メタデータのありがたみを完全に理解したので説明しよう #SnowflakeDB
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
ハライチのネタを書いてる方の岩井さんは相方の澤部さんに対して、「お前は漫才師ではなく、ネタ受け取り師なんだよ」とよく言っています。
Snowflakeのメタデータをそのまま当たり前のように受け取っていた、そんな数年前の澤部さんみたいな時期が私にもありました。しかしメタデータのありがたみを知った今日の私は昨日の私とは全く別人であり、きちんと自らが「私はアナリティクスコンサルタントではなく、Snowflakeのメタデータ受け取リティクスコンサルタント」であることを自覚しています。その点において、設楽さん欠席回のバナナムーンで日村さんが助っ人できていた岩井さんに対してクイズを出して軽率に賞金100万出すと言ってしまったことによりその後数ヶ月にも及ぶ岩井さんからの取り立てに苦しんだ日村さんのように、私は岩井さんから責め立てられることはないでしょう。改行なしで私は何を書いているんですか?そんなことよりここまでこの読みづらい文章を読み飛ばさずに読んだあなたはどれだけ律儀なんですか?いい人すぎますよ。そんなんじゃ日村さんから100万円もらえませんよ。え、別にいいって?そうですね。世の中の多くの人にとっていや私だってそんなことはどうでもいいんですよ。
まぁ、とりあえずメタデータのありがたみを完全に理解したので未だメタデータ受け取り師だという自覚のない人に教えてあげよう。
ことの始まり
Snowflakeの勉強と並行してデータ分析基盤についての勉強をしてたところ、列指向データベースはデータの圧縮率が高くI/O効率が良くなるというメリットがあるということを知りました。
は?
あれ、そもそもデータを圧縮するってなんだ?
で、
データを圧縮するとI/O効率が高くなるのはなぜ???
というわけで社内の有識者(スーパーヒーロー)に質問してみました。
データを圧縮するということ、I/O効率が高くなるということ
データを圧縮するということ、
「圧縮後のデータ量で・・・」とついつい何も考えずに話していたのですが、そもそもデータを圧縮するというのがどういうことなのかがわかっていませんでした。
そこで、社内の有識者(スーパーヒーロー)からこちらの記事を教えてもらいました。
圧縮前のデータ→圧縮後のデータ(イメージ)
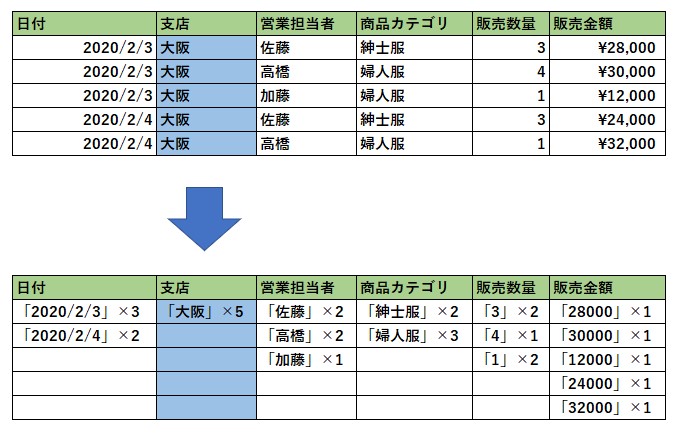
ブログの本文にも記載されていますが圧縮後のデータはあくまでもイメージです。理解優先の図なのでとてもわかりやすいですね。
つまり、上の図の通り支店列の中に「大阪」という値は5つあるというような形でデータが圧縮されています。
I/O効率が高くなるということ
単純にデータの量が小さくなればI/O効率は良くなることは私でもかろうじてわかります。ただ、列指向のデータベースでは値を集約して計算することが主な用途となるのであらかじめ値が集約されていればその数字を出せばいいということになります。
圧縮前のデータと圧縮後のデータに対してselect count(*) from 表とした時に圧縮したデータは計算するまでもなく5と返すことができます。
Snowflakeのメタデータじゃんそれ
この説明を聞きながら、Snowflakeのメタデータもそんな感じよな。と軽率に思考を飛ばしていたわけですが、ちょっと違います。そうSnowflakeは想像の上を行きます。
Snowflakeに上の表が入っていてselect count(*) from 表を実行した場合、Snowflakeはウェアハウスを起動せずに5と返すことができます。
すっげ。
さすが分析のために設計されたデータベス革新的なアーキテクチャを備えたデータプラットフォームですね!
まとめ
データの圧縮とかデータベースの成り立ちなんかをご存知の人には今更そんな当たり前なことに何をそんなハイテンションで盛り上がっているのだい?という話題だと思います。
ただ、初めて触るDWHがSnowflakeの私からすると、自分(Snowflake)のあたり前が歴史的な大転換だったんじゃん!ということが多々あり、このコーフンはブログにして発信せねばならぬという謎の使命感が芽生え、おかしなテンションで文章を書き連ねたわけであります。
Snowflakeてすごいね、スキ。本来この程度の語彙力の人間が頑張ってブログを書きました。










