![[新機能]SPCS上で実行されるOpenflow Snowflake Deploymentsを用いてSlackのデータをロードしてSnowflake Intelligenceから問い合わせしてみた](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-37f4322e7cca0bb66380be0a31ceace4/0886455fd66594d3e7d8947c9c7c844d/eyecatch_snowflake?w=3840&fm=webp)
[新機能]SPCS上で実行されるOpenflow Snowflake Deploymentsを用いてSlackのデータをロードしてSnowflake Intelligenceから問い合わせしてみた
さがらです。
先月、SPCS(Snowpark Container Services)上で実行されるOpenflow Snowflake Deploymentsがパブリックプレビューとなりました。(9月17日のリリースでしたが、実際にAWSの日本リージョンで利用できるようになったのは9月29日頃と認識しています。)
これまでのOpenflowはAWS上にデプロイする方式しかなかったのですが、EKS含む多くのAWSリソースがデプロイされるため、コストや運用面に課題がありました。
今回Snowpark Container Services上にデプロイできる方式となったことにより、今まで以上にマネージドサービスとしてOpenflowを使うことができるようになりました。
このSPCS上で実行されるOpenflow Snowflake Deploymentsを用いてSlackのデータをロードしてSnowflake Intelligenceから問い合わせしてみたので、その内容について本記事でまとめてみます。
検証内容
基本的に以下のQuickstartの内容とSlackコネクタのドキュメントに沿って、実施していきます。
検証するSnowflakeアカウントは、有償契約しているSnowflakeのAWS東京リージョンのEnterpriseエディションです。
Slack側の準備:Slackアプリの作成とインストール
先に事前準備として、Slackアプリを作成しインストールします。
Slackアプリの作成
ブラウザでSlackのYour Appsのページを開き、右上のCreate New Appを押します。
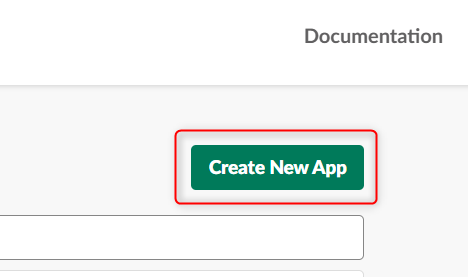
From a manifestを選択します。
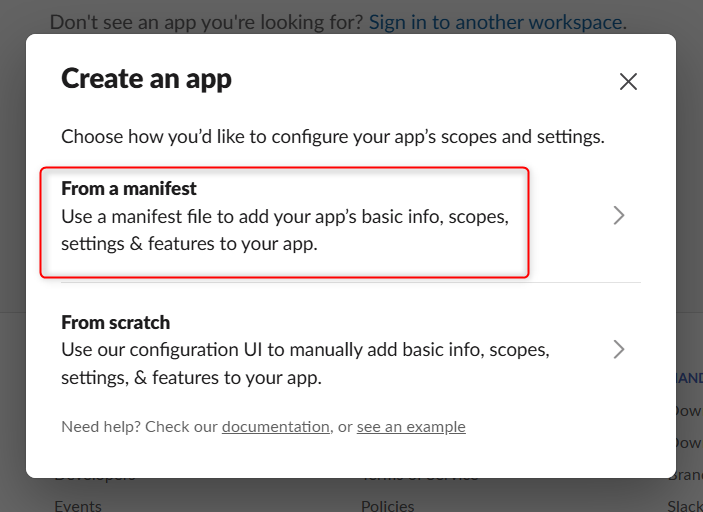
アプリをデプロイしたいワークスペースを選択します。
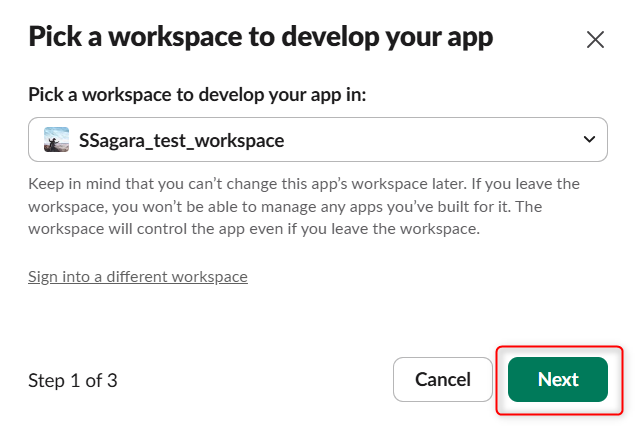
以下のコードをコピーして貼り付けます。(EXAMPLE_NAME_CHANGE_THISの箇所は変更してください。)
{
"display_information": {
"name": "EXAMPLE_NAME_CHANGE_THIS"
},
"features": {
"bot_user": {
"display_name": "EXAMPLE_NAME_CHANGE_THIS",
"always_online": false
}
},
"oauth_config": {
"scopes": {
"bot": [
"channels:history",
"channels:read",
"groups:history",
"groups:read",
"im:history",
"im:read",
"mpim:history",
"mpim:read",
"users.profile:read",
"users:read",
"users:read.email",
"files:read",
"app_mentions:read",
"reactions:read"
]
}
},
"settings": {
"event_subscriptions": {
"bot_events": [
"message.channels",
"message.groups",
"message.im",
"message.mpim",
"reaction_added",
"reaction_removed",
"file_created",
"file_deleted",
"file_change"
]
},
"interactivity": {
"is_enabled": true
},
"org_deploy_enabled": false,
"socket_mode_enabled": true,
"token_rotation_enabled": false
}
}
貼り付けると下図のようになるため、Nextを押します。
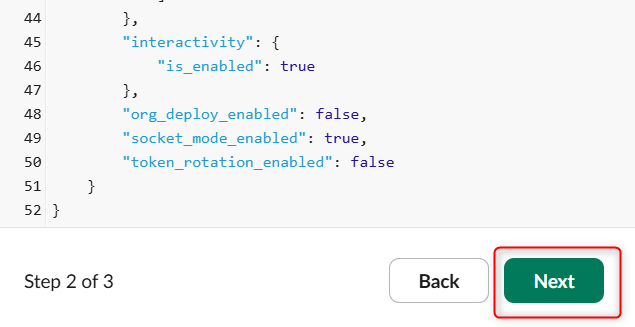
Createを押します。
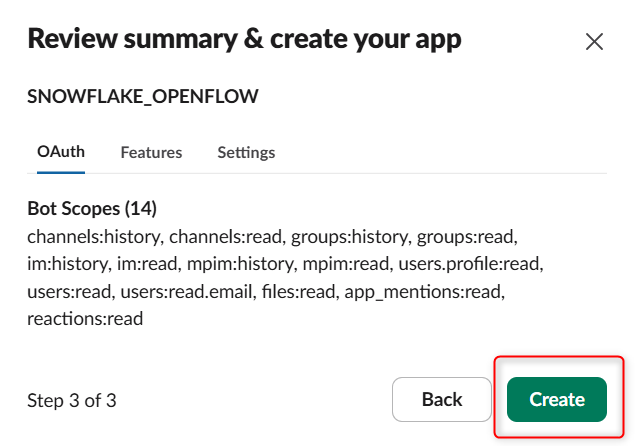
すると下図のように表示されます。これでアプリの作成は完了です。
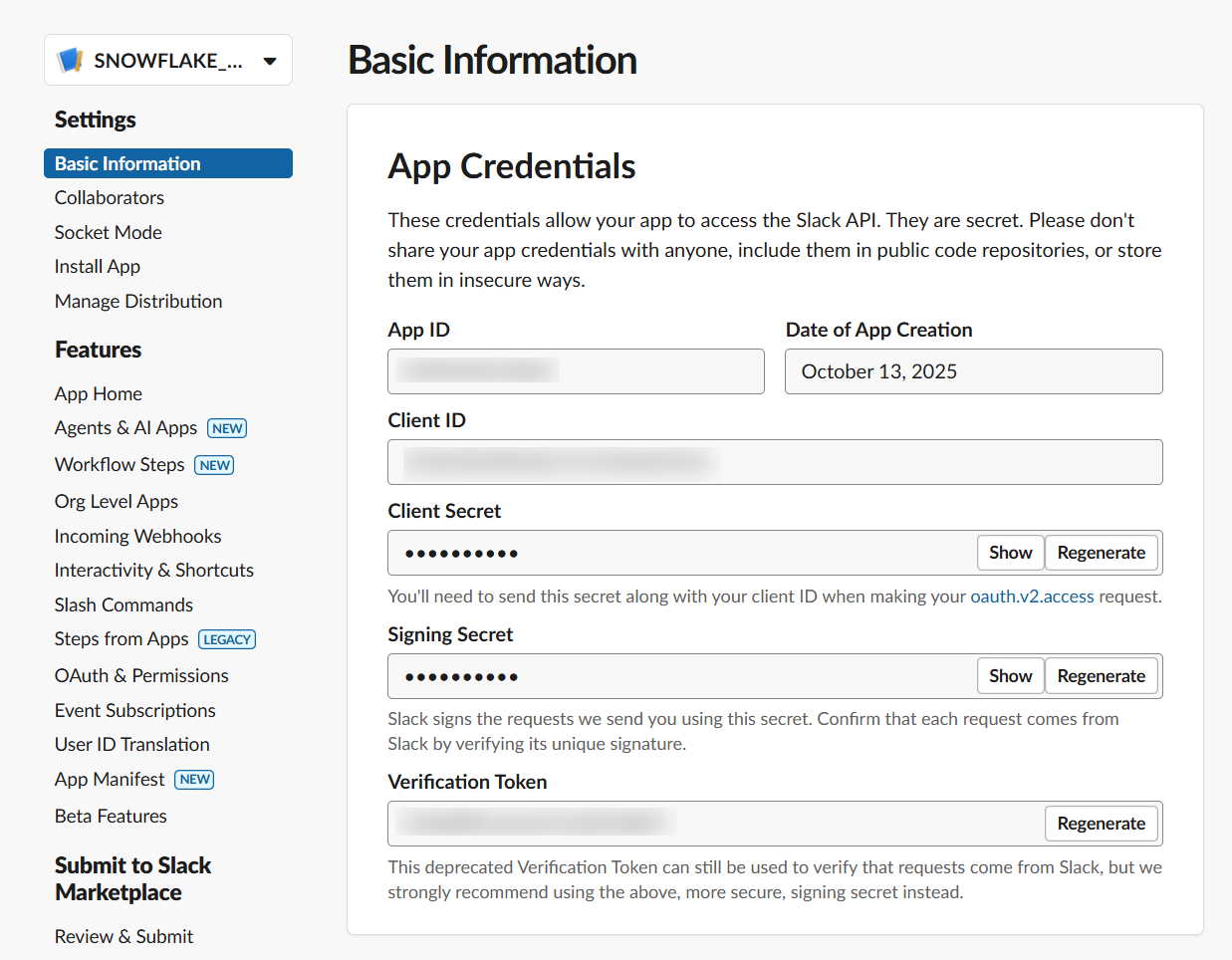
App-Level Tokensの生成
次に、App-Level Tokensの生成を行います。
作成したアプリのBasic Informationの中に、App-Level Tokensという項目があるので、その項目の中でGenerate Token and Scopesを押します。
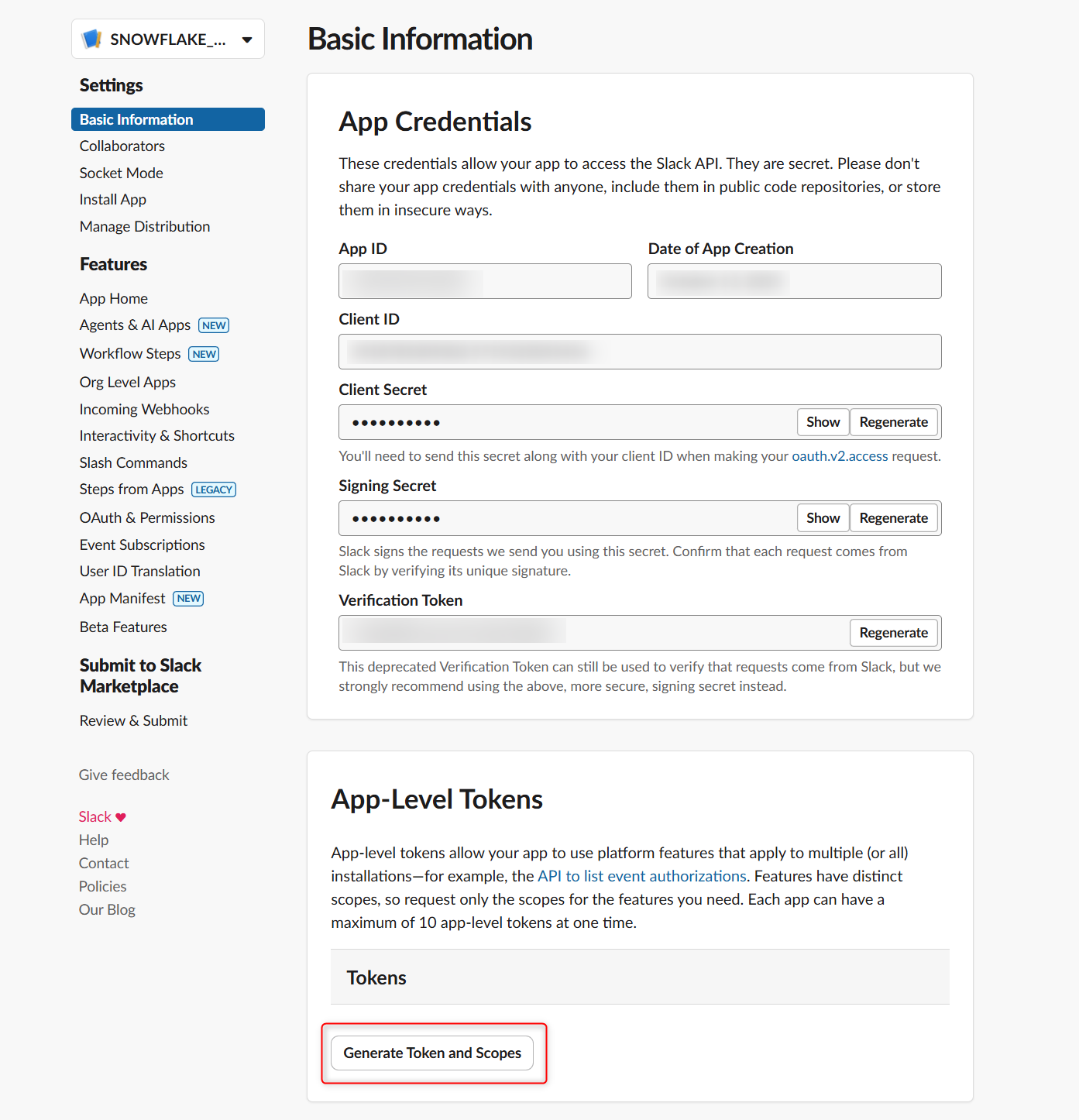
スコープとしてconnections:writeを追加して、Generateを押します。
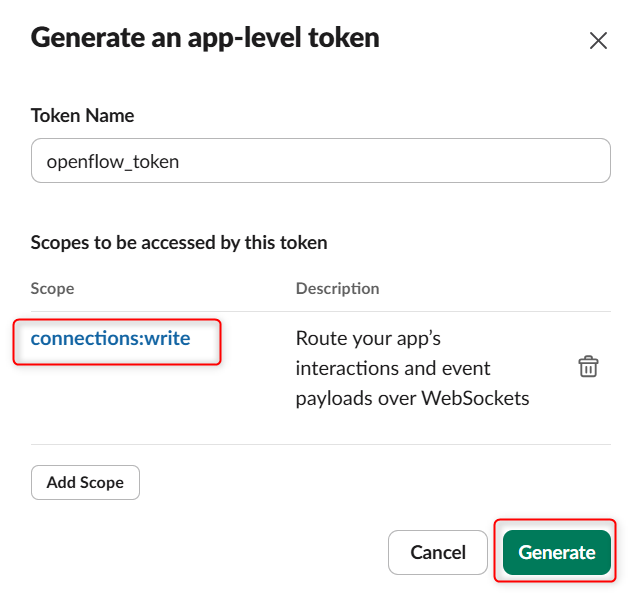
トークンが生成されますので、控えておきます。
作成したSlackアプリをインストール
作成したSlackアプリを対象のワークスペースにインストールします。
作成したSlackアプリの画面で、左のメニューからInstall Appを押し、Install to <ワークスペース名>を押します。
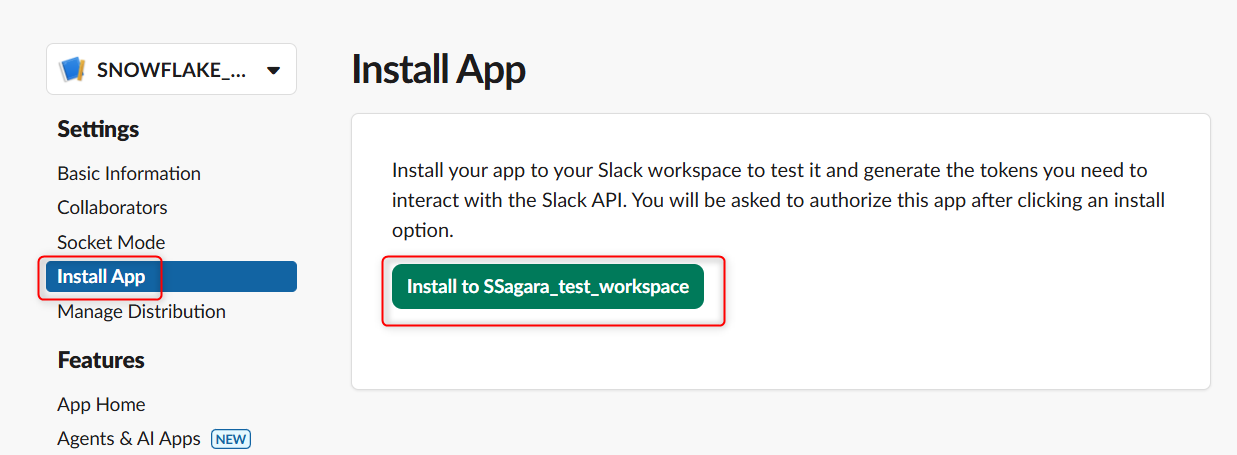
下図のようにOAuthの認証画面が表示されるため、Allowを押します。
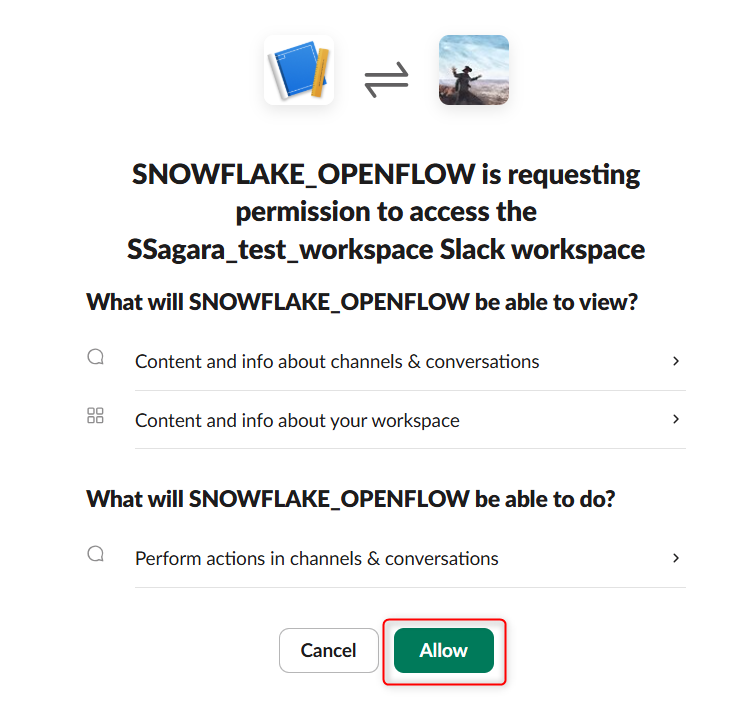
OAuth Tokensが表示されるので、控えておきます。
作成したアプリをデータをロードしたいチャンネルに追加
対象のSlackワークスペースでデータをロードしたいチャンネルを開き、/invite @<作成したアプリ名>とコマンドを実行します。
これにより、作成したSlackアプリがチャンネルに追加されました。
Snowflake側の準備
次にSnowflake側の準備をしていきます。
Openflow管理者用のロールを作成
まず、Openflow管理者用のロールを作成します。
-- Create the Openflow admin role (requires ACCOUNTADMIN or equivalent privileges)
USE ROLE ACCOUNTADMIN;
CREATE ROLE IF NOT EXISTS OPENFLOW_ADMIN;
-- Grant necessary privileges
GRANT CREATE DATABASE ON ACCOUNT TO ROLE OPENFLOW_ADMIN;
GRANT CREATE COMPUTE POOL ON ACCOUNT TO ROLE OPENFLOW_ADMIN;
GRANT CREATE INTEGRATION ON ACCOUNT TO ROLE OPENFLOW_ADMIN;
GRANT BIND SERVICE ENDPOINT ON ACCOUNT TO ROLE OPENFLOW_ADMIN;
-- Grant role to current user and ACCOUNTADMIN
GRANT ROLE OPENFLOW_ADMIN TO ROLE ACCOUNTADMIN;
GRANT ROLE OPENFLOW_ADMIN TO USER <ユーザー名>;
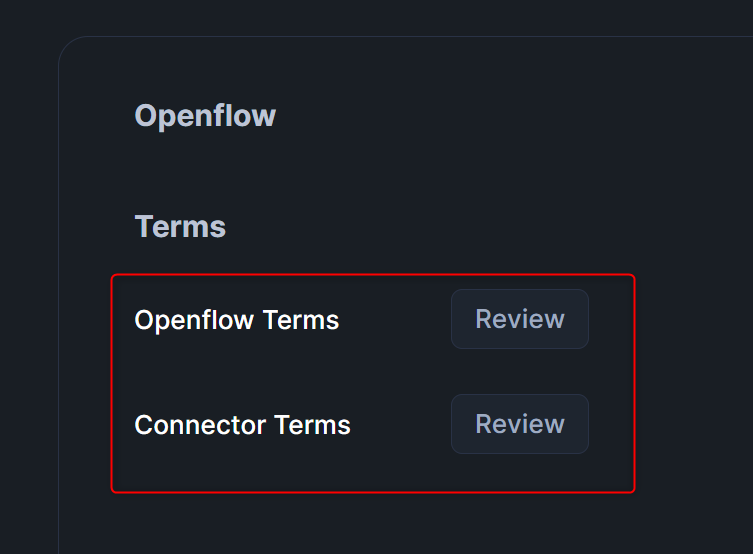
Termsに同意
Openflowの各コネクタを利用するには利用規約に同意する必要があるため、AdminのTermsから、Openflow TermsとConnector Termsに同意します。
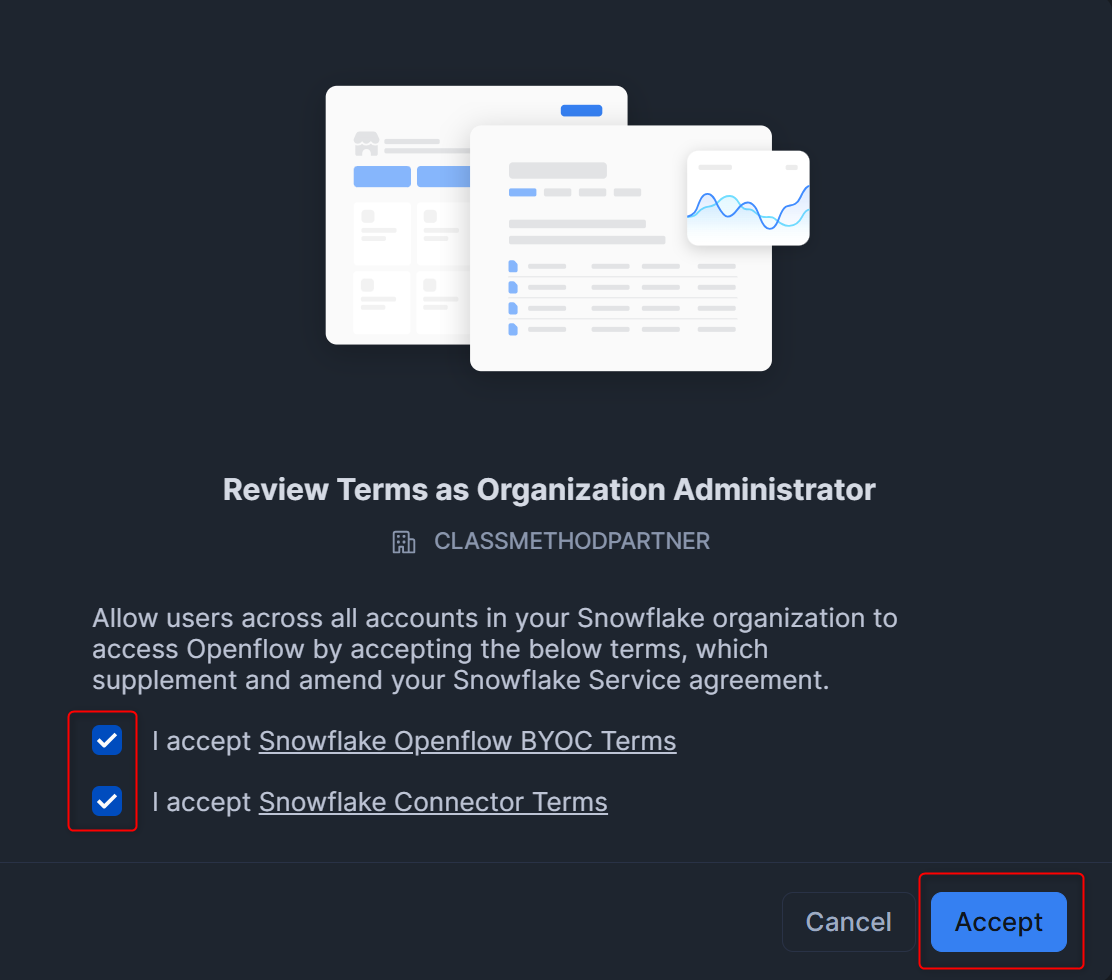
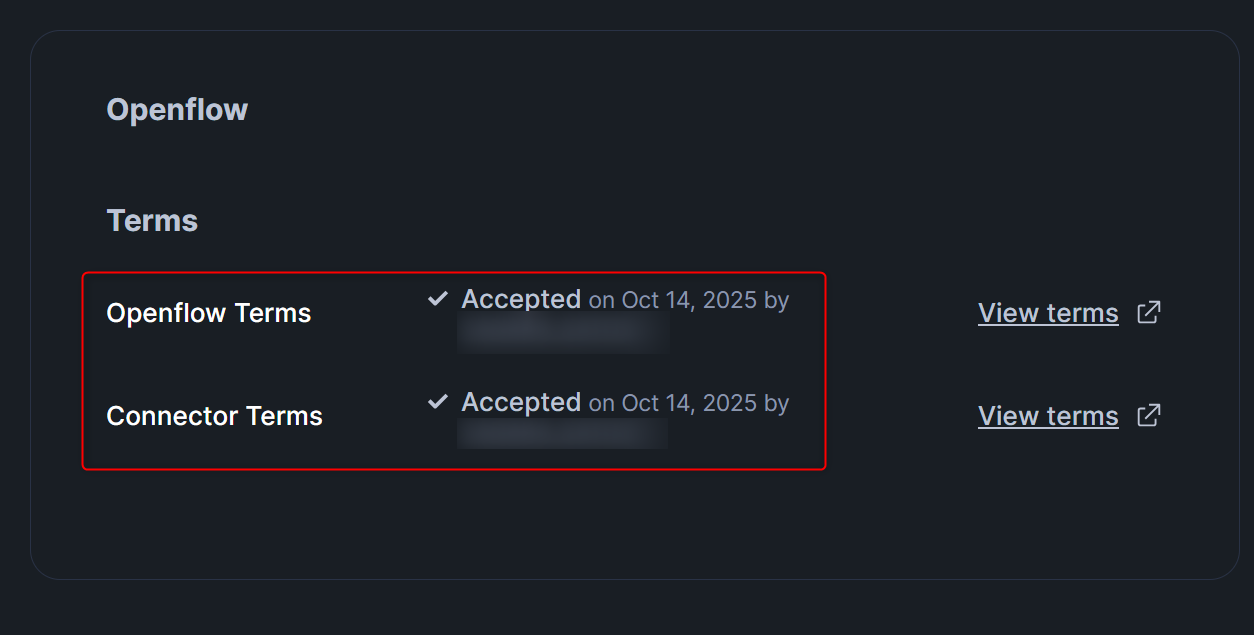
同意後、下図のように表示されていれば問題ありません。
バンドル2025_06を有効化 ※必要に応じて
最後に必要に応じて、バンドル2025_06を有効化します。(今回Slackコネクタを利用するためです。)
-- Check the bundle status
USE ROLE ACCOUNTADMIN;
CALL SYSTEM$BEHAVIOR_CHANGE_BUNDLE_STATUS('2025_06');
-- Enable BCR Bundle 2025_06
CALL SYSTEM$ENABLE_BEHAVIOR_CHANGE_BUNDLE('2025_06');
Openflowのデプロイメントの作成
次に、Openflowのデプロイメントを作成していきます。
まず、Snowsightで使用するロールが作成したOPENFLOW_ADMINであることを確認します。
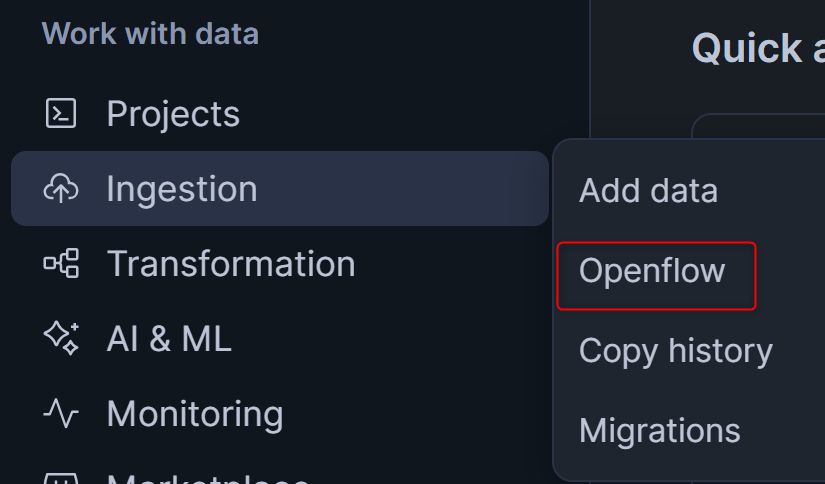
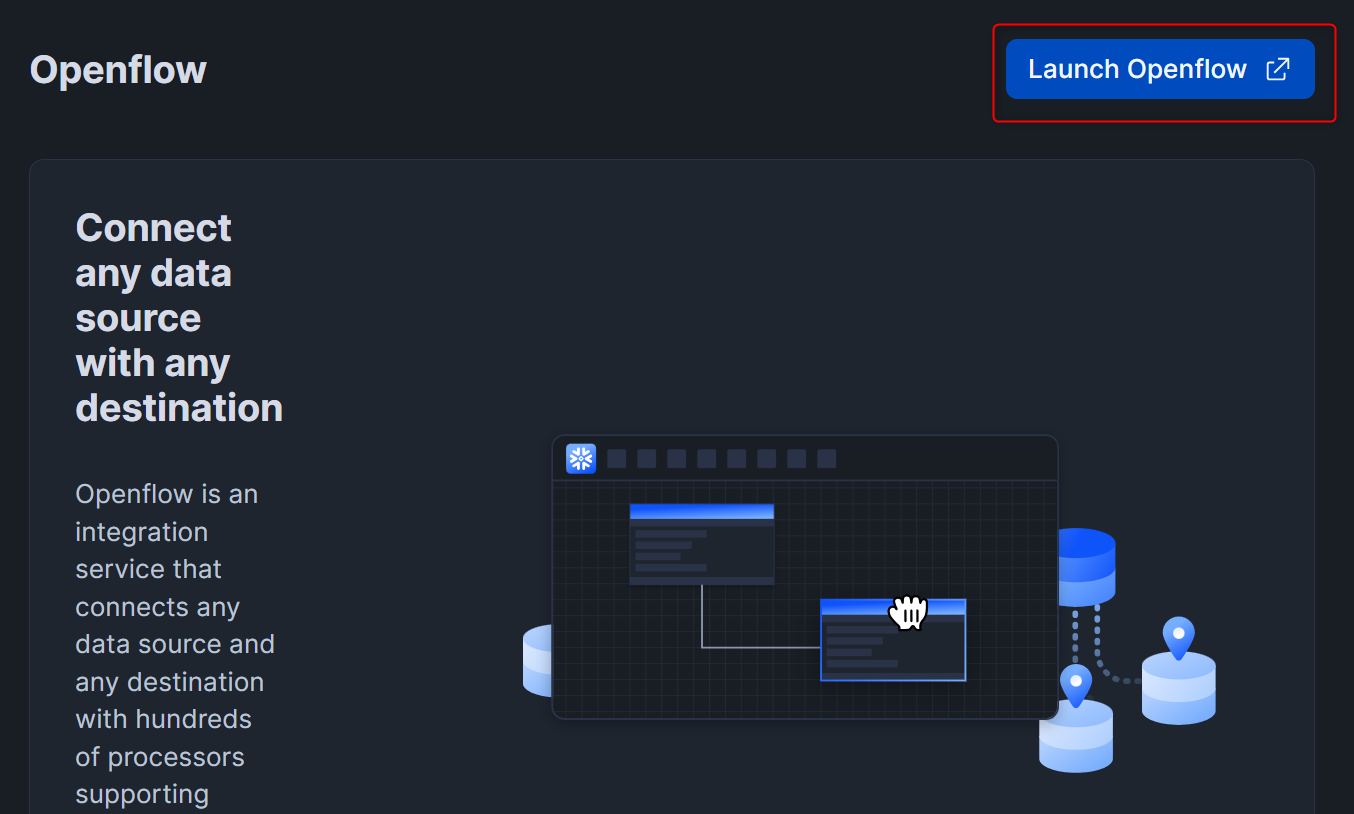
SnowsightのメニューからOpenflowを押し、右上のLaunch Openflowを押します。
ユーザー認証後、以下の画面となります。右上のロールがOPENFLOW_ADMINであることを確認してから作業しましょう。
Create a deploymentを押します。
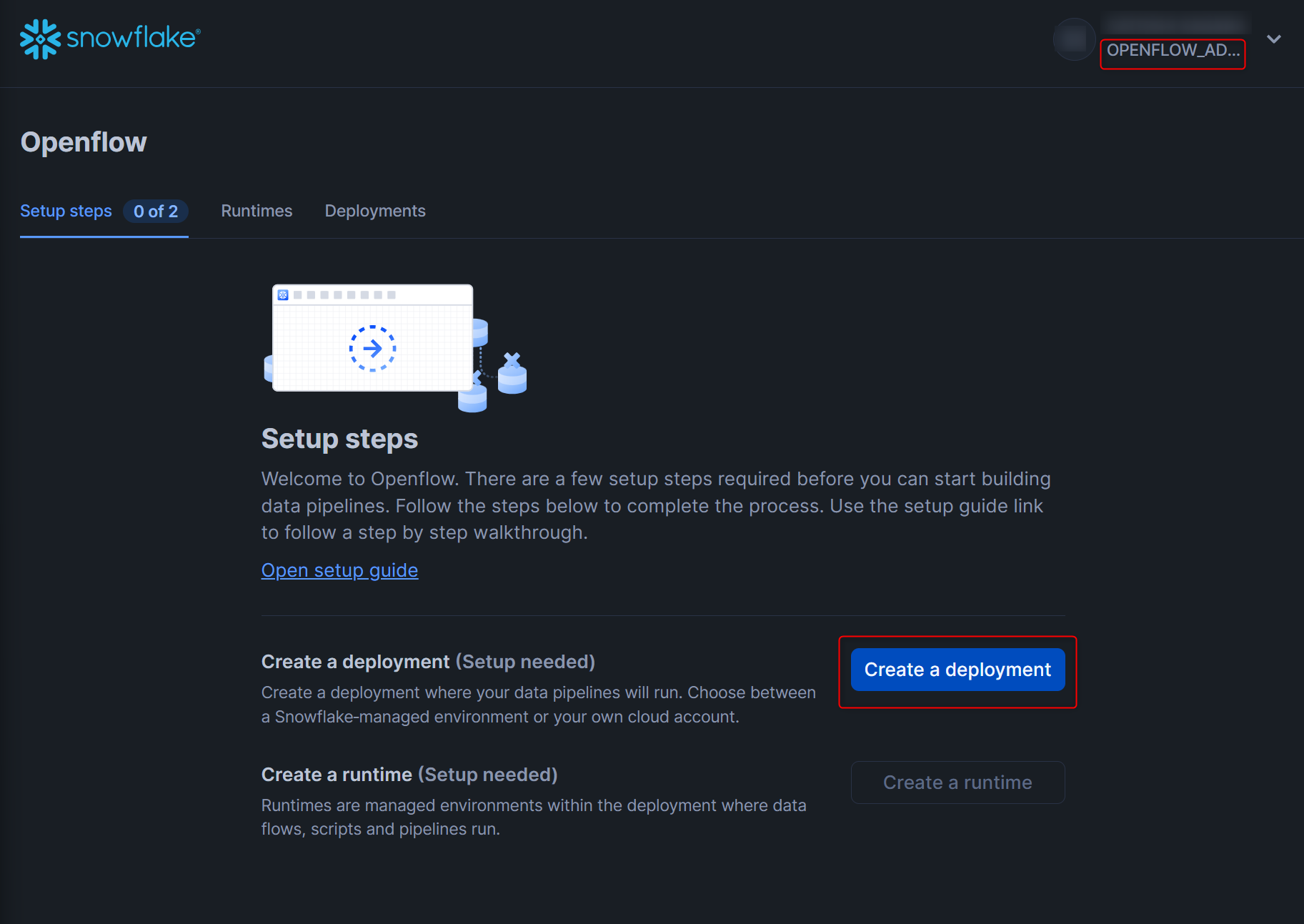
右下のNextを押します。
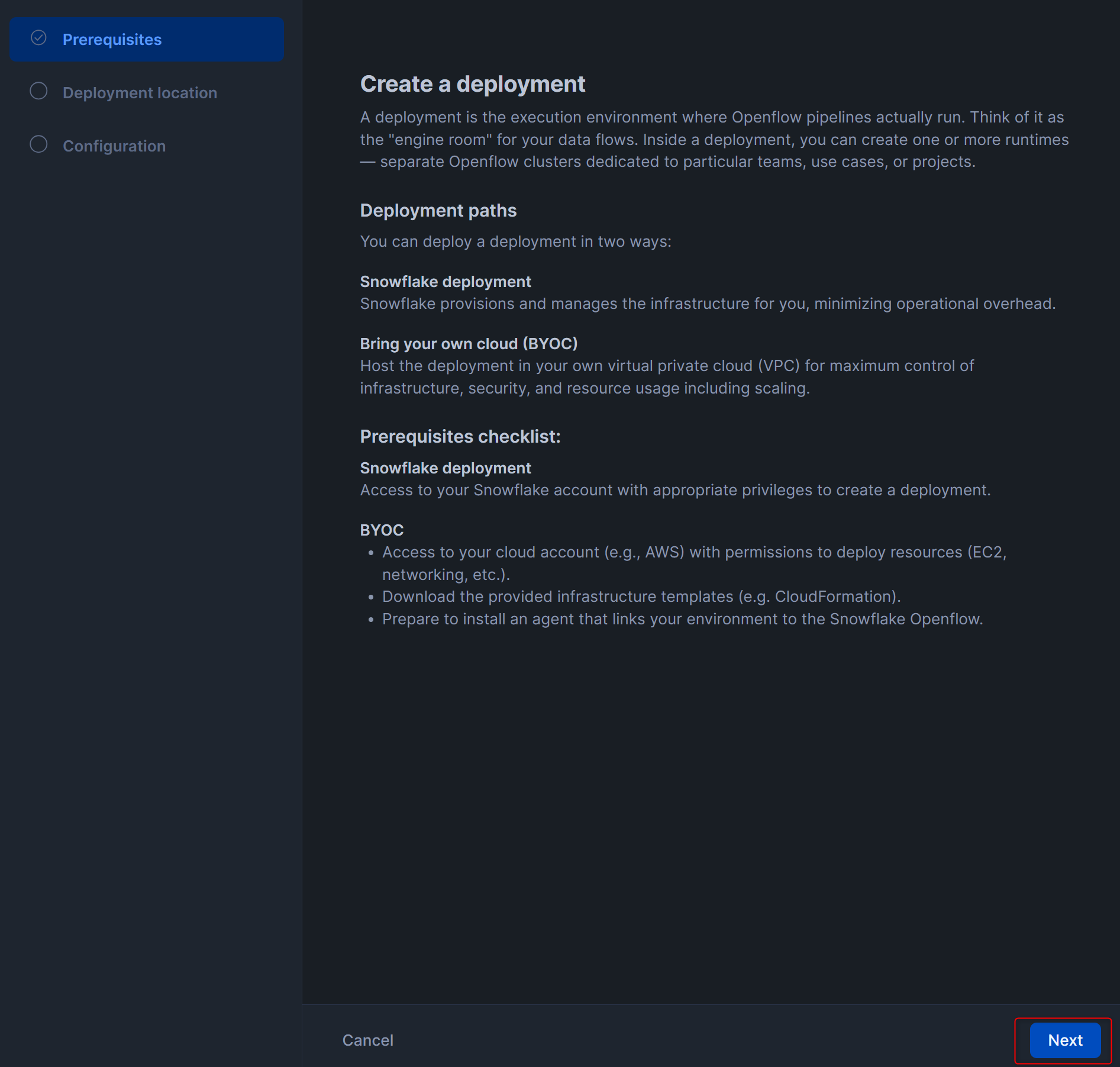
Deployment locationはSnowflake、NameはQUICKSTART_DEPLOYMENTとして、Nextを押します。
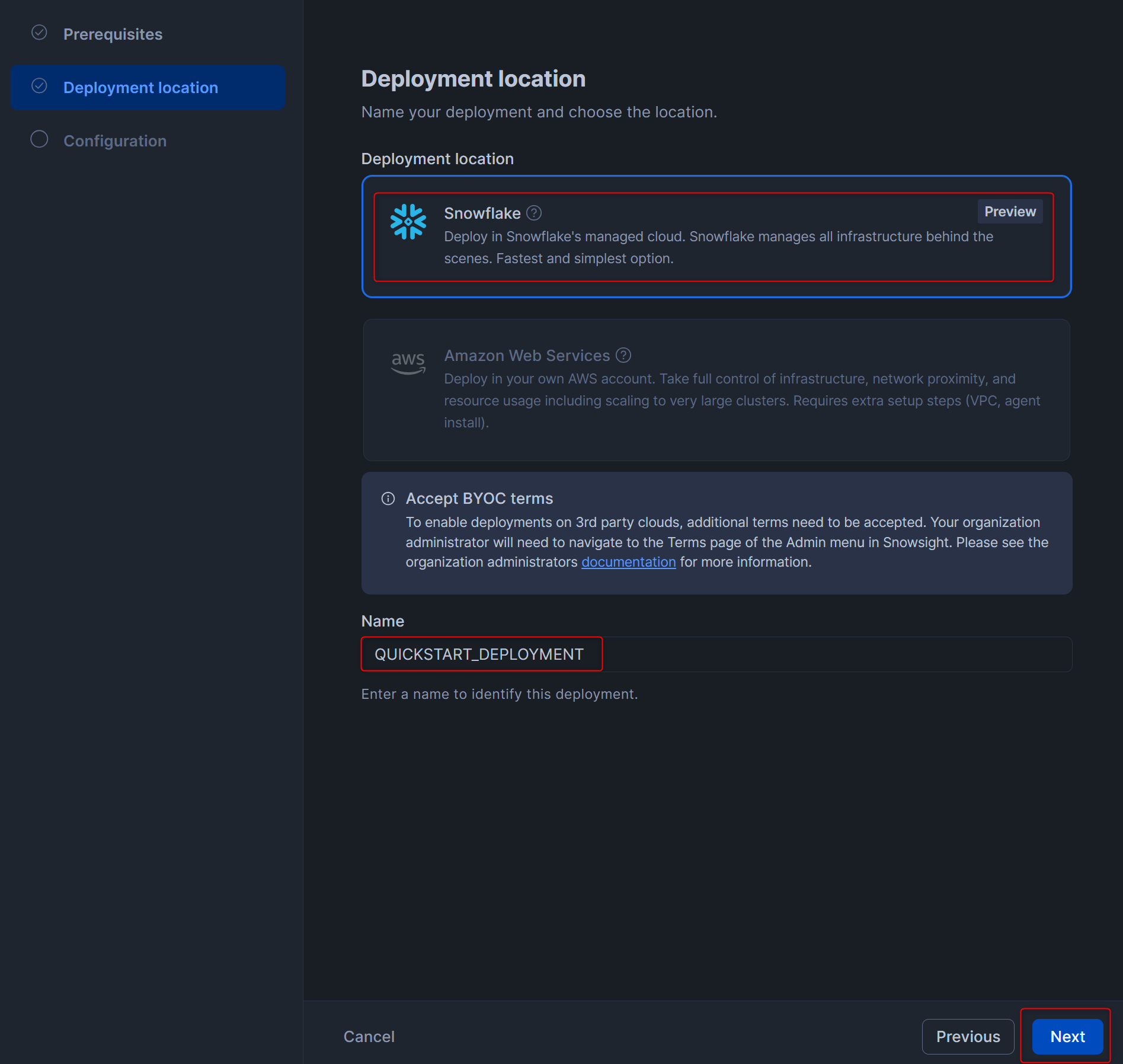
デプロイメントに対する権限を付与できる画面となりますが、ここでは何も設定せず、右下のCreate deploymentを押します。
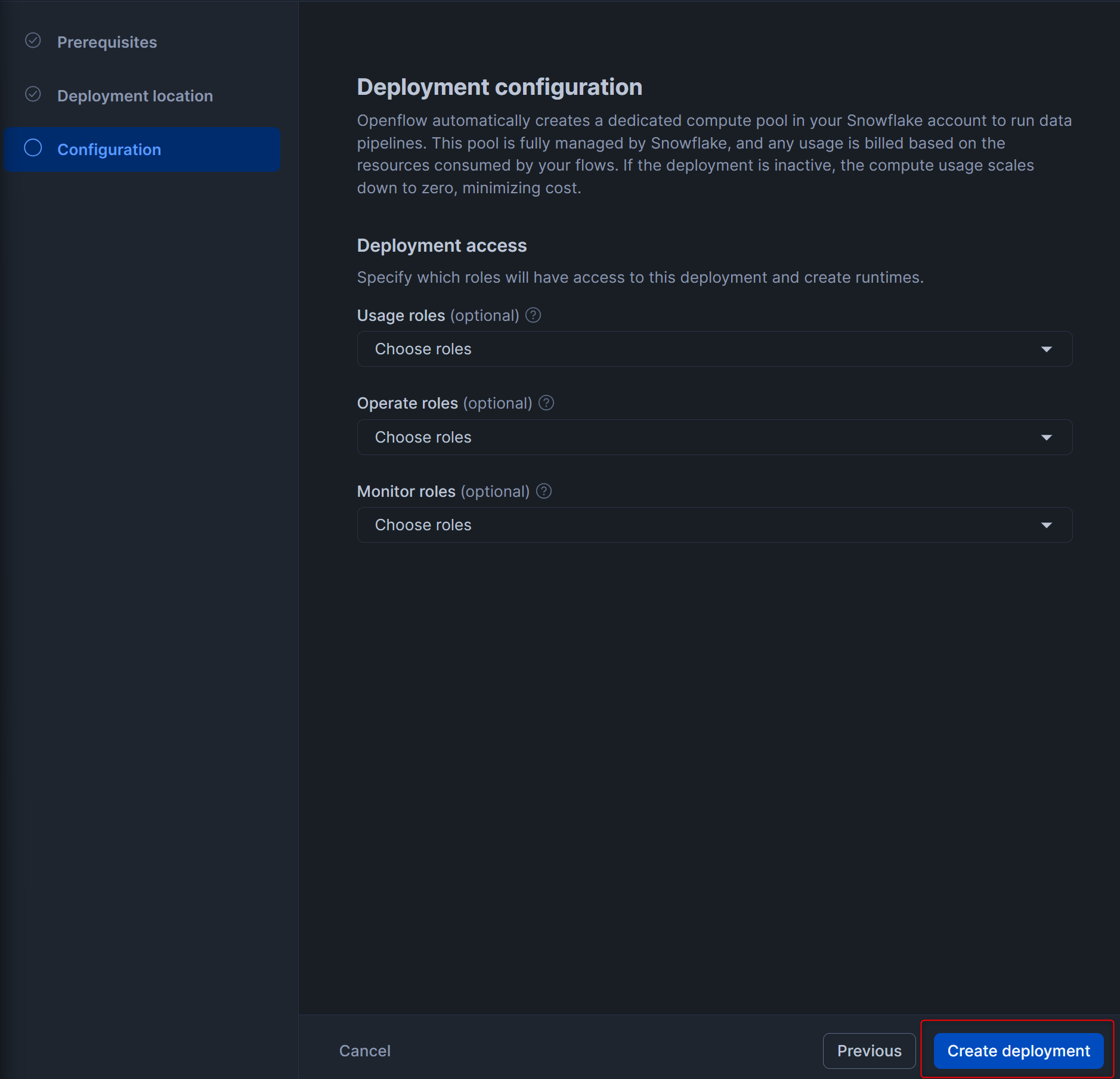
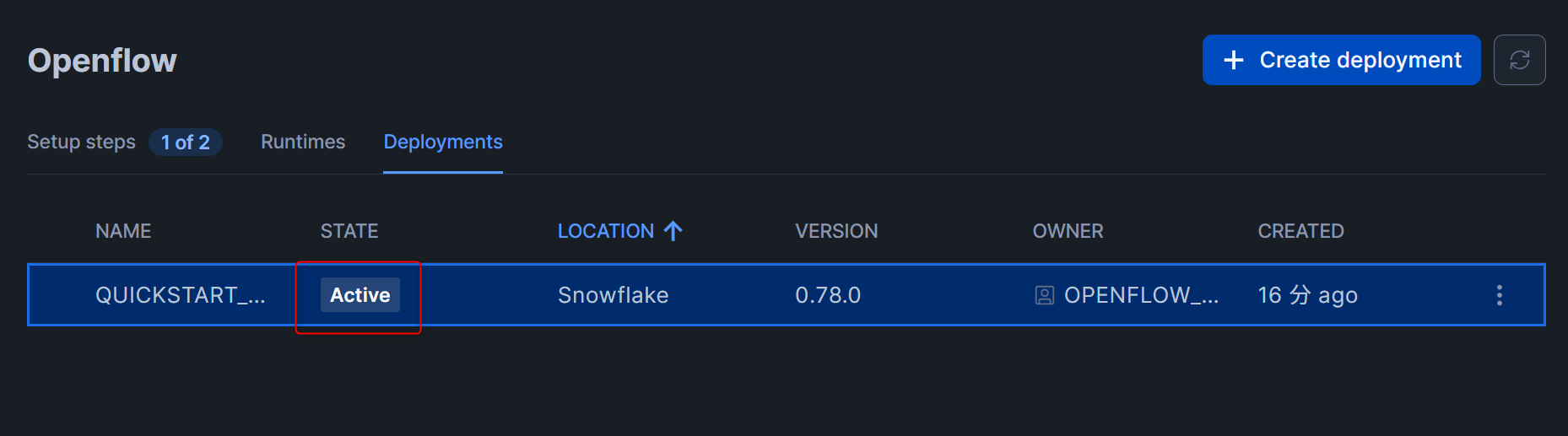
下図のような画面となるので、15分~20分ほど待ちます。(私の場合は15分かかりました。)
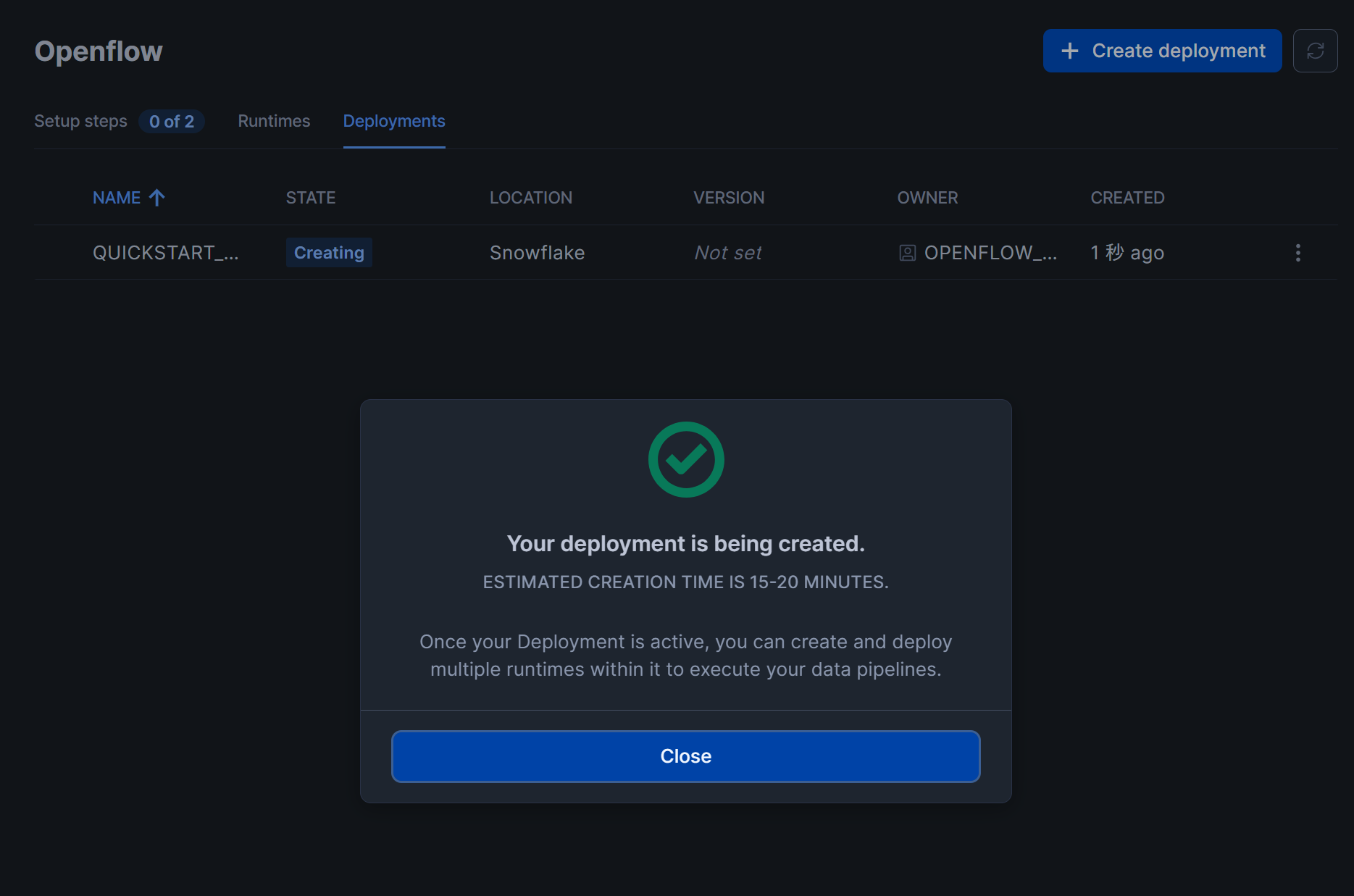
一定時間経過後、下図のようにSTATE列がActiveとなっていれば、Openflowのデプロイメントは作成完了です!
ランタイム用のロールやリソースを作成
次に、Openflowのランタイム用のロールやリソースを作成します。
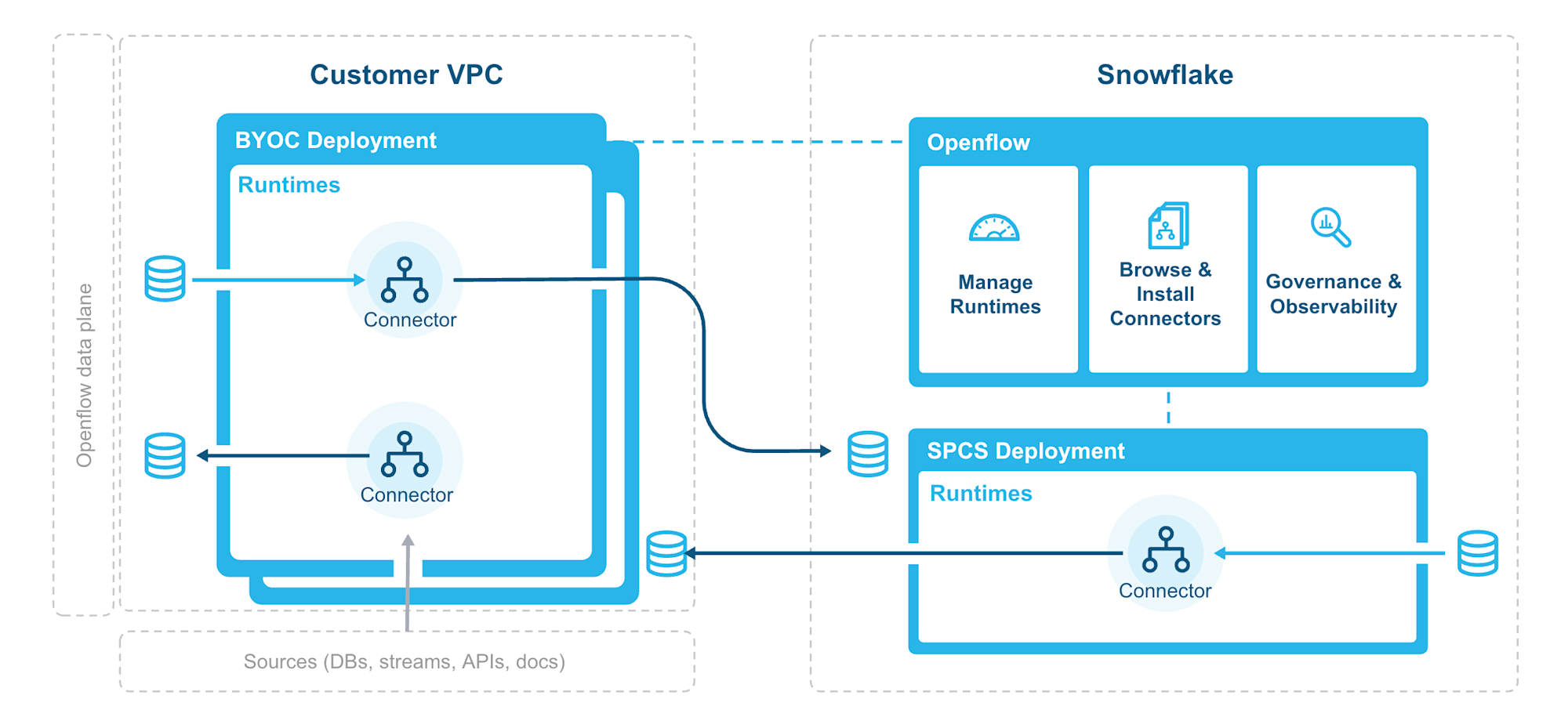
ランタイムは、実際にOpenflow用のコネクタをデプロイして動かす環境となります。(公式Docから引用した下図がわかりやすいです。)
まず、以下のクエリを実行してランタイム用のロールやリソースを作成します。(ウェアハウスのサイズと自動停止までの時間をQuickstartのクエリから変更しています。)
-- Create runtime role
USE ROLE ACCOUNTADMIN;
CREATE ROLE IF NOT EXISTS QUICKSTART_ROLE;
-- Create database for Openflow resources
CREATE DATABASE IF NOT EXISTS QUICKSTART_DATABASE;
-- Create warehouse for data processing
CREATE WAREHOUSE IF NOT EXISTS QUICKSTART_WH
WAREHOUSE_SIZE = XSMALL
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE;
-- Grant privileges to runtime role
GRANT USAGE ON DATABASE QUICKSTART_DATABASE TO ROLE QUICKSTART_ROLE;
GRANT USAGE ON WAREHOUSE QUICKSTART_WH TO ROLE QUICKSTART_ROLE;
-- Grant runtime role to Openflow admin
GRANT ROLE QUICKSTART_ROLE TO ROLE OPENFLOW_ADMIN;
次に、Slack APIにアクセスするためのExternal Access Integrationを作成します。
-- Create schema for network rules
USE ROLE ACCOUNTADMIN;
CREATE SCHEMA IF NOT EXISTS QUICKSTART_DATABASE.NETWORKS;
-- Create network rule for Slack
CREATE OR REPLACE NETWORK RULE slack_api_network_rule
MODE = EGRESS
TYPE = HOST_PORT
VALUE_LIST = ('slack.com', 'wss.slack.com');
-- Create external access integration with network rules
CREATE OR REPLACE EXTERNAL ACCESS INTEGRATION quickstart_access
ALLOWED_NETWORK_RULES = (slack_api_network_rule)
ENABLED = TRUE;
-- Grant usage to runtime role
GRANT USAGE ON INTEGRATION quickstart_access TO ROLE QUICKSTART_ROLE;
ランタイムを作成
先程作成したロールやリソースを用いて、ランタイムを作成していきます。
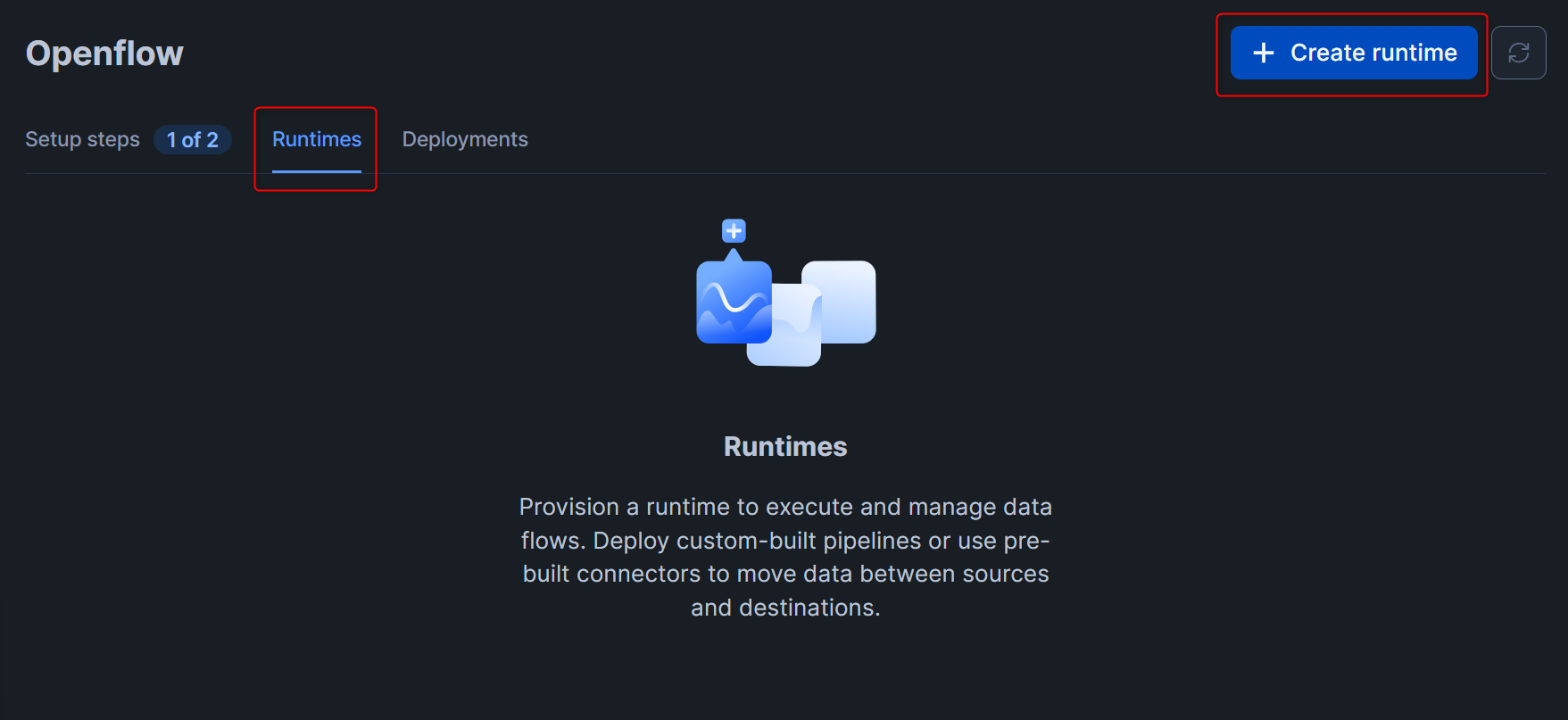
Openflowの画面で、Runtimesタブに切り替えて、右上のCreate runtimeを押します。
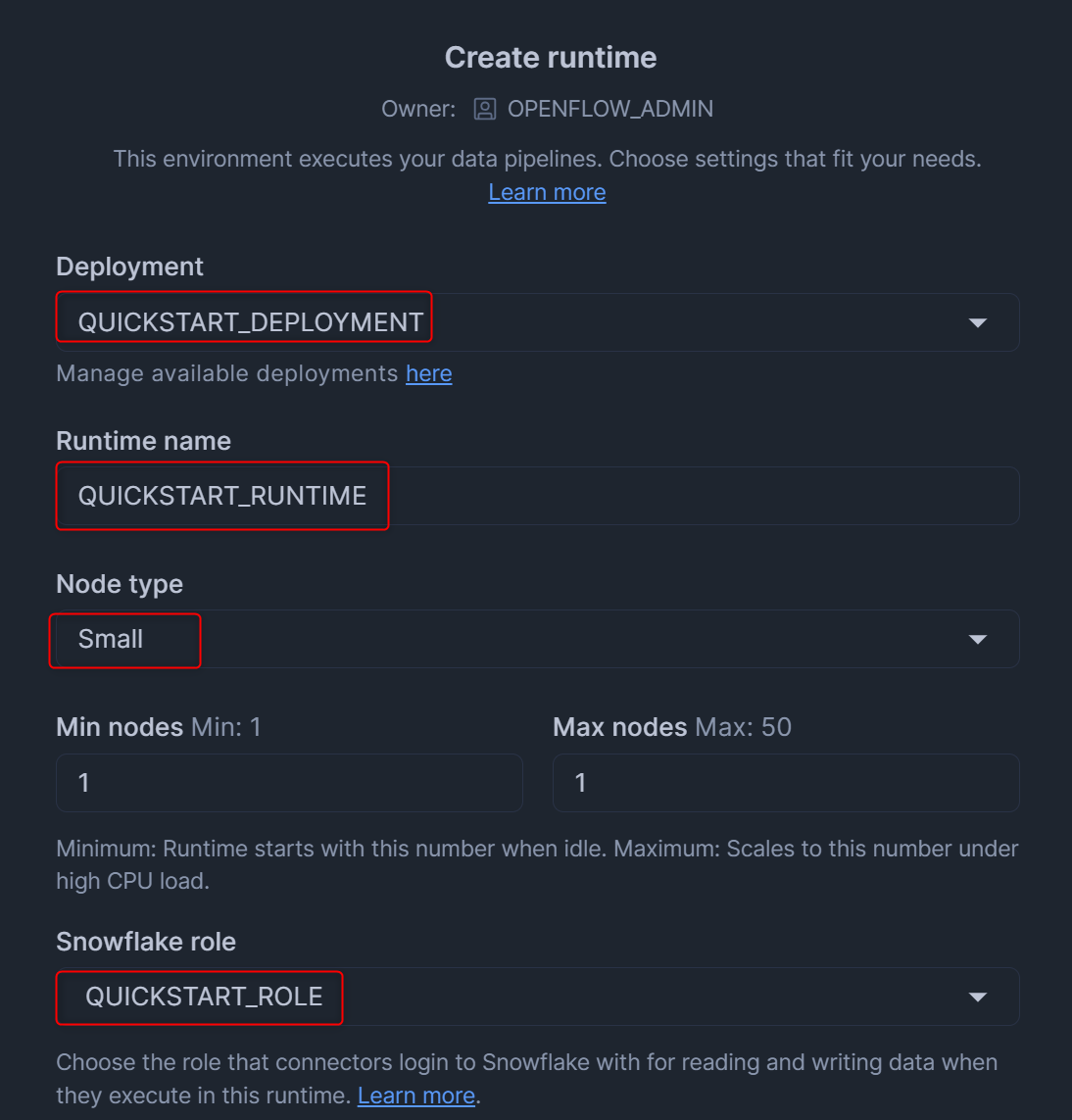
ランタイムの作成画面が表示されるため、下図のように設定します。設定後、右下のCreateを押します。
すると、下図のように表示されます。ランタイムの作成も5~10分必要です。(私の場合は4分かかりました。)
一定時間経過後、下図のようにSTATE列がActiveとなっていれば、ランタイムの作成は完了です!
作成したランタイムの名前をクリックすると、実際にコネクタの追加を行えるキャンバスの画面が開きます。
Slackコネクタの設定
Slackコネクタの設定を行っていきます。
まず、以下のクエリを実行して送信先となるデータベース・スキーマを作成し、必要な権限もQuickstart用のロールに付与します。(CREATE STAGEとCREATE SEQUENCEとCREATE CORTEX SEARCH SERVICEの権限も付与しています。)
USE ROLE SYSADMIN;
CREATE DATABASE DESTINATION_DB;
CREATE SCHEMA DESTINATION_DB.DESTINATION_SCHEMA;
GRANT USAGE ON DATABASE DESTINATION_DB TO ROLE QUICKSTART_ROLE;
GRANT USAGE ON SCHEMA DESTINATION_DB.DESTINATION_SCHEMA TO ROLE QUICKSTART_ROLE;
GRANT CREATE TABLE ON SCHEMA DESTINATION_DB.DESTINATION_SCHEMA TO ROLE QUICKSTART_ROLE;
GRANT CREATE STAGE ON SCHEMA DESTINATION_DB.DESTINATION_SCHEMA TO ROLE QUICKSTART_ROLE;
GRANT CREATE SEQUENCE ON SCHEMA DESTINATION_DB.DESTINATION_SCHEMA TO ROLE QUICKSTART_ROLE;
GRANT CREATE CORTEX SEARCH SERVICE ON SCHEMA DESTINATION_DB.DESTINATION_SCHEMA TO ROLE QUICKSTART_ROLE;
次に、Openflowのトップページに移動し、Featured connectorsからview more connectorsを押します。
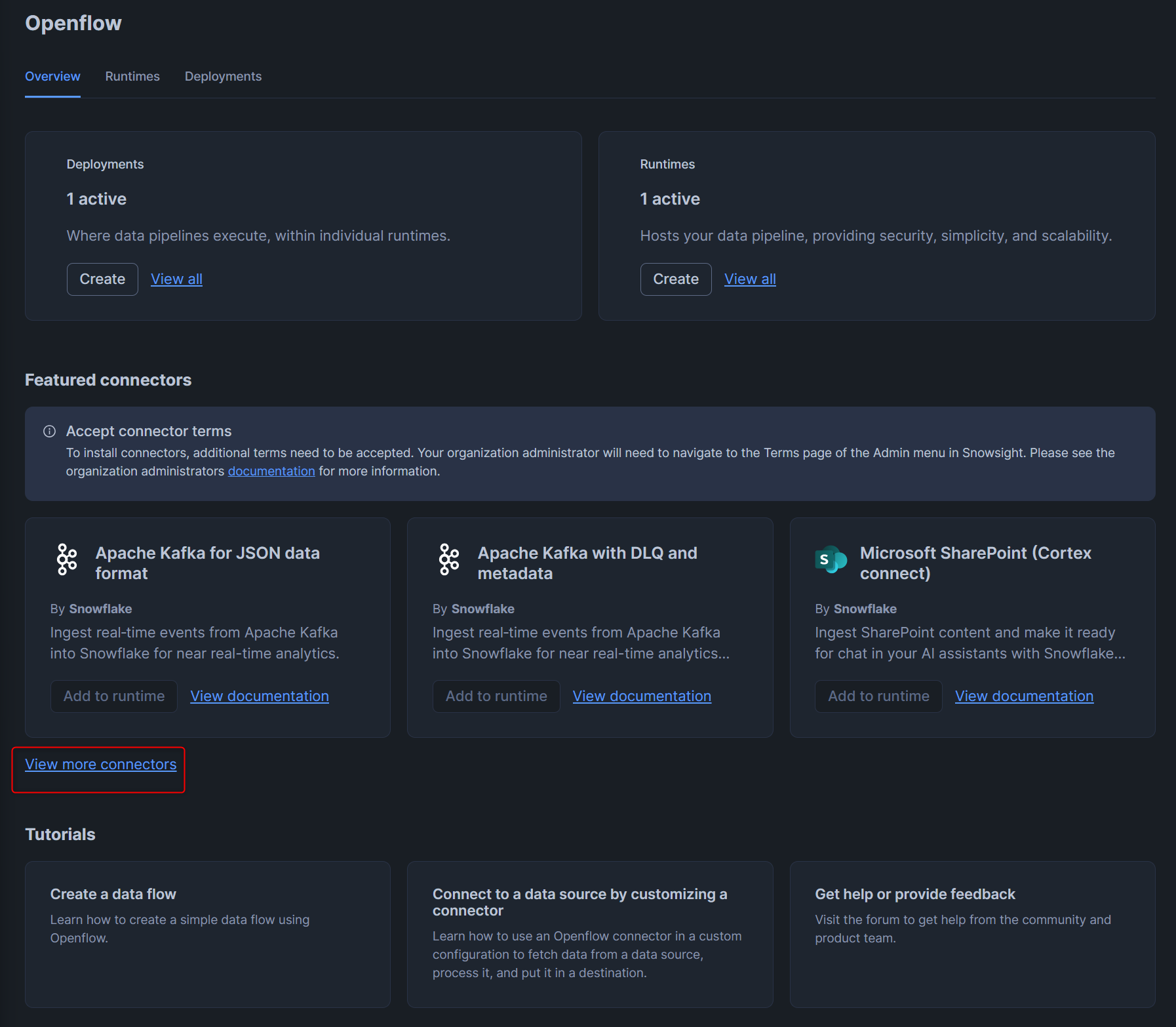
Slackでは2種類ありますが、Openflowならではの機能を使いたいので、Slack(Cortex connect)のAdd to runtimeを押します。
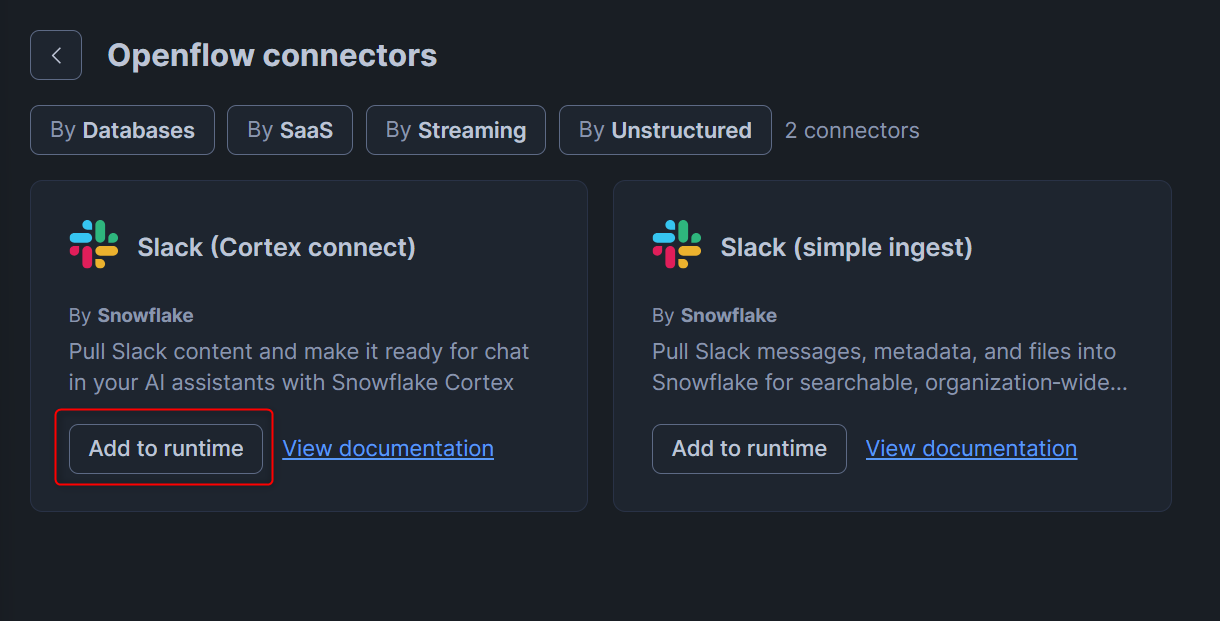
下図の画面となるため、作成したランタイムを設定して、Addを押します。
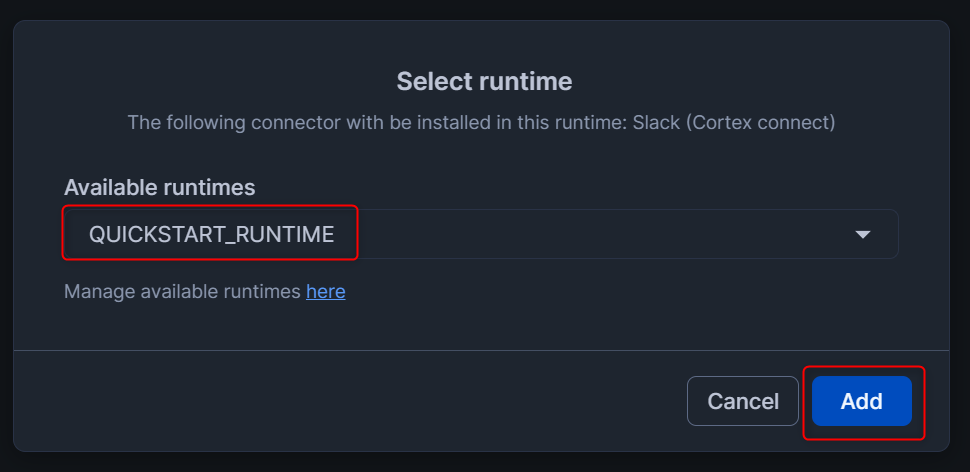
するとランタイムのキャンバス画面が立ち上がり、Slack(Cortex connect)が追加されていることがわかります。(この追加されたオブジェクトは、Openflow用語で「process group」と呼ぶようです。)
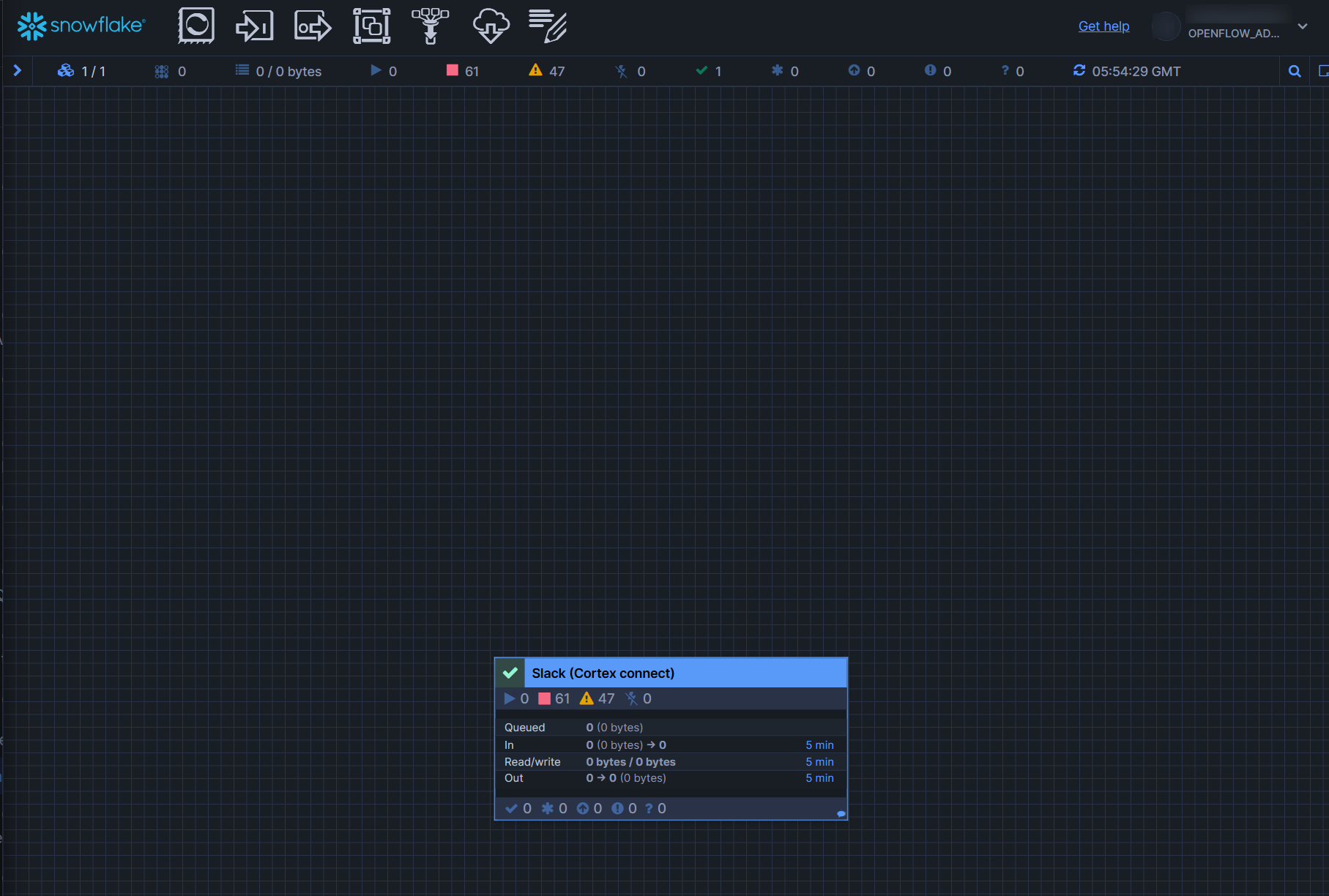
次に、追加されたprocess groupを右クリックし、Parametersを押します。
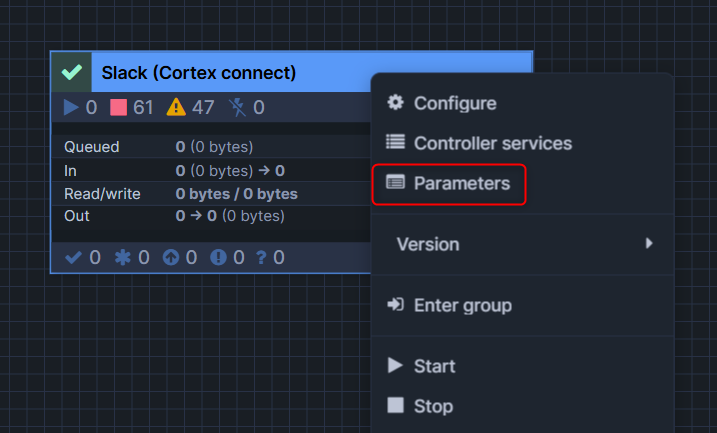
下図のような画面となるため、Slackコネクタの公式Docの内容に沿って、各種Parameterを入れていきます。
各設定値の横の「・・・」を押して、Overrideを押すことで入力することが出来ます。
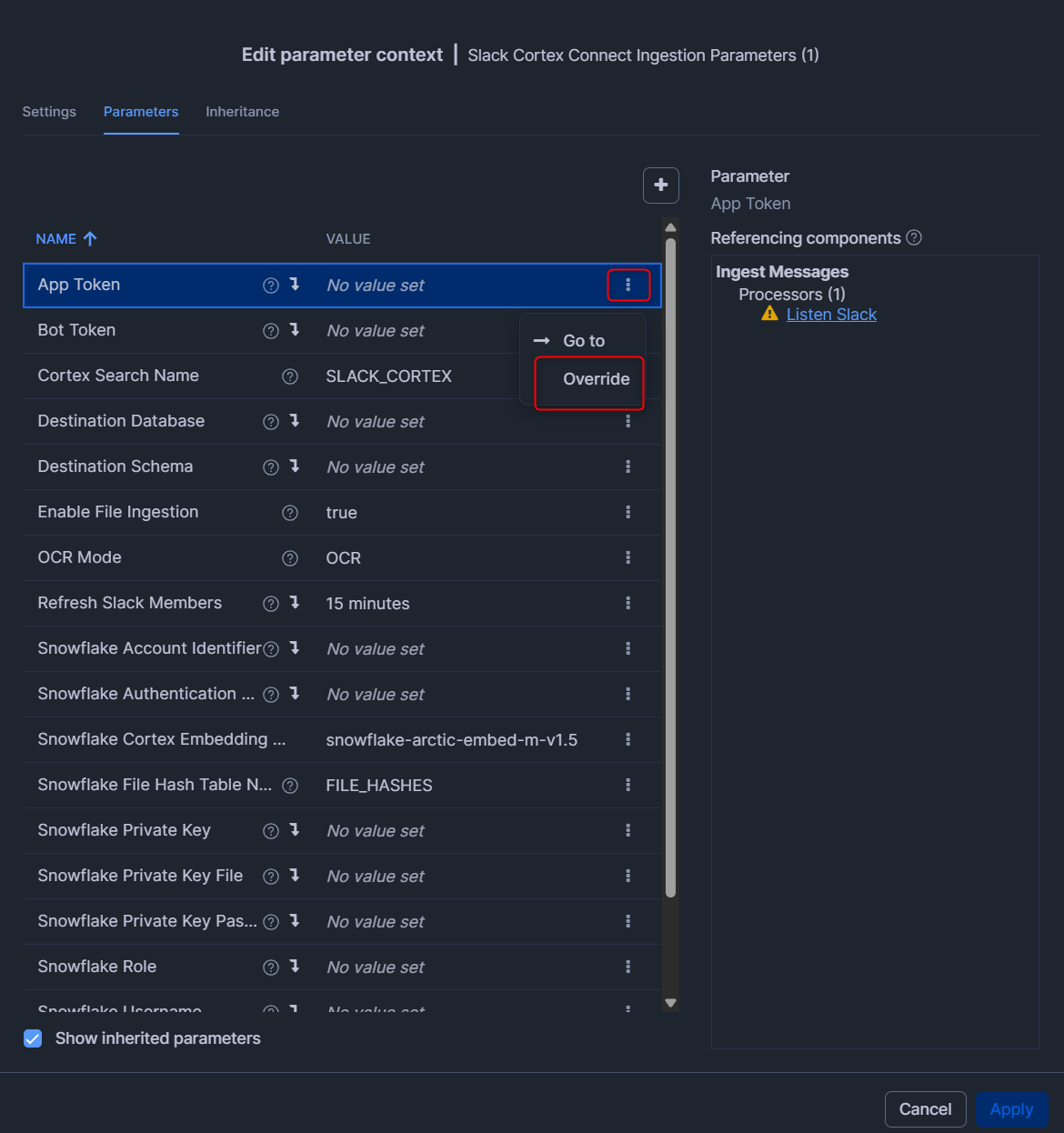
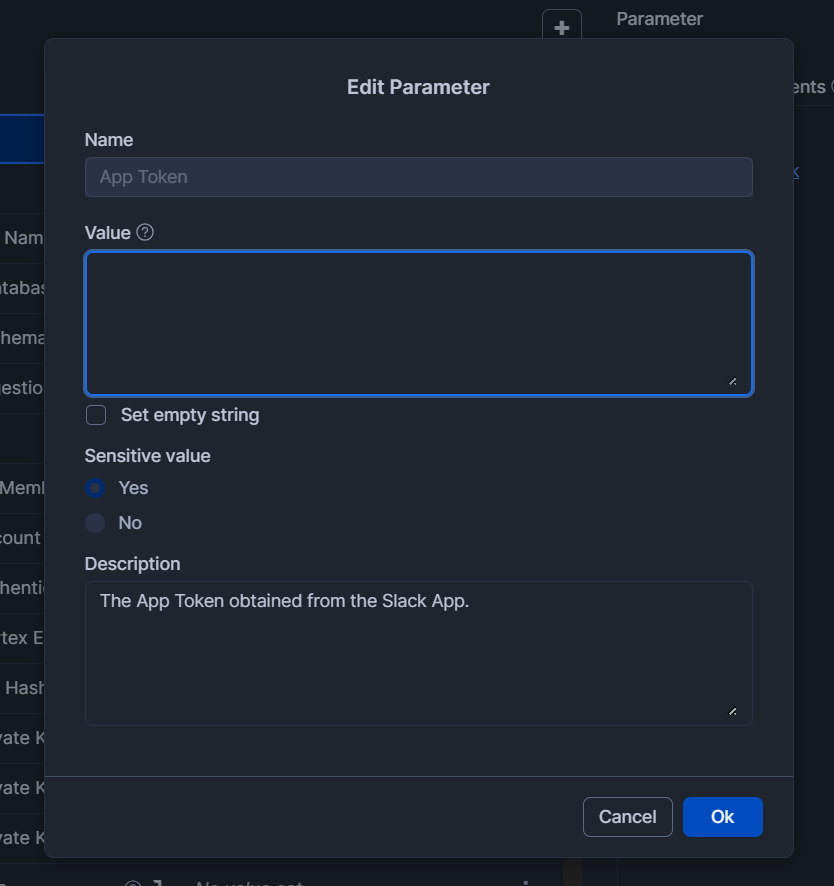
入力後、右下のApplyを押します。(今回はUpload Intervalを60 secondsに設定しました。)
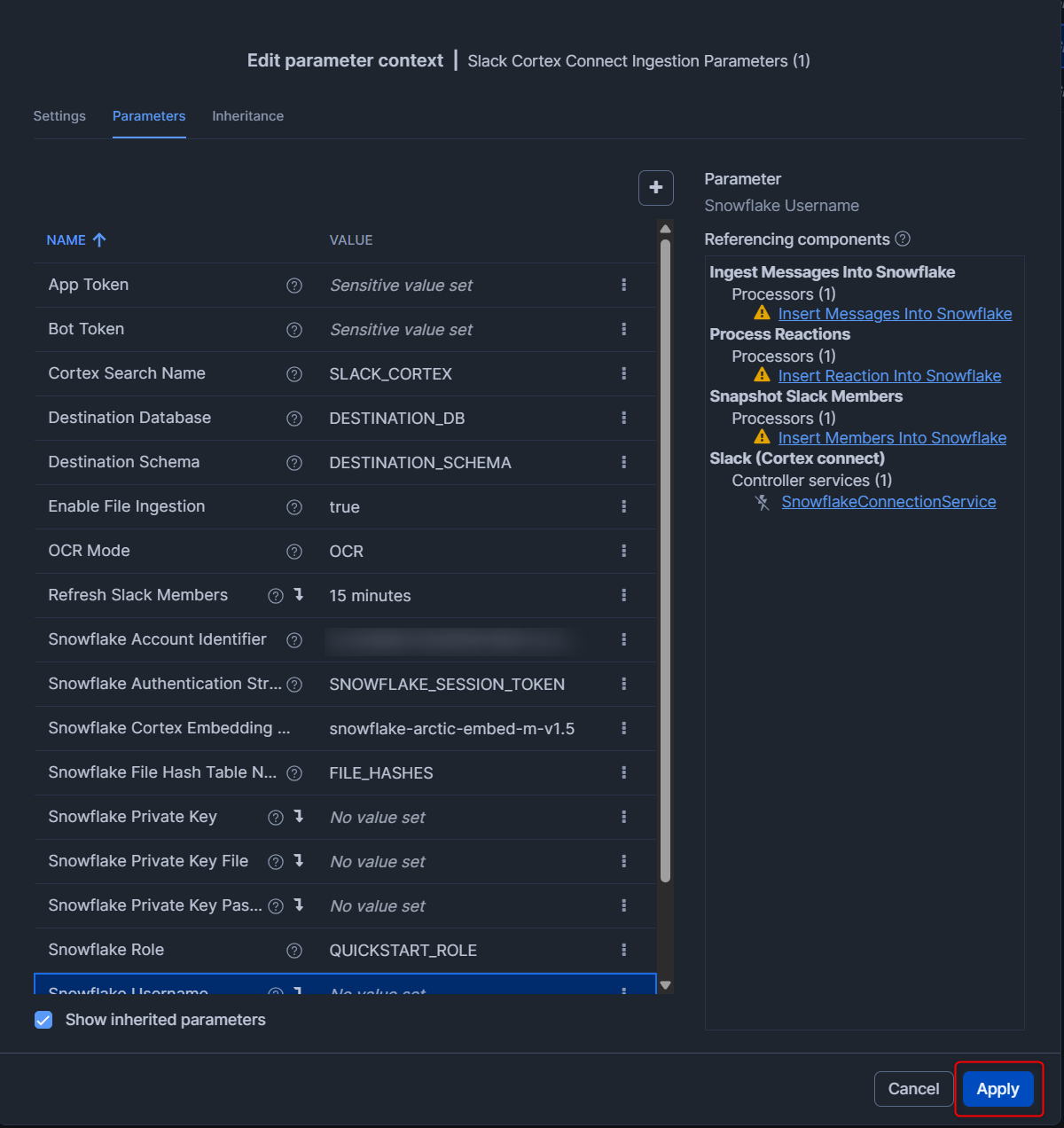
下図のようにパラメータのアップデートを確認する画面となります。右下のCloseを押します。
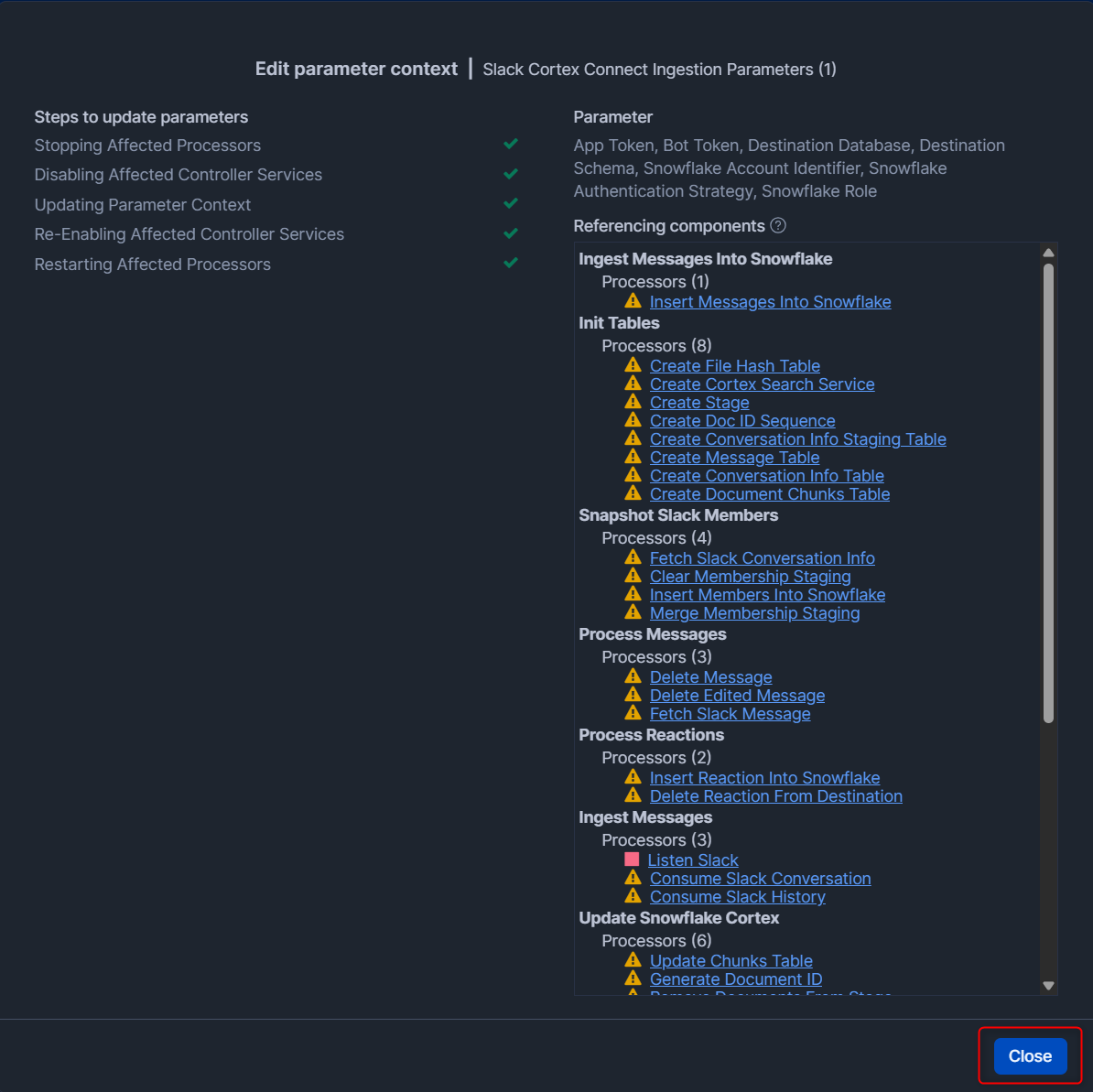
Slackのデータを同期してみる
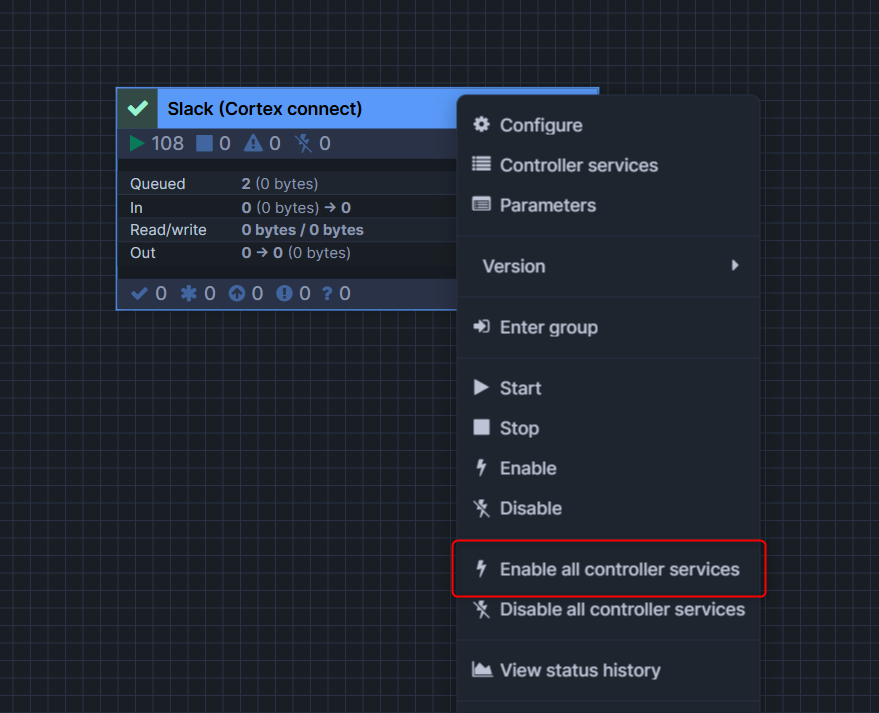
対象のprocess groupに対して右クリックして、Enable all controller servicesを押します。
そのあと、Startを押します。
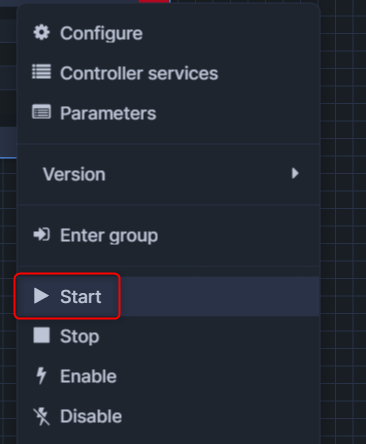
今回は60秒ごとに同期される設定としていたため、一定時間経過した後に正しくデータがロードされているか確認してみます。
一定時間経過すると、process groupのRead/Writeのスキャン量が増えているのがわかります。
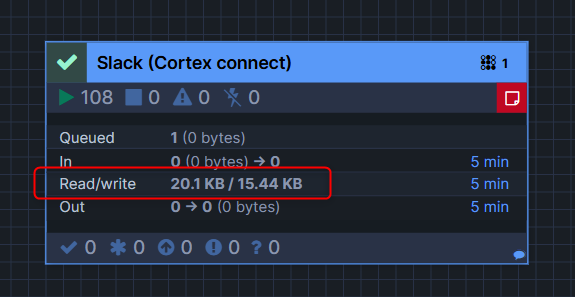
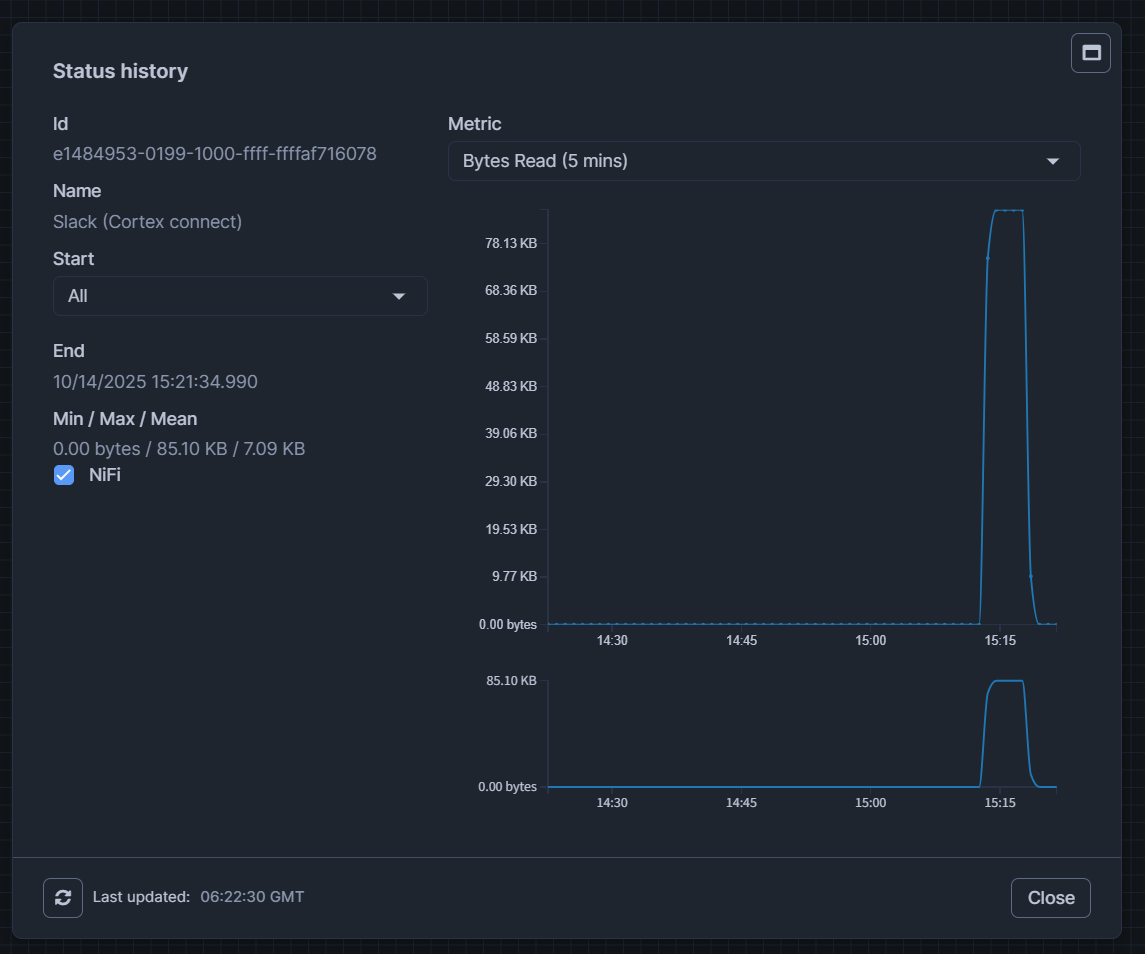
対象のprocess groupに対して右クリックして、View status historyを押すと、どれだけの容量が読み込まれたかなどのメトリクスを確認できます。
この上で、実際にデータを確認してみます。
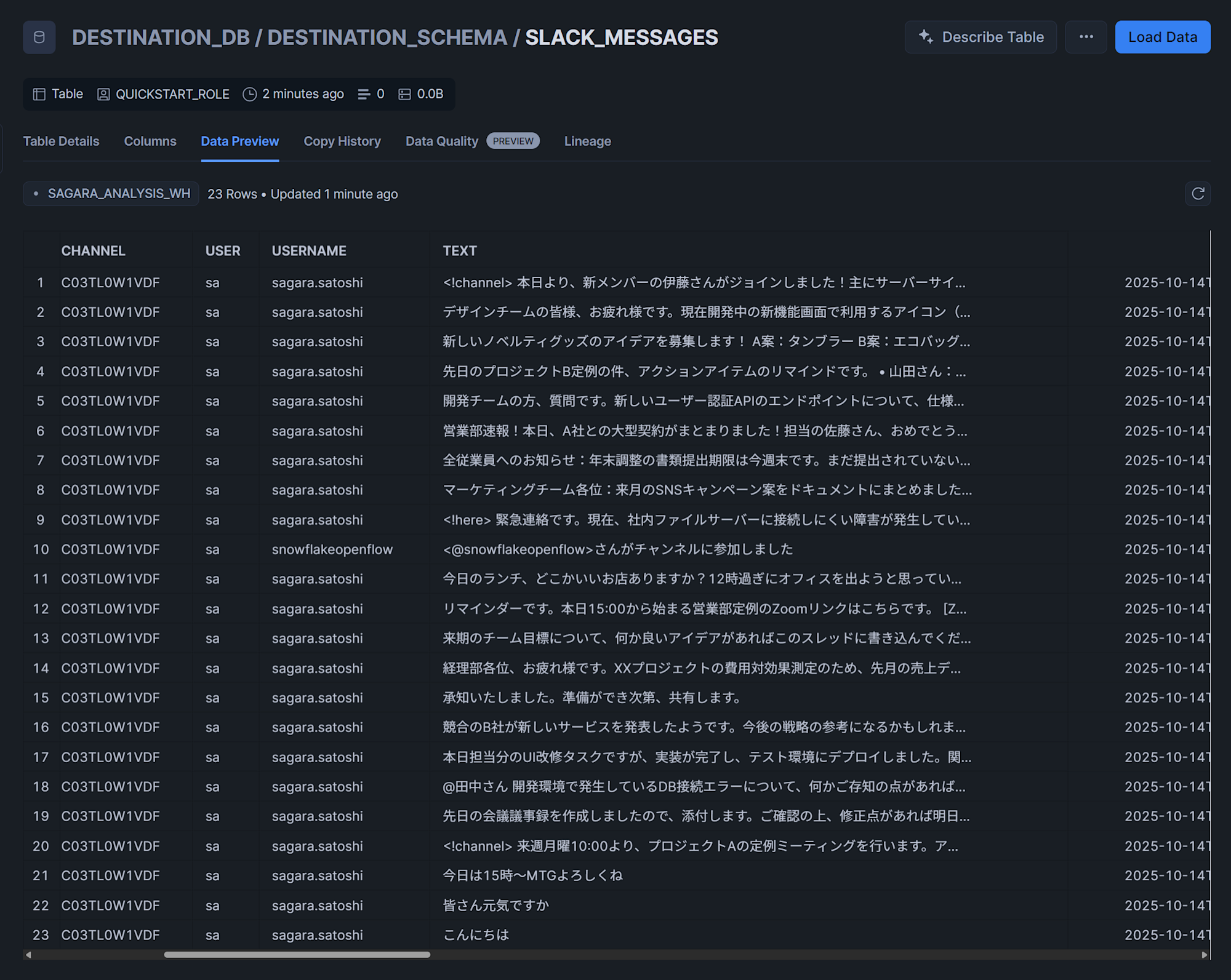
まず送信先として設定したスキーマを見ると、下図のようにテーブルなどのオブジェクトが作成されていることがわかります。
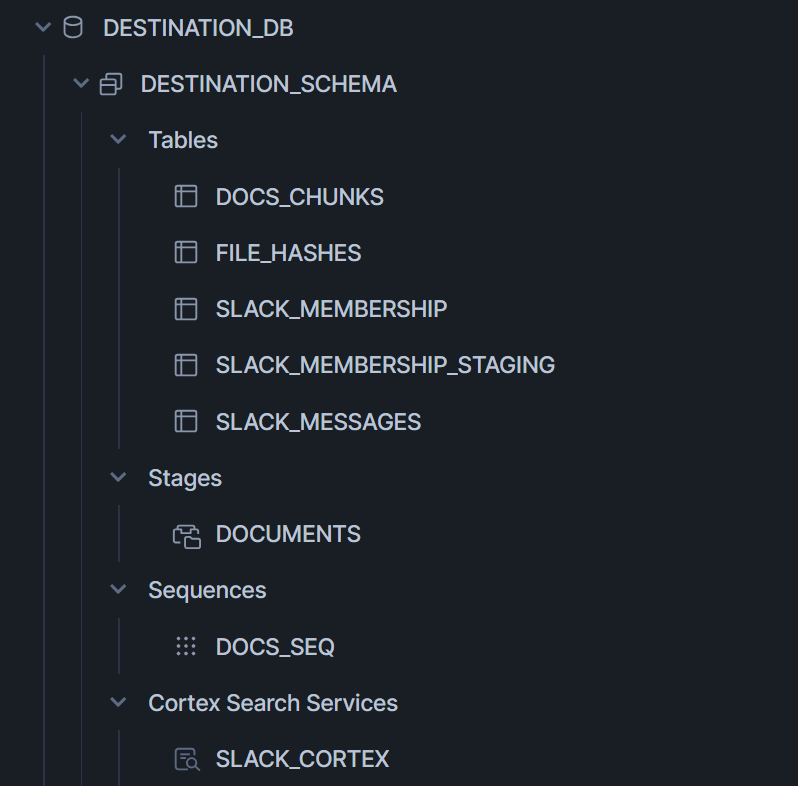
実際にテーブルを見ると、Slackのメッセージがデータとしてロードされていることがわかります。
おまけ:エラー発生時の対処方法
実際にエラーが起きていると、process groupの右上が赤く表示され、マウスオーバーするとエラーメッセージが表示されます。
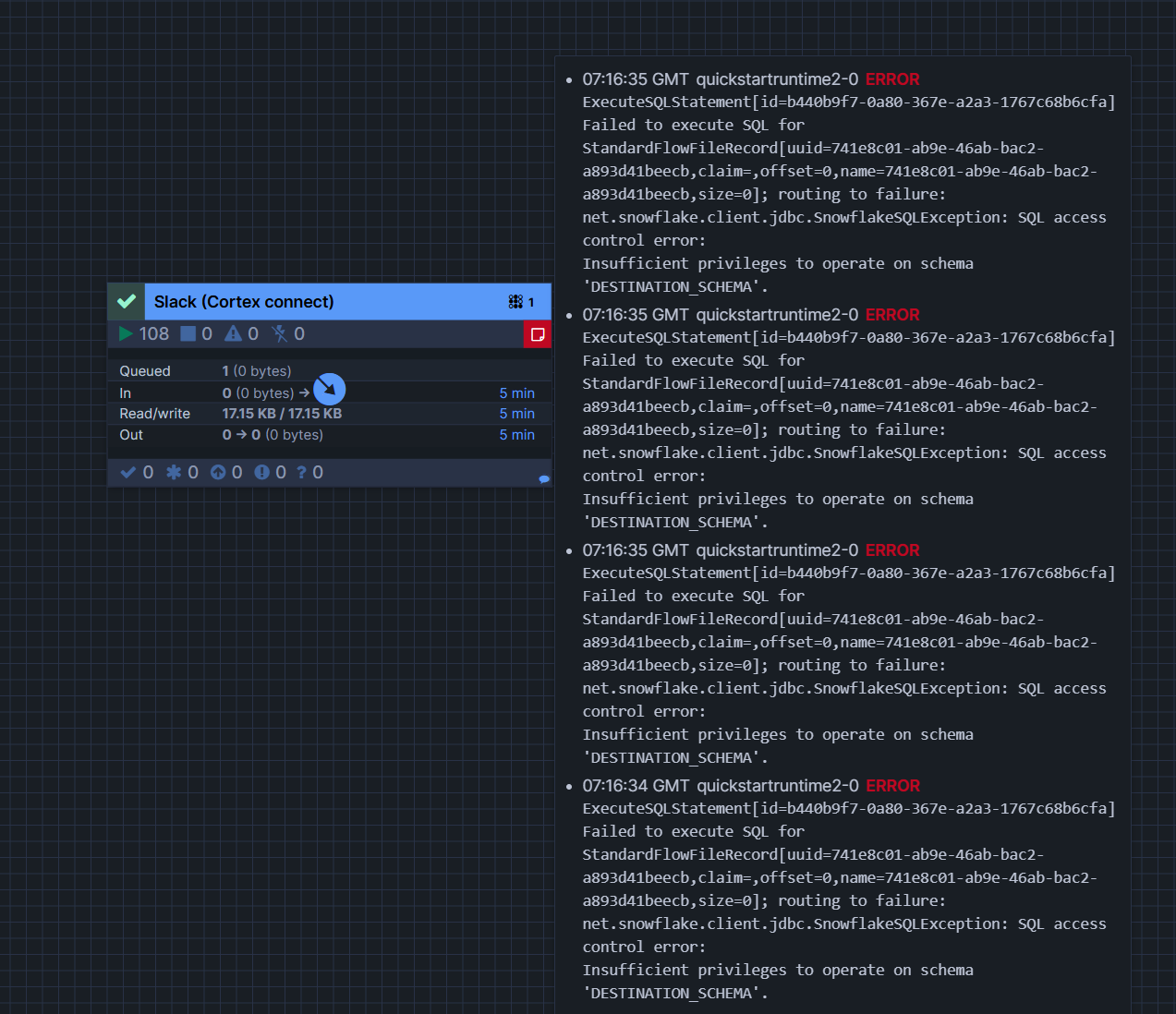
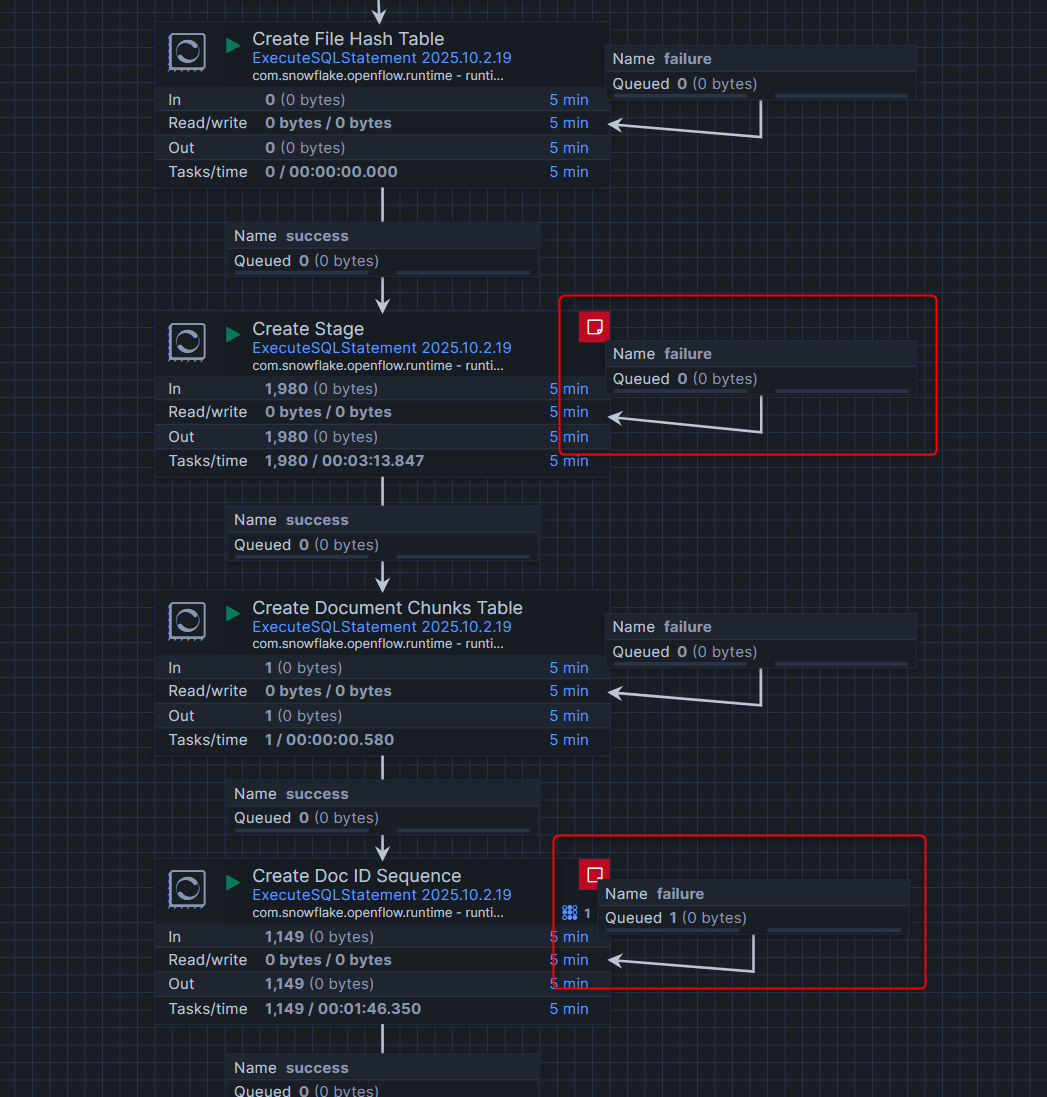
このエラーの原因調査ですが、対象のprocess groupをダブルクリックするとより細かくどのような処理が行われているかわかります。今回自分が試した際は、Create StageとCreate Doc ID Sequenceでエラーが出ていたので、「CREATE STAGEとCREATE SEQUENCEの権限が足りないのかも?」と予想し、権限を付与したらエラーが解消されました。
Snowflake Intelligenceから問い合わせしてみる
また、Cortex Search Serviceも自動で作成されているため、Snowflake-managed MCP ServerやSnowflake Intelligence経由でSlackのデータに対して問い合わせを行える仕組みが簡単に構築できます!
※以下は参考までに、Snowflake Intelligence用のロールに作成されたCortex Search Serviceの権限を付与して、Snowflake Intelligenceから自然言語で問い合わせしてみた例です。(Snowflake Intelligenceについてはこちらのブログをご覧ください。)
- 作成されたCortex Search Serviceの権限をSnowflake Intelligence用のロールに付与
GRANT USAGE ON DATABASE DESTINATION_DB TO ROLE SNOWFLAKE_INTELLIGENCE_ADMIN_RL;
GRANT USAGE ON SCHEMA DESTINATION_DB.DESTINATION_SCHEMA TO ROLE SNOWFLAKE_INTELLIGENCE_ADMIN_RL;
GRANT USAGE ON CORTEX SEARCH SERVICE DESTINATION_DB.DESTINATION_SCHEMA.SLACK_CORTEX TO ROLE SNOWFLAKE_INTELLIGENCE_ADMIN_RL;
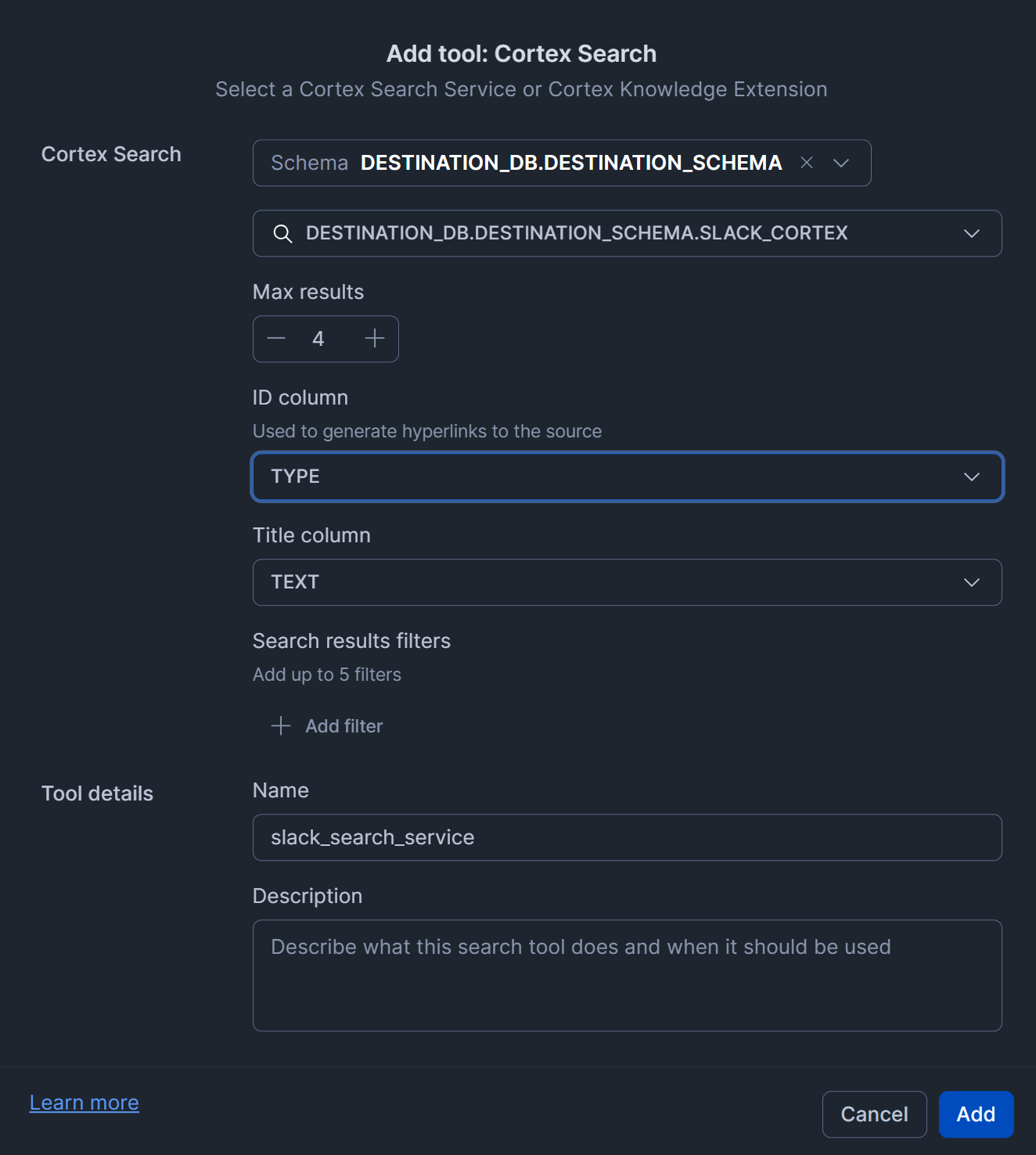
- Cortex Search Serviceをエージェントに追加(設定値が適切ではないかもしれないためご注意ください。)
- 実際にSnowflake Intelligenceで問い合わせしてみた結果
ちゃんと、Slackのメッセージ内容を元に回答していることがわかりますね!これは凄い!

Slackで追加メッセージを作成し、自動で同期されるかを確認してみる
※こちらはエラーが起きてうまく行きませんでした…
続いて、Slackアプリを追加しているチャンネルで下図のように追加の投稿を行って、自動で同期されるかを確認してみます。

この後でprocess groupをダブルクリックすると、Ingest Messagesのprocess groupの中のIngest Messages Into SnowflakeとLog Failuresでエラーとなりました。
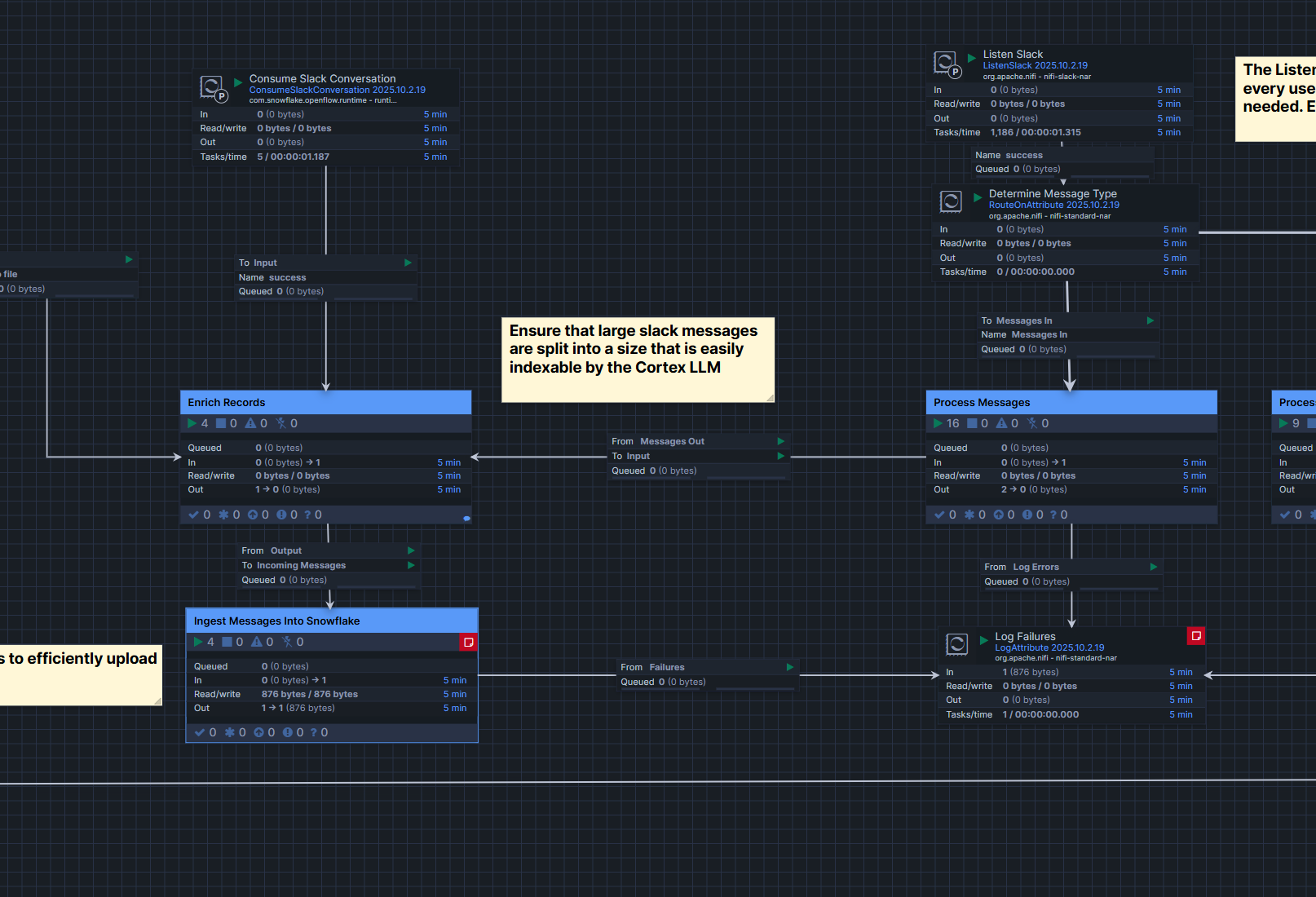
エラーメッセージは下記のようなものでした。このエラーがわからず、ここで検証を一旦終えることにしました…
Ingest Messages Into Snowflake
07:53:33 GMT
All Nodes
ERROR
PutSnowpipeStreaming[id=5bb92c9c-64b7-39d0-9520-e980ef038888] Failed to flush Channels for StandardFlowFileRecord[uuid=dcdf9349-a8ae-478b-8f19-cbc48914f3db,claim=StandardContentClaim [resourceClaim=StandardResourceClaim[id=1760425882818-2, container=repo1, section=2], offset=106084, length=876],offset=0,name=73eb0ff9-0bf1-4fff-b86c-caf9536589d4,size=876]: org.apache.nifi.processor.exception.ProcessException: Failed to flush rows to Invalid Ingest Channels [DESTINATION_DB.DESTINATION_SCHEMA.SLACK_MESSAGES.OPENFLOW.QUICKSTARTRUNTIME2-0.0]
Log Failuers
LogAttribute[id=26a93f83-4ff1-318e-b735-5dbd0773705c] logging for flow file StandardFlowFileRecord[uuid=dcdf9349-a8ae-478b-8f19-cbc48914f3db,claim=StandardContentClaim [resourceClaim=StandardResourceClaim[id=1760425882818-2, container=repo1, section=2], offset=106084, length=876],offset=0,name=73eb0ff9-0bf1-4fff-b86c-caf9536589d4,size=876]
--------------------------------------------------
FlowFile Properties
Key: 'entryDate'
Value: 'Tue Oct 14 07:52:33 GMT 2025'
Key: 'lineageStartDate'
Value: 'Tue Oct 14 07:52:33 GMT 2025'
Key: 'fileSize'
Value: '876'
FlowFile Attribute Map Content
Key: 'QueryRecord.Route'
Value: 'messages'
Key: 'filename'
Value: '73eb0ff9-0bf1-4fff-b86c-caf9536589d4'
Key: 'merge.bin.age'
Value: '60043'
Key: 'merge.completion.reason'
Value: 'Bin has reached Max Bin Age'
Key: 'merge.count'
Value: '1'
Key: 'mime.type'
Value: 'application/json'
Key: 'path'
Value: './'
Key: 'record.count'
Value: '1'
Key: 'slack.channel.id'
Value: 'C03TL0W1VDF'
Key: 'slack.channel.name'
Value: 'random'
Key: 'slack.message.count'
Value: '1'
Key: 'uuid'
Value: 'dcdf9349-a8ae-478b-8f19-cbc48914f3db'
また、このエラーログが出てから一定時間経過すると、データロードに成功していないのにエラー表示が下図のように消えていました。データロードに成功していないのにエラーが解消されると困ってしまうため、このエラー周りは改善されることを期待したいです!
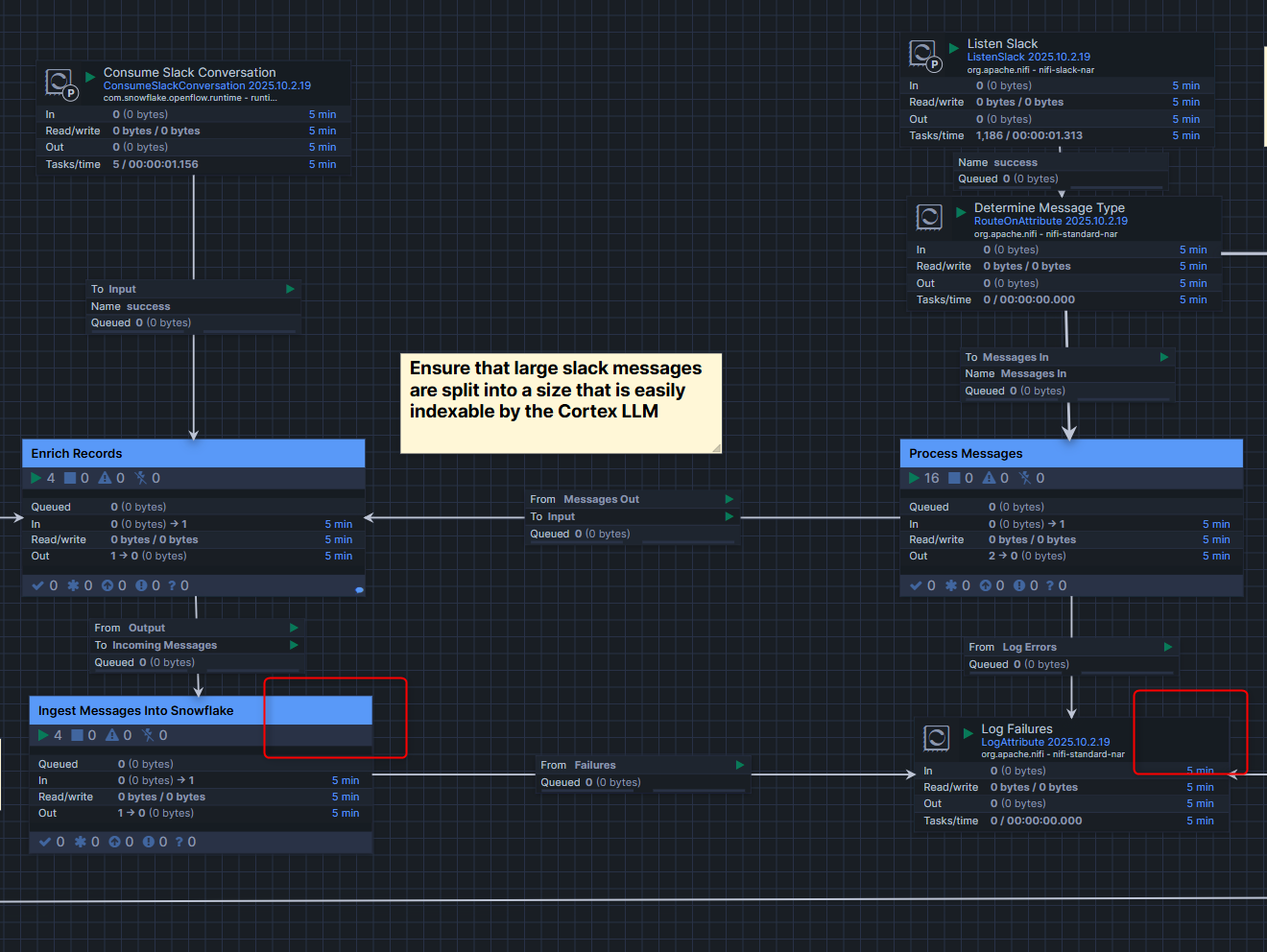
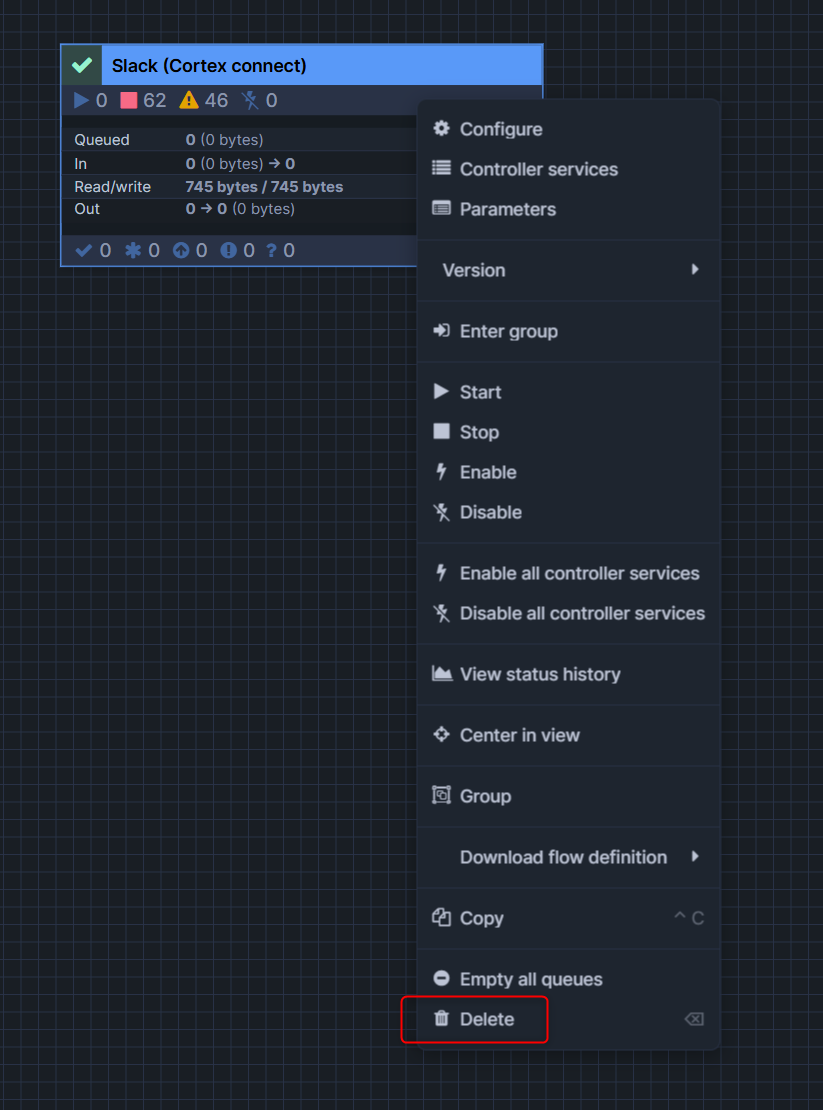
おまけ:process groupの削除方法
process groupの削除方法ですが、以下のような手順となります。
1.Stopを押して一時停止
2.Disable all controller servicesを押して無効化
3.Deleteを押して削除
お片付け
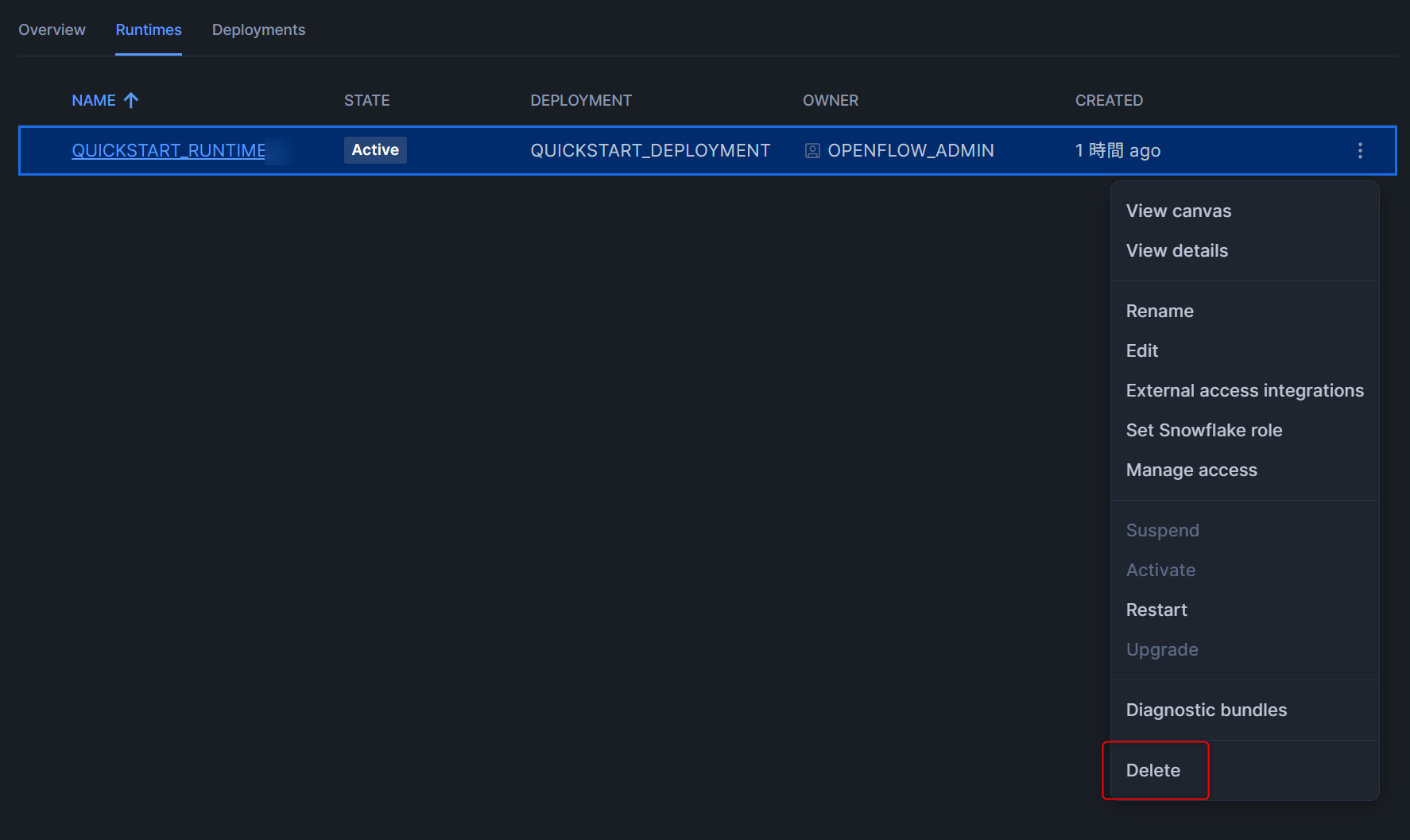
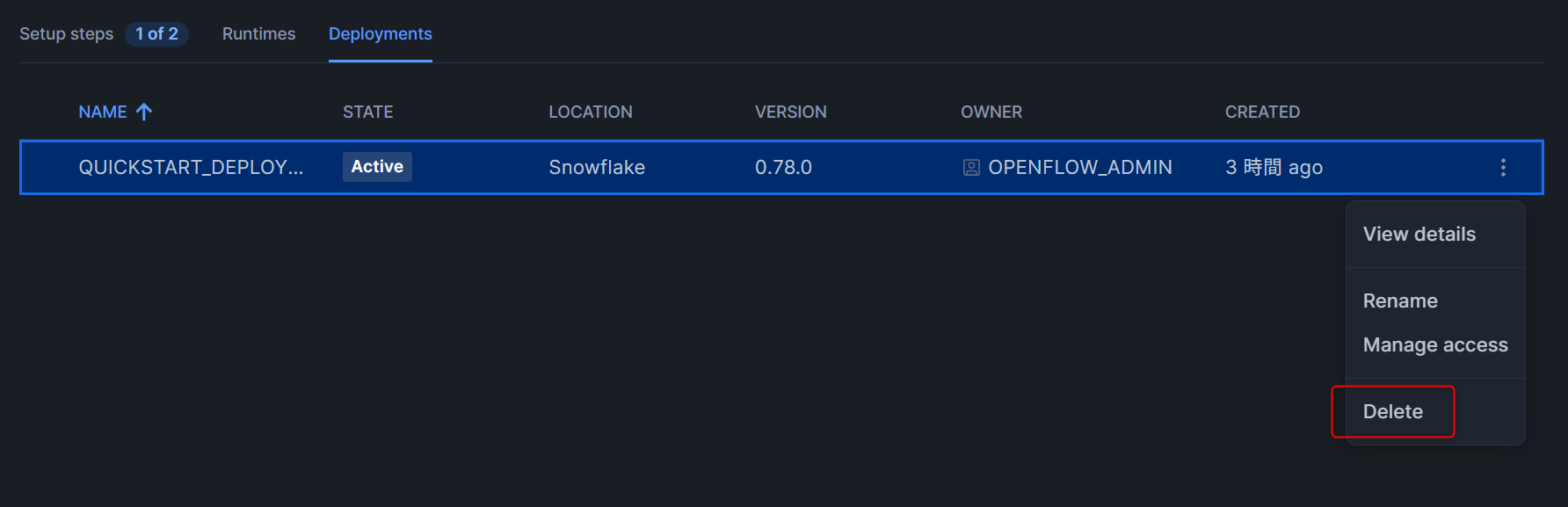
ランタイムとデプロイメントの削除
下図のように、ランタイムとデプロイメントをそれぞれ削除します。
- ランタイム
- デプロイメント(ランタイムの削除後でないと、削除できません)
各種Snowflakeリソースの削除
以下のクエリを実行して、各種Snowflakeリソースを削除します。
-- Switch to ACCOUNTADMIN
USE ROLE ACCOUNTADMIN;
-- Drop external access integration
DROP INTEGRATION IF EXISTS quickstart_access;
-- Drop network rules
DROP NETWORK RULE IF EXISTS slack_api_network_rule;
-- Drop warehouse
DROP WAREHOUSE IF EXISTS QUICKSTART_WH;
-- Drop database
DROP DATABASE IF EXISTS QUICKSTART_DATABASE;
DROP DATABASE IF EXISTS DESTINATION_DB;
-- Drop role
DROP ROLE IF EXISTS QUICKSTART_ROLE;
DROP ROLE IF EXISTS OPENFLOW_ADMIN;
参考:SPCS版のOpenflowのコストについて
SPCS版のOpenflowはとても簡単に利用できますが、やはり気になるのはコスト面だと思います。
コストについてはSnowflake公式からもドキュメントが出ており、こちらが参考になると思います。コストの基本的な考えとしては、「常時稼働するコントロールプールとして使っているコンピュートプールの費用がベースとなり、ランタイムに指定したコンピュートプールが稼働した分の費用と、ストレージやSnowpipeなどのSnowflakeの機能の利用料も発生する」という考えになります。
最後に
SPCS上で実行されるOpenflow Snowflake Deploymentsを用いてSlackのデータをロードしてSnowflake Intelligenceから問い合わせてみました。
データを追加した際の2回目のロードがうまくいかなかったりエラーの通知が消えてしまったことなどは気になったのですが、Cortex Search Serviceまで自動で作成してくれるため、すぐにロードしたデータに対してSnowflake-managed MCP ServerやSnowflake Intelligence経由で問い合わせできるのは素晴らしいなと感じました!
まだパブリックプレビュー段階のため、今後のアップデートに期待しています!







