面白いことが起きます。
Grafana Labs社内でハッカソンを開催しています。全エンジニアの約半数が参加し、年4回、各1週間の開催です。多くの企業がハッカソンをやっていますが、私たちはちょっと極端です。ハッカソンで作ったものの約半分を、実際のプロダクト機能としてリリースしています。
これを1週間のスタートアップのように感じてもらいたい。参加者はビデオでピッチを行い、プロジェクトの内容と成果をプレゼンします。全社投票で順位が決まり、優勝者には賞金が出ます。
エンジニアには、自分たちが直面する問題の痛みを体感してほしい。エンジニアのためのツールを作りたいなら、まずエンジニア自身がそのツールを使い、問題を感じるべきです。このサイクルを月単位で回す。年単位ではなく。
オープンソースとライセンシング
私たちはオープンソース企業です。どのライセンスをいつ適用するかについてのガイダンスがあります。基本的な考え方として、ユーザーの環境にインストールされるもの、つまりあなたのマシンに入るソフトウェアについては、適切なライセンス体系を用意する方針です。
オンコール: 全エンジニアが担う4つの責任
先ほど述べたとおり、すべてのエンジニアがオンコールを担当します。最低で月1週間、週12時間以上。エンジニアはオンコール中、複数のことを見なければなりません。
第一に、SLO(Service Level Objectives)。これが最も重要です。信頼性のあるシステムでなければなりません。信頼できないシステムは誰も買いません。
しかし、スケールアップしてお金をかければ信頼性の高いシステムは簡単に作れます。だから第二に、TCO(Total Cost of Ownership)。サービスのコストをバランスよく維持する責任があります。
第三に、脆弱性とセキュリティ。パッチを当てなければなりません。信頼性が高くコスト効率もいいサービスでも、セキュアでなければ意味がない。
そして第四に、レジリエンス。サービスが攻撃や障害に耐えられるようにする責任です。
質疑: エンジニアの評価方法
質問者「エンジニアとマネージャーの間に明確な区別があり、マネージャーには権力がないとのことですが、ではエンジニアはどう評価されるのですか?」
「私たちはエンジニアをビジネスアウトカム(事業成果)で評価します。 好きなことに取り組んで構いません。しかし、それが私たちにとって価値あるビジネス成果を生まなければ、事実上その仕事は認められません。正しい仕事を選ぶのはエンジニア自身です。つまり、ビジネスマインドが求められます。」
質問者「ということは、エンジニアは新しいことに取り組みたいと思っても、それがGrafana Cloudのビジネスにどう貢献するかを考えなければならない。提案にはビジネスマインドセットが必要で、成果物が会社全体のビジネスにどう貢献するか明確に理解していなければ、認められないということですね。つまりエンジニアリングに加えてビジネス視点、さらにオンコールも。それがGrafana Labsのエンジニアに求められることですか?」
「Correct.(その通りです。)」
セッション2:How to Start an Open Source Project — オープンソースプロジェクトはどうやって生まれるのか

セッション2はTed Youngさん(OpenTelemetry共同創設者、Grafana Labs Developer Programs Director)によるトーク。
皆さん、こんにちは。インターネット上ではTed Youngです。今日はオープンソースプロジェクトの始め方について話してほしいと頼まれました。本当に簡単ですよ。GitHubで新しいプロジェクトを作るだけです。

でも実際には、いくつかアドバイスがあります。私はオープンソースに長い間関わってきました。たぶん長すぎるくらいです。あまりに長くて、もうGitHubのアバターにも似ていません。新しい写真を撮ろうとしてるんですが、なぜか全部もっとひどくなるんです。これまでにApacheプロジェクト、Node.js、Ruby on Rails、Cloud Foundryなど、さまざまなプロジェクトに携わってきました。
これから話すのは、私が考える「調和の鍵」です。正解も不正解もありません。しかし、プロジェクトを始める際には、これらのことについて明確さと合意を持つことが重要です。
個人がOSSを始める3つの動機
個人としてOSSプロジェクトを作る理由は3つあります。Fun(楽しみ)、Passion(情熱)、Professional(職業)です。
Fun。これが一番いい理由ですよね? 自分のためにソフトウェアを作る。ある意味、これがオープンソースの最も純粋な形です。やりたいからやる。ただそれだけです。
次に多い理由がPassion。ここで言いたいのは、ソフトウェアが正しく動くかどうかをあなたが気にかけているということ。お金のためでも、仕事としてメンテナンスしているわけでもない。でもソフトウェアが動くことがあなたにとって重要。言い換えると、このソフトウェアはもはやあなた自身のためのものではない。
そして3つ目はもちろんProfessional。仕事としてソフトウェアを作るケースです。経済活動を生み出すために行われ、一般的に人々は給与を受けるか、何らかの形で報酬を得ています。
「サポートは楽しくない」
個人に対する私のたった一つのアドバイスはこれです。
サポートは楽しくない(Support is no fun)。

プロジェクトがサポートを必要とするようになったら、人々がサポートを求めてくるようになったら、そのプロジェクトは重要になったということです。でもそれは、もう楽しくないということでもある。なぜなら、もうあなたのためのものではないから。あなたがサポートしている人々のためのものです。
ここで選択があります。あなたがこのソフトウェアを使っている人々とその理由に情熱を持っていて、だから無償でサポートを続ける。あるいは、このソフトウェアがProfessionalの領域に入っていて、何らかの形で報酬を受けるべき。
あなたがサポートを提供しているが、この人々に情熱を持っているわけでもなく、報酬も受けていない。これはあなたのエゴがあなたを罠にかけているんです。 エゴに騙されてはいけない。人々にこう伝えてください。「これは楽しみで作ったもので、保証はありません。」
これが個人に対して最も重要なことです。
大規模OSSの成功条件
では大規模なプロフェッショナルOSSプロジェクトについてアドバイスが聞きたければ、いくつかあります。もし何かの理由でそういうものを始めようとしているなら。
大規模なオープンソースといえば、Linux Foundation、Linux、Kubernetes、OpenTelemetryのような共有インフラを思い浮かべるでしょう。でも、史上最大のオープンソースプロジェクトを忘れないでください。インターネットです。これはずっと大きい。なぜなら共有インフラの話ではなく、コミュニケーションの話だからです。
大規模ソフトウェアが成功するための要因は4つあります。
第一にプロトコル。コミュニケーションに関する最大規模のOSSプロジェクトは、アプリの上に構築されているのではありません。プロトコルの上に構築されています。アプリはプロトコルの上に作られる。真のアプリケーションはプロトコルそのものです。インターネットのすべてがこう動いていますよね? HTTP、FTP、BitTorrent、メールでさえも。
第二にモジュラリティ。大規模プロジェクトは、完成していなくても有用でなければなりません。実際、完成することはないのですから。インターネットだって単一のプロトコルではなく、一つずつ開発されたプロトコルのスタックで構成されています。
第三に冗長性(Redundancy)。ソフトウェアの冗長性だけではありません。ソフトウェアを作っている組織にも、単一障害点があってはならない。
そして最後に、当然ながらお金。大規模プロジェクトには多くのエンジニアリング時間が必要で、資金が必要です。
OpenTelemetryでの実践
では、私が携わっているOpenTelemetryで、これらの問題にどう対処してきたか、具体例を見せましょう。
最も重要なのは、OpenTelemetryは実はプロトコルだということです。実装には多くの労力がかかるので、実装が最も重要に見えるかもしれません。しかし実装は完全にオプショナルです。重要なのはプロトコルです。
もちろんOpenTelemetryを知っている方はOTLPを聞いたことがあるでしょう。これが私たちのメインプロトコルです。しかし実際にはいくつかの別のプロトコルも開発中です。Apache Arrowベースのものと、STEPというより効率的なメトリクスプロトコルです。
でも実は、OpenTelemetryで最も重要な部分は、最も退屈な部分でもあります。それがセマンティックコンベンション(Semantic Conventions)です。HTTPリクエストとは何か、SQLデータベース呼び出しとは何か、レポートするすべての対象を定義します。どこから報告されたかに関係なく、毎回同じ方法で報告されるようにする。
これこそが真のオープンソースです。データを送る。OTLPを使おうが、他のプロトコルを使おうが。セマンティックコンベンションに従ったデータであれば、それがOpenTelemetryです。データがどう作られたか、どう送られたかは関係ありません。
モジュラリティについて。OpenTelemetryのすべてのパーツは疎結合に保っています。これは実際には難しい設計上の課題です。よくこう言われます。「この機能をCollectorに入れて、全員がCollectorを使っている前提にすれば、全SDKに入れるよりシンプルじゃないか。」でも、もし全実装を結合させて、OpenTelemetryを使うには私たちの全実装を使わなければならないようにしたら、私たちはプロトコルではなく、ヘアボール(毛玉)を提供していることになります。
ベンダー中立ガバナンスについて。単一障害点を排除するため、同一組織から2人以上がGovernance CommitteeやTechnical Committeeのような主要ポジションを占めることはできないというルールがあります。
そしてマネタイズモデル。私たちはOpenTelemetryでどうお金を稼ぐべきかについて明示的です。データは共有する。データは標準化する。分析で競争する。 データは標準、分析はグリーンフィールドです。
これはKubernetesの初期から学んだ教訓です。Kubernetesの始まりの頃は、どうやってお金を稼ぐのか不明確でした。誰がソフトウェアを所有しているのかも不明確でした。CorosやHeptioのようなスタートアップがソフトウェアを所有していて、誰かが提案を出しても、それが良い提案なのか、スタートアップが金儲けの方法を見つけようとする巧妙な提案なのか、区別がつかなかった。エンジニアリングがストレスフルになることがありました。
OpenTelemetryではこのような問題はほとんどありません。なぜなら、みんながゲームのルールについて合意しているからです。
OpenTelemetryに寄贈しようとするプロジェクトの中には、面白くて有用に見えるものがありますが、私たちのモチベーションモデルに合致しない場合は受け入れられません。オリジナルのメンテナーが引退した後に維持される保証ができないからです。これは通常、DevTools、CLI、データビジュアライゼーションなど、OpenTelemetryの上に構築されたプロジェクトです。
でも実は、これらのプロジェクトに「No」と言うことで人々を救っていると思っています。なぜなら、OpenTelemetryの上に作られるものは、Funであってほしいからです。
だから会場の皆さんへのお願いです。オブザーバビリティとOpenTelemetryで何ができるか、考えてみてください。でも、それを楽しい旅として考えてください。プロジェクトを作って、人々と共有してください。サポートのことは心配しなくていい。皆さんが何を作るか、本当に楽しみにしています。
Ask Me Anything (AMA) — 何でも質問コーナー
休憩を挟んで、Dee KitchenさんとTed Youngさんの二人によるAMAセッションが行われました。参加者からの質問に対して、リアルタイムで回答していく形式です。ここでは特に盛り上がったトピックをまとめます。
コードのセキュリティ対策
質問: コードをセキュアに保つ目標に対して、具体的にどのような課題に対してどう対策を敷いているのか、可能な範囲で教えてください。
Dee Kitchen: 私たちはサプライチェーンリスクに直面しています。私たちのプロジェクトは100万以上のインストールがあり、ほぼすべての国で利用されているからです。
非常に優秀なCISO(最高情報セキュリティ責任者)のもと、出荷しないものも含めた全リポジトリに対する脆弱性スキャンを実施しています。非常に短い期間でのパッチ適用要件を設定し、すべてのシークレットは暗号化され、アクセス可能な環境でのみ利用可能です。すべての環境にカナリアトークンを配置し、シークレットが漏洩した場合は関連するすべてのシークレットを即座にローテーション・無効化します。
そしてエンジニアのインセンティブ設計も重要です。セキュリティに貢献することが昇進や報酬につながるよう設計しています。米国と欧州のほぼすべての主要な金融機関が顧客です。彼らが私たちに説明責任を求めてきます。
なぜ全エンジニアがオンコールなのか?
質問: 全てのエンジニアがOn-callを対応しなければならないという体制はかなり珍しいと考えます。なぜそのような体制がルール化されたのか、その背景を伺いたいです。
Dee Kitchen: SRE(Site Reliability Engineering)チームを別に設けると、ソフトウェアの作成者が問題の痛みを感じなくなります。信頼性の低い、ノイズの多いソフトウェアの痛みをSREに外部化してしまうのです。
私たちのアプローチは、インセンティブを一致させること。信頼性の高いソフトウェアを作れば、オンコール中は静かに過ごせます。逆にノイズの多いソフトウェアを作れば、オンコール中に苦しむことになる。この設計により、エンジニアは自分が書いたコードの品質に対して自然と責任を持つようになります。
マルチクラウドデプロイメント
質問: マルチクラウド(AWS、GCP、Azure)でデプロイされているのは、すごく新しい情報でした。Grafana Cloudのデプロイにおいて、それぞれのパブリッククラウドの使い分けはありますか?可能な範囲で教えて下さい。
Dee Kitchen: まったく同じ(Homogeneous)です。目的はセルラーアーキテクチャの提供です。AWSのリージョンを思い浮かべてください。別のリージョンに移動しても、すべてのサービスが利用可能です。私たちもまったく同じです。ユーザーは通常、アプリケーションのホスト先に近いリージョンを選択して、egress(データ送出コスト)を最小化します。
外部コントリビュータと製品ロードマップ
質問: OSSとして公開されているものは外部のコントリビュータからの機能追加のPRもあると思います。これをうまく製品ロードマップとマッチさせるために工夫していることはありますか?
Dee Kitchen: 特にありません。
(この質問に対してはシンプルな回答で、特別な仕組みは設けていないとのことでした。)
Botによる自動化の具体例
質問: Bot を用いて自動化されているとのことですが、具体的にどういったところまで自動化されていますか?
Dee Kitchen: 具体例を一つ挙げると、あるサービスに負荷がかかってアラートが発生した場合、そのデータが自動的にオートメーションに渡され、スケールアップして負荷を解消します。ただし、正確に状況を計測できるシナリオに限ります。いわばランブックの自動化です。
ベンダー中立性と収益のバランス
質問: ossのベンダーニュートラルとお金を稼ぐ両立は困難に思うのですが、opentelemetryでの方法、工夫を教えてください
Ted Young: 全員がオープンで、お金の稼ぎ方について合意していれば、資金自体は問題を生みません。最も重要なのは、人々が自分の動機に正直であること、そしてプロジェクトが嘘をつかなくていい構造になっていることです。
Kubernetesの初期にはこれが実現できていませんでした。誰がソフトウェアを所有しているか、どう収益化するかが不明確で、提案が純粋な技術的提案なのか、スタートアップが収益化を画策しているのか判断できず、エンジニアリングがストレスフルでした。OpenTelemetryではこのような問題はほとんどありません。なぜなら、みんながゲームのルールについて合意しているからです。
Dee Kitchen: エンドユーザーはベンダー中立性を非常に重視しています。信じてください、彼らが私たちを正直にしてくれます。
AI活用の現状
質問: 開発にAIを取り入れていますか?
Dee Kitchen: エンジニアの98%がAIを使っています。 どのAIツールを使うかの指示は一切ありません。Claude、Codex、ChatGPT、Gemini、Hugging Faceで自分のモデルを作ってもいい。自由に選べます。
トップエンジニアは、日中のほとんどの時間を問題の定義に費やします。そして夜間の16時間で、20〜30のAIエージェントのチームが実際にソリューションをコーディングします。一般的なエンジニアはCopilotやCodexを使用しており、平均で月間約3億トークンを消費しています。
一方で課題もあります。AIの活用によってコードの生産量が増えた結果、PRレビューがはるかに難しくなっている。
Grafana Assistantは、社内のエンジニアが自ら選んで使うレベルになるまでリリースしません。 私たちが自分たちで使わないものは、ユーザーにとっても十分ではありません。
ドッグフーディングの基準としてこれ以上ないほど明確で、この姿勢にはめっちゃ共感しました。
まとめ「よくこれだけ、オープンにしゃべってくれたものだ…」
一言、そんな感想でした。このミートアップの前日が、ObservabilityCon on the Road TokyoというGrafana Labsの大規模イベントだったので、そちらでのビジネスライクなテイストと全然違っていたのが、それはそれで新鮮でずーっと聞いていて楽しかったです。
個人的に特に印象に残ったのはこのあたり。
- 「マネージャーには権力がない。あるのは影響力だけ」というGrafana Labsのエンジニア中心の組織哲学
- ハッカソンの成果物の半分がプロダクト機能としてリリースされるという文化
- Ted Youngさんの「サポートは楽しくない。エゴの罠に注意」というOSSへの率直なアドバイス
- 「データは共有する。分析で競争する」というOpenTelemetryの明確なマネタイズモデル
普段は表に出にくいエンジニアリング組織の内部構造やOSSの運営哲学が、ここまで赤裸々に語られることはなかなかなかったと思います。Dee KitchenさんとTed Youngさんの率直さと誠実さが際立つミートアップでした。
Grafana Meetup Japanは今後も定期的に開催していきますので、興味のある方はぜひ参加してみてください。
それでは今日はこのへんで。濱田孝治(ハマコー)でした。









