
「失敗の積み重ね」がLLMを生んだ(後編)— Attentionからスケール革命、そして整列へ
はじめに
この記事は 前編 の続きです。
前編では、チューリングマシンからシャノンの情報理論、パーセプトロンとバックプロパゲーション、GPUによる訓練の高速化と勾配消失の克服、そしてWord2Vec/Embeddingによる「単語を意味のあるベクトルに変換する」技術までを辿りました。
後編では、文脈をどう扱うか という問いから出発し、RNNの構造的限界、Attentionの誕生、Transformerへの進化、GPT-3のスケール革命、そしてRLHFによる整列と効率化の現在まで——LLMが「設計されずに」完成していく後半の物語を追います。
第5章 ー 文脈をどう扱うか? — Attentionの誕生
注記: この章で登場するLSTM(1997年)やRNN自体の研究は、時系列としてはAlexNet(2012年)やWord2Vec(2013年)より前に始まっています。しかし「なぜ順序のあるデータが難しいのか」を理解するには、第3章(ニューラルネットワークの訓練と深さの壁)と第4章(単語をベクトルに変換する方法)の知識が前提になるため、この順番で扱っています。
なぜ機械翻訳が主戦場だったのか
2010年代前半、NLP(自然言語処理)の研究者たちがもっとも力を注いでいた応用分野は機械翻訳でした。
理由は単純です。翻訳は「言語を本当に理解しているか」を最も厳しくテストするタスクだからです。単語を一つずつ置き換えるだけでは翻訳できません。語順が変わり、文法が変わり、文化的なニュアンスが変わる。文全体の意味を理解し、別の言語で再構成する必要がある。
英語: The cat sat on the mat.
日本語: 猫がマットの上に座った。
単語の置き換えだけ: The=その cat=猫 sat=座った on=の上に the=その mat=マット
→ 「その猫座ったの上にそのマット」 ← 意味不明
正しい翻訳には語順の再構成、助詞の追加、冠詞の削除が必要
→ 文全体の意味の理解が前提
だから「機械がどこまで言語を扱えるか」の限界は、翻訳で最も早く露呈しました。そしてそのボトルネックを解消するために生まれた技術が、後にLLM全体の基盤になります。
翻訳モデルのボトルネック:RNNの構造的限界 (2014年頃)
当時の翻訳モデルは RNN(Recurrent Neural Network・再帰型ニューラルネットワーク) を使っていました。RNNは文脈を扱うための、当時の最善手です。
RNNは新しい発明ではなく、これまで見てきた部品の組み合わせです。内部のニューロン・重み・層・バックプロパゲーションは第3章と同じ。入力として受け取るのは第4章のEmbeddingベクトル。RNNの唯一の新しいアイデアを理解するには、まず通常のニューラルネットワークの限界を知る必要があります。
ここまでニューラルネットワークが成功してきたのは、画像のような一度に全体を入力できるデータでした。AlexNetが猫の写真を分類するとき、100万個のピクセルは同時に入力層に入ります。「まず左上のピクセルを見て、次に右隣のピクセルを見て…」と順番に処理するわけではありません。全体が一発で入力されるから、「前を覚えておく」必要がそもそもない。
しかし言語は本質的に順番に並んだデータです。「猫がマットの上に座った」の意味は、単語の順序に依存します。「マットが猫の上に座った」は同じ単語でも全く違う意味です。そして文の後半を理解するには、前半で何が言われたかを覚えている必要がある。
画像: [100万ピクセル全部] → 同時に入力 → 「猫の写真」
順序なし。記憶不要。
言語: 「猫」→「が」→「マット」→「の上に」→「座った」
順序あり。「座った」を理解するには「猫が」を覚えている必要あり。
この問題を身近な例えで言うと、講義を聞きながらノートを取る状況に似ています。
- 通常のネットワーク = 講義を聞くが、ノートを取らない。1文聞くたびに忘れる。今聞いた文にしか反応できない。
- RNN(これから説明します)= 1ページだけのメモ帳にノートを取りながら講義を聞く。メモ帳がいっぱいになると、古いメモを上書きして新しい内容を書く。講義が終わったとき、手元にはその1ページだけが残る。
この例えを頭に入れて、技術的な仕組みを見ていきましょう。
では、通常のニューラルネットワークで文を処理しようとするとどうなるでしょうか。
通常のネットワークで文を処理しようとすると(ノートを取らない):
「猫」→ [入力層]→[隠れ層]→[出力層] → 結果1 ← 処理完了、ネットワークはリセット
「が」→ [入力層]→[隠れ層]→[出力層] → 結果2 ← 「猫」の痕跡はゼロ
「マット」→ [入力層]→[隠れ層]→[出力層] → 結果3 ← 「猫が」の痕跡もゼロ
「各層は前の層の出力を受け取るのだから、情報は引き継がれるのでは?」と思うかもしれません。しかしそれは1つの入力が複数の層を通る流れ(空間的な流れ)の話です。「猫」が入力層→隠れ層→出力層と流れるのは、1つの単語が深い層へ進む過程。
問題は時間的な流れです。「猫」の処理が終わって「が」の処理が始まるとき、ネットワークは完全にリセットされます。隠れ層に「猫」の痕跡は一切残っていません。だから「座った」を処理するとき、「何が座ったのか(猫が)」を知る手段がない。
空間的な流れ(1つの入力が複数の層を通る)← これは通常ネットワークでもある
「猫」→ [Layer 1] → [Layer 2] → [Layer 3] → 出力
時間的な流れ(複数の入力が順番に処理される)← これが通常ネットワークにない
時点1: 「猫」→ 処理 → 完了 → リセット
時点2: 「が」→ 処理 → 完了 → リセット ← 「猫」を覚えていない
時点3: 「マット」→ 処理 → 完了 → リセット ← 「猫が」を覚えていない
RNNの解決策:同じ層が記憶を持ち越す
RNNのアイデアは、同じ層が異なる時点のトークンを順番に処理し、その際に内部の状態(メモ帳)を次の時点に引き継ぐことです。
これまでの部品がどう組み合わさるか:
第3章の部品: ニューロン、重み、層、バックプロパゲーション
↓(RNNの内部構造として使われる)
第4章の部品: Embedding(単語→ベクトル変換)
↓(RNNへの入力として使われる)
第5章の新要素: 同じ層が、時点をまたいでメモ帳を引き継ぐ
↓
= RNN(順序のあるデータを処理できるニューラルネットワーク)
この「メモ帳」を、専門用語では 隠れ状態(hidden state) と呼びます。第3章で「隠れ層(hidden layer)」を覚えているでしょうか——入力層と出力層の間にある、ユーザーからは見えない内部の作業スペースでした。RNNの「隠れ状態」も同じ「隠れ」です。入力(今読んでいる単語)にも出力(翻訳結果)にも直接現れない、ネットワーク内部の中間データだから「隠れ」と呼ばれます。
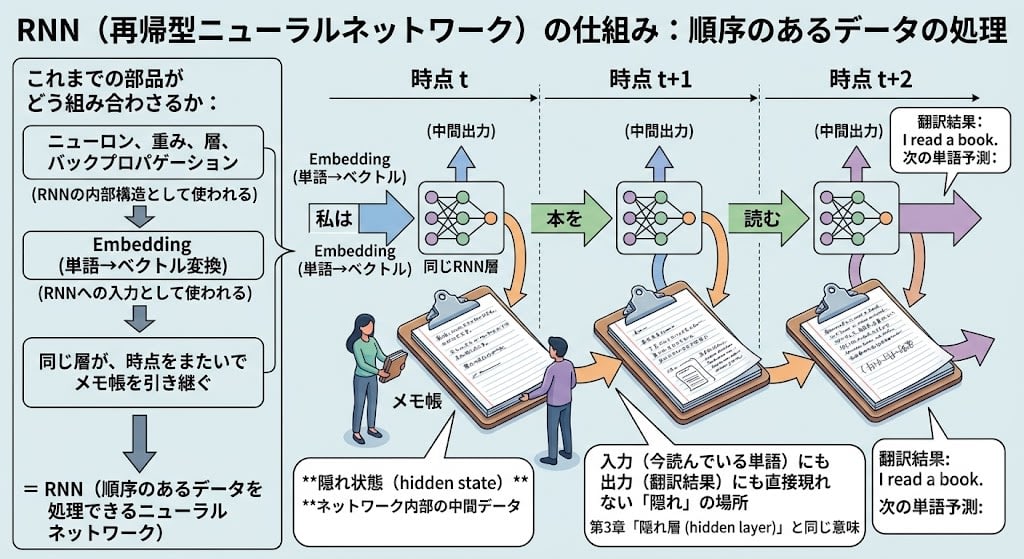
ポイントは、RNNでは同じ隠れ層が繰り返し(Recurrent=再帰的に)使われることです。異なる層のリレーではなく、1つの層が時点ごとに繰り返し動き、メモ帳を引き継ぐことで「前に何を読んだか」を覚えていられます。
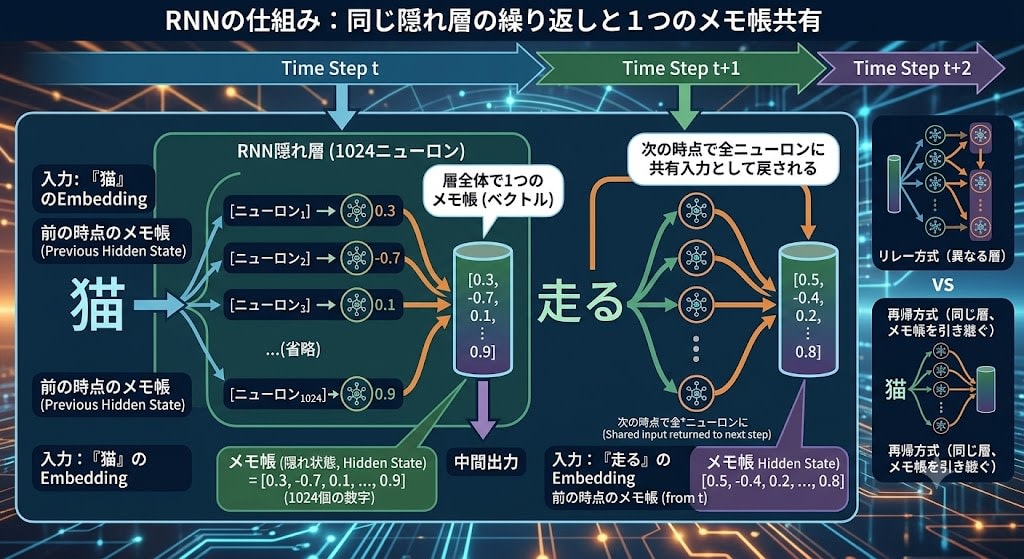
そしてメモ帳はニューロンごとに個別に持つものではなく、層全体で1つです。隠れ層に1024個のニューロンがあるなら、各ニューロンが1つの数字を出力し、それら1024個の数字をまとめたベクトルが「メモ帳」になります。次の時点では、この1024個の数字が層全体に共有入力として戻されます。
隠れ層(1024ニューロン)の1つの時点:
入力: 「猫」のEmbedding + 前の時点のメモ帳
↓
[ニューロン₁] → 0.3 ─┐
[ニューロン₂] → -0.7 ─┤
[ニューロン₃] → 0.1 ─┼→ メモ帳 = [0.3, -0.7, 0.1, ..., 0.9](1024個の数字)
... │
[ニューロン₁₀₂₄] → 0.9 ┘
↓
このメモ帳が次の時点で全ニューロンに共有される
Reactを知っている読者なら、RNNの隠れ状態は
useRefに近いと考えるとわかりやすいかもしれません。ref.currentはレンダリングをまたいで値を保持し、更新してもre-renderをトリガーしない——つまりReactのシステムからは「見えない(hidden)」内部状態です。RNNのメモ帳も同じで、各時点(トークン処理)をまたいでref.currentが上書き更新されていき、常に最新の状態だけを保持します。古い値は上書きされて消える。const memo = useRef(new Float32Array(1024)); function processToken(embedding) { memo.current = computeNewState(embedding, memo.current); // 古いmemo.currentは上書きされて消える } processToken(embed("猫")); // memo.current = [猫の情報] processToken(embed("が")); // memo.current = [猫が…の情報] processToken(embed("座った")); // memo.current = [猫が…座った の情報]
各ステップでRNNが使えるのは2つだけ——「今読んでいるEmbeddingベクトル」と「前のステップから渡されたメモ帳」。前の単語に戻って読み返すことはできません。読み終わった情報は、メモ帳の中にしか存在しない。講義の例えで言えば、1ページのメモ帳に書き続けていて、講義を巻き戻すことはできない状態です。
直感的には、各ニューロンが自分専用のメモ帳を持つ方が自然に思えます。しかしRNNのメモ帳が層全体で共有される理由は、各ニューロンの出力が他のニューロンの文脈になるからです。
「猫が座った」を処理するとき、あるニューロンが「主語は猫だ」という情報を検出し、別のニューロンが「動詞は過去形だ」を検出したとします。次のトークンを処理する際、「過去形の動詞の主語は猫」という複合的な理解が必要です。これは1つのニューロンだけでは持てない——複数のニューロンの出力を組み合わせて初めて成立する情報です。
メモ帳を全ニューロンの出力をまとめたベクトル(1024個の数字)として共有し、次の時点で全ニューロンに入力することで、各ニューロンは他のニューロンが前の時点で何を検出したかを参照できます。ニューロンごとに独立したメモ帳では、この「横の情報共有」ができません。
ニューロンはメモ帳をどう使うのか
各ニューロンは各時点で、「今のトークンのEmbedding」と「前の時点のメモ帳」を連結した1つのベクトルを入力として受け取り、第3章と同じ掛け算と足し算を行います。ニューロン自体は「どこまでがトークンでどこからがメモ帳か」を知りません。しかし訓練を通じて、トークン用の重みとメモ帳用の重みが異なる役割を学習します。例えば「現在のトークンが動詞なら、メモ帳の中で主語に相当する情報を重視する」というようなパターンが、重みの値として自然に現れます。
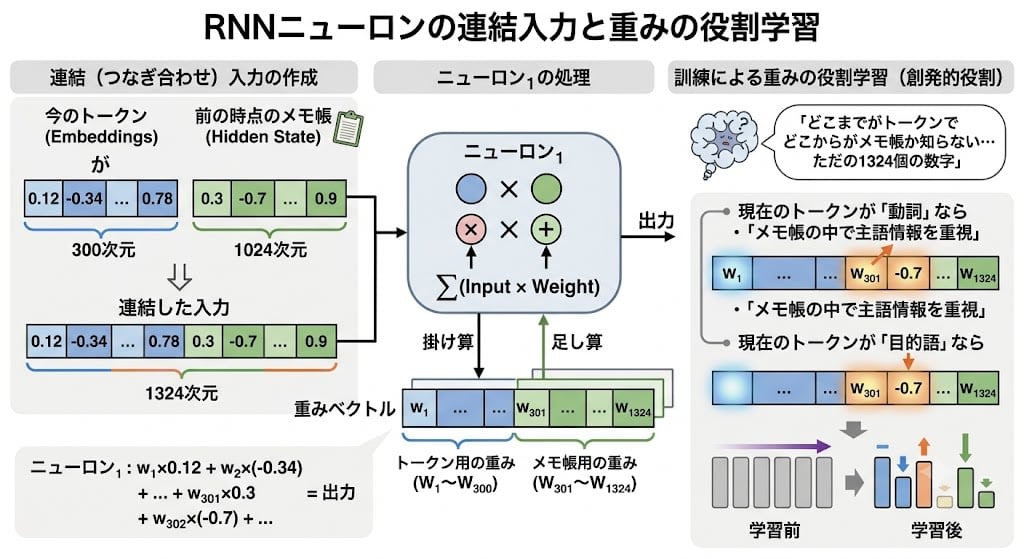
各ニューロンがどんなパターンを学ぶかは事前に決まっていません。訓練の過程で、各ニューロンが「次のトークンの予測に役立つ何らかのパターン」を自分で見つけます。そのパターンは人間には解釈できない抽象的なものかもしれません。これがニューラルネットワークが「ブラックボックス」と呼ばれる理由の一つです。
RNNの本当のボトルネック:スナップショットには問い合わせできない
メモ帳のサイズ(1024個の数字)は設計者が訓練前に決めるパラメータです。512でも2048でもかまいませんが、一度決めたら変わらない——これはニューロンの層が固定数の入力を期待するためです(第3章の構造を思い出してください)。
「サイズが固定だから長い文で情報が溢れる」——一見これが問題に見えます。しかし本当の問題はサイズではなく、データ構造です。
メモ帳は**データベースのスナップショット(ダンプ)**に似ています。ダンプファイルには過去のすべてのトランザクションの累積結果が反映されていますが、特定のINSERT文を復元することはできません。サイズを10倍にしても1000倍にしても、この性質は変わらない。
RNNのメモ帳も同じです。すべての過去のトークンが現在の状態に貢献していますが、個々のトークンの情報を個別に取り出せないという構造的制約は、メモ帳をどれだけ大きくしても変わりません。
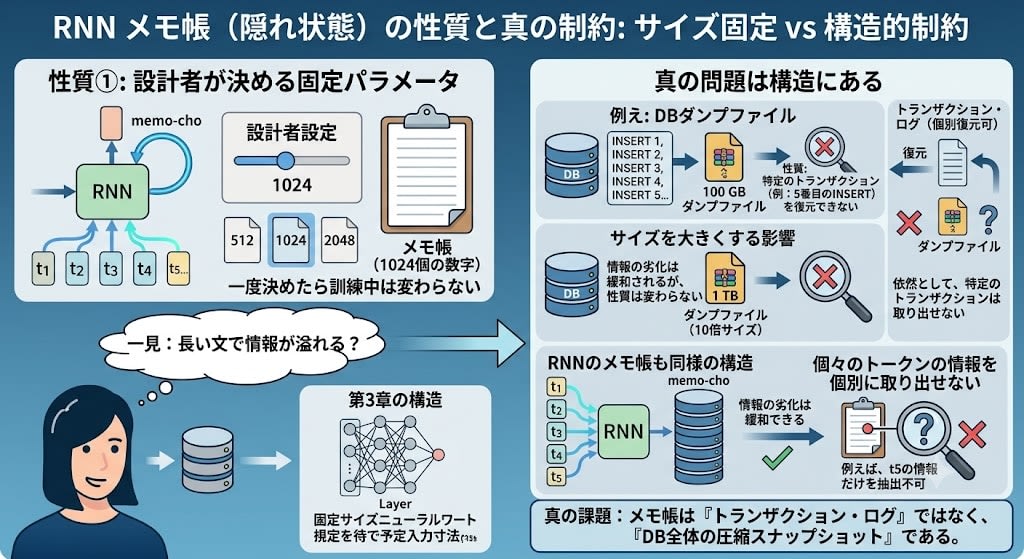
翻訳モデルでは、入力文を全部読み終わってから出力文を生成し始めます。
入力文 → [RNN: 1単語ずつ読んでメモ帳を更新] → 最終メモ帳(スナップショット)→ [出力RNN] → 翻訳文
出力RNNが翻訳文を生成するとき、手元にあるのは最終スナップショットだけです。例えば「彼女は市場に行った。そこで彼女は友人の彼女に会った」を翻訳するとき——出力RNNが3番目の「彼女」を訳すには、それが「友人の恋人」であることを確認するために入力文の対応する箇所を参照したい。しかし個々のトークンはスナップショットに溶け込んでいる。ピンポイントで取り出す手段がありません。
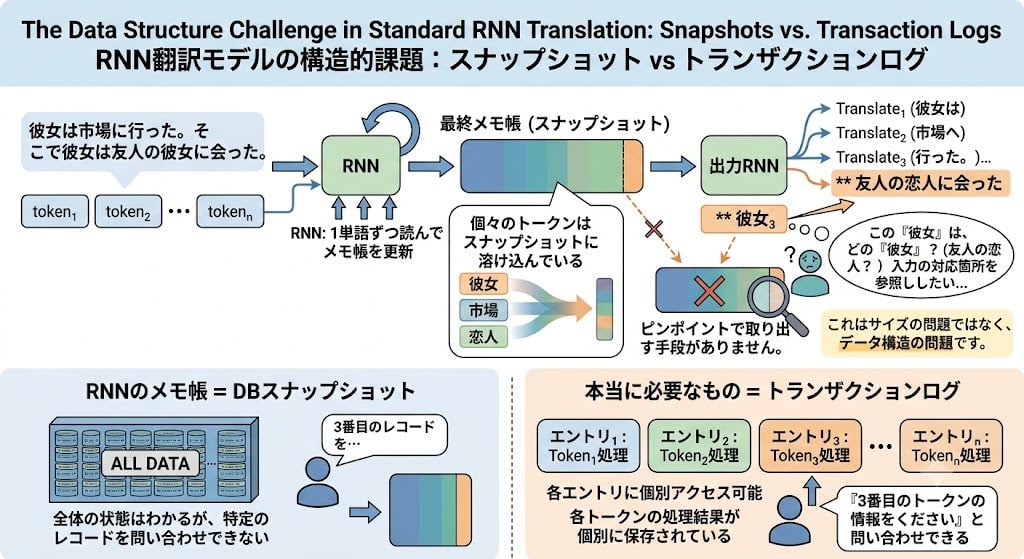
本当に必要なのは、スナップショットではなくトランザクションログ——各トークンの処理結果が個別に保存され、問い合わせできるデータ構造です。この転換が、後で登場するAttentionの核心になります。
第3章のデジャヴ:勾配消失、再び
RNNの問題は情報の溢れだけではありません。学習そのものにも壁がありました。
第3章で、バックプロパゲーション(誤差逆伝播)の仕組みを見ました。出力を正解と比較し、誤差信号を逆方向に伝えて各層の重みを調整する——「どの重みがどれだけ間違いに貢献したか」を追跡する「blame(責任追及)」の仕組みです。
RNNでも同じ仕組みが使われます。しかし第3章では誤差信号が層をまたいで逆方向に流れたのに対し、RNNでは時点をまたいで逆方向に流れます。
例えば50番目のトークンで予測を間違えたとき、「1番目のトークンの処理の仕方が悪かったのが原因」かもしれません。しかし誤差信号はメモ帳の連鎖を49回遡る必要があり、各ステップで信号が縮小される。結果、初期のトークンに対するフィードバックがゼロに近くなり、重みが調整されない——つまりネットワークは「文の冒頭をうまく処理する方法」を学習できません。
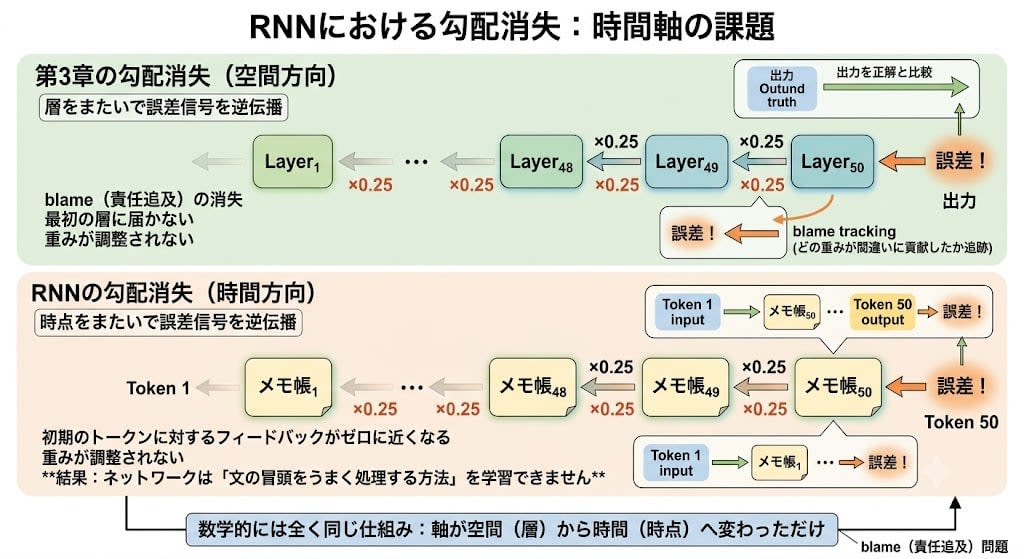
数学は全く同じです。第3章では深い層を通るたびに信号が消えた。RNNでは長い時間を遡るたびに信号が消える。軸が空間から時間に変わっただけで、同じ問題が再び現れたのです。
LSTM:時間方向のResNet (1997年発明、2014年〜翻訳の主力に)
第3章では、層方向の勾配消失を ResNet(残差接続) が解決しました。入力をショートカットで出力に加算し、勾配が直接流れる「高速道路」を作る仕組みです。
では時間方向の勾配消失には? 実は、ResNet(2015年)より18年も前の1997年に、同じ発想の解決策が提案されていました。ホッホライターとシュミットフーバーによる**LSTM(Long Short-Term Memory・長短期記憶)**です。長年ニッチな存在でしたが、2014年頃に深層学習ブームとGPUの普及が重なり、機械翻訳の主力アーキテクチャとして花開きました。
LSTMの核心は、通常のメモ帳に加えてセル状態(cell state)というもう1つの記憶を持つことです。このセル状態は、時点間でほぼそのまま素通りする高速道路です。
LSTMにはさらにゲートという仕組みがあります。「忘却ゲート」「入力ゲート」「出力ゲート」の3つが、セル状態に対して「何を忘れるか」「何を書き込むか」「何を読み出すか」を制御します。これにより、重要な情報を長期間保持しつつ、不要な情報を捨てることができます。
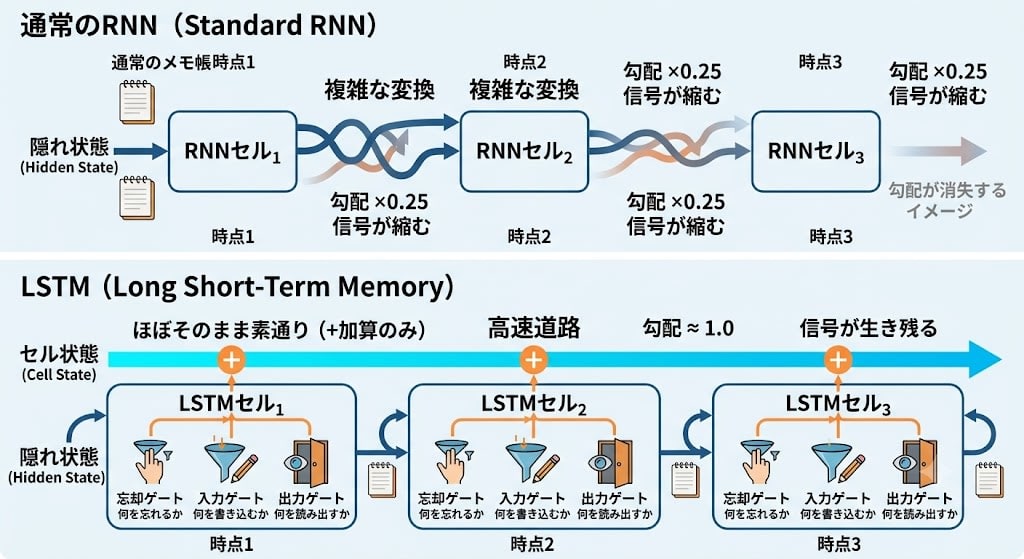
LSTMはRNNの記憶問題を大幅に改善し、2014年〜2017年頃の機械翻訳で主力として使われました。しかし根本的な制約は残っていました——逐次処理です。トークン1を処理してからトークン2、トークン2を処理してからトークン3。どんなにメモリが改善されても、GPUの並列計算を活かせない。
バグへのパッチ:Attention(注意機構)
バダナウらの解決策は、先ほどの「スナップショットからトランザクションログへ」の転換そのものでした。
ステップ1:スナップショットをトランザクションログにする
RNNは入力を処理するとき、各ステップでメモ帳(スナップショット)を更新します。従来はこの最終スナップショットだけを出力RNNに渡していました。バダナウらのアイデアは、各ステップのスナップショットを全部、独立したコピーとして保存しておくことでした。
重要なのは、保存されるのは差分(デルタ)ではなく、各時点の完全なスナップショットです。5トークンを処理したら、1024個の数字が5セット——合計5120個の数字が保存されます。
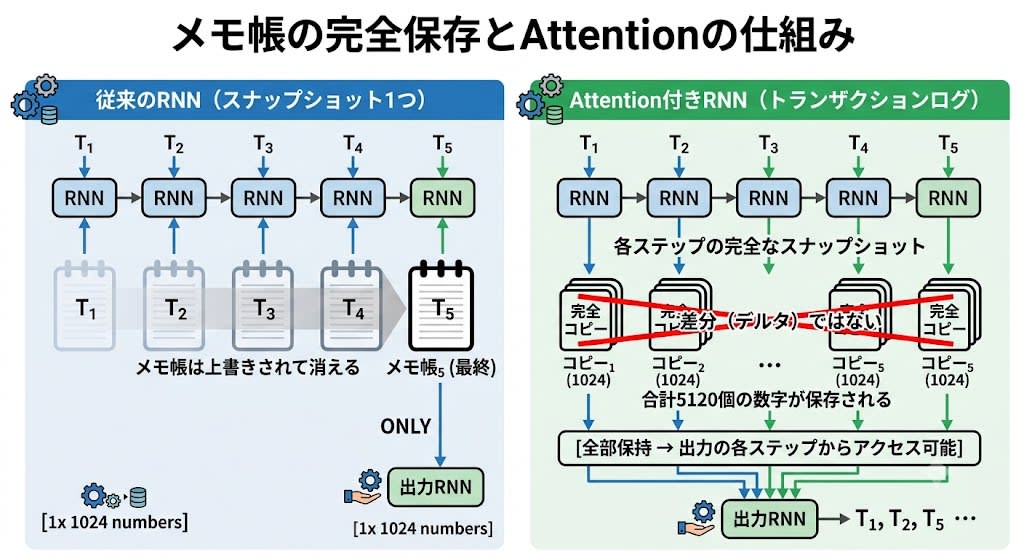
React的に言えば、Attentionは
ref.currentを上書きする前にhistory.push([...memo.current])でスプレッドコピーを保存しておくようなものです。出力時にはhistory[i]で任意の時点の状態にアクセスできます。
講義の例えに戻ると、Attentionは講義を録音することに相当します。ノート(最終メモ帳)だけに頼るのではなく、講義の各時点の録音が残っている。
しかし録音があるだけでは不十分です。2時間の講義の録音を毎回全部聴き直すわけにはいきません。「今、どの部分を聴き直すべきか」を判断する仕組みが必要です。これがAttentionの核心部分です。
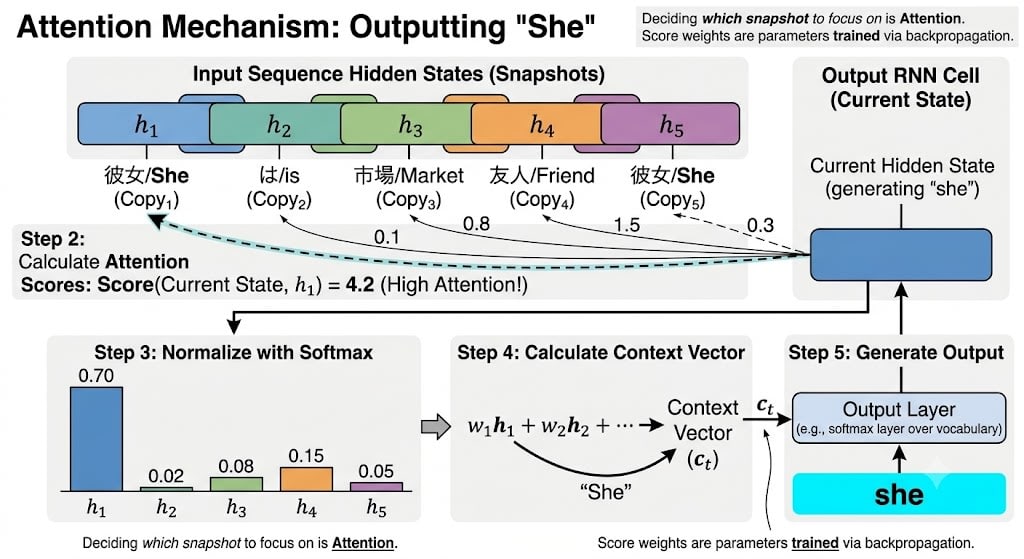
ステップ2:どのスナップショットに注目するかを学習する
出力RNNが翻訳の各単語を生成するとき、以下のプロセスが走ります:
- 出力RNNの現在の状態(「今、何を訳そうとしているか」)を取る
- 保存された全スナップショットそれぞれとの関連度スコアを計算する
- スコアをsoftmaxで正規化して、合計が1.0になる重みに変換する
- 重みに応じてスナップショットの加重平均を取り、文脈ベクトルを作る
- この文脈ベクトルを使って出力単語を生成する
この「どのスナップショットにどれだけ注目するか」を決める重み——これが **Attention(注意)**の 名前の由来です。人間が文章を読むとき、すべての単語に均等に注意を払うのではなく、今の文脈に関連する部分に注意を集中させます。Attentionメカニズムはまさにこれを数値的に再現しています。
そしてスコア計算に使われる重みも、バックプロパゲーションで訓練されるパラメータです。「動詞を訳すときは主語のスナップショットに高いスコアをつける」というようなパターンを、データから自動的に学びます。
Attentionは勾配消失も改善する
Attentionのもう一つの重要な効果があります。出力から各スナップショットへの直接的な接続が、勾配にとってのショートカットになるのです。
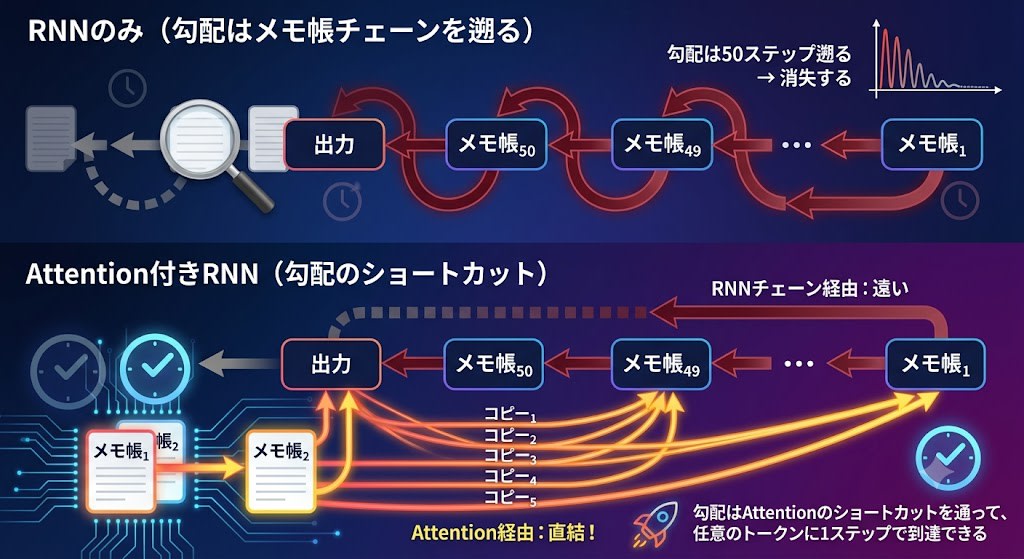
勾配はAttentionの直結路を通って任意のトークンに1ステップで到達できるため、RNNチェーンを遡る必要がなくなり、勾配消失が大幅に緩和されます。
これはグランドビジョンではありませんでした。翻訳の長文精度が落ちるというバグへの、工学的なパッチです。しかし結果として、スナップショットの制約(特定のトークンに問い合わせできない)を解決し、さらに勾配消失まで改善しました。
パッチがアーキテクチャになった:Transformer (2017)
バスワニらが立てた問い:「そもそもRNN(逐次処理の仕組み)は必要か? Attentionだけで翻訳できるのでは?」
ここまでの改善を振り返ると、Attention+RNNでもRNN部分の制約は残っていました——スナップショットの生成が逐次処理です。
Attention+RNNでは、参照(読み返し)は並列化できますが、スナップショットの生成は依然としてRNNが担当しています。各スナップショットは前のスナップショットに依存するため、順番にしか作れません。
Attention + RNN: 参照は改善されたが、スナップショット生成は逐次のまま
snapshot₁ = f("猫", 空) ← まずこれを計算
snapshot₂ = f("が", snapshot₁) ← snapshot₁が完成しないと計算できない
snapshot₃ = f("マット", snapshot₂) ← snapshot₂が完成しないと計算できない
各snapshotが前のsnapshotに依存 → チェーン → 並列化不可能
バスワニらの洞察は、このチェーン(メモ帳の連鎖)そのものを捨てることでした。
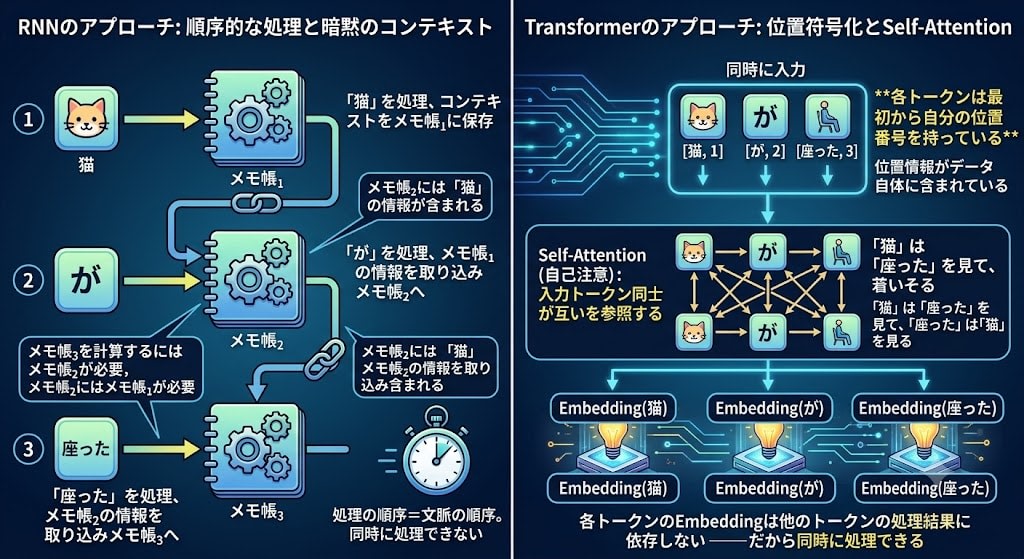
RNNなしでどう文脈を理解するか
RNNでは、トークンの順序はメモ帳の連鎖によって暗黙的に表現されていました。「猫」を処理してから「が」を処理するからこそ、「が」の時点のメモ帳に「猫」の情報が含まれる。処理の順序=文脈の順序。
Transformerは全く別のアプローチを取ります。各トークンは最初から自分の位置番号を持っている。
位置情報がデータ自体に含まれているので、全トークンを同時に処理しても順序が失われません。そして各トークンが他のすべてのトークンを参照する——これがTransformerの Self-Attention(自己注意) です。
先ほどのAttentionでは「出力RNNが入力のスナップショットを参照する」仕組みでした。Self-Attentionでは、入力トークン同士が互いを参照する。「猫」は「座った」を見て、「座った」は「猫」を見る——すべて同時に。
RNNでは「メモ帳₃を計算するにはメモ帳₂が必要、メモ帳₂にはメモ帳₁が必要」という依存チェーンがありました。Transformerにはこのチェーンがありません。各トークンのEmbeddingは他のトークンの処理結果に依存しない——だから同時に処理できるのです。
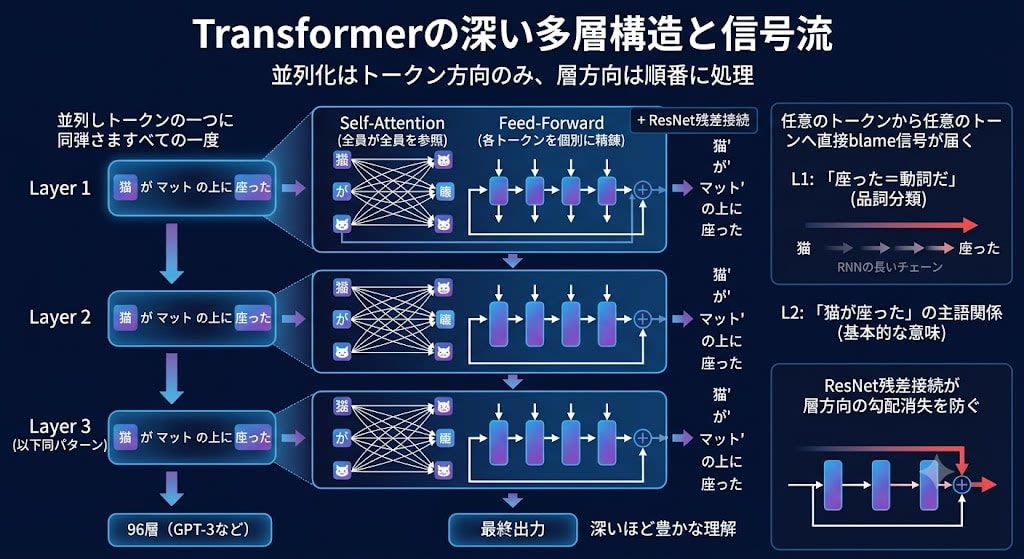
「全トークンを同時に処理」と聞くと、ネットワークが「平ら」になったように聞こえるかもしれません。しかし Transformerは依然として深い多層構造 です。GPT-3は96層あります。
並列化されたのはトークン方向だけです。層方向は依然として順番に処理します。
各層が表現を精錬していきます。Layer 1は「座った=動詞だ」を学び、Layer 2は「猫が座ったの主語だ」を学び、さらに深い層は複雑な意味関係を学ぶ。深いほど豊かな理解——第3章と同じ原理です。
バックプロパゲーション(blame)も第3章と同じ仕組みで層を逆方向に流れます。加えて、Self-Attentionの接続を通じて、任意のトークンから任意のトークンへ直接blame信号が届く——RNNのような長いチェーンを遡る必要がないので、勾配消失が大幅に緩和されます。そしてResNet残差接続が、層方向の勾配消失を防ぎます。
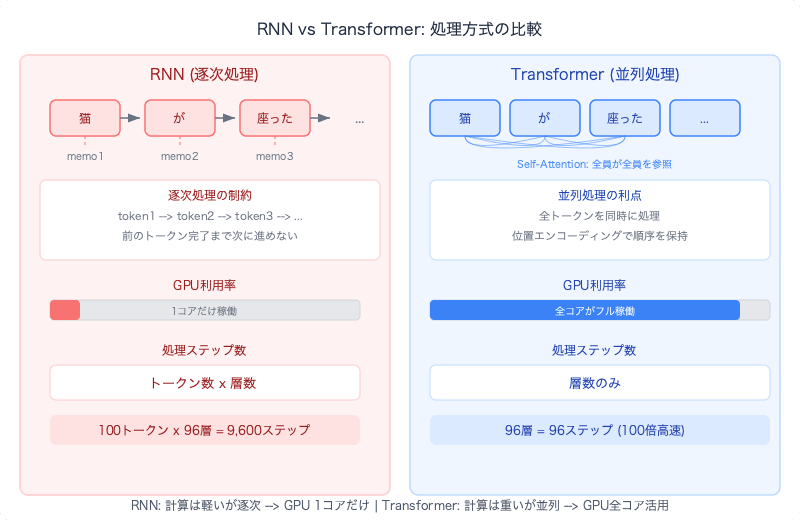
処理時間:なぜTransformerが速いのか
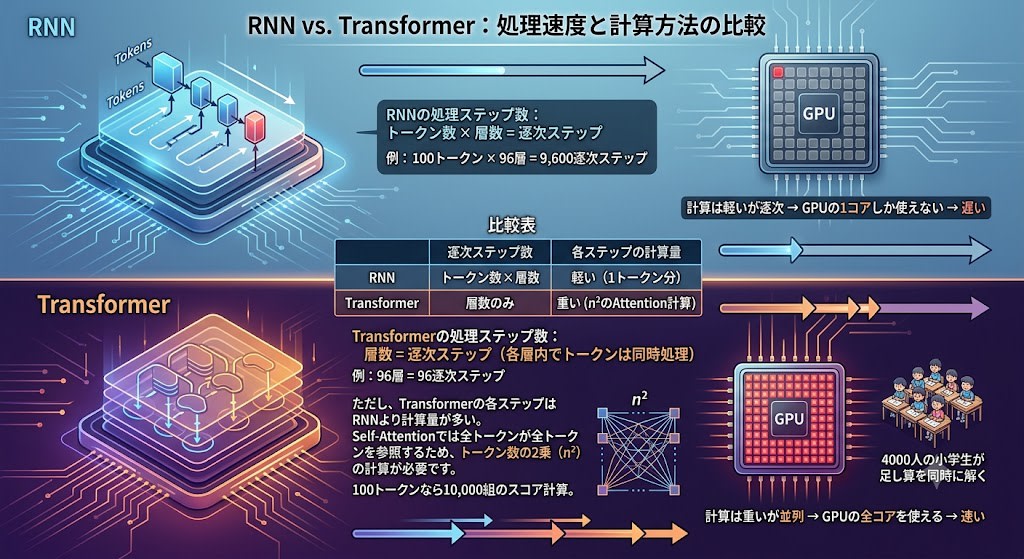
RNNとTransformerの処理時間を比較すると:
RNNの処理ステップ数:
トークン数 × 層数 = 逐次ステップ
例: 100トークン × 96層 = 9,600逐次ステップ
Transformerの処理ステップ数:
層数 = 逐次ステップ(各層内でトークンは同時処理)
例: 96層 = 96逐次ステップ
ただし、Transformerの各ステップはRNNより計算量が多い。Self-Attentionでは全トークンが全トークンを参照するため、トークン数の2乗(n²)の計算が必要です。100トークンなら10,000組のスコア計算。
| 逐次ステップ数 | 各ステップの計算量 | |
|---|---|---|
| RNN | トークン数 × 層数 | 軽い(1トークン分) |
| Transformer | 層数のみ | 重い(n²のAttention計算) |
合計の計算量はTransformerの方が多いこともあります。しかし重い計算はGPUで並列化できる。これは第3章のAlexNetと同じ構造です——4000人の小学生が足し算を同時に解く。n²のスコア計算は互いに独立しているため、GPUの数千コアで同時に実行できます。
一方、RNNの逐次ステップはどんなに高性能なGPUがあっても並列化できません。前のステップが完了しないと次に進めないからです。
結果として、Transformerはこの章で見てきた問題をすべて同時に解決しました:
| RNN | LSTM | Attention+RNN | Transformer | |
|---|---|---|---|---|
| スナップショット問題 | ✗ | ✗ | ✓ (ログ化) | ✓ |
| 勾配消失(時間方向) | ✗ | ✓ (高速道路) | ✓ (ショートカット) | ✓ (直結) |
| 並列処理 | ✗ | ✗ | ✗ (RNN部分が残る) | ✓ |
RNNを捨ててAttentionだけにした結果、訓練が劇的に速くなりました。速くなるということは、より大きいモデルをより多くのデータで訓練できるということです。
翻訳の速度改善を目的としたアーキテクチャが、スケールを可能にすることでLLM全体の基盤になりました。
第6章 ー 大きくすれば賢くなるか? — スケールと創発
スケール則の発見 (2020)
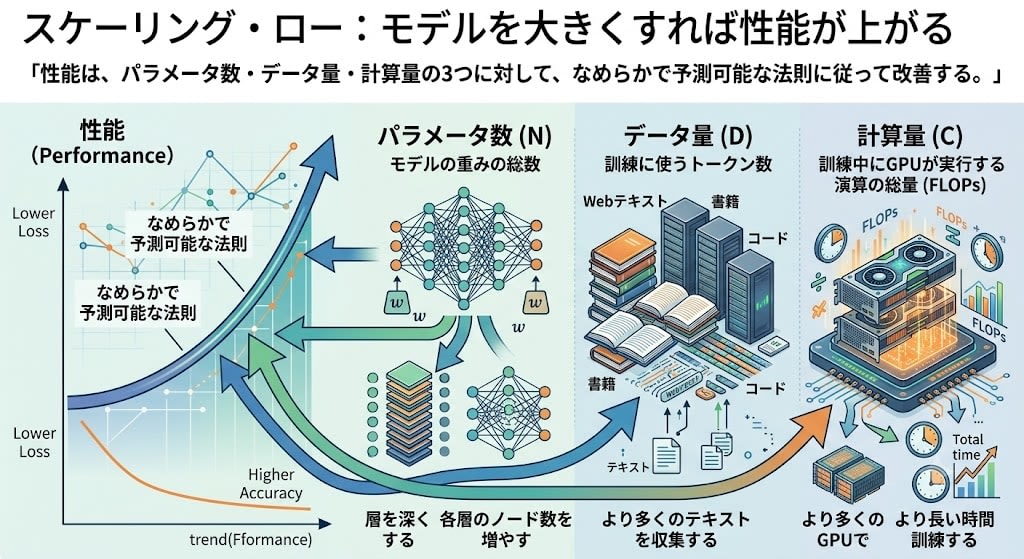
「モデルを大きくすれば性能が上がる」は経験則として知られていました。OpenAIのカプランらが、これを数式で示しました:
性能は、パラメータ数・データ量・計算量の3つに対して、なめらかで予測可能な法則に従って改善する。
3つの変数を具体的に見てみましょう:
| 変数 | 意味 | 増やす方法 |
|---|---|---|
| パラメータ数 (N) | モデルの重みの総数 | 層を深くする、各層のノード数を増やす |
| データ量 (D) | 訓練に使うトークン数 | より多くのテキストを収集する(Web、書籍、コードなど) |
| 計算量 (C) | 訓練中にGPUが実行する演算の総量(FLOPs) | より多くのGPUで、より長い時間訓練する |
パラメータ数とデータ量は直感的ですが、計算量は少し説明が必要です。
計算量とは、訓練中にGPUが実行する浮動小数点演算(FLOP: Floating Point Operation)の総数です。モデルが1つのバッチを処理するたびに、順伝播と逆伝播で大量の行列演算が走ります。その演算の累計が計算量です。
カプランらは、この3つの関係を近似式で示しました:
つまり計算量はパラメータ数とデータ量の積にほぼ比例します。計算量は独立した第3の変数というより、投入できる総予算です。予算が決まれば、モデルをどこまで大きくし、データをどれだけ食わせるかが決まります。
計算量を増やす方法はシンプルです——GPUの数 × 訓練時間。GPT-3の訓練には約3.14×10²³ FLOPsが費やされました。これは数千基のGPUを数週間走らせた結果です。つまり計算量を増やすとは、端的に言えばお金と時間を投入するということです。
補足:Chinchilla則 (2022)
カプランのスケール則は「計算予算が増えたら、モデルを大きくする方に多く配分すべき」と示唆しました。しかし2022年、DeepMindのホフマンらは「データ量にもっと配分すべき」と修正しました(Chinchilla則)。同じ計算予算でも、配分の最適比率が異なるという発見です。両者が一致しているのは、計算量が根本的な制約資源であるという点です。
これは「地図」でした。「このサイズのモデルをこれだけのデータで訓練すれば、これくらいの性能になる」と事前に予測できる。結果が見えるなら、大規模投資の判断ができます。
Transformerから「GPT」へ——目的の転換
Transformerは翻訳のために生まれました。しかしGPT(Generative Pre-trained Transformer——生成型の事前学習済みTransformer)は、翻訳とは別の問題を解こうとしていました。
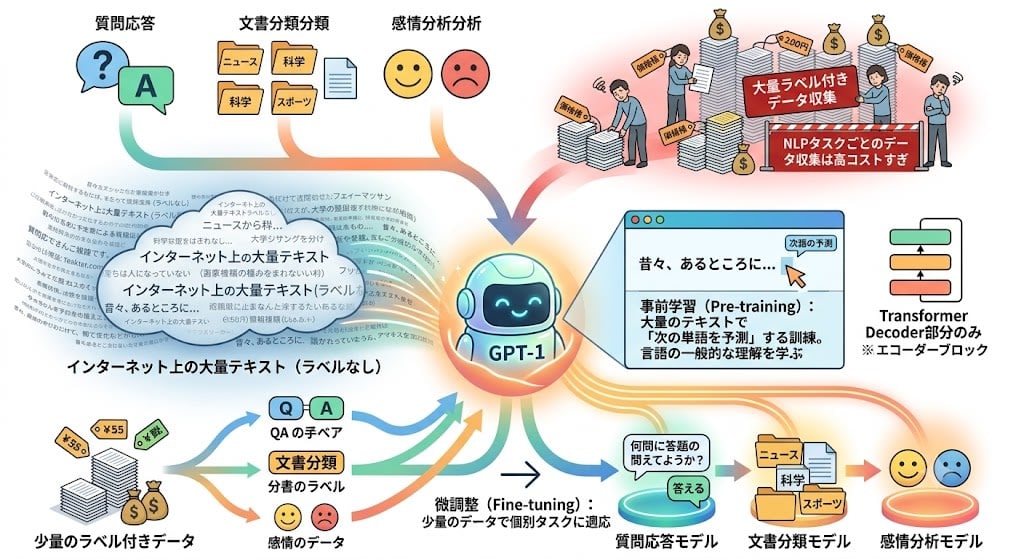
2018年、OpenAIのラドフォードらが直面していた問題はこうです:
NLPには多様なタスク(質問応答、文書分類、感情分析など)があるが、それぞれのタスクごとにラベル付きデータを大量に集めるのは高コストすぎる。
ラベルなしテキスト(インターネット上の文章)は大量にある。これを使って「言語の一般的な理解」を先に学び、少量のラベル付きデータで個別タスクに適応させれば良いのではないか?
これがGPT-1の核心アイデアです:
- 事前学習(Pre-training):大量のテキストで「次の単語を予測する」だけの訓練をする
- 微調整(Fine-tuning):個別タスク用の少量データで重みを調整する
アーキテクチャはTransformerのDecoder部分だけを使いました。翻訳のためのEncoder-Decoder構造は不要で、「テキストを読んで続きを予測する」というシンプルな構造で十分だったからです。
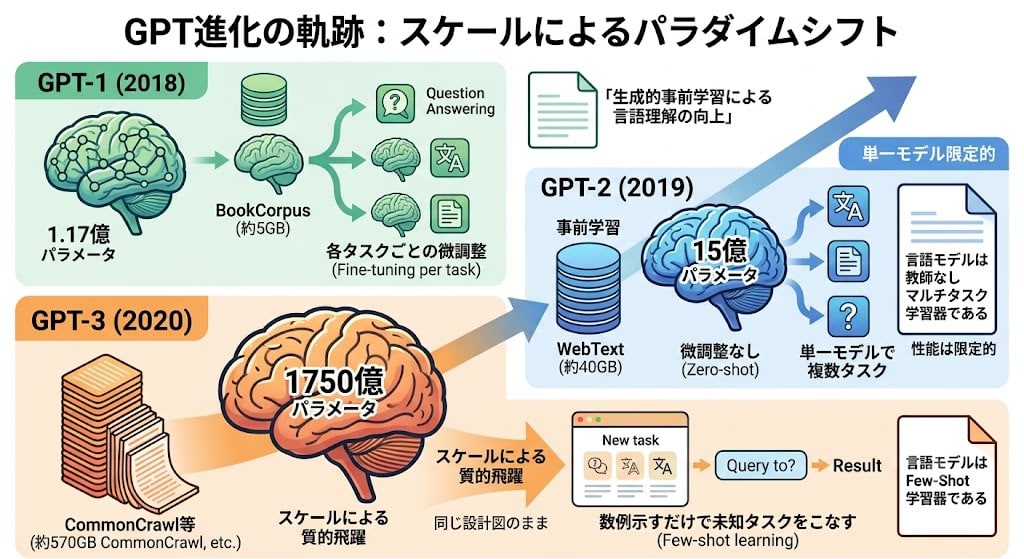
GPT-1 → GPT-2 → GPT-3:同じ設計図、異なるスケール
ここが重要です。GPT-1、GPT-2、GPT-3はアーキテクチャがほぼ同じです。 基本設計を変えず、スケールだけを変えて何が起きるかを観察した——これが3世代の本質です。
| GPT-1 (2018) | GPT-2 (2019) | GPT-3 (2020) | |
|---|---|---|---|
| パラメータ数 | 1.17億 | 15億 | 1750億 |
| 訓練データ | BookCorpus(約5GB) | WebText(約40GB) | CommonCrawl等(約570GB) |
| 核心の発見 | 事前学習 + 微調整が有効 | 微調整なしでもタスクが解ける(Zero-shot) | 数例示すだけで未知のタスクをこなす(Few-shot) |
| 論文タイトルが語る思想 | "Improving Language Understanding by Generative Pre-Training" | "Language Models are Unsupervised Multitask Learners" | "Language Models are Few-Shot Learners" |
GPT-1は「事前学習+微調整」の有効性を示しました。しかしタスクごとに微調整が必要でした。
GPT-2はモデルを13倍に大きくし、データも増やしました。すると、微調整なしでも一部のタスクをこなせるようになりました(Zero-shot)。論文タイトルの通り「言語モデルは教師なしのマルチタスク学習器である」という発見です。ただし性能はまだ限定的でした。
GPT-3はさらに117倍に大きくしました。アーキテクチャの変更はごくわずか(Sparse Attentionの部分導入程度)です。同じ設計図のまま、スケールだけで質的な飛躍が起きました。
ここで読者が抱きやすい疑問に答えます。
「Few-shotは訓練の一部なのか? それとも訓練の後に起きることなのか?」
答えは訓練の後です。Few-shotは推論時(ユーザーがモデルを使う時)のテクニックです。
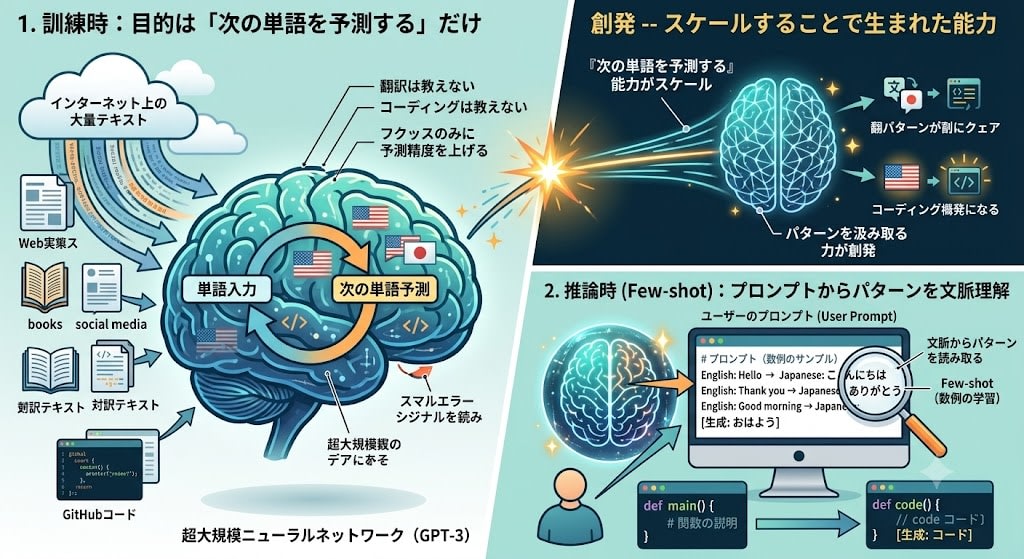
GPT-3の訓練プロセスを整理すると:
- 訓練時:インターネットから集めた大量のテキストで「次の単語を予測する」だけを学ぶ。翻訳を教えたわけでも、コーディングを教えたわけでもない。目的は一つだけ——次の単語の予測精度を上げる
- 推論時(Few-shot):ユーザーがプロンプトに数例のサンプルを示す。モデルはそのパターンを文脈から読み取り、同じパターンで続きを生成する
GPT-3は翻訳を明示的に訓練されていません。しかし訓練データに英日の対訳テキストが含まれていたため、「次の単語を予測する」能力がスケールすることで、パターンを汲み取って正しく続ける力が創発しました。
コード生成も同じです。GitHubのコードが訓練データに含まれていたので、「関数の説明 → コード」というパターンを数例示すだけで、見たことのない関数を書けるようになりました。
なぜGPT-3で「ビッグバン」が起きたのか?
GPT-2でもZero-shotは部分的に動いていました。では、GPT-3で何が変わったのか?
答えは閾値の突破です。
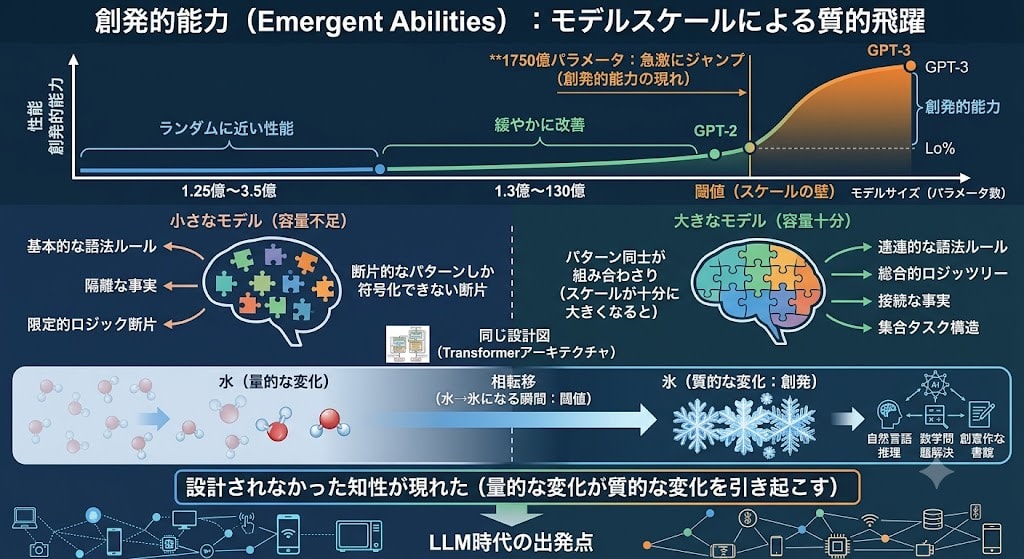
多くのタスクで、モデルサイズと性能の関係はこう推移しました:
- 1.25億~3.5億パラメータ:ランダムに近い性能
- 13億~130億パラメータ:緩やかに改善
- 1750億パラメータ:急激にジャンプ
これが**創発的能力(Emergent Abilities)**です。物理学の相転移(水が氷になる瞬間)のように、量的な変化がある閾値を超えると質的な変化を引き起こす。GPT-2はその閾値の手前にいて、GPT-3はその先にいました。
なぜ閾値が存在するのか? 訓練中、モデルは「次の単語を予測する」ために、テキストに含まれるあらゆるパターン(文法、論理、事実、タスク構造)を内部に符号化していきます。小さなモデルでは容量が足りず、個別パターンの断片しか学べない。しかしスケールが十分に大きくなると、パターン同士が組み合わさり、明示的に訓練していない能力として表面化する——これが創発の正体です。
GPT-3は新しいアーキテクチャで知性を設計したのではありません。同じ設計図を、閾値を超えるまでスケールさせた結果、設計されなかった知性が現れたのです。これが現在のLLM時代の出発点です。
第7章 ー 賢くなった後の課題 — 微調整から整列へ、そしてスケールの先
GPT-3は驚くほど多才でしたが、使いにくかった。人種差別的な文章を生成したり、質問に答える代わりに無関係な文章を続けたり、嘘を自信満々に語ったりしました。「次の単語を予測する」能力と「人間に役立つ回答をする」能力は、同じではなかったのです。
ここから先の歴史は、3つの段階に分けられます。
微調整(Fine-tuning)の仕組み
GPT-1で登場した微調整を、もう少し詳しく見てみましょう。
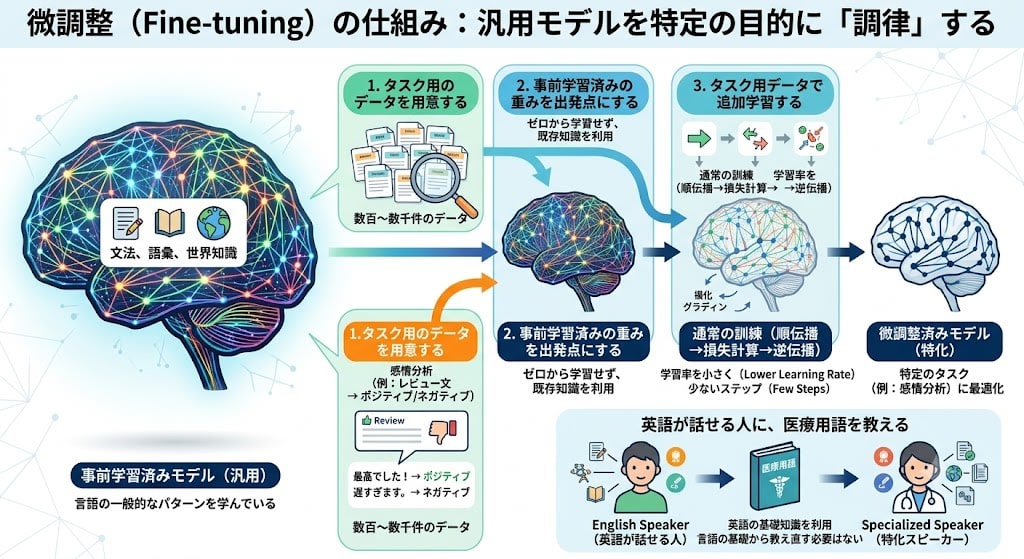
事前学習済みモデルは、言語の一般的なパターンを学んでいますが、特定のタスク(感情分析、質問応答など)に最適化されていません。微調整は、この汎用モデルを特定の目的に「調律」するプロセスです。
仕組みはシンプルです:
- タスク用のデータを用意する:例えば「レビュー文 → ポジティブ/ネガティブ」のペアを数百〜数千件
- 事前学習済みの重みを出発点にする:ゼロから学習するのではなく、すでに言語を理解している重みから始める
- タスク用データで追加学習する:通常の訓練と同じ仕組み(順伝播→損失計算→逆伝播)だが、学習率を小さくし、少ないステップで済ませる
なぜ少量のデータで効くのか? 事前学習で文法・語彙・世界知識をすでに獲得しているからです。微調整は「英語が話せる人に、医療用語を教える」ようなもので、言語の基礎から教え直す必要はありません。
InstructGPT:人間のフィードバックで「整列」させる (2022)
GPT-3の問題は「賢いが、人間の意図に沿わない」ことでした。OpenAIはこれを解決するために、微調整の概念を発展させた RLHF(Reinforcement Learning from Human Feedback——人間のフィードバックによる強化学習) を開発しました。
RLHFは3段階のパイプラインです:
第1段階:教師あり微調整(SFT)
人間のアノテーター(約40人)が、プロンプトに対する「理想的な回答」を手書きで約13,000件作成しました。これで通常の微調整を行い、「質問されたら回答する」という基本的な振る舞いを教えます。
第2段階:報酬モデルの訓練
同じプロンプトに対してモデルが複数の回答を生成し、人間がそれらを「どちらが良いか」でランク付けします。このランキングデータから、「良い回答とは何か」を数値化する 報酬モデル(Reward Model) を訓練します。
第3段階:強化学習による最適化
元のモデルが回答を生成し、報酬モデルがスコアをつけ、そのスコアを使って元のモデルの重みを更新します。「人間が好む回答」を生成する方向にモデルが調整されていきます。
結果は衝撃的でした。13億パラメータのInstructGPTが、1750億パラメータの素のGPT-3より人間に好まれる回答を生成したのです。パラメータ数で130倍小さいモデルが、「整列」するだけで逆転しました。
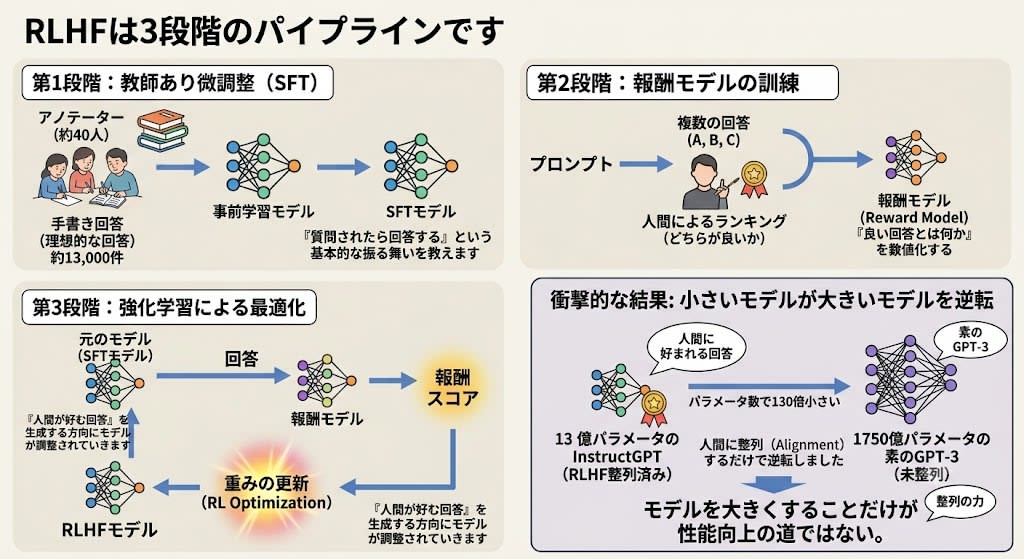
これは重要な教訓です:モデルを大きくすることだけが性能向上の道ではない。
微調整の現在地:いつ必要で、いつ不要か?
GPT-1の時代は、すべてのタスクに微調整が必須でした。GPT-3でFew-shotが使えるようになり、さらにInstructGPTでゼロショットでも指示に従えるようになった今、微調整の役割は変わりました。
| 微調整が不要なケース | 微調整が必要なケース | |
|---|---|---|
| 典型例 | メール作成、要約、一般的なQ&A | 医療診断支援、法律文書レビュー、社内用語の理解 |
| 理由 | 汎用モデルのプロンプトで十分な品質 | 専門用語・特定フォーマット・コンプライアンス要件が厳密 |
ラベル付きデータは依然として重要です——ただし用途が変わりました。GPT-1時代は「タスクを教える」ために必要でしたが、現在は主に「モデルの振る舞いを整列させる」ために必要です。RLHFの人間によるランキングデータがその典型です。
また、LoRA(Low-Rank Adaptation)やQLoRAといった パラメータ効率的微調整(PEFT) の登場により、全パラメータを更新せずとも、わずかなパラメータの追加だけで微調整できるようになりました。微調整のコストは2020年代前半と比べて90%以上削減されています。
スケールの先へ:LLMは今どう進化しているか?
「パラメータ・データ・計算量を増やせば賢くなる」——スケール則はGPT-3の成功を説明しました。しかし2024年頃から、この戦略は壁に直面しています。
壁1:データの枯渇
インターネット上の高品質なテキストデータは有限です。2026年現在、人間が書いた高品質テキストはほぼ使い尽くされたと言われています。
壁2:コストの限界
より大きなモデルの事前学習には数億ドル規模の投資が必要で、収穫逓減が見え始めています。
NeurIPS 2024で、OpenAI共同創設者のイリヤ・サツキヴァーはこう宣言しました:
「私たちが知っている形の事前学習は終わりを迎える。2010年代はスケールの時代だった。今は驚きと発見の時代に戻った。」
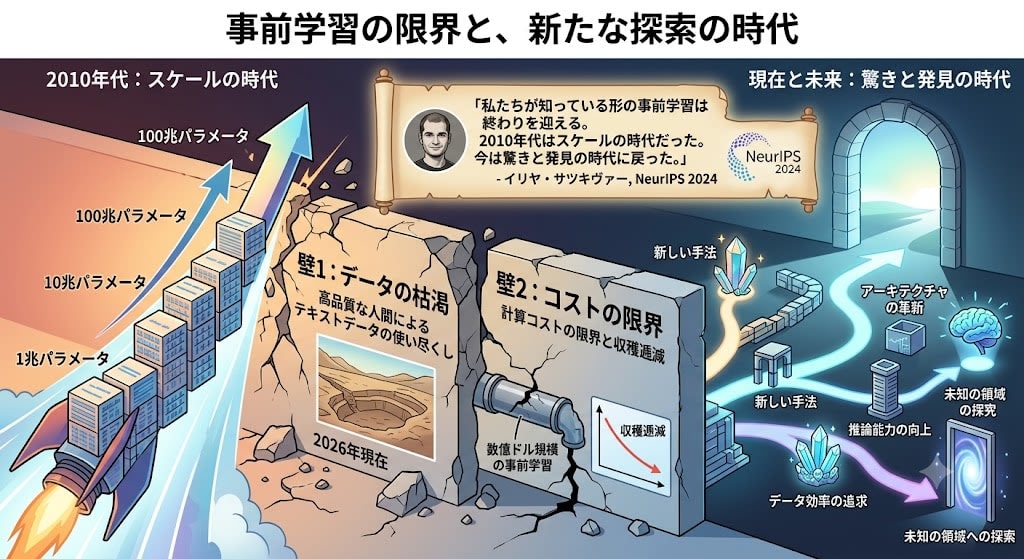
では、スケール以外にどんな進化の軸があるのか? 現在の主要なアプローチを整理します。
軸1:事後学習(Post-training)の深化
InstructGPTで始まったRLHFは、現在さらに洗練されています。事前学習(大量テキストで基礎能力を獲得)の後に行う追加学習——事後学習——が、モデルの能力を引き出す主戦場になりました。
- RLHF / RLAIF:人間またはAIのフィードバックで整列(Anthropic、OpenAIが継続的に改良)
- DPO(Direct Preference Optimization):報酬モデルを介さず、人間の好みデータから直接最適化する効率的な手法
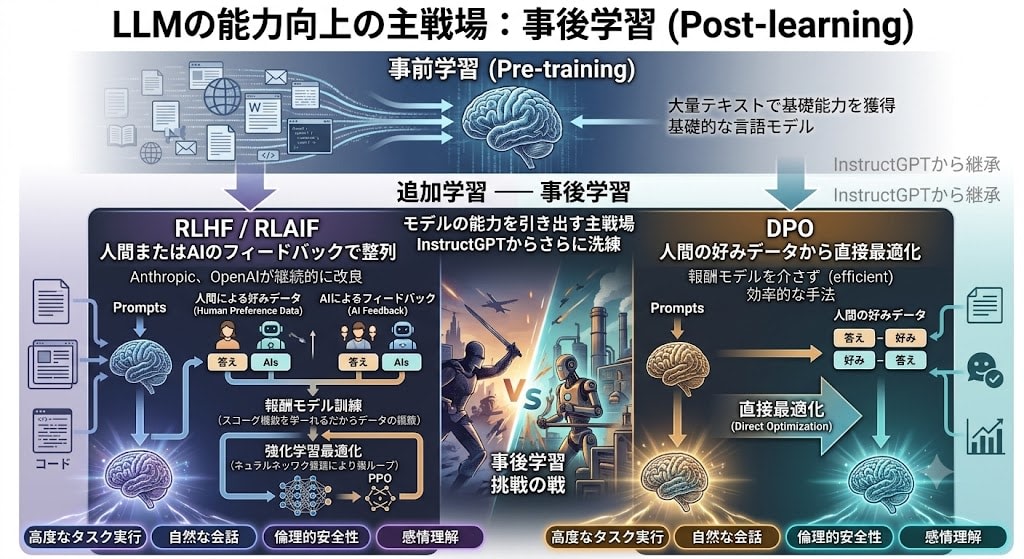
軸2:推論時計算(Test-time Compute)
訓練を大きくする代わりに、推論時にもっと考えさせるというアプローチです。
OpenAIのo1/o3シリーズやAnthropicのClaude(拡張思考モード)が代表例です。モデルが回答する前に「思考の連鎖(Chain of Thought)」を生成し、段階的に推論する。訓練時の計算量を増やす代わりに、推論時の計算量を増やすことで性能を上げます。
スケール則が「訓練にどれだけ計算を投入するか」の法則だったのに対し、これは「推論にどれだけ計算を投入するか」という新しい軸です。
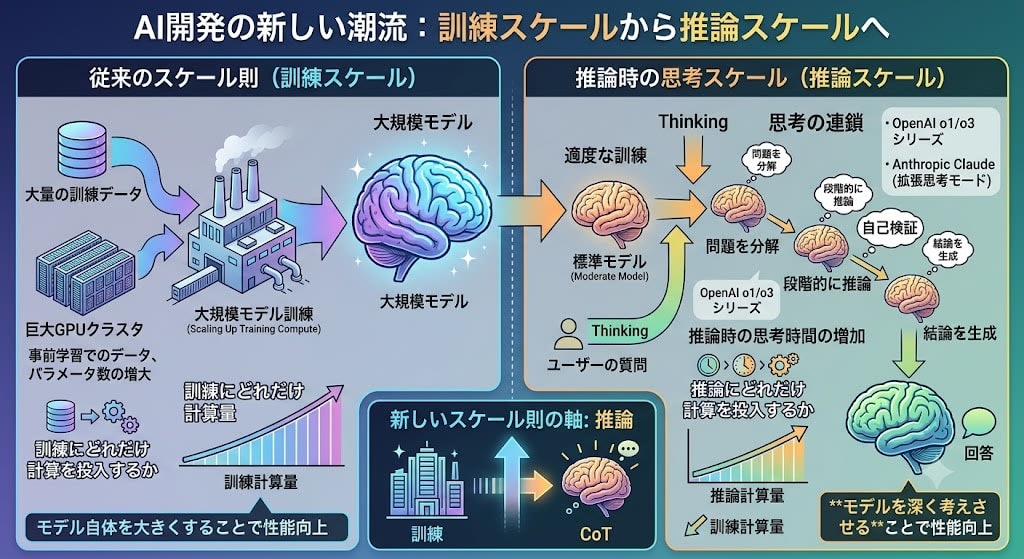
軸3:合成データと蒸留
人間のデータが枯渇するなら、AIにデータを作らせる。
- 蒸留(Distillation):大きなモデル(教師)が生成した回答で、小さなモデル(生徒)を訓練する。DeepSeek-R1の蒸留版やLlamaの派生モデルがこの手法で作られています
- Self-Play:モデルが自分自身と対話し、問題を出し合い、解き合うことで能力を向上させる
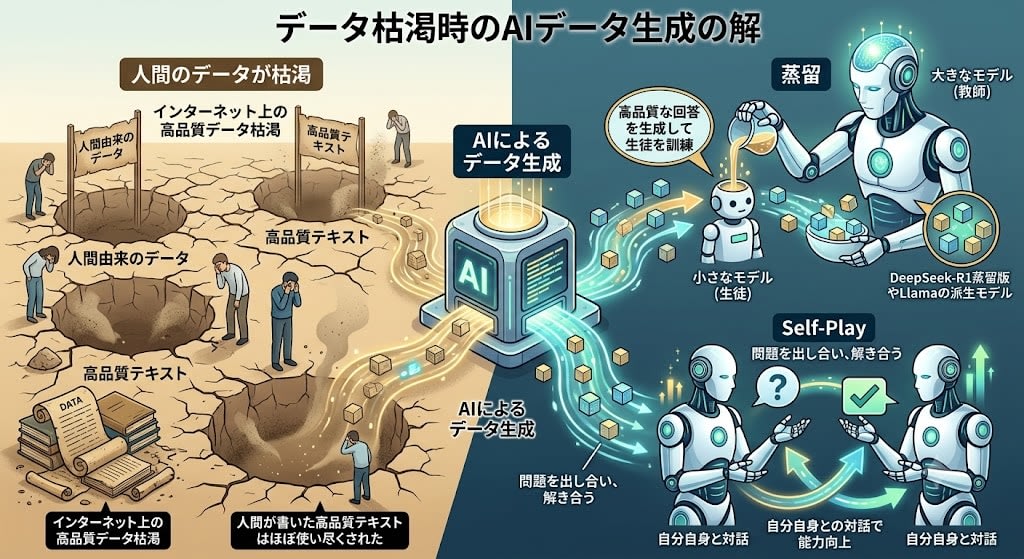
2026年の典型的なワークフローでは、200件の種データを人間が書き、それをフロンティアモデルで数万件に拡張し、品質フィルタをかけて小型モデルを訓練します。
これらは互いに排他的ではなく、現在のフロンティアモデルは3つすべてを組み合わせています。しかし重心は明確に移動しました——「大きくすれば賢くなる」から「賢く使えば小さくても強い」へ。
まとめ:設計されなかったLLM
LLMは誰もLLMを目指していなかった時代に、別々の問題への解答として積み重なってきた概念の集積です。

それぞれの研究者は自分の目の前の問題だけを見ていた。設計図なしに、80年余りかけて部品が揃いました。
今この瞬間も、誰かが全く別の問題に行き詰まり、その壁を越えるために書いている論文が、10年後のAIの部品になっているかもしれません。









