![[Isaac Lab] AWS EC2 g5.2xlarge で SO-ARM101 の Reach の報酬・目標を「指先(TCP)」基準に再設計してみました](https://devio2024-media.developers.io/image/upload/f_auto,q_auto,w_3840/v1780435591/user-gen-eyecatch/mwd9ijcarxhvbxxc3wct.png)
[Isaac Lab] AWS EC2 g5.2xlarge で SO-ARM101 の Reach の報酬・目標を「指先(TCP)」基準に再設計してみました
1 はじめに
製造ビジネステクノロジー部の平内(SIN)です。
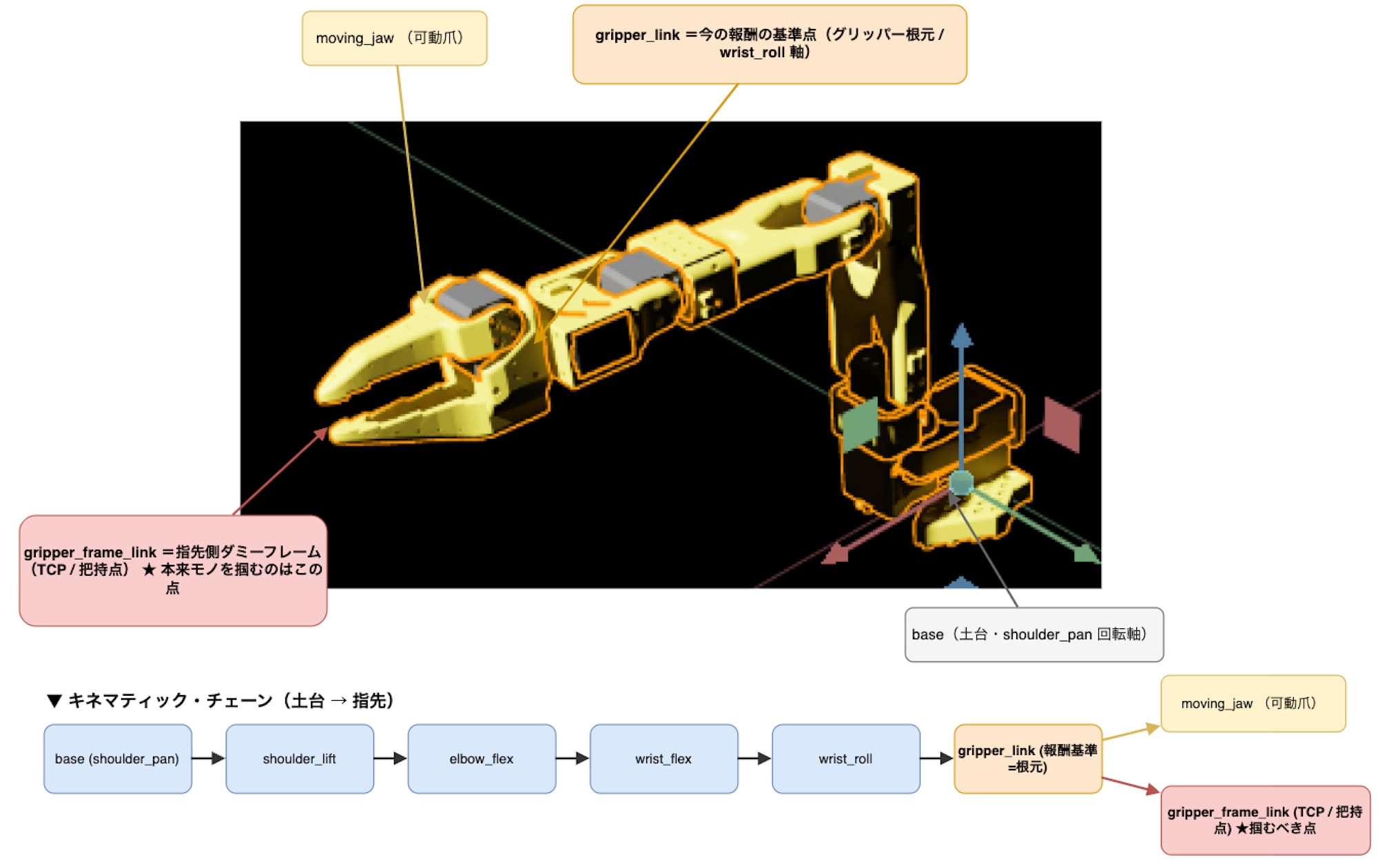
Isaac Lab に同梱される Reach タスクは、報酬の距離を gripper_link という body と目標点で測っています。そして、この gripper_link は、手首ロール軸(グリッパーの「根元」) にあたります。
しかし、目標点に到達した後、「物体を掴んで持ち上げる」という次の行動をイメージした場合、グリッパーの根元ではなく、先端が目標に向かう必要があると思います。
そこで、今回は、Isaac Lab の Reach タスクを元に、グリッパーの指先(TCP)を目標点へ到達させる強化学習(PPO)を行いました。
使用したのは、以下の構成です。
- ロボット: SO-ARM101(5 自由度 + グリッパーの小型アーム)
- 環境: Isaac Lab 2.3.0 + Isaac Sim 5.1.0、PPO(rsl_rl)
- 学習基盤: AWS EC2 g5.2xlarge(NVIDIA A10G)
- ベース: MuammerBay/isaac_so_arm101 の Reach タスク
EC2は、GPUを必要としない作業(コード編集やログ確認など)は t3.medium へ切り替えてコストを抑制しました。
2 学習の目標
URDF には指先用のダミーフレーム gripper_frame_link(根元から約 10cm 先)が用意されていますので、これを TCP として利用することにしました。
また、元の Reach タスクは、グリッパーの向き(姿勢)についてはまったく対象外でした。しかし物を掴む場合、向きも無視できない要素になります。
そこで、今回の目標は、以下のように設定してみました。
- 先端(TCP)を目標点へ持っていく
- 掴める向き(姿勢)を考慮する
- ある程度、目標値に近づいた時点で完了とする
3 は、私の実力とコスト抑制を考慮した緩和条件です。
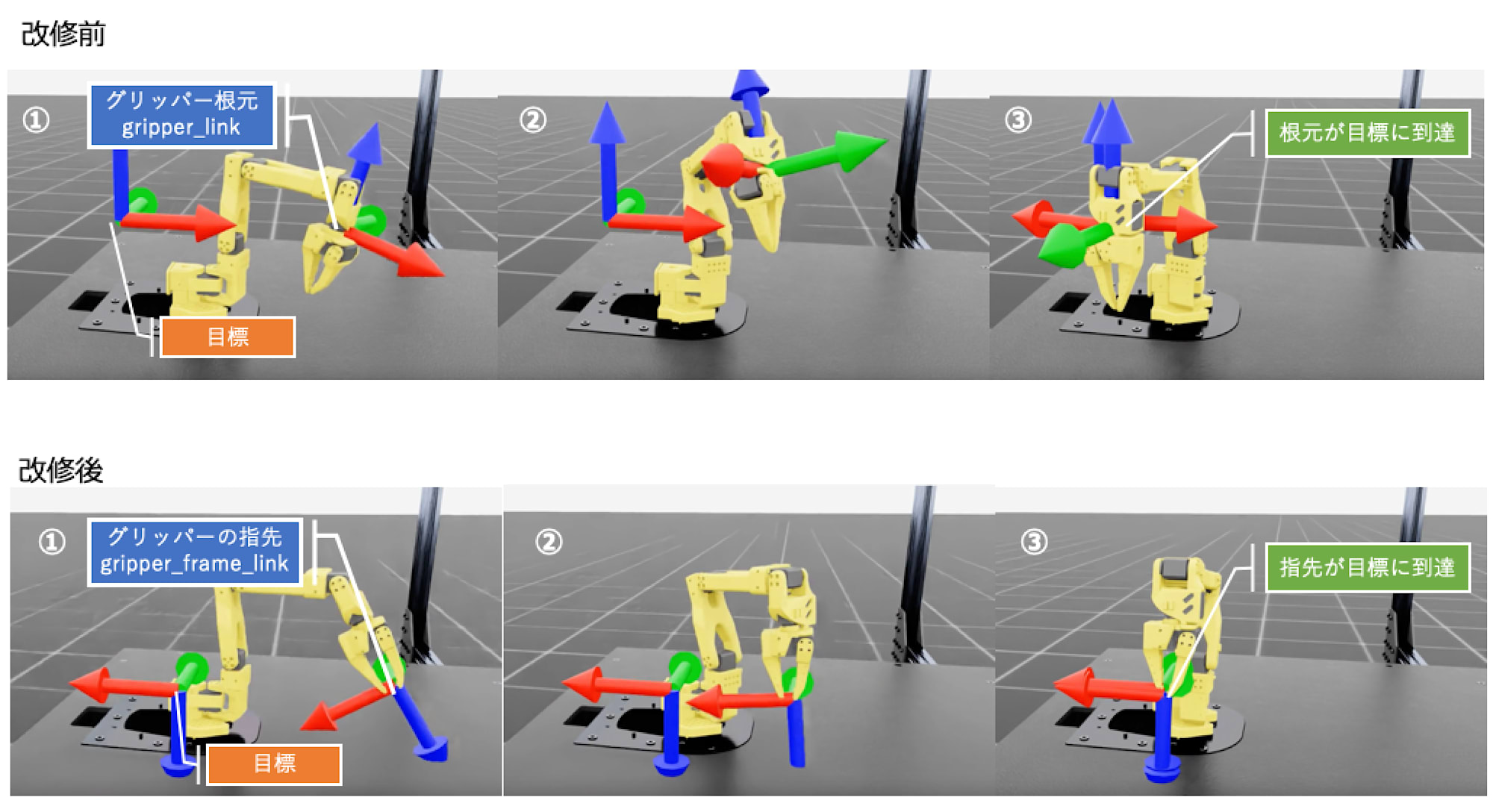
なかなか報酬関数の挙動が把握できず、試行錯誤の連続となりましたが、何とかたどり着いた様子が以下です。改修前は、根元が目標に向かっていましたが、改修後、先端が目標に向かうようになりました。
3 環境構築
学習環境は EC2 上に Isaac Lab + Isaac Sim をセットアップしていますが、今回はベースリポジトリの clone から uv sync で構築しました。
(1) リポジトリの clone
$ mkdir -p ~/work && cd ~/work
$ git clone https://github.com/MuammerBay/isaac_so_arm101.git
$ cd isaac_so_arm101 # 以降の作業は repo 内で行う
(2) 依存のインストール(uv sync)
x86_64 + NVIDIA GPU(CUDA 12.8 ドライバ)/ Python 3.11 が前提です。ARM64 は(NVIDIA DGX Spark を除き)不可で、一般的な Mac(Apple Silicon)や CPU だけの環境では動きません。学習には GPU が必要です。.venv はディスク数 GB〜十数 GB を要します。
uv が未導入であれば、先に入れておきます。
$ curl -LsSf https://astral.sh/uv/install.sh | sh
$ source $HOME/.local/bin/env
$ uv --version
一点だけハマりどころがありました。flatdict のビルドに必要な pkg_resources が setuptools 81 で同梱されなくなったため、それを含む古い版(< 81)を補う必要があります。pyproject.toml に以下を追記します。
$ cat >> pyproject.toml <<'EOF'
[tool.uv.extra-build-dependencies]
flatdict = ["setuptools<81"]
EOF
あとは uv sync で依存(Isaac Lab 2.3.0 + Isaac Sim 5.1.0 + torch)を .venv に入れます。数 GB のダウンロードがあり時間がかかります。
$ uv sync
# 入ったか確認
$ uv pip list 2>/dev/null | grep -iE "isaaclab|isaacsim|torch|flatdict"
isaaclab 2.3.0
isaacsim-* 5.1.0.0
torch 2.7.0+cu128
flatdict 4.0.1
(3) タスク登録の確認
train の前に、タスクが登録されているか確認します。
$ uv run list_envs 2>&1 | tee /tmp/envs.txt
$ grep -i reach /tmp/envs.txt # Isaac-SO-ARM101-Reach-v0 が見えれば OK
初回は NVIDIA の EULA 同意プロンプト(Do you accept... に Yes)が出ます。
ここまで作業は CPU で完了できます。
(4) 学習(train)と再生(play)
uvで環境が構築されているため、学習・再生の起動コマンドは、次のようになります。
ここからは、GPUが必要になります。
# 学習(train)
$ uv run train --task Isaac-SO-ARM101-Reach-Grasp-v0 \
--headless --num_envs 64 --max_iterations 1000
# 再生・録画(play)
# 録画は --headless + --video + --enable_cameras の3点セット
$ uv run play --task Isaac-SO-ARM101-Reach-Grasp-Play-v0 \
--num_envs 4 --headless --video --video_length 200 \
--enable_cameras \
--checkpoint logs/rsl_rl/reach/<日時>/model_999.pt
4 修正したコードと説明
Github: tasks/reach/__init__.py
Github: tasks/reach/joint_pos_env_cfg.py
変更は、tasks/reach/joint_pos_env_cfg.py へ元クラスを継承したクラスを追加し、tasks/reach/__init__.py へ登録しましら。新タスクの名前は Isaac-SO-ARM101-Reach-Grasp-v0 / -Grasp-Play-v0 です。
__init__.py(抜粋)
# Isaac-SO-ARM101-Reach-Grasp-v0で検索可能にする
gym.register(
id="Isaac-SO-ARM101-Reach-Grasp-v0",
entry_point="isaaclab.envs:ManagerBasedRLEnv",
kwargs={
"env_cfg_entry_point": f"{__name__}.joint_pos_env_cfg:SoArm101ReachGraspEnvCfg",
"rsl_rl_cfg_entry_point": f"{agents.__name__}.rsl_rl_ppo_cfg:ReachPPORunnerCfg",
},
disable_env_checker=True,
)
tasks/reach/joint_pos_env_cfg.py(抜粋)
@configclass
class SoArm101ReachGraspEnvCfg(SoArm101ReachEnvCfg):
"""親(元Reach)との差分をここで上書きする"""
def __post_init__(self):
# 元 Reachを継承
super().__post_init__()
(1) 報酬・コマンドの基準を「指先(TCP)」へ
まず、報酬の距離・姿勢を測る基準(body_names)を、根元 gripper_link から指先 gripper_frame_link(TCP)へ差し替えます。
tasks/reach/joint_pos_env_cfg.py(抜粋)
TCP_BODY = "gripper_frame_link"
# 距離・姿勢の基準を、根元 gripper_link → 指先 TCP へ
self.rewards.end_effector_position_tracking.params["asset_cfg"].body_names = [self.TCP_BODY]
self.rewards.end_effector_position_tracking_fine_grained.params["asset_cfg"].body_names = [self.TCP_BODY]
self.rewards.end_effector_orientation_tracking.params["asset_cfg"].body_names = [self.TCP_BODY]
# 目標ポーズの基準 body も指先に揃える
self.commands.ee_pose.body_name = [self.TCP_BODY]
(2) 姿勢制御を有効化し、目標姿勢を「上から掴む向き」に固定
元の Reach では姿勢の重みが 0.0(姿勢無視)でしたが、重みを与え、目標姿勢を物を上から掴む(top-down)向きにします。
tasks/reach/joint_pos_env_cfg.py(抜粋)
# 元は weight=0.0(姿勢無視)。掴むには向きの制御が要る
self.rewards.end_effector_orientation_tracking.weight = -0.4
# 目標姿勢 = 物を上から掴む(top-down)向きに固定
self.commands.ee_pose.ranges.roll = (0.0, 0.0)
self.commands.ee_pose.ranges.pitch = (math.pi, math.pi) # 先端を下へ
self.commands.ee_pose.ranges.yaw = (0.0, 0.0)
(3) 目標位置を「届く範囲」に限定
5 自由度の小型アームでは、top-down を保ったまま到達できる範囲は限られます。そこで、確実に届く範囲に目標位置を限定しました。
tasks/reach/joint_pos_env_cfg.py(抜粋)
# top-down を保ったまま確実に届く小さい箱に限定
self.commands.ee_pose.ranges.pos_x = (-0.03, 0.03) # アーム基準(base 座標)で左右 ±3cm(中心が正面)
self.commands.ee_pose.ranges.pos_y = (-0.18, -0.14) # アーム基準(base 座標)で前方 14〜18cm(負 = 前方)
self.commands.ee_pose.ranges.pos_z = (0.10, 0.14) # アーム基準(base 座標)で高さ 10〜14cm
(4) 位置精度を上げる:多段 tanh + 成功ボーナス
近距離ほど効く tanh 報酬(position_command_error_tanh)を 2cm(std=0.02)と 5mm(std=0.005)の 2 段 で足し合わせ、さらに「目標の 1cm 以内(threshold=0.01)なら +0.5」の成功ボーナス(position_success_bonus)を追加しました。
tasks/reach/joint_pos_env_cfg.py(抜粋)
_TCP = SceneEntityCfg("robot", body_names=[self.TCP_BODY])
# 近距離ほど効く精度報酬(std が小さいほど近距離特化)
self.rewards.position_tracking_2cm = RewTerm(
func=mdp.position_command_error_tanh, weight=0.3,
params={"asset_cfg": _TCP, "std": 0.02, "command_name": "ee_pose"})
self.rewards.position_tracking_5mm = RewTerm(
func=mdp.position_command_error_tanh, weight=0.3,
params={"asset_cfg": _TCP, "std": 0.005, "command_name": "ee_pose"})
# 1cm 以内のステップに +0.5("角"を直接報酬)
self.rewards.position_success_1cm = RewTerm(
func=position_success_bonus, weight=0.5,
params={"asset_cfg": _TCP, "command_name": "ee_pose", "threshold": 0.01})
成功ボーナスは、実績のある mdp.position_command_error(距離を返す)をしきい値判定するだけの、薄い自作関数です。フレーム計算そのものは既存関数に任せています。
def position_success_bonus(env, asset_cfg, command_name, threshold):
# 既存の距離関数をしきい値判定するだけ。1cm 以内なら 1.0、外なら 0.0
dist = mdp.position_command_error(env, asset_cfg=asset_cfg, command_name=command_name)
return (dist < threshold).float()
5 試行錯誤の経緯
当然ですが、一発では決まりません。各ステップで「効くと思った仮説」が外れ、その都度、考えなおす試行錯誤となっています。位置誤差・姿勢誤差はいずれも、終盤のエピソードの平均値です。
| 実験 | 変更点 | 位置誤差 | 姿勢誤差 | 学び |
|---|---|---|---|---|
| 初期 | TCP 化 + 姿勢 ON(-0.1) | 約 16cm | 約 3° | 向きは出るが位置が全然ダメ。姿勢制約を入れたことで位置に到達できない |
| 診断 | TCP 化 + 姿勢 OFF | 約 9cm | — | 確認のため姿勢を無効化すると位置が改善 = 位置劣化の主因は姿勢制約と判明。TCP 化自体は無害 |
| Exp1 | 精度報酬を多段化 + 姿勢 -0.1 | 約 13cm(未収束) | 約 2° | 精度報酬を尖らせても、その報酬が有効になるまで近づかない。まず必要なのは、近くに寄せること |
| Exp2a | 目標の出現位置を限定 | 約 1.5cm | 約 13° | 目標の出現位置を制限することで、位置は一気に解決。だが今度は位置報酬が姿勢を圧倒し向きが崩れる |
| Exp2b | 姿勢 weight -0.1 → -0.4 | 約 1.8cm | 約 8.5° | 向きも改善。ただし weight 調整は「位置 ⇄ 向き」のトレードオフとなる |
| Exp2c | 成功ボーナス(1cm) | 約 1.8cm(最良 6mm) | 約 7.85° | 位置と姿勢が、概ね両立 |
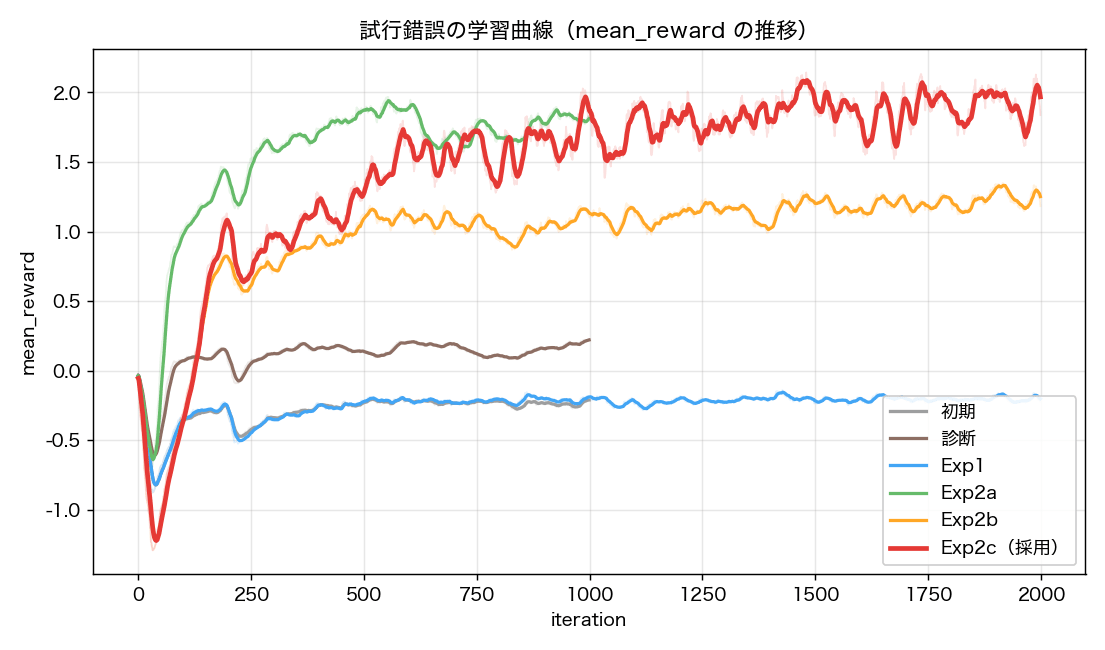
試行錯誤から得られた要点は、次の 3 つです。
- 精度報酬(小さい std の tanh)は「近距離の仕上げ」専用: 遠距離では効きにくいため、まず大きく近づけることが必要
- 報酬は「全体のバランス」が重要: 目標の出現位置を簡単にすると、簡単に位置報酬が上がってしまい、相対的に姿勢の報酬が効かなくなりました。姿勢の weight を上げて再バランスしました
- weight 調整だけでは届かなかった: 位置と姿勢は対立する課題となっているようで、weightの調整だけでは、最終目標にはなかなか到達できませんでした。成功ボーナスで「角」を直接報酬することで少し改良できました
うまくいった一方で、正直に書いておくべき限界も残っています。
- 目標の出現位置は約 6 × 4 × 4cm の範囲: 位置精度はこの狭い範囲で出した値で、範囲を広げると位置と姿勢の対立が再発する見込みです
- 姿勢は完全な垂直ではなく、やや前傾:
gripper_frame_linkのフレーム反転のため、pitch=πが厳密に何の向きになるかは動画で確認しました(破綻はしていません) - 評価はエピソード平均誤差: 本来は終端(掴む瞬間)の誤差や成功率で測るべきで、平均は道中も含むため実際の保持精度とはズレます
6 結果
学習曲線(mean_reward)は右肩上がりで、最終 reward は、約 +1.9(ピークで約 +2.0) でした。
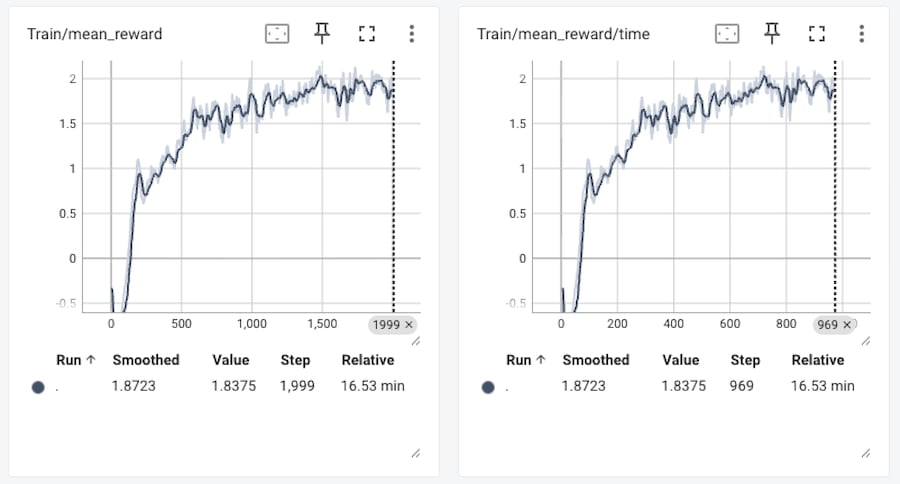
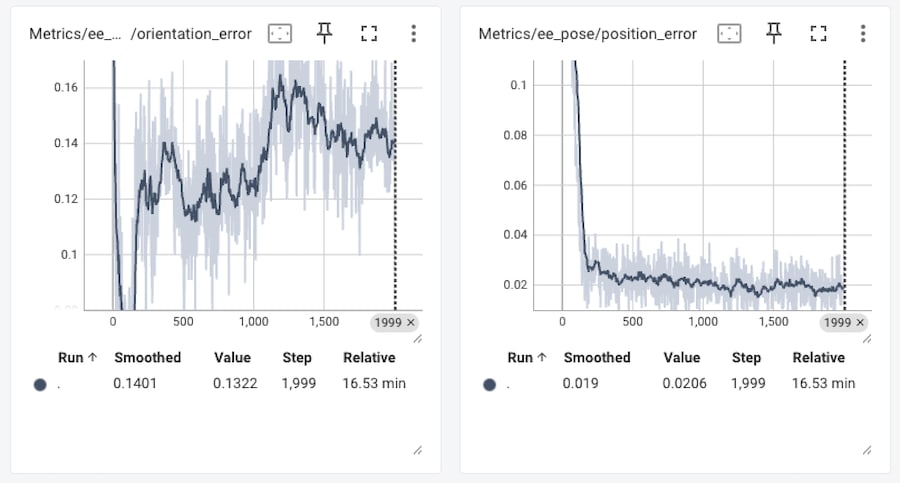
位置誤差(position_error)は、約1.8〜2.0cm、姿勢誤差(orientation_error)は、0.137rad(7.85°)で後半やや増加傾向でした。
先端 TCP の 1cm 圏内滞在割合は、最大 17% となっています。
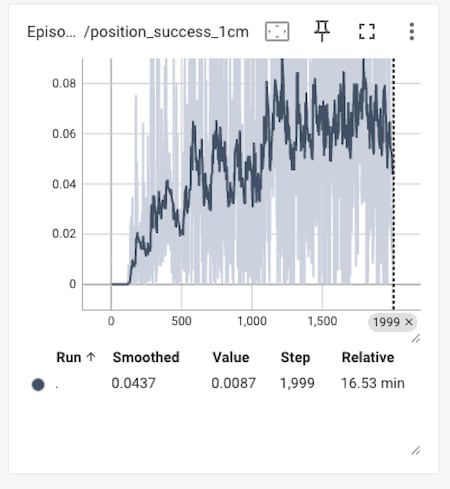
※ グラフは成功ボーナス項の値。weight=0.5 のため滞在割合 = 値 × 2。平滑ピーク約 0.085 → 約 17%
7 録画カメラを「前から」見える位置へ移動する
学習済みポリシーを play で再生して mp4 に録画する際、デフォルトのカメラは「後ろ斜め上」からで、ちょっとグリッパーの動きが分かりにくいので、視点を変更してみました。
- 変更前

- 変更後
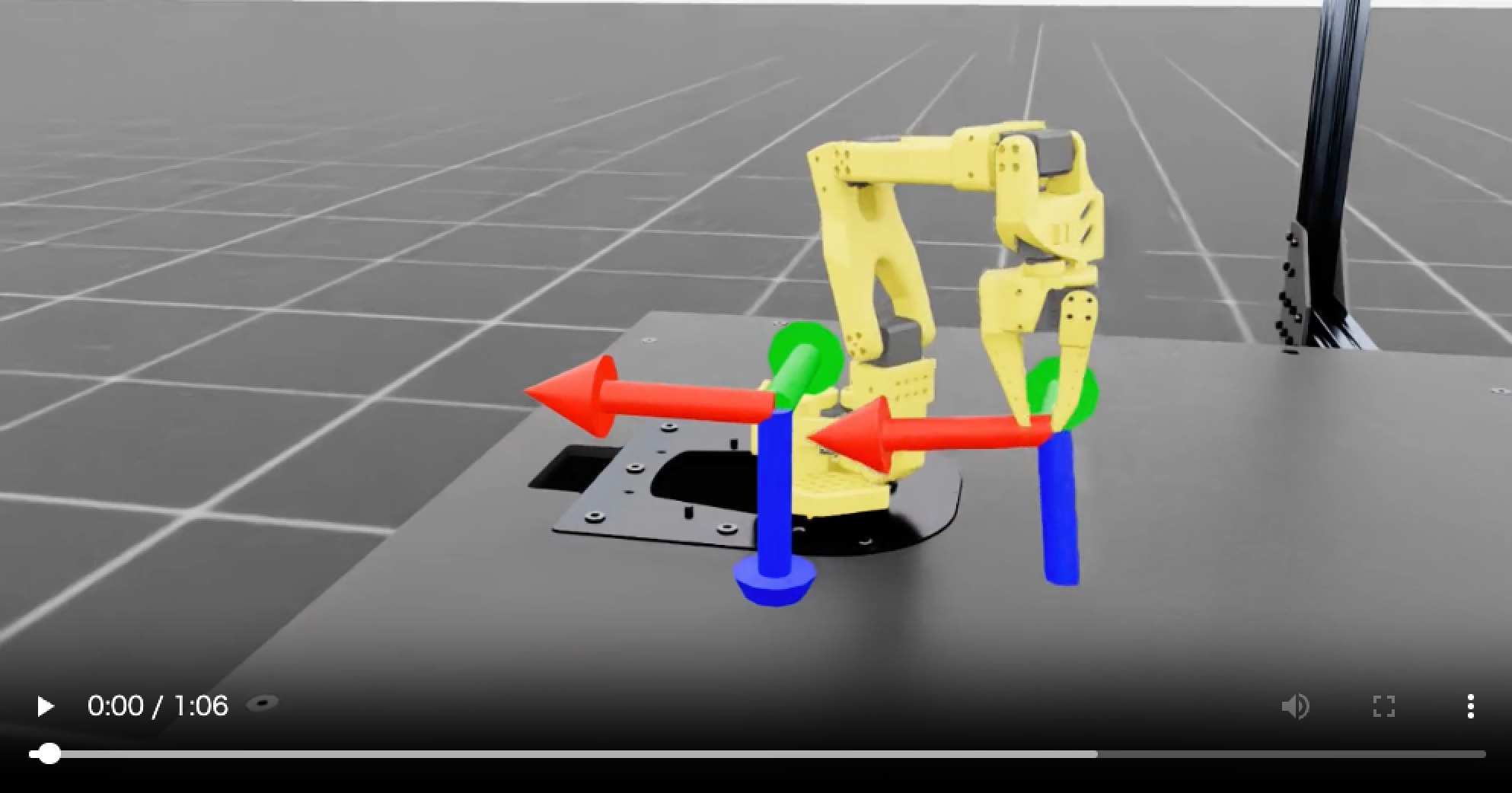
録画カメラは、Isaac Lab の viewer(ViewerCfg)の eye(カメラ位置)と lookat(注視点)で決まります。カメラ位置は、Reach 環境の基底クラス reach_env_cfg.py の __post_init__ に書かれているので、これを変更しました。
Github: tasks/reach/reach_env_cfg.py
# 変更前(デフォルト・後ろ斜め上・遠い)
# self.viewer.eye = (2.5, 2.5, 1.5)
# 変更後(前(-y) からやや上・グリッパー作業域に接近)
self.viewer.eye = (0.15, -0.85, 0.35) # カメラ位置:-y 側 = 前、少し上
self.viewer.lookat = (0.0, -0.15, 0.13) # 注視点:目標が出る作業空間の中心
なお、RecordVideo は録画フレームをメモリに溜め込みます。--video_length 2000 × 1280×720 で 5.5GB 程度になるため、RAM が小さいインスタンスでは Isaac Sim と合わさってメモリ枯渇に至ることがあります。長尺を撮る場合は g5.2xlarge(RAM 32GB クラス)を選ぶ必要がありました。
8 まとめ
今回は、Reach タスクを元に、姿勢を考慮して、グリッパーの指先(TCP)を目標点へ到達させる強化学習(PPO)を行いました。
基準を、根元(gripper_link)から指先(gripper_frame_link / TCP)へ変えること自体は簡単ですが、傾きを制御したり、より目標に近づけたりするための報酬の設計は難しいと感じました。特に、姿勢制約と位置精度がトレードオフの関係にあり、そこから抜け出すのにかなり時間を要しました。
まだまだ、完璧とは言えませんが、一定の成果が出せて本当に嬉しいです。
参考リンク
- ベースリポジトリ: MuammerBay/isaac_so_arm101
- 本記事の追加分(改修した完全ファイル 3 つ): https://github.com/furuya02/isaac-lab-so-arm101-reach-grasp
- Isaac Lab ドキュメント: https://isaac-sim.github.io/IsaacLab/
- rsl_rl(PPO 実装): https://github.com/leggedrobotics/rsl_rl
- Amazon EC2 オンデマンド料金: https://aws.amazon.com/jp/ec2/pricing/on-demand/