![[Amazon Athena]S3バケットとDynamoDBに保管されたデータのJOIN処理をAthenaでやってみた](https://devio2023-media.developers.io/wp-content/uploads/2019/04/amazon-athena.png)
[Amazon Athena]S3バケットとDynamoDBに保管されたデータのJOIN処理をAthenaでやってみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部の若槻です。
今回は、S3バケットとDynamoDBに保管されたデータのJOIN処理をAthenaでやってみました。
やりたいこと
下記のようなS3バケットに収集されたIoTデバイスデータと、DynamoDBテーブルで定義されたデバイスマスターデータを、Amazon Athenaで内部結合(INNER JOIN)してみます。
- IoTデバイスデータ(S3バケット)
| device_id | timestamp | state |
|---|---|---|
| device1 | 1609348014 | true |
| device2 | 1609348014 | false |
| device3 | 1609348014 | true |
| device3 | 1609348014 | false |
| device4 | 1609348014 | false |
- デバイスマスターデータ(DynamoDBテーブル)
| deviceId | deviceName |
|---|---|
| device1 | デバイス1 |
| device2 | デバイス2 |
| device3 | デバイス3 |
- JOIN後のデータ
| device_id | device_name | timestamp | state |
|---|---|---|---|
| device1 | デバイス1 | 1609348014 | true |
| device2 | デバイス2 | 1609348014 | false |
| device3 | デバイス3 | 1609348014 | true |
| device3 | デバイス3 | 1609348014 | false |
やってみた
環境作成
CloudFormationスタック
CloudFormationスタックのテンプレートです。
AWSTemplateFormatVersion: '2010-09-09'
Resources:
DeviceMasterDynamoDBTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: device_master
BillingMode: PAY_PER_REQUEST
AttributeDefinitions:
-
AttributeName: deviceId
AttributeType: S
KeySchema:
-
AttributeName: deviceId
KeyType: HASH
DevicesRawDataBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub devices-raw-data-${AWS::AccountId}-${AWS::Region}
DevicesDataAnalyticsBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub devices-data-analytics-${AWS::AccountId}-${AWS::Region}
DevicesDataAnalyticsGlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: devices_data_analystics
DevicesRawDataGlueTable:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName: !Ref DevicesDataAnalyticsGlueDatabase
TableInput:
Name: devices_raw_data
TableType: EXTERNAL_TABLE
Parameters:
has_encrypted_data: false
serialization.encoding: utf-8
EXTERNAL: true
StorageDescriptor:
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Columns:
- Name: device_id
Type: string
- Name: timestamp
Type: bigint
- Name: state
Type: boolean
InputFormat: org.apache.hadoop.mapred.TextInputFormat
Location: !Sub s3://${DevicesRawDataBucket}/raw-data
SerdeInfo:
Parameters:
paths: "device_id, timestamp, state"
SerializationLibrary: org.apache.hive.hcatalog.data.JsonSerDe
DeviceMasterDynamoDBTableがデバイスマスターデータとなるDynamoDBテーブル、DevicesRawDataBucketがIoTデバイスデータが格納されるS3バケットのリソース定義となります。
スタックをデプロイします。
% aws cloudformation deploy \
--template-file template.yaml \
--stack-name devices-data-analytics-stack \
--capabilities CAPABILITY_NAMED_IAM \
--no-fail-on-empty-changeset
Engine Version 2のAthena WorkGroupの作成
Athenaでのクエリ実行時に、Engine Version 2のAthena WorkGroupを使用する必要がありますが、Engine Version 2の場合はマネジメントコンソールからのみ作成可能です。下記を参考に作成します。
DynamoDBへのデータソース接続の作成
下記を参考にAthenaからDynamoDBへFederated Queryにより接続可能となるデータソース接続を作成します。
JOIN元となるデータの投入
DynamoDBテーブルdevice_masterにデータを投入します。
{
"device_master": [
{
"PutRequest": {
"Item": {
"deviceId": {"S": "device1"},
"deviceName": {"S": "デバイス1"}
}
}
},
{
"PutRequest": {
"Item": {
"deviceId": {"S": "device2"},
"deviceName": {"S": "デバイス2"}
}
}
},
{
"PutRequest": {
"Item": {
"deviceId": {"S": "device3"},
"deviceName": {"S": "デバイス3"}
}
}
}
]
}
% aws dynamodb batch-write-item \
--request-items file://request-items.json
GlueテーブルのLocationとなるS3バケットのパスにデータとなるオブジェクトを作成します。
{"device_id": "device1", "timestamp": 1609348014, "state": true}
{"device_id": "device2", "timestamp": 1609348014, "state": false}
{"device_id": "device3", "timestamp": 1609348014, "state": true}
{"device_id": "device3", "timestamp": 1609348014, "state": false}
{"device_id": "device4", "timestamp": 1609348014, "state": false}
% AWS_REGION=ap-northeast-1
% ACCOUNT_ID=$(aws sts get-caller-identity | jq -r ".Account")
% RAW_DATA_BUCKET=s3://devices-raw-data-${ACCOUNT_ID}-${AWS_REGION}
% GLUE_DATABASE_NAME=devices_data_analystics
% RAW_DATA_GLUE_TABLE_NAME=devices_raw_data
% aws s3 cp raw-data.json \
${RAW_DATA_BUCKET}/raw-data/raw-data.json
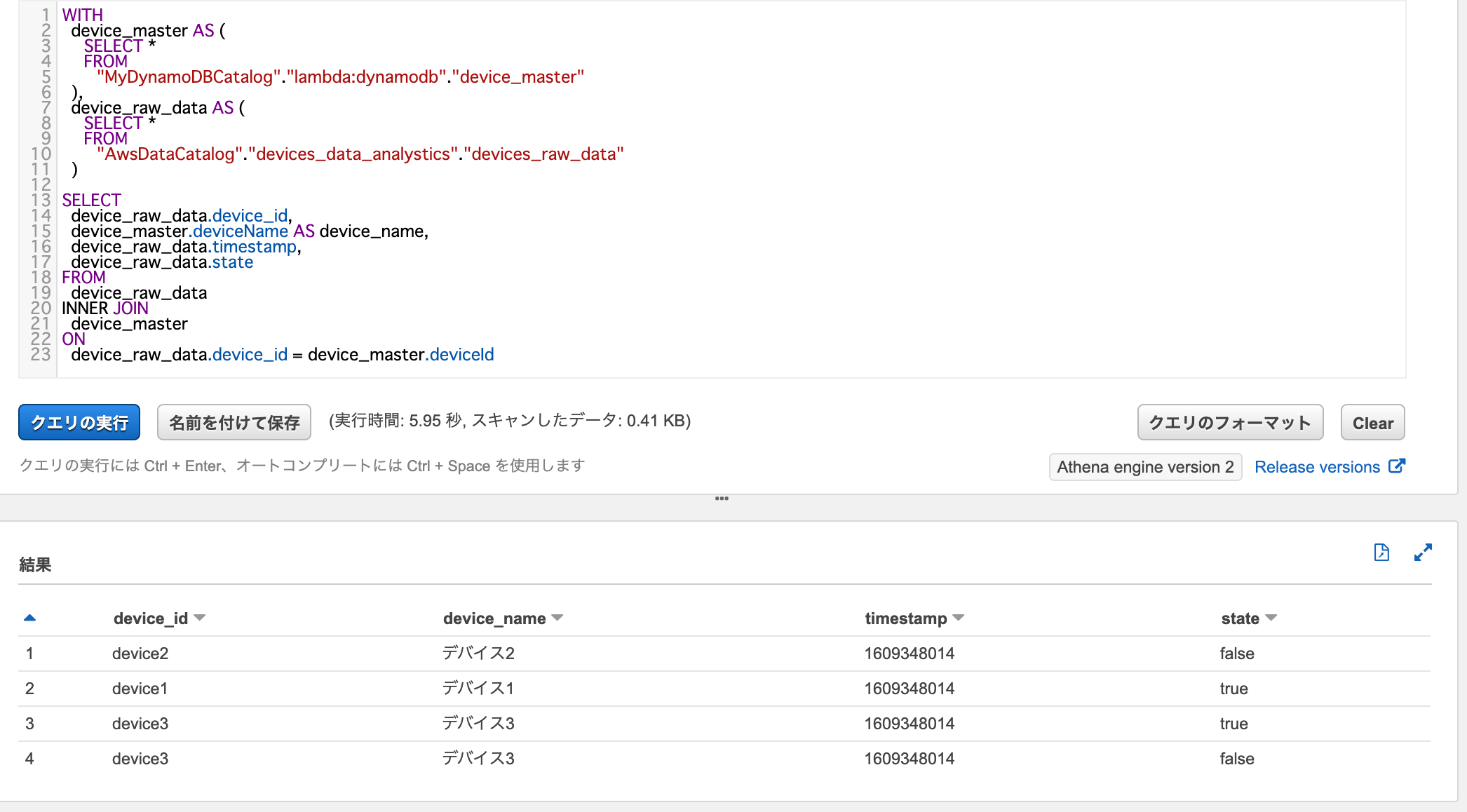
データをJOINしてみる
Athenaのマネジメントコンソールから、Engine Version 2のWorkGroupを使用して以下のクエリを実行します。
WITH
device_master AS (
SELECT *
FROM
"MyDynamoDBCatalog"."lambda:dynamodb"."device_master"
),
device_raw_data AS (
SELECT *
FROM
"AwsDataCatalog"."devices_data_analystics"."devices_raw_data"
)
SELECT
device_raw_data.device_id,
device_master.deviceName AS device_name,
device_raw_data.timestamp,
device_raw_data.state
FROM
device_raw_data
INNER JOIN
device_master
ON
device_raw_data.device_id = device_master.deviceId
JOIN後のデータが取得できていますね。
おわりに
S3バケットとDynamoDBに保管されたデータのJOIN処理をAthenaでやってみました。
異なるデータソースからのデータ取得、かつ一方がFederated Queryという条件でしたので同じクエリ内でのデータ取得ができるか分からなかったのですが、今回できることが確認できて良かったです。
これで後はJOIN後のデータをCTASやINSERT INTOを組み合わせて別のテーブルに吐き出すようにすれば、コストの高いGlueジョブを使わなくてもAthenaだけで実装できるETL処理の幅がグンと広がりますね。
参考
- AWS::DynamoDB::Table - AWS CloudFormation
- AWS::Athena::WorkGroup - AWS CloudFormation
- Amazon AthenaでいろいろなSELECTを実行してみる | Developers.IO
- batch-write-item — AWS CLI 1.18.223 Command Reference
- Using CTAS and INSERT INTO for ETL and Data Analysis - Amazon Athena
- Amazon AthenaでいろいろなSELECTを実行してみる | Developers.IO
- SELECT - Amazon Athena
- 【INNER JOIN, LEFT JOIN , RIGHT JOIN】テーブル結合の挙動をまとめてみた【SQL】 - Qiita
- Athenaで億単位のレコード数のテーブル同士をJOINしてみる - Qiita
- SQL素人でも分かるテーブル結合(inner joinとouter join)
- 【Athena】With句を使って一時テーブルを作成してSQLを簡略化させる - Qiita
以上










