
AWS CDKでAmazon Athena Parameterized Queriesを作ってみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部 IoT事業部の若槻です。
Amazon Athenaでは、Parameterized Queriesを使用することにより、あらかじめ作成したQuery Statementに対して実行時にParameter値を渡して実行することができます。
Parameterized QueriesのStatementは下記のようにParameterのプレースメントホルダーを?で指定する構文となります。
SELECT * FROM "my_database"."my_table"
WHERE year = ? and month= ? and day= ?
今回は、このAmazon Athena Parameterized QueriesをAWS CDKで作ってみました。
やってみた
実装
AWS CDK v2(TypeScript)で次のようなCDKスタックを作成します。
import { Construct } from 'constructs';
import {
aws_s3,
aws_athena,
RemovalPolicy,
Stack,
StackProps,
} from 'aws-cdk-lib';
import * as glue from '@aws-cdk/aws-glue-alpha';
export class ProcessStack extends Stack {
constructor(scope: Construct, id: string, props: StackProps) {
super(scope, id, props);
// ソースデータ格納バケット
const sourceDataBucket = new aws_s3.Bucket(this, 'sourceDataBucket', {
bucketName: `data-${this.account}`,
removalPolicy: RemovalPolicy.DESTROY,
});
// Athenaクエリ結果格納バケット
const athenaQueryResultBucket = new aws_s3.Bucket(
this,
'athenaQueryResultBucket',
{
bucketName: `athena-query-result-${this.account}`,
removalPolicy: RemovalPolicy.DESTROY,
},
);
// データカタログ
const dataCatalog = new glue.Database(this, 'dataCatalog', {
databaseName: 'data_catalog',
});
// データカタログテーブル
const sourceDataGlueTable = new glue.Table(this, 'sourceDataGlueTable', {
tableName: 'source_data_glue_table',
database: dataCatalog,
bucket: sourceDataBucket,
s3Prefix: 'data/',
partitionKeys: [
{
name: 'date',
type: glue.Schema.STRING,
},
],
dataFormat: glue.DataFormat.JSON,
columns: [
{
name: 'userId',
type: glue.Schema.STRING,
},
{
name: 'count',
type: glue.Schema.INTEGER,
},
],
});
// データカタログテーブルへのPartition Projectionの設定
(sourceDataGlueTable.node.defaultChild as any).tableInput.parameters = {
'projection.enabled': true,
'projection.date.type': 'date',
'projection.date.range': '2022/06/20,NOW',
'projection.date.format': 'yyyy/MM/dd',
'projection.date.interval': 1,
'projection.date.interval.unit': 'DAYS',
'storage.location.template':
`s3://${sourceDataBucket.bucketName}/data/` + '${date}',
};
// Athenaワークグループ
const athenaWorkGroup = new aws_athena.CfnWorkGroup(
this,
'athenaWorkGroup',
{
name: 'athenaWorkGroup',
workGroupConfiguration: {
resultConfiguration: {
outputLocation: `s3://${athenaQueryResultBucket.bucketName}/result-data`,
},
},
},
);
// Prepared Queries
new aws_athena.CfnPreparedStatement(this, 'athenaPreparedStatement', {
statementName: 'athenaPreparedStatement',
workGroup: athenaWorkGroup.name,
queryStatement: `
SELECT *
FROM ${dataCatalog.databaseName}.${sourceDataGlueTable.tableName}
WHERE date = ?
LIMIT 10`,
});
}
}
- AWS CDK v2ではCfnPreparedStatement Classが用意されているので使用しています。
上記をCDK Deployしてスタックをデプロイします。
Deploy後にget-prepared-statementコマンドでPrepared Queriesを取得してみると、作成されていることが確認できます。
$ aws athena get-prepared-statement \
--work-group athenaWorkGroup \
--statement-name athenaPreparedStatement
{
"PreparedStatement": {
"StatementName": "athenaPreparedStatement",
"QueryStatement": "SELECT *\n FROM data_catalog.source_data_glue_table\n WHERE date = ?\n LIMIT 10",
"WorkGroupName": "athenaWorkGroup",
"LastModifiedTime": "2022-07-10T22:50:56.049000+09:00"
}
}
環境準備
データソースのLocationにデータをアップロードします。
$ cat data1
{"userId":"u001","count":3}
{"userId":"u001","count":1}
{"userId":"u002","count":5}
{"userId":"u002","count":8}
{"userId":"u003","count":2}
$ cat data2
{"userId":"u001","count":14}
{"userId":"u002","count":10}
{"userId":"u003","count":12}
$ cat data3
{"userId":"u001","count":4}
{"userId":"u002","count":4}
{"userId":"u003","count":0}
aws s3 cp data1 s3://${BUCKET_NAME}/data/2022/06/26/data1
aws s3 cp data2 s3://${BUCKET_NAME}/data/2022/06/27/data2
aws s3 cp data3 s3://${BUCKET_NAME}/data/2022/06/28/data3
動作確認
AthenaのQuery Editorで、先程作成したParameterized Queriesの実行をしてみます。
その際のパラメータの指定方法は2通りあります。
Parameter値をメニューから指定する
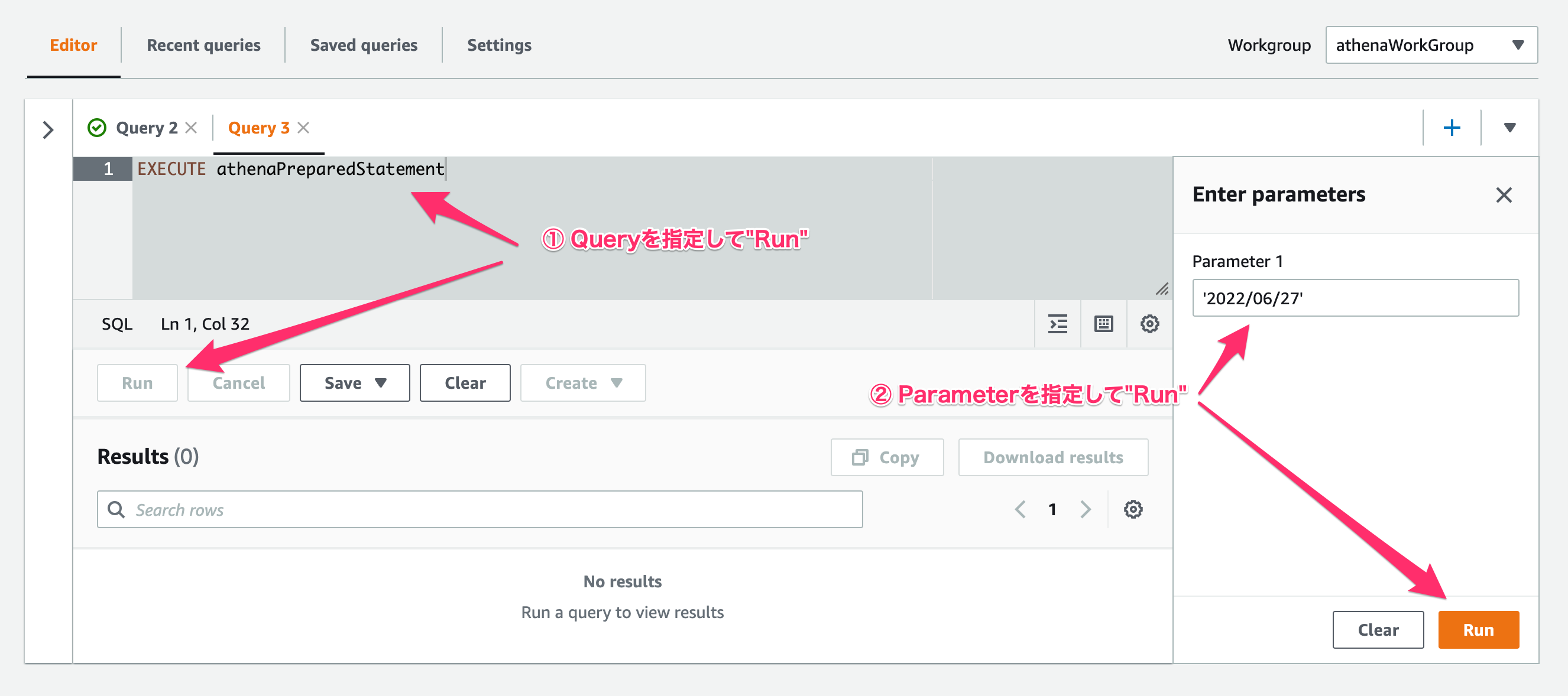
まずQuery StatementをEXECUTE statement_nameとして実行する場合。
この場合は、Query EditorでParameter入力メニューを使用してParameter値を指定するので、下記のようにQuery Statementを実行します。
EXECUTE athenaPreparedStatement
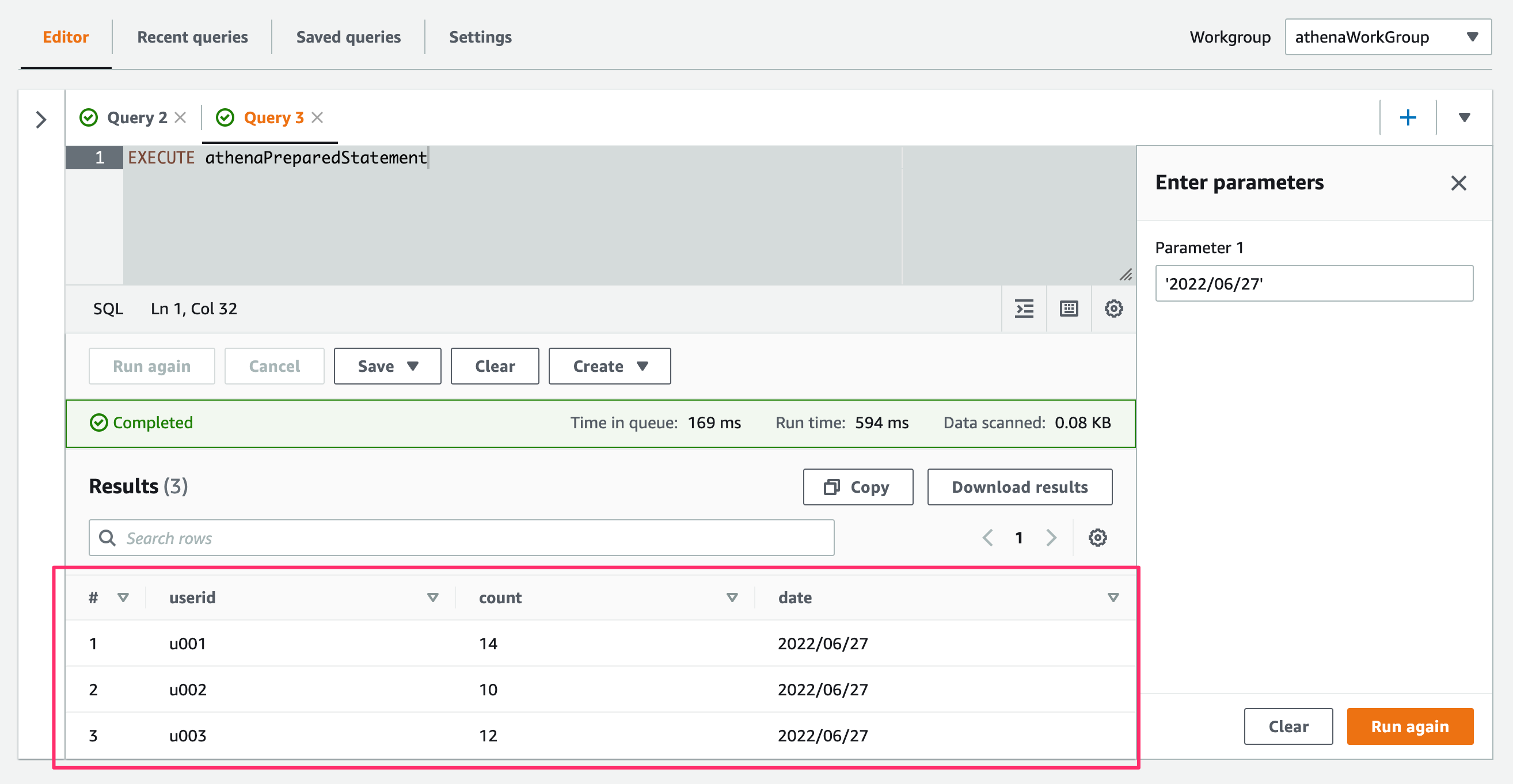
EditorでQuery Statementを指定して実行(Run)すると、Editor右側にParameter入力メニューが出てくるので、値を指定して実行(Run)します。
指定したParameter値を使用したQueryが実行されて結果が取得できました!
Parameter値をStatement内で指定する
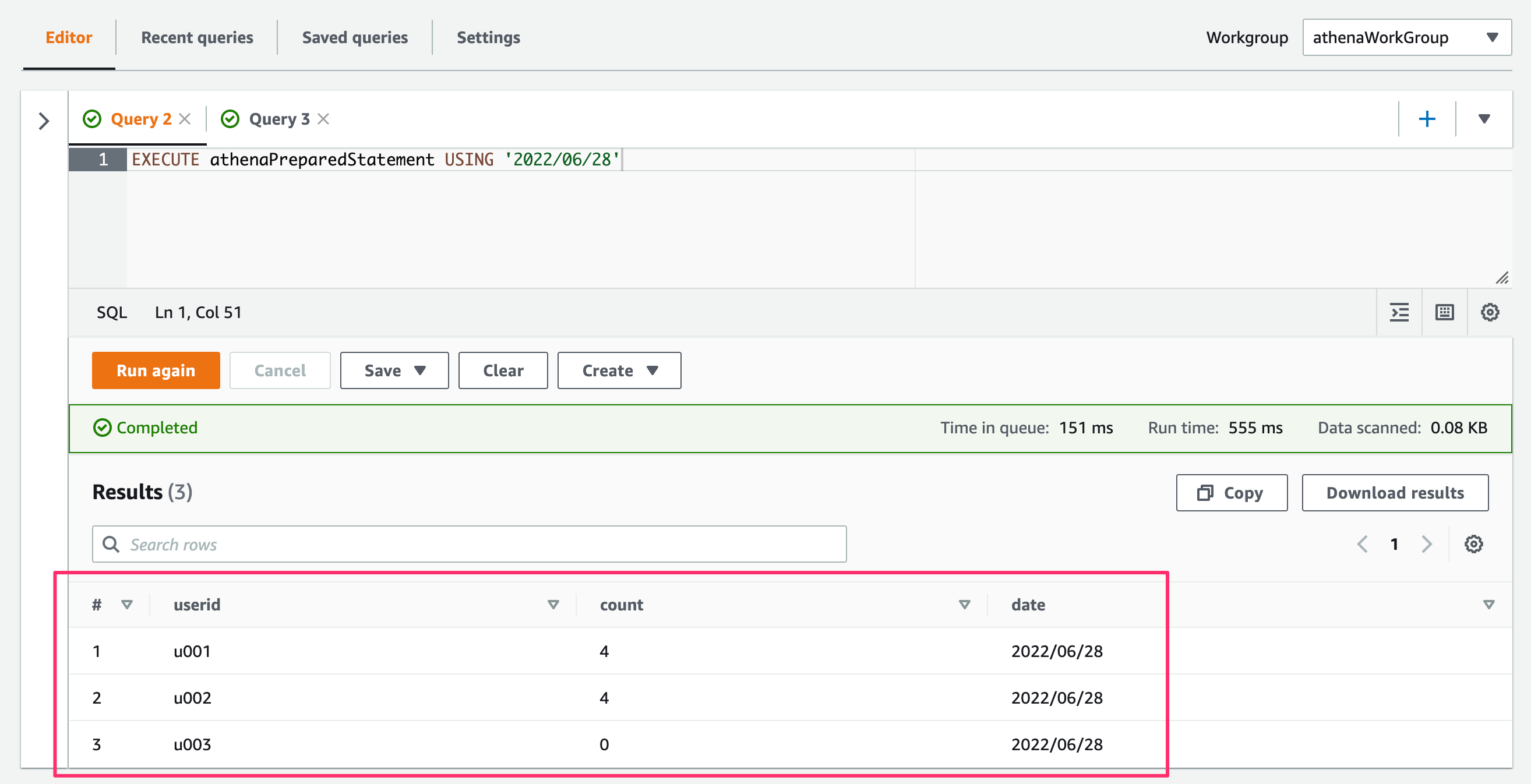
次にQuery StatementをEXECUTE statement_name [USING value1 [ ,value2, ... ] ]として実行する場合。
この場合は、Statement内にParameter値を直接指定するので、入力メニューは使用しません。下記のようにQuery Statementを実行します。
EXECUTE athenaPreparedStatement USING '2022/06/28'
EditorでQuery Statementを指定して実行(Run)すると、結果が取得できました!
参考
- [Amazon Athena] ALTER TABLE ADD PARTITIONコマンドでnon-Hiveなパーティションを追加してみた | DevelopersIO
- AWS Step FunctionsからS3 Bucket内のデータに対するAthenaクエリを実行して結果を取得する(AWS CDK v2) | DevelopersIO
- 【新機能】Amazon Athenaでパラメータ変更できるSQLを実行可能になりました! | DevelopersIO
以上









