【登壇レポート】 JAWS-UG熊本で「今からでも間に合う! 生成AI『RAG』再入門」と題して登壇しました! #jawsug #jawsugkmmt
みなさん、こんにちは!
福岡オフィスの青柳です。
2025年6月14日に熊本市内で開催された「JAWS-UG熊本」に参加・登壇してきました。
前回 (1月開催) に続き、今回も「JAWS-UG九州キャラバン」と題して、九州のJAWS-UG各支部 (福岡・佐賀・大分・熊本) が4週連続でイベント開催するという「お祭り」の一環としての開催でした。
登壇資料
今回の勉強会は「AWSを触るのは初めて」「生成AIを利用したことはあるけど構築は初めて」という参加者の方が多いという話を伺いまして、初めての方にも楽しんで頂けるテーマで登壇しました。
以下、ポイントを抜粋して紹介します。(詳しくは登壇スライドを参照ください!)
「RAG」が生まれた経緯
- LLM (基盤モデル) の弱点
- ごく最近の情報に関する質問に答えることができない
- 企業の社内情報など非公開の情報に答えることができない
- 弱点を克服する従来の手法
- 「最新データ」「社内データ」を使ってモデルを1から作る
- 既存のモデルに「最新データ」「社内データ」を追加学習させる
- → いずれも「コスト」や「時間」がネック
- そこで考案された「RAG」
- 基盤モデルに「検索」を組み合わせることで「最新データ」「社内データ」に対応
RAGの仕組み
利用開始前に「検索データ」を用意する (①〜②)
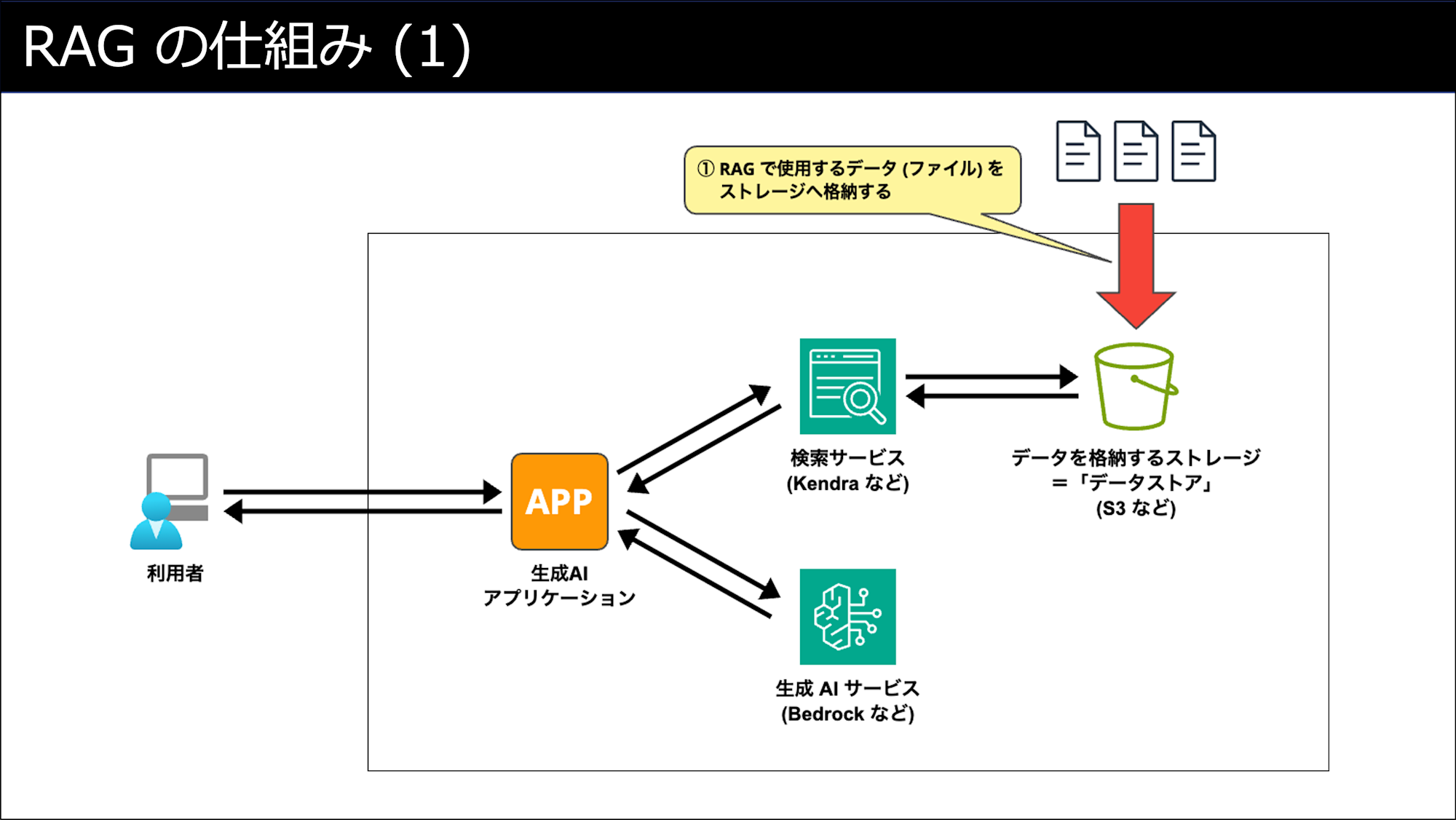
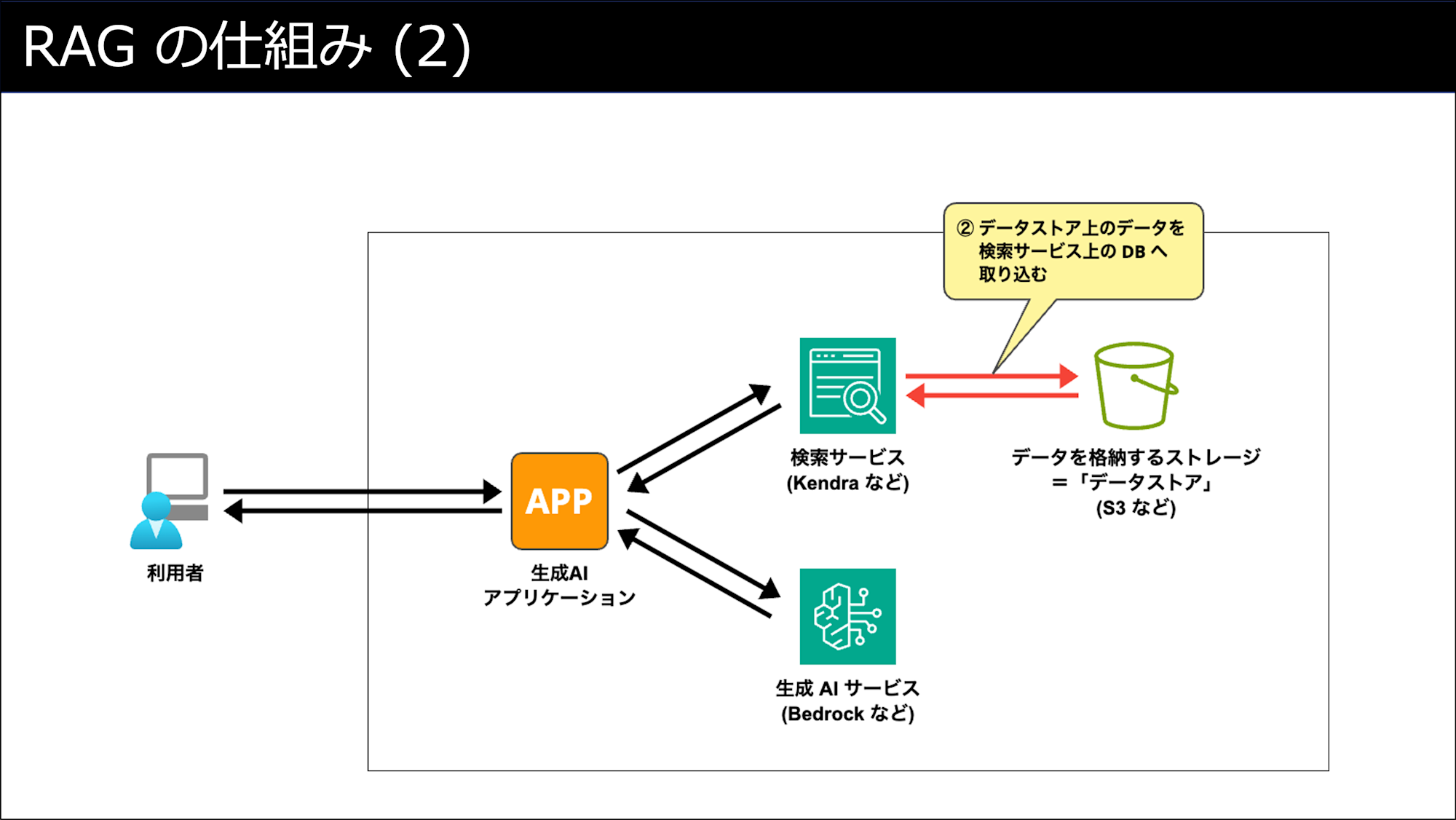
ユーザーがRAGを利用する際の動作 (③〜④)
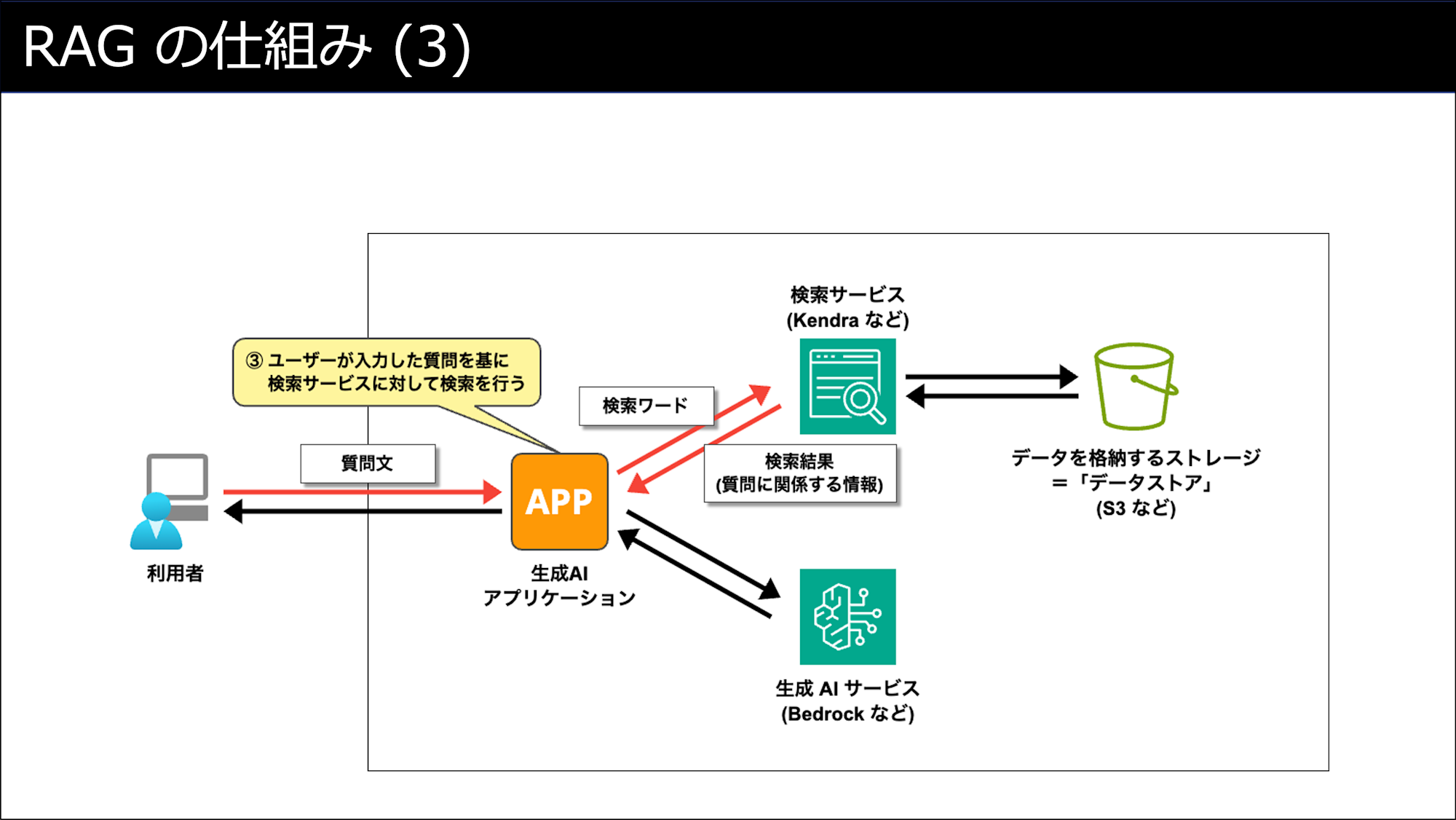
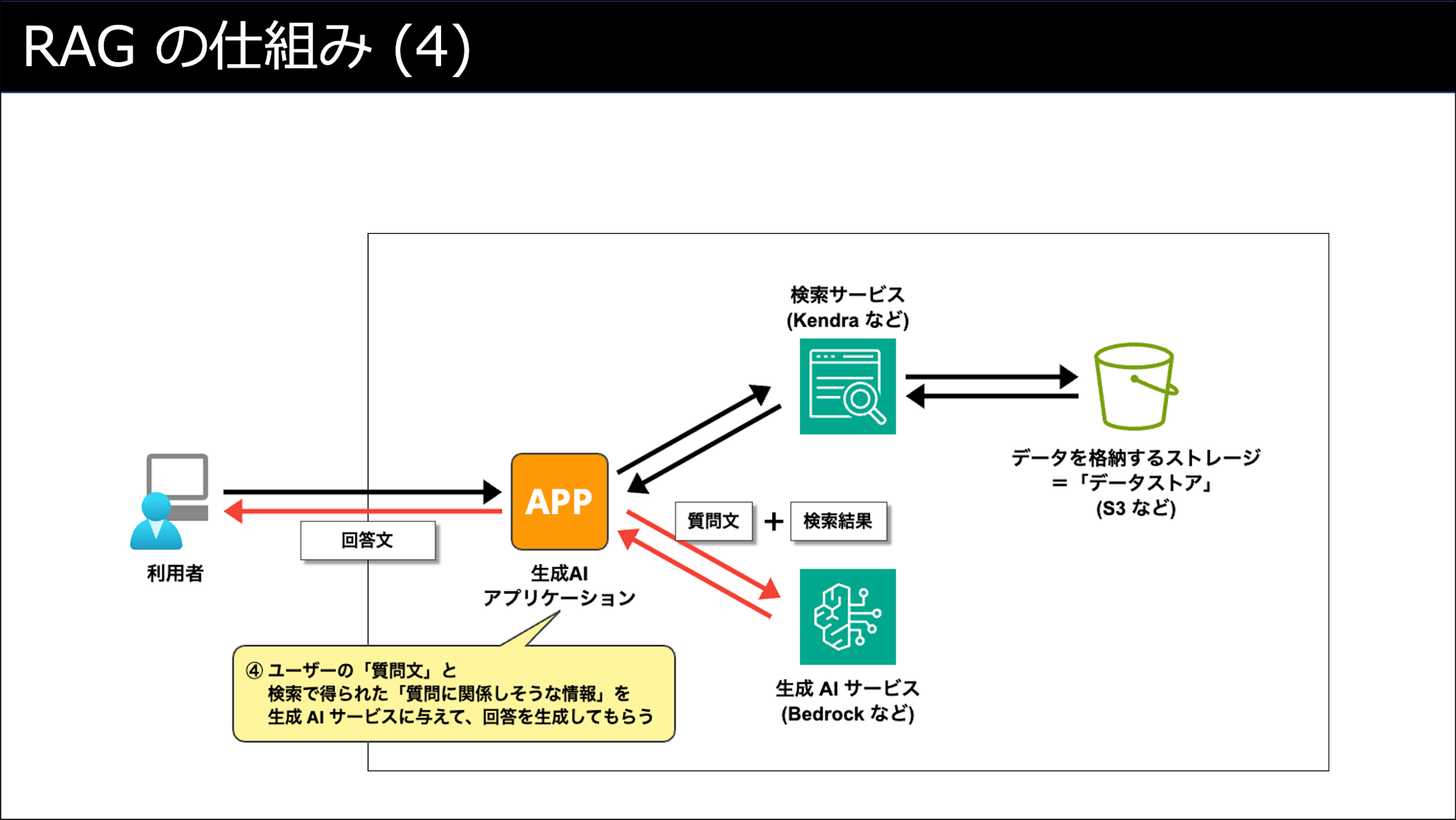
RAGで使われる検索技術
- 「ベクトル検索」
- 一般的に使われる検索方式=「キーワード検索 (文字列比較)」のデメリットを改善する検索方式
- 検索対象テキストや検索キーワードを「ベクトルデータ」(=多次元の数値情報) に変換して比較することで検索を行う
- 「チャンキング」
- 何百ページもあるドキュメント全体を検索対象とすると、必要な情報をピンポイントで検索できない
- → 大きなドキュメントを検索に適した単位の情報=「チャンク」に分割する
これらの技術は奥が深く全てを理解するのは難しいですが、RAGを扱う上で頻発する用語ですので、キーワードだけでも覚えておくと良いと思います。
RAGの「回答精度」を改善する
「社内のFAQを集めたExcelファイルを使ってRAGチャットボットを作る」場合を例にします。
作成したRAGチャットボットに質問したところ、間違った回答を返してきました。(正しくは「経理部」)
- 質問「出張費を精算する時、どこに申請すればよいですか?」
- 回答「情報システム部に申請してください」
正しい回答を返してくれるようにするために「原因」を分析します。
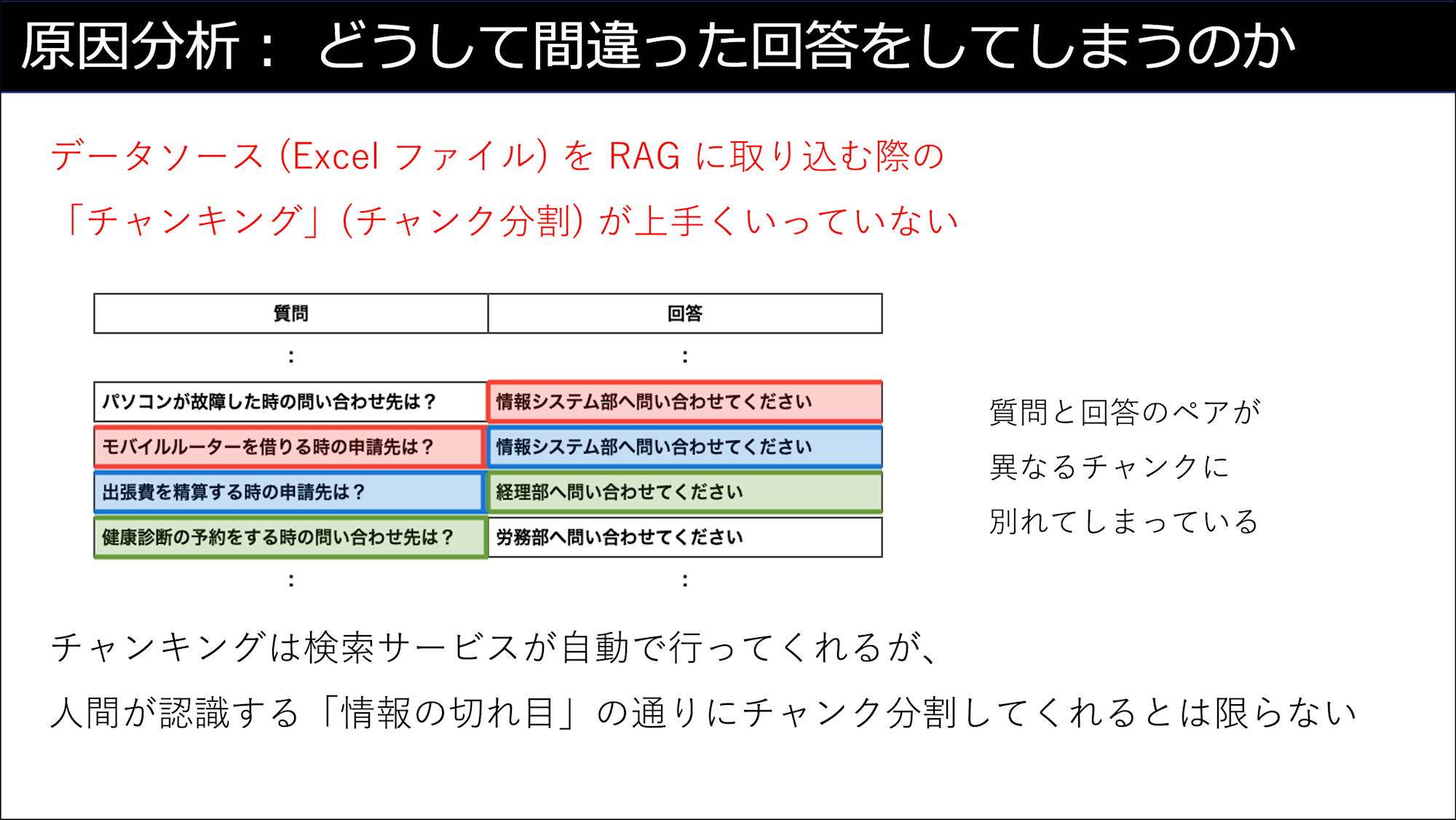
前の節で説明した「チャンキング」(チャンク分割) に原因がありました。
この場合の改善策は、各チャンクが理想の形になるように「事前にドキュメント (Excelファイル) を分割しておく」という対応になります。(いわゆる「ドキュメントの前処理」)

おわりに
勉強会の後の「懇親会」で、参加者の方から「登壇内容を社内の勉強会で使いたい!」とのありがたい声を頂きました。
もちろんOKです! どんどんお使いください!
みなさんの「RAGを理解する第一歩」の手助けとなれば幸いです。
JAWS-UGでは熊本を始め九州各県 (主に北の方) で勉強会・イベントを開催しています。
今回のレポートで興味を持った方は、ぜひ、お近くのJAWS-UG支部のイベントをチェックしてみてください。








