![[レポート] MCPを活用してHRデータを統合し、意思決定を行う #ISV319 #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/4pUQzSdez78aERI3ud3HNg/fe4c41ee45eccea110362c7c14f1edec/reinvent2025_devio_report_w1200h630.png?w=3840&fm=webp)
[レポート] MCPを活用してHRデータを統合し、意思決定を行う #ISV319 #AWSreInvent
こんにちは、スーパーマーケットが大好きなコンサルティング部の神野です。
本記事ではre:Invent 2025で参加したLightning Talk「No More Orphans: Bringing Work and People Data Into Decisions with MCP(ISV319)」のセッションレポートをお届けします。
このセッションではHR(人事)データという実務に直結する分野でMCPを活用した事例が紹介されるとのことで、具体的にどうやって企業レベルでデータを統合して実現しているのだろうかと気になり、参加してみたいと思いました。
セッション概要
- セッションタイトル: No More Orphans: Bringing Work and People Data Into Decisions with MCP (ISV319)
- スピーカー:
- Kinman (Sr. Solutions Architect, AWS)
- Ike Benion (VP of Product Management, Platform, Visier)
- 日時: Wednesday, Dec 3, 12:30 PM - 12:50 PM PST
- 会場: Mandalay Bay | Level 2 South | Oceanside C | Content Hub | Lightning Theater
- レベル: 300 – Advanced
- 形式: Lightning Talk
セッション説明(公式)
Managers make dozens of high-impact decisions every week — but too often, work and people data is missing from the table especially in ad hoc decisions. The result? Strategy built on partial context, disconnected systems, and underused insights. In this session, we'll explore how Visier's Model Context Protocol (MCP) server changes that. By transforming fragmented HR and workforce data into a unified, AI-ready semantic layer, MCP lets organizations combine people data with critical business data, automate context delivery, and surface insights where decisions happen.
セッション内容
「孤立データ(Orphan Data)」問題とは
セッションは、モデレーターのKinmanさんによる印象的な問いかけから始まりました。
「あなたは重要なプロジェクトのために、既存の社員からチームを編成するよう任されました。誰が興味を持っている?誰にキャパシティがある?誰がこのプロジェクトを成功に導くスキルを持っている?」
多くのマネージャーやリーダーは、データが複数のシステムに散在しているため、
完全な情報を持たずに意思決定をしています。これが「孤立データ(Orphan Data)問題」であり、より良い意思決定を行う能力を奪っているとおっしゃっていました。
Orphan Dataという言葉自体、私は初めて聞いたのですが、上記に記載したような孤立したデータという意味合いなのだと学びになりました。
3つの根本的な課題

Ike Benionさんは、データ駆動の意思決定が実現しない理由として3つの問題を挙げました。
1. データの課題
企業のエコシステム全体にデータが散在しており、数十年かけて一箇所に統合しようとしても、依然として大きな課題となっています。これはMCPのようなテクノロジースタックで解決できる大きな機会です。
2. 時間の課題
事前に構築されたプロセスには意思決定のためのデータが組み込まれていますが、アドホックな意思決定(日々行われる多くの人事関連の決定)には、必要なタイミングでデータが利用できません。
3. データリテラシーの課題
利用可能なデータの使い方、異なるメトリクスの定義、データ間の関係性の理解など、データリテラシー自体に苦労している組織が多いです。
これら3つの課題すべてに、MCPとエージェントの企業実装によって、データ統合を実現し解決機会をもたらすと説明されました。
3つの課題は確かに・・・と思いました。データ駆動型の意思決定をしようにもデータ自体を整備していく必要もあり、すぐに利用するためには基盤を整えたりと一筋縄では難しい印象なので納得しました。
VisierのMCPサーバーアーキテクチャ

Visierのアーキテクチャは以下のように構成されています。
データソースとインジェスト層
HCM(Human Capital Management)、ERP、VMS(Vendor Management System)など、企業エコシステム全体から様々なソースのデータを取り込み、データのクレンジングと準備を行います。
セマンティック層
従業員ライフサイクル全体にわたる質問に答えるため、すぐに使える数千のメトリクス、コンセプト、ディメンションを設計しています。事前に設計されているため組織はこれらのデータをすぐに使い始めることができます。
キャッシングと配信層
大規模なデータベースでのアナリティクス処理には多くの計算リソースが必要で、遅延が発生しがちです。Visierはデータ取得を高速化するためにキャッシングなども工夫しています。
MCP展開
キャッシングと配信層の既存APIの上にMCPをスタックしています。
AWSの支援を受けて構築されたMCPサーバーの具体的な実装について説明がありました。
- Amazon ECR(Elastic Container Registry): MCPサーバーコンテナのリリース管理
- Amazon EC2: グローバルリージョンとアベイラビリティゾーンへのコンテナデプロイ
- Elastic Load Balancer & Auto Scaling Group: 需要の変化に応じたEC2インスタンスのスケーリング
- Amazon Route 53: マルチテナント階層のドメイン名マッチング(各組織が独自の環境を持つため)
- Amazon CloudWatch: パフォーマンスとアップタイムの監視
オープンソースのMCPコードをベースに、Visierの特定のユースケース向けに修正を加えてサーバーを構築したとのことです。オーソドックスなAWS構成にClaudeをMCPのクライアントに使用しているといった形ですね。多くのユーザーが使われるのでキャッシュを活用してコストを抑えていくのも大事です。
デモ: エンジニアの離職リスク分析
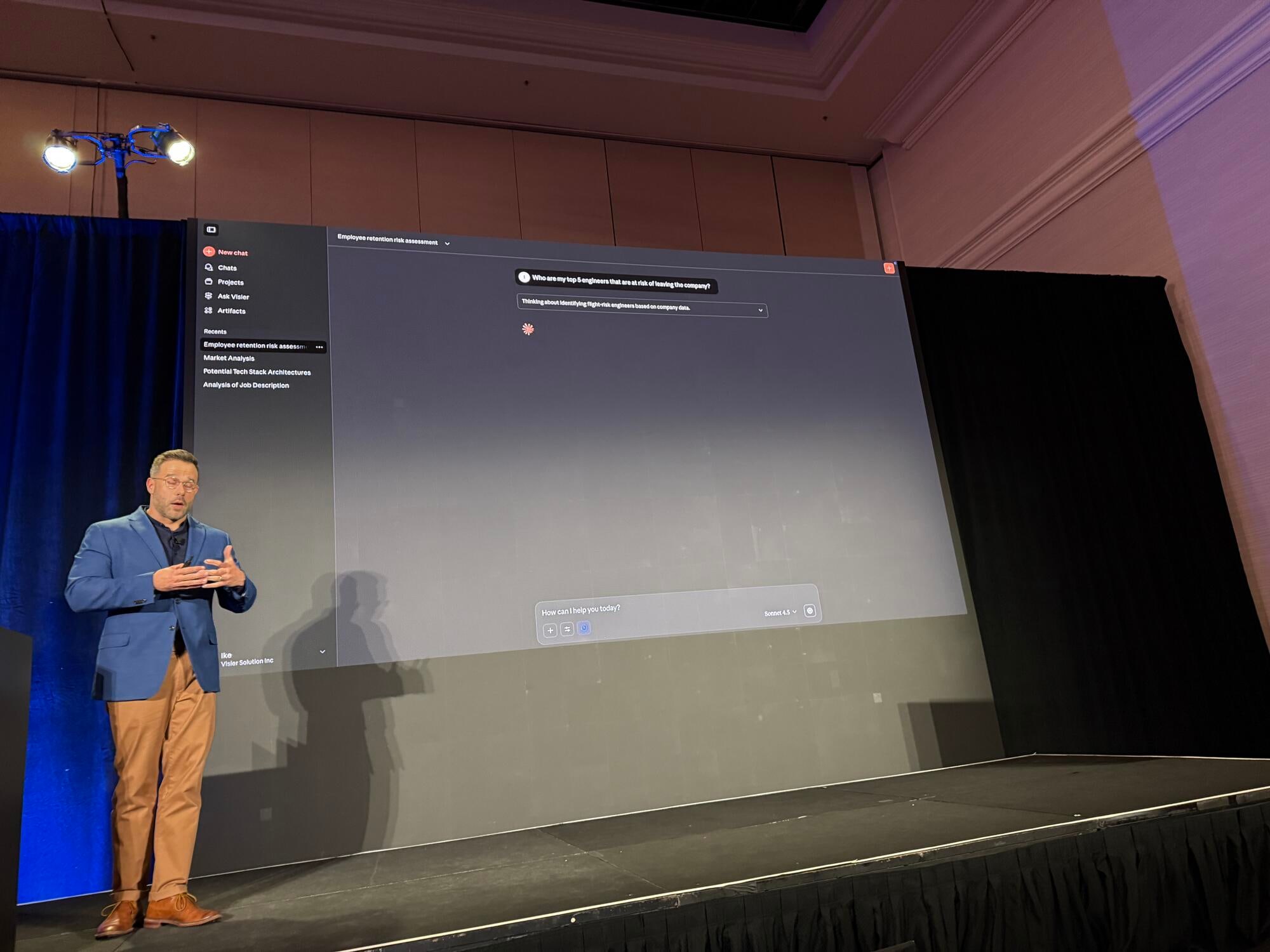

実際のデモでは、Claudeを使ったユースケースが紹介されました。MCP Serverに問い合わせする例を見せてくれました。デモやシナリオが身近な例でわかりやすかったです。具体的にご紹介します。
シナリオ設定
エンジニア開発チームのリーダーとして、高パフォーマーが退職するというショックな出来事がありました。
残りの重要なメンバーに引き続き勤めてもらうために何ができるかを知りたいという状況です。
シナリオがよくあるような話で面白いですね。
Claudeへの最初のプロンプト
ClaudeはVisierのMCPサーバーに接続し、様々なツールを取得し始めます。分析オブジェクトの検索、オブジェクトのフィルタリング、組織レベルの情報取得などを行い、「トップ5の従業員は誰か」「来年の退職リスクはどうか」という結果を出力します。
MCPとAPIの違い
Ikeさんは、MCPがAPIと比べて優れている点を強調しました。MCPでは、ツールの目的やエージェントがどのように使うべきかについての追加コンテキストを提供できます。これにより、多くのAPIでより良い動作が実現し、時間の経過とともにスケーラブルになります。MCPで統合しておけば、後からAPI側を改善しても、連携しているすべてのシステムの設定を変更する必要がありません。
退職リスクの要因分析
知るだけでは十分ではなく、その結果として「何をすべきか」を知ることが重要です。そこで、退職リスクの要因を尋ねます。
エージェントは5人のハイリスクエンジニアを取り、各要因を分析します。結果として、報酬の問題、キャリアの停滞、マネージャーとの関係の悪さ、パフォーマンスの懸念などが特定されました。
ここは聞いていて人事データと連携してこんなユースケースがあるんだ面白いな〜と率直に思いました。
MCPサーバー経由でデータを取得することができれば、普段自分たちがしている業務の壁打ちや代わりに仮説を出してくれるのはありがたいですよね。同時に分析をするにあたって必要なデータもかなり多くありそうで、課題も残り得る中で、ここまで整備されているのはすごいと感じました。
学んだ教訓

Ikeさんは、MCP実装から得た重要な教訓を共有してくれました。
APIの再構成が必要
既存のAPIをラップするのは一般的なアプローチですが、APIは特定のユースケース向けに構築されており、エージェントのアプローチ方法とは根本的に異なります。追加ツールの提供、エンドポイントの統合、ユースケースに応じたMCPの分割など、何らかの作業が必要になるでしょう。
参考になりますね。そのままできるだけ再活用したところですが、認証など難しいところもあるため、分割したり、軽量であれば作り直したりすることも選択肢として考えることが大事ですね。
エージェントのエラーハンドリングの難しさ
エージェントは何がうまくいかなかったかを親切に教えてくれません。典型的なインターフェースでそれを見つけられると思っていると、見つかりません。API側での可観測性を持つことがより有効です。適切な動作を確認し、予測可能で高品質な結果を時間をかけて提供できるようにしましょう。
これも自分自身でAIエージェントを作っていてデバッグの難しさはよく感じます。AIエージェントが必ず同じ動きがするわけではないので、インプットとアウトプットやツールの結果など詳細にかつ一貫して見れるのが大事ですね。
AWSのAIエージェントサービスであるAgentCoreならアプリケーションログや、Observirityで提供しているダッシュボードで可観測性を確認したり、後は直近で追加されたEvaluation機能でエージェント自体を評価させるのも大事になる気がします。
ツールの説明文が非常に重要
デモで見られたエラーは、2つのAPIの依存関係が原因でした。最善の解決策は、ツールへのより良い指示を提供することです。ただし、マルチエージェント環境では、エージェントがツールを異なる方法で、一貫性なく使用することが観察されています。実装方法と、顧客がどのように実装しているかの両方について戦略的に考えましょう。
ここはAnthopicのエージェントにとっての良いツールの作成方法の記事が上記の話と関連して参考になるなと感じました。
コストへの考慮
潜在的なコストは大きな考慮事項です。予防措置として、キャップ、レート制限などの典型的な対策でコストを軽減しました。例えば、エラーが発生したエージェントがサーバーにパフォーマンス問題を引き起こすことを防ぎます。APIに対するユースケースが実際にどうなるかは、やってみないと分かりません。企業との取り組みでも、まだパイロット段階が多いとのことです。
今後の展望

Visierが今後取り組む方向性について、3つの質問を中心に説明がありました。
エージェントへのリターンの拡大
エージェントはシステムから得ようとするものが非常に限定的で直接的なことが多く、UIに来た場合とは異なるエンドユーザー価値を制限する可能性があります。Visier独自のLLM(データ、ユーザーのコンテキスト、何を求めているか、何を尋ねるべきかについて非常に詳しい)を活用して、より広い価値提案を提供し、マネージャーを助けるデータについてのより良いストーリーを提供する適切なコンテキストをエージェントに与えることを考えています。
ユーザー自身の属性を考慮することも大切ですね。記憶を持たせたり、マスタデータから属性を共有したりして、よりユーザーに適した回答を実現できそうな印象を持ちました。
スケールしたユースケースの予測
企業パートナーとのパイロットユースケースがまだ多い中、顧客の数と多様性がどのように見えるか、MCPがより広いユーザーに対して本番環境でサービスを提供するとどうなるか、期待値を考えています。
追加ツールの影響
現在提供している基本的なクエリツールに加えて、可視化機能などの新しいツールを追加した場合、どのような影響があるでしょうか。また、ユーザーはこれらの追加ツールを使ってエージェントが生成した結果を、どの程度信頼して意思決定に活用するのでしょうか。
おわりに
このセッションでは、VisierがMCPを活用してHRデータの統合問題を解決するアプローチについて学ぶことができました。
20分のLightning Talkでしたが、MCPの実践的な活用事例と得られた教訓が詰まっていて良い内容だったな感じました。自分だったらどう設計するのが良いかとか考えさせられて面白かったです。今日学んだ観点は今後MCP Serverの設計・構築をする際は振り返りたいなと思います。
今回の話ではあまり見えなかったですが、データの整備をしたりMCP Server化するまでに色々な課題もありつつも成功したのは他の企業にとってもいい事例なのかなと感じました。
以上、セッションレポートでした。最後までご覧いただきありがとうございましたー!!










